Índice
Por que realizar a otimização do banco de dados?
otimização de banco de dados mysql
instalação e desinstalação do mysql (instalação e desinstalação on-line do Linux)
Seleção de versão do banco de dados
relacionamento de estrutura de tabela
Como detectar SQL problemático
Verifique se o log de verificação lenta está habilitado:
Ver informações variáveis de todos os logs
Formato de armazenamento de log de verificação lenta do MySQL
Ferramenta de análise de log de verificação lenta do MySQL (mysqldumpslow)
Ferramenta de análise de log de consulta lenta MySQL (pt-query-digest)
Instale a ferramenta pt-query-digest
Instalação rápida (nota: o wget deve ser instalado primeiro)
Verifique se a instalação foi concluída:
Introdução ao uso da ferramenta:
Como encontrar SQL problemático verificando lentamente os logs
SQL com muitas consultas e cada consulta demora muito
Analise o plano de execução SQL por meio de consulta explicativa
Use explicar para consultar o plano de execução SQL
Casos de otimização para consultas lentas específicas
Otimização de consulta de limite
Por que realizar a otimização do banco de dados?
1. Evite erros de acesso nas páginas do site
Erro na página 5xx devido ao tempo limite de conexão do banco de dados
A página não pode carregar devido à consulta lenta
Os dados não podem ser enviados devido ao bloqueio
2. Aumente a estabilidade do banco de dados
Muitos problemas de banco de dados são causados por consultas ineficientes
3. Otimize a experiência do usuário
Velocidade suave de acesso à página
Boa experiência de funcionalidade do site
otimização de banco de dados mysql
Em quais aspectos o banco de dados pode ser otimizado? Como mostrado abaixo:
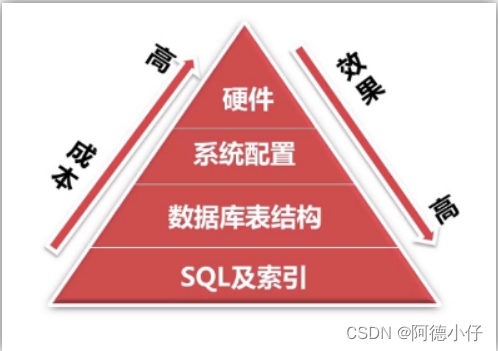
1.SQL e otimização de índice
Escreva um bom SQL de acordo com os requisitos e crie índices eficazes. Para atingir um determinado requisito, você pode escrevê-lo de várias maneiras. Neste momento, temos que escolher a forma mais eficiente de escrever. Neste momento, você precisa entender a otimização de SQL
2. Otimização da estrutura da tabela do banco de dados
Projetar a estrutura da tabela de acordo com o paradigma do banco de dados.O bom design da estrutura da tabela está diretamente relacionado à escrita de instruções SQL.
3. Otimização da configuração do sistema
A maioria é executada em máquinas Linux, como restrições no número de conexões TCP, restrições no número de arquivos abertos e restrições de segurança, portanto, precisamos otimizar essas configurações de acordo.
4. Otimização da configuração de hardware
Escolha uma CPU adequada para serviços de banco de dados, E/S mais rápida e maior memória; mais CPUs nem sempre são melhores, algumas versões de banco de dados têm limitações máximas e as operações de E/S não reduzem o bloqueio.
Nota: Pode-se observar na figura acima que, na pirâmide, o custo da otimização aumenta gradualmente de baixo para cima, enquanto o efeito da otimização diminui gradualmente.
Otimização de SQL e índice
instalação e desinstalação do mysql (instalação e desinstalação on-line do Linux)
Seleção de versão do banco de dados
1. Verifique a versão do banco de dados
select @@version;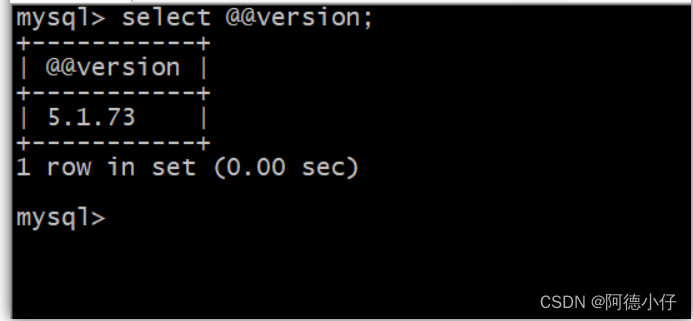
Preparar dados
URL: https://dev.mysql.com/doc/sakila/en/sakila-installation.html
Os arquivos contidos no pacote compactado sakila-db.zip são explicados abaixo
Baixar dados
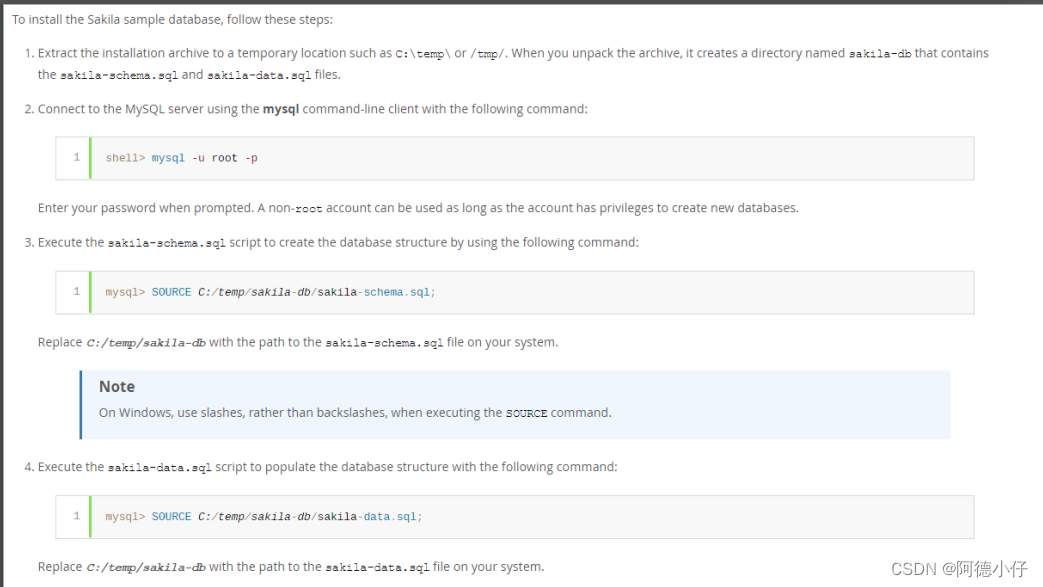
As etapas são mostradas abaixo
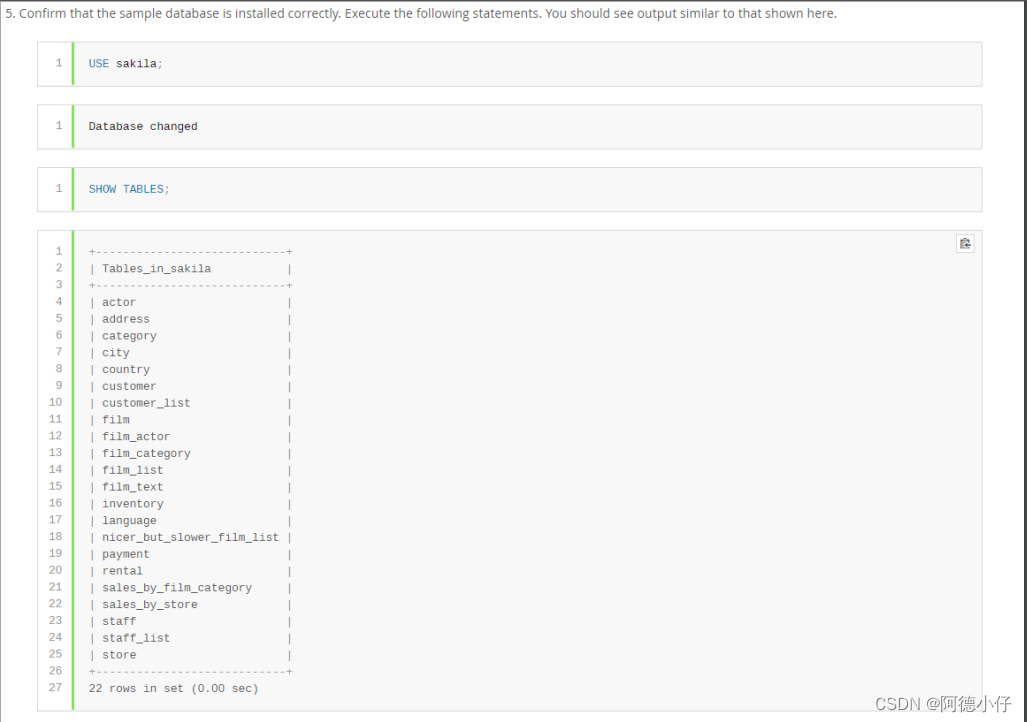

relacionamento de estrutura de tabela

Nota: Este relacionamento de estrutura de tabela é gerado por meio de ferramentas.
Como detectar SQL problemático
Como abrir o log de verificação lenta do MySQL e o formato de armazenamento
Verifique se o log de verificação lenta está habilitado:
show variables like 'slow_query_log'
show variables like 'slow_query_log'
//查看是否开启慢查询日志
set global slow_query_log_file=' /usr/share/mysql/sql_log/mysql-slow.log'
//慢查询日志的位置
set global log_queries_not_using_indexes=on;
//开启慢查询日志
set global long_query_time=1;
//大于1秒钟的数据记录到慢日志中,如果设置为默认0,则会有大量的信息存储在磁盘中,磁盘很容易满掉Ver informações variáveis de todos os logs
show variables like '%log%'mysql> show variables like '%log%';
+-----------------------------------------+------------------------------------+
| Variable_name | Value |
+-----------------------------------------+------------------------------------+
| back_log | 80 |
| binlog_cache_size | 32768 |
| binlog_checksum | CRC32 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_error_action | IGNORE_ERROR |
| binlog_format | STATEMENT |
| binlog_gtid_simple_recovery | OFF |
| binlog_max_flush_queue_time | 0 |
| binlog_order_commits | ON |
| binlog_row_image | FULL |
| binlog_rows_query_log_events | OFF |
| binlog_stmt_cache_size | 32768 |
| binlogging_impossible_mode | IGNORE_ERROR |
| expire_logs_days | 0 |
| general_log | OFF |
| general_log_file | /var/lib/mysql/mysql-host.log |
| innodb_api_enable_binlog | OFF |
| innodb_flush_log_at_timeout | 1 |
| innodb_flush_log_at_trx_commit | 1 |
| innodb_locks_unsafe_for_binlog | OFF |
| innodb_log_buffer_size | 8388608 |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
| innodb_mirrored_log_groups | 1 |
| innodb_online_alter_log_max_size | 134217728 |
| innodb_undo_logs | 128 |
| log_bin | OFF |
| log_bin_basename | |
| log_bin_index | |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| log_error | /var/log/mysqld.log |
| log_output | FILE |
| log_queries_not_using_indexes | ON |
| log_slave_updates | OFF |
| log_slow_admin_statements | OFF |
| log_slow_slave_statements | OFF |
| log_throttle_queries_not_using_indexes | 0 |
| log_warnings | 1 |
| max_binlog_cache_size | 18446744073709547520 |
| max_binlog_size | 1073741824 |
| max_binlog_stmt_cache_size | 18446744073709547520 |
| max_relay_log_size | 0 |
| relay_log | |
| relay_log_basename | |
| relay_log_index | |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | FILE |
| relay_log_purge | ON |
| relay_log_recovery | OFF |
| relay_log_space_limit | 0 |
| simplified_binlog_gtid_recovery | OFF |
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/mysql-host-slow.log |
| sql_log_bin | ON |
| sql_log_off | OFF |
| sync_binlog | 0 |
| sync_relay_log | 10000 |
| sync_relay_log_info | 10000 |
+-----------------------------------------+------------------------------------+
61 rows in set (0.01 sec)Habilite o registro de verificação lenta:
show variables like 'slow_query_log'
//查看是否开启慢查询日志
set global slow_query_log_file=' /var/lib/mysql/mysql-host-slow.log '
//慢查询日志的位置
set global log_queries_not_using_indexes=on;
//开启慢查询日志
set global long_query_time=1;
//大于1秒钟的数据记录到慢日志中,如果设置为默认0,则会有大量的信息存储在磁盘中,磁盘很容易满掉Verifique se o log de consulta lenta está habilitado:
Na operação mysql,
show databases;
use sakila;
select * from store;
select * from staff;Monitore o arquivo de log para ver se ele está gravado
tail -50f /var/lib/mysql/mysql-host-slow.log
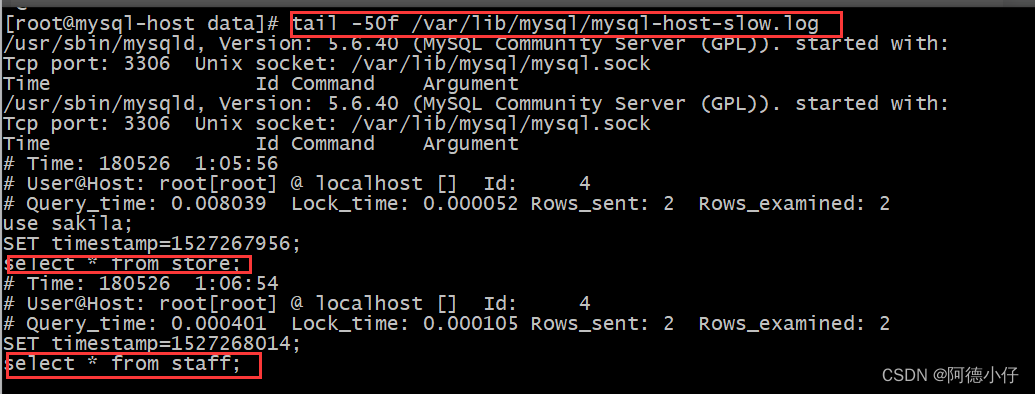
Formato de armazenamento de log de verificação lenta do MySQL
Como mostrado abaixo:

ilustrar:
1. # Tempo: 180526 1:06:54 ------->Tempo de execução da consulta
2. # User@Host: root[root] @ localhost [] Id: 4 ------->Informações do host para execução de sql
3. # Query_time: 0,000401 Lock_time: 0,000105 Rows_sent: 2 Rows_examined: 2-------> Informações de execução SQL:
Query_time: tempo de consulta SQL
Lock_time: tempo de bloqueio
Rows_sent: Número de linhas enviadas
Rows_examined: o número de linhas verificadas pelo bloqueio
4. SET timestamp = 1527268014; -------> Tempo de execução SQL
5. selecione * da equipe; ------->Conteúdo de execução SQL
Ferramenta de análise de log de verificação lenta do MySQL ( mysqldumpslow )
introduzir
Como visualizar o log de consulta lenta? Se o log de consulta lenta estiver ativado, muitos dados serão gerados. Então podemos analisar o log, gerar um relatório de análise e depois otimizar por meio do relatório.
uso
A seguir vamos verificar o uso desta ferramenta:
Nota: No servidor onde o banco de dados mysql está localizado, não na linha de comando mysql >
Como usar esta ferramenta:
mysqldumpslow -h
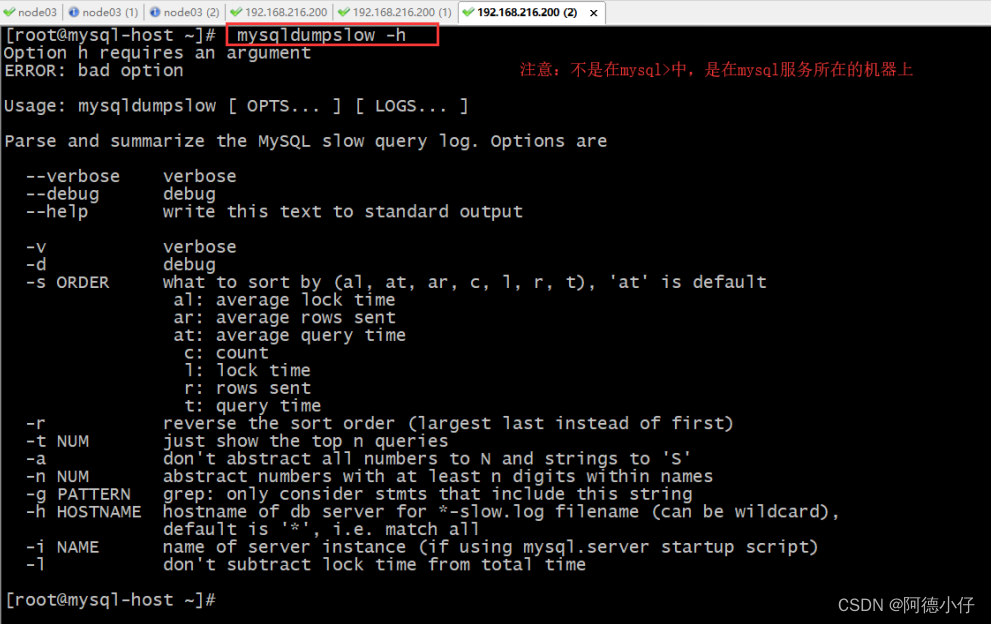
Ver informações detalhadas
Meu ysqldump lento -v

Veja os 10 principais logs de consulta lenta. Os resultados da análise mysqldumpslow são os seguintes:
mysqldumpslow -t 10 /var/lib/mysql/mysql-slow.log

As duas imagens acima são os resultados da análise. Cada resultado mostra o tempo de execução, tempo de bloqueio, número de linhas enviadas e número de linhas digitalizadas.
Esta ferramenta é a ferramenta mais comumente usada. Ela é instalada instalando o mysql. No entanto, os resultados estatísticos desta ferramenta são relativamente poucos e os dados sobre o desempenho do nosso bloqueio de otimização ainda são relativamente pequenos.
Ferramenta de análise de log de consulta lenta MySQL (pt-query-digest)
Introdução e função
Como um excelente DBA MySQL, você também precisa dominar diversas ferramentas úteis de gerenciamento de MySQL, por isso estou organizando e procurando algumas ferramentas que possam facilitar o gerenciamento de MySQL. No próximo período, grande parte da energia será gasta na busca por essas ferramentas.
O gerenciamento de desempenho sempre foi a primeira prioridade. O gerenciamento de muitas tarefas do DBA não consegue ver e não tem como medir o valor. No entanto, se um sistema for tão lento quanto um caracol, o DBA pode restaurar o sistema da beira do colapso por meio do monitoramento. e ajuste. Traga-nos de volta à era ferroviária de alta velocidade. O valor e o toque devem ser enormes. (Muitos líderes de empresas acreditam que se o sistema não puder mais funcionar, eles precisarão substituí-lo por uma CPU mais rápida, memória maior e armazenamento mais rápido, e isso não é uma minoria. Portanto, o valor de um DBA não foi refletido, e o salário naturalmente não será muito alto)
O log do mysql é a maneira mais rápida e direta de rastrear gargalos de desempenho do mysql. Quando ocorre um gargalo de desempenho do sistema, você deve primeiro abrir o log de consulta lenta e rastreá-lo. Durante esse período, o gerenciamento e a visualização do log de consulta lenta foram resolvido duas vezes. Depois de ler este artigo, descobri acidentalmente outra ferramenta para visualizar logs de consultas lentas: mk-query-digest. Essa ferramenta é conhecida como as dez principais ferramentas que o DBA MySQL deve dominar na Internet.
Instale a ferramenta pt-query-digest
Instalação rápida (nota: o wget deve ser instalado primeiro)
wget https://www.percona.com/downloads/percona-toolkit/2.2.16/RPM/percona-toolkit-2.2.16-1.noarch.rpm && yum localinstall -y percona-toolkit-2.2.16-1 .norch.rpm
Verifique se a instalação foi concluída :
Digite: pt-summary na linha de comando
A tela é mostrada abaixo: a instalação foi bem-sucedida! Digite [[root@node03 mysql]#pt-query-digest --help]
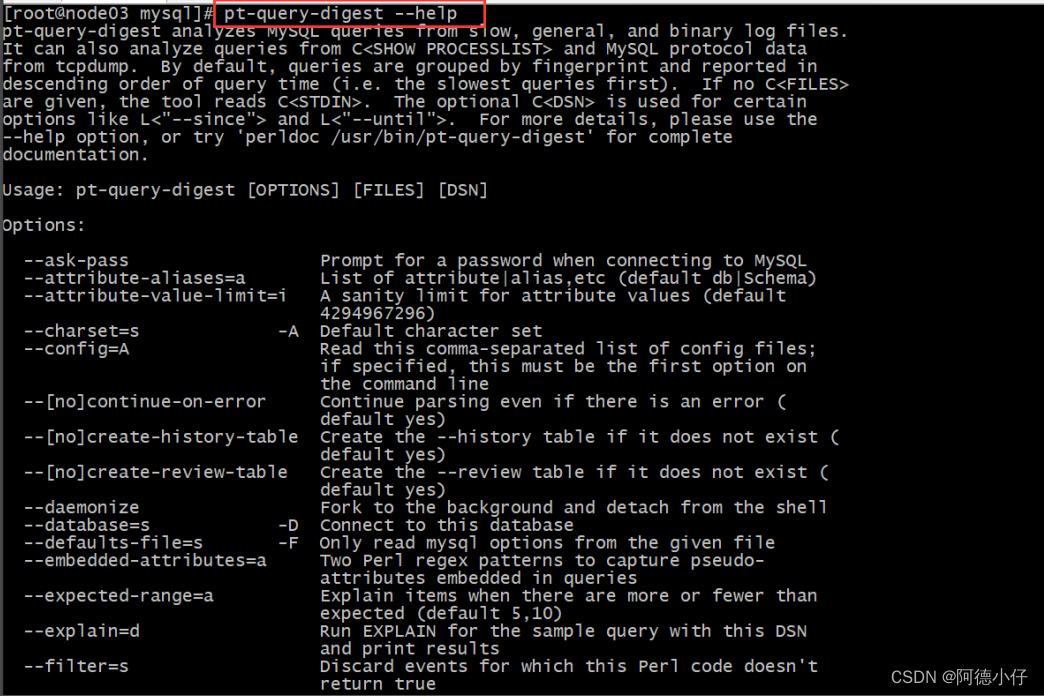
Introdução ao uso da ferramenta:
resumo-pt –ajuda
wget http://percona.com/get/pt-summary
Ver informações do servidor
Comando: pt-resumo
Ver informações de uso de sobrecarga de disco
Comando: pt-diskstats
Ver informações do banco de dados mysql
Instrução: pt-mysql-summary --user=root --password=123456

Analise logs de consultas lentas
Comando: pt-query-digest /data/mysql/data/db-3-12-slow.lo
Encontre o banco de dados escravo e o status de sincronização do mysql
Instrução: pt-slave-find --host=localhost --user=root --password=123456
Ver informações de impasse do mysql
pt-deadlock-logger --user=root --password=123456 localhost
Analise o uso do índice de logs de consultas lentas
pt-index-usage slow_20131009.log
Encontre índices duplicados em tabelas de banco de dados
pt-duplicate-key-checker --host=localhost --user=root --password=123456
Visualize a sobrecarga de E/S ativa atual para tabelas e arquivos MySQL
pt-ioprofile
Veja as diferenças entre os diferentes arquivos de configuração do MySQL
pt-config-diff /etc/my.cnf /etc/my_master.cnf
pt-find encontra a tabela mysql e executa o comando. O exemplo é o seguinte
Encontre tabelas maiores que 2G no banco de dados:
pt-find --user=root --password=123456 --tablesize +2G
Encontre a tabela criada há 10 dias no mecanismo MyISAM:
pt-find --user=root --password=123456 --ctime +10 --engine MyISAM
Visualize tamanhos de tabelas e índices e classifique
pt-find --user=root --password=123456 --printf "%T\t%D.%N\n" | classificar -rn
pt-kill mata o processo mysql que atende aos padrões
Exibir consultas que levam mais de 60 segundos
pt-kill --user=root --password=123456 --busy-time 60 --print
Elimine consultas com mais de 60 segundos
pt-kill --user=root --password=123456 --busy-time 60 --kill
Ver autorização mysql
1.pt - show-grants --user=root --password=123456
2. pt -show-grants --user=root --password=123456 --separate –revoke
Verifique a integridade da replicação do banco de dados
pt-table-checksum --user=root --password=123456
apêndice:

Como encontrar SQL problemático verificando lentamente os logs
SQL com muitas consultas e cada consulta demora muito
Normalmente são as primeiras consultas analisadas pelo pt-query-digest; esta ferramenta consegue ver claramente o número e a percentagem de cada SQL executado. SQL que é executado mais vezes e representa uma proporção maior
IO grande sql
Preste atenção ao item Rows examine na análise pt-query-digest. Quanto mais linhas forem verificadas, maior será o IO.
SQL para erros de índice
Preste atenção na comparação entre Rows examine e Rows Send na análise pt-query-digest. Isso significa que a taxa de acerto do índice deste SQL não é alta, devemos prestar atenção especial a esse tipo de SQL.
Analise o plano de execução SQL por meio de consulta explicativa
Use explicar para consultar o plano de execução SQL
O plano de execução do SQL reflete a eficiência de execução do SQL. O método de execução específico é o seguinte:
Basta adicionar a palavra-chave explicar na frente do SQL executado;

Descrição de cada campo:
1) Quanto maior o número na coluna id, mais rápido ele será executado. Se os números forem iguais, eles serão executados de cima para baixo. Se a coluna id for nula, significa que este é um conjunto de resultados , e não há necessidade de usá-lo para consulta.
2) Colunas select_type comuns incluem:
A: simples: indica uma consulta de seleção simples que não requer operações de união ou não contém subconsultas. Quando há uma consulta de conexão, a consulta externa é simples e há apenas uma
B: primário: uma seleção que requer uma operação de união ou contém uma subconsulta. O select_type da consulta da unidade mais externa é primário. e apenas um
C: União: Duas consultas selecionadas conectadas por união. A primeira consulta é uma tabela derivada derivada. Exceto para a primeira tabela, o select_type da segunda e das tabelas subsequentes é união.
D: união dependente: igual a união, aparece na instrução union ou union all, mas esta consulta será afetada por consulta externa
E: Resultado da união: O conjunto de resultados que contém a união.Na união e na união de todas as instruções, por não precisar participar da consulta, o campo id é nulo.
F: subconsulta: Exceto para a subconsulta contida na cláusula from, as subconsultas que aparecem em outro lugar podem ser subconsultas.
G: subconsulta dependente: semelhante à união dependente, indicando que a consulta desta subconsulta será afetada pela consulta da tabela externa
H: derivado: A subconsulta que aparece na cláusula from também é chamada de tabela derivada. Em outros bancos de dados, pode ser chamada de visualização inline ou seleção aninhada.
3) mesa
O nome da tabela de consulta exibida. Se a consulta usar um alias, o alias será exibido aqui. Se não envolver a operação da tabela de dados, será exibido como nulo. Se for exibido como <derivado N> entre colchetes angulares, significa que esta é uma tabela temporária, o N a seguir é o id no plano de execução, indicando que os resultados vêm desta consulta. Se for <union M,N> entre colchetes angulares, é semelhante a <derived N> e também é uma tabela temporária, indicando que o resultado vem do conjunto de resultados com id M,N da consulta union.
4)tipo
Do melhor ao pior: sistema, const, eq_ref, ref, fulltext, ref_or_null, unique_subquery, index_subquery, range, index_merge, index, ALL, exceto todos, outros tipos podem usar índice, exceto index_merge, other Apenas um índice pode ser usado para o tipo
R: sistema: Há apenas uma linha de dados na tabela ou é uma tabela vazia e só pode ser usada para tabelas myisam e memória. Se for uma tabela de mecanismo Innodb, a coluna de tipo neste caso geralmente é all ou index.
B: const: Ao usar um índice exclusivo ou chave primária, o registro retornado deve ser equivalente onde a condição de 1 linha de registros, geralmente o tipo é const. Outros bancos de dados também são chamados de varreduras de índice exclusivo
C: eq_ref: aparece no plano de consulta para estar conectado a duas tabelas. A tabela do driver retorna apenas uma linha de dados, e esta linha de dados é a chave primária ou índice exclusivo da segunda tabela e não deve ser nula. O índice exclusivo e chave primária são múltiplas colunas, eq_ref só aparecerá quando todas as colunas forem usadas para comparação
D: ref: Não requer a ordem de conexão como eq_ref, e não há exigência de chave primária e índice exclusivo. Pode ocorrer desde que condições iguais sejam usadas para recuperação e pesquisas de igualdade com índices auxiliares sejam comuns. Ou numa chave primária de múltiplas colunas ou num índice único,também pode ocorrer a utilização de colunas diferentes da primeira coluna como uma pesquisa de valor igual.Em suma,uma pesquisa de valor igual pode ocorrer onde os dados devolvidos não são únicos.
E: texto completo: recuperação do índice de texto completo. Observe que a prioridade do índice de texto completo é muito alta. Se o índice de texto completo e o índice comum existirem ao mesmo tempo, o mysql dará prioridade ao texto completo índice independentemente do custo.
F: ref_or_null: Semelhante ao método ref, exceto que a comparação de valores nulos é adicionada. Na verdade, não é muito usado.
G: unique_subquery: usado para subconsultas no formulário em onde.A subconsulta retorna valores únicos sem valores duplicados.
H: index_subquery: usado para subconsultas em formato que usam índices auxiliares ou em listas constantes. A subconsulta pode retornar valores duplicados e o índice pode ser usado para desduplicar a subconsulta.
I: intervalo: varredura de intervalo de índice, comumente usada em consultas que usam operadores como >, <, é nulo, entre, em, como, etc.
J: index_merge: indica que a consulta usa mais de dois índices e, finalmente, usa a interseção ou união. As condições comuns e e ou usam índices diferentes. A classificação oficial é após ref_or_null, mas na verdade, porque todos os índices precisam ser lidos, o desempenho pode não ser tão bom quanto o alcance na maioria das vezes
K: índice: varredura completa da tabela de índice, varredura do índice do início ao fim.É comum usar colunas de índice para processar consultas que não precisam ler arquivos de dados e usar classificação de índice ou consultas de agrupamento.
L: todos: serve para verificar o arquivo de dados em toda a tabela e, em seguida, filtrá-lo na camada do servidor para retornar registros que atendam aos requisitos.
5)possíveis_chaves
Os índices que podem ser usados pela consulta serão listados aqui.
6)chave
Consulte o índice realmente utilizado. Quando select_type for index_merge, mais de dois índices poderão aparecer aqui. Para outros select_types, apenas um aparecerá aqui.
7) key_len
O comprimento do índice usado para processar consultas. Se for um índice de coluna única, todo o comprimento do índice será incluído. Se for um índice de várias colunas, a consulta poderá não ser capaz de usar todas as colunas. Especificamente, quantas colunas índices são usados, aqui será calculado. Colunas não utilizadas não serão calculadas aqui. Preste atenção ao valor desta coluna e calcule o comprimento total do seu índice multicolunas para saber se todas as colunas são usadas. Deve-se observar que os índices utilizados pelo recurso ICP do mysql não serão contados. Além disso, key_len calcula apenas o comprimento do índice usado na condição where e, mesmo que o índice seja usado na classificação e agrupamento, não será calculado em key_len.
8) referência
Se for uma consulta equivalente constante, const será exibido aqui. Se for uma consulta de conexão, o plano de execução da tabela dirigida exibirá os campos associados da tabela de condução. Se a condição usar uma expressão ou função, ou a condição coluna tem um erro interno. Conversão implícita, que pode aparecer como função aqui
9) linhas
Aqui está o número estimado de linhas de varredura no plano de execução, não um valor exato
10) extras
Esta coluna pode exibir muitas informações, existem dezenas delas, as mais usadas são
A: distinto: a palavra-chave distinta é usada na parte selecionada
B: nenhuma tabela usada: consulta sem cláusula from ou consulta From dual
C: Use a subconsulta do formulário not in() ou a consulta de junção do operador inexistente. Isso é chamado de anti-junção. Ou seja, uma consulta de junção geral consulta primeiro a tabela interna e depois a tabela externa, enquanto uma consulta anti-junção consulta primeiro a tabela externa e depois a tabela interna.
D: usando filesort: ocorre quando o índice não pode ser usado durante a classificação. Comumente visto em declarações ordenadas e agrupadas por
E: usando índice: Não há necessidade de consultar a tabela durante a consulta. Os dados consultados podem ser obtidos diretamente através do índice.
F: usando buffer de junção (loop aninhado de bloco), usando buffer de junção (acesso de chave em lote): versões posteriores a 5.6.x otimizam os recursos BNL e BKA de consultas relacionadas. O objetivo principal é reduzir o número de loops na tabela interna e verificar a consulta sequencialmente.
G: usando sort_union, usando_union, usando intersect, usando sort_intersection:
usando intersect: Ao expressar as condições de cada índice usando e, esta informação indica que a interseção é obtida a partir dos resultados do processamento.
using union: Indica que ao utilizar ou conectar as condições de cada índice, esta informação indica que a união é obtida a partir dos resultados do processamento.
usando sort_union e usando sort_intersection: são semelhantes aos dois anteriores, exceto que aparecem ao usar e e ou para consultar uma grande quantidade de informações.A chave primária é consultada primeiro e, em seguida, os registros são lidos e retornados após a classificação e mesclagem.
H: usando temporário: Indica que uma tabela temporária é usada para armazenar resultados intermediários. Tabelas temporárias podem ser tabelas temporárias de memória e tabelas temporárias de disco. Elas não podem ser vistas no plano de execução. Você precisa verificar as variáveis de status, used_tmp_table e used_tmp_disk_table para vê-las.
I: usando where: indica que nem todos os registros retornados pelo mecanismo de armazenamento atendem às condições de consulta e precisam ser filtrados na camada do servidor. As condições de consulta são divididas em condições de restrição e condições de inspeção.Antes de 5.6, o mecanismo de armazenamento só podia verificar e retornar dados de acordo com as condições de restrição e, em seguida, a camada do servidor filtrava de acordo com as condições de inspeção e retornava dados que realmente atendiam à consulta. Após 5.6.x, o recurso ICP é suportado e as condições de verificação podem ser empurradas para a camada do mecanismo de armazenamento.Os dados que não atendem às condições e restrições de verificação não serão lidos diretamente, o que reduz bastante o número de registros verificados por o mecanismo de armazenamento. A coluna extra mostra o uso da condição de índice
J: firstmatch(tb_name): Um dos novos recursos de otimização de subconsultas introduzidos em 5.6.x. É comum em subconsultas contendo in() tipo em cláusulas where. Se a quantidade de dados na tabela interna for relativamente grande, isso poderá ocorrer.
K: loosescan(m..n): Um dos novos recursos de otimização de subconsultas introduzidos após 5.6.x. Na subconsulta do tipo in(), isso pode ocorrer quando a subconsulta retorna registros duplicados.
Além dessas, existem muitas bibliotecas de dicionário de dados de consulta.Durante o processo do plano de execução, são encontradas algumas mensagens de prompt informando que os resultados não podem existir.
11)filtrado
Esta coluna aparecerá ao usar explicação estendida.As versões posteriores a 5.7 possuem este campo por padrão, portanto não há necessidade de usar explicação estendida. Este campo indica a proporção dos registros restantes que satisfazem a consulta após os dados retornados pelo mecanismo de armazenamento serem filtrados na camada do servidor. Observe que é uma porcentagem e não um número específico de registros.
Fotos anexadas:


Casos de otimização para consultas lentas específicas
Otimização da função Max()
Objetivo: Consultar o último horário de pagamento - otimizar a função max()
Declaração:
select max(payment_date) from payment;
Plano de implementação:
explain select max(payment_date) from payment;

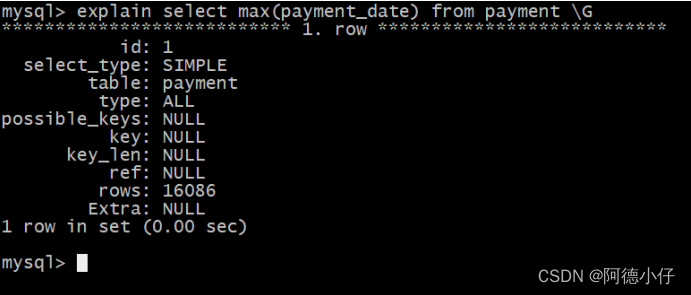
Você pode ver que o plano de execução exibido não é muito eficiente e pode diminuir a eficiência do servidor. Como ele pode ser otimizado?
Criar índice
create index inx_paydate on payment(payment_date);

O índice é operado sequencialmente e não precisa varrer a tabela, portanto a eficiência de execução será relativamente constante.
Otimização da função Count()
Requisito: Verifique simultaneamente o número de filmes em 2006 e 2007 em um SQL
Caminho errado:
Declaração:
select count(release_year='2006' or release_year='2007') from film;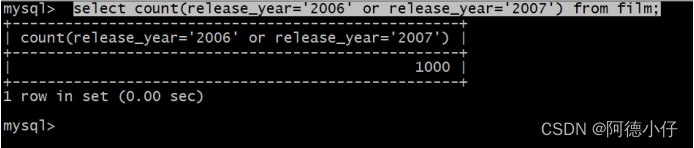
Não sei dizer quais eram os números em 2006 e 2007.
select count(*) from film where release_year='2006' or release_year='2007';
Maneira correta de escrever:
select count(release_year='2006' or null) as '06films',count(release_year='2007' or null) as '07films' from film;
Diferença: contagem(*) e contagem(id)
Criar tabela e inserir instrução
create table t(id int);
insert into t values(1),(2),(null);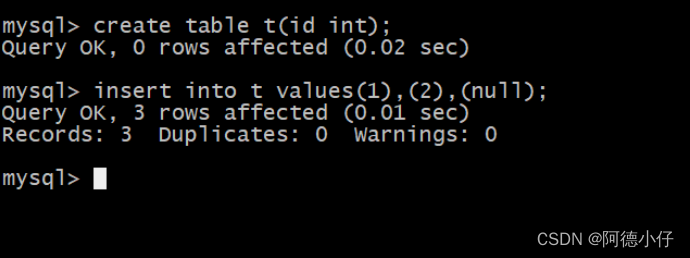
Count(*):select count(*)from t;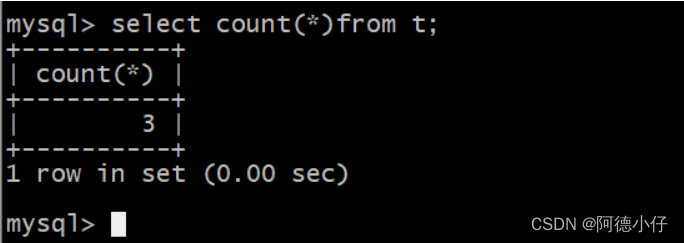
Count(id):select count(id)from t;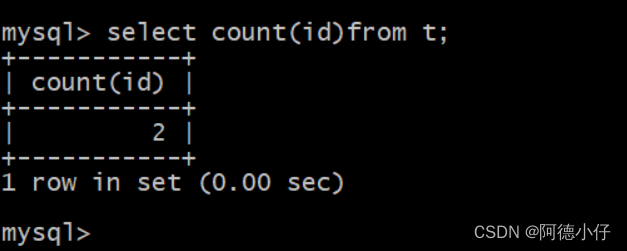
ilustrar:
Count(id) é um valor que não contém nulo
Count(*) é um valor que contém nulo
Otimização de subconsulta
Subconsulta é um método que usamos frequentemente no processo de desenvolvimento. Em circunstâncias normais, a subconsulta precisa ser otimizada em uma consulta de junção. No entanto, durante a otimização, você precisa prestar atenção se a chave associada tem um relacionamento um-para-muitos e preste atenção aos dados duplicados.
Veja a tabela t que criamos
show create table t;
Em seguida, criamos uma tabela t1
create table t1(tid int);e insira um dado

Precisamos realizar uma subconsulta, o requisito é: consultar todos os dados da tabela t cujo id seja tid na tabela t1;
select * from t where t.id in (select t1.tid from t1);
Em seguida, usamos a operação join para realizar a operação
select id from t join t1 on t.id =t1.tid;
A julgar pelos resultados acima, os resultados da consulta são consistentes, por isso otimizamos a subconsulta em uma operação de junção.
A seguir, inserimos outro dado na tabela t1
insert into t1 values (1);
select * from t1;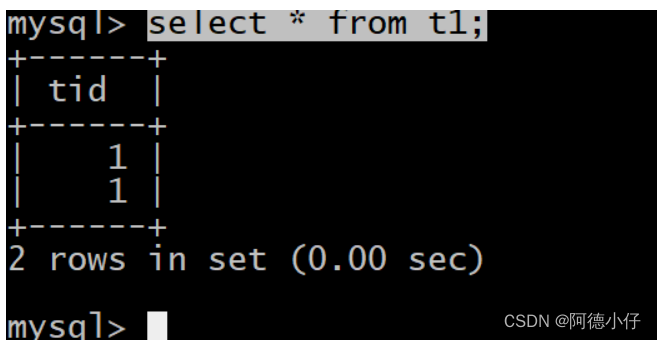
Neste caso, se usarmos subconsulta para consultar, o resultado retornado será conforme mostrado abaixo:

Se você usar o método join para pesquisar, conforme mostrado na figura abaixo:
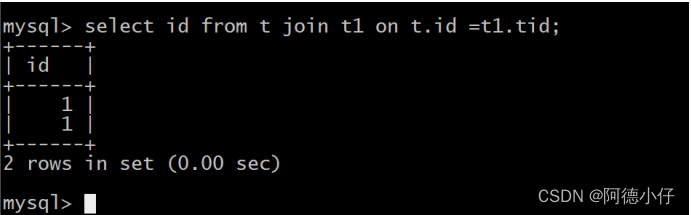
Neste caso, existe um relacionamento um-para-muitos e haverá duplicação de dados.Para evitar a duplicação de dados, temos que usar a palavra-chave distinta para realizar operações de desduplicação.
select distinct id from t join t1 on t.id =t1.tid;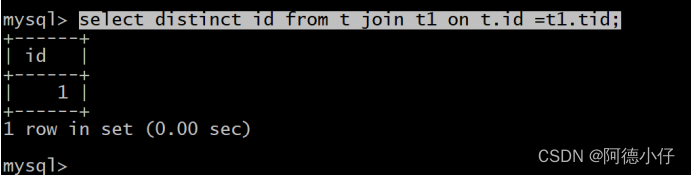
Observação: esse relacionamento um-para-muitos é uma armadilha que encontramos durante o processo de desenvolvimento. Ocorre duplicação de dados e todos precisam prestar atenção a isso.
Exemplo: Consulte todos os filmes estrelados por Sandra:
explain select title,release_year,length
from film
where film_id in (
select film_id from film_actor where actor_id in (
select actor_id from actor where first_name='sandra'));Otimização de agrupar por
É melhor usar colunas da mesma tabela,
Requisitos: O número de filmes em que cada ator participou - (lista de filmes e lista de elenco)
explain select actor.first_name,actor.last_name,count(*)
from sakila.film_actor
inner join sakila.actor using(actor_id)
group by film_actor.actor_id;
SQL otimizado:
explain select actor.first_name,actor.last_name,c.cnt
from sakila.actor inner join (
select actor_id,count(*) as cnt from sakila.film_actor group by actor_id
)as c using(actor_id);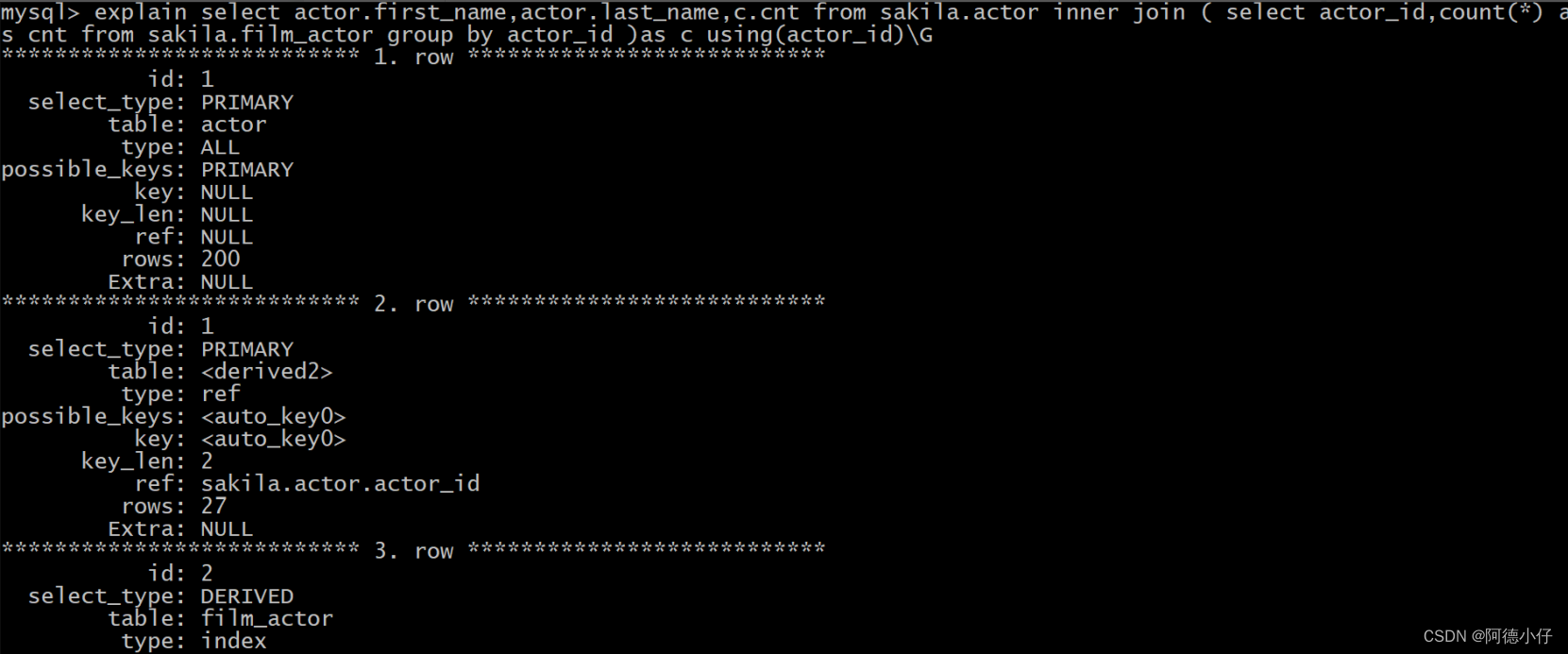
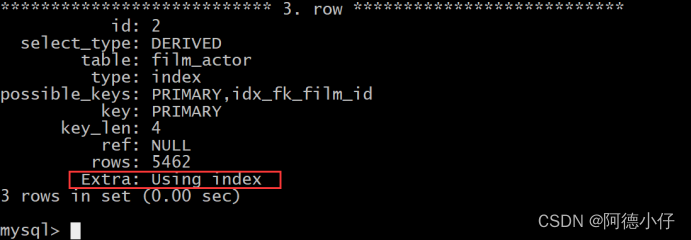
Nota: A julgar pelo plano de execução acima, este método otimizado não usa arquivos temporários e classificação de arquivos , mas usa índices. A eficiência da consulta é muito alta.
Neste momento, os dados em nossa tabela são relativamente grandes, o que ocupará muitas operações de IO, otimizará a eficiência da execução do SQL e economizará recursos do servidor, por isso precisamos otimizar.
Perceber:
1. O papel da palavra-chave using no mysql : ou seja , para usar using, as tabelas a e b devem ter as mesmas colunas .
2. Ao usar Join para realizar consultas conjuntas em múltiplas tabelas, normalmente usamos On para estabelecer o relacionamento entre as duas tabelas. Na verdade, existe uma palavra-chave mais conveniente, que é Usando.
3. Se os nomes dos campos associados das duas tabelas forem iguais, você pode usar Using para estabelecer o relacionamento, que é conciso e claro.
Otimização de consulta de limite
Limit é frequentemente usado para processamento de paginação, e a duração é usada com a cláusula order by, portanto, na maioria das vezes, Filesorts é usado, o que causará muitos problemas de IO.
exemplo:
Requisito: consulte o ID do filme e as informações de descrição, classifique de acordo com o tema e recupere 5 dados a partir do número de série 50.
select film_id,description from sakila.film order by title limit 50,5;Resultado da execução:

Confira seu plano de execução:
 Que método de otimização devemos usar para esta operação?
Que método de otimização devemos usar para esta operação?
Etapa de otimização 1:
Use colunas indexadas ou chaves primárias para realizar operações ordenadas, porque como todos sabemos, o innodb classifica de acordo com a ordem lógica das chaves primárias. Muitas operações de IO podem ser evitadas.
select film_id,description from sakila.film order by film_id limit 50,5; Confira o plano de execução
Confira o plano de execução
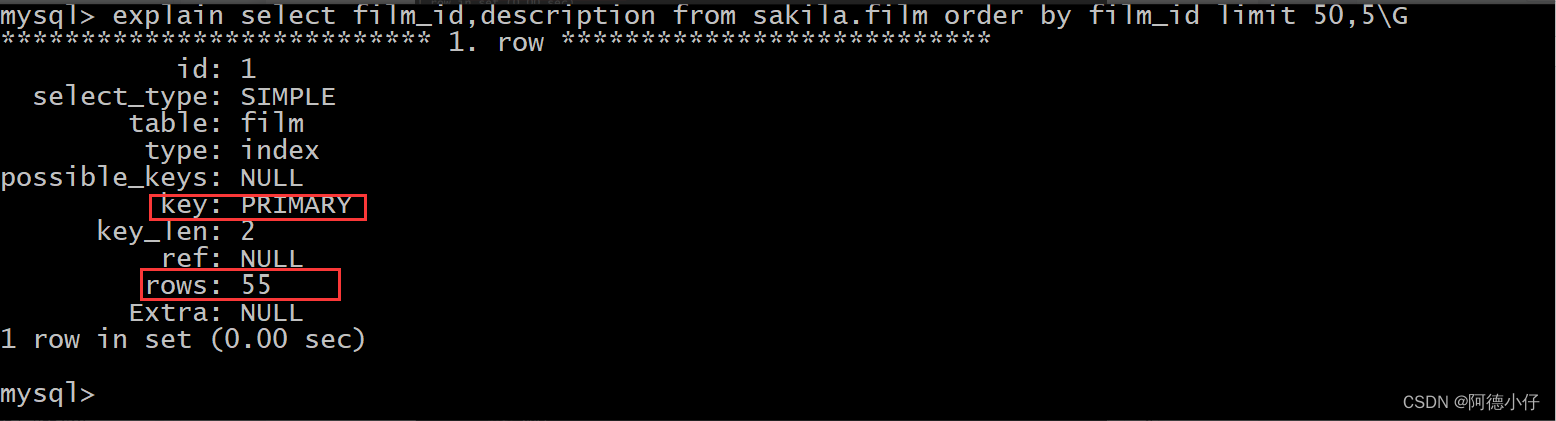
Então, se obtivermos 5 registros começando na linha 500, como será o plano de execução?
explain select film_id,description from sakila.film order by film_id limit 500,5\G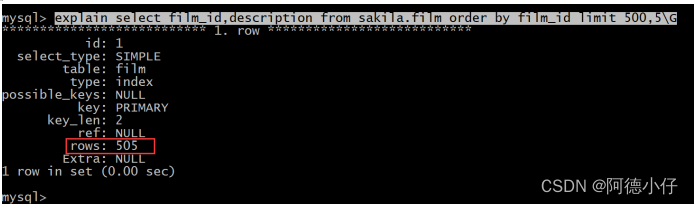

À medida que viramos a página, a operação de IO se tornará cada vez maior. Se uma tabela tiver dezenas de milhões de linhas de dados, a virada da página se tornará cada vez mais lenta, por isso precisamos otimizá-la ainda mais.
Etapa 2 de otimização: registre a chave primária retornada da última vez e use a filtragem de chave primária na próxima consulta. ( Nota: Isso evita a verificação de muitos registros quando a quantidade de dados é grande )
O último limite foi 50,5, então precisamos usar o último valor do registro do índice neste processo de otimização.
select film_id,description from sakila.film where film_id >55 and film_id<=60 order by film_id limit 1,5;Veja o plano de execução:
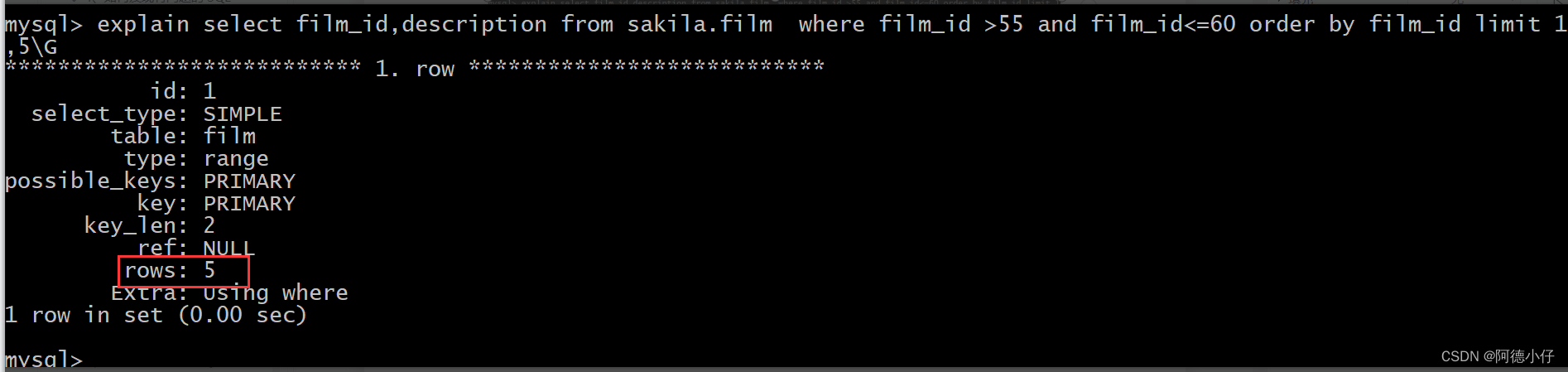


Conclusão: O número de linhas de varredura permanece inalterado, o plano de execução é muito fixo e a eficiência também é muito fixa.
Precauções:
As chaves primárias devem ser classificadas sequencial e consecutivamente. Se houver uma determinada coluna ou várias colunas no meio da chave primária, haverá menos de 5 linhas de dados listados; se não for contínuo, crie uma coluna adicional index_id para certifique-se de que esta coluna de dados. Se quiser aumentá-la automaticamente, basta adicionar um índice.
Otimização do índice
1. O que é um índice?
O índice é equivalente ao índice de um livro. Você pode encontrar rapidamente o conteúdo necessário com base nos números das páginas do índice.
O banco de dados usa um índice para encontrar um valor específico e então aponta para frente para encontrar a linha que contém esse valor. Crie um índice na tabela, encontre o valor do índice que atenda às condições de consulta no índice e, por fim, encontre rapidamente o registro correspondente na tabela por meio do ROWID (equivalente ao número da página) salvo no índice. O estabelecimento de um índice é um campo relativamente direcional na tabela, que equivale a um diretório. Por exemplo, o código de área administrativa. Os códigos de área administrativa na mesma região são todos iguais. Em seguida, adicione um índice a esta coluna para evite varreduras repetidas. Alcance o propósito de otimização!
2. Como criar um índice
Os índices podem ser criados ao executar a instrução CREATE TABLE, ou CREATE INDEX ou ALTER TABLE podem ser usados sozinhos para adicionar índices à tabela.
1. ALTERAR TABELA
ALTER TABLE é usado para criar um índice normal, índice UNIQUE ou índice PRIMARY KEY.
ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)Observação: nome_tabela é o nome da tabela a ser indexada, lista_coluna indica quais colunas indexar e, se houver múltiplas colunas, separe-as com vírgulas. O nome do índice index_name é opcional. Por padrão, o MySQL atribuirá um nome baseado na primeira coluna do índice. Além disso, ALTER TABLE permite que várias tabelas sejam alteradas em uma única instrução, para que vários índices possam ser criados ao mesmo tempo.
2. CRIAR ÍNDICE
CREATE INDEX pode adicionar índices comuns ou índices UNIQUE à tabela.
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)Nota: nome_tabela, nome_índice e lista_coluna têm o mesmo significado que na instrução ALTER TABLE e o nome do índice não é opcional. Além disso, você não pode usar a instrução CREATE INDEX para criar um índice PRIMARY KEY.
3. Tipo de índice
Ao criar um índice, você pode especificar se o índice pode conter valores duplicados. Se não for incluído, o índice deverá ser criado como um índice PRIMARY KEY ou UNIQUE. Para um índice exclusivo de coluna única, isso garante que a coluna única não contenha valores duplicados. Para índices únicos de múltiplas colunas, é garantido que a combinação de múltiplos valores não se repete.
Os índices PRIMARY KEY são muito semelhantes aos índices UNIQUE.
Na verdade, um índice PRIMARY KEY é apenas um índice UNIQUE com o nome PRIMARY. Isso significa que uma tabela só pode conter uma CHAVE PRIMÁRIA, pois é impossível ter dois índices com o mesmo nome em uma tabela.
A instrução SQL a seguir adiciona um índice PRIMARY KEY em sid à tabela de alunos.
ALTER TABLE students ADD PRIMARY KEY (sid)4. Excluir índice
Os índices podem ser excluídos usando a instrução ALTER TABLE ou DROP INDEX. Semelhante à instrução CREATE INDEX, DROP INDEX pode ser processado como uma instrução dentro de ALTER TABLE. A sintaxe é a seguinte.
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEYEntre elas, as duas primeiras instruções são equivalentes e o índice index_name em table_name é excluído.
A terceira instrução é usada apenas ao excluir o índice PRIMARY KEY, porque uma tabela só pode ter um índice PRIMARY KEY, portanto não há necessidade de especificar o nome do índice. Se nenhum índice PRIMARY KEY for criado, mas a tabela tiver um ou mais índices UNIQUE, o MySQL descarta o primeiro índice UNIQUE.
Se uma coluna for excluída de uma tabela, o índice será afetado. Para um índice de múltiplas colunas, se uma das colunas for excluída, a coluna também será excluída do índice. Se você excluir todas as colunas que compõem o índice, todo o índice será excluído.
5. Ver índice
show index from tblname;
show keys from tblname;6. Em que circunstâncias são utilizados índices?
1. A chave primária da tabela
2. Crie automaticamente um índice exclusivo
3. Restrições exclusivas nos campos da tabela
4. Campos para consulta condicional direta (campos usados para restrições condicionais em SQL)
5. Campos associados a outras tabelas da consulta
6. Os campos classificados na consulta (se os campos classificados forem acessados por meio do índice, a velocidade de classificação será bastante melhorada)
7. Campos para estatísticas ou estatísticas de grupo em consultas
8. Os registros da tabela são muito poucos (se uma tabela tiver apenas 5 registros e um índice for usado para acessar os registros, então a tabela de índice precisa ser acessada primeiro e, em seguida, a tabela de dados é acessada por meio da tabela de índice. Geralmente, a tabela de índice e a tabela de dados não estão no mesmo bloco de dados)
9. Tabelas que são inseridas, excluídas ou modificadas com frequência (para algumas tabelas de negócios processadas com frequência, os índices devem ser reduzidos tanto quanto possível se as consultas permitirem)
10. Campos de tabela com dados repetidos e distribuição uniforme (se uma tabela tiver 100.000 linhas de registros e houver um campo A que tenha apenas dois valores: T e F, e a probabilidade de distribuição de cada valor for de cerca de 50%, então para esse tipo de tabela A Construir índices em campos geralmente não melhora a velocidade de consulta do banco de dados.)
11. Campos de tabela que geralmente são consultados junto com o campo principal, mas possuem muitos valores de índice de campo principal
12. O que fazer ao indexar dezenas de milhões de bancos de dados MySQL e como melhorar o desempenho
3. Como selecionar colunas apropriadas para criar índices
1. Adicione índices às colunas na cláusula where, na cláusula group by, na cláusula order by e na cláusula on
2. Quanto menor o campo de índice, melhor (porque a unidade de armazenamento de dados do banco de dados é baseada em “página”, quanto mais dados forem armazenados, maior será o IO)
3. Colunas com grande dispersão são colocadas na frente do índice da junta.
exemplo:
select * from payment where staff_id =2 and customer_id =584;Perceber:
O índice ( staff_id , customer_id ) é melhor ou o índice ( customer_id , staff_id ) é melhor?
Então, como verificamos a dispersão?
A. Vejamos primeiro a estrutura da tabela
desc payment;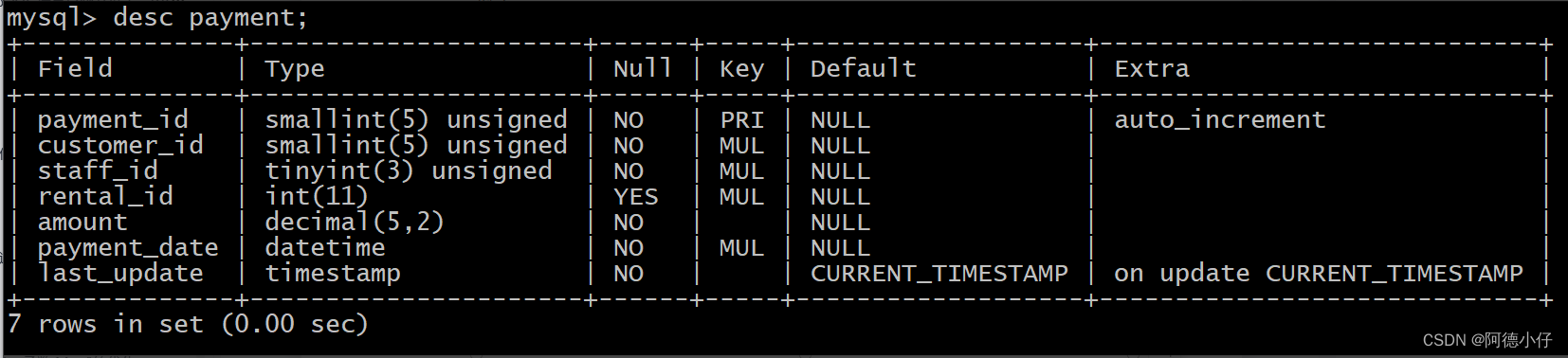
B. Verifique a quantidade de IDs diferentes nesses dois campos respectivamente. Quanto maior o número, maior o grau de dispersão: Portanto, pode-se observar na figura abaixo: customer_id possui maior grau de dispersão.

Conclusão: Como customer_id é altamente discreto, é melhor usar índice ( customer_id , staff_id )
C. índice conjunto mysql
①Regras de nomenclatura: nome da tabela_nome do campo
1. Os campos que precisam ser indexados devem estar na condição where
2. Campos com pequena quantidade de dados não precisam ser indexados
3. Se houver um relacionamento OR na condição where, a indexação não funcionará.
4. Siga o princípio mais à esquerda
②O que é um índice conjunto?
- Um índice em duas ou mais colunas é chamado de índice conjunto, também conhecido como índice composto.
- Usar colunas adicionais em um índice permite restringir o escopo da sua pesquisa, mas usar um índice com duas colunas é diferente de usar dois índices separados. A estrutura de um índice composto é semelhante a uma lista telefônica, onde o nome de uma pessoa é composto por um nome e um sobrenome. A lista telefônica é primeiro classificada por pares de sobrenomes e, em seguida, classificada por nome para pessoas com o mesmo sobrenome . Uma lista telefônica é muito útil se você souber seu sobrenome, mais útil se você souber seu nome e sobrenome, mas inútil se você souber apenas seu nome, mas nenhum sobrenome.
Portanto, ao criar um índice composto, a ordem das colunas deve ser considerada cuidadosamente. Os índices compostos são úteis ao pesquisar em todas as colunas do índice ou apenas nas primeiras colunas; eles não são úteis ao pesquisar em colunas subsequentes.
4. Métodos para otimização de índice SQL
1. Manutenção e otimização de índices (índices duplicados e redundantes)
Aumentar os índices será benéfico para a eficiência da consulta, mas reduzirá a eficiência de inserção, atualização e exclusão. No entanto, isso geralmente não é o caso. Muitos índices não afetarão apenas a eficiência do uso, mas também afetarão a eficiência da consulta. Isso é devido à consulta ao banco de dados. Ao analisar, você deve primeiro escolher qual índice usar para consulta. Se houver muitos índices, o processo de análise será mais lento, o que também reduzirá a eficiência da consulta. Portanto, precisamos saber como aumentar e às vezes manter e excluir os desnecessários.
2. Como encontrar índices duplicados e redundantes
Índice duplicado:
Índices duplicados referem-se a índices do mesmo tipo construídos nas mesmas colunas e na mesma ordem.Os índices nas colunas de chave primária e ID na tabela a seguir são índices duplicados.
create table test(
id int not null primary key,
name varchar(10) not null,
title varchar(50) not null,
unique(id)
)engine=innodb;Índice redundante:
Um índice redundante refere-se a um índice com a mesma coluna de prefixo em vários índices,ou a um índice que contém a chave primária num índice conjunto.No exemplo a seguir,chave (nome,id)é um índice redundante.
create table test(
id int not null primary key,
name varchar(10) not null,
title varchar(50) not null,
key(name,id)
)engine=innodb;Nota: Para innodb, a chave primária será realmente incluída atrás de cada índice.Neste momento, o índice conjunto que estabelecemos artificialmente inclui a chave primária, portanto é um índice redundante no momento.
3. Como encontrar índices duplicados
Ferramentas: Use a ferramenta pt-duplicate-key-checker para verificar índices duplicados e redundantes
pt-duplicate-key-checker -uroot -padmin -h 127.0.0.1

4. Métodos de manutenção de índice
Devido a mudanças nos negócios, alguns índices não são mais necessários e devem ser excluídos.
No MySQL, o uso do índice só pode ser analisado por meio de logs de consultas lentas e da ferramenta pt-index-usage;
pt-index-usage -uroot -padmin /var/lib/mysql/mysql-host-slow.lo
 Em anexo: https://www.percona.com/downloads/
Em anexo: https://www.percona.com/downloads/
5. Coisas a serem observadas
Índices MySql bem projetados podem fazer seu banco de dados voar e melhorar muito a eficiência do banco de dados. Existem alguns pontos a serem observados ao projetar índices MySql:
1. Crie um índice
Para aplicações onde as consultas dominam, os índices são particularmente importantes. Muitas vezes, os problemas de desempenho são simplesmente causados por esquecermos de adicionar um índice ou por não adicionarmos um índice mais eficaz. Se não houver índice,então será realizada uma varredura completa da tabela para encontrar até mesmo um dado específico.Se a quantidade de dados em uma tabela for grande e houver poucos resultados qualificados,então não adicionar um índice causará degradação fatal do desempenho .
Mas não é necessário construir um índice em todas as situações. Por exemplo, o gênero pode ter apenas dois valores. Construir um índice não só não traz nenhuma vantagem, mas também afeta a velocidade de atualização. Isso é chamado de indexação excessiva.
2. Índice composto
Por exemplo, existe uma declaração como esta: select * from users where area='beijing' and age=22;
Se criarmos um único índice em área e idade respectivamente, uma vez que a consulta mysql só pode usar um índice por vez, embora isso tenha melhorado a eficiência da idade , A criação de um índice composto na coluna trará maior eficiência. Se criarmos um índice composto de (área, idade, salário), na verdade é equivalente a criar três índices (área, idade, salário), (área, idade) e (área).Isso é chamado de melhor característica de prefixo esquerdo .
Portanto, ao criarmos um índice composto, devemos colocar as colunas mais utilizadas como restrições à esquerda, em ordem decrescente.
3. O índice não conterá colunas com valores NULL.
Contanto que uma coluna contenha um valor NULL, ela não será incluída no índice.Enquanto uma coluna no índice composto contiver um valor NULL, essa coluna será inválida para o índice composto. Portanto, ao projetar o banco de dados, não devemos permitir que o valor padrão do campo seja NULL.
4. Use índices curtos
Para indexar colunas de string, um comprimento de prefixo deve ser especificado, se possível. Por exemplo, se você tiver uma coluna CHAR(255), não indexe a coluna inteira se a maioria dos valores for exclusiva nos primeiros 10 ou 20 caracteres. Índices curtos não apenas melhoram a velocidade da consulta, mas também economizam espaço em disco e operações de E/S.
5. Problema de classificação de índice
As consultas MySQL usam apenas um índice, portanto, se um índice tiver sido usado na cláusula where, as colunas ordenadas por não usarão o índice. Portanto, não use operações de classificação quando a classificação padrão do banco de dados puder atender aos requisitos; tente não incluir a classificação de múltiplas colunas. Se necessário, é melhor criar índices compostos para essas colunas.
6. Operação de declaração semelhante
Em circunstâncias normais, o uso de operações semelhantes é desencorajado.Se for necessário usá-lo, como usá-lo também será um problema. Assim como “%aaa%” não usará o índice, mas como “aaa%” usará o índice.
7. Não realize operações em colunas
selecione * dos usuários onde
ANO(adicionar)
8. Não use a operação NOT IN
As operações NOT IN não usarão o índice e executarão uma varredura completa da tabela. NOT IN pode ser substituído por NOT EXISTS