Análise de desempenho SQL, otimização SQL
Análise de desempenho SQL
Frequência de execução SQL
Após o cliente MySQL se conectar com sucesso, o comando show [session|global] status pode fornecer informações de status do servidor. Você pode visualizar a frequência de acesso de INSERT, UPDATE, DELETE e SELECT do banco de dados atual usando os seguintes comandos:
-- session 是查看当前会话 ;
-- global 是查询全局数据 ;
SHOW GLOBAL STATUS LIKE 'Com_______';
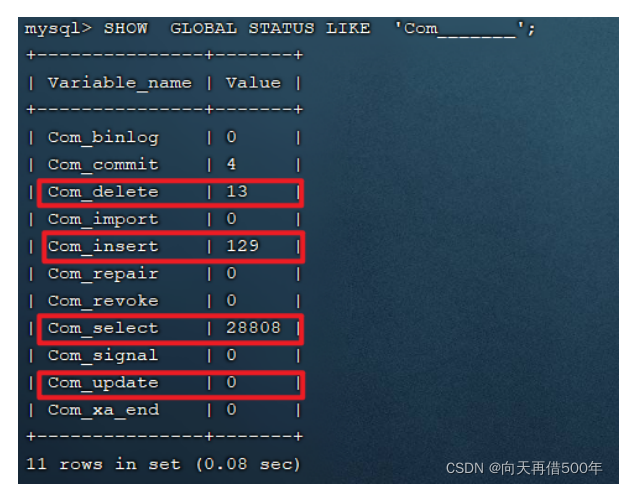
- Com_delete: excluir contagem
- Com_insert: tempos de inserção
- Com_select: número de consultas
- Com_update: número de atualizações
Através dos comandos acima, podemos verificar se o banco de dados atual é baseado principalmente em consulta, ou se é baseado principalmente em adições e exclusões, de modo a fornecer uma referência para otimização do banco de dados. Se for baseado em adições e exclusões, podemos considerar a otimização sem indexação. Se for baseado principalmente em consulta, é necessário considerar a otimização do índice do banco de dados.
log de consulta lenta
O log de consulta lenta registra todas as instruções SQL cujo tempo de execução excede o parâmetro especificado (long_query_time, unidade: segundos, padrão 10 segundos).
O log de consultas lentas do MySQL não está habilitado por padrão, podemos verificar a variável do sistema slow_query_log.
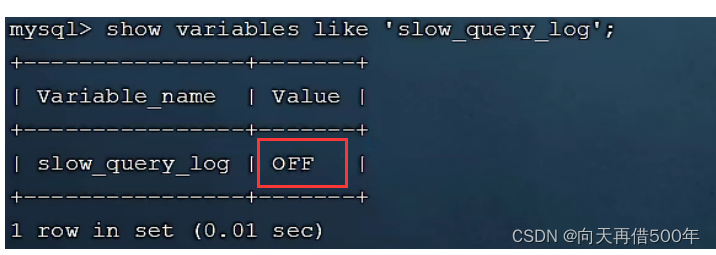
Se você deseja habilitar o log de consultas lentas, você precisa configurar as seguintes informações no arquivo de configuração do MySQL (/etc/my.cnf):
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
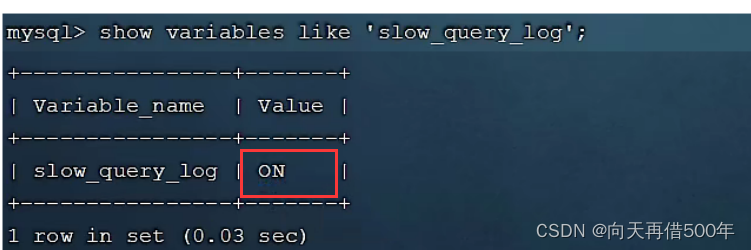
Após a conclusão da configuração, reinicie o servidor MySQL para teste com o comando a seguir e verifique as informações registradas no arquivo de log lento
/var/lib/mysql/localhost-slow.log.
systemctl restart mysqld
Em seguida, verifique a situação do switch novamente e o log de consulta lenta foi ativado.
Detalhes de perfil
show profiles pode nos ajudar a entender onde o tempo é gasto ao fazer a otimização do SQL. Através do parâmetro have_profiling, você pode ver se o MySQL atual suporta operações de perfil:
SELECT @@have_profiling ;
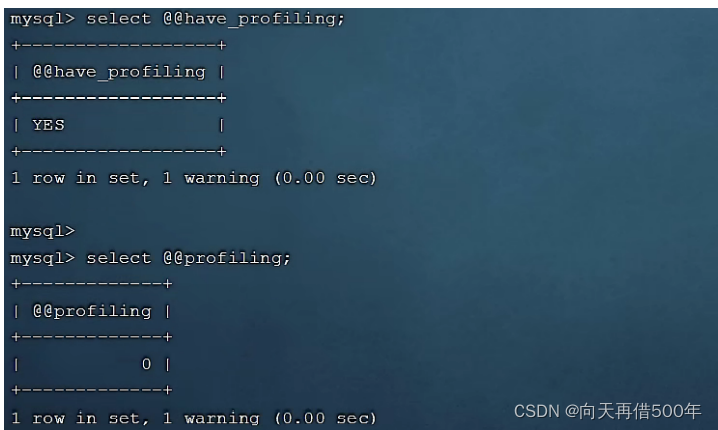
Como você pode ver, o MySQL atualmente suporta operações de perfil, mas a chave está desligada. A criação de perfil pode ser habilitada no nível de sessão/global por meio da instrução set:
SET profiling = 1;
A chave foi ligada, em seguida, as instruções SQL que executamos serão gravadas pelo MySQL, e o tempo de execução será registrado
. Executamos diretamente a seguinte instrução SQL:
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_sku;
Execute uma série de operações SQL de negócios e, em seguida, verifique o tempo de execução do comando por meio dos seguintes comandos:
-- 查看每一条SQL的耗时基本情况
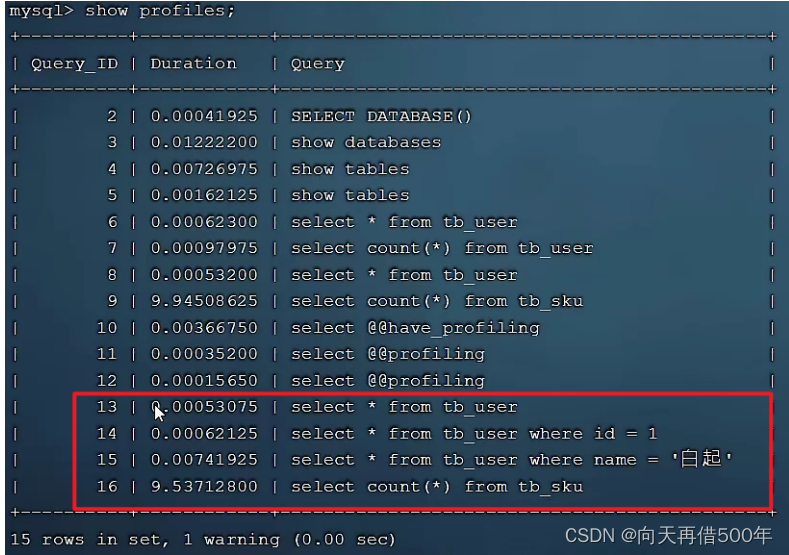
show profiles;
-- 查看指定query_id的SQL语句各个阶段的耗时情况
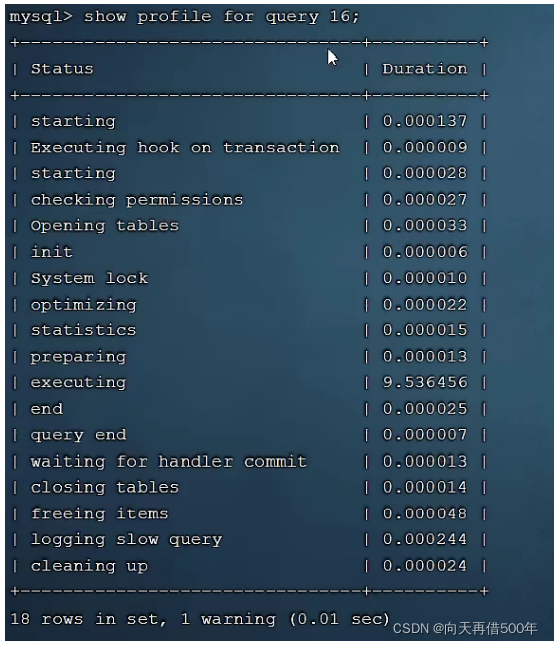
show profile for query query_id;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
Veja a situação demorada de cada SQL:
Veja a situação demorada de cada estágio do SQL especificado:
explique
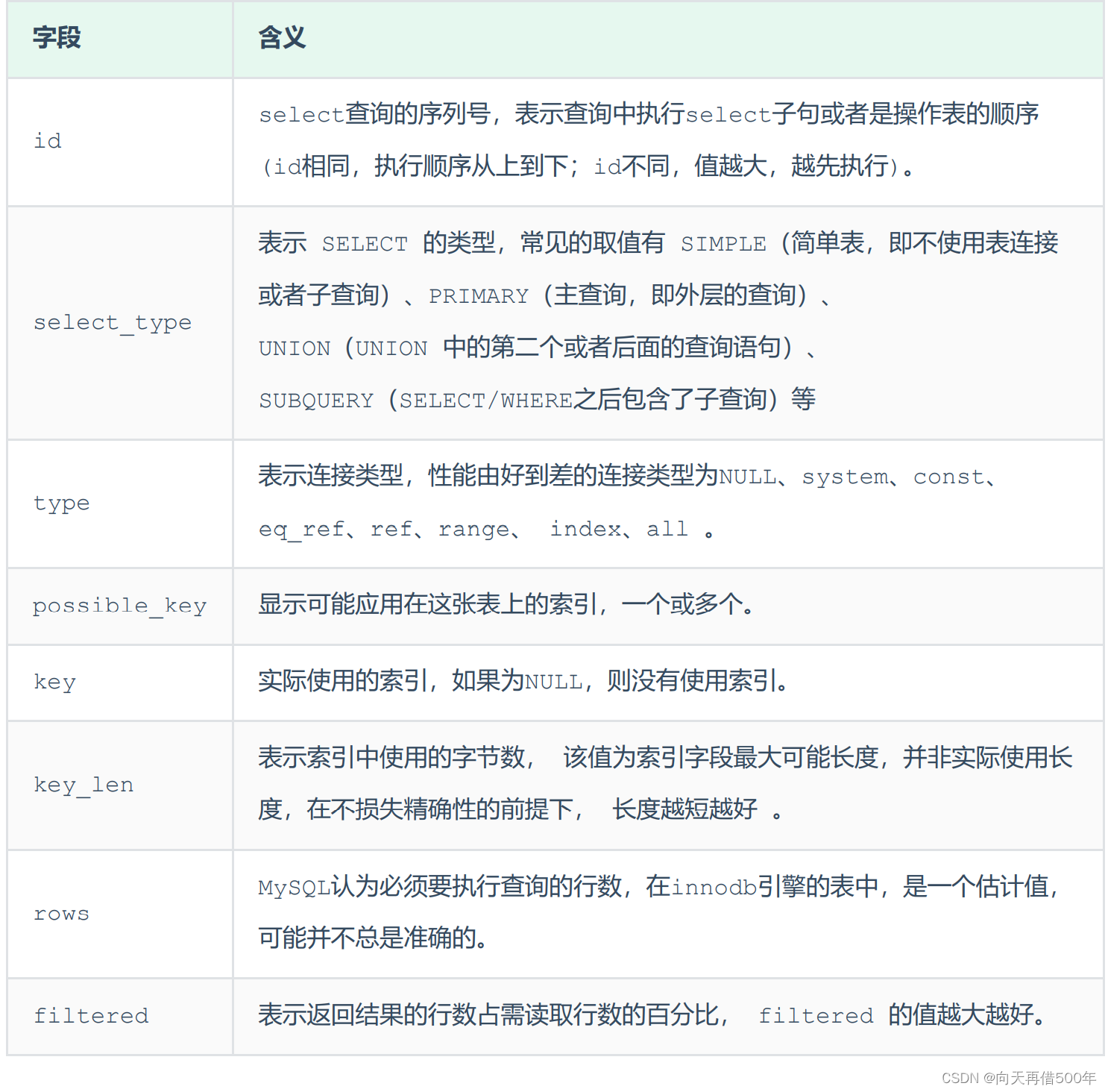
O comando EXPLAIN ou DESC obtém informações sobre como o MySQL executa a instrução SELECT, incluindo
como as tabelas são unidas e a ordem na qual elas são unidas durante a execução da instrução SELECT.
-- 直接在select语句之前加上关键字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ;

Explique o significado de cada campo no plano de execução:
Otimização SQL
inserir dados
Se precisarmos inserir vários registros na tabela do banco de dados de uma só vez, podemos otimizar a partir dos três aspectos a seguir.
insert into tb_test values(1,'tom');
insert into tb_test values(2,'cat');
insert into tb_test values(3,'jerry');
Plano de otimização um
Dados de inserção em massa
Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
Plano de otimização dois
Controle manualmente as transações
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;
Plano de otimização três
A chave primária é inserida sequencialmente e o desempenho é superior ao da inserção fora de ordem.
Inserir dados em massa
Se você precisar inserir uma grande quantidade de dados de uma só vez (por exemplo: milhões de registros), o desempenho de inserção é baixo usando a instrução insert. Nesse caso, você pode usar o comando load fornecido pelo banco de dados MySQL para inserir. A operação é a seguinte:
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/load_user_100w_sort.sql' into table
tb_user fields terminated by ',' lines terminated by '\n' ;
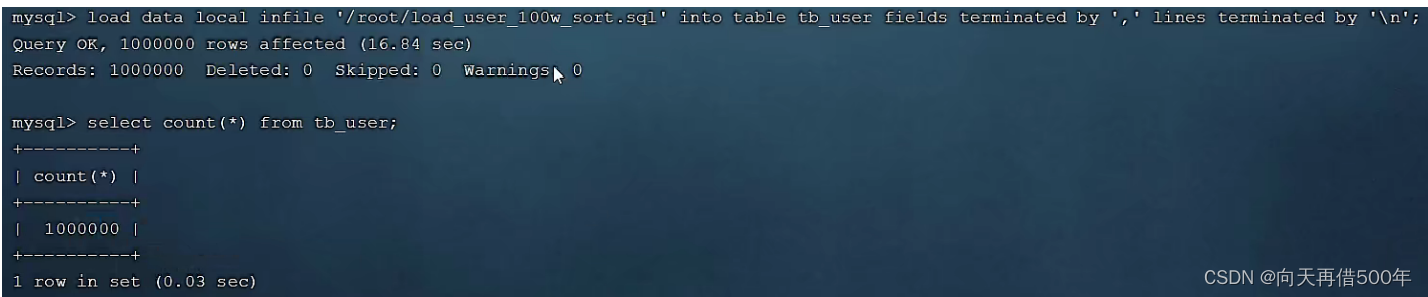
Durante o carregamento, o desempenho da inserção sequencial de chave primária é maior do que a inserção fora de ordem
Otimização de chave primária
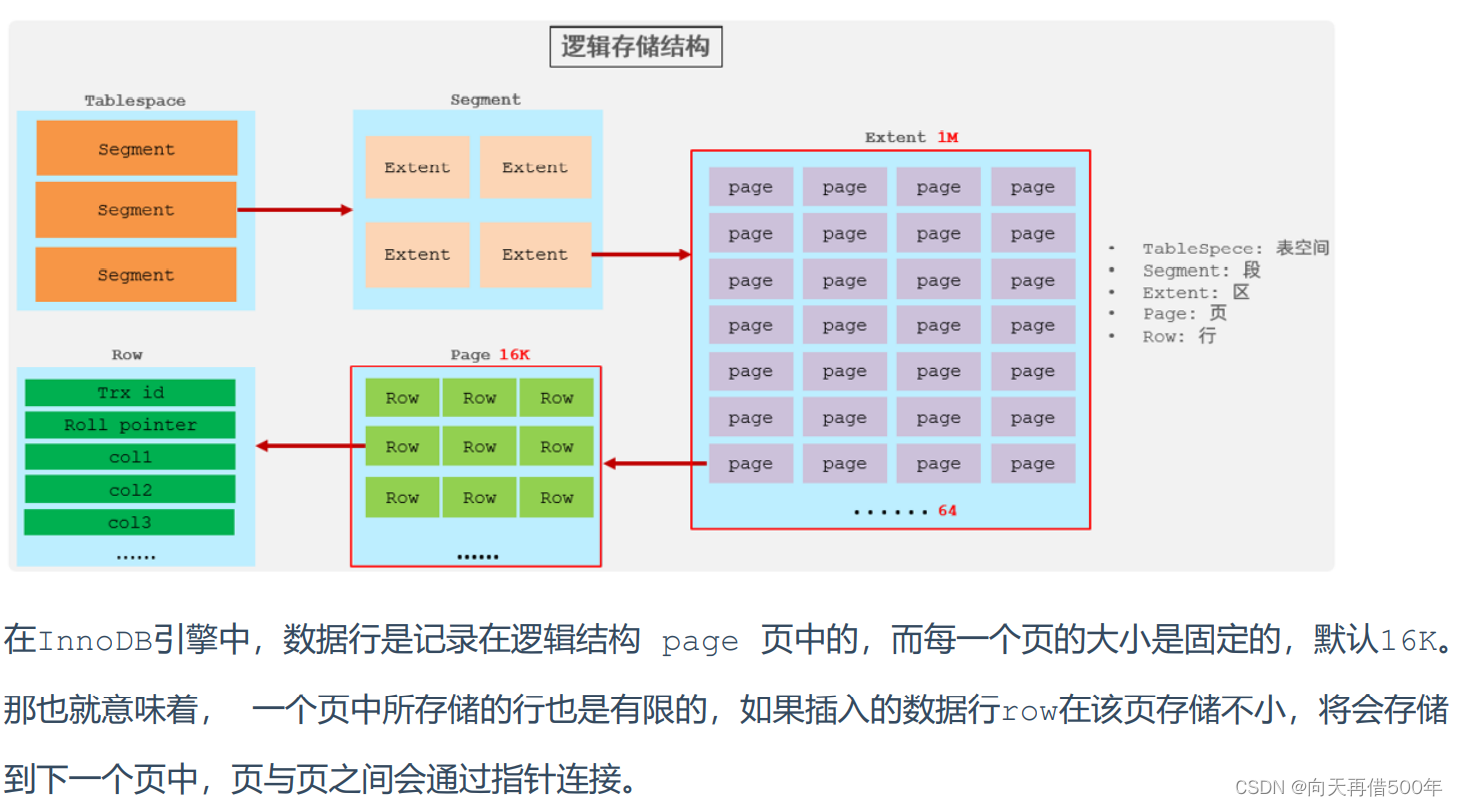
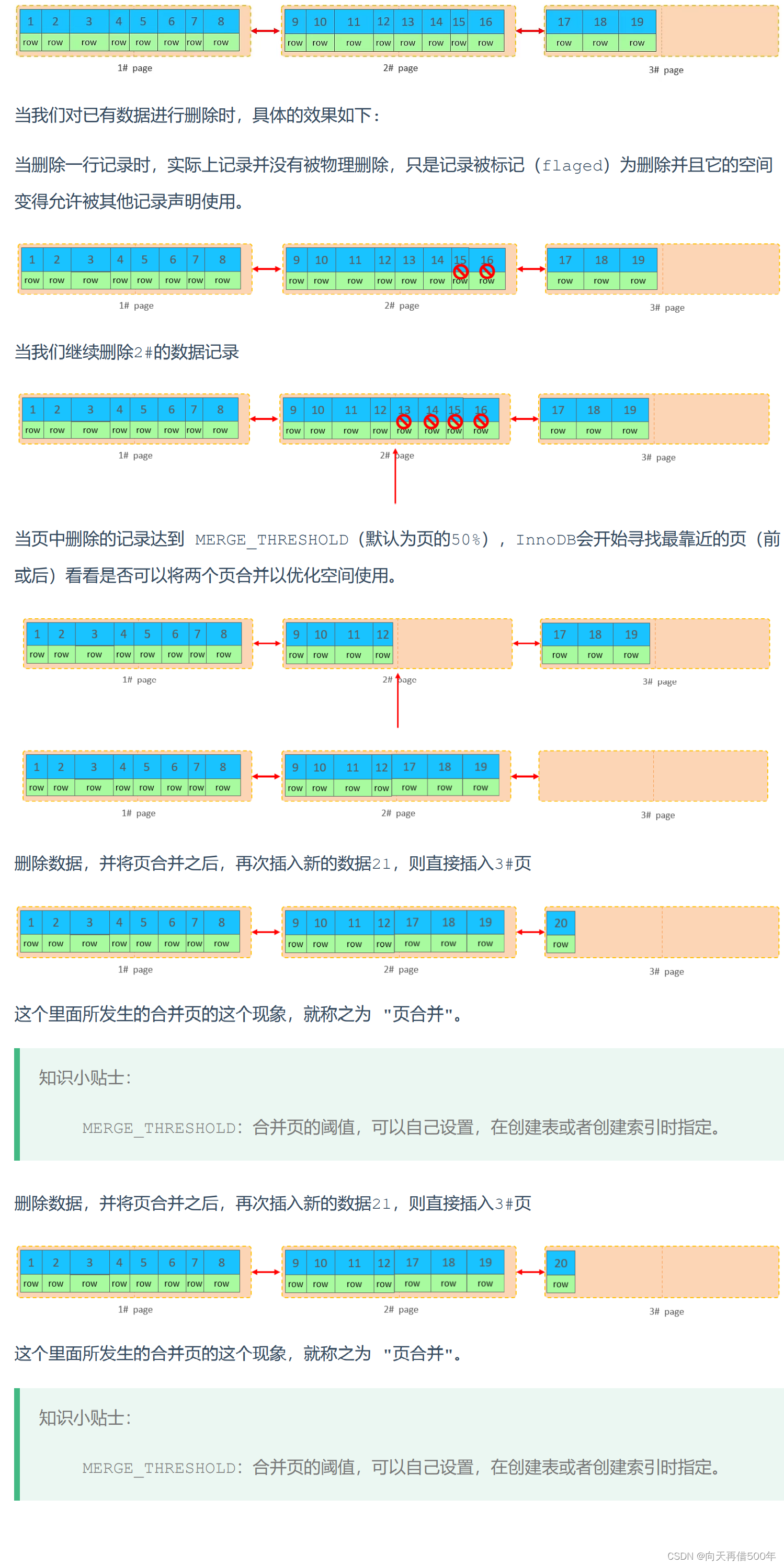
divisão de página
As páginas podem estar vazias, meio preenchidas ou 100% preenchidas. Cada página contém 2-N linhas de dados (se uma linha de dados for muito grande, a linha transbordará), organizadas de acordo com a chave primária.
Efeito de inserção de sequência de chave primária
- Solicitar páginas do disco, inserir a chave primária sequencialmente
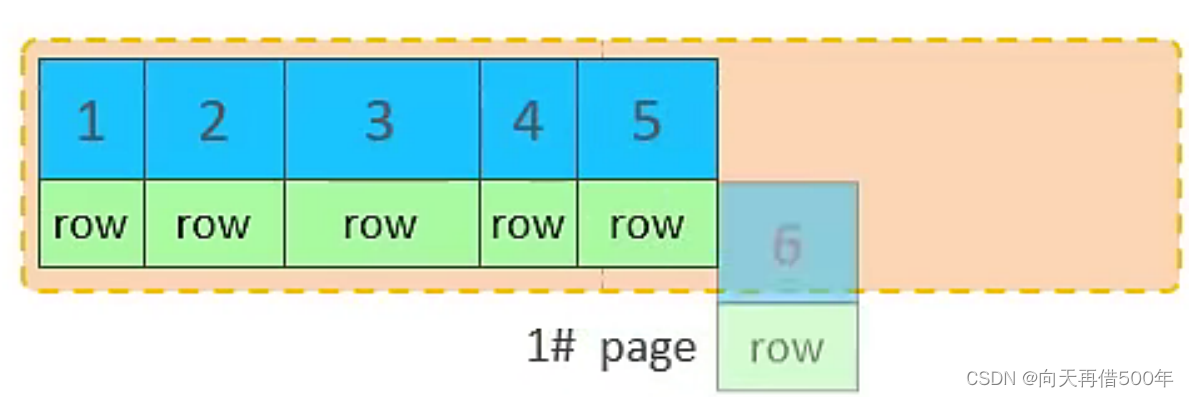
- A primeira página não está cheia, continue a inserir na primeira página
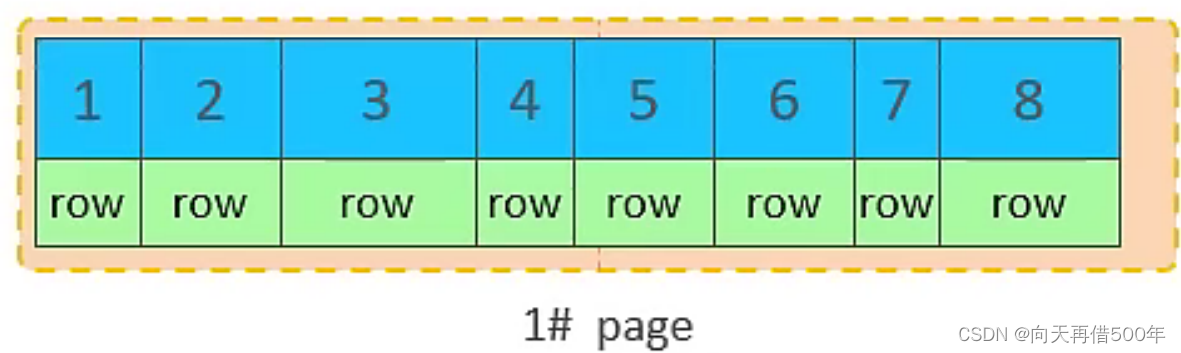
- Quando a primeira página também estiver cheia, escreva a segunda página e as páginas serão conectadas por ponteiros

- Quando a segunda página estiver cheia, escreva na terceira página

Efeito de inserção fora de ordem da chave primária
- Adicionando as páginas 1# e 2# já estão cheias, armazenando os dados conforme mostrado na figura

- Neste ponto, insira o registro com id 50
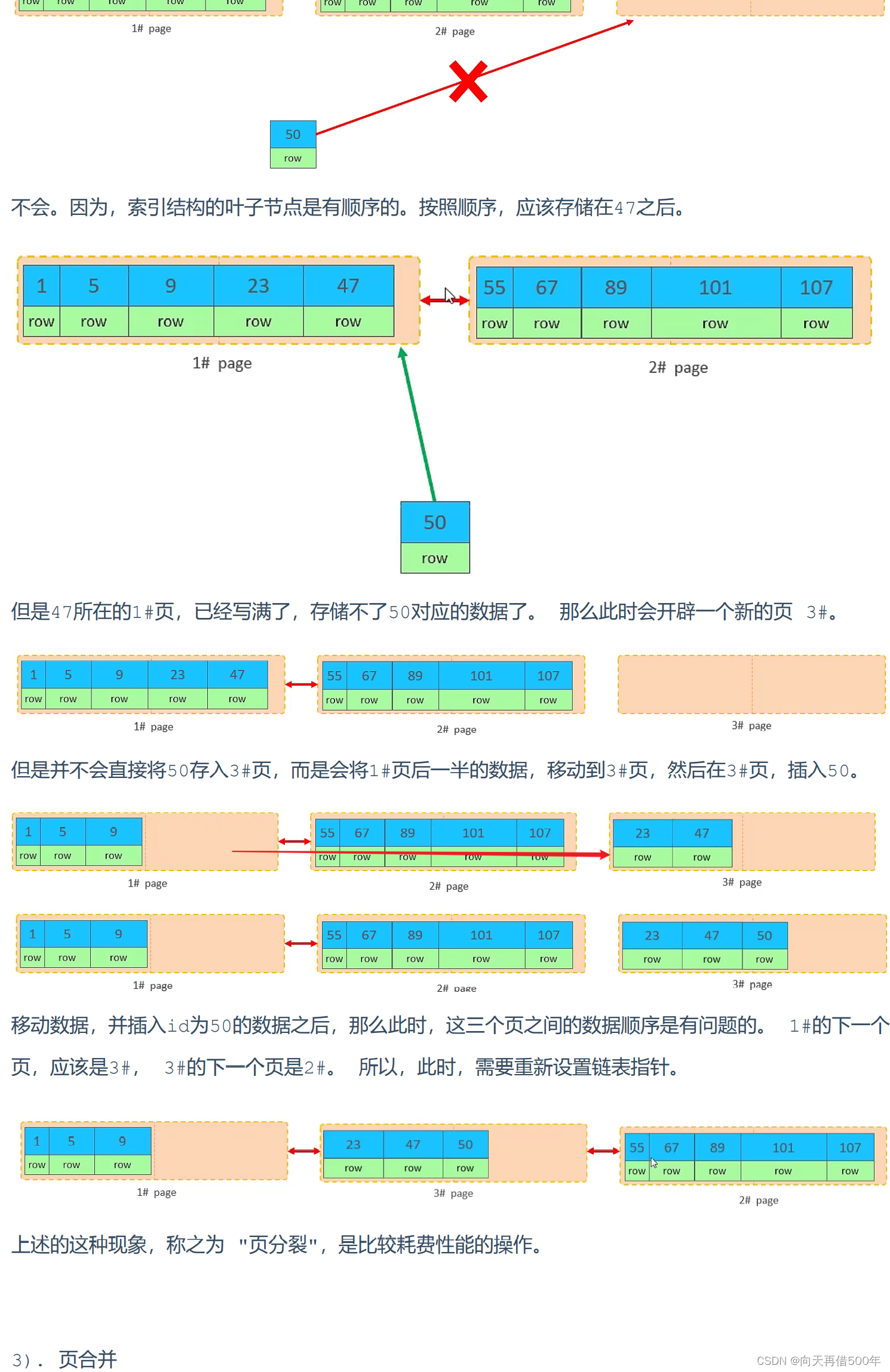
mesclagem de página
A estrutura do índice (nó folha) dos dados existentes na tabela é a seguinte:
Princípios de design de chave primária
- No caso de atender aos requisitos de negócios, tente reduzir o comprimento da chave primária.
- Ao inserir dados, tente inserir em ordem e opte por usar a chave de incremento automático AUTO_INCREMENT.
- Tente não usar UUID como chave primária ou outras chaves primárias naturais, como números de ID.
- Durante as operações comerciais, evite modificar a chave primária.
ordem por otimização
ordenação do MySQL, existem duas maneiras:
- Usando filesort : Por meio do índice da tabela ou varredura completa da tabela, leia as linhas de dados que atendem às condições e conclua a operação de classificação no buffer de classificação sortbuffer. Toda classificação que não retorna diretamente o resultado da classificação por meio do índice é chamada Classificação de FileSort.
- Using index : Os dados ordenados são retornados diretamente através da varredura seqüencial do índice ordenado, neste caso, o índice using é usado, não é necessária ordenação adicional e a eficiência da operação é alta.
Para os dois métodos de classificação acima, o desempenho de Using index é alto, enquanto o desempenho de Using filesort é baixo. Ao otimizar a operação de classificação, tentamos otimizá-la como Using index.
explain select id,age,phone from tb_user order by age ;

explain select id,age,phone from tb_user order by age, phone ;

Como não há índice para idade e telefone, ao reordenar neste momento, Using filesort aparece e o desempenho de classificação é baixo.
criar índice
-- 创建索引
create index idx_user_age_phone_aa on tb_user(age,phone);
Após criar o índice, classifique-o em ordem crescente de acordo com idade, telefone
explain select id,age,phone from tb_user order by age;

explain select id,age,phone from tb_user order by age , phone;

Depois que o índice é estabelecido, a consulta de classificação é executada novamente e a classificação de arquivos Using original é alterada para o índice Using, e o desempenho é relativamente alto.
Após criar o índice, classifique em ordem decrescente de acordo com idade, telefone
explain select id,age,phone from tb_user order by age desc , phone desc ;

Using index também aparece, mas Backward index scan aparece em Extra neste momento, o que representa o índice de varredura reversa, pois no índice que criamos no MySQL, os nós folha do índice padrão são classificados de pequeno a grande, e neste momento nós consultar a classificação Ao digitalizar, é de grande para pequeno, portanto, ao digitalizar, é uma verificação reversa e uma verificação de índice reverso será exibida. Na versão MySQL8, o índice descendente é suportado, também podemos criar o índice descendente
Classificar por telefone, idade em ordem crescente, telefone primeiro, idade por último
explain select id,age,phone from tb_user order by phone , age;

Ao classificar, você também precisa satisfazer a regra do prefixo mais à esquerda, caso contrário, a classificação de arquivos também aparecerá. Porque ao criar um índice, idade é o primeiro campo e telefone é o segundo campo, portanto, ao ordenar, deve estar nesta ordem, caso contrário, aparecerá Usingfilesort.
Descendente de acordo com a idade, telefone, um ascendente, um descendente
explain select id,age,phone from tb_user order by age asc , phone desc ;

Porque ao criar um índice, se a ordem não for especificada, o padrão é classificar em ordem crescente, e ao consultar, uma crescente e outra decrescente, aparecerá Using filesort.

Para resolver os problemas acima, podemos criar um índice.Neste índice conjunto, a idade é classificada em ordem crescente e o telefone é classificado em ordem inversa.
Crie um índice conjunto (idade em ordem crescente, telefone em ordem inversa)
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);
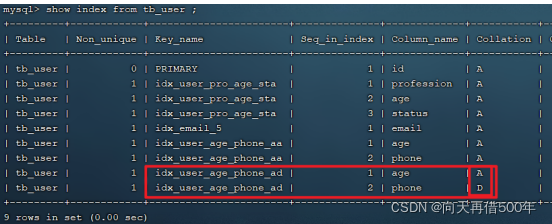
explain select id,age,phone from tb_user order by age asc , phone desc ;

ordem por princípio de otimização
- Estabeleça um índice adequado de acordo com o campo de classificação e também siga a regra do prefixo mais à esquerda ao classificar vários campos.
- Use índices de cobertura sempre que possível.
- Classificação de vários campos, um ascendente e outro decrescente, neste momento, você precisa prestar atenção às regras (ASC/DESC) ao criar um índice conjunto.
- Se a classificação de arquivos for inevitável, ao classificar uma grande quantidade de dados, você poderá aumentar adequadamente o tamanho do buffer de classificação sort_buffer_size (padrão 256k).
agrupar por otimização
Operações de agrupamento, analisamos principalmente o impacto dos índices nas operações de agrupamento.
Em seguida, na ausência de um índice, execute o seguinte SQL para consultar o plano de execução:
explain select profession , count(*) from tb_user group by profession ;

Em seguida, criamos um índice conjunto sobre profissão, idade e status.
create index idx_user_pro_age_sta on tb_user(profession , age , status);
Em seguida, execute o mesmo SQL de antes para visualizar o plano de execução.
explain select profession , count(*) from tb_user group by profession ;

Em seguida, execute a seguinte consulta de agrupamento SQL para visualizar o plano de execução:
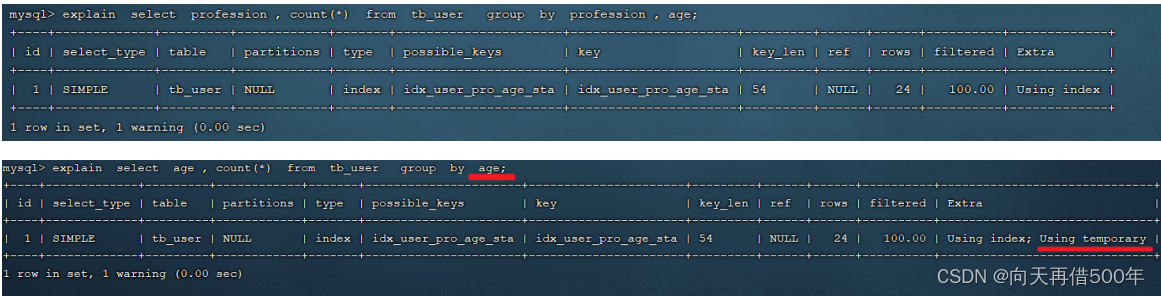
Descobrimos que se agrupado apenas por idade, aparecerá Using temporário; e se estiver agrupado de acordo com a profissão e a idade, não haverá o Using temporário. A razão é porque para a operação de agrupamento, no índice conjunto, também está em conformidade com a regra do prefixo mais à esquerda.
agrupar por princípio de otimização
- Ao agrupar operações, você pode melhorar a eficiência por meio da indexação.
- Ao agrupar operações, o uso de índices também atende à regra de prefixo mais à esquerda.
otimização de limite
Quando a quantidade de dados for relativamente grande, se a consulta de paginação limite for executada, quanto mais para trás na consulta, menor será a eficiência da consulta de paginação.
Através do teste, veremos que quanto mais abaixo na página, menor a eficiência da consulta de paginação, que é o problema da consulta de paginação. Porque, ao realizar a consulta de paginação, se o limite 2000000,10 for executado, o MySQL precisará classificar os primeiros 2000010 registros e retornará apenas 2000000 - 2000010 registros, outros registros serão descartados e o custo da classificação da consulta é muito alto.
Ideia de otimização: Na consulta de paginação geral, o desempenho pode ser melhor aprimorado criando um índice de cobertura, que pode ser otimizado na forma de índice de cobertura e subconsulta.
explain select * from tb_sku t , (select id from tb_sku order by id
limit 2000000,10) a where t.id = a.id;
otimização de contagem
select count(*) from tb_user ;
No teste anterior, descobrimos que se a quantidade de dados for grande, é muito demorado realizar a operação de contagem.
O mecanismo MyISAM armazena o número total de linhas em uma tabela no disco, portanto, ao executar count( ), ele retornará diretamente esse número, o que é muito eficiente; mas se for uma contagem condicional, MyISAM também é lento.
O mecanismo InnoDB é problemático, quando executa count( ), ele precisa ler os dados do mecanismo linha por linha e, em seguida, acumular a contagem.
contagem de uso
count() é uma função agregada. Para o conjunto de resultados retornado, ele é julgado linha por linha. Se o parâmetro da função count não for NULL, o valor acumulado será adicionado por 1, caso contrário não será adicionado e, finalmente, o valor acumulado valor é devolvido.
Uso: contagem(*), contagem(chave primária), contagem(campo), contagem(número)
| contagem de uso | significado |
|---|---|
| contagem (chave primária) | O mecanismo InnoDB percorrerá toda a tabela, retirará o valor de id da chave primária de cada linha e o retornará à camada do servidor. Depois que a camada de serviço obtém a chave primária, ela acumula diretamente por linha (a chave primária não pode ser nula) |
| contagem(campo) | Não há restrição não nula: o mecanismo InnoDB percorrerá toda a tabela para retirar o valor do campo de cada linha e devolvê-lo à camada de serviço. A camada de serviço determina se é nulo ou não, e a contagem é acumulada. Existe uma restrição não nula: o mecanismo InnoDB percorrerá toda a tabela para retirar os valores dos campos de cada linha, devolvê-los à camada de serviço e acumulá-los diretamente por linha. |
| número de contagem) | O mecanismo InnoDB percorre toda a tabela, mas não recebe valores. Para cada linha retornada, a camada de serviço coloca um número "1" nela e o acumula diretamente por linha. |
| contar(*) | O mecanismo InnoDB não retira todos os campos, mas os otimiza especificamente, sem receber valores, e a camada de serviço os acumula diretamente por linha. |
Se classificado por eficiência, count(field) < count(primary key id) < count(1) ≈ count( ), então tente usar count( ).
atualização de otimização
Precisamos principalmente prestar atenção às precauções quando a instrução de atualização é executada.
update course set name = 'javaEE' where id = 1 ;
Quando executamos a instrução SQL excluída, os dados da linha com id 1 serão bloqueados e, em seguida, o bloqueio da linha será liberado após a confirmação da transação.
Mas quando estamos executando o seguinte SQL.
update course set name = 'SpringBoot' where name = 'PHP' ;
Quando abrimos várias transações e executamos o SQL acima, descobrimos que os bloqueios de linha são atualizados para bloqueios de tabela. O desempenho da instrução de atualização é bastante reduzido.
O bloqueio de linha do InnoDB é um bloqueio para um índice, não um bloqueio para um registro, e o índice não pode ser invalidado, caso contrário, ele será atualizado de um bloqueio de linha para um bloqueio de tabela.