Olá a todos, meu nome é Mu Chuan
O principal componente do desempenho de simultaneidade da linguagem Go está em seu princípio de agendamento. Go usa um modelo chamado agendamento M:N, onde M representa o thread de estado do kernel do sistema operacional e N representa o thread de estado do usuário Goroutines (nível leve da linguagem Go fio)
Em essência, o escalonamento de Goroutine é o processo de envio de Goroutine (G) para a CPU para execução de acordo com um algoritmo específico. Como a CPU não pode detectar Goroutines e apenas detectar threads do kernel, o agendador Go é necessário para agendar as Goroutines para o thread do kernel M e, em seguida, o agendador do sistema operacional coloca o thread do kernel M na CPU para execução. M é na verdade um encapsulamento de threads em nível de kernel, então a principal tarefa do agendador Go é atribuir Goroutines a M
A implementação do agendador Go passou por múltiplas evoluções, inclusive do modelo GM original para o modelo GMP, do não suporte à preempção ao suporte à preempção cooperativa e, em seguida, ao suporte à preempção assíncrona baseada em sinal. Este processo evolutivo passou por otimização e polimento contínuos para melhorar o desempenho de simultaneidade da linguagem Go.
1. Conceito de modelo GMP
Na linguagem Go, a unidade básica de processamento simultâneo são as Goroutines, que são threads leves agendadas e gerenciadas pelo tempo de execução Go. No centro deste sistema de agendamento está o modelo GMP, que consiste em três componentes principais:
G (Goroutines): thread do usuário, criado através da palavra-chave go
M (Máquina): thread do sistema operacional
P (Processador): Contexto de agendamento, que mantém um conjunto de filas Goroutine
As Goroutines ocupam menos memória que os threads tradicionais e seus custos de criação e destruição são muito baixos, portanto, milhares de Goroutines podem ser facilmente criadas sem causar um grande consumo de recursos. Esse recurso é muito útil em aplicativos de alta simultaneidade. Por exemplo, precisamos escrever um servidor de rede e cada conexão de cliente requer uma Goroutine separada para lidar com a solicitação. No modelo de threading tradicional, a criação de threads para cada conexão pode levar ao esgotamento dos recursos, mas no Go, milhares de Goroutines podem ser facilmente criadas para lidar com solicitações de clientes simultaneamente, sem problemas significativos de desempenho.
2. Idéias de design de modelo GMP
Aproveite o paralelismo
Múltiplas corrotinas estão vinculadas a diferentes threads do sistema operacional e podem tirar proveito de CPUs multi-core
Reutilização de thread
Mecanismo de roubo de trabalho: quando o thread M não tem G executável, ele tenta roubar G de P vinculado a outro M para reduzir a ociosidade.Mecanismo de transferência: quando o thread M é bloqueado devido à chamada do sistema G, ele transfere P para outro M ocioso para execução. , M executa o G restante de P
Agendamento preventivo
Evite que certos Goroutines ocupem threads por muito tempo, fazendo com que outros Goroutines morram de fome, e resolva problemas de justiça.
3. Princípio do modelo GMP
Quem vai providenciar
O agendador Go é responsável por agendar G para M. O agendador Go faz parte do tempo de execução Go. O tempo de execução Go é responsável por implementar funções importantes, como agendamento simultâneo, coleta de lixo e gerenciamento de pilha de memória do Go.
Objeto agendado
Fonte de G
Runnext de P (apenas 1 G, princípio de localidade, será sempre agendado primeiro)
Fila local de P (matriz, até 256 G)
Fila G global (lista vinculada, ilimitada)
Network poller_network poller_ (armazena G onde as chamadas de rede são bloqueadas)
Fonte de P
fila P global (matriz, GOMAXPROCS P)
Fonte de M
Fila de threads em suspensão (não vinculada a P, dormir por muito tempo aguardará a reciclagem e destruição do GC)
Execute o thread (vincule P, aponte para G em P)
Fio giratório (ligado P, apontando para G0 de M)
Agendamento de horário
Nas seguintes situações, a goroutine em execução será trocada
Agendamento preventivo
Sysmon detecta que a corrotina está em execução por muito tempo (como suspensão ou loop infinito), muda para g0 e entra no loop de agendamento.
agendamento proativo
Uma nova corrotina é iniciada e executada, acionando um loop de agendamento.
Chame ativamente runtime.Gosched(), mude para g0 e entre no loop de agendamento
Após a coleta de lixo stw, g será selecionado novamente para iniciar a execução.
agendamento passivo
A chamada do sistema bloqueia (sincroniza), bloqueia G e M, separa P de M, entrega P a outro M para ligação e outro M executa o G restante de P
A chamada de E/S da rede bloqueia (de forma assíncrona), bloqueia G, move G para o NetPoller e M executa o G restante de P.
Bloco atômico/mutex/canal, etc. (de forma assíncrona), o bloco G, G move-se para a fila de espera do canal e M executa o G restante de P.
Processo de agendamento
O escalonamento de corrotinas adota o modelo produtor-consumidor, que realiza o desacoplamento das tarefas do usuário e dos escalonadores.
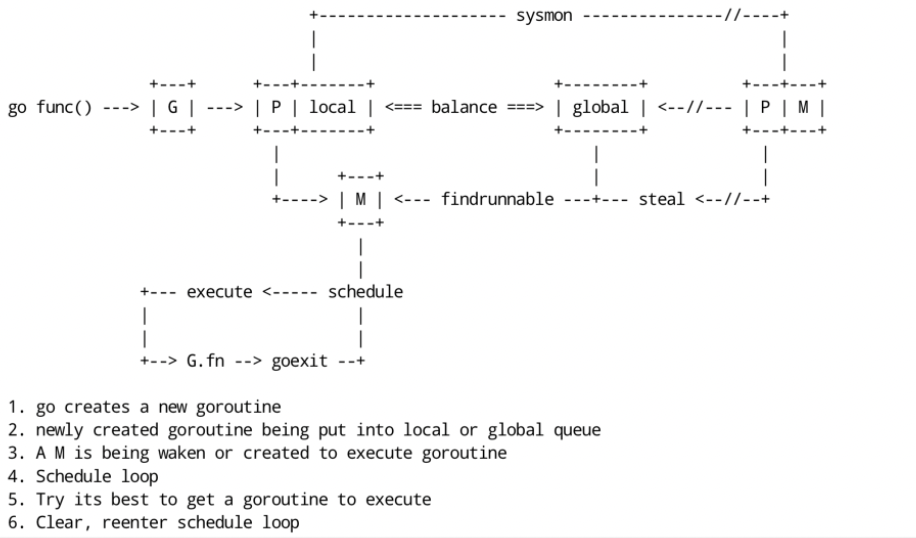
Cada corrotina que iniciamos no lado da produção é uma tarefa de computação e essas tarefas serão submetidas ao tempo de execução do go. Se houver muitas tarefas de computação, dezenas de milhares delas, então é impossível que essas tarefas sejam executadas imediatamente ao mesmo tempo, então a tarefa de computação será armazenada temporariamente primeiro. A abordagem geral é colocá-la na fila de memória e aguarde para ser executado.
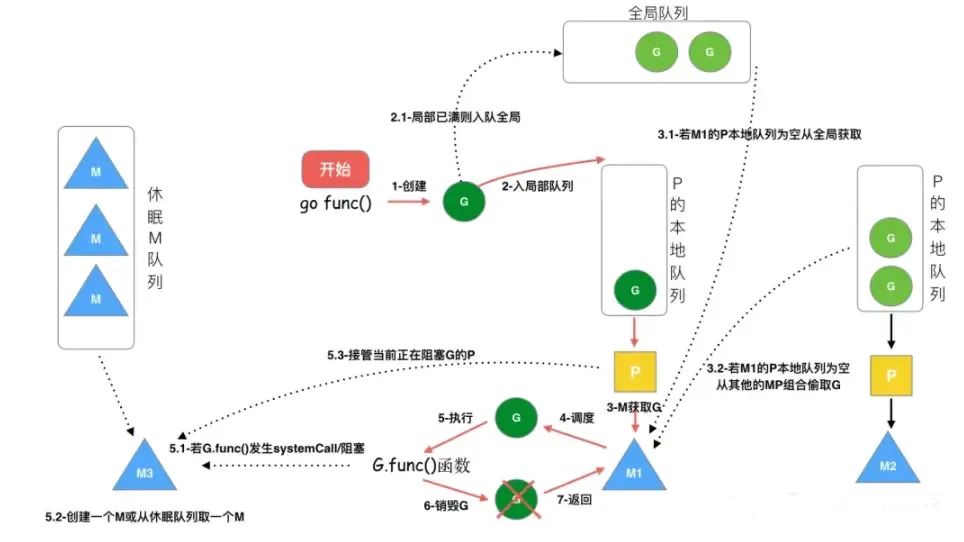
O ciclo de vida de G: G é criado, salvo, adquirido, programado e executado, bloqueado e destruído. As etapas são as seguintes:
Etapa 1: criar G
Ao executar go func, o thread principal M0 chamará newproc() para gerar uma estrutura G
Etapa 2: Salvar G
O G criado é primeiro salvo na fila local P. Se P estiver cheio, parte de P será balanceada na fila global.
Cada corrotina G será tentada para ser colocada primeiro em runnext em P. Se runnext estiver vazio, ele será colocado em runnext e a produção terminará.
Se o runnext estiver cheio, chute o G no runnext original para a fila local, coloque o G atual no runnext e a produção termina.
Se a fila local também estiver cheia, metade do G da fila local será retirada e colocada na fila global e a produção será encerrada.
Passo 3: Acorde ou crie um novo M
Encontre um M e entre no ciclo de agendamento: repita as etapas 4, 5 e 6
Etapa 4: M obtém G
Consulte a estratégia de agendamento abaixo para obter detalhes.
Etapa 5: M agenda e executa G
M chama a função G.func() para executar G
Se o bloqueio de chamadas do sistema (sincronização) ocorrer enquanto M estiver executando G , G e M serão bloqueados (restrições do sistema operacional).Neste momento, P será desvinculado do M atual e procurará um novo M. Se não houver nenhum livre M, será criado um novo M. Um M assume o P que está bloqueando G e então continua a executar o G restante em P. Essa forma de liberar P após o bloqueio é chamada de hand off. Quando a chamada do sistema terminar , este G tentará obter um P ocioso para execução, dando prioridade à obtenção do P previamente vinculado, e colocando-o na fila local deste P. Se não conseguir obter P, então este thread M se tornará inativo. Junte-se ao thread inativo e então este G será colocado na fila global.
Se M for bloqueado em operações como IO de rede durante a execução de G (de forma assíncrona), G será bloqueado, mas M não será bloqueado . M procurará outro executável G em P para continuar a execução. G será assumido pelo poller da rede. Quando o G bloqueado se recuperar, ele será movido de volta para a fila local de P do poller da rede e entrará novamente no executável estado. Em situações assíncronas, por meio de agendamento, o agendador Go converte com êxito tarefas de E/S em tarefas de CPU ou converte a alternância de threads no nível do kernel em alternância de goroutines no nível do usuário, o que melhora muito a eficiência.
Passo 6: Limpe a cena
Depois que M termina de executar G, ele limpa a cena e entra novamente no ciclo de agendamento (troca a goroutine em execução em M para G0, que é responsável por trocar as corrotinas durante o agendamento)
Estratégia de agendamento
Qual estratégia é usada para selecionar a próxima goroutine a ser executada: Como os G em P são distribuídos em runnext, fila local, fila global e poller de rede, é necessário determinar se existem Gs executáveis um por um. A lógica geral é do seguinte modo:
Cada vez que 61 loops de agendamento são executados, G é obtido da fila global e, se houver, é retornado diretamente (principalmente para evitar a privação de G na fila global)
Use runnext em P para ver se existe G e, em caso afirmativo, retorne diretamente.
Verifique se existe G da fila local em P e, em caso afirmativo, retorne diretamente
Se nenhuma das opções acima for encontrada, pesquise na fila global, no poller da rede ou roube de outro P e bloqueie até que um G disponível seja obtido.
O código-fonte é implementado da seguinte forma:
func schedule() {
_g_ := getg()
var gp *g
var inheritTime bool
...
if gp == nil {
// 每执行61次调度循环会看一下全局队列。为了保证公平,避免全局队列一直无法得到执行的情况,当全局运行队列中有待执行的G时,通过schedtick保证有一定几率会从全局的运行队列中查找对应的Goroutine;
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
// 先尝试从P的runnext和本地队列查找G
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
// 仍找不到,去全局队列中查找。还找不到,要去网络轮询器中查找是否有G等待运行;仍找不到,则尝试从其他P中窃取G来执行。
gp, inheritTime = findrunnable() // blocks until work is available
// 这个函数是阻塞的,执行到这里一定会获取到一个可执行的G
}
...
// 调用execute,继续调度循环
execute(gp, inheritTime)
}4. Resumo
Em aplicações práticas, Go provou seu desempenho superior em ambientes de alta simultaneidade.Por exemplo, servidores web altamente simultâneos, sistemas distribuídos e computação paralela se beneficiam do modelo GMP. Compreender e utilizar o modelo GMP tornará seu programa mais competitivo e capaz de lidar com simultaneidade em larga escala com eficiência.
Por fim, deixe-me anunciar meu livreto de entrevista original do Go. Se você estiver envolvido no desenvolvimento relacionado ao Go, fique à vontade para escanear o código para comprá-lo. A compra atual é de 10 yuans. Adicione a captura de tela de pagamento do WeChat abaixo para enviar uma cópia adicional do seu próprio vídeo gravado de explicação da pergunta da entrevista Go.

Se for útil para você, por favor me ajude a clicar para assistir ou encaminhar. Bem-vindo a seguir minha conta oficial