Índice
Referência de texto completo: Notas de leitura do artigo: Autoencoders mascarados são escaláveis Vision Learners_Tower_Tass' Blog-CSDN Blog
Masked autoencoders (MAE) é outro novo trabalho de hekaiming. Seu método é muito simples. É mascarar aleatoriamente alguns patches e reconstruir os pixels perdidos. Pode ser considerado como um aprendiz auto-supervisionado escalável (escalável), que pode ser extremamente Acelere bastante a velocidade de treinamento do modelo e melhore a precisão. O desempenho da migração downstream é melhor do que o pré-treinamento supervisionado e tem boa escalabilidade (escalabilidade).
1. Introdução
Os autoencoders de máscara são uma abordagem mais geral para redução de ruído .
A densidade de informações do idioma é maior e mascarar parte do texto pode tornar a semântica completamente diferente. Essa tarefa levará a uma compreensão mais complexa da linguagem. Enquanto a redundância de imagens é muito alta, mascarar parte do patch reduz muito informações redundantes . E crie uma tarefa de criação auto-supervisionada muito desafiadora para melhorar a compreensão geral da imagem.
O decodificador de AE mapeia a representação latente de volta para a saída.Comparada com a reconstrução da linguagem, a reconstrução dos pixels da imagem tem um nível semântico menor. Muitas vezes, os decodificadores só precisam ser leves, mais rasos e mais estreitos do que os codificadores. Mas descobrimos que, para imagens, o design do decodificador afeta amplamente o nível de expressão semântica da representação latente.
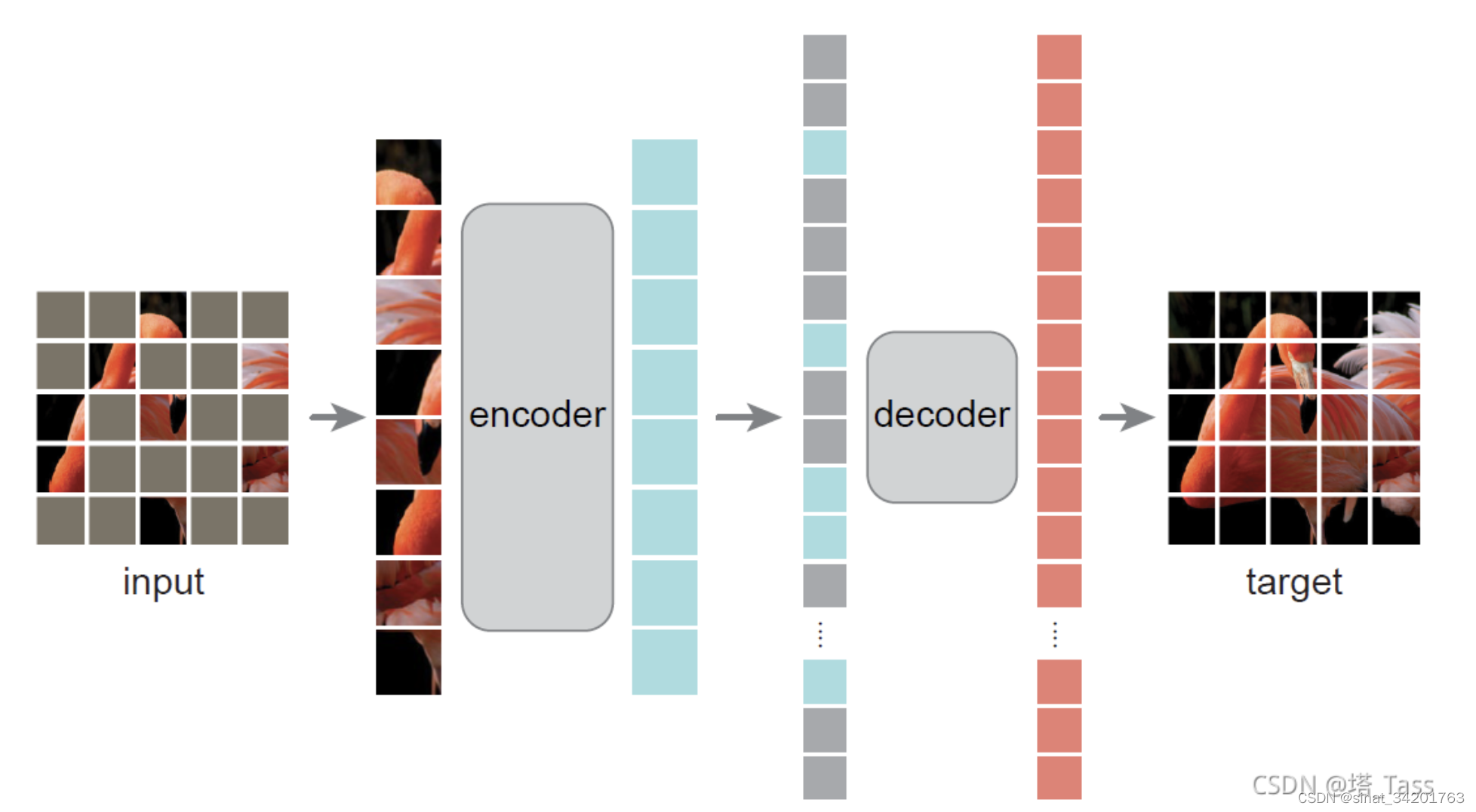
2. Estrutura da rede
Nós projetamos um codificador decodificador assimétrico. O codificador apenas codifica no patch não mascarado para gerar uma representação latente. O decodificador então reconstrói o patch mascarado com base na representação latente.
1. codificador
Aqui, o codificador não preenche o patch mascarado com 0, mas o ignora diretamente. Portanto, a redução no número de patches pode reduzir diretamente a quantidade de cálculo e acelerar a velocidade de treinamento (75% da taxa de máscara é equivalente a 3 vezes mais rápido) e o consumo reduzido de memória permite modelos maiores.
2. decodificador
O decodificador executa apenas tarefas de reconstrução no estágio de pré-treinamento (ou seja, o decodificador não é necessário para a tarefa downstream finetune ), portanto, o design do decodificador pode ser flexível.
O aprofundamento do codificador é benéfico para a representação latente que pode expressar informações semânticas mais abstratas, e o decodificador pode ser projetado para ser mais raso e estreito. Também podemos ter um bom desempenho com um único transformador, como um pequeno decodificador, e a velocidade é rápido.
3. PERDA
Usamos a perda MSE (erro quadrado médio) da imagem original e a imagem reconstruída na parte do patch da máscara. Uma variante é calcular o MSE dos pixels normalizados de cada patch após a normalização com o padrão médio de cada patch , o que pode melhorar significativamente a qualidade da representação .
3. Experimente
(compare com métodos de pré-treinamento supervisionados/não supervisionados)
1) Melhor do que o pré-treinamento do MOCOv3
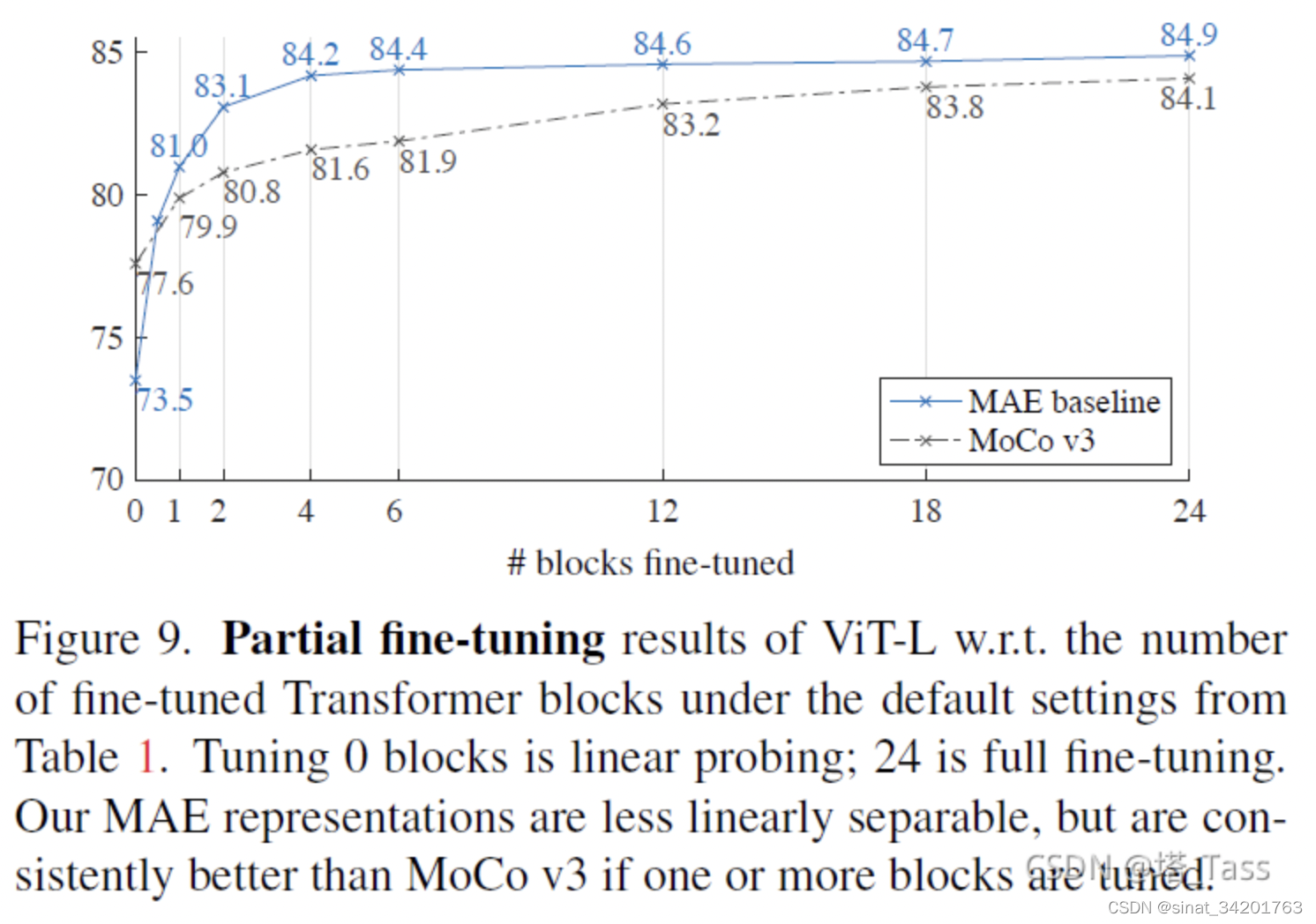
2) Na tarefa de detecção de alvos, o ViT é melhor combinado com o FPN, e o MAE é melhor do que o pré-treinamento supervisionado.
Meu próprio resumo: MAE é um treinador auto-supervisionado muito bom. O modelo pré-treinado treinado por ele alcança melhores resultados no ajuste fino da tarefa a jusante do que os modelos supervisionados e auto-supervisionados MOCO.