Índice
- 1. Introdução
- 2. Princípio do Algoritmo
- 3. Processo de algoritmo
- 4. Prática de caso
- 5. Vantagens e Desvantagens do Algoritmo
- 6. Comparação com outros algoritmos semelhantes
- 7. Resumo
Neste artigo aprofundado, analisamos abrangentemente o algoritmo de árvore de decisão C4.5, incluindo seus princípios básicos, processo de implementação, casos práticos e comparação com outros algoritmos de árvore de decisão populares (como ID3, CART e Random Forests).
Siga o TechLead e compartilhe conhecimento abrangente de IA. O autor tem mais de 10 anos de arquitetura de serviços de Internet, experiência em desenvolvimento de produtos de IA e experiência em gerenciamento de equipes. Ele possui mestrado pela Universidade Tongji na Universidade Fudan, membro do Fudan Robot Intelligence Laboratory, arquiteto sênior certificado pela Alibaba Cloud, um profissional de gerenciamento de projetos e pesquisa e desenvolvimento de produtos de IA com receita de centenas de milhões.

1. Introdução
O algoritmo C4.5 é um algoritmo de árvore de decisão amplamente utilizado em aprendizado de máquina e mineração de dados. Foi proposto pelo professor Ross Quinlan em 1993 como uma expansão e melhoria de seu algoritmo ID3 (Iterative Dichotomiser 3). Este algoritmo é projetado para dividir um problema complexo de tomada de decisão em uma série de decisões simples e, em seguida, construir um modelo de árvore de decisão para resolver o problema.
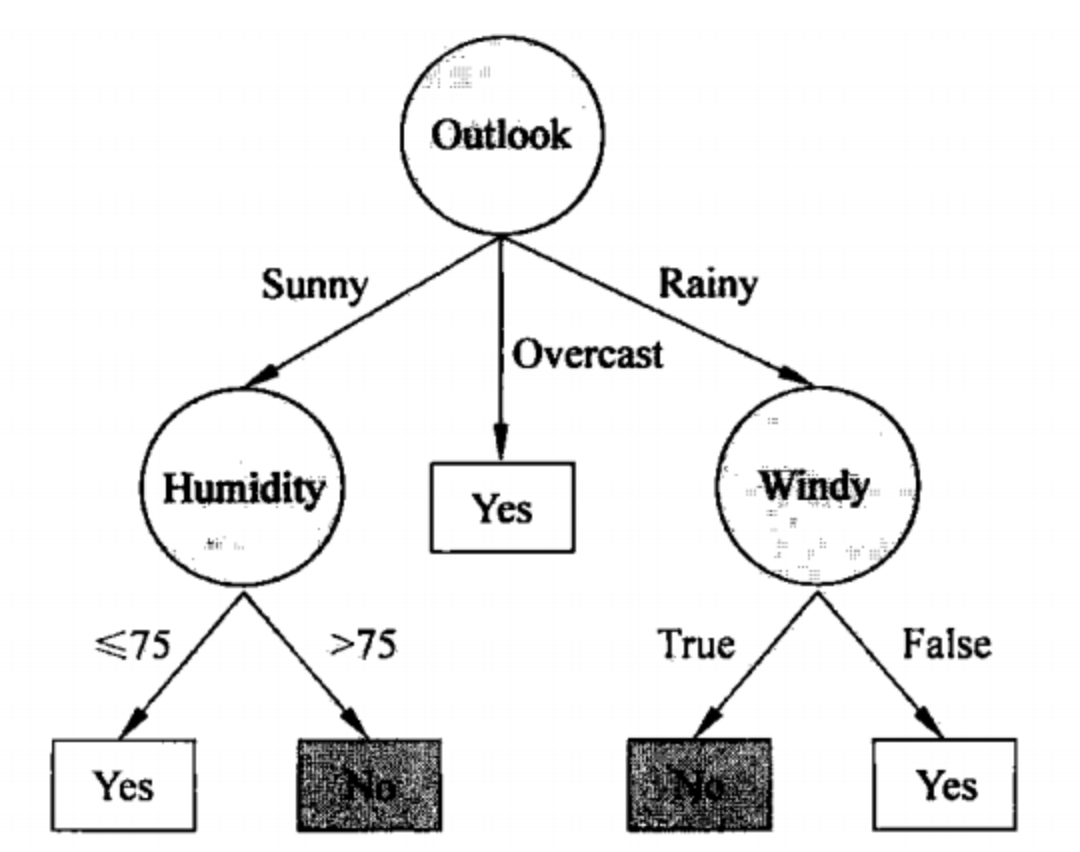
Árvore de decisão
Uma árvore de decisão é um modelo estruturado em árvore usado para tomar decisões ou classificar um determinado conjunto de recursos. Neste modelo, cada nó interno representa um teste de recurso, cada ramificação representa um resultado de teste e cada nó folha representa um resultado de decisão.
exemplo:
Suponha que temos um conjunto de dados que inclui clima, temperatura e se atividades ao ar livre são realizadas. Uma árvore de decisão pode primeiro ramificar-se com base no "clima": se estiver ensolarado, atividades ao ar livre são recomendadas; se estiver chuvoso, ramificar-se ainda mais com base na "temperatura".
Entropia de informação e ganho de informação
A entropia da informação é um indicador usado para medir a incerteza dos dados, enquanto o ganho de informação representa quanta “informação” pode ser trazida até nós após a divisão por um determinado recurso para reduzir essa incerteza.
exemplo:
Considere um conjunto de dados com duas classes A e B. Se todas as instâncias pertencem à categoria A, então a entropia da informação é 0, porque temos certeza absoluta de que qualquer instância pertence à categoria A. Mas se metade pertence à categoria A e a outra metade pertence à categoria B, a entropia da informação é maior porque os dados são mais incertos.
Taxa de ganho de informação (taxa de ganho)
Semelhante ao ganho de informação, a taxa de ganho de informação é usada para avaliar a importância de um recurso, mas também leva em consideração o número de divisões (ou seja, o número de valores de recurso) que um recurso pode causar.
exemplo:
Suponha que exista um recurso “cor”, que possui muitos valores possíveis (vermelho, azul, verde, etc.). Mesmo que a "cor" forneça um alto ganho de informação, a taxa de ganho de informação pode ser relativamente baixa, uma vez que causa muitas divisões na árvore.
Através desses conceitos básicos e melhorias, o algoritmo C4.5 não apenas melhora a eficiência computacional, mas também tem vantagens significativas no tratamento de atributos contínuos, valores ausentes e otimização de redução de ramificação.
2. Princípio do Algoritmo
Antes de compreender o algoritmo C4.5 em profundidade, é necessário esclarecer vários conceitos e métricas fundamentais. Esta seção se concentrará na entropia da informação, no ganho de informação e na taxa de ganho de informação, que são fatores-chave na construção da árvore de decisão do algoritmo C4.5.
Entropia de Informação
A entropia da informação é usada para medir o grau de incerteza ou confusão em um conjunto de dados. É um conceito baseado na teoria das probabilidades e geralmente é definido pela seguinte fórmula matemática:
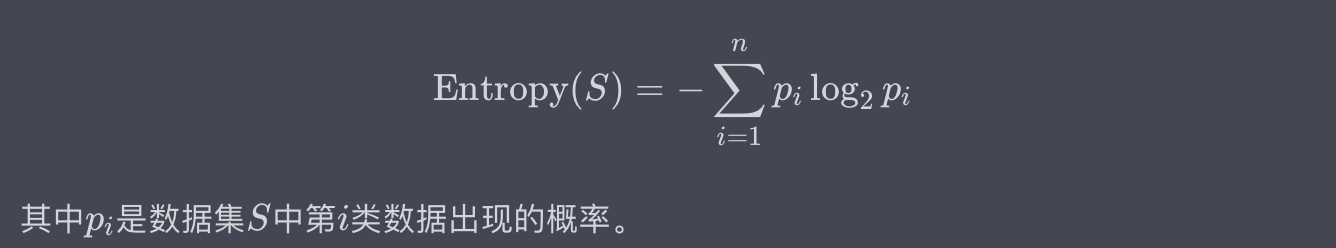
exemplo:
Suponha que temos um conjunto de dados contendo 10 amostras, 5 das quais são positivas (Sim) e 5 são negativas (Não). A entropia da informação pode ser calculada como:

Ganho de informação
O ganho de informação representa o grau em que a incerteza (ou seja, entropia de informação) de um conjunto de dados diminui após a divisão por uma determinada característica. O ganho de informação é geralmente definido pela seguinte fórmula matemática:

exemplo:
Considere um conjunto de dados simples com um recurso "clima" que possui dois valores possíveis: "ensolarado" e "chuvoso". Através do cálculo, constatamos que após a divisão pelo atributo “clima”, o ganho de informação é de 0,2. Isso significa que a divisão usando esse recurso reduz a incerteza do conjunto de dados em 0,2.
Taxa de ganho de informação (taxa de ganho)
A taxa de ganho de informações é a proporção entre o ganho de informações e a complexidade de divisão do conjunto de dados (informações divididas) causada pelo recurso. Expresso como uma fórmula matemática:

exemplo:
Se no exemplo anterior do recurso "clima" calculamos que a informação dividida é 0,5, então a taxa de ganho de informação é 0,2 / 0,5 = 0,4.
Através dos três conceitos-chave de entropia de informação, ganho de informação e taxa de ganho de informação, o algoritmo C4.5 pode selecionar efetivamente os recursos ideais e dividir o conjunto de dados para construir uma árvore de decisão eficiente e precisa. Isto não só resolve as deficiências do algoritmo ID3 em alguns aspectos, mas também torna o modelo de árvore de decisão mais adequado para problemas práticos.
3. Processo de algoritmo
Nesta parte, nos aprofundaremos no processo central do algoritmo C4.5. O processo geralmente pode ser dividido em várias etapas principais, desde o pré-processamento dos dados até a geração da árvore de decisão e subsequente poda da árvore de decisão. Aqui está uma explicação mais detalhada:
Etapa 1: preparação de dados
conceito:
No processo de construção de uma árvore de decisão, primeiro você precisa preparar um conjunto de dados de treinamento. Este conjunto de dados deve conter vários recursos (ou atributos) e uma variável de destino (ou rótulo). A fase de preparação de dados também pode incluir limpeza e transformação de dados.
exemplo:
Por exemplo, no diagnóstico médico, as características podem incluir a idade, o sexo, os sintomas do paciente, etc., enquanto a variável alvo pode ser se o paciente sofre de uma determinada doença.
Etapa 2: Calcular a entropia da informação
conceito:
A entropia da informação é uma medida de incerteza nos dados. No algoritmo C4.5, a entropia da informação é usada para avaliar como dividir os dados.
exemplo:
Suponha que exista um conjunto de dados com duas categorias: “Sim” e “Não”, cada categoria contém 50% dos dados. Nesse caso, a entropia da informação é maior porque os dados apresentam o maior grau de incerteza.
Etapa 3: selecione os recursos ideais
conceito:
Em cada nó da árvore de decisão, o algoritmo precisa selecionar um recurso para dividir os dados. Qual recurso é escolhido depende de qual recurso resulta na maior diminuição na entropia da informação (ou no maior ganho de informação).
exemplo:
Na tarefa de prever se vai chover, podem existir múltiplas características como temperatura, umidade, etc. Se for constatado que a divisão dos dados pelo recurso "umidade" resultará no maior ganho de informação, então o nó deverá ser dividido com base na "umidade".
Etapa 4: construir recursivamente a árvore de decisão
conceito:
Uma vez que o recurso ideal é selecionado e os dados são divididos com base nesse recurso, o algoritmo executará recursivamente o mesmo processo em cada subconjunto de divisão até que uma determinada condição de parada seja atendida (por exemplo, todos os dados pertencem à mesma categoria ou a um conjunto predeterminado). profundidade máxima, etc.).
exemplo:
Considere uma árvore de decisão usada para classificar animais. Primeiro, os dados são segmentados com base no recurso "se tem coluna", depois, no subconjunto de "tem coluna", são segmentados ainda mais com base em "se pode voar" e assim por diante.
Etapa 5: poda da árvore de decisão (opcional)
conceito:
A poda da árvore de decisão é um método de otimização usado para remover nós desnecessários na árvore de decisão para evitar ajuste excessivo.
exemplo:
Se todos os nós filhos de um nó corresponderem ao mesmo rótulo de categoria, então este nó pode ser desnecessário porque seu nó pai já pode ser classificado com precisão.
4. Prática de caso
Nesta seção, usaremos um conjunto de dados real para mostrar como aplicar o algoritmo C4.5. Através deste caso, você obterá uma compreensão mais clara de como aplicar a teoria a problemas práticos. Usaremos Python e a biblioteca Scikit-learn para implementar este algoritmo (observe que o Scikit-learn DecisionTreeClassifierfornece um parâmetro criterion='entropy'para implementar o critério de ganho de informação C4.5).
Seleção de conjunto de dados
conceito:
Em projetos de aprendizado de máquina, escolher um conjunto de dados apropriado é uma etapa muito crítica. Os conjuntos de dados devem ser relevantes para o problema, ricos e limpos.
exemplo:
Para este exemplo, usaremos o conjunto de dados clássico Iris, que é usado para classificar três espécies diferentes de flores de íris.
Pré-processamento de dados
conceito:
O pré-processamento de dados é o processo de preparação de dados para uso em modelos de aprendizado de máquina. Isso pode incluir padronização, tratamento de valores ausentes, etc.
exemplo:
No conjunto de dados Iris, todos os recursos são numéricos e não requerem transformação ou padronização adicional.
Código de implementação Python
Abaixo está o código para implementar o algoritmo C4.5 usando Python e Scikit-learn.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化决策树分类器
clf = DecisionTreeClassifier(criterion='entropy')
# 训练模型
clf.fit(X_train, y_train)
# 测试模型
score = clf.score(X_test, y_test)
print(f'Accuracy: {
score * 100:.2f}%')
Entrada e saída:
- Entrada: recursos e rótulos do conjunto de dados Iris
- Saída: precisão do modelo
Processo de processamento:
- Carregue o conjunto de dados Iris.
- Divida o conjunto de dados em conjunto de treinamento e conjunto de teste.
- Inicialize um classificador de árvore de decisão usando entropia de informação como critério de divisão.
- Use o conjunto de treinamento para treinar o classificador.
- Avalie o classificador usando o conjunto de testes.
5. Vantagens e Desvantagens do Algoritmo
Como membro da família das árvores de decisão, o algoritmo C4.5 é amplamente utilizado em problemas de classificação. Porém, como todos os algoritmos, o C4.5 tem suas vantagens e desvantagens. Esta seção explora esses aspectos em detalhes.
vantagem
Fácil de entender e explicar
conceito:
As árvores de decisão são modelos de caixa branca, o que significa que são mais fáceis de entender e interpretar do que modelos de caixa preta, como redes neurais.
exemplo:
Digamos que você tenha um modelo de árvore de decisão para pontuação de crédito. Cada nó descreve claramente qual recurso é usado para segmentação, como renda anual ou índice de endividamento. Isto permite que os bancos expliquem facilmente aos clientes porque é que os seus pedidos de empréstimo foram rejeitados.
Capaz de lidar com relacionamentos não lineares
conceito:
C4.5 pode lidar bem com o relacionamento não linear entre recursos e variáveis de destino.
exemplo:
Considere um site de comércio eletrônico onde pode haver uma relação não linear entre a idade do usuário e a intenção de compra. Os jovens e os idosos podem estar mais inclinados a comprar, enquanto as pessoas de meia-idade podem estar relativamente menos inclinadas. O algoritmo C4.5 pode capturar esta relação não linear.
Melhor tolerância para valores ausentes
conceito:
O algoritmo C4.5 pode tolerar valores ausentes nos dados de entrada.
exemplo:
Em cenários de diagnóstico médico, alguns resultados do exame do paciente podem estar incompletos ou ausentes, e o algoritmo C4.5 ainda pode realizar uma classificação eficaz.
deficiência
Fácil de superajustar
conceito:
O algoritmo C4.5 é muito propenso a overfitting, especialmente quando a árvore de decisão é muito profunda.
exemplo:
Se um modelo de árvore de decisão tiver um desempenho excepcionalmente bom em um problema de previsão do mercado de ações, é provável que o modelo tenha sido superajustado porque os preços das ações são afetados por uma variedade de fatores imprevisíveis.
Sensível a ruídos e outliers
conceito:
Como os modelos de árvore de decisão são muito sensíveis a pequenas mudanças na distribuição de dados quando construídos, ruídos e valores discrepantes podem afetar bastante o desempenho do modelo.
exemplo:
Em aplicativos que identificam spam, o algoritmo C4.5 pode classificar erroneamente e-mails legítimos como spam se os dados de treinamento contiverem ruído devido a erros de rotulagem.
A complexidade computacional pode ser alta
conceito:
Devido à necessidade de calcular o ganho de informação ou taxa de ganho de todos os recursos, o algoritmo C4.5 pode ter altos custos computacionais quando a dimensão do recurso é muito alta.
exemplo:
Em conjuntos de dados de expressão gênica, o uso do algoritmo C4.5 pode resultar em aumento de custos computacionais, pois o número de características pode chegar a milhares ou mais.
6. Comparação com outros algoritmos semelhantes
Existem várias implementações diferentes do algoritmo de árvore de decisão, como ID3, CART (Árvores de Classificação e Regressão) e Florestas Aleatórias. Nesta seção, focaremos na comparação das principais diferenças e cenários aplicáveis entre C4.5 e esses algoritmos.
C4.5 versus ID3
Critérios de seleção de recursos
conceito:
O algoritmo ID3 usa o ganho de informação como critério para seleção de recursos, enquanto C4.5 usa a taxa de ganho de informação.
exemplo:
Suponha que você esteja classificando dados de texto e um dos recursos seja o comprimento do texto. O ID3 pode preferir usar esse recurso porque pode ter alto ganho de informação. No entanto, C4.5 pode reduzir esse viés usando taxas de ganho, selecionando assim características mais discriminativas.
Tratamento de atributos contínuos
conceito:
C4.5 pode lidar diretamente com atributos contínuos, mas ID3 não.
exemplo:
No modelo de previsão do preço da habitação, a área da casa é um atributo contínuo. C4.5 é capaz de lidar com esse tipo de dados naturalmente, enquanto ID3 precisa primeiro discretizá-los.
C4.5 versus CART
Tipo de saída
conceito:
CART suporta classificação e saída de regressão, enquanto C4.5 é usado principalmente para classificação.
exemplo:
Se o seu objetivo é prever uma variável de produção contínua (como os preços das casas), então o CART pode ser uma escolha melhor.
Critérios de seleção de recursos
conceito:
CART usa "impureza de Gini" ou "erro quadrático médio" como critério de seleção de recursos, enquanto C4.5 usa taxa de ganho de informação.
exemplo:
Numa aplicação de diagnóstico médico, assumindo que a distribuição de uma determinada característica em duas categorias é muito diferente, C4.5 pode dar prioridade a esta característica, mas CART não.
C4.5 vs Florestas Aleatórias
Complexidade do modelo
conceito:
Random Forests é um método conjunto que geralmente inclui múltiplas árvores de decisão, portanto o modelo é mais complexo.
exemplo:
Em um conjunto de dados de alta dimensão (como classificação de imagens), Random Forests pode ter um desempenho melhor que C4.5, mas requer mais recursos computacionais.
robustez
conceito:
Como Random Forests é um método conjunto, geralmente é menos sujeito a overfitting e é mais robusto a ruídos e valores discrepantes.
exemplo:
Na aplicação de detecção de fraude financeira, como os dados geralmente são muito desequilibrados e contêm muito ruído, o uso de Random Forests geralmente alcançará melhores resultados do que C4.5.
7. Resumo
Algoritmos de árvore de decisão, especialmente o algoritmo C4.5, são amplamente utilizados porque são intuitivos, fáceis de entender e implementar. Neste artigo, temos uma discussão aprofundada do algoritmo C4.5 de múltiplas perspectivas, incluindo princípios de algoritmo, processos, estudos de caso reais, vantagens e desvantagens e comparação com outros algoritmos semelhantes.
-
Diversidade na seleção de recursos : O algoritmo C4.5 otimiza a seleção de recursos usando a taxa de ganho de informação, fornecendo uma escolha mais apropriada que o ID3 em alguns casos. Isto é especialmente importante ao lidar com dados de alta dimensão ou quando há dependências entre recursos.
-
Aplicabilidade e limitações : Embora o C4.5 seja muito poderoso ao lidar com problemas de classificação, ele também tem suas próprias limitações, como ser propenso a overfitting e ser sensível ao ruído. Compreender essas limitações não apenas nos ajuda a tomar decisões mais informadas em aplicações específicas, mas também nos motiva a explorar como melhorar o algoritmo por meio de métodos de conjunto ou ajuste de parâmetros.
-
Posição relativa com outros algoritmos : Quando comparamos C4.5 com outros algoritmos de árvore de decisão, como CART e Random Forests, podemos ver que cada algoritmo tem seus cenários e limitações de aplicação exclusivos. Por exemplo, onde a interpretabilidade do modelo é necessária, C4.5 e CART podem ser mais adequados; enquanto em conjuntos de dados complexos de alta dimensão, as Florestas Aleatórias podem ter mais vantagens.
-
Complexidade e custo computacional : Embora C4.5 seja um algoritmo relativamente simples, seu custo computacional não pode ser ignorado ao processar dados em grande escala ou de alta dimensão. Isso nos lembra que o desempenho do algoritmo e o custo computacional precisam ser considerados de forma abrangente em aplicações práticas.
Siga o TechLead e compartilhe conhecimento abrangente de IA. O autor tem mais de 10 anos de arquitetura de serviços de Internet, experiência em desenvolvimento de produtos de IA e experiência em gerenciamento de equipes. Ele possui mestrado pela Universidade Tongji na Universidade Fudan, membro do Fudan Robot Intelligence Laboratory, arquiteto sênior certificado pela Alibaba Cloud, um profissional de gerenciamento de projetos e pesquisa e desenvolvimento de produtos de IA com receita de centenas de milhões.