Artigo de ataque e defesa adversário NeurIPS
NeurIPS2022|Compilação de documentos de ataque e defesa adversários-Zhihu
BIRD: Detecção e remoção generalizável de backdoor para aprendizado por reforço profundo
https://neurips.cc/virtual/2023/poster/70618
Resumo:
Os ataques backdoor representam uma séria ameaça ao gerenciamento da cadeia de suprimentos de políticas de aprendizagem por reforço profundo (DRL). Embora as defesas iniciais tenham sido propostas em estudos recentes, a generalização e a escalabilidade destes métodos são muito limitadas. Para resolver este problema, propomos o BIRD, uma técnica para detectar e remover backdoors de políticas DRL pré-treinadas em um ambiente limpo, sem exigir qualquer conhecimento sobre a especificação do ataque e acesso ao seu processo de treinamento. Ao analisar a natureza e o comportamento únicos dos ataques de backdoor, formulamos a recuperação de gatilho como um problema de otimização e projetamos uma nova métrica de detecção de estratégia de backdoor. Também projetamos um método de ajuste fino para remover o backdoor e, ao mesmo tempo, manter o desempenho do agente em um ambiente limpo. Avaliamos a capacidade do BIRD de resistir a três ataques backdoor em dez ambientes diferentes de agente único ou multiagente. Nossos resultados verificam a eficácia, eficiência e generalização do BIRD, bem como sua robustez a diferentes variações e adaptações de ataques.
Os ataques backdoor representam uma grave ameaça à gestão da cadeia de abastecimento de políticas de aprendizagem por reforço profundo (DRL). Apesar das defesas iniciais propostas em estudos recentes, estes métodos têm generalização e escalabilidade muito limitadas. Para resolver esse problema, propomos o BIRD, uma técnica para detectar e remover backdoors de uma política DRL pré-treinada em um ambiente limpo, sem exigir qualquer conhecimento sobre as especificações do ataque e acessar seu processo de treinamento. Ao analisar as propriedades e comportamentos únicos dos ataques backdoor, formulamos a restauração de gatilhos como um problema de otimização e projetamos uma nova métrica para detectar políticas backdoor. Também projetamos um método de ajuste fino para remover o backdoor, enquanto mantemos o desempenho do agente no ambiente limpo. Avaliamos o BIRD contra três ataques backdoor em dez ambientes diferentes de agente único ou multiagente. Nossos resultados verificam a eficácia, eficiência e generalização do BIRD, bem como sua robustez a diferentes variações e adaptações de ataques.
Desaprendizado Adversário Compartilhado: Mitigação de Backdoor ao Desaprender Exemplos Adversariais Compartilhados
https://neurips.cc/virtual/2023/poster/69874
Artigo: https://arxiv.org/abs/2307.10562
Resumo:
Os ataques backdoor são uma séria ameaça à segurança dos modelos de aprendizado de máquina, onde um adversário pode injetar amostras envenenadas no conjunto de treinamento, fazendo com que o modelo backdoor preveja amostras envenenadas com gatilhos específicos para uma classe-alvo específica, enquanto funciona bem em amostras benignas normais. Neste artigo, exploramos a tarefa de higienizar modelos de backdoor usando pequenos conjuntos de dados limpos. Ao estabelecer a conexão entre o risco de backdoor e o risco adversário, derivamos um novo limite superior de risco de backdoor que captura principalmente o risco de instâncias adversárias compartilhadas (SAEs) entre modelos backdoor e sanitizados. Este limite superior propõe ainda um novo problema de otimização de duas camadas para mitigar backdoors usando técnicas de treinamento adversárias. Para resolver este problema, propomos a Liberação Adversarial Compartilhada (SAU). Especificamente, o SAU primeiro gera SAEs e depois ignora os SAEs gerados para que sejam classificados corretamente pelo modelo purificado e/ou classificados de forma diferente pelos dois modelos, de modo que o efeito backdoor no modelo backdoor seja mitigado no modelo purificado. Experimentos em vários conjuntos de dados de benchmark e arquiteturas de rede mostram que nosso método proposto atinge desempenho de última geração na defesa de backdoor.
Os ataques backdoor são sérias ameaças à segurança dos modelos de aprendizado de máquina, onde um adversário pode injetar amostras envenenadas no conjunto de treinamento, causando um modelo backdoor que prevê amostras envenenadas com gatilhos específicos para classes-alvo específicas, enquanto se comporta normalmente em amostras benignas. Neste artigo, exploramos a tarefa de purificar um modelo backdoor usando um pequeno conjunto de dados limpo. Ao estabelecer a ligação entre o risco de backdoor e o risco adversário, derivamos um novo limite superior para o risco de backdoor, que captura principalmente o risco nos exemplos adversários partilhados (SAEs) entre o modelo backdoor e o modelo purificado. Este limite superior sugere ainda um novo problema de otimização de dois níveis para mitigar backdoors usando técnicas de treinamento adversárias. Para resolvê-lo, propomos a Desaprendizagem Adversarial Compartilhada (SAU). Especificamente, O SAU primeiro gera SAEs e, em seguida, desaprende os SAEs gerados de modo que sejam classificados corretamente pelo modelo purificado e/ou classificados de forma diferente pelos dois modelos, de modo que o efeito backdoor no modelo backdoor será mitigado no modelo purificado. Experimentos em vários conjuntos de dados de benchmark e arquiteturas de rede mostram que nosso método proposto atinge desempenho de última geração para defesa de backdoor.

VillanDiffusion: uma estrutura unificada de ataque backdoor para modelos de difusão
https://neurips.cc/virtual/2023/poster/70045
Artigo: https://arxiv.org/abs/2306.06874
Resumo:
O modelo de difusão (DM) é um modelo generativo de última geração que aprende um processo de destruição reversível a partir da adição iterativa de ruído e remoção de ruído. Eles são a espinha dorsal de muitas aplicações generativas de inteligência artificial, como a geração condicional de texto para imagens. No entanto, pesquisas recentes mostraram que DMs incondicionais básicos (como DDPM e DDIM) são vulneráveis à injeção backdoor, um ataque de manipulação de saída desencadeado por padrões incorporados maliciosamente na entrada do modelo. Este artigo propõe uma estrutura unificada de ataque de backdoor (VillanDiffusion) para expandir o escopo da análise atual de backdoor de DM. Nossa estrutura abrange DM incondicional e condicional convencional (baseado em remoção de ruído e baseado em pontuação), bem como vários amostradores sem treinamento para avaliação geral. Experimentos mostram que nossa estrutura unificada facilita a análise de backdoor em diferentes configurações de DM e fornece novos insights sobre ataques de backdoor baseados em legendas em DM.
Modelos de difusão (DMs) são modelos generativos de última geração que aprendem um processo de corrupção reversível a partir da adição e remoção de ruído iterativa. Eles são a espinha dorsal de muitas aplicações generativas de IA, como a geração condicional de texto para imagem. No entanto, estudos recentes mostraram que DMs incondicionais básicos (por exemplo, DDPM e DDIM) são vulneráveis à injeção backdoor, um tipo de ataque de manipulação de saída desencadeado por um padrão incorporado maliciosamente na entrada do modelo. Este artigo apresenta uma estrutura unificada de ataque backdoor (VillanDiffusion) para expandir o escopo atual da análise de backdoor para DMs. Nossa estrutura abrange DMs incondicionais e condicionais convencionais (baseados em remoção de ruído e baseados em pontuação) e vários amostradores sem treinamento para avaliações holísticas.



Modelando teoricamente a divergência de dados do cliente para defesa backdoor de linguagem natural federada
https://neurips.cc/virtual/2023/poster/70177
Resumo:
Algoritmos de aprendizado federado permitem que modelos de redes neurais sejam treinados em vários dispositivos de borda distribuídos sem expor dados privados. No entanto, eles são vulneráveis a ataques backdoor lançados por clientes mal-intencionados. Os algoritmos robustos de agregação federada existentes detectam e excluem heuristicamente clientes suspeitos com base em sua distância paramétrica, mas são ineficazes em tarefas de processamento de linguagem natural (PNL). A principal razão é que, embora os padrões de backdoor textuais sejam evidentes no nível do conjunto de dados subjacente, eles geralmente ficam ocultos no nível dos parâmetros porque a injeção de backdoors no texto com um espaço de recursos discreto tem menos impacto estatístico nos parâmetros do modelo. Para resolver este problema, propomos identificar clientes backdoor modelando explicitamente diferenças de dados entre clientes em sistemas de PNL federados. Através da análise teórica, derivamos a métrica de divergência f para estimar a divergência de dados do cliente com atualizações agregadas e Hessianos. Além disso, guiados pela teoria da difusão, projetamos um método de síntese de conjunto de dados com um mecanismo de redistribuição Hessiano para enfrentar o principal desafio de conjuntos de dados inacessíveis ao calcular os dados do cliente Hessiano. Em seguida, propomos um novo algoritmo Federated F-Divergence-Based Aggregation (Fed-FA), que aproveita as métricas de F-Divergence para detectar e descartar clientes suspeitos. Um grande número de resultados empíricos mostram que o Fed-FA supera todos os métodos paramétricos baseados em distância na resistência a ataques backdoor em vários cenários de ataque backdoor em linguagem natural.
Algoritmos de aprendizagem federados permitem que modelos de redes neurais sejam treinados em vários dispositivos de borda descentralizados sem exposição de dados privados. No entanto, eles são suscetíveis a ataques backdoor lançados por clientes mal-intencionados. Os algoritmos robustos de agregação federada existentes detectam e excluem heuristicamente clientes suspeitos com base nas distâncias de seus parâmetros, mas são ineficazes em tarefas de processamento de linguagem natural (PNL). A principal razão é que, embora os padrões de backdoor de texto sejam óbvios no nível do conjunto de dados subjacente, eles geralmente ficam ocultos no nível dos parâmetros, uma vez que a injeção de backdoors em textos com espaço de recursos discreto tem menos impacto nas estatísticas dos parâmetros do modelo. Para resolver esta questão, propomos identificar clientes backdoor modelando explicitamente a divergência de dados entre clientes em sistemas de PNL federados. Através da análise teórica, derivamos o indicador de divergência f para estimar a divergência de dados do cliente com atualizações de agregação e Hessianos. Além disso, desenvolvemos um método de síntese de conjuntos de dados com um mecanismo de reatribuição Hessiano guiado pela teoria da difusão para enfrentar o principal desafio de conjuntos de dados inacessíveis no cálculo de dados Hessianos dos clientes. Em seguida, apresentamos o novo algoritmo Federated F-Divergence-Based Aggregation (Fed-FA), que aproveita o indicador de f-divergência para detectar e descartar clientes suspeitos. Extensos resultados empíricos mostram que o Fed-FA supera todos os métodos baseados em distância de parâmetros na defesa contra ataques de backdoor entre vários cenários de ataque de backdoor em linguagem natural. derivamos o indicador de divergência f para estimar a divergência de dados do cliente com atualizações de agregação e Hessianos. Além disso, desenvolvemos um método de síntese de conjuntos de dados com um mecanismo de reatribuição Hessiano guiado pela teoria da difusão para enfrentar o principal desafio de conjuntos de dados inacessíveis no cálculo de dados Hessianos dos clientes. Em seguida, apresentamos o novo algoritmo Federated F-Divergence-Based Aggregation (Fed-FA), que aproveita o indicador de f-divergência para detectar e descartar clientes suspeitos. Extensos resultados empíricos mostram que o Fed-FA supera todos os métodos baseados em distância de parâmetros na defesa contra ataques de backdoor entre vários cenários de ataque de backdoor em linguagem natural. derivamos o indicador de divergência f para estimar a divergência de dados do cliente com atualizações de agregação e Hessianos. Além disso, desenvolvemos um método de síntese de conjuntos de dados com um mecanismo de reatribuição Hessiano guiado pela teoria da difusão para enfrentar o principal desafio de conjuntos de dados inacessíveis no cálculo de dados Hessianos dos clientes. Em seguida, apresentamos o novo algoritmo Federated F-Divergence-Based Aggregation (Fed-FA), que aproveita o indicador de f-divergência para detectar e descartar clientes suspeitos. Extensos resultados empíricos mostram que o Fed-FA supera todos os métodos baseados em distância de parâmetros na defesa contra ataques de backdoor entre vários cenários de ataque de backdoor em linguagem natural. desenvolvemos um método de síntese de conjunto de dados com um mecanismo de reatribuição Hessiano guiado pela teoria da difusão para enfrentar o principal desafio de conjuntos de dados inacessíveis no cálculo de dados Hessianos de clientes. Em seguida, apresentamos o novo algoritmo Federated F-Divergence-Based Aggregation (Fed-FA), que aproveita o indicador de f-divergência para detectar e descartar clientes suspeitos. Extensos resultados empíricos mostram que o Fed-FA supera todos os métodos baseados em distância de parâmetros na defesa contra ataques de backdoor entre vários cenários de ataque de backdoor em linguagem natural. desenvolvemos um método de síntese de conjunto de dados com um mecanismo de reatribuição Hessiano guiado pela teoria da difusão para enfrentar o principal desafio de conjuntos de dados inacessíveis no cálculo de dados Hessianos de clientes. Em seguida, apresentamos o novo algoritmo Federated F-Divergence-Based Aggregation (Fed-FA), que aproveita o indicador de f-divergência para detectar e descartar clientes suspeitos. Extensos resultados empíricos mostram que o Fed-FA supera todos os métodos baseados em distância de parâmetros na defesa contra ataques de backdoor entre vários cenários de ataque de backdoor em linguagem natural.
BadTrack: um ataque backdoor somente venenoso no rastreamento visual de objetos
https://neurips.cc/virtual/2023/poster/71420
Resumo:
O rastreamento visual de objetos (VOT) é uma das tarefas mais fundamentais da visão computacional. Os rastreadores VOT da técnica anterior extraem exemplos positivos e negativos que são usados para orientar o rastreador para distinguir objetos do fundo. Neste artigo, demonstramos que esse recurso pode ser explorado para introduzir novas ameaças e, portanto, propomos um ataque backdoor simples, porém eficaz, apenas com veneno. Especificamente, envenenamos uma pequena parte dos dados de treinamento anexando um padrão de gatilho predefinido à região de fundo de cada quadro de vídeo, de modo que os gatilhos apareçam quase exclusivamente em exemplos negativos extraídos. Até onde sabemos, este é o primeiro trabalho a revelar que os rastreadores VOT são ameaçados por ataques de backdoor apenas com veneno. Nossos experimentos mostram que nosso ataque backdoor pode reduzir significativamente o desempenho de rastreadores Transformer siameses de fluxo duplo e de fluxo único em dados envenenados, ao mesmo tempo em que alcança desempenho comparável ao de rastreadores benignos
O rastreamento visual de objetos (VOT) é uma das tarefas mais fundamentais na comunidade de visão computacional. Os rastreadores VOT de última geração extraem exemplos positivos e negativos que são usados para orientar o rastreador para distinguir o objeto do fundo. Neste artigo, mostramos que esta característica pode ser explorada para introduzir novas ameaças e, portanto, propor um ataque backdoor simples, mas eficaz, apenas com veneno. Para ser mais específico, envenenamos uma pequena parte dos dados de treinamento anexando um padrão de disparo predefinido à região de fundo de cada quadro de vídeo, de modo que o disparo apareça quase exclusivamente nos exemplos negativos extraídos. Até onde sabemos, este é o primeiro trabalho que revela a ameaça de ataque backdoor apenas com veneno em rastreadores VOT.
Pré-treinamento robusto e contrastivo de linguagem-imagem contra envenenamento de dados e ataques backdoor
https://neurips.cc/virtual/2023/poster/71818
Artigo: https://arxiv.org/abs/2303.06854
Resumo:
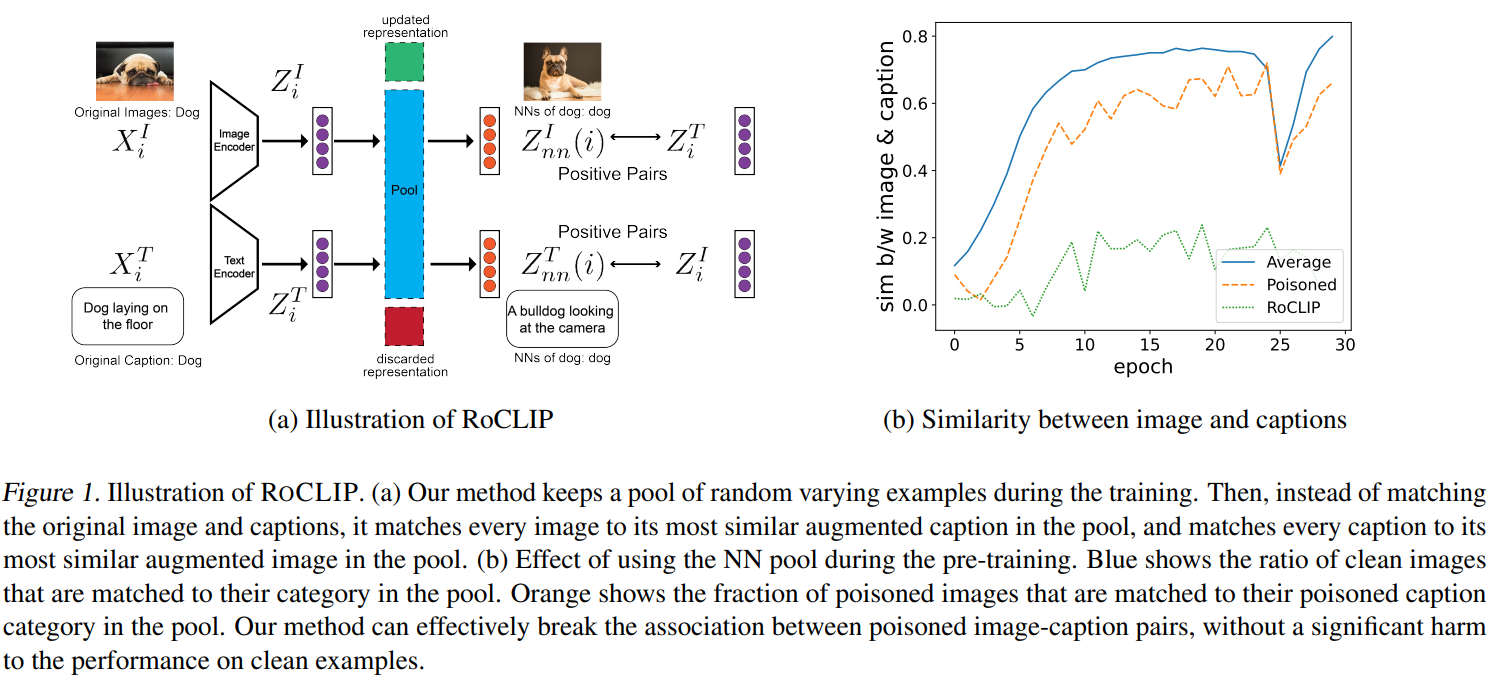
O aprendizado contrastivo de representação visual-verbal alcança desempenho de última geração na classificação zero-shot, aprendendo com milhões de pares imagem-cognitivos extraídos da Internet. No entanto, as grandes quantidades de dados que alimentam grandes modelos multimodais, como o CLIP, tornam-nos altamente vulneráveis a ataques direcionados e de backdoor de envenenamento de dados. Apesar desta vulnerabilidade, o pré-treinamento robusto de linguagem visual contrastiva contra esses ataques permanece sem solução. Neste trabalho, propomos o ROCLIP, o primeiro método eficaz para pré-treinamento robusto de modelos de linguagem visual multimodais contra envenenamento de dados alvo e ataques backdoor. O ROCLIP efetivamente quebra a correlação entre pares de legendas de imagens envenenadas, considerando um conjunto relativamente grande e variado de legendas aleatórias e combinando cada imagem com o texto mais semelhante no conjunto (em vez de sua própria legenda). Nossos extensos experimentos mostram que nossa abordagem torna o envenenamento de dados direcionado de última geração e os ataques backdoor ineficazes durante o pré-treinamento do CLIP. Em particular, o RoCLIP reduz a taxa de sucesso do ataque venenoso de 93,75% para 12,5% e a taxa de sucesso do ataque backdoor para 0%, e melhora efetivamente o desempenho de detecção linear do modelo em 10%, mantendo o desempenho de emissão zero semelhante ao CLIP.
O aprendizado contrastivo de representação de linguagem de visão alcançou desempenho de última geração para classificação zero-shot, aprendendo com milhões de pares de legendas de imagens rastreados na Internet. No entanto, os dados massivos que alimentam grandes modelos multimodais, como o CLIP, tornam-nos extremamente vulneráveis a ataques direcionados e de backdoor de envenenamento de dados. Apesar desta vulnerabilidade, o pré-treinamento robusto da linguagem visual contrastiva contra esses ataques permaneceu sem solução. Neste trabalho, propomos o ROCLIP, o primeiro método eficaz para pré-treinamento robusto de modelos de linguagem de visão multimodais contra envenenamento de dados direcionados e ataques backdoor. O ROCLIP quebra efetivamente a associação entre pares imagem-legenda envenenados, considerando um conjunto relativamente grande e variado de legendas aleatórias, e combinar cada imagem com o texto mais semelhante a ela no conjunto, em vez de sua própria legenda. Nossos extensos experimentos mostram que nosso método torna o envenenamento de dados direcionado de última geração e os ataques backdoor ineficazes durante o CLIP pré-treinamento. Em particular, o RoCLIP diminui a taxa de sucesso do ataque venenoso de 93,75% para 12,5% e as taxas de sucesso do ataque backdoor para 0% e melhora efetivamente o desempenho da sonda linear do modelo em 10% e mantém um desempenho de tiro zero semelhante em comparação com o CLIP.

Purificação de backdoor estável com ajuste de mudança de recursos
https://neurips.cc/virtual/2023/poster/72630
Artigo: https://arxiv.org/abs/2310.01875v1
Código: https://github.com/AISafety-HKUST/stable_backdoor_purification
Resumo:
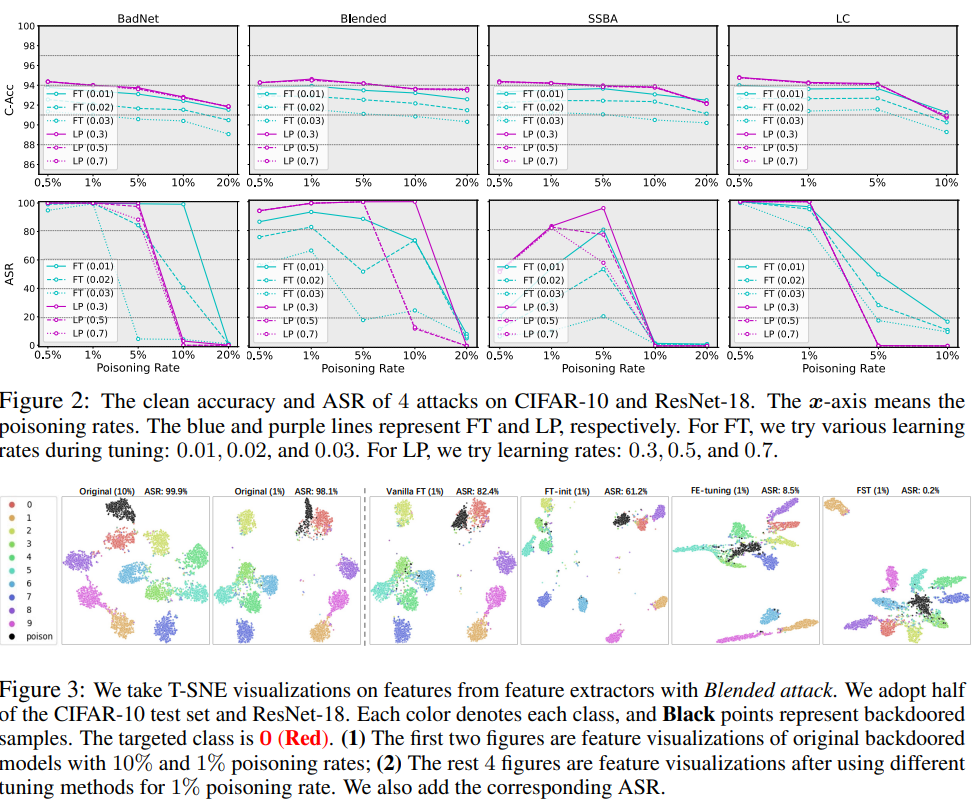
Tem sido amplamente observado que redes neurais profundas (DNNs) são vulneráveis a ataques backdoor, por meio dos quais os invasores podem manipular maliciosamente o comportamento do modelo, adulterando um pequeno conjunto de amostras de treinamento. Embora uma linha de métodos de defesa tenha sido proposta para mitigar esta ameaça, eles exigem modificações complexas no processo de treinamento ou dependem fortemente de arquiteturas de modelos específicos, o que os torna difíceis de implantar em aplicações do mundo real. Portanto, neste artigo, começaremos com o ajuste fino, uma das defesas de backdoor mais comuns e fáceis de implantar, por meio de uma avaliação completa de diferentes cenários de ataque. Observações feitas através de experimentos preliminares indicam que, ao contrário dos resultados defensivos promissores em altas taxas de envenenamento, a abordagem de ajuste básico falha completamente em baixas taxas de envenenamento. Nossa hipótese é que, no caso de baixas taxas de envenenamento, o emaranhado entre os recursos backdoor e os recursos limpos destrói a eficácia das defesas baseadas em ajuste e, portanto, o desembaraço entre os recursos limpos e os recursos backdoor é necessário para melhorar a higienização do backdoor. Propomos um método de sanitização de backdoor baseado em ajuste chamado Feature Shift Tuning (FST), que é simples e estável e pode resistir a vários ataques de backdoor. Especificamente, nossa abordagem incentiva a transferência de recursos, desviando ativamente a cabeça do classificador dos pesos inicialmente comprometidos, desemaranhando recursos limpos e recursos backdoor. Extensos experimentos mostram que nosso FST oferece desempenho consistente e estável sob diferentes configurações de ataque. Além disso, pode ser facilmente implantado em cenários do mundo real, reduzindo significativamente os custos computacionais.
Tem sido amplamente observado que redes neurais profundas (DNN) são vulneráveis a ataques backdoor, onde os invasores podem manipular o comportamento do modelo de forma maliciosa, adulterando um pequeno conjunto de amostras de treinamento. Embora seja proposta uma linha de métodos de defesa para mitigar esta ameaça, eles exigem modificações complicadas no processo de treinamento ou dependem fortemente da arquitetura do modelo específico, o que os torna difíceis de serem implantados em aplicações do mundo real. Portanto, neste artigo, começamos com o ajuste fino, uma das defesas de backdoor mais comuns e fáceis de implantar, por meio de avaliações abrangentes contra diversos cenários de ataque. Observações feitas através de experimentos iniciais mostram que, em contraste com os resultados defensivos promissores em altas taxas de envenenamento, os métodos de ajuste padrão falham completamente em cenários de baixa taxa de envenenamento. Postulamos que, com a baixa taxa de envenenamento, o emaranhado entre os recursos backdoor e clean prejudica o efeito das defesas baseadas em ajuste e, portanto, é necessário desembaraçar os recursos clean e backdoor para melhorar a purificação do backdoor. Propomos um método de purificação de backdoor baseado em ajuste chamado feature shift tuning (FST), que é simples e estável contra uma ampla gama de ataques de backdoor. Especificamente, nosso método incentiva mudanças de recursos, desviando ativamente a cabeça do classificador dos pesos originalmente comprometidos, desembaraçando os recursos limpos e de backdoor. Extensos experimentos demonstram que nosso FST fornece desempenho consistentemente estável sob diferentes configurações de ataque e, além disso, também é conveniente para implantação em cenários do mundo real com custos de computação significativamente reduzidos.


Defesa de backdoor de caixa preta por meio de purificação de imagem zero-shot
https://neurips.cc/virtual/2023/poster/71421
Artigo: https://arxiv.org/abs/2303.12175
Resumo:
O ataque backdoor injeta amostras envenenadas nos dados de treinamento, fazendo com que a entrada envenenada seja classificada incorretamente durante a implantação do modelo. A proteção contra esses ataques é um desafio, especialmente para modelos de caixa preta do mundo real que permitem apenas acesso a consultas. Neste artigo, propomos uma nova estrutura de defesa de backdoor para defesa contra ataques de backdoor por meio de Zero-Sample Image Purification (ZIP). Nossa estrutura pode ser aplicada a modelos de caixa preta sem exigir informações internas sobre o modelo envenenado ou qualquer conhecimento prévio de amostras limpas/envenenadas. Nossa estrutura de defesa consiste em duas etapas. Primeiro, aplicamos uma transformação linear à imagem envenenada, com o objetivo de destruir o padrão backdoor. Em seguida, usamos um modelo de difusão pré-treinado para recuperar as informações semânticas ausentes removidas pela transformação. Em particular, projetamos um novo procedimento inverso que utiliza imagens transformadas para orientar a geração de imagens purificadas de alta fidelidade que funcionam em uma configuração de amostra zero. Avaliamos nossa estrutura ZIP em vários conjuntos de dados com diferentes tipos de ataques. Resultados experimentais demonstram as vantagens de nossa estrutura ZIP em comparação com linhas de base de defesa de backdoor de última geração. Acreditamos que nossas descobertas fornecerão informações valiosas sobre futuros métodos de defesa para modelos de caixa preta.
Os ataques backdoor injetam amostras envenenadas nos dados de treinamento, resultando na classificação incorreta da entrada envenenada durante a implantação de um modelo. A defesa contra esses ataques é um desafio, especialmente para modelos de caixa preta do mundo real, onde apenas o acesso a consultas é permitido. Neste artigo, propomos uma nova estrutura de defesa de backdoor para defesa contra ataques de backdoor por meio de purificação de imagem zero-shot (ZIP). Nossa estrutura pode ser aplicada a modelos de caixa preta sem exigir informações internas sobre o modelo envenenado ou qualquer conhecimento prévio das amostras limpas/envenenadas. Nossa estrutura de defesa envolve duas etapas. Primeiro, aplicamos uma transformação linear na imagem envenenada com o objetivo de destruir o padrão backdoor. Em seguida, usamos um modelo de difusão pré-treinado para recuperar as informações semânticas ausentes removidas pela transformação. Em particular, projetamos um novo processo reverso usando a imagem transformada para orientar a geração de imagens purificadas de alta fidelidade, que funcionam em configurações de disparo zero. Avaliamos nossa estrutura ZIP em vários conjuntos de dados com diferentes tipos de ataques. Resultados experimentais demonstram a superioridade de nossa estrutura ZIP em comparação com linhas de base de defesa backdoor de última geração. Acreditamos que nossos resultados fornecerão informações valiosas para futuros métodos de defesa para modelos de caixa preta. Resultados experimentais demonstram a superioridade de nossa estrutura ZIP em comparação com linhas de base de defesa backdoor de última geração. Acreditamos que nossos resultados fornecerão informações valiosas para futuros métodos de defesa para modelos de caixa preta. Resultados experimentais demonstram a superioridade de nossa estrutura ZIP em comparação com linhas de base de defesa backdoor de última geração. Acreditamos que nossos resultados fornecerão informações valiosas para futuros métodos de defesa para modelos de caixa preta.



A3FL: Ataques backdoor adaptativos adversamente à aprendizagem federada
https://neurips.cc/virtual/2023/poster/71628
Resumo:
O aprendizado federado (FL) é um paradigma de aprendizado de máquina distribuído que permite que vários clientes treinem de forma colaborativa um modelo global sem compartilhar dados de treinamento locais. Devido à sua natureza distribuída, muitos estudos mostraram que é vulnerável a ataques backdoor. No entanto, os estudos existentes muitas vezes usam gatilhos backdoor fixos e predeterminados ou os otimizam com base apenas em dados e modelos locais, sem considerar a dinâmica global de treinamento. Isso resulta em eficácia de ataque abaixo do ideal e menos persistente, ou seja, eles têm taxas de sucesso de ataque mais baixas quando os orçamentos de ataque são limitados e as taxas de sucesso de ataque diminuem rapidamente se o invasor não puder mais executá-lo. Para resolver essas limitações, propomos o A3FL, um novo ataque backdoor que adapta adversamente o gatilho backdoor para torná-lo menos provável de ser removido dinamicamente pelo treinamento global. Nossa principal intuição é que a diferença entre os modelos globais e locais em FL torna os gatilhos de otimização local significativamente menos eficazes quando transferidos para o modelo global. Resolvemos este problema otimizando os gatilhos, mesmo no pior caso, o modelo global é treinado para ignorar diretamente os gatilhos. Extensos experimentos são conduzidos em 12 defesas existentes em conjuntos de dados de referência para avaliar de forma abrangente a eficácia do nosso A3FL.
Federated Learning (FL) é um paradigma de aprendizado de máquina distribuído que permite que vários clientes treinem um modelo global de forma colaborativa sem compartilhar seus dados de treinamento locais. Devido à sua natureza distribuída, muitos estudos mostraram que é vulnerável a ataques backdoor. No entanto, os estudos existentes geralmente usavam um gatilho de backdoor fixo e predeterminado ou o otimizavam com base apenas nos dados e no modelo local, sem considerar a dinâmica global de treinamento. Isso leva a uma eficácia de ataque abaixo do ideal e menos durável, ou seja, a taxa de sucesso do ataque é baixa quando o orçamento de ataque é limitado e diminui rapidamente se o invasor não puder mais realizar ataques. Para resolver essas limitações, propomos A3FL, um novo ataque backdoor que adapta adversamente o gatilho backdoor para torná-lo menos provável de ser removido pela dinâmica global de treinamento. Nossa principal intuição é que a diferença entre o modelo global e o modelo local em FL torna o gatilho otimizado local muito menos eficaz quando transferido para o modelo global. Resolvemos isso otimizando o gatilho para sobreviver até mesmo ao pior cenário, onde o modelo global foi treinado para desaprender diretamente o gatilho. Extensos experimentos em conjuntos de dados de referência são conduzidos para doze defesas existentes para avaliar de forma abrangente a eficácia do nosso A3FL. Resolvemos isso otimizando o gatilho para sobreviver até mesmo ao pior cenário, onde o modelo global foi treinado para desaprender diretamente o gatilho. Extensos experimentos em conjuntos de dados de referência são conduzidos para doze defesas existentes para avaliar de forma abrangente a eficácia do nosso A3FL. Resolvemos isso otimizando o gatilho para sobreviver até mesmo ao pior cenário, onde o modelo global foi treinado para desaprender diretamente o gatilho. Extensos experimentos em conjuntos de dados de referência são conduzidos para doze defesas existentes para avaliar de forma abrangente a eficácia do nosso A3FL.
Definindo a armadilha: capturando e derrotando ameaças backdoor em PLMs por meio de Honeypots
https://neurips.cc/virtual/2023/poster/72945
Resumo:
No campo do processamento de linguagem natural, os métodos populares incluem o ajuste fino de modelos de linguagem pré-treinados (PLM) usando amostras locais. Uma pesquisa recente expôs a suscetibilidade do PLM a ataques backdoor, onde um adversário pode incorporar um comportamento preditivo malicioso manipulando algumas amostras de treinamento. Neste estudo, pretendemos desenvolver um procedimento de ajuste resistente a backdoor que produza modelos livres de backdoor, independentemente de o conjunto de dados de ajuste fino conter amostras envenenadas ou não. Para tanto, propomos e integramos um módulo honeypot no PLM original, que é projetado especificamente para absorver informações de backdoor. Nosso projeto é baseado na observação de que as representações da camada inferior no PLM possuem recursos de backdoor suficientes, enquanto carregam informações mínimas sobre a tarefa original. Portanto, podemos penalizar as informações obtidas pelo módulo honeypot para suprimir a criação de backdoors durante o ajuste fino da rede tronco. Experimentos abrangentes em conjuntos de dados de referência confirmam a eficácia e a robustez da nossa estratégia de defesa. Notavelmente, estes resultados mostram taxas de sucesso de ataque significativamente reduzidas em comparação com métodos de última geração anteriores, variando de 10% a 40%.
No campo do processamento de linguagem natural, a abordagem predominante envolve o ajuste fino de modelos de linguagem pré-treinados (PLMs) usando amostras locais. Uma pesquisa recente expôs a suscetibilidade dos PLMs a ataques backdoor, nos quais os adversários podem incorporar comportamentos de previsão maliciosos manipulando algumas amostras de treinamento. Neste estudo, nosso objetivo é desenvolver um procedimento de ajuste resistente a backdoor que produza um modelo livre de backdoor, independentemente de o conjunto de dados de ajuste fino conter amostras envenenadas. Para este fim, propomos e integramos um \emph{módulo honeypot} no PLM original, projetado especificamente para absorver exclusivamente informações de backdoor. Nosso projeto é motivado pela observação de que as representações da camada inferior em PLMs carregam recursos de backdoor suficientes, enquanto carregam informações mínimas sobre as tarefas originais. Consequentemente, podemos impor penalidades às informações adquiridas pelo módulo honeypot para inibir a criação de backdoor durante o processo de ajuste fino da rede tronco. Experimentos abrangentes conduzidos em conjuntos de dados de referência comprovam a eficácia e a robustez da nossa estratégia defensiva. Notavelmente, esses resultados indicam uma redução substancial na taxa de sucesso do ataque, variando de 10\% a 40\% quando comparado aos métodos anteriores do estado da arte.
IBA: Rumo a ataques backdoor irreversíveis na aprendizagem federada
https://neurips.cc/virtual/2023/poster/71079
Artigo: https://arxiv.org/abs/2303.02213
Resumo:
O aprendizado federado (FL) é um método de aprendizado distribuído que permite que modelos de aprendizado de máquina sejam treinados em dados descentralizados sem comprometer dados pessoais e potencialmente confidenciais de dispositivos finais. No entanto, a natureza distribuída e os dados não investigados introduzem intuitivamente novas vulnerabilidades de segurança, incluindo ataques backdoor. Nesse caso, o adversário implanta uma função backdoor no modelo global durante o treinamento, que pode ser ativada para causar o mau comportamento desejado em qualquer entrada com um padrão adversário específico. Apesar do seu notável sucesso em desencadear e distorcer o comportamento do modelo, os ataques backdoor anteriores na FL muitas vezes tinham suposições irrealistas, imperceptibilidade limitada e persistência. Especificamente, o adversário precisa controlar uma parcela suficientemente grande de clientes ou compreender a distribuição de dados de outros clientes honestos. Em muitos casos, os gatilhos inseridos são muitas vezes visualmente óbvios, e o efeito backdoor é rapidamente diluído se o oponente for removido do processo de treinamento. Para resolver essas limitações, propomos uma nova estrutura de ataque backdoor em FL que aprende em conjunto os gatilhos visuais furtivos ideais e, em seguida, incorpora gradualmente o backdoor no modelo global. Essa abordagem permite que adversários realizem ataques backdoor que podem escapar da inspeção humana e de máquinas. Além disso, melhoramos a eficiência e a persistência do ataque proposto, envenenando seletivamente os parâmetros do modelo que têm menos probabilidade de serem atualizados pelo processo de aprendizagem da tarefa principal e limitando as atualizações do modelo envenenado às proximidades do modelo global. Finalmente, avaliamos a estrutura de ataque proposta em vários conjuntos de dados de referência, incluindo MNIST, CIFAR10 e Tiny ImageNet, e alcançamos uma alta taxa de sucesso ao contornar as defesas de backdoor existentes, em comparação com outros ataques de backdoor. Um efeito de backdoor mais duradouro é alcançado. No geral, nossa estrutura fornece um método mais eficaz, secreto e persistente para ataques backdoor na FL.
O aprendizado federado (FL) é uma abordagem de aprendizado distribuído que permite que modelos de aprendizado de máquina sejam treinados em dados descentralizados sem comprometer os dados pessoais potencialmente confidenciais dos dispositivos finais. No entanto, a natureza distribuída e os dados não investigados introduzem intuitivamente novas vulnerabilidades de segurança, incluindo ataques backdoor. Nesse cenário, um adversário implanta funcionalidade de backdoor no modelo global durante o treinamento, que pode ser ativada para causar os maus comportamentos desejados para qualquer entrada com um padrão adversário específico. Apesar de ter um sucesso notável em desencadear e distorcer o comportamento do modelo, ataques backdoor anteriores em FL muitas vezes possuem suposições impraticáveis, imperceptibilidade e durabilidade limitadas. Especificamente, o adversário precisa controlar uma fração suficientemente grande de clientes ou conhecer a distribuição de dados de outros clientes honestos. Em muitos casos, o gatilho inserido é muitas vezes visualmente aparente, e o efeito backdoor é rapidamente diluído se o adversário for removido do processo de treinamento. Para resolver essas limitações, propomos uma nova estrutura de ataque backdoor em FL que aprende em conjunto o gatilho ideal e visualmente furtivo e, em seguida, implanta gradualmente o backdoor em um modelo global. Essa abordagem permite que o adversário execute um ataque backdoor que pode escapar de inspeções humanas e de máquinas. Adicionalmente, aumentamos a eficiência e durabilidade do ataque proposto envenenando seletivamente os parâmetros do modelo que são menos prováveis atualizados pelo processo de aprendizagem da tarefa principal e restringindo a atualização do modelo envenenado à vizinhança do modelo global.Finalmente, avaliamos a estrutura de ataque proposta em vários conjuntos de dados de referência, incluindo MNIST, CIFAR10 e Tiny-ImageNet, e alcançou altas taxas de sucesso ao mesmo tempo em que contornava as defesas de backdoor existentes e alcançava um efeito de backdoor mais durável em comparação com outros ataques de backdoor. No geral, nossa estrutura oferece uma abordagem mais eficaz, furtiva e durável para ataques backdoor na FL. e alcançou altas taxas de sucesso ao mesmo tempo em que contornava as defesas de backdoor existentes e alcançava um efeito de backdoor mais durável em comparação com outros ataques de backdoor. No geral, nossa estrutura oferece uma abordagem mais eficaz, furtiva e durável para ataques backdoor na FL. e alcançou altas taxas de sucesso ao mesmo tempo em que contornava as defesas de backdoor existentes e alcançava um efeito de backdoor mais durável em comparação com outros ataques de backdoor. No geral, nossa estrutura oferece uma abordagem mais eficaz, furtiva e durável para ataques backdoor na FL.




CBD: um detector de backdoor certificado com base na probabilidade dominante local
https://neurips.cc/virtual/2023/poster/72180
Resumo:
Os ataques backdoor são uma ameaça comum às redes neurais profundas e, durante os testes, as amostras incorporadas com gatilhos backdoor serão classificadas incorretamente em classes de alvo adversários pelo modelo backdoor. Neste artigo, apresentamos o primeiro detector backdoor certificado (CBD) baseado em um novo esquema de predição conformal ajustável usando uma estatística chamada "probabilidade de dominância local". Para qualquer classificador a ser examinado, não apenas fornecemos inferências de detecção, mas também derivamos (para o mesmo domínio de classificação) as condições sob as quais um ataque é garantido como detectável, bem como um limite superior probabilístico na taxa de falsos positivos. Nossos resultados teóricos mostram que os flip-flops são mais resilientes ao ruído do tempo de teste e que ataques com amplitudes de perturbação menores têm maior probabilidade de serem detectados com segurança. Além disso, conduzimos extensos experimentos em quatro conjuntos de dados de benchmark com diferentes tipos de backdoor, como BadNet, CB e Blend. Empiricamente, a precisão da detecção de CBD é comparável, ou até superior, aos detectores de última geração que não podem fornecer certificação de detecção. Vale a pena notar que para ataques backdoor com gatilhos de perturbação aleatórios limitados por $\ell_2\leq0.75$, a taxa de sucesso do ataque excede 90%, e o CBD alcança melhores resultados em quatro conjuntos de dados de referência: GTSRB, SVHN, CIFAR-10 e As taxas de verdadeiros positivos de autenticação no TinyImageNet são 98%, 84%, 98% e 40%, respectivamente, e a taxa de falsos positivos é baixa.
O ataque backdoor é uma ameaça comum às redes neurais profundas, onde amostras incorporadas com um gatilho backdoor serão classificadas incorretamente para uma classe alvo adversária por um modelo backdoor durante o teste. Neste artigo, apresentamos o primeiro detector backdoor certificado (CBD), que é com base em um novo esquema de previsão conforme ajustável usando uma estatística proposta chamada *probabilidade dominante local*. Para qualquer classificador a ser inspecionado, não apenas fornecemos uma inferência de detecção, mas também derivamos (para o mesmo domínio de classificação) a condição sob a qual o os ataques são garantidos como detectáveis, bem como um limite superior probabilístico para a taxa de falsos positivos. Nossos resultados teóricos mostram que ataques com gatilhos mais resilientes a ruídos de tempo de teste e menores em magnitude de perturbação têm maior probabilidade de serem detectados com garantias. ,conduzimos extensos experimentos em quatro conjuntos de dados de referência para vários tipos de backdoor, como BadNet, CB e Blend. Empiricamente, o CBD atinge uma precisão de detecção comparável ou até maior do que os detectores de última geração, que não podem fornecer certificação de detecção. para ataques backdoor com gatilhos de perturbação aleatórios limitados por $\ell_2\leq0.75$ que atingem mais de 90\% de taxa de sucesso de ataque, o CBD atinge 98\%, 84\%, 98\% e 40\% de taxas de verdadeiro positivo certificado nos quatro conjuntos de dados de benchmark GTSRB, SVHN, CIFAR-10 e TinyImageNet, respectivamente, com baixas taxas de falsos positivos.Notavelmente, para ataques backdoor com gatilhos de perturbação aleatórios limitados por $\ell_2\leq0.75$ que atingem mais de 90\% de taxa de sucesso de ataque, o CBD atinge 98\%, 84\%, 98\% e 40\% de certificado verdadeiro taxas positivas nos quatro conjuntos de dados de referência GTSRB, SVHN, CIFAR-10 e TinyImageNet, respectivamente, com baixas taxas de falsos positivos.Notavelmente, para ataques de backdoor com gatilhos de perturbação aleatórios limitados por $\ell_2\leq0.75$ que atingem mais de 90\% de taxa de sucesso de ataque, o CBD atinge 98\%, 84\%, 98\% e 40\% de certificado verdadeiro taxas positivas nos quatro conjuntos de dados de referência GTSRB, SVHN, CIFAR-10 e TinyImageNet, respectivamente, com baixas taxas de falsos positivos.
Defendendo modelos de linguagem pré-treinados como aprendizes rápidos contra ataques de backdoor
https://neurips.cc/virtual/2023/poster/72193
Artigo: https://arxiv.org/abs/2309.13256
Código: https://github.com/zhaohan-xi/PLM-prompt-defense
Resumo:
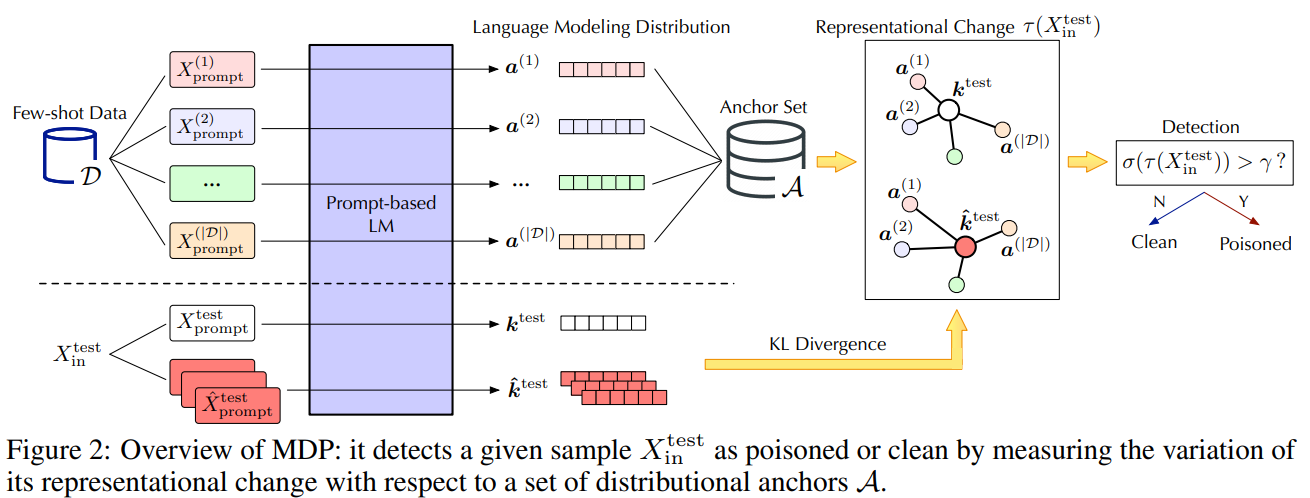
Modelos de linguagem pré-treinados (PLMs) mostram desempenho notável como alunos que atiram em minorias. No entanto, neste caso, os seus riscos de segurança permanecem em grande parte inexplorados. Neste trabalho, conduzimos um estudo piloto mostrando que o PLM, como um aprendizado de poucos disparos, é altamente vulnerável a ataques de backdoor e que as capacidades de defesa existentes são insuficientes devido aos desafios únicos dos cenários de poucos disparos. Para enfrentar esses desafios, defendemos o MDP, um novo método de defesa leve, conectável e eficaz para PLMs que são aprendizes de atiradores minoritários. Especificamente, o MDP explora a lacuna entre as sensibilidades de mascaramento de amostras envenenadas e limpas: referindo-se a um número limitado de dados de disparo como âncoras de distribuição, compara a representação de uma determinada amostra sob diferentes mascaramentos e identifica a amostra envenenada como tendo amostras significativamente alteradas. Nossa análise mostra que o MDP cria um dilema interessante para os invasores escolherem entre a eficácia do ataque e a evasão da detecção. A avaliação empírica utilizando conjuntos de dados de referência e ataques representativos valida a eficácia do MDP.
Modelos de linguagem pré-treinados (PLMs) demonstraram desempenho notável como aprendizes de poucas tentativas. No entanto, os seus riscos de segurança sob tais configurações são em grande parte inexplorados. Neste trabalho, conduzimos um estudo piloto mostrando que os PLMs, como aprendizes de poucas tentativas, são altamente vulneráveis a ataques de backdoor, enquanto as defesas existentes são inadequadas devido aos desafios únicos dos cenários de poucas tentativas. Para enfrentar esses desafios, defendemos o MDP, uma nova defesa leve, conectável e eficaz para PLMs como aprendizes de poucas tentativas. Especificamente, o MDP aproveita a lacuna entre a sensibilidade ao mascaramento de amostras envenenadas e limpas: com referência aos dados limitados de poucos disparos como âncoras de distribuição, compara as representações de determinadas amostras sob mascaramento variável e identifica amostras envenenadas como aquelas com variações significativas. Mostramos analiticamente que o MDP cria um dilema interessante para o invasor escolher entre a eficácia do ataque e a evasão da detecção. A avaliação empírica utilizando conjuntos de dados de referência e ataques representativos valida a eficácia do MDP.

Lockdown: Defesa Backdoor para Aprendizagem Federada com Treinamento em Subespaço Isolado
https://neurips.cc/virtual/2023/poster/71476
Código: https://github.com/LockdownAuthor/Lockdown
Resumo:
A aprendizagem federada (FL) é vulnerável a ataques backdoor devido à sua natureza de computação distribuída. As soluções de defesa existentes muitas vezes requerem computação extensiva durante a fase de treinamento ou teste, o que limita sua utilidade em cenários com recursos limitados. Num ambiente de backdoor centralizado, é proposto um método de defesa mais prático, nomeadamente a defesa baseada na poda da rede neural. No entanto, nosso estudo empírico mostra que as soluções tradicionais baseadas em poda sofrem com o efeito \textit{acoplamento tóxico} no FL, o que degrada significativamente o desempenho da defesa. Este artigo propõe um método de treinamento de subespaço isolado, Lockdown, para aliviar o efeito de acoplamento tóxico. O bloqueio segue três procedimentos principais. Primeiro, modifica o protocolo de treinamento isolando subespaços de treinamento para diferentes clientes. Em segundo lugar, ele utiliza aleatoriedade para inicializar subespaços isolados e executa remoção e recuperação de subespaços para isolar subespaços entre clientes maliciosos e benignos. Terceiro, introduz o consenso de quórum para reparar o modelo global, eliminando parâmetros maliciosos/falsos. Os resultados empíricos mostram que, em comparação com os métodos representativos existentes contra ataques backdoor, o Lockdown atinge um desempenho de defesa \textit{superior} e \textit{consistente}. Outro recurso de valor agregado do Lockdown é a eficiência da comunicação e a redução da complexidade do modelo, ambos cruciais para cenários de FL com recursos limitados.
A aprendizagem federada (FL) é vulnerável a ataques backdoor devido à sua natureza de computação distribuída. As soluções de defesa existentes geralmente requerem maior quantidade de computação na fase de treinamento ou de teste, o que limita sua praticidade em cenários de restrição de recursos. Uma defesa mais prática, baseada na poda da rede neural (NN), foi proposta em um ambiente de backdoor centralizado. No entanto, nosso estudo empírico mostra que a solução tradicional baseada em poda sofre efeito \textit{acoplamento venenoso} em FL, o que degrada significativamente o desempenho da defesa. Este artigo apresenta Lockdown, um método de treinamento em subespaço isolado para mitigar o efeito de acoplamento de veneno. O bloqueio segue três procedimentos principais. Primeiro, modifica o protocolo de treinamento isolando os subespaços de treinamento para diferentes clientes. Segundo, ele utiliza aleatoriedade na inicialização de subespaços isolados e executa remoção e recuperação de subespaços para segregar os subespaços entre clientes maliciosos e benignos. Terceiro, introduz o consenso de quórum para curar o modelo global, eliminando parâmetros maliciosos/fictícios. Os resultados empíricos mostram que o Lockdown atinge um desempenho de defesa \textit{superior} e \textit{consistente} em comparação com as abordagens representativas existentes contra ataques backdoor. Outra propriedade de valor agregado do Lockdown é a eficiência da comunicação e a redução da complexidade do modelo, que são críticas para o cenário de FL com restrição de recursos. introduz consenso de quórum para curar o modelo global, eliminando parâmetros maliciosos/fictícios. Os resultados empíricos mostram que o Lockdown atinge um desempenho de defesa \textit{superior} e \textit{consistente} em comparação com as abordagens representativas existentes contra ataques backdoor. Outra propriedade de valor agregado do Lockdown é a eficiência da comunicação e a redução da complexidade do modelo, que são críticas para o cenário de FL com restrição de recursos. introduz consenso de quórum para curar o modelo global, eliminando parâmetros maliciosos/fictícios. Os resultados empíricos mostram que o Lockdown atinge um desempenho de defesa \textit{superior} e \textit{consistente} em comparação com as abordagens representativas existentes contra ataques backdoor. Outra propriedade de valor agregado do Lockdown é a eficiência da comunicação e a redução da complexidade do modelo, que são críticas para o cenário de FL com restrição de recursos.
FedGame: uma defesa teórica dos jogos contra ataques backdoor na aprendizagem federada
https://neurips.cc/virtual/2023/poster/70499
Resumo:
O Federated Learning (FL) implementa um modo de treinamento distribuído onde vários clientes podem treinar em conjunto um modelo global sem compartilhar seus dados locais. No entanto, pesquisas recentes mostram que o aprendizado federado fornece uma superfície adicional para ataques backdoor. Por exemplo, um invasor pode comprometer um subconjunto de clientes, corrompendo assim o modelo global e, assim, prevendo erroneamente os gatilhos de backdoor como entradas para alvos adversários. As defesas de aprendizagem federadas existentes contra ataques backdoor geralmente são baseadas em modelos de invasor $\textit{static}$ para detectar e excluir informações corrompidas em clientes comprometidos. No entanto, tais defesas são insuficientes contra atacantes $\textit{dynamic}$ que ajustam estrategicamente suas táticas de ataque. Para preencher esta lacuna na defesa, modelamos a interação estratégica de estágio único ou múltiplo entre defensores e atacantes dinâmicos em FL como um jogo maximin. Com base no modelo de análise, projetamos um mecanismo de defesa interativo FedGame. Mostramos também que, sob suposições moderadas, o modelo FL global treinado com FedGame sob ataques backdoor está próximo do modelo FL treinado sem ataques. Empiricamente, conduzimos avaliações extensas em conjuntos de dados de referência e comparamos o FedGame com várias linhas de base de última geração. Nossos resultados experimentais mostram que o FedGame pode se defender eficazmente contra invasores estratégicos e alcançar uma robustez significativamente maior do que as linhas de base. Por exemplo, em comparação com seis linhas de base de defesa de última geração sob ataques de escalonamento, a taxa de sucesso de ataque do FedGame no CIFAR10 é reduzida em 82%.
A aprendizagem federada (FL) permite um paradigma de treinamento distribuído, onde vários clientes podem treinar em conjunto um modelo global sem a necessidade de compartilhar seus dados locais. No entanto, estudos recentes mostraram que a aprendizagem federada fornece uma superfície adicional para ataques backdoor. Por exemplo, um invasor pode comprometer um subconjunto de clientes e, assim, corromper o modelo global para prever erroneamente uma entrada com um gatilho de backdoor como alvo adversário. As defesas existentes para aprendizagem federada contra ataques backdoor geralmente detectam e excluem as informações corrompidas dos clientes comprometidos com base em um modelo de invasor $\textit{static}$. Tais defesas, no entanto, não são adequadas contra atacantes $\textit{dinâmicos}$ que adaptam estrategicamente suas estratégias de ataque. Para colmatar esta lacuna na defesa, modelamos interações estratégicas de estágio único ou múltiplo entre o defensor em FL e os atacantes dinâmicos como um jogo minimax. Com base na análise do nosso modelo, projetamos um mecanismo de defesa interativo FedGame. Também provamos que, sob suposições moderadas, o modelo FL global treinado com FedGame sob ataques backdoor é próximo daquele treinado sem ataques. Empiricamente, realizamos avaliações extensas em conjuntos de dados de referência e comparamos o FedGame com várias linhas de base de última geração. Nossos resultados experimentais mostram que o FedGame pode se defender com eficácia contra invasores estratégicos e alcançar uma robustez significativamente maior do que as linhas de base. Por exemplo, o FedGame reduz a taxa de sucesso de ataque em 82\% no CIFAR10 em comparação com seis linhas de base de defesa de última geração sob ataque de escala. Com base na análise do nosso modelo, projetamos um mecanismo de defesa interativo FedGame. Também provamos que, sob suposições moderadas, o modelo FL global treinado com FedGame sob ataques backdoor é próximo daquele treinado sem ataques. Empiricamente, realizamos avaliações extensas em conjuntos de dados de referência e comparamos o FedGame com várias linhas de base de última geração. Nossos resultados experimentais mostram que o FedGame pode se defender com eficácia contra invasores estratégicos e alcançar uma robustez significativamente maior do que as linhas de base. Por exemplo, o FedGame reduz a taxa de sucesso de ataque em 82\% no CIFAR10 em comparação com seis linhas de base de defesa de última geração sob ataque de escala. Com base na análise do nosso modelo, projetamos um mecanismo de defesa interativo FedGame. Também provamos que, sob suposições moderadas, o modelo FL global treinado com FedGame sob ataques backdoor é próximo daquele treinado sem ataques. Empiricamente, realizamos avaliações extensas em conjuntos de dados de referência e comparamos o FedGame com várias linhas de base de última geração. Nossos resultados experimentais mostram que o FedGame pode se defender com eficácia contra invasores estratégicos e alcançar uma robustez significativamente maior do que as linhas de base. Por exemplo, o FedGame reduz a taxa de sucesso de ataque em 82\% no CIFAR10 em comparação com seis linhas de base de defesa de última geração sob ataque de escala. o modelo global de FL treinado com FedGame sob ataques backdoor é próximo daquele treinado sem ataques. Empiricamente, realizamos avaliações extensas em conjuntos de dados de referência e comparamos o FedGame com várias linhas de base de última geração. Nossos resultados experimentais mostram que o FedGame pode se defender com eficácia contra invasores estratégicos e alcançar uma robustez significativamente maior do que as linhas de base. Por exemplo, o FedGame reduz a taxa de sucesso de ataque em 82\% no CIFAR10 em comparação com seis linhas de base de defesa de última geração sob ataque de escala. o modelo global de FL treinado com FedGame sob ataques backdoor é próximo daquele treinado sem ataques. Empiricamente, realizamos avaliações extensas em conjuntos de dados de referência e comparamos o FedGame com várias linhas de base de última geração. Nossos resultados experimentais mostram que o FedGame pode se defender com eficácia contra invasores estratégicos e alcançar uma robustez significativamente maior do que as linhas de base. Por exemplo, o FedGame reduz a taxa de sucesso de ataque em 82\% no CIFAR10 em comparação com seis linhas de base de defesa de última geração sob ataque de escala.
Polarizador Neural: uma defesa leve e eficaz de backdoor por meio de recursos purificadores envenenados
https://neurips.cc/virtual/2023/poster/71467
Artigo: https://arxiv.org/abs/2306.16697
Resumo:
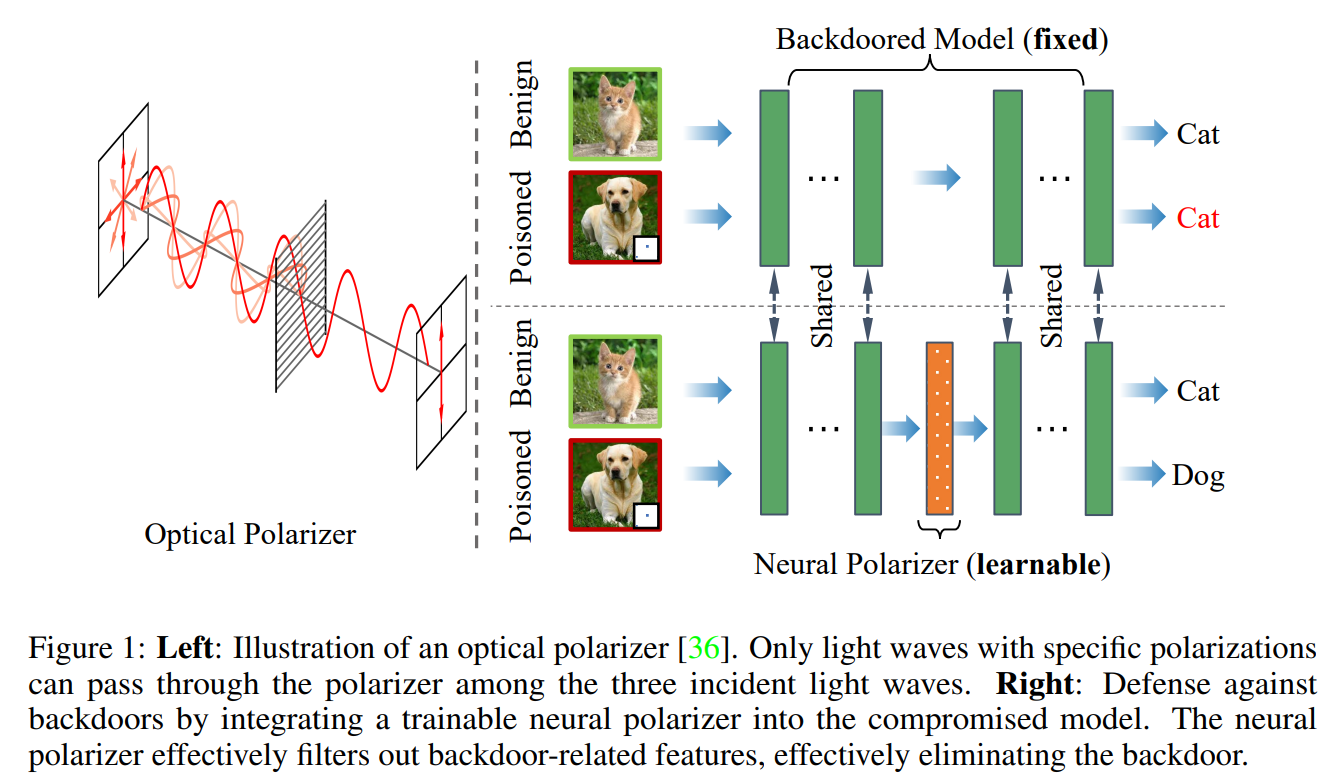
Pesquisas recentes demonstraram a suscetibilidade das redes neurais profundas a ataques backdoor. Dado um modelo backdoor, embora coexistam informações de gatilho e informações benignas, suas previsões para amostras envenenadas com gatilhos serão dominadas por informações de gatilho. Inspirado no mecanismo de polarizadores de luz que podem transmitir ondas de luz com uma polarização específica enquanto filtram ondas de luz com outras polarizações. Propomos um novo método de defesa de backdoor, inserindo um polarizador neural que pode ser aprendido como uma camada intermediária no modelo de backdoor para purificar amostras envenenadas, filtrando informações de gatilho enquanto mantém informações benignas. O polarizador neural é instanciado como uma camada de transformação linear leve que é aprendida resolvendo um problema de otimização de duas camadas cuidadosamente projetado com base em um conjunto de dados limpo e limitado. Comparado com outros métodos de defesa baseados em ajuste fino que muitas vezes ajustam todos os parâmetros do modelo backdoor, o método proposto só precisa aprender uma camada adicional, por isso é mais eficiente e requer menos dados limpos. Extensos experimentos demonstram a eficácia e eficiência de nossa abordagem na eliminação de backdoors em várias arquiteturas e conjuntos de dados de redes neurais, especialmente quando os dados limpos são muito limitados.
Estudos recentes demonstraram a suscetibilidade das redes neurais profundas a ataques backdoor. Dado um modelo backdoor, sua previsão de uma amostra envenenada com gatilho será dominada pelas informações de gatilho, embora coexistam informações de gatilho e informações benignas. Inspirados no mecanismo do polarizador óptico de que um polarizador poderia passar ondas de luz com polarizações específicas enquanto filtra ondas de luz com outras polarizações, propomos um novo método de defesa de backdoor, inserindo um polarizador neural que pode ser aprendido no modelo backdoor como uma camada intermediária, em ordem para purificar a amostra envenenada por meio da filtragem de informações de gatilho, mantendo informações benignas. O polarizador neural é instanciado como uma camada de transformação linear leve, que é aprendido resolvendo um problema de otimização de dois níveis bem projetado, com base em um conjunto de dados limpo e limitado. Em comparação com outros métodos de defesa baseados em ajuste fino que muitas vezes ajustam todos os parâmetros do modelo backdoor, o método proposto só precisa aprender uma camada adicional, de modo que seja mais eficiente e exija menos dados limpos. Extensos experimentos demonstram a eficácia e eficiência do nosso método na remoção de backdoors em várias arquiteturas e conjuntos de dados de redes neurais, especialmente no caso de dados limpos muito limitados.

Uma estrutura unificada para defesas de backdoor em estágio de inferência
https://neurips.cc/virtual/2023/poster/72827
Uma estrutura unificada para defesas de backdoor em estágio de inferência (jding.org)
Resumo:
Os ataques backdoor envolvem a inserção de amostras envenenadas durante o treinamento, fazendo com que o modelo contenha um backdoor oculto que pode desencadear comportamentos específicos sem afetar o desempenho de amostras normais. Esses ataques são difíceis de detectar porque o modelo backdoor parece normal até ser ativado pelo gatilho do backdoor, tornando-os particularmente furtivos. Neste estudo, projetamos uma estrutura unificada de detecção de estágio de inferência para defesa contra ataques backdoor. Primeiro formulamos rigorosamente o problema de detecção de backdoor no estágio de inferência, incluindo vários métodos existentes, e discutimos alguns desafios e limitações. Propomos então uma estrutura com garantias comprováveis sobre a taxa de falsos positivos, ou a probabilidade de classificação incorreta de uma amostra limpa. Além disso, derivamos as regras de detecção mais poderosas para maximizar o poder de detecção, ou seja, a taxa de identificação precisa de amostras de backdoor, dada a taxa de falsos positivos em cenários de aprendizagem clássicos. Com base em regras teóricas de detecção ótima, propomos uma abordagem prática e eficiente para aplicações do mundo real de representações latentes baseadas em backdoor deep nets. Avaliamos extensivamente nosso método em 12 ataques backdoor diferentes usando conjuntos de dados de benchmark de visão computacional (CV) e processamento de linguagem natural (PNL). Os resultados experimentais são consistentes com nossos resultados teóricos. Superamos significativamente os métodos de última geração, por exemplo, o AUROC avalia uma melhoria de 300% nas capacidades de detecção em comparação com as defesas de última geração contra ataques backdoor adaptativos avançados.
Os ataques backdoor envolvem a inserção de amostras envenenadas durante o treinamento, resultando em um modelo contendo um backdoor oculto que pode desencadear comportamentos específicos sem afetar o desempenho em amostras normais. Esses ataques são difíceis de detectar, pois o modelo backdoor parece normal até ser ativado pelo gatilho backdoor, tornando-os particularmente furtivos. Neste estudo, desenvolvemos uma estrutura unificada de detecção de estágio de inferência para defesa contra ataques backdoor. Primeiro formulamos rigorosamente o problema de detecção de backdoor no estágio de inferência, abrangendo vários métodos existentes, e discutimos vários desafios e limitações. Propomos então uma estrutura com garantias comprováveis sobre a taxa de falsos positivos ou a probabilidade de classificação incorreta de uma amostra limpa. Além disso, derivamos a regra de detecção mais poderosa para maximizar o poder de detecção, nomeadamente a taxa de identificação precisa de uma amostra backdoor, dada uma taxa de falsos positivos em cenários de aprendizagem clássicos. Com base na regra de detecção teoricamente ideal, sugerimos uma abordagem prática e eficaz para aplicações do mundo real com base nas representações latentes de redes profundas backdoor. Avaliamos extensivamente nosso método em 12 ataques backdoor diferentes usando conjuntos de dados de benchmark de visão computacional (CV) e processamento de linguagem natural (PNL). As descobertas experimentais estão alinhadas com nossos resultados teóricos. Superamos significativamente os métodos de última geração, por exemplo, até 300% de melhoria no poder de detecção avaliado pela AUCROC, em relação à defesa de última geração contra ataques backdoor adaptativos avançados. Com base na regra de detecção teoricamente ideal, sugerimos uma abordagem prática e eficaz para aplicações do mundo real com base nas representações latentes de redes profundas backdoor. Avaliamos extensivamente nosso método em 12 ataques backdoor diferentes usando conjuntos de dados de benchmark de visão computacional (CV) e processamento de linguagem natural (PNL). As descobertas experimentais estão alinhadas com nossos resultados teóricos. Superamos significativamente os métodos de última geração, por exemplo, até 300% de melhoria no poder de detecção avaliado pela AUCROC, em relação à defesa de última geração contra ataques backdoor adaptativos avançados. Com base na regra de detecção teoricamente ideal, sugerimos uma abordagem prática e eficaz para aplicações do mundo real com base nas representações latentes de redes profundas backdoor. Avaliamos extensivamente nosso método em 12 ataques backdoor diferentes usando conjuntos de dados de benchmark de visão computacional (CV) e processamento de linguagem natural (PNL). As descobertas experimentais estão alinhadas com nossos resultados teóricos. Superamos significativamente os métodos de última geração, por exemplo, até 300% de melhoria no poder de detecção avaliado pela AUCROC, em relação à defesa de última geração contra ataques backdoor adaptativos avançados. Avaliamos extensivamente nosso método em 12 ataques backdoor diferentes usando conjuntos de dados de referência de visão computacional (CV) e processamento de linguagem natural (PNL). As descobertas experimentais estão alinhadas com nossos resultados teóricos. Superamos significativamente os métodos de última geração, por exemplo, até 300% de melhoria no poder de detecção avaliado pela AUCROC, em relação à defesa de última geração contra ataques backdoor adaptativos avançados. Avaliamos extensivamente nosso método em 12 ataques backdoor diferentes usando conjuntos de dados de referência de visão computacional (CV) e processamento de linguagem natural (PNL). As descobertas experimentais estão alinhadas com nossos resultados teóricos. Superamos significativamente os métodos de última geração, por exemplo, até 300% de melhoria no poder de detecção avaliado pela AUCROC, em relação à defesa de última geração contra ataques backdoor adaptativos avançados.