Implementierung von CNN
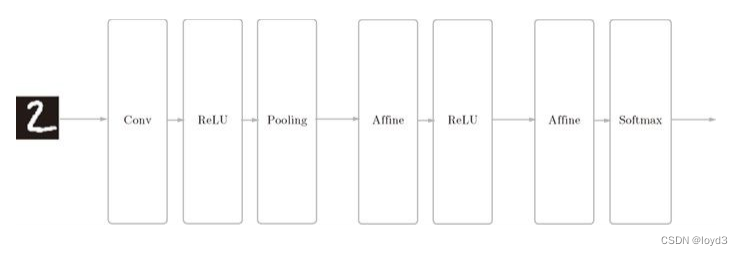
Die Zusammensetzung des Netzwerks lautet „Convolution – ReLU – Pooling – Affine – ReLU – Affine – Softmax“, und wir implementieren es als eine Klasse mit dem Namen SimpleConvNet .
Schauen Sie sich zunächst die Initialisierung von SimpleConvNet ( init ) an und übernehmen Sie die folgenden Parameter.
input_dim – Dimensionen der Eingabedaten: (Kanal, Höhe, Länge)
conv_param – Hyperparameter (Wörterbuch) der Faltungsschicht. Die Schlüsselwörter des Wörterbuchs lauten wie folgt:
filter_num – die Anzahl der Filter
filter_size – die Größe des Filters
Stride – das Stride-
Pad – Füllung
Hidden_Size – die Anzahl der Neuronen in der verborgenen Schicht (vollständige Verbindung)
Output_size – die Ausgabeschicht ( vollständige Verbindung) Die Anzahl der Neuronen
weitght_int_std – die Standardabweichung des Gewichts bei der Initialisierung
Hier werden die Hyperparameter der Faltungsschicht über ein Wörterbuch namens conv_param übergeben.
Die Implementierung von SimpleConvNet ist wie folgt:
class SimpleConvNet:
def __init__(self, input_dim=(1,28,28), conv_param={
'filter_num':30, 'filter_size':5,'pad':0, 'stride':1}, hidden_size=100,output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['filter_pad']
filter_stride = conv_param['filter_stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride +1
pool_output_size = int(filter_num * (conv_output_size /2) * (conv_output_size/2))
# 这里将由初始化参数传入的卷积层的超参数从字典中取了出来(以方便后面使用),然后,计算卷积层的输出大小。
# 接下来是权重参数的初始化部分
self.params = {
}
self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0],filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 最后生成必要的层
self.layers = OrderDict()
self.layers['Conv1'] = Convolution(self.params['W1'],self.params['b1'],conv_param['stride'],conv_param['pad'])
self.layers['Relu1']= Relu()
self.layers['Pool1']= Pooling(poo_h=2,pool_w=2,stride=2)
self.layers['Affine1'] = Affine(self.params['W2'],self.params['b2'])
self.layers['Relu2'] = Relu()
self,layers['Affine2']= Affine(self.params['W3'],self.params['b3'])
self.last_layer = SoftmaxWithLoss()
# 从最前面开始按顺序向有序字典(OrderedDict)的layers中添加层。只有最后的SoftmaxWithLoss层被添加到别的变量LastLayer中。
Das Obige ist die Verarbeitung, die bei der Initialisierung von simpleConvNet durchgeführt wird. Nach einer solchen Initialisierung können die Vorhersagemethode für die Schlussfolgerung und die Verlustmethode zur Berechnung des Werts der Verlustfunktion wie folgt implementiert werden
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y,t)
Hier ist der Parameter x die Eingabedaten und t das überwachte Label. Die Vorhersagemethode für die Inferenz ruft die hinzugefügten Schichten nacheinander von Anfang an auf und übergibt das Ergebnis an die nächste Schicht.
Bei der Verlustmethode zum Ermitteln der Verlustfunktion wird zusätzlich zur Vorwärtsverarbeitung mit der Vorhersagemethode die Vorwärtsverarbeitung fortgesetzt, bis die letzte SoftmaxwithLoss-Schicht erreicht ist .
Das Folgende ist die Code-Implementierung, die auf der Fehler-Backpropagation-Methode basiert, um den Gradienten zu finden
def gradient(self,x,t):
#forward
self.loss(x,t)
#backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads={
}
grads['W1'] = self,layers['Conv1'].dw
grads['b1'] = self.layers['Conv1'].db
grads['W2'] = self.layers['Affine1'].dw
grads['b2'] = self,layers['Affine1'].db
grads['W3'] = self,layers['Affine2'].dw
grads['b3'] = self.layers['Affine2'].db
return grads
Der Gradient des Parameters wird durch die Fehler-Backpropagation-Methode (Backpropagation) erhalten.
Verwenden Sie dieses SimpleConvNet, um mehr über den MNIST-Datensatz zu erfahren. Die Erkennungsrate der Trainingsdaten beträgt 99,82 %, die Erkennungsrate der Testdaten beträgt 98,96 % und die Erkennungsrate der Testdaten beträgt etwa 99 %, was für ein kleines Netzwerk eine sehr hohe Erkennungsrate darstellt.