Índice
A diferença entre RDD e DataFrame:
Converter RDD em DataFrame e DataFrame em RDD
DataFrame para DataSet e DataSet para DataFrame
RDD para DataSet e DataSet para RDD
A relação entre RDD, DataFrame e DataSet
Características comuns entre os três
2. Função agregada definida pelo usuário (tipo fraco)
Métodos universais de carregamento e salvamento
Visão geral do SparkSQL
O que é SparkSQL
Spark SQL é um módulo usado pelo Spark para processar dados estruturados. Ele fornece 2 abstrações de programação: DataFrame e
DataSet e funciona como um mecanismo de consulta SQL distribuído.
Recursos do Spark SQL
(1), fácil de integrar
Combine perfeitamente consultas SQL com programas Spark
(2) Método unificado de acesso a dados
Conecte-se a qualquer fonte de dados da mesma maneira
(3), compatível com Hive
Execute consultas SQL ou HiveQL no warehouse existente
(4), conexão de dados padrão
Conecte-se via JDBC ou ODBC
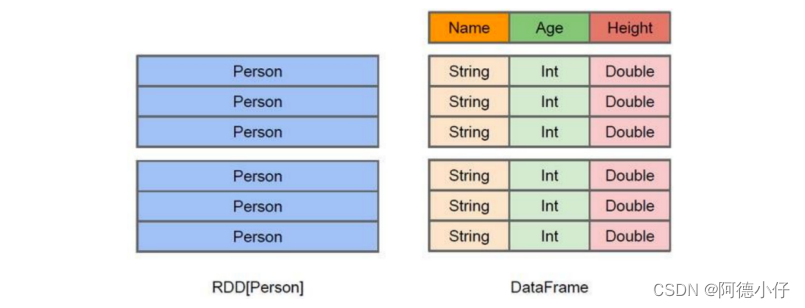
O que é DataFrame
Semelhante ao RDD, o DataFrame também é um contêiner de dados distribuído. No entanto, o DataFrame é mais parecido com uma tabela bidimensional em um banco de dados tradicional.
O Grid, além dos dados, também registra as informações estruturais dos dados, ou seja, esquema. Ao mesmo tempo, semelhante ao Hive, o DataFrame também suporta
Suporta tipos de dados aninhados (struct, array e map). Do ponto de vista da facilidade de uso da API, a API DataFrame fornece
Um conjunto de operações relacionais de alto nível é mais amigável e tem um limite mais baixo do que a API RDD funcional.
A diferença entre RDD e DataFrame :
exemplo:
usuários
.
join
(
eventos
,
usuários
(
"id"
)
===
eventos
(
"uid"
)).
filtro
(
eventos
(
"data"
)
>
"2022-01-01"
)

O que é DataSet
DataSet é uma coleção de dados distribuída. DataSet é uma nova abstração adicionada no Spark1.6 e uma extensão do DataFrame.
exibição. Ele fornece as vantagens dos RDDs (tipagem forte, capacidade de usar funções lambda poderosas), bem como execução otimizada do SparkSQL
As vantagens do motor. DataSets também podem usar transformações funcionais (mapa operacional, flatMap, filtro, etc.).
(1), é uma extensão da API Dataframe e é a mais recente abstração de dados do Spark.
(2) Estilo de API amigável, com verificação de segurança de tipo e recursos de otimização de consulta Dataframe.
(3) O conjunto de dados suporta codecs. Quando você precisa acessar dados não heap, pode evitar a desserialização de todo o objeto e melhorar a eficiência.
Avaliar.
(4). A classe de amostra é usada para definir as informações estruturais dos dados no conjunto de dados. O nome de cada atributo na classe de amostra é mapeado diretamente para
O nome do campo no DataSet.
(5) Dataframe é uma coluna especial do Dataset, DataFrame=Dataset[Row], então você pode usar o método as para
Dataframe é convertido em Dataset. Row é um tipo, assim como Car e Person. Todas as informações da estrutura da tabela
Eu uso Row para representar informações. (6), DataSet é fortemente tipado. Por exemplo, pode haver Dataset[Car], Dataset[Person].
(7) O DataFrame conhece apenas os campos, mas não conhece os tipos dos campos, portanto não pode ser utilizado na execução dessas operações.
Verifique se o tipo falha durante a compilação. Por exemplo, você pode realizar uma operação de subtração em uma String e relatá-la apenas durante a execução.
Errado, e o DataSet não apenas conhece os campos, mas também os tipos de campo, portanto, possui uma verificação de erros mais rigorosa. Assim como JSON
Analogia entre elefantes e objetos de classe.
Programação SparkSQL
novo ponto de partida
Na versão antiga, o SparkSQL fornece dois pontos de partida para consultas SQL: um é chamado SQLContext, que é usado pelo próprio Spark.
Consultas SQL fornecidas; um HiveContext usado para conectar-se a consultas do Hive.
SparkSession é o ponto de partida de consulta SQL mais recente do Spark. É essencialmente uma combinação de SQLContext e HiveContext.
Portanto, as APIs disponíveis no SQLContext e no HiveContext também estão disponíveis no SparkSession.
SparkSession encapsula sparkContext internamente, então os cálculos são realmente concluídos por sparkContext.
Quadro de dados
A API DataFrame do SparkSQL nos permite usar DataFrames sem precisar registrar tabelas temporárias ou produzir SQL
expressão. A API DataFrame possui operações de transformação e operações de ação.
criar
No Spark SQL, SparkSession é o ponto de entrada para criar DataFrame e executar SQL.
DataFrame vem de três maneiras:
(1) Criar por meio da fonte de dados Spark;
(2) Converter de um RDD existente;
(3) Você também pode consultar e retornar da Tabela Hive.
Criar a partir da fonte de dados do Spark
//1 . Visualize o formato de arquivo criado pela fonte de dados Spark//spark.read.//2 . Leia o arquivo json para criar DataFrame// Cria um arquivo user.jsonval df = spark.read.json("/usr/local/soft/data/user.json")//3 . Exibir resultadosdf.showdf.createTempView("usuário")spark.sql("selecione * do usuário").show
Nota: Se você obtiver dados da memória, o Spark poderá saber qual é o tipo de dados. Se for um número, padrão
É tratado como Int; entretanto, o tipo do número lido do arquivo não pode ser determinado e o índice é recebido usando bigint.
Ele pode ser convertido para o tipo Long, mas não pode ser convertido para Int.
- Converter de um RDD existente (explicado mais tarde)
- Você também pode consultar e retornar da Tabela Hive (explicado mais tarde)
Sintaxe SQL
O estilo de sintaxe SQL significa que usamos instruções SQL ao consultar dados. Este estilo de consulta deve ter
Visão temporária ou visão global para auxiliar.
(1), leia o arquivo JSON para criar DataFrame
val df = spark.read.json("/usr/local/soft/data/user.json")
(2) Crie uma tabela temporária para o DataFrame
df.createOrReplaceTempView("pessoas")
Nota: A diferença entre View e tabela é que View não pode ser modificada e só pode ser consultada, enquanto a tabela pode ser adicionada, excluída, modificada e consultada.
(3) Consulte a tabela inteira por meio de instruções SQL
spark.sql("selecione * de pessoas").show
(4), Exibição de resultados
df.show
Nota: Tabelas temporárias comuns estão dentro do escopo da Sessão. Se você quiser ser válido no escopo da aplicação, você pode usar tabelas temporárias globais.
superfície. Ao usar tabelas temporárias globais, é necessário acesso ao caminho completo, como: global_temp.people
spark.newSession.sql("select * from people").show 报错
(5)
Crie uma tabela global
para
DataFrame
df.createOrReplaceGlobalTempView("pessoas")df.createGlobalTempView("pessoas")spark.newSession.sql("selecione * de global_temp.people").show
Sintaxe DSL
DataFrame fornece uma linguagem específica de domínio (DSL) para gerenciar dados estruturados. Pode ser usado em Scala, Java,
DSL é usado em Python e R. Usar o estilo de sintaxe DSL elimina a necessidade de criar visualizações temporárias.
(1), crie um DataFrame
val df = spark.read.json("/usr/local/soft/data/user.json")
(2) Visualizar as informações do esquema do DataFrame
df.printSchem
(3), visualize apenas os dados da coluna "idade"
//df. //tecla tab para visualizar os métodos em dfdf.select("idade").show()
(4) Visualize os dados da coluna "nome de usuário" e os dados de "idade + 1"
df.select("idade" + 1).show() // relatório de errodf.select($"idade" + 1).show()df.select('idade + 1).show()df.select($"nome de usuário",$"idade" + 1).show()df.select($"username",$"age" + 1 as "newage").show() // 取别名
Nota: Quando se trata de operações, cada coluna deve usar $, ou usar uma expressão entre aspas: aspas simples + nome do campo
(5). Visualizar dados com "idade" maior que "30"
df.filter($"idade" > 20).show()df.filter($"idade" > 30).show()
(6) Agrupe por "idade" para visualizar o número de itens de dados
df.groupBy("idade").count.show()
Converter RDD em DataFrame e DataFrame em RDD
Ao desenvolver em IDE, se você precisar operar entre RDD e DF ou DS, será necessário introduzir a importação.
faísca.implícitos._
O spark aqui não é o nome do pacote em scala, mas o nome da variável no objeto sparkSession criado, portanto deve
O objeto SparkSession deve ser criado primeiro e depois importado. O objeto spark aqui não pode ser declarado usando var porque apenas Scala
Apoie a introdução de objetos modificados por val.
Nota: Nenhuma importação é necessária no spark-shell, isso é feito automaticamente.
val rdd = sc.makeRDD(Lista(1,2,3,4))//rdd. //tecla tab para visualizar todos os métodos do rddval df = rdd.toDF("id")df.show()//df. // Tecla Tab para visualizar todos os métodos do dfdf.rdd
Conjunto de dados
DataSet é uma coleção de dados fortemente tipada e as informações de tipo correspondentes precisam ser fornecidas.
CriarDataSet _
(1) Crie um DataSet usando a sequência de classes de exemplo
//classe de caso Pessoa(nome:String,idade:Long)lista val = Lista(Pesso("zhangsan",30),Pessoa("lisi",20))val ds = lista.toDSds.show
DataFrame para DataSet e DataSet para DataFrame
//df // Verifica se df existe//classe de caso Emp(idade:Long,nome de usuário:String)//val ds = df.as[Emp]//ds.show()//ds. // Método de visualização da tecla Tab//ds.toDF
RDD para DataSet e DataSet para RDD
val rdd = sc.makeRDD(List(Emp(30,"zhangsan"),Emp(20,"lisi")))rdd.toDS// Pré-requisito: Deve ser uma classe de amostra para preparar o tipoval rdd = sc.makeRDD(Lista(1,2,3,4))rdd.toDSval rdd = sc.makeRDD(List(Emp(30,"zhangsan"),Emp(20,"lisi")))val ds = rdd.toDSval rdd1 = ds.rdd
A relação entre RDD , DataFrame e DataSet
No SarpkSQL, o Spark nos fornece duas novas abstrações, nomeadamente DataFrame e DataSet.
Diferença de versão
De acordo com a versão:
Spark1.0 ----> RDD
Spark1.3 ---->DataFrame
Spark1.6 ----> Conjunto de dados
Se os mesmos dados forem fornecidos a essas três estruturas de dados, elas darão o mesmo resultado após o cálculo, respectivamente. a diferença é
Com que eficiência e como eles são executados. Em versões posteriores do Spark, o DataSet pode substituir gradualmente o RDD e
DataFrame se torna a única interface API.
Características comuns entre os três
1. RDD, DataFrame e Dataset são todos conjuntos de dados elásticos distribuídos na plataforma Spark e são projetados para processar dados extremamente grandes.
A conveniência é fornecida.
2. Todos os três têm um mecanismo lento. Ao criar e converter, como o método map, eles não serão executados imediatamente. Eles só serão executados quando encontrarem
Quando Action for como foreach, os três iniciarão a operação de travessia.
3. Todos os três armazenarão em cache automaticamente as operações de acordo com a memória do Spark, portanto, mesmo que a quantidade de dados seja grande, não há necessidade de se preocupar em ficar sem memória.
transbordar.
4. Todos os três possuem o conceito de partição.
5. Os três têm muitas funções comuns, como filtro, classificação, etc.
6. Muitas operações em DataFrame e Dataset requerem suporte deste pacote: importação
spark.implicits._。
7. Tanto o DataFrame quanto o Dataset podem usar correspondência de padrões para obter o valor e o tipo de cada campo.
A diferença entre os três
1.RDD:
(1) RDD é geralmente usado junto com spark mlib
(2) RDD não suporta operações sparksql
2.DataFrame:
(1). Ao contrário do RDD e do Dataset, o tipo de cada linha do DataFrame é fixado em Row e o valor de cada coluna não pode ser diretamente
Acesso, o valor de cada campo só pode ser obtido através de análise.
(2) DataFrame e Dataset geralmente não são usados junto com spark mlib.
(3), DataFrame e Dataset suportam operações sparksql, como select, groupby, etc., e também podem observar
Registre a tabela/janela temporária e execute operações de instrução SQL.
(4) DataFrame e Dataset suportam alguns métodos de salvamento particularmente convenientes, como salvar em csv, que podem ser trazidos com tabelas
cabeçalho para que os nomes dos campos de cada coluna fiquem claros à primeira vista.
3.Conjunto de dados:
(1), Dataset e DataFrame têm exatamente as mesmas funções de membro, a única diferença é o tipo de dados de cada linha.
(2) DataFrame também pode ser chamado de Dataset[Row]. O tipo de cada linha é Row. Não é analisado. O que exatamente cada linha tem?
Não há como saber os tipos de campos e os tipos de cada campo, você só pode usar o método getAS mencionado acima ou o sétimo ponto em comum.
O padrão mencionado corresponde para destacar campos específicos. No conjunto de dados, o tipo de cada linha não é certo. Ao personalizar
Após adicionar a classe de caso, você pode obter livremente as informações de cada linha.
IDEA cria programa SparkSQL
No desenvolvimento real, IDEA é usado para desenvolvimento. Os métodos de empacotamento e execução de programas no IDEA são iguais aos do SparkCore
Da mesma forma, novas dependências precisam ser adicionadas às dependências do Maven:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql --><dependência><groupId> org.apache.spark </groupId><artifactId> spark-sql_2.12 </artifactId><versão > 2.4.5 </versão></dependency>
package com.shujia.core.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Demo01_SparkSql {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkSql")
// new SparkSession() //表示没有构造器在这可以访问
//原因:构造方法私有化,所以在外面不能直接访问
val spark: SparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
//builder()构建器构建对象,使用getOrCreate()构建,获取或创建//注意:创建环境的时候需要告知连的是什么,通过config()将配置对象传进去
//在使用DataFrame时,如果设计到转换操作,需要引入转换规则
import spark.implicits._
//TODO 执行逻辑操作
//DataFrame
// val df: DataFrame = spark
// .read
// .json("data/user.json")
// df.show()
//DataFrame =>SQL
// df.createOrReplaceTempView("user")
//
// spark.sql(
// """
// |select * from user
// |""".stripMargin)
// .show()
//
// spark.sql(
// """
// |select age from user
// |""".stripMargin)
// .show()
//
// spark.sql(
// """
// |select avg(age) from user
// |""".stripMargin)
// .show()
//DataFrame =>DSL
//在使用DataFrame时,如果设计到转换操作,需要引入转换规则
// import spark.implicits._
// df.select("age","username").show
// df.select($"age"+ 1 ).show
// df.select('age + 1).show
//TODO DataSet
//DataFrame其实就是特定泛型到DataSet
// val seq: Seq[Int] = Seq(1, 2, 3, 4)
// val ds: Dataset[Int] = seq.toDS()
// ds.show()
//RDD <=> DataFrame
val rdd: RDD[(Int, String, Int)] =
spark.sparkContext.makeRDD(List((1,"zhangsan",20),(2,"lisi",21),
(1,"wangwu",23)))
val df: DataFrame = rdd.toDF("id","name","age")
df.show()
val rdd1: RDD[Row] = df.rddrdd1.foreach(println)
//DataFrame <=> DataSet
val ds: Dataset[User] = df.as[User]
ds.show()
val df1: DataFrame = ds.toDF("id","name","age")
df1.show()
//RDD <=> DataSet
//DataSet:有数据有类型有结构
val ds2: Dataset[User] = rdd.map {
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
ds2.show()
val rdd2: RDD[User] = ds2.rdd
rdd2.foreach(println)
//TODO 关闭环境
spark.close()
}
case class User (id:Int,name:String,age:Int)
}função definida pelo usuário
Os usuários podem adicionar funções personalizadas por meio da função spark.udf para implementar funções personalizadas.
UDF
1. Crie DataFrame
package com.shujia.core.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Demo02_SparkSql_UDF {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkSql")
val spark: SparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
//TODO 执行逻辑操作
val df: DataFrame = spark.read.json("data/user.json")
df.createOrReplaceTempView("user")// spark.sql(
// """
// |select age,"name" + username from user
// |""".stripMargin)
// .show()
spark.udf.register("prefixName",(name:String) =>{
"name:"+ name
})
spark.sql(
"""
|select age,prefixName(username) from user
|""".stripMargin)
.show()
//TODO 关闭环境
spark.close()
}
}
Tanto o DataSet de tipo forte quanto o DataFrame de tipo fraco fornecem funções agregadas relacionadas, como count(),
contagemDistinta(),avg(),max(),min(). Além disso, os usuários podem definir suas próprias funções agregadas personalizadas. seguindo
Herda UserDefinedAggregateFunction para implementar funções agregadas de tipo fraco definidas pelo usuário. Da versão Spark3.0
UserDefinedAggregateFunction não é mais recomendado.Funções agregadas fortemente digitadas podem ser usadas uniformemente.
Agregador.
2. Função agregada definida pelo usuário (tipo fraco)
package com.shujia.core.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.{MutableAggregationBuffer,
UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField,
StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object Demo03_SparkSql_UDAF {
def main(args: Array[String]): Unit = {//TODO 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkSql")
val spark: SparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
//TODO 执行逻辑操作
val df: DataFrame = spark.read.json("data/user.json")
df.createOrReplaceTempView("user")
spark.udf.register("ageAvg",new MyAvgUDAF)
spark.sql(
"""
|select ageAvg(age) from user
|""".stripMargin)
.show()
//TODO 关闭环境
spark.close()
}
/**
* 自定义聚合函数类:计算年龄的平均值
* 1、继承UserDefinedAggregateFunction
* 2、重写方法(8)
*
*/
class MyAvgUDAF extends UserDefinedAggregateFunction{
//输入数据的结构 IN
override def inputSchema: StructType = {
StructType(
Array(
StructField("age",LongType)
)
)
}
//缓冲区的结构 Buffer
override def bufferSchema: StructType = {
StructType(
Array(
//所有年龄的和
StructField("total",LongType) ,
//所有年龄出现的次数
StructField("count",LongType)
)
)
}
//函数计算结果的数据类型:Out
override def dataType: DataType = LongType//函数的稳定性
override def deterministic: Boolean = true
//缓冲区初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer.update(0,0L)
buffer.update(1,0L)
}
//根据输入的值更新缓冲区数据
override def update(buffer: MutableAggregationBuffer, input: Row):
Unit = {
//buffer.getLong(0)缓冲区之前的值 + input.getLong(0)输入的值
buffer.update(0,buffer.getLong(0) + input.getLong(0))
buffer.update(1,buffer.getLong(1) + 1)
}
//缓冲区数据合并
override def merge(buffer1: MutableAggregationBuffer, buffer2:
Row): Unit = {
//x y
//1 2 3 4
//x+y===>x
//x y
//3 3 4
//x+y===>x
//x y
//6 4
//x+y===>x
buffer1.update(0,buffer1.getLong(0) + buffer2.getLong(0))
buffer1.update(1,buffer1.getLong(1) + buffer2.getLong(1))
}
//计算平均值
override def evaluate(buffer: Row): Any = {
buffer.getLong(0) / buffer.getLong(1)
}
}
}
(用户自定义聚合函数(Spark3.0.0以下版本的强类型)
package com.shujia.core.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.{Aggregator,
MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField,
StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Encoder, Encoders,
Row, SparkSession, TypedColumn}
object Demo03_SparkSql_UDAF2 {def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkSql")
val spark: SparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
//TODO 执行逻辑操作
val df: DataFrame = spark.read.json("data/user.json")
//在Spark3.0.0以下的版本,也就是我们所用的版本是不能在sql中使用强类型UDAF操作
//SQL & DSL
//Spark3.0.0以下的版本,强类型UDAF聚合函数使用DSL语法操作
val ds: Dataset[User] = df.as[User]
//将UDAF函数转为查询的列对象
val udaf: TypedColumn[User, Long] = new MyAvgUDAF().toColumn
//查询
ds.select(udaf).show()
//TODO 关闭环境
spark.close()
}
/**
* 自定义聚合函数类:计算年龄的平均值
* 1、继承UserDefinedAggregateFunction
* 2、重写方法(8)
*
*/
case class User(username:String,age:BigInt)
/**
* 自定义聚合函数类:计算年龄的平均值
* 1、继承 org.apache.spark.sql.expressions.Aggregator,定义泛型
* IN:输入的数据类型 User
* BUF:缓冲区的数据类型
* OUT:输出的数据类型 Long
* 2、重写方法(6)
*
*/
case class Buff(var total:Long,var count:Long)
class MyAvgUDAF extends Aggregator[User,Buff,Long]{
// z & zero都为初始值或零值
//缓冲区的初始化
override def zero: Buff = {
Buff(0L,0L)
}
//根据输入的数据更新缓冲区数据override def reduce(buff: Buff, in: User): Buff = {
buff.total = buff.total + in.age.toInt
buff.count = buff.count + 1
buff
}
//合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
//计算结果
override def finish(buff: Buff): Long = {
buff.total / buff.count
}
//缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product
//输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}
Função agregada definida pelo usuário (tipo forte em spark3.0.0 ou superior)
Nota:
Spark3.0.0
não possui
funções.udaf
.Se quiser usá-lo, você precisa modificar
a versão do spark no arquivo
pom
.
package com.shujia.core.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{DataFrame, Encoder, Encoders,
SparkSession, functions}
object Demo04_SparkSql_UDAF1 {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkSql")
val spark: SparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
//TODO 执行逻辑操作
val df: DataFrame = spark.read.json("data/user.json")
df.createOrReplaceTempView("user")spark.udf.register("ageAvg", functions.udaf(new MyAvgUDAF))
spark.sql(
"""
|select ageAvg(age) from user
|""".stripMargin)
.show()
//TODO 关闭环境
spark.close()
}
/**
* 自定义聚合函数类:计算年龄的平均值
* 1、继承 org.apache.spark.sql.expressions.Aggregator,定义泛型
* IN:输入的数据类型 Long
* BUF:缓冲区的数据类型
* OUT:输出的数据类型 Long
* 2、重写方法(6)
*
*/
case class Buff(var total:Long,var count:Long)
class MyAvgUDAF extends Aggregator[Long,Buff,Long]{
// z & zero都为初始值或零值
//缓冲区的初始化
override def zero: Buff = {
Buff(0L,0L)
}
//根据输入的数据更新缓冲区数据
override def reduce(buff: Buff, in: Long): Buff = {
buff.total = buff.total + in
buff.count = buff.count + 1
buff
}
//合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
//计算结果
override def finish(buff: Buff): Long = {
buff.total / buff.count
}
//缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product//输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}Carregando e salvando dados
Métodos universais de carregamento e salvamento
SparkSQL fornece uma maneira comum de salvar e carregar dados. Comum aqui refere-se ao uso da mesma API, root
Leia e salve dados em diferentes formatos de acordo com diferentes parâmetros. O formato de arquivo padrão lido e salvo pelo SparkSQL é:
parquete。
(1) Carregar dados
spark.read.load é um método geral para carregar dadosspark .read . // método de visualização da tecla tab
Se você ler dados em formatos diferentes, poderá definir formatos de dados diferentes.
faísca . leia . formato ( "..." )[. opção ( "..." )]. carregar ( "..." )
1. format("..."): Especifique o tipo de dados a ser carregado, incluindo "csv", "jdbc", "json", "orc", "parquet" e "textFile".
2. load("..."): Nos formatos "csv", "jdbc", "json", "orc", "parquet" e "textFile", é necessário passar o caminho para carregar os dados.
3. opção("..."): No formato "jdbc", você precisa passar os parâmetros JDBC correspondentes, url, usuário, senha e dbtable. Usamos a API de leitura para carregar o arquivo no DataFrame primeiro e em seguida, consulte-o. Na verdade, também podemos consultar diretamente no arquivo:
// Formato do arquivo.`Caminho do arquivo` _// Carregar user.json para HDFS _//hadoop fs -put user.json/dadosfaísca . sql ( "selecione * de json.`data/user.json`" ). mostrar
(2)
Salvar dados
df.write.save é um método geral para salvar dadosdf .write . // Método de visualização da tecla Tabdf . escreva . formato ( "json" ). salvar ( "/dados/saída1" )
Se você salvar dados em formatos diferentes, poderá definir formatos de dados diferentes.
df . escreva . formato ( "..." )[. opção ( "..." )]. salvar ( "..." )
1. format("..."): Especifica o tipo de dados a ser carregado, incluindo
Como "csv", "jdbc", "json", "orc", "parquet" e "textFile"。
2. load("..."): precisa ser passado nos formatos "csv", "jdbc", "json", "orc", "parquet" e "textFile"
Insira o caminho para carregar os dados.
3. opção("..."): No formato "jdbc", você precisa passar os parâmetros JDBC correspondentes, url, usuário, senha e
A operação de salvamento dbtable pode usar SaveMode para especificar como processar os dados. Use o método mode() para definir
Definir.
Nota: Esses SaveMode não estão bloqueados e não são operações atômicas.
SaveMode é uma classe de enumeração cujas constantes incluem:

df . escreva . modo ( "anexar" ). json ( "dados/saída1" )df . escreva . modo ( “sobrescrever” ). json ( "dados/saída1" )df . escreva . modo ( "ignorar" ). json ( "dados/saída1" )
parquete
A fonte de dados padrão do SparkSQL é o formato parquet. parquet é um armazenamento colunar que pode armazenar dados aninhados com eficiência
Formatar.
Quando a fonte de dados é um arquivo parquet, o SparkSQL pode executar facilmente todas as operações sem usar formato. Rever
O item de configuração spark.sql.sources.default pode modificar o formato da fonte de dados padrão.
(1) Carregar dados
// Envia arquivos para HDFS//hadoop fs -put users.parquet /dataval df = faísca . leia . carregar ( "/data/users.parquet" )df . mostrar
(2)Salvar dados
val df = faísca . leia . json ( "dados/usuário.json" )df . escreva . modo ( "anexar" ). salvar ( "/dados/saída2" )
JSON
SparkSQL pode inferir automaticamente a estrutura de um conjunto de dados JSON e carregá-lo como um DataSet[ROW]. capaz de passar
SparkSession.read.json() para carregar arquivos JSON.
Nota: O arquivo JSON lido pelo Spark não é um arquivo JSON tradicional. Cada linha deve ser uma string JSON. O formato é como
Abaixo:
{ "nome" : "zhangsan" }{ "nome" : "lisi" , "idade" : 21 }{ "nome" : "wangwu" , "idade" : 24 },{ "nome" : "zhaoliu" , "idade" : 23 }
(1)Importar conversão implícita
importar faísca . implícitos . _
(2) Carregar arquivo JSON
val caminho = "dados/user.json"val userDF = faísca . leia . json ( caminho )
(3) Crie uma tabela temporária
usuárioDF . createOrReplaceTempView ( "usuário" )
(4) Consulta de dados
faísca . sql ( "selecione * do usuário" ). mostrar
CSV
SparkSQL pode configurar as informações da lista do arquivo CSV, ler o arquivo CSV e definir a primeira linha do arquivo CSV como a coluna de dados
.
// Envia arquivos para HDFS//hadoop fs -put people.csv /datavalor df_csv =faísca . leia . formato ( "csv" ). opção ( "seq" , ";" ). opção ( "inferSchema" , "true" ). opção ( "cabeçalho" , "true" ). carregar ( "/data/people.csv" )
MySQL
SparkSQL pode criar um DataFrame lendo dados de um banco de dados relacional por meio de JDBC.
Após uma série de cálculos no DataFrame, os dados podem ser gravados de volta no banco de dados relacional. Se estiver usando a operação spark-shell
Para fazer isso, você pode especificar o caminho do driver de banco de dados relevante ao iniciar o shell ou colocar o driver de banco de dados relevante na classe Spark.
sob o caminho
.
bin / faísca - concha--jars mysql - conector - java - 5.1 . 27 caixas . _ jarra
Operamos Mysql através de JDBC no IDEA.
(1) Importar dependências
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependência><groupId> mysql </groupId><artifactId> mysql-connector-java </artifactId><versão > 5.1.49 </versão></dependency>
(2) Ler dados
package com.shujia.core.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql._
object Demo05_SparkSql_JDBC {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkSql")
val spark: SparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
//TODO 执行逻辑操作
//读取mysql数据
val df: DataFrame = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://master:3306/dtt_data")
//注意mysql5.7用:com.mysql.jdbc.Driver
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "student")
.load()
// df.show()
df.write
.format("jdbc")
.option("url","jdbc:mysql://master:3306/dtt_data")
.option("driver","com.mysql.jdbc.Driver")
.option("user","root")
.option("password","123456")
.option("dbtable","student_1")
.mode(SaveMode.Append)
.save()
//TODO 关闭环境
spark.close()
}
}Colmeia
ApacheHive é o mecanismo SQL no Hadoop. SparkSQL pode ser compilado com ou sem suporte Hive.
SparkSQL incluindo suporte Hive pode suportar acesso Hive, UDF (função definida pelo usuário) e linguagem de consulta Hive
(HiveQL/HQL) etc. Uma coisa que precisa ser enfatizada é que se você deseja incluir a biblioteca Hive no Spark SQL, não precisa fazer nada
Instale o Hive primeiro. De modo geral, é melhor introduzir o suporte do Hive ao compilar o Spark SQL para que você possa usar isso
algumas características. Se você baixou a versão binária do Spark, ela deveria ter sido compilada com suporte Hive adicionado.
(1) Colmeia embutida
// Colmeia integrada//faísca-shell// Primeiro exclua metastore_db da pasta spark-local// Executa novamentefaísca . sql ( "mostrar tabelas" ). mostrar// Verifica a pasta spark-local novamenteval df = faísca . leia . json ( "dados/usuário.json" )df . createOrReplaceTempView ( "usuário" )// Você pode ver que existe uma tabela temporáriafaísca . sql ( "mostrar tabelas" ). mostrar// Cria uma tabela shujiafaísca . sql ( "criar tabela shujia(id int)" )// Carrega dados// Antes de carregar os dados, você precisa criar um arquivo id.txt na pasta de dados .faísca . sql ( "carregar dados locais inpath'data/id.txt' na tabela shujia" )// consultafaísca . sql ( "selecione * de shujia" ). mostrar
No desenvolvimento real, quase ninguém usa o Hive integrado.
(2) Colmeia Externa
Se quiser se conectar ao Hive que foi implantado externamente, você precisará seguir as seguintes etapas:
(1) Para assumir o controle do Hive, o Spark precisa copiar o arquivo hive-site.xml para o diretório conf/;
[root@master conf] # cp hive-site.xml /usr/local/soft/spark-local/conf/
(2) Copie o driver mysql para o diretório jars/;
[pacotes root@master] # cp mysql-connector-java-5.1.49.jar /usr/local/soft/spark-local/jars/
(3) Se você não conseguir acessar o hdfs, será necessário copiar core-site.xml e hdfs-site.xml para o diretório conf/.
(4) Reinicie o spark-shell
bin / faísca - concha
(5) Colmeia de operação de código
Adicione dependências:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive --><dependência><groupId> org.apache.spark </groupId><artifactId> spark-hive_2.12 </artifactId><versão > 2.4.5 </versão></dependency><!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec --><dependência><groupId> org.apache.hive </groupId><artifactId> hive-exec </artifactId><versão> 1.2.1 </versão></dependency>
Escreva o código:
package com.shujia.core.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object Demo06_SparkSql_Hive {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkSql")
val spark: SparkSession =
SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreat
e()
//使用SparkSQL连接外置的Hive
//1、拷贝hive-site.xml文件到classpath下
//2、启用hive到支持.enableHiveSupport()
//3、增加对应到依赖关系(包含Mysql驱动)
//TODO 执行逻辑操作
spark.sql("show tables").show()
//TODO 关闭环境
spark.close()
}
}A seguir está uma solução para um determinado relatório de erro
//Erro ao instanciar'org.apache.spark.sql.hive.HiveSessionState':java.lang.RuntimeException: O diretório raiz: /tmp/hive no HDFSdeve ser gravável. As permissões atuais são: ---------% HADOOP_HOME % \bin\winutils . exe ls E : \tmp\hive% HADOOP_HOME % \bin\winutils . exe chmod 777 E : \tmp\hive% HADOOP_HOME % \bin\winutils . exe ls E : \tmp\hive// Erro encontrado: modifique a codificação do conjunto de caracteres do banco de dados de metadados do hivemysql > altere o conjunto de caracteres do hive do banco de dados latin1 ;
Exemplo de código SparkSQL
//使用spark加载数据
package com.shujia.spark.test
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object DemoSpark_hive {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","root")
//TODO 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SparkSql")
val spark: SparkSession =
SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql(
"""
|create table user_log_action(
| `date` string,
| `user_id` bigint,
| `session_id` string,
| `page_id` string,
| `action_time` string,
| `search_keyword` string,
| `click_category_id` bigint,
| `click_product_id` bigint,
| `order_category_ids` string,
| `order_product_ids` string,
| `pay_category_ids` string,
| `pay_product_ids` string,
| `city_id` bigint
|)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'data/user_log_action.txt' into table
user_log_action
|""".stripMargin)
spark.sql(
"""
|create table product_info(
| `product_id` bigint,
| `product_name` string,
| `extend_info` string
|)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'data/product_info.txt' into table
product_info
|""".stripMargin)
spark.sql(
"""
|create table city_info(
| `city_id` bigint,
| `city_name` string,
| `area` string
|)
|row format delimited fields terminated by '\t'
|""".stripMargin)
spark.sql(
"""
|load data local inpath 'data/city_info.txt' into table city_info
|""".stripMargin)
spark.sql(
"""
|select * from product_info
|""".stripMargin)
.show()
spark.close()
}
}