Novos modelos além do SWin e CSWin Transformer

Endereço do código: https://github.com/OliverRensu/SG-Former
Endereço do artigo: https://arxiv.org/pdf/2308.12216.pdf
Embora o ViT seja bem-sucedido em várias tarefas de visão, seu custo computacional aumenta quadraticamente com o comprimento da sequência de tokens, o que limita bastante seu desempenho ao processar grandes mapas de características. Para aliviar os custos computacionais, estudos anteriores basearam-se na autoatenção refinada restrita a pequenas áreas locais ou na autoatenção global, mas com comprimentos de sequência mais curtos, resultando em problemas de granulação grossa.
Transformador autoguiado (SG-Former) para obter autoatenção global eficaz com granulação fina adaptativa. A ideia central deste método é utilizar um mapa de saliência estimado pela Autoatenção em escala mista e autoevoluído durante o processo de treinamento para redistribuir os tokens de acordo com a importância de cada região. Intuitivamente, mais tokens são atribuídos a regiões salientes para obter uma atenção mais refinada, enquanto menos tokens são atribuídos a regiões secundárias em troca de eficiência e campos de consciência global. O SG-Former supera os modelos de última geração em tarefas de classificação, detecção e segmentação.
Para calcular a autoatenção em recursos de alta resolução, alguns métodos propõem limitar a região de autoatenção a uma janela local em vez de todo o mapa de recursos (ou seja, autoatenção local refinada ). Por exemplo, o Swin Transformer foi projetado com atenção à janela, enquanto o CSWin foi projetado com atenção ao formato cruzado. Portanto, esses métodos sacrificam a capacidade de modelar informações globais em cada camada de Autoatenção. Outro fluxo de métodos visa agregar tokens em todo o mapa de recursos de valor-chave para reduzir o comprimento da sequência global (ou seja, atenção global de granulação grossa ). Por exemplo, o Pyramid Vision Transformer (PVT) usa núcleos grandes com grandes avanços para agregar tokens uniformemente em todo o mapa de recursos, resultando em informações aproximadas e uniformes em todo o mapa de recursos.
O Transformador Autoguiado (SG-Former) neste artigo alcança atenção global adaptativa e refinada por meio de um design de Autoatenção em evolução. A ideia central do SG-Former é preservar as dependências de longo alcance em todo o mapa de recursos enquanto redistribui os tokens de acordo com a importância das regiões da imagem.
Ou seja, o modelo alocará mais Tokens para as áreas salientes para que cada Token possa interagir com as áreas salientes com granularidade fina, enquanto alocará menos Tokens para áreas secundárias para maior eficiência. O SG-Former calcula a autoatenção com um campo perceptivo global eficiente enquanto se concentra de forma adaptativa em informações refinadas em áreas importantes.
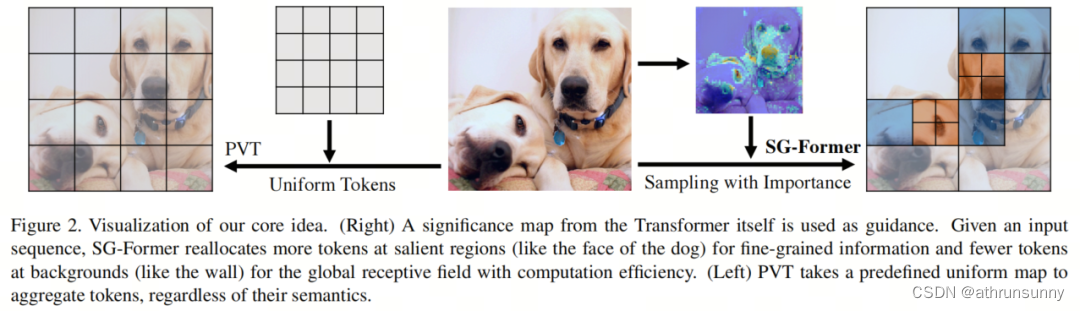
Conforme mostrado na Figura 2, o SG-Former redistribui Tokens com base no mapa de atenção obtido dele mesmo, como alocar mais Tokens em áreas salientes, como cães, e alocar menos Tokens em áreas secundárias, como paredes. O PVT adota uma estratégia predefinida para agregar tokens uniformemente.
Especificamente, o token de consulta é retido, mas o token de chave e valor são reatribuídos para obter autoatenção global eficiente. A importância das regiões da imagem, na forma de um mapa de pontuação, é estimada pela própria Autoatenção em escala mista e é posteriormente utilizada para orientar a reatribuição de tokens.
Ou seja, dada uma imagem de entrada, a reatribuição de token é feita por meio do Autoguiado, o que significa que cada imagem passa por uma reatribuição de token única que se aplica apenas a ela mesma. Portanto, os tokens redistribuídos são menos afetados pelos antecedentes humanos.
Além disso, este Autoguiado continuará a evoluir com previsões de mapas de atenção cada vez mais precisas durante o treinamento. O mapa de atenção afeta muito a eficácia da realocação, portanto, é proposta uma autoatenção em escala mista que possui várias informações de granularidade na mesma camada e com o mesmo custo do Swin. A autoatenção em escala mista obtém várias informações de granularidade agrupando cabeças e diversificando cada grupo para diferentes granularidades de atenção. A autoatenção em escala mista também fornece informações em escala mista para todo o Transformer.
Este artigo tem as seguintes contribuições:
1. Informações refinadas locais e globais são extraídas por meio de informações unificadas em escala mista dentro de uma camada de autoatenção. Previsão de mapas de atenção para identificar a importância regional com informações unificadas em escala híbrida local-global.
2. Com o mapa de atenção, você pode simular a atenção autoguiada, localizar automaticamente áreas salientes e permitir que as áreas salientes extraiam informações refinadas, ao mesmo tempo que permite que as áreas secundárias extraiam informações refinadas para reduzir custos computacionais.
3. Em comparação com os modelos de última geração, há uma melhoria significativa nas tarefas de classificação, detecção de alvos e segmentação.
A seguir está uma explicação do artigo com base no código. A parte do código é decomposta com base na configuração do sgformer_s.
A configuração específica dos parâmetros pode ser vista na tabela abaixo

1.1、Visão Geral
O processo geral do SG-Former é mostrado na Figura 3. O SG-Former compartilha a mesma camada de incorporação de patch e arquitetura de pirâmide de quarta ordem dos modelos anteriores da CNN e do Transformer.

Primeiro, a imagem é reduzida por um fator de 4 por meio de uma camada de incorporação de patch no nível de entrada. Há uma camada de redução da resolução de taxa 2x entre os dois estágios. Portanto,
o tamanho do mapa de características no estágio é
. Com exceção do último estágio, cada estágio possui
um Bloco Transformador, que é composto por dois tipos de repetições de blocos:
-
Bloco transformador de escala mista
-
Bloco transformador autoguiado。
A autoatenção em escala mista extrai objetos de escala mista e informações de multigranularidade para orientar a importância regional. Modelo de autoatenção autoguiada com informações globais, mantendo a granularidade das áreas salientes de acordo com as informações de importância do bloco transformador de escala mista;
Vamos primeiro dar uma olhada na estrutura geral do código do SG Former. Algumas operações de inicialização de parâmetros são omitidas no exemplo de código.
class SGFormer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4, linear=False):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
self.num_patches = img_size//4
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
if i == 0:
patch_embed = Head(embed_dims[0]) #
else:
patch_embed = PatchMerging(dim=embed_dims[i - 1],
out_dim=embed_dims[i])
block = nn.ModuleList([Block(
dim=embed_dims[i], mask=True if (j%2==1 and i<num_stages-1) else False, num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j], norm_layer=norm_layer,
sr_ratio=sr_ratios[i], linear=linear)
for j in range(depths[i])])
norm = norm_layer(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
self.pos_embed = nn.Parameter(torch.zeros(1, self.num_patches*self.num_patches, embed_dims[0])) # fixed sin-cos embedding
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def forward_features(self, x):
B = x.shape[0]
mask=None
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x) # [N 3136 64] #[N 784 128] #[N 196 256] #[N 49 512]
if i==0:
x+=self.pos_embed # [1 3136 64]
for blk in block:
x, mask = blk(x, H, W, mask)
x = norm(x) # [N 3136 64] [N 784 128] [N 196 256] [N 49 512]
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() # [N 64 56 56] [N 128 28 28] [N 256 14 14]
return x.mean(dim=1)
def forward(self, x):
x = self.forward_features(x) # entry
x = self.head(x)
return xA imagem primeiro passa pela incorporação do Patch (cabeçalho no código)
class Head(nn.Module):
def __init__(self, n):
super(Head, self).__init__()
self.conv = nn.Sequential(
Conv2d_BN(3, n, 3, 2, 1),
nn.GELU(),
Conv2d_BN(n, n, 3, 1, 1),
nn.GELU(),
Conv2d_BN(n, n, 3, 2, 1),
)
self.norm = nn.LayerNorm(n)
self.apply(self._init_weights)
def forward(self, x):
x = self.conv(x)
_, _, H, W = x.shape # [N 64 56 56]
x = x.flatten(2)#.transpose(1, 2) # [N 64 3136]
x = x.transpose(1, 2)
x = self.norm(x) # [N 3136 64]
return x, H,WNa verdade, após três convoluções 2d mais BN, duas funções de ativação GELU são inseridas no meio. As duas convoluções 2d sequenciais têm um passo de 2 para redução da resolução. A entrada X=[N,3.224.224] é reduzida em 4 vezes. [N ,64,56,56] e, em seguida, execute a conversão de dimensão e adicione LayerNorm.
A primeira camada adicionará incorporação pos (a forma é [1,3136,64]) à saída da incorporação de Patch.
A incorporação da amostragem intermediária é concluída pelo PatchMerging:
class PatchMerging(nn.Module):
def __init__(self, dim, out_dim):
super().__init__()
self.dim = dim
self.out_dim = out_dim
self.act = nn.GELU()
self.conv1 = Conv2d_BN(dim, out_dim, 1, 1, 0)
self.conv2 = Conv2d_BN(out_dim, out_dim, 3, 2, 1, groups=out_dim)
self.conv3 = Conv2d_BN(out_dim, out_dim, 1, 1, 0)
def forward(self, x):
# x B C H W
x = self.conv1(x)
x = self.act(x)
x = self.conv2(x)
x = self.act(x)
x = self.conv3(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
return x, H, WServe principalmente uma função de redução da resolução.
Em seguida vem o Transformer Block, módulo chave deste artigo, que consiste em dois tipos de repetições de bloco:
-
Bloco transformador de escala mista
-
Bloco transformador autoguiado。
Esses dois módulos, incluindo o Transformer Block básico, são construídos pela função Block
class Block(nn.Module):
def __init__(self, dim, mask, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1, linear=False):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, mask,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio, linear=linear)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.apply(self._init_weights)
def forward(self, x, H, W, mask):
x_, mask = self.attn(self.norm1(x), H, W, mask) # x[N 3136 64] mask[[N 3136],[N 3136]]
x = x + self.drop_path(x_)
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x, maskA coisa mais importante na função Block é Atenção
1.2、 Bloco Transformador
Com dois mecanismos de autoatenção, dois tipos de blocos transformadores são projetados de acordo. Esses dois blocos transformadores diferem apenas na camada de atenção, enquanto todo o resto permanece o mesmo:

Conforme mostrado na Figura 3, os primeiros 3 estágios são customizados usando nossa proposta de escala híbrida ou Bloco Transformador Autoguiado, enquanto para o último estágio é utilizado um Bloco Transformador padrão, que é baseado no Transformador anterior. Observe que o número de blocos transformadores nos primeiros 3 estágios (ou seja, N1, N2 e N3) é par, enquanto o último estágio (ou seja, N4) pode ser par ou ímpar.
1.3、Atenção em escala híbrida
A atenção em escala mista serve a dois propósitos:
-
Extraia informações globais e refinadas em escalas mistas sem mais custo computacional do que a atenção da janela no Swin Transformer
-
Dê importância à atenção autoguiada

Conforme mostrado na Figura 5, o recurso de entrada X é projetado para Consulta (Q), Chave (K) e Valor (V). Então, a Autoatenção Multi-Head usa H cabeças independentes. Normalmente, esses cabeçotes independentes H realizam operações dentro da mesma área local e, portanto, não possuem diversidade de cabeçotes.
Em contraste, este artigo divide H Heads uniformemente em grupos h e injeta a atenção de escalas mistas e campos multi-receptivos nesses grupos H. Há uma cabeça em cada grupo (do ponto de vista do código, ela é dividida em metade A cabeça presta atenção global e metade da cabeça presta atenção local). Na décima cabeça pertencente ao ésimo
grupo
, use a escala
(onde
) para mesclar cada Token em {K, V}
em um Token. Em seguida, divida {Q,K,V} em janelas (o mesmo que swin). O tamanho da janela de {K,V} é definido como M e permanece constante em todos os grupos. Para alinhar os tamanhos das janelas de {Q} e {K,V} com os tokens em {K,V}, o tamanho da janela de {Q} é selecionado para ser múltiplos do tamanho da janela de {K,V }
:
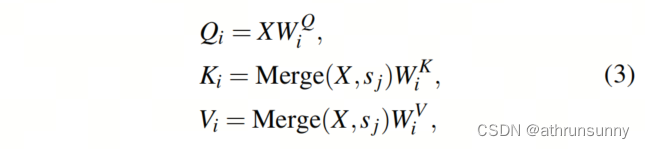
O que significa mesclar cada
Token em um Token, o que é
obtido por meio de convolução passo a passo. O caso especial é que quando
é igual a 1, a fusão de tokens não é realizada e {Q, K, V} tem a janela do mesmo tamanho.
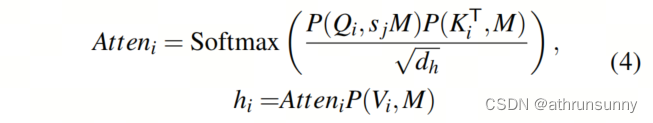
onde representa
a divisão da janela com o tamanho da janela.
é um mapa de atenção. Há um caso especial:
igual a
, nenhuma segmentação de janela é necessária, todos os tokens em {K, V} são seguidos por {Q}, conseguindo assim a extração global de informações.
A importância de um token é considerada como a soma dos produtos de todos os tokens e do token atual:
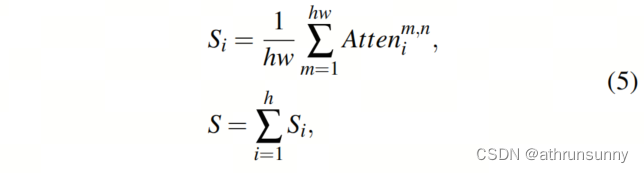
onde S é o mapa de atenção final obtido pela soma de todos , que é usado para orientação em escala mista para fornecer informações globais e refinadas. Correspondente a esta parte do código
# global
q1 = self.q1(x).reshape(B, N, self.num_heads//2, C // self.num_heads).permute(0, 2, 1, 3) # [N 1 3136 32] # [N 2 784 32] # [N 4 196 32]
x_ = x.permute(0, 2, 1).reshape(B, C, H, W) # [N 64 56 56] # [N 128 28 28] # [N 256 14 14]
x_1 = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1) # [N 49 64] sr --> conv2d(64, 64) # [N 49 128] sr --> conv2d(128, 128) # [N 49 256] sr --> conv2d(256, 256)
x_1 = self.act(self.norm(x_1)) # [N 49 64] # [N 49 128] # [N 49 256]
kv1 = self.kv1(x_1).reshape(B, -1, 2, self.num_heads//2, C // self.num_heads).permute(2, 0, 3, 1, 4) # [2 N 1 49 32] # [2 N 2 49 32] # [2 N 4 49 32]
k1, v1 = kv1[0], kv1[1] #B head N C [N 1 49 32] [N 2 49 32] [N 4 49 32]
attn1 = (q1 @ k1.transpose(-2, -1)) * self.scale #B head Nq Nkv [N 1 3136 49] [N 2 784 49] [N 4 196 49]
attn1 = attn1.softmax(dim=-1)
attn1 = self.attn_drop(attn1)
x1 = (attn1 @ v1).transpose(1, 2).reshape(B, N, C//2) # [N 3136 32] [N 784 64] [N 196 128]
global_mask_value = torch.mean(attn1.detach().mean(1), dim=1) # B Nk #max ? mean ? # [N 49]
global_mask_value = F.interpolate(global_mask_value.view(B,1,H//self.sr_ratio,W//self.sr_ratio),
(H, W), mode='nearest')[:, 0] # [N 56 56] [N 28 28] [N 14 14]
# local
q2 = self.q2(x).reshape(B, N, self.num_heads // 2, C // self.num_heads).permute(0, 2, 1, 3) #B head N C # [N 1 3136 32] [N 2 784 32] [N 4 196 32]
kv2 = self.kv2(x_.reshape(B, C, -1).permute(0, 2, 1)).reshape(B, -1, 2, self.num_heads // 2,
C // self.num_heads).permute(2, 0, 3, 1, 4)# [2 N 1 3136 32] [2 N 2 784 32] [2 N 4 196 32]
k2, v2 = kv2[0], kv2[1] # [N 1 3136 32] [N 2 784 32] [N 4 196 32]
q_window = 7
window_size= 7
q2, k2, v2 = window_partition(q2, q_window, H, W), window_partition(k2, window_size, H, W), \
window_partition(v2, window_size, H, W) # [N*64,49,32] [N*32,49,32] [N*16 49 32]
attn2 = (q2 @ k2.transpose(-2, -1)) * self.scale # [N*64 49 49] [N*32 49 49] [N*16 49 49]
# (B*numheads*num_windows, window_size*window_size, window_size*window_size)
attn2 = attn2.softmax(dim=-1)
attn2 = self.attn_drop(attn2)
x2 = (attn2 @ v2) # B*numheads*num_windows, window_size*window_size, C .transpose(1, 2).reshape(B, N, C) # [N*64 49 32] [N*32 49 32] [N*16 49 32]
x2 = window_reverse(x2, q_window, H, W, self.num_heads // 2) # [N 3136 32] [N 784 64] [N 196 128]
local_mask_value = torch.mean(attn2.detach().view(B, self.num_heads//2, H//window_size*W//window_size, window_size*window_size, window_size*window_size).mean(1), dim=2) #[N 64 49]
local_mask_value = local_mask_value.view(B, H // window_size, W // window_size, window_size, window_size) # [N 8 8 7 7]
local_mask_value=local_mask_value.permute(0, 1, 3, 2, 4).contiguous().view(B, H, W) # [N 56 56] [N 28 28] [N 14 14]
# mask B H W
x = torch.cat([x1, x2], dim=-1) # [N 3136 64] [N 784 128] [N 196 256]
x = self.proj(x+lepe) # linear(64,64) # linear(128,128) # linear(256,256)
x = self.proj_drop(x)
# cal mask
mask = local_mask_value+global_mask_value # [N 56 56] [N 28 28] [N 14 14]
mask_1 = mask.view(B, H * W) # [N 3136] [N 784] [N 196]
mask_2 = mask.permute(0, 2, 1).reshape(B, H * W) # [N 3136] [N 784] [N 196]
mask = [mask_1, mask_2]1.4、Atenção Autoguiada
Embora o modelo de Autoatenção seja capaz de modelar uma ampla gama de informações, seu alto custo computacional e consumo de memória são proporcionais ao quadrado do comprimento da sequência, limitando seu uso para recursos de grande porte em diversas tarefas de visão computacional, como segmentação e detecção.A aplicabilidade do diagrama. Pesquisas recentes sugerem reduzir o comprimento da sequência mesclando vários tokens em um. No entanto, esta agregação trata cada Token igualmente, ignorando as diferenças de importância inerentes entre os diferentes Tokens. Esta agregação enfrenta dois problemas:
-
Em áreas importantes, as informações podem ser perdidas ou misturadas com informações irrelevantes
-
Em áreas secundárias ou de segundo plano, um grande número de Tokens é redundante para uma semântica simples, mas requer muita computação
Inspirados nesta observação, propomos a atenção autoguiada, que utiliza a importância como guia para agregar tokens. Ou seja, na área saliente, mais tokens são retidos para obter informações refinadas, enquanto na área secundária, menos tokens são retidos para manter a visão global da Autoatenção e ao mesmo tempo reduzir o custo computacional.
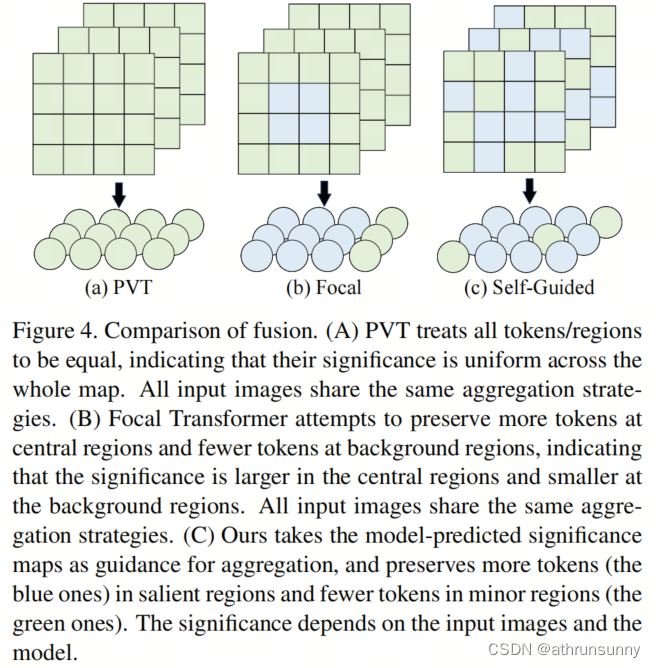
Conforme mostrado na Figura 4, "autoguiado" significa que o próprio Transformer determina a estratégia de redução de custos computacionais durante o treinamento, em vez de conhecimento prévio introduzido artificialmente, como atenção de janela no Swin, atenção de formato cruzado em CSWin, redução de espaço estático em PVT.
O mapa de recursos de entrada é primeiro projetado em Consulta (Q), Chave (K) e Valor (V). Em seguida, H chefes de autoatenção independentes calculam a autoatenção em paralelo. A fim de reduzir o custo computacional e manter inalterado o tamanho do mapa de características após a autoatenção, o comprimento de Q é fixo, mas o módulo de agregação guiada por importância (IAM) é usado para agregar os tokens de K e V.
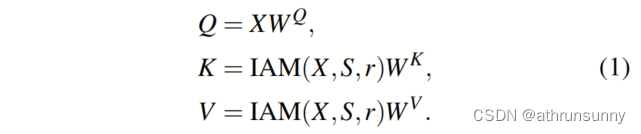
O objetivo do IAM é agregar menos Tokens em um (ou seja, reter mais Tokens) na área saliente e agregar mais Tokens em um (ou seja, reter menos Tokens) na área de fundo. Na fórmula (1), o mapa de atenção contém informações de importância da região com múltiplas granularidades.
Classifique os valores do mapa de atenção em ordem crescente e divida S igualmente em n sub-regiões . Portanto,
e
são as áreas mais importantes e secundárias respectivamente. Ao mesmo tempo, agrupe todos os Tokens
em . Na fórmula (1), a taxa de agregação em áreas de importância diferente é expressa de forma que cada subárea tenha uma taxa de agregação, e quanto mais importante a subárea, menor será a taxa de agregação. Os valores específicos dos diferentes estágios estão listados na Tabela 1. Portanto, o IAM redistribui os tokens dos recursos de entrada agrupados de cada grupo, conectando as diferentes taxas de agregação de cada grupo.

onde está a função de agregação, nós a implementamos através de uma camada totalmente conectada com dimensão de entrada r e dimensão de saída 1.
O número de Tokens em é igual ao
número de Tokens em dividido pelo número de Tokens em
. Correspondente a esta parte do código
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # [N 2 3136 32] [N 4 784 32] [N 8 196 32]
# mask [local_mask global_mask] local_mask [value index] value [B, H, W]
# use mask to fuse
mask_1, mask_2 = mask # [[N 3136],[N 3136]] [[N 784],[N 784]] [[N 196],[N 196]]
mask_sort1, mask_sort_index1 = torch.sort(mask_1, dim=1)
mask_sort2, mask_sort_index2 = torch.sort(mask_2, dim=1)
if self.sr_ratio == 8:
token1, token2, token3 = H * W // (14 * 14), H * W // 56, H * W // 28 # [16 56 112]
token1, token2, token3 = token1 // 4, token2 // 2, token3 // 4 # [4 28 28]
elif self.sr_ratio == 4:
token1, token2, token3 = H * W // 49, H * W // 14, H * W // 7 # [16 56 112]
token1, token2, token3 = token1 // 4, token2 // 2, token3 // 4 # [4 28 28]
elif self.sr_ratio == 2:
token1, token2 = H * W // 2, H * W // 1 # [98 196]
token1, token2 = token1 // 2, token2 // 2 # [49 98]
if self.sr_ratio==4 or self.sr_ratio==8:
p1 = torch.gather(x, 1, mask_sort_index1[:, :H * W // 4].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C # [N 784 64] 根据mask中的index对x[:, :H * W // 4(784)]进行重新排序 [N 196 128]
p2 = torch.gather(x, 1, mask_sort_index1[:, H * W // 4:H * W // 4 * 3].unsqueeze(-1).repeat(1, 1, C)) # [N 1568 64] [N 392 128]
p3 = torch.gather(x, 1, mask_sort_index1[:, H * W // 4 * 3:].unsqueeze(-1).repeat(1, 1, C)) # [N 784 64] [N 196 128]
seq1 = torch.cat([self.f1(p1.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1), # [N 64 4 196] # linear(196,1) # [N 128 4 49] # linear(49,1) 次要
self.f2(p2.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1), # [N 64 28 56] # linear(56,1) # [N 128 28 14] # linear(14,1)
self.f3(p3.permute(0, 2, 1).reshape(B, C, token3, -1)).squeeze(-1)], dim=-1).permute(0,2,1) # B N C # [N 64 28 28] # linear(28,1) # [N 128 28 7] # linear(7,1) 最重要
# seq1 [N 60 64] # seq1 [N 60 128]
x_ = x.view(B, H, W, C).permute(0, 2, 1, 3).reshape(B, H * W, C) # [N 3136 64] [N 784 128]
p1_ = torch.gather(x_, 1, mask_sort_index2[:, :H * W // 4].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 784 64] [N 196 128]
p2_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 4:H * W // 4 * 3].unsqueeze(-1).repeat(1, 1, C)) # [N 1568 64] [N 392 128]
p3_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 4 * 3:].unsqueeze(-1).repeat(1, 1, C)) # [N 784 64] [N 196 128]
seq2 = torch.cat([self.f1(p1_.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1),
self.f2(p2_.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1),
self.f3(p3_.permute(0, 2, 1).reshape(B, C, token3, -1)).squeeze(-1)], dim=-1).permute(0,2,1) # B N C # seq2 [N 60 64] seq2 [N 60 128]
elif self.sr_ratio==2:
p1 = torch.gather(x, 1, mask_sort_index1[:, :H * W // 2].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 98 256]
p2 = torch.gather(x, 1, mask_sort_index1[:, H * W // 2:].unsqueeze(-1).repeat(1, 1, C)) # [N 98 256]
seq1 = torch.cat([self.f1(p1.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1), # [N 256 49 2] # linear(2,1)
self.f2(p2.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1)], dim=-1).permute(0, 2, 1) # B N C # [N 256 98 1] # linear(1,1)
# seq1 [N 147 256]
x_ = x.view(B, H, W, C).permute(0, 2, 1, 3).reshape(B, H * W, C)
p1_ = torch.gather(x_, 1, mask_sort_index2[:, :H * W // 2].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 98 256]
p2_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 2:].unsqueeze(-1).repeat(1, 1, C)) # [N 98 256]
seq2 = torch.cat([self.f1(p1_.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1),
self.f2(p2_.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1)], dim=-1).permute(0, 2, 1) # B N C
# seq2 [N 147 256]
kv1 = self.kv1(seq1).reshape(B, -1, 2, self.num_heads // 2, C // self.num_heads).permute(2, 0, 3, 1, 4) # kv B heads N C # [2 N 1 60 32] # [2 N 2 60 32] # [2 N 4 147 32]
kv2 = self.kv2(seq2).reshape(B, -1, 2, self.num_heads // 2, C // self.num_heads).permute(2, 0, 3, 1, 4) # [2 N 1 60 32] # [2 N 2 60 32] # [2 N 4 147 32]
kv = torch.cat([kv1, kv2], dim=2) # [2 N 2 60 32] # [2 N 4 60 32] # [2 N 8 147 32]
k, v = kv[0], kv[1] # [N 2 60 32] # [N 4 60 32] # [N 8 147 32]
attn = (q @ k.transpose(-2, -1)) * self.scale # [N 2 3136 60] # [N 4 784 60] [N 8 196 147]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # [N 3136 64] # [N 784 128] [N 196 256]
x = self.proj(x+lepe)
x = self.proj_drop(x)
mask=NoneJunte as duas partes:
class Attention(nn.Module):
def __init__(self, dim, mask, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1, linear=False):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.sr_ratio=sr_ratio
if sr_ratio>1:
if mask:
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv1 = nn.Linear(dim, dim, bias=qkv_bias)
self.kv2 = nn.Linear(dim, dim, bias=qkv_bias)
if self.sr_ratio==8:
f1, f2, f3 = 14*14, 56, 28
elif self.sr_ratio==4:
f1, f2, f3 = 49, 14, 7
elif self.sr_ratio==2:
f1, f2, f3 = 2, 1, None
self.f1 = nn.Linear(f1, 1)
self.f2 = nn.Linear(f2, 1)
if f3 is not None:
self.f3 = nn.Linear(f3, 1)
else:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
self.act = nn.GELU()
self.q1 = nn.Linear(dim, dim//2, bias=qkv_bias)
self.kv1 = nn.Linear(dim, dim, bias=qkv_bias)
self.q2 = nn.Linear(dim, dim // 2, bias=qkv_bias)
self.kv2 = nn.Linear(dim, dim, bias=qkv_bias)
else:
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.lepe_linear = nn.Linear(dim, dim)
self.lepe_conv = local_conv(dim)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.linear = linear
self.apply(self._init_weights)
def forward(self, x, H, W, mask):
B, N, C = x.shape
lepe = self.lepe_conv(
self.lepe_linear(x).transpose(1, 2).view(B, C, H, W)).view(B, C, -1).transpose(-1, -2) # [N 3136 64] #[N 784 128] #[N 196 256] #[N 49 512]
if self.sr_ratio > 1:
if mask is None:
# global
q1 = self.q1(x).reshape(B, N, self.num_heads//2, C // self.num_heads).permute(0, 2, 1, 3) # [N 1 3136 32] # [N 2 784 32] # [N 4 196 32]
x_ = x.permute(0, 2, 1).reshape(B, C, H, W) # [N 64 56 56] # [N 128 28 28] # [N 256 14 14]
x_1 = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1) # [N 49 64] sr --> conv2d(64, 64) # [N 49 128] sr --> conv2d(128, 128) # [N 49 256] sr --> conv2d(256, 256)
x_1 = self.act(self.norm(x_1)) # [N 49 64] # [N 49 128] # [N 49 256]
kv1 = self.kv1(x_1).reshape(B, -1, 2, self.num_heads//2, C // self.num_heads).permute(2, 0, 3, 1, 4) # [2 N 1 49 32] # [2 N 2 49 32] # [2 N 4 49 32]
k1, v1 = kv1[0], kv1[1] #B head N C [N 1 49 32] [N 2 49 32] [N 4 49 32]
attn1 = (q1 @ k1.transpose(-2, -1)) * self.scale #B head Nq Nkv [N 1 3136 49] [N 2 784 49] [N 4 196 49]
attn1 = attn1.softmax(dim=-1)
attn1 = self.attn_drop(attn1)
x1 = (attn1 @ v1).transpose(1, 2).reshape(B, N, C//2) # [N 3136 32] [N 784 64] [N 196 128]
global_mask_value = torch.mean(attn1.detach().mean(1), dim=1) # B Nk #max ? mean ? # [N 49]
global_mask_value = F.interpolate(global_mask_value.view(B,1,H//self.sr_ratio,W//self.sr_ratio),
(H, W), mode='nearest')[:, 0] # [N 56 56] [N 28 28] [N 14 14]
# local
q2 = self.q2(x).reshape(B, N, self.num_heads // 2, C // self.num_heads).permute(0, 2, 1, 3) #B head N C # [N 1 3136 32] [N 2 784 32] [N 4 196 32]
kv2 = self.kv2(x_.reshape(B, C, -1).permute(0, 2, 1)).reshape(B, -1, 2, self.num_heads // 2,
C // self.num_heads).permute(2, 0, 3, 1, 4)# [2 N 1 3136 32] [2 N 2 784 32] [2 N 4 196 32]
k2, v2 = kv2[0], kv2[1] # [N 1 3136 32] [N 2 784 32] [N 4 196 32]
q_window = 7
window_size= 7
q2, k2, v2 = window_partition(q2, q_window, H, W), window_partition(k2, window_size, H, W), \
window_partition(v2, window_size, H, W) # [N*64,49,32] [N*32,49,32] [N*16 49 32]
attn2 = (q2 @ k2.transpose(-2, -1)) * self.scale # [N*64 49 49] [N*32 49 49] [N*16 49 49]
# (B*numheads*num_windows, window_size*window_size, window_size*window_size)
attn2 = attn2.softmax(dim=-1)
attn2 = self.attn_drop(attn2)
x2 = (attn2 @ v2) # B*numheads*num_windows, window_size*window_size, C .transpose(1, 2).reshape(B, N, C) # [N*64 49 32] [N*32 49 32] [N*16 49 32]
x2 = window_reverse(x2, q_window, H, W, self.num_heads // 2) # [N 3136 32] [N 784 64] [N 196 128]
local_mask_value = torch.mean(attn2.detach().view(B, self.num_heads//2, H//window_size*W//window_size, window_size*window_size, window_size*window_size).mean(1), dim=2) #[N 64 49]
local_mask_value = local_mask_value.view(B, H // window_size, W // window_size, window_size, window_size) # [N 8 8 7 7]
local_mask_value=local_mask_value.permute(0, 1, 3, 2, 4).contiguous().view(B, H, W) # [N 56 56] [N 28 28] [N 14 14]
# mask B H W
x = torch.cat([x1, x2], dim=-1) # [N 3136 64] [N 784 128] [N 196 256]
x = self.proj(x+lepe) # linear(64,64) # linear(128,128) # linear(256,256)
x = self.proj_drop(x)
# cal mask
mask = local_mask_value+global_mask_value # [N 56 56] [N 28 28] [N 14 14]
mask_1 = mask.view(B, H * W) # [N 3136] [N 784] [N 196]
mask_2 = mask.permute(0, 2, 1).reshape(B, H * W) # [N 3136] [N 784] [N 196]
mask = [mask_1, mask_2]
else:
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # [N 2 3136 32] [N 4 784 32] [N 8 196 32]
# mask [local_mask global_mask] local_mask [value index] value [B, H, W]
# use mask to fuse
mask_1, mask_2 = mask # [[N 3136],[N 3136]] [[N 784],[N 784]] [[N 196],[N 196]]
mask_sort1, mask_sort_index1 = torch.sort(mask_1, dim=1)
mask_sort2, mask_sort_index2 = torch.sort(mask_2, dim=1)
if self.sr_ratio == 8:
token1, token2, token3 = H * W // (14 * 14), H * W // 56, H * W // 28 # [16 56 112]
token1, token2, token3 = token1 // 4, token2 // 2, token3 // 4 # [4 28 28]
elif self.sr_ratio == 4:
token1, token2, token3 = H * W // 49, H * W // 14, H * W // 7 # [16 56 112]
token1, token2, token3 = token1 // 4, token2 // 2, token3 // 4 # [4 28 28]
elif self.sr_ratio == 2:
token1, token2 = H * W // 2, H * W // 1 # [98 196]
token1, token2 = token1 // 2, token2 // 2 # [49 98]
if self.sr_ratio==4 or self.sr_ratio==8:
p1 = torch.gather(x, 1, mask_sort_index1[:, :H * W // 4].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C # [N 784 64] 根据mask中的index对x[:, :H * W // 4(784)]进行重新排序 [N 196 128]
p2 = torch.gather(x, 1, mask_sort_index1[:, H * W // 4:H * W // 4 * 3].unsqueeze(-1).repeat(1, 1, C)) # [N 1568 64] [N 392 128]
p3 = torch.gather(x, 1, mask_sort_index1[:, H * W // 4 * 3:].unsqueeze(-1).repeat(1, 1, C)) # [N 784 64] [N 196 128]
seq1 = torch.cat([self.f1(p1.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1), # [N 64 4 196] # linear(196,1) # [N 128 4 49] # linear(49,1) 次要
self.f2(p2.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1), # [N 64 28 56] # linear(56,1) # [N 128 28 14] # linear(14,1)
self.f3(p3.permute(0, 2, 1).reshape(B, C, token3, -1)).squeeze(-1)], dim=-1).permute(0,2,1) # B N C # [N 64 28 28] # linear(28,1) # [N 128 28 7] # linear(7,1) 最重要
# seq1 [N 60 64] # seq1 [N 60 128]
x_ = x.view(B, H, W, C).permute(0, 2, 1, 3).reshape(B, H * W, C) # [N 3136 64] [N 784 128]
p1_ = torch.gather(x_, 1, mask_sort_index2[:, :H * W // 4].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 784 64] [N 196 128]
p2_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 4:H * W // 4 * 3].unsqueeze(-1).repeat(1, 1, C)) # [N 1568 64] [N 392 128]
p3_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 4 * 3:].unsqueeze(-1).repeat(1, 1, C)) # [N 784 64] [N 196 128]
seq2 = torch.cat([self.f1(p1_.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1),
self.f2(p2_.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1),
self.f3(p3_.permute(0, 2, 1).reshape(B, C, token3, -1)).squeeze(-1)], dim=-1).permute(0,2,1) # B N C # seq2 [N 60 64] seq2 [N 60 128]
elif self.sr_ratio==2:
p1 = torch.gather(x, 1, mask_sort_index1[:, :H * W // 2].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 98 256]
p2 = torch.gather(x, 1, mask_sort_index1[:, H * W // 2:].unsqueeze(-1).repeat(1, 1, C)) # [N 98 256]
seq1 = torch.cat([self.f1(p1.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1), # [N 256 49 2] # linear(2,1)
self.f2(p2.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1)], dim=-1).permute(0, 2, 1) # B N C # [N 256 98 1] # linear(1,1)
# seq1 [N 147 256]
x_ = x.view(B, H, W, C).permute(0, 2, 1, 3).reshape(B, H * W, C)
p1_ = torch.gather(x_, 1, mask_sort_index2[:, :H * W // 2].unsqueeze(-1).repeat(1, 1, C)) # B, N//4, C [N 98 256]
p2_ = torch.gather(x_, 1, mask_sort_index2[:, H * W // 2:].unsqueeze(-1).repeat(1, 1, C)) # [N 98 256]
seq2 = torch.cat([self.f1(p1_.permute(0, 2, 1).reshape(B, C, token1, -1)).squeeze(-1),
self.f2(p2_.permute(0, 2, 1).reshape(B, C, token2, -1)).squeeze(-1)], dim=-1).permute(0, 2, 1) # B N C
# seq2 [N 147 256]
kv1 = self.kv1(seq1).reshape(B, -1, 2, self.num_heads // 2, C // self.num_heads).permute(2, 0, 3, 1, 4) # kv B heads N C # [2 N 1 60 32] # [2 N 2 60 32] # [2 N 4 147 32]
kv2 = self.kv2(seq2).reshape(B, -1, 2, self.num_heads // 2, C // self.num_heads).permute(2, 0, 3, 1, 4) # [2 N 1 60 32] # [2 N 2 60 32] # [2 N 4 147 32]
kv = torch.cat([kv1, kv2], dim=2) # [2 N 2 60 32] # [2 N 4 60 32] # [2 N 8 147 32]
k, v = kv[0], kv[1] # [N 2 60 32] # [N 4 60 32] # [N 8 147 32]
attn = (q @ k.transpose(-2, -1)) * self.scale # [N 2 3136 60] # [N 4 784 60] [N 8 196 147]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # [N 3136 64] # [N 784 128] [N 196 256]
x = self.proj(x+lepe)
x = self.proj_drop(x)
mask=None
else:
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # [N 16 49 32]
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) #[2 N 16 49 32]
k, v = kv[0], kv[1] # [N 16 49 32]
attn = (q @ k.transpose(-2, -1)) * self.scale # [N 16 49 49]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # [N 49 512]
x = self.proj(x+lepe) # linear(512,512)
x = self.proj_drop(x)
mask=None
return x, maskA janela dividida e o transformador swin são iguais.
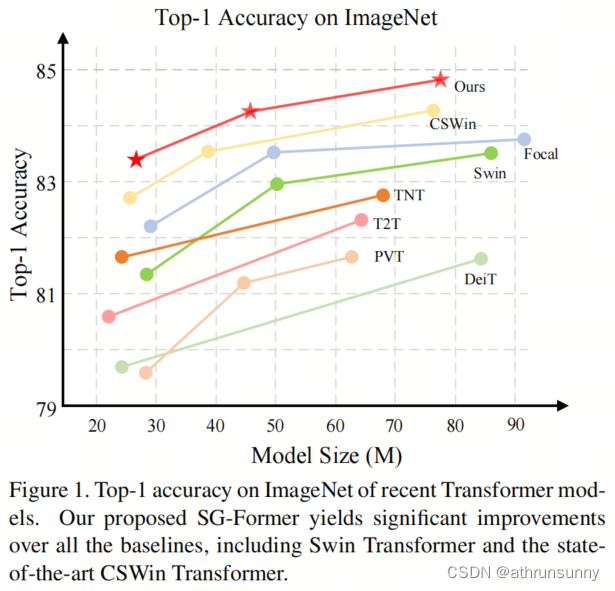
Desempenho na classificação:


Sob parâmetros semelhantes, o SG-Former supera significativamente os seus concorrentes em desempenho. Especificamente, o modelo básico supera o Swin-B 1.6. Comparado com o CSWin de última geração anterior, o SG-Former-S/M/B alcançou melhorias de desempenho de +0,4, +0,3 e +0,4, respectivamente.
O autor também mediu seu desempenho em diversas tarefas, e todas foram melhores que os atuais modelos de última geração.