
In der „X“-Einbettung in NLP-Fortgeschrittenenreihe haben wir die Grundkenntnisse der Verarbeitung natürlicher Sprache eingeführt – Token-, N-Gramm- und Bag-of-Word-Sprachmodelle in natürlicher Sprache. Heute werden wir weiterhin mit Ihnen „üben“, uns mit Sprachmodellen neuronaler Netze, insbesondere wiederkehrenden neuronalen Netzen, befassen und kurz verstehen, wie Einbettungsvektoren generiert werden.
01. Tiefes Verständnis neuronaler Netze
Lassen Sie uns zunächst kurz die Komponenten neuronaler Netze betrachten, nämlich Neuronen, mehrschichtige Netze und den Backpropagation-Algorithmus. Wenn Sie detailliertere Informationen zu diesen Grundkonzepten erhalten möchten, können Sie auf andere Ressourcen verweisen, z. B. auf die Kursnotizen zu CS231n .
Beim maschinellen Lernen sind Neuronen die Grundeinheiten, aus denen alle neuronalen Netze bestehen. Im Wesentlichen ist ein Neuron eine Einheit in einem neuronalen Netzwerk, die eine gewichtete Summe aller ihrer Eingaben plus einen optionalen Bias-Term verarbeitet. Die Gleichungsdarstellung lautet wie folgt:
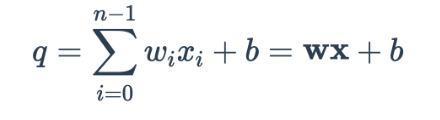
Stellt hier 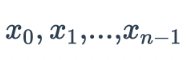 die Ausgabe des Neurons in der vorherigen Schicht dar und
die Ausgabe des Neurons in der vorherigen Schicht dar und 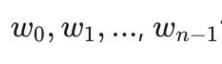 stellt das Gewicht dar, das dieses Neuron zum Synthetisieren des Ausgabewerts verwendet.
stellt das Gewicht dar, das dieses Neuron zum Synthetisieren des Ausgabewerts verwendet.
Wenn ein mehrschichtiges neuronales Netzwerk nur aus den gewichteten Summen in der obigen Gleichung bestünde, könnten wir alle Terme in einer einzigen linearen Schicht kombinieren – was für die Modellierung von Beziehungen zwischen Token oder die Kodierung komplexer Texte nicht besonders ideal ist. Aus diesem Grund enthalten alle Neuronen nach der gewichteten Summe eine nichtlineare Aktivierungsfunktion. Das bekannteste Beispiel hierfür ist die Funktion der gleichgerichteten linearen Einheit (ReLU):
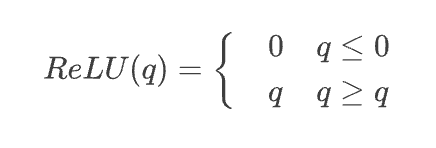
Bei den meisten modernen Sprachmodellen für neuronale Netze ist die Aktivierungsfunktion der Gaussian Error Linear Unit (GELU) häufiger anzutreffen:
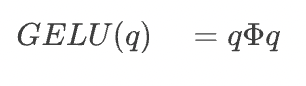
Hier 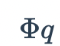 stellt die Gaußsche kumulative Verteilungsfunktion dar, die
stellt die Gaußsche kumulative Verteilungsfunktion dar, die  zum Ausdruck verwendet werden . Diese Aktivierungsfunktion wird nach der oben beschriebenen gewichteten Summierung angewendet. Alles in allem sieht ein einzelnes Neuron so aus:
zum Ausdruck verwendet werden . Diese Aktivierungsfunktion wird nach der oben beschriebenen gewichteten Summierung angewendet. Alles in allem sieht ein einzelnes Neuron so aus:
Um komplexere Funktionen zu lernen, können wir Neuronen übereinander stapeln, um eine Schicht zu bilden. Alle Neuronen in derselben Schicht erhalten den gleichen Input; der einzige Unterschied zwischen ihnen ist das Gewicht W und der Bias b. Wir können die obige Gleichung in Matrixschreibweise für eine einzelne Schicht ausdrücken:
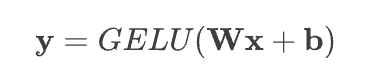
Hier ist w eine zweidimensionale Matrix, die alle auf die Eingabe x angewendeten Gewichte enthält ; jede Zeile der Matrix entspricht dem Gewicht eines Neurons. Diese Art von Schicht wird oft als dichte Schicht oder vollständig verbundene Schicht bezeichnet, da alle Eingänge x mit allen Ausgängen y verbunden sind .
Wir können diese beiden Schichten verketten, um ein grundlegendes Feedforward-Netzwerk zu erstellen:
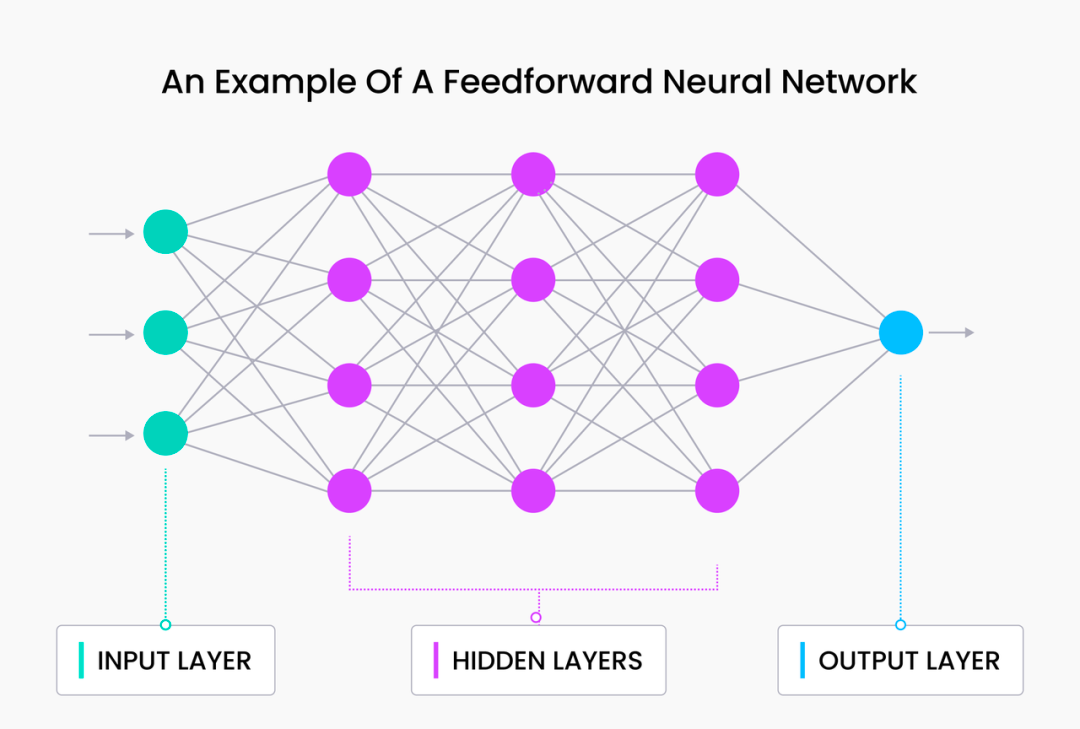
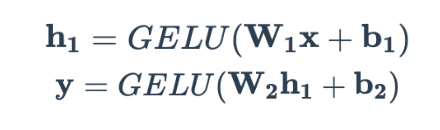
Hier führen wir eine neue verborgene Schicht h1 ein , die weder direkt mit dem Eingang x noch mit dem Ausgang y verbunden ist . Diese Schicht erhöht effektiv die Tiefe des Netzwerks und erhöht die Gesamtzahl der Parameter (mehrere Gewichtsmatrizen w ). Zu diesem Zeitpunkt ist es wichtig zu beachten, dass mit dem Hinzufügen weiterer verborgener Ebenen die verborgenen Werte (Aktivierungswerte) in der Nähe der Eingabeebene „ x “ ähnlicher sind , während die Aktivierungswerte in der Nähe der Ausgabe „ähnlicher“ sind ähnlicher zu y .
Wir werden das Einbetten von Vektoren basierend auf diesem Prinzip in den folgenden Artikeln diskutieren. Das Konzept der verborgenen Ebenen ist für das Verständnis der Vektorsuche von entscheidender Bedeutung.
Die Parameter einzelner Neuronen in einem Feedforward-Netzwerk können durch einen Prozess namens Backpropagation aktualisiert werden, bei dem es sich im Wesentlichen um die wiederholte Anwendung der Kettenregel in der Analysis handelt. Sie können nach einigen Kursen suchen, die Backpropagation speziell erklären. In diesen Kursen wird erläutert, warum Backpropagation für das Training neuronaler Netze so effektiv ist. Wir gehen hier nicht auf Details ein. Der grundlegende Prozess ist wie folgt:
-
Führen Sie einen Datenstapel durch ein neuronales Netzwerk.
-
Verluste berechnen. Dies ist typischerweise der L2-Verlust (quadratierte Differenz) für die Regression und der Kreuzentropieverlust für die Klassifizierung.
-
Verwenden Sie diesen Verlust, um den Verlustgradienten mit den letzten Gewichten der verborgenen Schicht zu berechnen
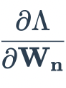 .
. -
Berechnen Sie den Verlust durch die letzte verborgene Schicht, d. h
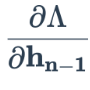 .
. -
Tragen Sie diesen Verlust auf die Gewichte der vorletzten verborgenen Schicht zurück
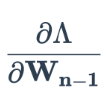 .
. -
Wiederholen Sie die Schritte 4 und 5, bis die partiellen Ableitungen aller Gewichte berechnet sind.
Nach der Berechnung der partiellen Ableitungen des mit allen Gewichtungen im Netzwerk verbundenen Verlusts kann eine umfangreiche Gewichtsaktualisierung basierend auf dem Optimierer und der Lernrate durchgeführt werden. Dieser Vorgang wird wiederholt, bis das Modell Konvergenz erreicht oder alle Epochen abgeschlossen sind.
02. Wiederkehrendes neuronales Netzwerk
Alle Formen von Text und natürlicher Sprache sind ihrer Natur nach sequentiell, was bedeutet, dass Wörter/Tokens nacheinander verarbeitet werden. Scheinbar einfache Änderungen, wie das Hinzufügen eines Wortes, das Vertauschen zweier aufeinanderfolgender Token oder das Hinzufügen von Satzzeichen, können zu großen Unterschieden in der Interpretation führen. Zum Beispiel sind die Sätze „Lass uns essen, Charles“ und „Lass uns essen, Charles“ völlig unterschiedliche Dinge. Aufgrund der sequentiellen Natur natürlicher Sprache sind rekurrente neuronale Netze (RNNs) natürlich die beste Wahl für die Sprachmodellierung.
Rekursion ist eine einzigartige Form der Rekursion, bei der die Funktion ein neuronales Netzwerk und kein Code ist. RNN hat auch biologischen Ursprung – das menschliche Gehirn kann mit einem (künstlichen) neuronalen Netzwerk verglichen werden, und die Wörter, die wir eingeben oder die wir sprechen, sind das Ergebnis biologischer Verarbeitung.
RNN besteht aus zwei Komponenten: 1) einem Standard-Feed-Forward-Netzwerk und 2) einer rekursiven Komponente. Feedforward-Netzwerke sind die gleichen, die wir im vorherigen Abschnitt besprochen haben. Bei der rekursiven Komponente wird der letzte verborgene Zustand in die Eingabe zurückgeführt, damit das Netzwerk den vorherigen Kontext beibehalten kann. Daher wird bei jedem neuen Zeitschritt Vorwissen (in Form verborgener Schichten aus dem vorherigen Zeitschritt) in das Netzwerk eingefügt.
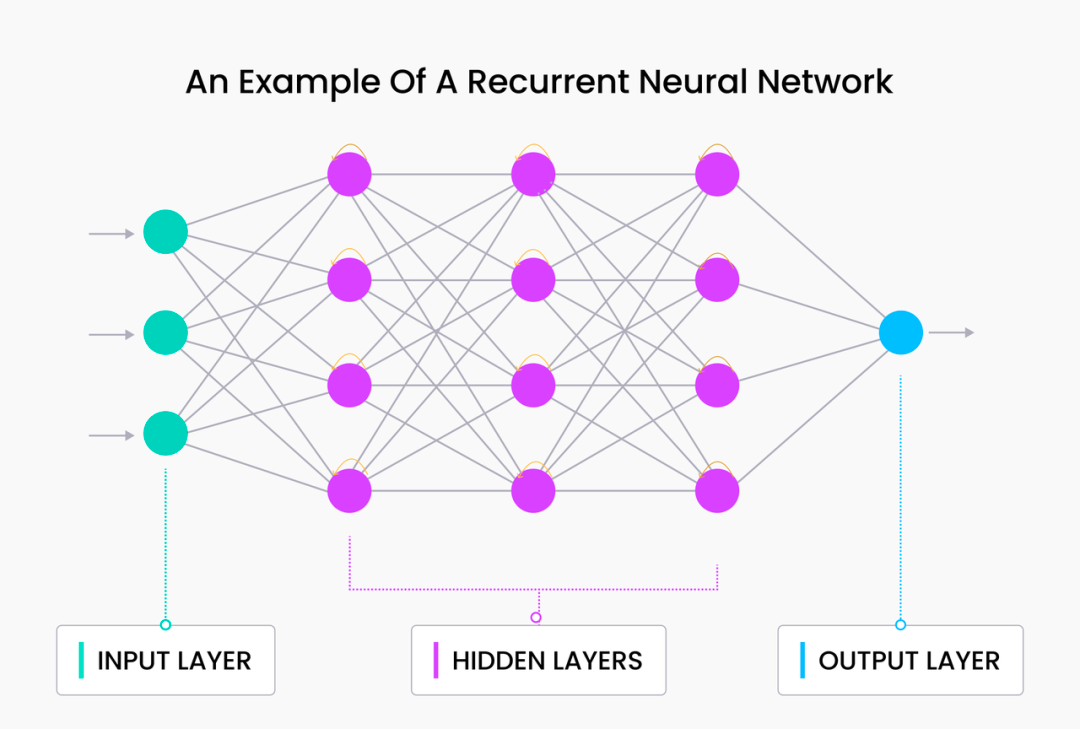
Basierend auf der obigen Makrodefinition und Erklärung von RNN können wir grob verstehen, wie es implementiert wird und warum RNN bei der semantischen Modellierung gute Leistungen erbringt.
Erstens ermöglicht die wiederkehrende Struktur von RNNs ihnen die sequentielle Erfassung und Verarbeitung von Daten, ähnlich wie Menschen sprechen, lesen und schreiben. Darüber hinaus können RNNs effektiv auf „Informationen“ aus früheren Zeiten zugreifen und natürliche Sprache besser verstehen als N-Gramm-Modelle und reine Feed-Forward-Netzwerke.
Sie können versuchen, mit PyTorch ein RNN zu implementieren. Beachten Sie, dass dies ein tiefgreifendes Verständnis der Grundlagen von PyTorch erfordert. Wenn Sie mit PyTorch nicht vertraut sind, wird empfohlen, zuerst diesen Link zu lesen .
Definieren Sie zunächst ein einfaches Feedforward-Netzwerk, erweitern Sie es dann zu einem einfachen RNN und definieren Sie zunächst die Schichten:
from torch import Tensor
import torch.nn as nn
class BasicNN(nn.Module):
def __init__(self, in_dims: int, hidden_dims: int, out_dims: int):
super(BasicNN, self).__init__()
self.w0 = nn.Linear(in_dims, hidden_dims)
self.w1 = nn.Linear(hidden_dims, out_dims)
Beachten Sie, dass wir den Stil des Verlusts nicht definiert haben, da wir nur rohe logische Werte ausgeben. Während des Trainings können einige Standards basierend auf der tatsächlichen Situation hinzugefügt werden, z nn.CrossEntropyLoss.
Jetzt können wir den Vorwärtsdurchlauf implementieren:
def forward(self, x: Tensor):
h = self.w0(x)
y = self.w1(h)
return y
Diese beiden Codeschnipsel bilden zusammen ein sehr einfaches Feedforward-Neuronales Netzwerk. Um dies in ein RNN umzuwandeln, müssen wir eine Rückkopplungsschleife vom letzten verborgenen Zustand zurück zur Eingabe hinzufügen:
def forward(self, x: Tensor, h_p: Tensor):
h = self.w0(torch.cat(x, h_p))
y = self.w1(h)
return (y, h)
Das Obige sind im Grunde alle Schritte. Da wir nun w0die Anzahl der Eingaben in die durch definierte Neuronenschicht erhöhen, müssen wir __init__ihre Definition in aktualisieren. Jetzt machen wir das und kombinieren alles in einem Code-Snippet:
import torch.nn as nn
from torch import Tensor
class SimpleRNN(nn.Module):
def __init__(self, in_dims: int, hidden_dims: int, out_dims: int):
super(RNN, self).__init__()
self.w0 = nn.Linear(in_dims + hidden_dims, hidden_dims)
self.w1 = nn.Linear(hidden_dims, out_dims)
def forward(self, x: Tensor, h_p: Tensor):
h = self.w0(torch.cat(x, h_p))
y = self.w1(h)
return (y, h)
Bei jedem Vorwärtsdurchlauf hwerden die Aktivierungswerte der verborgenen Schicht zusammen mit der Ausgabe zurückgegeben. Diese Aktivierungswerte können dann mit jedem neuen Token in der Sequenz wieder an das Modell zurückgegeben werden. Ein solcher Prozess läuft wie folgt ab (der folgende Code dient nur zur Veranschaulichung):
model = SimpleRNN(n_in, n_hidden, n_out)
...
h = torch.zeros(1, n_hidden)
for token in range(seq):
(out, h) = model(token, )
Zu diesem Zeitpunkt haben wir erfolgreich ein einfaches Feedforward-Netzwerk definiert und es zu einem einfachen RNN erweitert.
03. Einbettung des Sprachmodells
Die verborgene Schicht, die wir im obigen Beispiel gesehen haben, kodiert effektiv alles, was in das RNN eingegeben wurde (alle Token). Genauer gesagt sollten alle Informationen, die zum Parsen des vom RNN gesehenen Textes erforderlich sind, im Aktivierungswert h enthalten sein. Mit anderen Worten, h kodiert die Semantik der Eingabesequenz, und der durch h definierte geordnete Satz von Gleitkommawerten ist der Einbettungsvektor, der als Einbettung bezeichnet wird.
Diese Vektordarstellungen bilden weitgehend die Grundlage für Vektorsuchen und Vektordatenbanken. Obwohl heutige Einbettungen in natürlicher Sprache von einer anderen Klasse von Modellen für maschinelles Lernen namens Transformers und nicht von RNNs generiert werden, ist das zugrunde liegende Konzept im Grunde dasselbe: Textinhalte in computerverständliche Einbettungsvektoren kodieren. In unserem nächsten Blogbeitrag werden wir die Verwendung von Einbettungsvektoren ausführlich besprechen.
04. Zusammenfassung
Wir haben ein einfaches wiederkehrendes neuronales Netzwerk in PyTorch implementiert und kurz die Einbettung von Sprachmodellen eingeführt. Obwohl rekurrente neuronale Netze leistungsstarke Werkzeuge zum Verständnis von Sprache sind und in einer Vielzahl von Anwendungen eingesetzt werden können (maschinelle Übersetzung, Klassifizierung, Beantwortung von Fragen usw.), sind sie immer noch nicht die Art von ML-Modell, die zur Generierung von Einbettungsvektoren verwendet wird.
Im nächsten Tutorial werden wir das Open-Source-Transformer-Modell verwenden, um Einbettungsvektoren zu generieren und die Leistungsfähigkeit von Vektoren zu demonstrieren, indem wir Vektorsuchen und Operationen an ihnen durchführen. Darüber hinaus werden wir auch auf das Konzept der Bag-of-Words-Modelle zurückkommen und sehen, wie beide zusammen verwendet werden können, um Vokabular und Semantik zu kodieren. Bleiben Sie dran!
Tang Xiaoou, Gründer von SenseTime, verstarb im Alter von 55 Jahren. Im Jahr 2023 stagnierte PHP . Das Hongmeng-System steht kurz vor der Unabhängigkeit und viele Universitäten haben „Hongmeng-Kurse“ eingerichtet. Die PC-Version von Quark Browser hat mit internen Tests begonnen . ByteDance wurde von OpenAI „verboten“. Das Startup-Unternehmen von Zhihuijun wurde mit einem Betrag von über 600 Millionen Yuan und einer Pre-Money-Bewertung von 3,5 Milliarden Yuan refinanziert. KI-Code-Assistenten sind so beliebt, dass sie nicht einmal in der Programmierung mithalten können Sprachrankings . Das 5G-Modem und die Hochfrequenztechnologie des Mate 60 Pro liegen weit vorne. No Star, No Fix MariaDB spaltet SkySQL ab und gründet sich als unabhängiges Unternehmen