
fundo:
Atualmente, o desenvolvimento de grandes modelos está em alta, e o treinamento e o ajuste fino de grandes modelos também são o foco de diversas empresas. No entanto, o problema do treinamento de modelos grandes é que os parâmetros do modelo são muito grandes, muitas vezes atingindo dezenas de bilhões. É basicamente impossível concluir o treinamento com uma única GPU. Portanto, é necessário treinamento distribuído ou com vários cartões para concluir este trabalho.
1. Treinamento distribuído
1.1 Atualmente, existem dois tipos principais de treinamento distribuído em grandes modelos:
- Treinamento paralelo de dados
- Treinamento paralelo de modelo
2.DeepSpeed
DeepSpeed é uma ferramenta de treinamento distribuída fornecida pela Microsoft, projetada para oferecer suporte a modelos de maior escala e fornecer mais estratégias e ferramentas de otimização. Para o treinamento de modelos maiores, o DeepSpeed disponibiliza mais estratégias, como Zero, Offload, etc.
2.1 Componentes básicos
O treinamento distribuído requer o domínio da configuração básica no ambiente distribuído, incluindo alterações de nós, números de processos globais, números de processos locais, número total de processos globais, nós mestres, etc. Esses componentes estão intimamente relacionados ao treinamento distribuído e também existem conexões muito grandes entre os componentes, como conexões de comunicação.
2.2 Estratégia de comunicação
Por se tratar de um treinamento distribuído, a comunicação deve ser mantida entre as máquinas para que os parâmetros do modelo, parâmetros de gradiente e outras informações possam ser transmitidos.
DeepSpeed fornece estratégias de comunicação como mpi, gio e nccl.
| estratégia de comunicação | ação de comunicação |
|---|---|
| mpi | É uma biblioteca de comunicação cross-point frequentemente usada para treinamento distribuído de clusters de CPU. |
| brilho | É uma estrutura de treinamento distribuído de alto desempenho que pode suportar treinamento distribuído em CPU ou GPU. |
| ncl | É uma biblioteca de comunicação específica para GPU fornecida pela nvidia e é amplamente utilizada para treinamento distribuído em GPUs. |
Quando usamos DeepSpeed para treinamento distribuído, podemos escolher a biblioteca de comunicação apropriada de acordo com nossa situação.Normalmente, se usarmos GPU para treinamento distribuído, podemos escolher nccl.
2.3 Zero (otimizador de redundância zero)
Zero desenvolvido pela Microsoft pode resolver as limitações do paralelismo de dados e do paralelismo de modelos no processo de treinamento distribuído. Por exemplo: Zero resolve o problema de possível redundância de memória no paralelismo de dados dividindo o estado do modelo (otimizador, gradiente, parâmetros) durante o processo de paralelização de dados (treinamento paralelo de dados normal, todos os parâmetros do modelo são copiados em cada máquina); ao mesmo tempo, planos de comunicação dinâmica podem ser usados durante o treinamento para compartilhar variáveis de estado importantes entre dispositivos distribuídos, mantendo assim a granularidade computacional e o volume de comunicação paralela de dados.
Zero é uma tecnologia usada para otimização de treinamento de modelos em larga escala. Seu principal objetivo é reduzir o uso de memória do modelo para que o modelo possa ser treinado na placa gráfica. O uso de memória é dividido principalmente em duas partes: Estados do modelo e A ativação .Zero resolve principalmente o problema de uso de memória dos estados do modelo.
Zero divide os parâmetros do modelo em três partes:
| estado | efeito |
|---|---|
| Estados do otimizador | Os dados que o otimizador precisa usar ao realizar atualizações de gradiente |
| Gradiente | Dados gerados durante o processo de transmissão reversa, que determina a direção de atualização dos parâmetros |
| Parâmetro do modelo | Parâmetros do modelo, informações “aprendidas” dos dados durante o treinamento do modelo |
Os níveis de Zero são os seguintes:
| nível | efeito |
|---|---|
| Zero-0 | Não usando todos os tipos de sharding, apenas usando DeepSpeed como DDP |
| Zero-1 | Divida os Estados do Otimizador, reduzindo a memória em 4 vezes, com a mesma capacidade de comunicação e paralelismo de dados |
| Zero-2 | Divida Estados e Gradientes do Otimizador, reduzindo a memória em 8 vezes, com a mesma capacidade de comunicação e paralelismo de dados |
| Zero-3 | Ao dividir os estados do otimizador, gradientes e parâmetros, a redução de memória está linearmente relacionada ao paralelismo de dados. Por exemplo, a divisão entre 64 GPUs (Nd=64) resultará em uma redução de memória de 64x. Houve um aumento moderado de 50% no volume de comunicação |
| Zero-Infinito | Zero-Infinity é uma extensão do Zero-3 que permite o treinamento de modelos grandes estendendo a memória da GPU e da CPU usando SSDs NVMe |
2.4 Descarregamento Zero:
Em comparação com a GPU, a CPU é relativamente barata, então a ideia do Zero-Offload é descarregar certos estados do modelo na fase de treinamento para memória e cálculo da CPU.

Zero-Offload não quer reduzir a eficiência computacional do sistema para minimizar o uso de memória, mas se você usar a CPU, você também precisa considerar problemas de comunicação e computação (comunicação: comunicação entre GPU e CPU; computação: também muita computação pela CPU levará à redução da eficiência).
O que Zero-Offload quer fazer é distribuir nós de computação e nós de dados em GPUs e CPUs. Qualquer dispositivo em que o nó de computação cair executará cálculos, e qualquer dispositivo em que o nó de dados cair será responsável pelo armazenamento.
Ideias de segmentação Zero-Offload:
Existem quatro nós de cálculo na figura abaixo: FWD, BWD, Param update e float2half. A complexidade de cálculo dos dois primeiros é aproximadamente O(MB), B é o tamanho do lote e a complexidade de cálculo dos dois últimos é O( M). Para não reduzir a eficiência da computação, os dois primeiros nós são colocados na GPU. Os dois últimos nós não apenas têm uma pequena quantidade de cálculo, mas também precisam lidar com o estado Adam, por isso são colocados na CPU. O estado de Adam é naturalmente colocado na memória. Para simplificar o gráfico de dados, mescle os dois primeiros nós em um nó FWD-BWD Super Node e mescle os dois últimos nós em um nó Atualizar Super Node. Conforme mostrado no lado direito da figura abaixo, ele está dividido ao longo das duas bordas do gradiente 16 e do parâmetro 16.
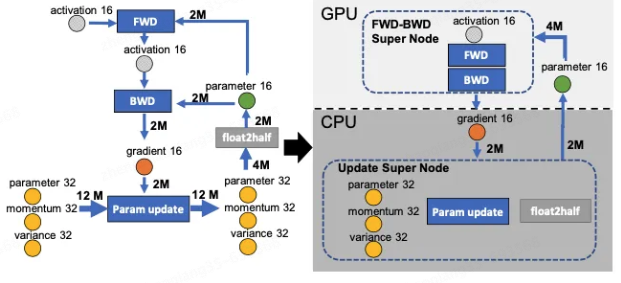
Idéia de cálculo de descarregamento zero:
Execute cálculos progressivos e regressivos na GPU, passe o gradiente para a CPU, atualize os parâmetros e, em seguida, passe os parâmetros atualizados para a GPU. Para melhorar a eficiência, o cálculo e a comunicação podem ser paralelizados. Durante o estágio de retropropagação, a GPU pode esperar até que os valores do gradiente preencham o balde, então calcular o novo gradiente e transferir o balde para a CPU. Quando a retropropagação é concluído, a CPU basicamente tem o valor de gradiente mais recente. Da mesma forma, a CPU também transmite de forma síncrona os parâmetros calculados para a GPU quando os parâmetros são atualizados, conforme mostrado na figura abaixo.
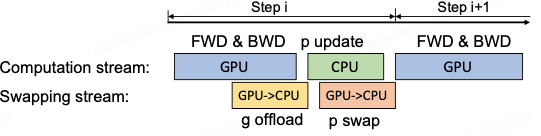
2.5 Precisão Mista:
O treinamento de precisão mista refere-se a uma técnica que usa a precisão FP16 (ponto flutuante de meia precisão) e FP32 (ponto flutuante de precisão única) durante o processo de treinamento. O uso do FP16 pode reduzir bastante o consumo de memória, permitindo o treinamento de modelos maiores. Porém, devido à menor precisão do FP16, problemas como desaparecimento de gradiente e colapso do modelo podem ocorrer durante o processo de treinamento.
DeepSpeed suporta treinamento de precisão mista, que pode ser definido no arquivo de configuração config.json para permitir precisão mista ("fp16.enabled": true). Durante o processo de treinamento, o DeepSpeed converterá automaticamente algumas operações no formato FP16 e ajustará dinamicamente o fator de escala de precisão conforme necessário para garantir a estabilidade e precisão do treinamento.
Ao usar o treinamento de precisão mista, você precisa prestar atenção a alguns problemas, como recorte de gradiente (Gradient Clipping) e ajuste da taxa de aprendizagem (Learning Rate Schedule). O recorte do gradiente pode evitar a explosão do gradiente e o ajuste da taxa de aprendizagem pode ajudar o modelo a convergir melhor.
3. Resumo
DeepSpeed torna conveniente treinar e ajustar modelos grandes quando a máquina é limitada. Ao mesmo tempo, ele também possui muitas propriedades excelentes para usar e podemos continuar a extraí-las mais tarde.
O atual método de treinamento do modelo convencional: GPU + PyTorch + Megatron-LM + DeepSpeed
Vantagem
- Eficiência de armazenamento: DeepSpeed fornece uma nova solução Zero para reduzir o uso de memória de vídeo de treinamento. Ao contrário do paralelismo de dados tradicional, ele particiona estados e gradientes do modelo para economizar uma grande quantidade de memória de vídeo;
- Escalabilidade: DeepSpeed suporta paralelismo de dados eficiente, paralelismo de modelo, paralelismo de pipeline e sua combinação, também chamado de paralelismo 3D aqui;
- Facilidade de uso: Durante a fase de treinamento, apenas algumas linhas de código precisam ser modificadas para que o modelo pytorch use DeepSpeed e Zero.
referência:
1. http://wed.xjx100.cn/news/204072.html?action=onClick
2. https://zhuanlan.zhihu.com/p/513571706
Lei Jun anunciou a arquitetura completa do sistema do ThePaper OS da Xiaomi, dizendo que a camada inferior foi completamente reestruturada. Yuque anunciou a causa da falha e do processo de reparo em 23 de outubro. CEO da Microsoft, Nadella: Abandonar o Windows Phone e os negócios móveis foi uma decisão errada . As taxas de uso do Java 11 e do Java 17 excederam o acesso do Java 8 Hugging Face foi restrito. A interrupção da rede Yuque durou cerca de 10 horas e agora voltou ao normal. A Oracle lançou extensões de desenvolvimento Java para o Visual Studio Code . A Administração Nacional de Dados oficialmente revelou Musk: Doe 1 bilhão se a Wikipedia for renomeada como "Enciclopédia Weiji" USDMySQL 8.2.0 GAAutor: JD Logística Zheng Shaoqiang
Fonte: JD Cloud Developer Community Por favor, indique a fonte ao reimprimir