Autor: Programador Jiang
prefácio
AndroidA estabilidade do aplicativo é Androidum importante indicador de desempenho e também é a parte mais básica e crítica do sistema de construção de qualidade do aplicativo . Se o aplicativo travar com frequência ou se os principais recursos estiverem indisponíveis, isso obviamente terá um grande impacto em nossa retenção.
Para garantir a estabilidade do aplicativo, devemos primeiro estabelecer uma compreensão correta da estabilidade. Este artigo inclui principalmente o seguinte conteúdo:
- Compreensão Correta da Otimização de Estabilidade
CrashEtapas gerais do processamentoCrashGovernança de longo prazo- Construção de Soluções de Alta Disponibilidade Empresarial
- Perguntas comuns da entrevista sobre otimização de estabilidade
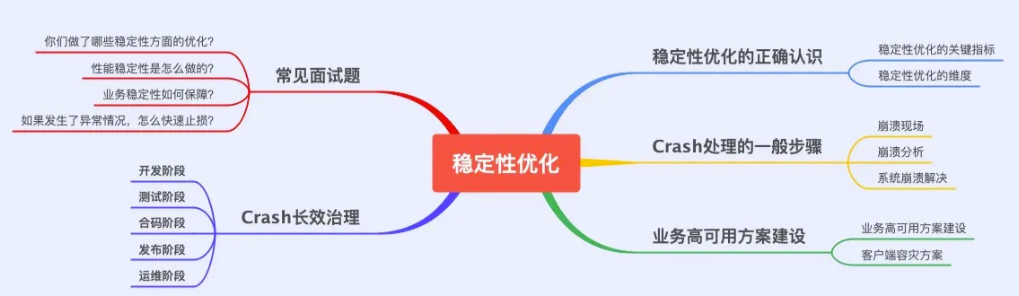
Compreensão Correta da Otimização de Estabilidade
Principais métricas para otimização de estabilidade
Para otimizar a estabilidade, a primeira pergunta é: qual efeito deve ser alcançado? CrashQual é o índice de excelência? Só depois de esclarecido o objetivo é que podemos entender corretamente o papel do nosso trabalho
Para calcular Crasha taxa, devemos primeiro entender alguns indicadores-chave de otimização de estabilidade
UV Crashtaxa versus PV Crashtaxa
PV(Page View)Ou seja, o número de visitas, UV(Unique Visitor)ou seja, visitantes únicos, e o mesmo terminal dentro de 0-24 horas é contabilizado apenas uma vez
UV CrashTaxa: Para as estatísticas de uso do usuário, é contada a proporção de travamentos de todos os usuários em um período de tempo, que é usada para avaliar aCrashfaixa de influência da taxa.PV CrashTaxa: com base nas estatísticas dos tempos de uso do usuário, avalieCrasha gravidade dos impactos relacionados.
Você pode escolher o indicador adequado de acordo com suas próprias necessidades, lembrando que você precisa garantir que sempre use o mesmo método de medição.
Crashavaliação de taxa
Então, quanto mais baixo é o nosso Appíndice Crashpara ser considerado um nível normal ou um nível excelente?
JavaANativetaxa total de acidentes deve ser inferior a 2 por mil.CrashO percentil 10.000 é excelente
Observe que o mencionado acima é UVa taxa de falhas
Dimensões de Otimização de Estabilidade
Muitas pessoas pensam que a otimização da estabilidade é reduzir Crasha taxa, mas se seu aplicativo APPnão travar, mas as principais funções não estiverem disponíveis, como ele pode ser considerado estável?
Portanto, a estabilidade do aplicativo pode ser dividida em três latitudes, conforme segue:
- 1.
CrashLatitude: O indicador mais importante éCrasha taxa de aplicação. - 2. Latitude de desempenho: incluindo direções de otimização como velocidade de inicialização, memória, desenho etc., que
Crashsão relativamente secundárias, mas também fazem parte da estabilidade do aplicativo. - 3. Latitude de alta disponibilidade de negócios: Esta é uma etapa muito crítica. Precisamos usar vários métodos para garantir
Appa estabilidade de nosso processo principal e caminho principal.
CrashEtapas gerais do processamento
Vamos dar uma olhada em como lidar com isso Crash, ou seja, se o aplicativo travar, como você deve analisá-lo?
Analisar principalmente a partir de duas perspectivas da cena do acidente e da análise do acidente
local de acidente
A cena do acidente é a nossa "primeira cena do crime" e contém muitas pistas valiosas. Quanto mais informações extrairmos aqui, mais clara será a direção da próxima análise, em vez de confiar em suposições cegas.
Em seguida, vamos dar uma olhada em quais informações devem ser coletadas no local do acidente.
informações de acidente
A partir das informações básicas do acidente, podemos ter um julgamento preliminar sobre o acidente.
- Nome do processo, nome do encadeamento. O processo de falha é um processo de primeiro plano ou um processo de segundo plano e se a falha ocorreu no thread da interface do usuário.
- Bater pilha e tipo. A falha pertence a
Javacrash ,Nativecrash ouANR, prestamos atenção diferente a diferentes tipos de falhas. Em particular, precisamos examinar o topo da pilha de falhas para ver se a falha específica está no código do sistema ou em nosso próprio código.
mensagem do sistema
Além das informações do travamento, as informações do sistema às vezes contêm algumas pistas importantes, que são muito úteis para resolvermos o problema.
Logcatsaída. Isso inclui logs de operação do aplicativo e do sistema. Às vezes, você não consegue ver muita informação da pilha, mas pode obter ganhos inesperadosLogcatdela- Modelo, sistema, fabricante,
CPU,ABI,Linuxversão, etc. Coletaremos até dezenas de dimensões, o que será muito útil para encontrar problemas comuns quando falarmos sobre isso mais tarde. - Status do dispositivo: se
root, se é um emulador. Alguns problemas são causados porXposedou software de abertura excessiva , temos que tratar esses problemas de forma diferente.
informações de memória
OOM, ANR, esgotamento da memória virtual, etc., muitas falhas estão diretamente relacionadas à memória. Se dividirmos a memória do celular do usuário em dois baldes de "abaixo de 2 GB" e "acima de 2 GB", descobriremos que a taxa de travamento de usuários "abaixo de 2 GB" é várias vezes maior do que a de usuários "acima de 2 GB".
- Memória restante do sistema. Em relação ao status da memória do sistema, os arquivos podem ser lidos diretamente
/proc/meminfo. Quando a memória disponível do sistema é muito pequena (menosMemTotalde 10%), é muito provável que ocorram problemas comoOOMmemória, grandes quantidades e suicídios frequentes do sistema.GC - Os aplicativos usam memória. Incluindo
Javaa memória ,RSS(Resident Set Size),PSS(Proportional Set Size), podemos obter o tamanho e a distribuição da própria memória do aplicativo. - Memória virtual. A memória virtual pode
/proc/self/statusser obtida , e/proc/self/mapsa distribuição específica pode ser obtida através do arquivo. Às vezes, geralmente não prestamos muita atenção à memória virtual, mas muitos problemas comoOOM,tgkilletc. são causados por memória virtual insuficiente.
Name: com.sample.name // 进程名
FDSize: 800 // 当前进程申请的文件句柄个数
VmPeak: 3004628 kB // 当前进程的虚拟内存峰值大小
VmSize: 2997032 kB // 当前进程的虚拟内存大小
Threads: 600 // 当前进程包含的线程个数
De um modo geral, para um processo de 32 bits, se for de 32 bits CPU, a memória virtual chega a 3 GB, o que pode causar falha no aplicativo de memória. Se for de 64 bits CPU, a memória virtual geralmente fica entre 3 e 4 GB. Obviamente, se oferecermos suporte a processos de 64 bits, a memória virtual não será um problema. Portanto, nosso aplicativo deve tentar se adaptar a 64 bits
informações de recursos
Às vezes, descobriremos que a memória heap do aplicativo e a memória do dispositivo são muito suficientes, mas ainda haverá falhas de alocação de memória, que podem ter uma relação maior com vazamentos de recursos.
- identificador de arquivo
fd. Geralmente, o número máximo de identificadores de arquivo que podem ser abertos por um único processo é1024. Mas se o identificador de arquivo800exceder , é mais perigoso. Você precisafdenviar todos os nomes de arquivo correspondentes para o log e verificar se há um vazamento de arquivo ou thread - Tópicos. Um único thread pode
2MBocupar a memória virtual, muitos threads sobrecarregarão a memória virtual e os manipuladores de arquivos. De acordo com minha experiência, se o número de threads exceder 400, é perigoso. Todos os encadeamentoside enviados para o log para verificar se há problemas relacionados ao encadeamento.
informações do aplicativo
Além do sistema, nosso aplicativo realmente se entende melhor e pode deixar muitas informações relevantes.
- Cena do acidente. Em qual
ActivityouFragment, em qual negócio ocorreu o crash. - caminho operacional crítico. Diferentemente do log de gerenciamento detalhado durante o processo de desenvolvimento, podemos registrar os principais caminhos de operação do usuário, o que nos ajudará muito na reprodução de falhas.
- Informações personalizadas adicionais. Aplicativos diferentes podem ter preocupações diferentes. Por exemplo, o Netease Cloud Music se concentrará na música que está sendo reproduzida no momento e o QQ Browser se concentrará no URL ou vídeo aberto no momento. Além disso, informações como tempo de atividade, se um patch foi carregado, se é uma nova instalação ou atualização, etc. também são muito importantes.
As informações que devem ser coletadas no local do acidente são apresentadas acima. Claro, ainda é muito complicado desenvolver tal plataforma de coleta. Na maioria dos casos, precisamos apenas acessar algumas plataformas de terceiros, como buglye Sentry. Mas através da introdução acima, podemos saber em quais informações devemos nos concentrar ao analisar falhas. Ao mesmo tempo, se os recursos da plataforma estiverem ausentes, também podemos adicionar relatórios personalizados
análise de colisão
Depois que informações suficientes são relatadas no local do acidente, podemos começar a analisar o acidente. Abaixo, apresentamos a "trilogia" da análise do acidente
Passo 1: Determine seu foco
Para confirmar e analisar os pontos-chave, a chave é encontrar informações importantes no log e ter um julgamento geral sobre o problema. De um modo geral, sugiro que você se concentre nos seguintes pontos na etapa de determinação do foco.
-
Confirme a gravidade e a prioridade . Resolver travamentos também depende de custo-benefício, damos prioridade à resolução
Topde travamentos ou que tenham grande impacto nos negócios. -
Informações básicas sobre falhas . Determine o tipo de travamento e a descrição da exceção e faça um julgamento aproximado sobre o travamento. De um modo geral, as falhas mais simples podem ser concluídas após esta etapa.
Javacolapso.JavaO tipo de falha é óbvio,NullPointerExceptioncomo um ponteiro nuloOutOfMemoryErrorou recursos insuficientes. Neste momento, você precisa verificar as "informações de memória" e "informações de recursos" no log.Nativecolapso. Precisa assistirsignal, etc, e a pilha no momento docode. Para obter uma introdução ao significado , você pode ver a introdução aos sinais de colisão. Os mais comuns são e , o primeiro é geralmente causado por ponteiros nulos e ponteiros ilegais, e o último é causado principalmente por chamadas e saídas.fault addrJavasignalSIGSEGVSIGABRTANRabort()ANR. Minha experiência é, primeiro olhe para a pilha do thread principal, se é causado por espera de bloqueio. Em seguida,ANRobserveiowait,CPU, e outras informações no registro para determinar se é um problema , um problema deGCconcorrência ou um grande número de causas para o cartão morrersystem serverI/OCPUGC
-
Logcat.LogcatGeralmente, haverá algumas pistas valiosas, e o nível de registro éWarningeErrorprecisa de atenção especial. A partirLogcatdele, podemos ver alguns comportamentos do sistema e o estado do celular naquele momento, por exemplo,ANRquando aparecer, haverá "am_anr";Appquando for morto, haverá "am_kill". Os logs produzidos por diferentes sistemas e fabricantes são diferentes. Quando você não consegue ver a causa do problema ou obter informações úteis de um log de travamento, não desista. É recomendável verificar mais logs de travamento no mesmo ponto de travamento . -
A situação de cada recurso. Combinado com as informações básicas da falha, vamos ver se está relacionado a "informações de memória" ou "informações de recursos". Por exemplo, a memória física é insuficiente, a memória virtual é insuficiente ou o identificador de arquivo está
fdvazando .
Tanto os arquivos de recursos quanto Logcatas informações relacionadas à memória e ao encadeamento requerem atenção especial, e muitas falhas são causadas por seu uso indevido.
Etapa dois: encontrar pontos em comum
Se o método acima ainda não conseguir localizar o problema com eficácia, podemos tentar descobrir se há pontos em comum nessas falhas. Uma vez que a semelhança é encontrada, as diferenças podem ser encontradas e a solução para o problema estará um passo mais perto.
Modelo, sistema, ROM, fabricante e ABI, essas informações do sistema coletadas podem ser agregadas como dimensões. Problemas comuns, como se é porque está instalado Xposed, se aparece apenas em celulares x86de , se é apenas o modelo Samsung, se é é apenas no sistema Android 5.0de . As informações do aplicativo também podem ser agregadas como dimensões, como links sendo abertos, vídeos sendo reproduzidos, países, regiões, etc. Se você encontrar algo em comum, poderá ter diretrizes mais claras para a próxima etapa para reproduzir o problema.
Etapa 3: tente reproduzir
Se já sabemos a causa do travamento, para confirmar mais informações, precisamos tentar reproduzir o travamento. Se não tivermos nenhuma pista sobre o travamento, também esperamos tentar reproduzi-lo por meio do caminho de operação do usuário e, em seguida, analisar a causa do travamento.
"Desde que possa ser reproduzido localmente, posso resolver", acredito que seja o que muitos desenvolvedores e testes disseram. Essa confiança ocorre principalmente porque, no caminho de recorrência estável, podemos usar vários meios ou ferramentas, como adicionar logs ou usá-los para análise posterior Debugger.GDB
Resolução de falha do sistema
Às vezes, algumas falhas não são causadas por nosso aplicativo, mas pelo sistema. As falhas do sistema geralmente nos fazem sentir muito impotentes. Pode ser causada por uma determinada Androidversão modificaçãobug de um determinado fabricante . A pilha de falha neste caso pode não ter nosso próprio código e é difícil localizar o problema diretamente.ROM
Para este problema difícil, podemos tentar resolvê-lo através dos seguintes métodos.
- Procure possíveis causas. Através da classificação comum acima, vamos primeiro verificar se é um problema de uma determinada versão do sistema ou um problema específico
ROMde . Embora o log de falhas possa não ter nosso próprio código, ao manipular o caminho e o log, podemos encontrar alguns pontos suspeitos. - Tente evitá-lo. Verifique as chamadas de código suspeitas, se as inapropriadas são usadas
APIe se outros métodos de implementação podem ser usados para evitá-las. Hookresolver. Depois de entender o motivo, você pode finalmenteHookmodificar a lógica do código do sistema para lidar com isso
Por exemplo, descobrimos que houve uma falha de sistema on-line Toastrelacionada , que apareceu apenas Android 7.0no sistema de , e parecia Toastque a janela tokenera inválida quando foi exibida. É possível que a janela tenha sido destruída quando Toastprecisa ser exibida.
android.view.WindowManager$BadTokenException:
at android.view.ViewRootImpl.setView(ViewRootImpl.java)
at android.view.WindowManagerGlobal.addView(WindowManagerGlobal.java)
at android.view.WindowManagerImpl.addView(WindowManagerImpl.java4)
at android.widget.Toast$TN.handleShow(Toast.java)
Android 8.0Por que o sistema não tem esse problema? Android 8.0Após verificar o código fonte do , encontramos as seguintes modificações:
try {
mWM.addView(mView, mParams);
trySendAccessibilityEvent();
} catch (WindowManager.BadTokenException e) {
/* ignore */
}
Portanto, podemos nos referir à Android 8.0sua prática e catchcapturar diretamente essa exceção. A chave aqui é encontrar Hooko ponto , Toastexiste uma variável chamada mTN, seu tipo é handler, só precisamos fazer um proxy para realizar a captura.
CrashGovernança de longo prazo
A descrição acima descreve Crashas etapas gerais para lidar com o online, mas Crasho estágio realmente importante da governança é antes de entrar online. Precisamos começar do estágio de desenvolvimento e realizar Crashuma governança sistemática de longo prazo
estágio de desenvolvimento
CrashA governança de longo prazo precisa começar no estágio de desenvolvimento. No longo prazo, uma melhor qualidade de código trará melhor estabilidade. Podemos melhorar a qualidade do código a partir das duas perspectivas a seguir
- Padrões de codificação unificados, habilidades de codificação aprimoradas, revisão técnica,
CodeReviewmecanismo aprimorado - Otimização da arquitetura, convergência de capacidade (encapsulamento de algumas operações comuns), tolerância a falhas unificada: Por exemplo, nos utilitários da biblioteca de rede, as informações retornadas são pré-verificadas uniformemente e, se forem ilegais, o próximo processo não será seguido diretamente.
fase de teste
Além dos procedimentos de teste de rotina, como teste funcional, teste automatizado, teste de regressão e instalação de sobreposição, também é necessário testar cenários especiais, modelos e outros limites: como dados anormais retornados pelo servidor, tempo de inatividade do servidor etc. .
estágio composto
- Quando nossa função é desenvolvida e está prestes a ser mesclada no ramo principal, devemos primeiro realizar a detecção de compilação e a varredura estática para encontrar possíveis problemas.
- Depois que a verificação é concluída, ela não pode ser mesclada diretamente, porque várias ramificações podem entrar em conflito; portanto, primeiro realizamos um processo de pré-compilação, ou seja, mesclamos em uma ramificação igual à ramificação principal e, em seguida, empacotamos para teste de regressão do processo principal. Após o processo passar Mesclar para o ramo principal novamente. Claro, pode ser problemático fazer isso, mas essas etapas devem ser automatizadas
fase de lançamento
- No estágio de liberação, devemos realizar várias rodadas de escala de cinza, e a escala de cinza deve mudar gradualmente de pequena para grande, de modo a expor problemas com antecedência com o menor custo
- Os lançamentos em escala de cinza também devem ser divididos em cenários e cobrir várias latitudes de forma abrangente. Escalas de cinza especiais podem ser realizadas para versões especiais, modelos, etc., para ver se os usuários com maior probabilidade de ter problemas têm problemas
Fase de operação e manutenção
- Depois de ficar online, também é necessário prestar atenção aos problemas de estabilidade, por isso depende especialmente do
APMmonitoramento sensível e do alarme oportuno quando são encontrados problemas - Se houver uma situação anormal, também é necessário reverter ou rebaixar a estratégia de acordo com a situação
- Se não puder ser revertido ou rebaixado, também pode ser reparado por hot repair. Se o hot repair falhar, ele só pode contar com a solução de recuperação de desastre local para recuperar
Construção de Soluções de Alta Disponibilidade Empresarial
Muitas pessoas pensam que a otimização da estabilidade é para reduzir Crasha taxa, mas, na verdade, outra dimensão importante da otimização da estabilidade é a alta disponibilidade do negócio.
A indisponibilidade do negócio pode não causar um travamento, mas reduzirá a experiência do usuário, o que afetará diretamente nossa receita
Construção de Soluções de Alta Disponibilidade Empresarial
- Ao contrário da alta disponibilidade de negócios
Crash, precisamos fazer a coleta de dados por nós mesmos. Precisamos classificar o processo principal, o caminho principal, os principais nós do projeto e adicionar pontos - Para coleta de dados, também podemos usar
AOPmétodos para coletar dados para reduzir o custo do gerenciamento manual. - Depois que os dados são informados, podemos criar um painel de dados e contar a taxa de conversão de cada etapa.
- Após o relatório de dados, também podemos estabelecer estratégias de alarme, como alarmes de limite, alarmes de tendência (comparados com o mesmo período) e alarmes de indicadores específicos (como falhas de pagamento)
- Ao mesmo tempo, podemos fazer algum trabalho de monitoramento anormal, como
Catchrelatar anormalidades e lógica anormal. Embora essas anormalidades não falhem, elas também são o que precisamos prestar atenção. - Para alguns problemas difíceis de resolver, podemos usar o método de recuperação completa de log para usuários específicos para coletar mais informações.
- Depois de descobrir a anormalidade, podemos resolver o problema por meio de algumas estratégias de vaivém, como suporte para habilitar ou desabilitar o interruptor de função por meio do centro de configuração. Quando encontramos um problema com uma nova função, podemos ocultar diretamente o função, ou configurar a rota. pular para outro caminho
Solução de recuperação de desastres do cliente
Depois que ocorre uma exceção de desempenho ou de negócios, como devemos resolvê-la? O processo tradicional precisa passar por várias etapas, como feedback do usuário, reempacotamento e atualização do canal. Pode-se ver que, na verdade, é mais problemático e menos responsivo aos usuários. Podemos criar uma solução de recuperação de desastres para o cliente a partir das seguintes
perspectivas
- Para funções recém-adicionadas ou refatoração de código, há suporte para configurar o switch por meio do centro de configuração e pode ser fechado a tempo se ocorrer um problema
- Ao mesmo tempo, se todas as nossas
Apppáginas forem redirecionadas por meio de roteamento, podemos pular para a página unificada de tratamento de erros configurando dinamicamente o roteamento ou pular para a página h5 temporária - Repare por meio da tecnologia de reparo a quente
BUG, como acessar TencentTinkerou Meituan,Robustetc. - Se o seu projeto usa
RNouWeex, você pode implementar atualizações incrementais diretamente - Se a falha ocorrer na inicialização
APP, a atualização dinâmica e a configuração dinâmica serão inválidas neste momento, e o modo de segurança precisa ser usado neste momento. O modo de segurançaCrashé restaurado automaticamente de acordo com as informações e redefine o aplicativo para o estado inicial da instalação após várias falhas de inicialização. Se for particularmente graveBug, também pode ser resolvido bloqueando o reparo a quente, ou seja, somente depois que o reparo a quente for bem-sucedido, ele poderá ser inseridoAPP. O modo de segurança pode ser usado não apenas paraAPPcomponentes, mas também para componentes. Se um componente relatar um erro várias vezes, você pode entrar na página inferior
Perguntas comuns da entrevista sobre otimização de estabilidade
A seguir, apresentamos as perguntas simuladas da entrevista para otimização da estabilidade
Que otimizações de estabilidade você fez?
Resposta de referência:
Com o amadurecimento gradual do projeto, a base de usuários aumentou gradativamente e DAUcontinuou aumentando. Encontramos muitos problemas de estabilidade. Para nossos alunos técnicos, encontramos muitos desafios. Os usuários costumam usar nossos Appcongelamentos ou funções não estão disponíveis, por isso, iniciamos uma otimização especial para estabilidade e otimizamos principalmente três itens:
CrashOtimização especial- Otimização da estabilidade de desempenho
- Otimização da estabilidade do negócio
Através da otimização desses três aspectos, construímos uma plataforma de alta disponibilidade para terminais móveis. Ao mesmo tempo, muitas medidas foram tomadas para Appalcançar realmente alta disponibilidade.
Como é feita a estabilidade de desempenho?
Resposta de referência:
- Otimização de desempenho abrangente: velocidade de inicialização, otimização de memória, otimização de desenho
- Encontre problemas off-line e concentre-se na otimização
- Monitoramento principalmente online
CrashOtimização especial
Fizemos otimizações multidimensionais em termos de velocidade de inicialização, memória, carregamento de layout, congelamento, emagrecimento, tráfego e energia.
Nossa otimização é dividida principalmente em dois níveis, ou seja, online e offline. Para offline, focamos em encontrar problemas e resolvê-los diretamente, visando resolver os problemas o máximo possível antes de entrar no online. Quando se trata da linha real, nosso principal objetivo é monitorar. Para o monitoramento de várias latitudes de desempenho, podemos obter o alarme de situações anormais o mais cedo possível.
Ao mesmo tempo, para o problema de desempenho online mais sério: Crash, fizemos uma otimização especial, não apenas otimizando Crashos indicadores específicos, mas também obtendo o Crashmáximo de informações detalhadas possíveis quando ocorreu, combinada com agregação de back-end, alarme e outras funções, para que possamos localizar rapidamente o problema.
Como garantir a estabilidade do negócio?
Resposta de referência:
- Aquisição de Dados + Alarme
- É necessário monitorar o processo principal e o caminho principal do projeto,
- Ao mesmo tempo, também precisamos saber quantas exceções ocorreram em cada etapa, para sabermos a taxa de conversão de todos os processos de negócios e a taxa de conversão da interface correspondente
- Combinado com o mercado, se a taxa de conversão for inferior a um determinado valor, será emitido um alarme
- Monitoramento anormal + rastreamento de ponto único
- Estratégias de ida e volta, como o modelo de segurança Tmall
A alta disponibilidade dos serviços móveis foca na total disponibilidade das funções do usuário, principalmente para resolver algumas anormalidades online que fazem com que os usuários não tenham travamentos ou problemas de desempenho, mas é apenas uma função simples que não está disponível. e core path do projeto são monitorados em pontos enterrados para calcular a taxa de conversão real de cada etapa.Ao mesmo tempo, também é necessário saber quantas exceções ocorreram em cada etapa. Desta forma, conhecemos a taxa de conversão de todos os processos de negócios e a taxa de conversão da interface correspondente. Com os dados do mercado, sabemos que se a taxa de conversão ou a taxa de sucesso de algum monitoramento for inferior a um determinado valor, é muito importante. Pode ser que haja uma anormalidade online. Combinado com a função de alarme correspondente, não precisamos esperar que os usuários dêem feedback. Esta é a base para a garantia de estabilidade do negócio.
Ao mesmo tempo, para alguns casos especiais, por exemplo, alguns blocos de código aparecem durante o processo de desenvolvimento ou no código, catche a exceção é capturada para que o programa não trave. Isso é realmente irracional. Embora o programa não trave , a função do programa naquele momento já ficou indisponível, então catchtambém precisamos relatar essas anormalidades, para que possamos saber quais problemas o usuário causou a anormalidade. Além disso, existem alguns problemas de ponto único online. Por exemplo, os usuários não podem fazer login depois de clicar no botão de login. Este é um problema de ponto único. Na verdade, não podemos descobrir a semelhança entre ele e outros problemas. é necessário encontrar seus detalhes correspondentes.
Finalmente, se ocorrer uma situação anormal, também adotamos uma série de medidas para interromper rapidamente a perda.
Se ocorrer uma situação anormal, como interromper rapidamente a perda?
Resposta de referência:
- interruptor de função
- centro de salto
- Correções dinâmicas: hot fixes, atualizações de pacotes de recursos
- Autocorreção: modo de segurança
Antes de tudo, ele precisa ter Appalguns recursos avançados. Para que qualquer nova função seja lançada, precisamos adicionar um switch de função. O switch emitido pelo centro de configuração determina se deve exibir a entrada da nova função. Se houver uma situação anormal, a entrada da nova função pode ser fechada com urgência, para que esta seja mantida Appem um estado controlável.
Em seguida, precisamos Appconfigurar saltos de roteamento. Todos os saltos de interface precisam ser distribuídos por meio de roteamento. Se correspondermos a uma nova função que precisa pular para bugalgum , não pularemos ou pularemos para a interface unificada de tratamento de exceções. Se esses dois métodos não forem possíveis, você pode considerar o reparo dinâmico por meio do reparo a quente. A solução atual de reparo a quente é relativamente madura. Podemos adicionar recursos de reparo a quente a nossos projetos a baixo custo. Claro, seria melhor RNou , a atualização dinâmica pode ser realizada atualizando o pacote de recursos. WeeXE se nada disso for possível, você pode considerar adicionar um recurso de autorreparo ao aplicativo. Se você Appiniciá-lo várias vezes, considere limpar todos os dados em cache e Appredefini-los para o estado instalado. O nível mais grave pode bloqueie o thread principal. Neste momento, os usuários devem esperar que Appo hotfix seja bem-sucedido antes de permitir que os usuários entrem.
Resumir
Este artigo apresenta principalmente Androido entendimento correto da estabilidade, como lidar com ela Crash, Crashgovernança de longo prazo, construção de soluções de negócios de alta disponibilidade, etc., e apresenta algumas ideias e soluções para otimização da estabilidade.
Quando estivermos em otimização e monitoramento de desempenho, você descobrirá que existem muitos pontos de conhecimento relacionados ao Framework subjacente. Portanto, ao aprender otimização e monitoramento de desempenho, também precisamos aprender e entender os princípios subjacentes do Framework. Para referência:
Notas do estudo de ajuste de desempenho do Android:https://qr18.cn/FVlo89
