Antecedentes do projeto
Com base na vigorosa promoção do projeto Xinchhuang pelo país, para o desenvolvimento tecnológico independente e controlável, os componentes básicos serão gradualmente substituídos por componentes domésticos.Portanto, a partir do banco de dados, a biblioteca elástica JED é implantada na máquina doméstica Huawei Kunpeng (baseada em Arquitetura ARM) para ajuste.Excelente comparação de desempenho com Intel (X86).
Configuração física da máquina
| Fabricante do processador | Projeto de arquitetura | Modelo de CPU | CPU | Frequência turbo | frequência de memória | sistema operacional |
|---|---|---|---|---|---|---|
| Huawei | BRAÇO | kunpeng920-7262C | 128°C | nenhum | 3200 MT/s | Euler |
| Informações | X86 | platium-8338C-3rd | 128°C | ligar | 3200 MT/s | centos 8 |
| Informações | X86 | platium-8338C-3rd | 128°C | ligar | 3200 MT/s | centos 8 |
Configuração do banco de dados
| Implantar sala de informática | Langfang |
|---|---|
| Método de implantação | recipiente |
| Configuração do gateway | Disco 16C/12G:/exportação:30G |
| esquema de banco de dados | 1 cluster, um mestre e um escravo |
| Configuração do banco de dados | Disco 8C/24G:/exportação:512G |
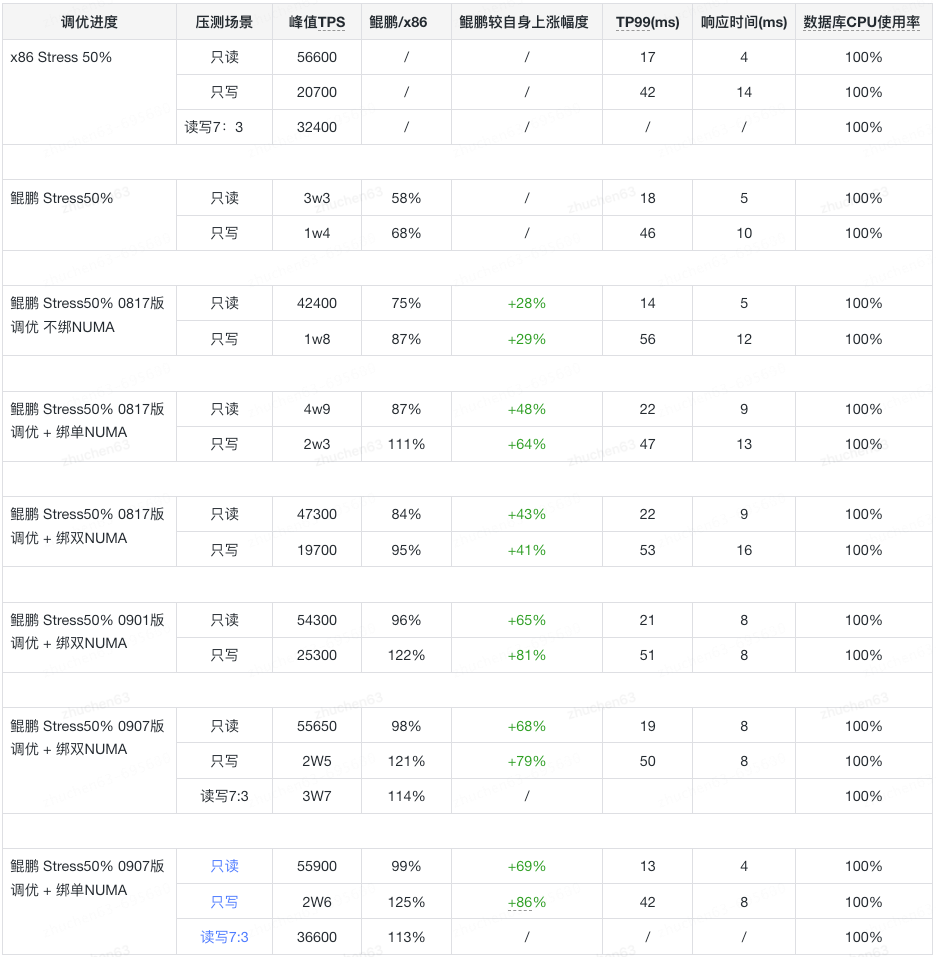
Resultados de ajuste
Antes do ajuste: Quando a pressão de fundo é de 50%, o desempenho de leitura do JED no Kunpeng é de 58% do da Intel e o desempenho de gravação é de 68%.
Após o ajuste: o desempenho de leitura do JED no Kunpeng atinge 99% do da Intel, o desempenho de gravação atinge 121% do da Intel e atinge 113% quando a mistura de leitura e gravação é 7: 3. O desempenho do TP99 e do tempo de resposta é melhor, e o banco de dados O uso da CPU atinge 100% neste momento. 100%.Os principais cenários e dados de desempenho registrados durante o processo de ajuste são os seguintes:
Processo de ajuste específico
1. Otimização do BIOS
A sala de computadores precisa ser modificada e a máquina host precisa ser reiniciada.
Expectativa: a pré-busca da CPU tem impacto no desempenho do banco de dados e precisa ser desativada ; a política de energia é o desempenho pronto para uso; o Smmu não precisa ser desativado
2. Altere o tamanho da página do host de 4K para 64K.
Configuração original:


O tamanho da tabela de páginas tem um impacto no desempenho do banco de dados. Confirme se os tamanhos das tabelas de páginas dos sistemas host x86 e Kunpeng são consistentes. Alterar o tamanho da tabela de páginas do sistema operacional host requer a recompilação do kernel. As operações em sistemas operacionais diferentes são diferentes. Por favor entre em contato com a equipe de operação e manutenção. Mudanças de contato
rpm -ivh http://storage.jd.local/k8s-node/kernel/5.10-jd_614-arm64/kernel-5.10.0-1.64kb.oe.jd_614.aarch64.rpm --force
3. Otimização no sistema operacional host
3.1 Desligue o firewall
A máquina online foi desligada e nenhuma modificação é necessária.
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
3.2 Otimização dos parâmetros do kernel da rede (se tornará inválido após o host ser reiniciado)
O desempenho de leitura e gravação não melhorou significativamente e não foi alterado.
echo 1024 >/proc/sys/net/core/somaxconn
echo 16777216 >/proc/sys/net/core/rmem_max
echo 16777216 >/proc/sys/net/core/wmem_max
echo "4096 87380 16777216" >/proc/sys/net/ipv4/tcp_rmem
echo "4096 65536 16777216" >/proc/sys/net/ipv4/tcp_wmem
echo 360000 >/proc/sys/net/ipv4/tcp_max_syn_backlog
3.3 Otimização de parâmetros IO
O desempenho não foi melhorado e não foi alterado.
echo deadline > /sys/block/nvme0n1/queue/scheduler;
echo deadline > /sys/block/nvme1n1/queue/scheduler;
echo deadline > /sys/block/nvme2n1/queue/scheduler;
echo deadline > /sys/block/nvme3n1/queue/scheduler;
echo deadline > /sys/block/sda/queue/scheduler;
echo 2048 > /sys/block/nvme0n1/queue/nr_requests;
echo 2048 > /sys/block/nvme1n1/queue/nr_requests;
echo 2048 > /sys/block/nvme2n1/queue/nr_requests;
echo 2048 > /sys/block/nvme3n1/queue/nr_requests;
echo 2048 > /sys/block/sda/queue/nr_requests
3.4 Otimização de parâmetros de cache
O desempenho não foi melhorado e não foi alterado.
echo 5 >/proc/sys/vm/dirty_ratio;
echo 1 > /proc/sys/vm/swappiness
3.5 Placa de rede interrompe e vincula núcleo
A solução geral não foi implementada, mas o número de filas de placas de rede ethxx pode ser modificado.
ethtool -l ethxxx Verifica o número de filas da placa de rede ethxxx
ethtool -L ethxxx combinado 8 ethxxx O número de filas da placa de rede precisa ser definido como 8, o que é consistente com x 86. Após a modificação, o desempenho é melhorado (todo o tráfego entra pela placa de rede eth).
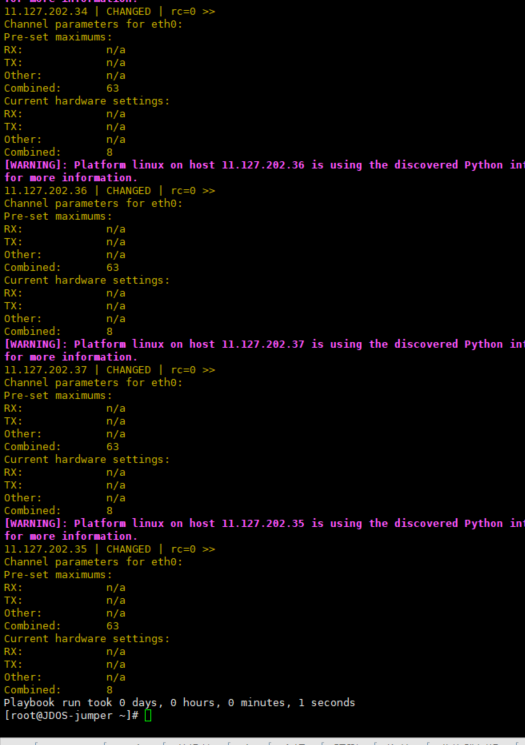
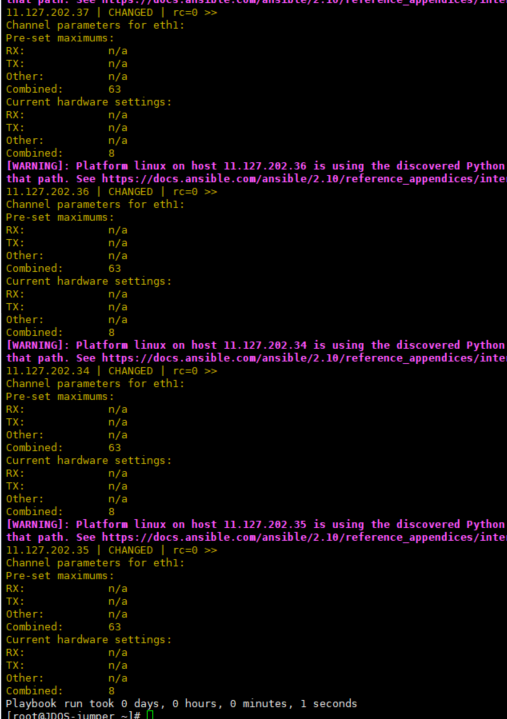
systemctl stop irqbalance
systemctl disable irqbalance
ethtool -L eth0 combined 1 #将网卡eth0的队列配置为 combined 模式,将所有队列合并为一个。
#eth0 修改为实际使用的网卡设备名 这项参数对性能有影响
# 查看网卡队列信息
ethtool -l ethxxx
netdevice=eth0
cores=31
#查看网卡所属的 NUMANODE
cat /sys/class/net/${netdevice}/device/numa_node
#查看网卡中断号
cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}') | awk -F ':' '{print $1}'
# 网卡中断绑核
for i in `cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}')| awk -F ':' '{print $1}'`;do echo ${cores} > /proc/irq/$i/smp_affinity_list;done
netdevice=eth0
# 查看绑核后的结果
for i in `cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}')| awk -F ':' '{print $1}'`;do cat /proc/irq/$i/smp_affinity_list;done
netdevice=eth1
cores=31
# 网卡中断绑核
for i in `cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}')| awk -F ':' '{print $1}'`;do echo ${cores} > /proc/irq/$i/smp_affinity_list;done
# 查看绑核后的结果
for i in `cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}')| awk -F ':' '{print $1}'`;do cat /proc/irq/$i/smp_affinity_list;done
4. Vincule o contêiner de negócios ao NUMA (atualize o agendador e implante o agente de colocalização)
Antes da implantação da plataforma, se precisar testar, você pode modificar a configuração do cgroup do contêiner para vincular núcleos para isolar a CPU e a memória do NUMA onde a pressão de fundo está localizada.
As operações de exemplo são as seguintes
# 进入业务容器cgroup配置地址
cd /sys/fs/cgroup/cpuset/kubepods/burstable/poded***********/7b40a68a************
# 停docker,如果重启会重置cgroup配置
systemctl stop docker
# 压测过程中注意观察配置文件是否生效,如果docker服务会不停重启,可写个小脚本一直停服务或者覆盖写cgroup配置
echo 16-23 > cpu.set
echo 0 > mem.set
5. mysql-crc32 editado suavemente para editado permanentemente para ARM
Compilado no lado do banco de dados e pode ser implantado uniformemente
cd /mysql-5.7.26
git apply crc32-mysql5.7.26.patch
6. Otimização de compilação de feedback do mysqld
Compilado no lado do banco de dados e pode ser implantado uniformemente
Precisa confirmar usando openEuler gcc 10.3.1

https://gitee.com/openeuler/A-FOT/wikis/README
Preparação do ambiente (executada em ambiente de teste e ambiente de compilação)
git clone https://gitee.com/openeuler/A-FOT.git
yum install -y A-FOT (仅支持 openEuler 22.03 LTS)
yum -y install perf
Modifique o arquivo de configuração a-fot.ini (executado no ambiente de teste e ambiente de compilação)
cd /A-FOT
vim ./a-fot.ini # 修改内容如下
# 文件和目录请使用绝对路径
# 优化模式(AutoFDO、AutoPrefetch、AutoBOLT、Auto_kernel_PGO)(选择 AutoBolt) opt_mode=AutoBOLT
# 脚本工作目录(用来编译应用程序/存放 profile、日志,中间过程文件可能会很大,确保有 150G 的空 间)
work_path=/pgo-opt
# 应用运行脚本路径(空文件占位即可,使用 chmod 777 /root/run.sh 赋予可执行权限) run_script=/root/run.sh
# GCC 路径(bin、lib 的父目录,修改成所要使用的 gcc 的目录)
gcc_path=/usr
# AutoFDO、AutoPrefetch、AutoBOLT
# 针对应用的三种优化模式,请填写此部分配置
# 应用进程名
application_name=mysqld
# 二进制安装后可执行文件
bin_file=/usr/local/mysql-pgo/bin/mysqld
# 应用构建脚本路径(文件内填写源码编译 mysql 的相关命令, 赋予可执行权限)
chmod 777 /root/ build.sh
build_script=/root/build.sh
# 最大二进制启动时间(单位:秒)
max_waiting_time=700
# Perf 采样时长(单位:秒)(设置采样时间为 10min)
perf_time=600
# 检测是否优化成功(1=启用,0=禁用) check_success=1
# 构建模式 (Bear、Wrapper) build_mode=Wrapper
# auto_kernel_PGO
# 针对内核的优化模式,请填写此部分配置
# 内核 PGO 模式(arc=只启用 arc profile,all=启用完整的 PGO 优化) pgo_mode=all
# 执行阶段(1=编译插桩内核阶段,2=编译优化内核阶段) pgo_phase=1
# 内核源码目录(不指定则自动下载) kernel_src=/opt/kernel
# 内核构建的本地名(将根据阶段添加"-pgoing"或"-pgoed"后缀) kernel_name=kernel
# 内核编译选项(请确保选项修改正确合法,不会造成内核编译失败) #CONFIG_...=y
# 重启前的时间目录(用于将同一套流程的日志存放在一起)
last_time=
# 内核源码的 Makefile 地址(用于不自动编译内核的场景) makefile=
# 内核配置文件路径(用于不自动编译内核的场景) kernel_config=
# 内核生成的原始 profile 目录(用于不自动编译内核的场景) data_dir=
/root/build.sh (o conteúdo de referência é o seguinte)
cd /mysql-8.0.25 rm -rf build mkdir build
cd build
cmake .. -DBUILD_CONFIG=mysql_release -DCMAKE_INSTALL_PREFIX=/usr/local/mysql-pgo -
DMYSQL_DATADIR=/data/mysql/data -DWITH_BOOST=/mysql-8.0.25/boost/boost_1_73_0 make -j 96
make -j 96 install

Compilação de comentários
1. Compile pela primeira vez
Você pode ignorá-lo e apenas colocar A-FOT no processo mysql executável do docker.
2. Coleta de dados (executada em ambiente de teste)
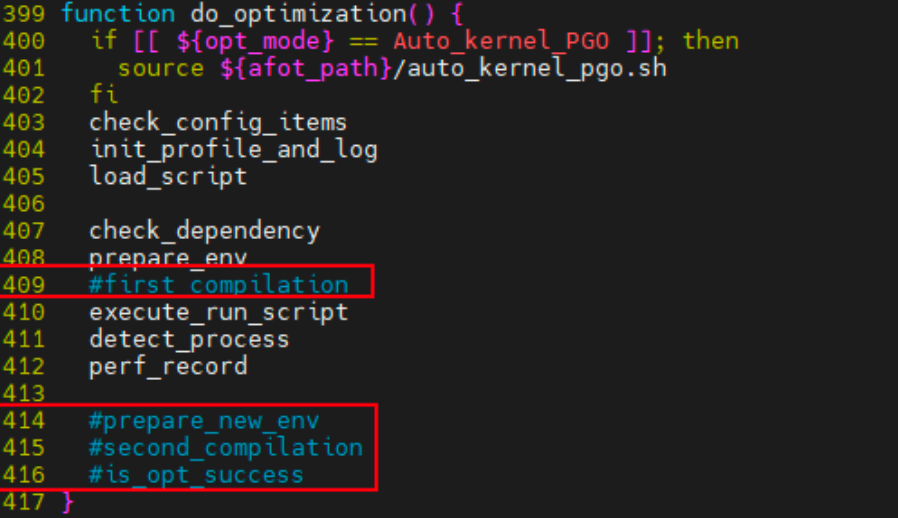
Modifique o arquivo /A-FOT/a-fot da seguinte maneira: comente as funções 409 e 414-416
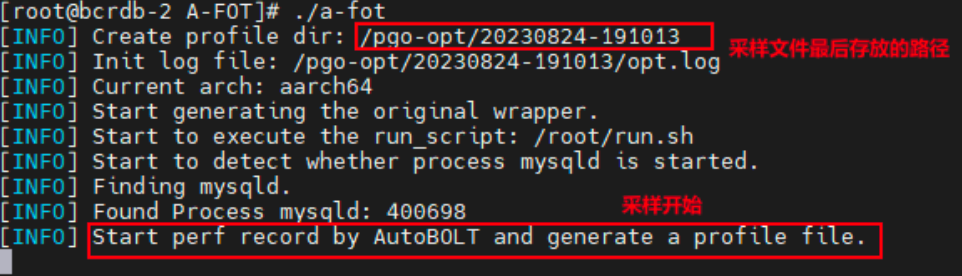
Inicie o processo mysqld e, ao mesmo tempo, o fim da pressão começa a pressionar o mysql, fazendo com que o mysqld comece a processar negócios
Execute ./a-fot e o seguinte eco aparecerá na tela.
Após o sucesso, você pode observar o arquivo profile.gcov no diretório /pgo-opt correspondente.

Após a abertura, o seguinte conteúdo aparecerá:
3. Mesclar manualmente no perfil para compilação
cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local/mysql-5.7.26-pgo/ -
DMYSQL_DATADIR=/data/mysql/data -DSYSCONFDIR=/usr/local/mysql-5.7.26- pgo/etc -DWITH_INNOBASE_STORAGE_ENGINE=1 - DWITH_PERFSCHEMA_STORAGE_ENGINE=1 - DWITH_BLACKH0LE_ST0RAGE_ENGINE=1 -DDEFAULT_CHARSET=utf8 - DDEFAULT_COLLATION=utf8_general_ci - DMYSQL_UNIX_ADDR=/data/mysql/tmp/mysql.sock -DENABLED_LOCAL_INFILE=ON -DENABLED_PROFILING=ON - DWITH_DEBUG=0 -DMYSQL_TCP_PORT=3358 - DCMAKE_EXE_LINKER_FLAGS="-ljemalloc" -Wno-dev -DWITH_BOOST=/mysql-5.7.26/boost/boost_1_59_0 -Wno-dev -DCMAKE_CXX_FLAGS="-fbolt-use=Wl,-q" -DCMAKE_CXX_LINK_FLAGS="-Wl,-q"
PATH_OF_PROFILE 改成 profile 所在的原始路径
7. Atualização de versão e compilação de feedback
Os agentes relacionados ao banco de dados só precisam operar se usarem go.
7.1 Atualize o golang para 1.21
7.2 Otimização Go PGO
1. Adicione import _ "net/http/pprof" ao código do programa import pprof
2. Inicie o programa e realize um teste de estresse
- Depois que a pressão for iniciada, execute as seguintes operações para coletar arquivos de perfil: o segundo é o tempo de coleta e a unidade é s curl -o cpu.pprof http://localhost:8080/debug/pprof/profile?seconds=304. De acordo com o cpu.pprof gerado Recompile o binário mv cpu.pprof default.pgo Recompile o programa com a opção –pgo go build –pgo=auto
Em relação à melhoria de desempenho, os dados oficiais fornecidos pela Golang são:
No Go 1.21, os benchmarks de um conjunto representativo de programas Go mostram que construir com PGO pode melhorar o desempenho em aproximadamente 2-7%.
O autor da estrutura de código aberto NanUI passou a vender aço e o projeto foi suspenso. A lista gratuita número um na App Store da Apple é o software pornográfico TypeScript. Ele acaba de se tornar popular, por que os grandes começam a abandoná-lo ? Lista TIOBE de outubro: Java tem o maior declínio, C # está se aproximando Java Rust 1.73.0 lançado Um homem foi encorajado por sua namorada AI a assassinar a Rainha da Inglaterra e foi condenado a nove anos de prisão Qt 6.6 lançado oficialmente Reuters: RISC-V a tecnologia se torna a chave para a guerra tecnológica sino-americana Novo campo de batalha RISC-V: não controlada por nenhuma empresa ou país, a Lenovo planeja lançar o Android PCAutor: JD Varejo Zhu Chen
Fonte: JD Cloud Developer Community Por favor, indique a fonte ao reimprimir