Resumo
À medida que o número de tarefas e os requisitos do tipo de tarefa continuam a crescer, requisitos mais elevados foram colocados na nossa plataforma de desenvolvimento de dados. Este artigo compartilha principalmente nossa experiência prática na atualização do mecanismo de agendamento para Apache DolphinScheduler, bem como algumas idéias sobre a plataforma de desenvolvimento de dados.
1. Fundo
Primeiro, vamos apresentar nossa arquitetura de plataforma de big data:
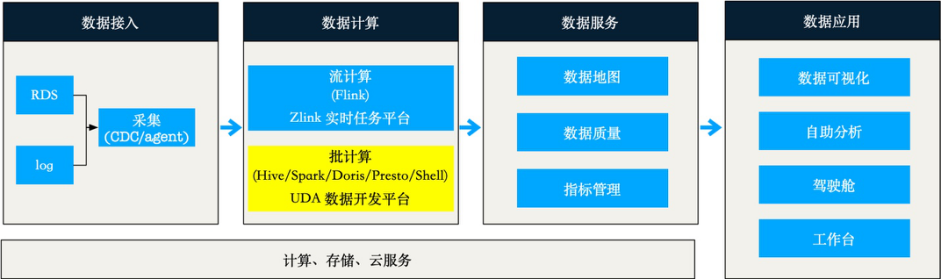
A camada de computação de dados atende às necessidades de desenvolvimento de dados de toda a empresa e é responsável pela execução de diversas tarefas de cálculo de indicadores.
Entre elas, tarefas de computação em lote são executadas na plataforma de desenvolvimento de dados UDA, que suporta cenários de tarefas de desenvolvimento de link completo: desenvolvimento, depuração, isolamento de ambiente, operação e manutenção e monitoramento. O suporte destas funções e a operação estável das tarefas dependem fortemente do sistema de escalonamento subjacente.
O sistema de agendamento original foi autodesenvolvido em 2015 (ou antes).À medida que os tipos de tarefas foram adicionados e o número de tarefas aumentou, muitos problemas foram expostos:

- Estabilidade: problemas frequentes, como conexões mysql não sendo liberadas e tempos limite de bloqueio, ocorrem; a pressão do banco de dados leva ainda a gargalos de desempenho de agendamento e as tarefas não podem ser agendadas a tempo.
- Capacidade de manutenção: O agendador principal é desenvolvido através de PHP. O código é antigo e foi entregue muitas vezes. Os módulos periféricos são implementados usando várias linguagens, como go, java e python. Além disso, também existem módulos únicos pontos em funcionalidade e o custo de manutenção é muito alto.
- Escalabilidade: Com o rápido desenvolvimento dos negócios, há cada vez mais demandas para diferentes tipos de tarefas, mas o agendamento, como serviço subjacente, sempre foi incapaz de suportá-lo.
- Observabilidade: Devido ao método nohup programado para iniciar o processo de tarefa, as tarefas muitas vezes fogem e os indicadores observáveis expostos pelo sistema são quase 0.
Acho que os principais requisitos do sistema de agendamento estão divididos em duas partes: função e sistema:
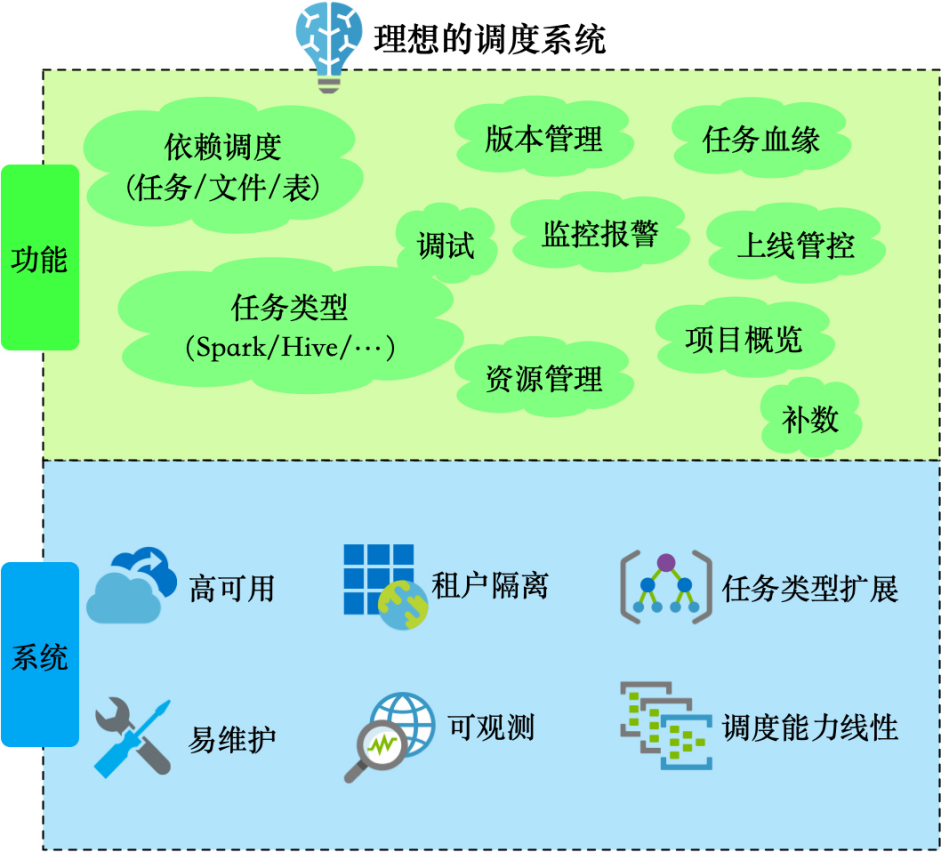
Funcionalmente, a principal capacidade do sistema de agendamento é resolver o problema de agendamento de dependência da construção de data warehouse, por isso ele precisa suportar vários formulários de dependência; suportar uma variedade de tipos de tarefas e pode expandir e personalizar novos tipos de tarefas. Bem como gerenciamento e controle on-line, reversão de versão histórica, linhagem de tarefas e outros recursos para melhorar a facilidade de uso.
No sistema, a estabilidade é a primeira prioridade, por isso precisa ter capacidades de alta disponibilidade. Ele também oferece suporte ao isolamento do locatário, à expansão linear e à observabilidade para facilitar o desenvolvimento, a manutenção e o alerta precoce do sistema.
Historicamente, investigamos várias opções, como Airflow e DolphinScheduler.No último ano, migramos a maioria das tarefas de nosso sistema de agendamento desenvolvido por nós mesmos para o DolphinScheduler.
Uma visão geral do sistema de agendamento atual é a seguinte:
- Em termos de tipos de tarefas: HiveSQL, SparkSQL, DorisSQL, PrestoSQL e algumas tarefas de shell são todas agendadas através do DolphinScheduler; algumas tarefas de shell restantes são agendadas no sistema de agendamento original.
- Em termos de número de tarefas: DolphinScheduler pode agendar dezenas de milhares de instâncias de fluxo de trabalho e centenas de milhares de instâncias de tarefas diariamente e executar instâncias de fluxo de trabalho de 4K+ ao mesmo tempo durante períodos de pico. Após a conclusão da migração, espera-se que o número de instâncias de fluxo de trabalho dobre.
2. Prática de plataforma de desenvolvimento de dados
2.1. Transformação baseada em DolphinScheduler
A transformação do DolphinScheduler concentra-se na estabilidade e facilidade de uso.As funções bem projetadas do sistema de agendamento original precisam ser compatíveis para reduzir os custos de migração de tarefas.
Fizemos as seguintes atualizações com base no DolphinScheduler:
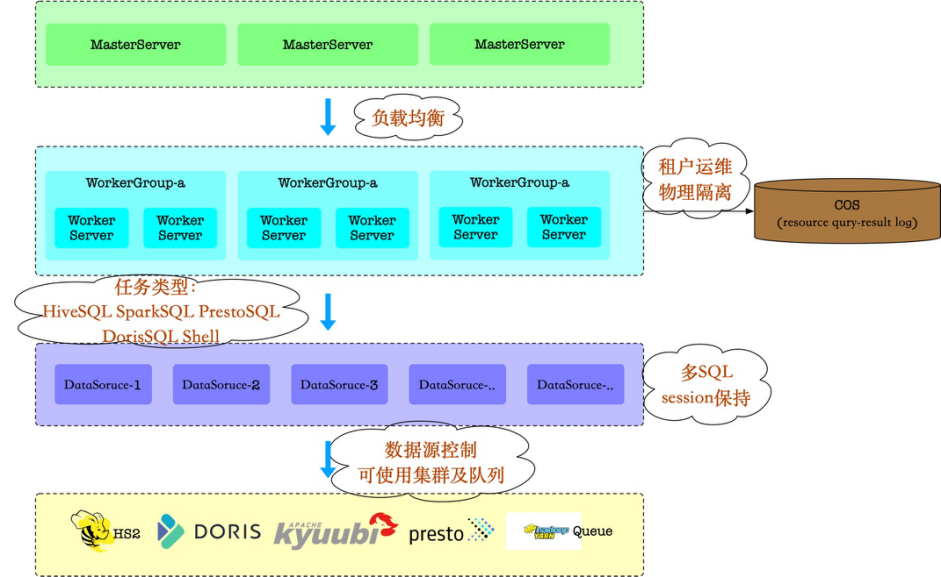
Como o design da arquitetura do DolphinScheduler é relativamente bom, a otimização pode basicamente focar em um único ponto ou reutilizar recursos existentes sem a necessidade de mudanças drásticas na arquitetura.
Nossas tarefas SQL são compostas por diversas tarefas SQL, mas as tarefas SQL nativas só podem enviar uma. Para garantir a simplicidade do sistema, não apresentei vários clientes (hive-client, spark-client, etc.), mas apoiei o envio de vários SQLs de tarefa única por meio do protocolo JDBC por meio de análise SQL e gerenciamento de pool de conexões reconstrução.
Ao mesmo tempo, o design do DolphinScheduler para fontes de dados é totalmente reutilizado e as fontes de dados recebem mais atributos, como conectar diferentes HiveServer2, Kyubbi, Presto Coordinator, etc. só é permitido usar uma única fila. Adicione controle de permissão às fontes de dados para que tarefas diferentes possam usar apenas recursos de cluster autorizados.
Carregamos arquivos de recursos e dados de resultados de operações DQL para o armazenamento de objetos COS da Tencent Cloud para garantir que o Worker seja verdadeiramente sem estado. (Observação: o upload do log está em andamento)
Além disso, inclui otimização de balanceamento de carga, isolamento de agendamento de inquilinos de múltiplas linhas de negócios, otimização do uso de banco de dados, etc.
2.2. Migração tranquila em grande escala
Embora existam enormes diferenças nas funções e na arquitetura entre os dois sistemas de agendamento, a migração tranquila é necessária por três razões principais:
- O sistema de agendamento original está em serviço há muitos anos e os usuários desenvolveram hábitos em design funcional e substantivos de campo específicos do sistema.
- Espera-se que a migração de fluxos de trabalho 2W+ demore muito tempo, cubra muitos fluxos de dados importantes da empresa e tenha um alto grau de impacto problemático.
- Os usuários cobrem muitas das linhas de negócios da empresa (plataformas, aulas ao vivo, hardware, livros), e o problema tem um amplo impacto
Conseguimos uma migração em grande escala quase sem conhecimento dos usuários, contando principalmente com a integração e DIFF dos antigos e novos sistemas de agendamento.
A seguir, apresentaremos como fazer isso.
2.2.1. Integrando os antigos e novos sistemas de agendamento
Na fase de migração de tarefas, quando algumas tarefas são executadas no novo sistema de agendamento e outras no sistema de agendamento original, dois problemas precisam ser resolvidos:
- Os usuários podem visualizar o status de execução de todas as instâncias de tarefas, incluindo alguns termos de agendamento familiares (run_index, result_ftp, log_ftp, csv_result_path, etc.) Esta parte da informação obviamente não está disponível no agendamento do DolphinScheduler.
- Existem dependências entre tarefas. Ao agendar tarefas entre dois sistemas, também é necessário consultar o status das instâncias de tarefas agendadas pelo outro sistema para determinar se as dependências de tarefas atuais estão prontas.
Portanto, quando estamos na fase de migração, a arquitetura é a seguinte:
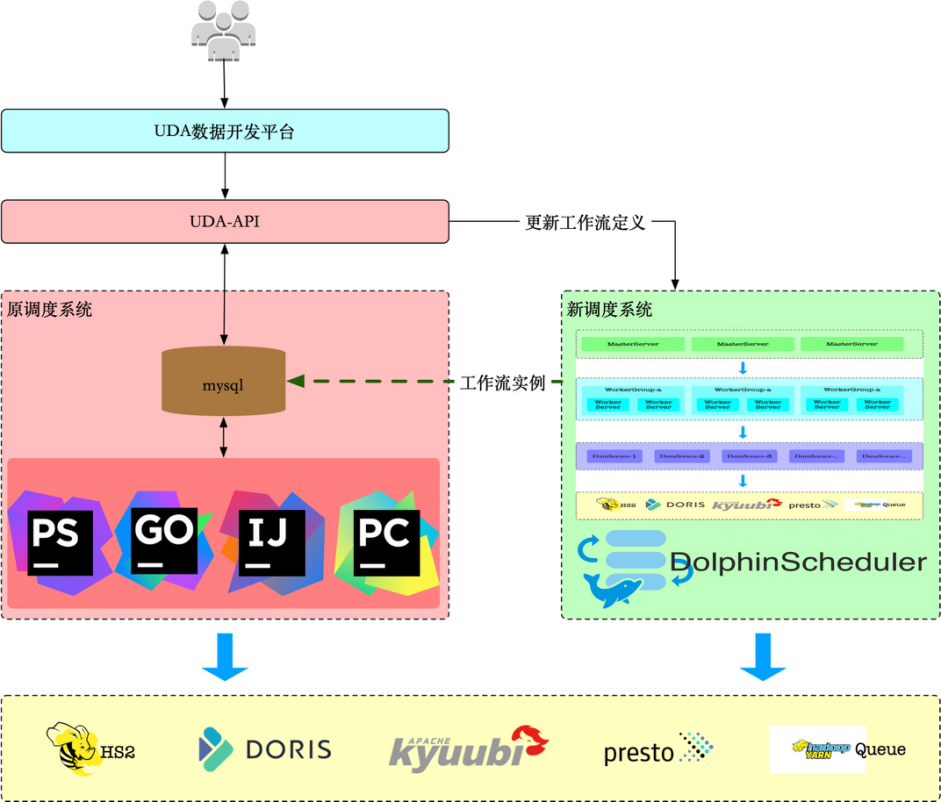
Existem dois designs principais.
Primeiro, o status da instância da tarefa é unificado no banco de dados original do sistema de agendamento. Para a plataforma:
- O método de consulta, campos e API são os mesmos de antes
- Quando uma tarefa é atualizada, se a tarefa tiver sido migrada para o novo sistema de agendamento, a definição do fluxo de trabalho no DolphinScheduler também será atualizada.
Portanto, a plataforma não tem conhecimento dos usuários ao utilizá-la.
Em segundo lugar, modificamos o código do DolphinScheduler DependentTaskProcessor para suportar a consulta do status da instância da tarefa do DolphinScheduler e do sistema de agendamento original. Desta forma, as tarefas agendadas pelo DolphinScheduler podem contar livremente com instâncias de tarefas dos dois sistemas de agendamento.
Portanto, em termos de capacidades de agendamento, os usuários não estão cientes disso.
A arquitetura acima, após a conclusão da migração no futuro, será capaz de fornecer recursos completos de agendamento somente por meio de UDA-API + DolphinScheduler.
Ao mesmo tempo, também otimizamos a facilidade de uso das dependências de configuração. Historicamente, oferecemos suporte a vários métodos de dependência: dependências de arquivo, dependências de tarefas, dependências hql, dependências prestosql, etc. Os dois últimos exigem que os usuários configurem manualmente a tabela correspondente à consulta e nós os otimizamos para dependência de tabela. A plataforma analisa o SQL do usuário e adiciona automaticamente as dependências correspondentes à tabela lida. Ele não apenas melhora a facilidade de uso, mas também protege os usuários dos detalhes do tipo de armazenamento de tabela específico subjacente (Hive/Presto/Iceberg/...):
Para dependências de tarefas, também há suporte para pesquisa global, deslocamento e unidades de deslocamento para melhorar ainda mais a facilidade de uso.
2.2.2. DIFERENÇA entre sistemas de agendamento antigos e novos
O segundo é o DIFF entre o antigo e o novo sistema de agendamento.
Como plataforma básica, atende diversas linhas de negócios e os recursos do YARN são extremamente escassos, portanto, temos altos requisitos para a estabilidade do sistema de agendamento. Para garantir uma migração tranquila, uma versão customizada é feita especialmente com base nos recursos do DolphinScheduler DryRun:
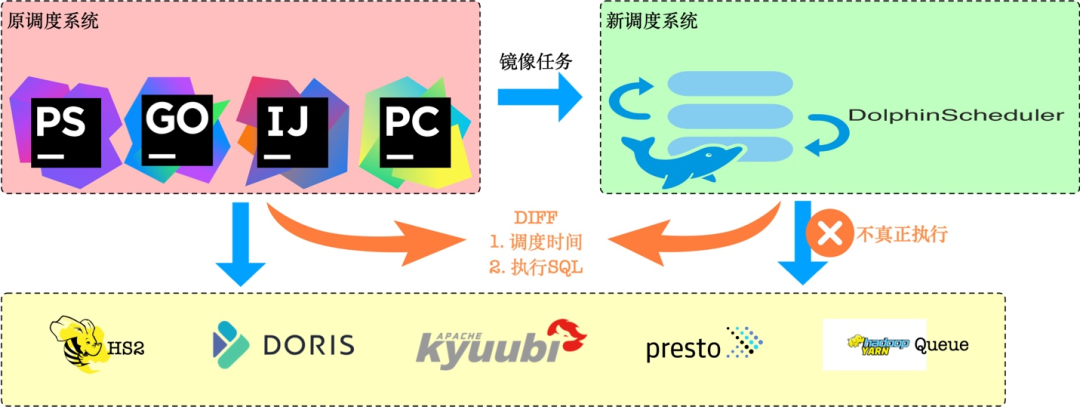
A chamada tarefa de espelho significa que antes de migrarmos o novo agendamento, primeiro espelharemos uma tarefa idêntica no DolphinScheduler.A tarefa também sofre substituição de variáveis e outras operações, mas a tarefa está marcada para não ser realmente executada.
Desta forma podemos comparar o DIFF entre os dois sistemas, incluindo principalmente:
- Se o tempo de agendamento é basicamente consistente: usado para verificar a compatibilidade de configurações dependentes, configurações de tempo, etc.
- Se o SQL é completamente consistente: verifique se o SQL realmente enviado é exatamente o mesmo após substituição de variável, mascaramento de SQL e configuração de fila.
Após a observação de funcionamento a seco mencionada acima por um período de tempo para garantir que não haja diferença, as tarefas online são realmente migradas para o novo mecanismo de agendamento.
2.2.3. Observabilidade do sistema
No tempo limitado, fizemos os preparativos acima, mas ainda não foram suficientes.
O sistema precisa ter boa observabilidade e o DolphinScheduler fornece indicadores básicos no formato Prometheus. Adicionamos alguns indicadores de alta qualidade e os convertemos para o formato Falcon para conectá-los ao sistema de monitoramento interno da empresa.
Verifique o estado de saúde do sistema de despacho monitorando o mercado e configure alarmes de telefone/DingTalk para diferentes níveis de indicadores e limites:
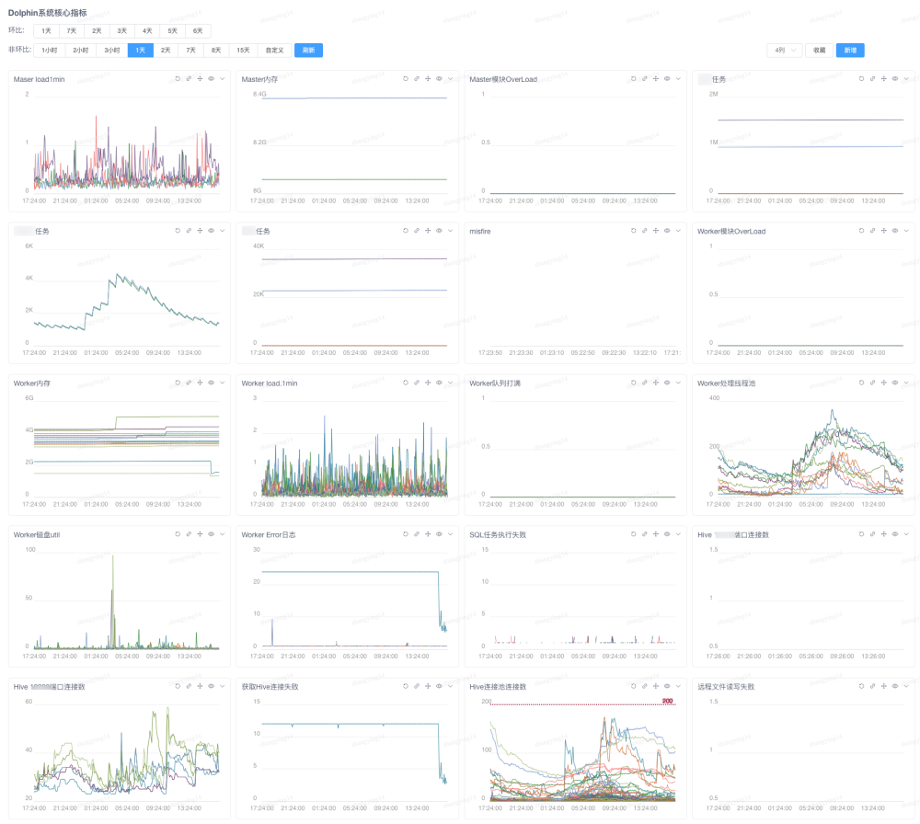
Depois que a observabilidade é melhorada, o custo do trabalho de análise do problema também é controlado, por exemplo, para esta curva:
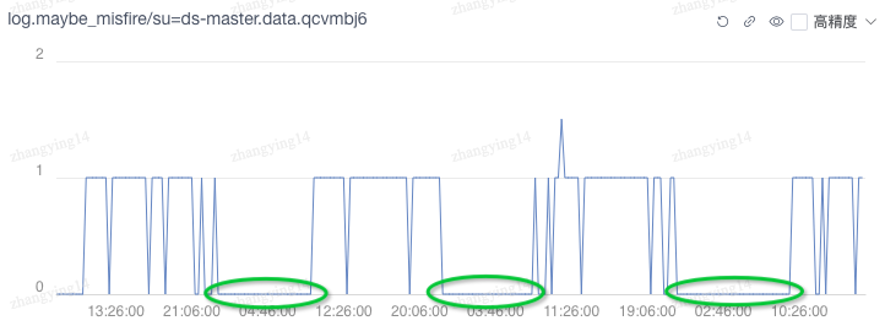
É fácil observar que o valor da curva é basicamente 0 fora do horário de trabalho, portanto, pode-se julgar que a anormalidade do indicador (=1) é provavelmente acionada pela modificação do usuário. Em comparação com o método anterior, onde os problemas só podiam ser adivinhados e conectado para analisar os logs um por um., os problemas podem ser descobertos e avisados antecipadamente por meio da análise de métricas.
Após o início da migração, concentre-se e avalie indicadores como falha de ignição, saturação do pool de threads de trabalho, saturação do pool de conexões, io-util e sobrecarga para garantir uma migração tranquila.
2.3. Benefícios da migração
Atualmente, a migração está mais da metade concluída. Comparamos o uso de recursos do banco de dados e da máquina de agendamento do antigo e do novo sistema de agendamento:
-
base de dados:
-
QPS: 10.000+ -> 500
-
Carga: 4,0 -> 1,0
-
-
Uso de recursos reduzido em 65%
Durante o processo de migração, usamos o DolphinScheduler para dar suporte às novas necessidades de agendamento de empresas como SparkSQL, DorisSQL e PrestoSQL de versão superior com custos de desenvolvimento muito baixos.
Outras comparações funcionais:
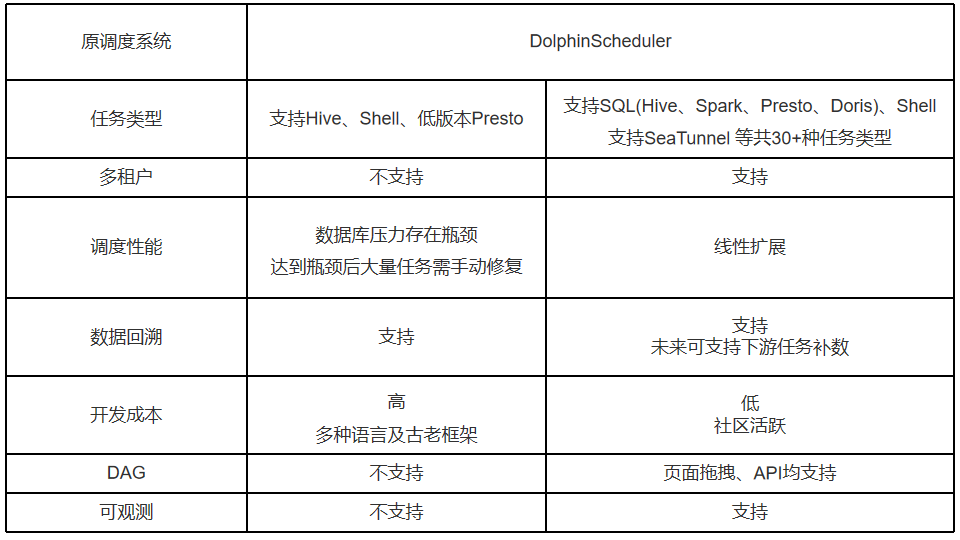
3. Planejamento futuro
- Todas as tarefas de rotina e recursos de depuração são migrados para o DolphinScheduler e os SOPs de operação online são precipitados.
- Combinado com o progresso da conteinerização da comunidade, a implantação do módulo K8S é implementada. O módulo API atual foi usado no ambiente de produção e Worker e Master estão em andamento.
- Rastreabilidade de dados de link completo com um clique
- Conexão de plataforma offline e em tempo real
Linguagem de programação do ano TIOBE 2023: C# Uma escola de ensino médio comprou um "dispositivo de catarse interativo inteligente" - que na verdade era uma concha para o Nintendo Wii. Acompanhamento do incidente de executivas demitindo funcionários: o presidente da empresa chamou os funcionários de "infratores habituais " e questionou a "falsificação de qualificações acadêmicas e currículos" do artefato de código aberto LSPosed anunciou que iria parar de atualizar. O autor disse que sofreu um grande número de ataques maliciosos e foi demitido ilegalmente por uma executiva. Os funcionários se manifestaram e foram alvo por se opor ao uso de ferramentas EDA piratas para projetar chips. Linux Kernel 6.7 foi lançado oficialmente. Luo Yonghao afirmou que "Glory Any Door" plagiou o software de código aberto Hammer One Step Chinese JDK. O site do tutorial foi lançado oficialmente para ajudar os desenvolvedores a dominar a linguagem de programação Java . Em 2024, a linguagem de desenvolvimento do kernel Linux será convertida de C para C++? "Xie Yihui", um desenvolvedor conhecido na comunidade da linguagem R, foi demitido do RStudio/PositEste artigo foi publicado pela Beluga Open Source Technology !