1. Visão geral do tratador
1. Definição do tratador
Zookeeper é um projeto Apache distribuído de código aberto que fornece serviços de coordenação para estruturas distribuídas.
2. Mecanismo de funcionamento do Zookeeper
Zookeeper é entendido sob a perspectiva do padrão de design: é uma estrutura de gerenciamento de serviços distribuídos projetada com base no padrão observador. É responsável por armazenar e gerenciar dados que interessam a todos e, em seguida, aceita o registro de observadores. Uma vez que o status destes alterações de dados, o Zookeeper será responsável por notificar os observadores registrados no Zookeeper para reagirem de acordo. Em outras palavras, Zookeeper = sistema de arquivos + mecanismo de notificação.
3. Recursos do Zookeeper
(1) Zookeeper: um líder e um grupo de seguidores.
(2) Enquanto mais da metade dos nós do cluster Zookeeper sobreviverem, o cluster Zookeeper poderá servir normalmente. Portanto, Zookeeper é adequado para instalar um número ímpar de servidores.
(3) Consistência global de dados: Cada servidor salva uma cópia dos mesmos dados. Não importa a qual servidor o cliente se conecte, os dados são consistentes.
(4) As solicitações de atualização são executadas sequencialmente. As solicitações de atualização do mesmo Cliente são executadas sequencialmente na ordem em que são enviadas, ou seja, primeiro a entrar, primeiro a sair.
(5) Atomicidade da atualização de dados, uma atualização de dados é bem-sucedida ou falha.
(6) Em tempo real, dentro de um determinado intervalo de tempo, o Cliente pode ler os dados mais recentes.
4. Estrutura de dados do Zookeeper
A estrutura do modelo de dados ZooKeeper é muito semelhante ao sistema de arquivos Linux, pode ser considerada uma árvore como um todo, e cada nó é chamado de ZNode. Cada ZNode pode armazenar 1 MB de dados por padrão, e cada ZNode pode ser identificado exclusivamente por seu caminho.
5. Cenários de aplicação do Zookeeper
Os serviços fornecidos incluem: serviço de nomenclatura unificado, gerenciamento de configuração unificado, gerenciamento de cluster unificado, nós de servidor dinâmicos online e offline, balanceamento de carga suave, etc.
●Serviço de nomenclatura unificado
Em um ambiente distribuído, muitas vezes é necessário nomear aplicativos/serviços de maneira uniforme para facilitar a identificação. Por exemplo: o IP não é fácil de lembrar, mas o nome de domínio é fácil de lembrar.
●Gerenciamento de configuração unificado
(1) Em um ambiente distribuído, a sincronização de arquivos de configuração é muito comum. Geralmente é necessário que as informações de configuração de todos os nós em um cluster sejam consistentes, como um cluster Kafka. Depois de modificar o arquivo de configuração, espero que ele possa ser sincronizado rapidamente para cada nó.
(2) O gerenciamento de configuração pode ser implementado pelo ZooKeeper. As informações de configuração podem ser gravadas em um Znode no ZooKeeper. Cada servidor cliente escuta este Znode. Assim que os dados no Znode forem modificados, o ZooKeeper notificará cada servidor cliente.
●Gerenciamento unificado de clusters
(1) Num ambiente distribuído, é necessário compreender o estado de cada nó em tempo real. Alguns ajustes podem ser feitos com base no status em tempo real do nó.
(2) O ZooKeeper pode monitorar as mudanças no status do nó em tempo real. As informações do nó podem ser gravadas em um ZNode no ZooKeeper. Monitore este ZNode para obter suas alterações de status em tempo real.
●Servidor dinâmico on-line e off-line
O cliente pode obter informações em tempo real sobre as alterações on-line e off-line do servidor.
●Balanceamento de carga suave
Registre o número de visitas a cada servidor no Zookeeper e deixe o servidor com o menor número de visitas lidar com a última solicitação do cliente.
6. Mecanismo de eleição do tratador
●Iniciar o mecanismo eleitoral pela primeira vez
(1) O servidor 1 inicia e inicia uma eleição. O Servidor 1 dá seu voto. Neste momento, o servidor 1 tem um voto, que não é suficiente para mais da metade (3 votos), a eleição não pode ser concluída e o status do servidor 1 permanece PROCURANDO;
(2) O servidor 2 inicia e inicia outra eleição. Os servidores 1 e 2 votam em si mesmos e trocam informações de voto: neste momento, o servidor 1 descobre que o myid do servidor 2 é maior do que aquele em que está votando atualmente (servidor 1) e altera a votação para recomendar o servidor 2. Neste momento, o servidor 1 tem 0 votos, o servidor 2 tem 2 votos e não há mais da metade dos resultados. A eleição não pode ser concluída e o status dos servidores 1 e 2 permanece PROCURANDO.
(3) O servidor 3 inicia e inicia uma eleição. Neste momento, ambos os servidores 1 e 2 mudarão os votos para o servidor 3. Os resultados desta votação: Servidor 1 tem 0 votos, Servidor 2 tem 0 votos e Servidor 3 tem 3 votos. Neste momento, o servidor 3 tem mais da metade dos votos e o servidor 3 é eleito líder. Os servidores 1 e 2 alteram o status para SEGUINTE e o servidor 3 altera o status para LEADING;
(4) O servidor 4 inicia e inicia uma eleição. Neste momento, os servidores 1, 2 e 3 não estão mais no estado LOOKING e não alterarão as informações de votação. O resultado da troca de informações de voto: o Servidor 3 tem 3 votos e o Servidor 4 tem 1 voto. Neste momento, o servidor 4 obedece à maioria, altera as informações de votação para o servidor 3 e altera o status para SEGUINTE;
(5) O servidor 5 inicia e atua como o irmão mais novo, como o servidor 4.

●Esta não é a primeira vez que o mecanismo eleitoral é iniciado
(1) Quando um servidor no cluster ZooKeeper encontrar uma das duas situações a seguir, ele começará a entrar na eleição de Líder:
1) A inicialização do servidor é iniciada.
2) O servidor não pode manter uma conexão com o Líder enquanto estiver em execução.
(2) Quando uma máquina entra no processo de eleição do Líder, o cluster atual também pode estar nos dois estados a seguir:
1) Já existe um Líder no cluster.
Para situações onde já existe um líder, quando a máquina tentar eleger um líder, ela será informada das informações do líder do servidor atual, para esta máquina basta estabelecer uma conexão com a máquina líder e sincronizar o status.
2) Na verdade não há Líder no cluster.
Suponha que o ZooKeeper consista em 5 servidores, com SIDs 1, 2, 3, 4 e 5 e ZXIDs 8, 8, 8, 7 e 7, e o servidor com SID 3 seja o Líder. Em algum momento, os servidores 3 e 5 falharam, então a eleição do Líder começou.
Regras para eleição de líderes:
1. Aquele com a ÉPOCA maior vence diretamente.
2. ÉPOCA é a mesma, vence aquele com o ID de transação maior.
3. Se os IDs de transação forem iguais, aquele com o ID de servidor maior vence.
-------------------------------------------------- ----------------------------------
SID: ID do servidor. Usado para identificar exclusivamente uma máquina no cluster ZooKeeper. Cada máquina não pode ser repetida e é consistente com myid.
ZXID: ID da transação. ZXID é um ID de transação usado para identificar uma alteração no status do servidor. Em determinado momento, o valor ZXID de cada máquina do cluster pode não ser exatamente o mesmo, isso está relacionado à velocidade lógica de processamento da "solicitação de atualização" do servidor ZooKeeper.
Época: O codinome de cada termo do Líder. Quando não há líder, o valor do relógio lógico na mesma rodada de votação é o mesmo. Esses dados aumentarão cada vez que um voto for lançado.
2. Implantar cluster Zookeeper
1. Etapas para implantar um cluster Zookeeper
Prepare 3 servidores para cluster Zookeeper
192.168.229.33
192.168.229.77
192.168.229.99
1.1 Preparação antes da instalação
//Desliga o firewall
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
//Instalar o JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
//Baixe o pacote de instalação.
Endereço oficial de download: Índice de /dist/zookeeper
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
1.2. Instale o Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
1.3 Modificar arquivo de configuração
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.2.33:3188:3288
server.2=192.168.2.77:3188:3288
server.3=192.168.2.99:3188:3288
server.A=B:C:D
●A é um número, indicando qual é o número do servidor. No modo cluster, você precisa criar um arquivo myid no diretório especificado por dataDir em zoo.cfg. Há um dado neste arquivo que é o valor de A. O Zookeeper lê este arquivo quando é iniciado e obtém os dados dentro e o configuração em zoo.cfg. As informações são comparadas para determinar qual servidor se trata.
●B é o endereço deste servidor.
●C é a porta através da qual este servidor Seguidor troca informações com o servidor Líder no cluster.
●D é se o servidor Líder no cluster desligar, uma porta é necessária para reeleger e selecionar um novo Líder, e esta porta é a porta usada pelos servidores para se comunicarem entre si durante a eleição.
-------------------------------------------------- ----------------------------------
1.4 Copie o arquivo de configuração configurado do Zookeeper para outras máquinas
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.229.50:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.229.40:/usr/local/zookeeper-3.5.7/conf/
1.5 Crie um diretório de dados e um diretório de log em cada nó
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
1.6 Crie um arquivo myid no diretório especificado por dataDir de cada nó
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid
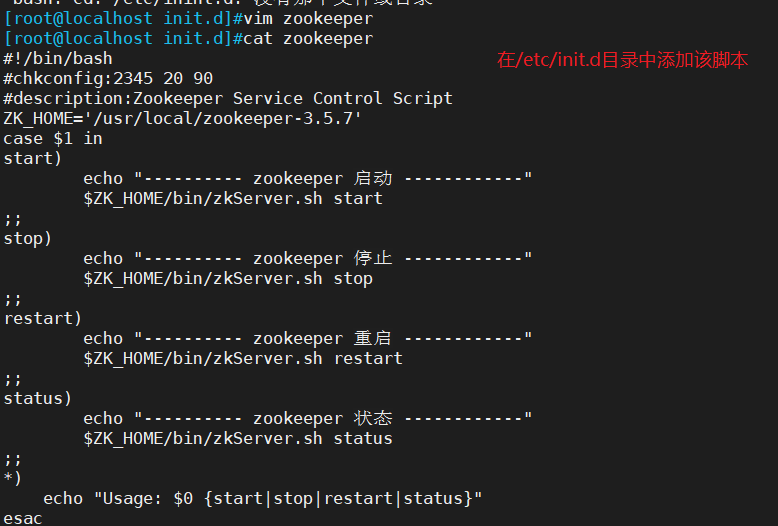
1.7 Configurar script de inicialização do Zookeeper
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
1.8 Configure a inicialização automática na inicialização
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
1.9 Inicie o Zookeeper separadamente
service zookeeper start
1.10 Ver status atual
service zookeeper status
2. Operação da instância: implantar cluster Zookeeper
2.1 Preparação antes da instalação

2.2. Instale o Zookeeper

2.3 Modificar arquivo de configuração

1.4 Copie o arquivo de configuração configurado do Zookeeper para outras máquinas

1.5 Crie um diretório de dados e um diretório de log em cada nó

1.6 Crie um arquivo myid no diretório especificado por dataDir de cada nó



1.7 Configurar script de inicialização do Zookeeper
1.8 Configure a inicialização automática na inicialização e inicie o serviço

1.9 Ver o status atual
Um líder, dois seguidores



3. Visão geral de Kafka
1. Por que você precisa do serviço de enfileiramento de mensagens (MQ)?
A principal razão é que, em um ambiente de alta simultaneidade, as solicitações de sincronização não são processadas a tempo e muitas vezes as solicitações são bloqueadas. Por exemplo, um grande número de solicitações acessa o banco de dados simultaneamente, resultando em bloqueios de linha e de tabela.Finalmente, muitos threads de solicitação serão acumulados, provocando muitos erros de conexão e desencadeando um efeito de avalanche.
Usamos filas de mensagens para lidar com solicitações de forma assíncrona para aliviar a pressão no sistema. As filas de mensagens são frequentemente usadas em processamento assíncrono, redução de pico de tráfego, desacoplamento de aplicativos, comunicação de mensagens e outros cenários.
Atualmente, os middlewares MQ mais comuns incluem ActiveMQ, RabbitMQ, RocketMQ, Kafka, etc.
2. Benefícios de usar filas de mensagens
(1) Desacoplamento
Permite estender ou modificar os processos de ambos os lados de forma independente, desde que sigam as mesmas restrições de interface.
(2) Restaurabilidade
Quando um componente do sistema falha, isso não afeta todo o sistema. A fila de mensagens reduz o acoplamento entre processos, portanto, mesmo que um processo que processa mensagens seja interrompido, as mensagens adicionadas à fila ainda poderão ser processadas após a recuperação do sistema.
(3) Buffer
Ajuda a controlar e otimizar a velocidade do fluxo de dados através do sistema e a resolver o problema de velocidades de processamento inconsistentes de mensagens de produção e mensagens de consumidor.
(4) Flexibilidade e capacidade de processamento de pico
O aplicativo ainda precisa continuar funcionando apesar do aumento no tráfego, mas tais picos de tráfego são incomuns. Seria um enorme desperdício investir recursos para ficar de prontidão com base no padrão de capacidade para lidar com esses picos de visitas. O uso de filas de mensagens pode permitir que os principais componentes resistam à pressão de acesso repentina sem entrar em colapso completo devido a solicitações repentinas e sobrecarregadas.
(5) Comunicação assíncrona
Muitas vezes, os usuários não querem ou não precisam processar mensagens imediatamente. A fila de mensagens fornece um mecanismo de processamento assíncrono que permite aos usuários colocar uma mensagem na fila, mas não processá-la imediatamente. Coloque quantas mensagens quiser na fila e processe-as quando necessário.
3. Dois modos de fila de mensagens
(1) Modo ponto a ponto (um para um, os consumidores extraem dados ativamente e as mensagens são apagadas após serem recebidas)
O produtor da mensagem produz a mensagem e a envia para a fila de mensagens e, em seguida, o consumidor da mensagem a retira da fila de mensagens e a consome. Depois que a mensagem é consumida, não há mais armazenamento na fila de mensagens, portanto é impossível para o consumidor da mensagem consumir a mensagem que foi consumida. A fila de mensagens suporta a existência de vários consumidores, mas para uma mensagem, apenas um consumidor pode consumi-la.
(2) Modo de publicação/assinatura (um para muitos, também chamado de modo observador, o consumidor não limpará a mensagem após consumir os dados)
Um produtor de mensagens (publicador) publica uma mensagem em um tópico e vários consumidores de mensagens (assinaturas) consomem a mensagem ao mesmo tempo. Ao contrário do método ponto a ponto, as mensagens publicadas em um tópico serão consumidas por todos os assinantes.
O padrão publicar/assinar define um relacionamento de dependência um-para-muitos entre objetos, de modo que sempre que o estado de um objeto (objeto alvo) mudar, todos os objetos que dependem dele (objetos observadores) serão notificados e atualizados automaticamente.
4. Definição de Kafka
Kafka é uma fila de mensagens distribuídas (MQ, Message Queue) baseada no modelo de publicação/assinatura, usada principalmente na área de processamento em tempo real de big data.
5. Introdução a Kafka
Kafka foi originalmente desenvolvido pela Linkedin Company. É um sistema de middleware de mensagens distribuídas que suporta partições, múltiplas réplicas e é coordenado pelo Zookeeper. Sua maior característica é que ele pode processar grandes quantidades de dados em tempo real. Para atender a vários cenários de demanda, como sistema de processamento em lote baseado em hadoop, sistema de baixa latência em tempo real, mecanismo de streaming Spark/Flink, log de acesso nginx, serviço de mensagens, etc., escrito em linguagem scala,
O Linkedin contribuiu para a Fundação Apache em 2010 e se tornou um dos principais projetos de código aberto.
6. Recursos do Kafka
●Alto rendimento, baixa latência
Kafka pode processar centenas de milhares de mensagens por segundo e sua latência é de apenas alguns milissegundos. Cada tópico pode ser dividido em várias partições, e o grupo de consumidores realiza operações de consumo em partições para melhorar os recursos de balanceamento de carga e de consumo.
●Escalabilidade
Cluster Kafka suporta expansão a quente
●Durabilidade e confiabilidade
As mensagens são mantidas no disco local e o backup de dados é suportado para evitar perda de dados.
●Tolerância a falhas
Permitir falhas de nós no cluster (no caso de múltiplas cópias, se o número de cópias for n, n-1 nós podem falhar)
●Alta simultaneidade
Apoie milhares de clientes lendo e escrevendo ao mesmo tempo
7. Arquitetura do sistema Kafka
(1) Corretor
Um servidor kafka é um corretor. Um cluster consiste em vários corretores. Um corretor pode acomodar vários tópicos.
(2)Tópico
Pode ser entendida como uma fila, e tanto produtores quanto consumidores estão orientados para o mesmo tema.
Semelhante ao nome da tabela do banco de dados ou ao índice do ES
Mensagens de tópicos fisicamente diferentes são armazenadas separadamente.
(3) Partição
Para obter escalabilidade, um tópico muito grande pode ser distribuído para vários corretores (ou seja, servidores).Um tópico pode ser dividido em uma ou mais partições, e cada partição é uma fila ordenada. Kafka apenas garante que os registros dentro da partição sejam ordenados, mas não garante a ordem das diferentes partições no tópico.
Cada tópico possui pelo menos uma partição. Quando o produtor gerar dados, ele selecionará a partição de acordo com a estratégia de distribuição e, em seguida, anexará a mensagem ao final da fila da partição especificada.
Regras de roteamento de dados de partição:
- Se a partição for especificada, use-a diretamente;
- Se a partição não for especificada, mas a chave for especificada (equivalente a um atributo na mensagem), uma partição será selecionada fazendo hash do valor do módulo da chave;
- Nem a partição nem a chave são especificadas e a pesquisa é usada para selecionar uma partição.
Cada mensagem terá um número auto-crescente usado para identificar o deslocamento da mensagem, e a sequência de identificação começa em 0.
Os dados em cada partição são armazenados usando vários arquivos de segmento.
Se um tópico tiver diversas partições, a ordem dos dados não poderá ser garantida ao consumir dados. Em cenários onde a ordem de consumo de mensagens é estritamente garantida (como vendas flash de produtos e captura de envelopes vermelhos), o número de partições precisa ser definido como 1.
●O corretor armazena dados do tópico. Se um tópico tiver N partições e o cluster tiver N corretores, cada corretor armazenará uma partição do tópico.
●Se um tópico tiver N partições e o cluster tiver (N+M) brokers, então N brokers armazenam uma partição do tópico e os M brokers restantes não armazenam dados de partição do tópico.
●Se um tópico tiver N partições e o número de agentes no cluster for menor que N, então um agente armazena uma ou mais partições do tópico. Em ambientes de produção reais, tente evitar esta situação, que pode facilmente levar ao desequilíbrio dos dados do cluster Kafka.
Motivo do particionamento
●É conveniente expandir no cluster, cada partição pode ser ajustada para se adaptar à máquina onde está localizada, e um tópico pode ser composto por múltiplas partições, para que todo o cluster possa se adaptar a dados de qualquer tamanho;
●A simultaneidade pode ser melhorada porque pode ser lida e escrita em unidades de partição.
(4) Réplica
Réplica. Para garantir que, quando um nó no cluster falhar, os dados da partição no nó não sejam perdidos e o Kafka ainda possa continuar funcionando. O Kafka fornece um mecanismo de réplica. Cada partição de um tópico possui várias réplicas e um líder. e vários seguidores.
(5)Líder
Cada partição possui múltiplas cópias, das quais uma e apenas uma serve como Líder. O Líder é a partição atualmente responsável pela leitura e gravação de dados.
(6)Seguidor
O Seguidor segue o Líder, todas as solicitações de gravação são roteadas através do Líder, as alterações de dados são transmitidas para todos os Seguidores e os Seguidores mantêm os dados sincronizados com o Líder. O seguidor é responsável apenas pelo backup e não pela leitura e gravação de dados.
Se o Líder falhar, um novo Líder é eleito entre os Seguidores.
Quando um Seguidor desliga, fica preso ou sincroniza muito lentamente, o Líder excluirá o Seguidor da lista ISR (uma coleção de Seguidores mantida pelo Líder que está sincronizada com o Líder) e criará um novo Seguidor.
(7) Produtor
O produtor é o editor dos dados. Esta função publica mensagens no tópico Kafka.
Depois que o corretor recebe a mensagem enviada pelo produtor, o corretor anexa a mensagem ao arquivo de segmento atualmente usado para anexar dados.
As mensagens enviadas pelo produtor são armazenadas em uma partição. O produtor também pode especificar a partição para armazenamento de dados.
(8) Consumidor
Os consumidores podem ler os dados do corretor. Os consumidores podem consumir dados de vários tópicos.
(9)Grupo de Consumidores(CG)
Um grupo de consumidores consiste em vários consumidores.
Todos os consumidores pertencem a um determinado grupo de consumidores, ou seja, o grupo de consumidores é um assinante lógico. Um nome de grupo pode ser especificado para cada consumidor. Se nenhum nome de grupo for especificado, ele pertencerá ao grupo padrão.
Reunir vários consumidores para processar os dados de um determinado tópico pode melhorar rapidamente os recursos de consumo de dados.
Cada consumidor do grupo de consumidores é responsável por consumir dados de diferentes partições. Uma partição só pode ser consumida por consumidores de um grupo para evitar que os dados sejam lidos repetidamente.
Os grupos de consumidores não têm influência uns sobre os outros.
(10) deslocamento de deslocamento
Pode identificar exclusivamente uma mensagem.
O deslocamento determina a localização dos dados lidos e não haverá problemas de segurança do thread.O consumidor usa o deslocamento para determinar a próxima mensagem a ser lida (ou seja, o local de consumo).
Depois que a mensagem é consumida, ela não é excluída imediatamente, para que várias empresas possam reutilizar as mensagens do Kafka.
Uma determinada empresa também pode reler mensagens modificando o deslocamento, que é controlado pelo usuário.
As mensagens serão eventualmente excluídas e o ciclo de vida padrão é de 1 semana (7*24 horas).
(11)Zookeeper
Kafka usa Zookeeper para armazenar metainformações do cluster.
Como o consumidor pode sofrer cortes de energia e outras falhas durante o processo de consumo, após a recuperação do consumidor, ele precisa continuar consumindo da posição anterior à falha. Portanto, o consumidor precisa registrar em tempo real qual compensação consumiu para que possa pode continuar consumindo após a falha ser restaurada.
Antes da versão 0.9 do Kafka, o consumidor salva compensações no Zookeeper por padrão; a partir da versão 0.9, o consumidor salva compensações em um tópico integrado do Kafka por padrão, que é __consumer_offsets.
4. Implantar zookeeper + cluster kafka
1. Implantar zookeeper + cluster kafka
1.1 Baixe o pacote de instalação
Endereço oficial de download: Apache Kafka
cd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz
1.2. Instale o Kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
1.3 Modificar arquivo de configuração
cd /usr/local/kafka/config/
cp server.properties{,.bak}
vim server.properties
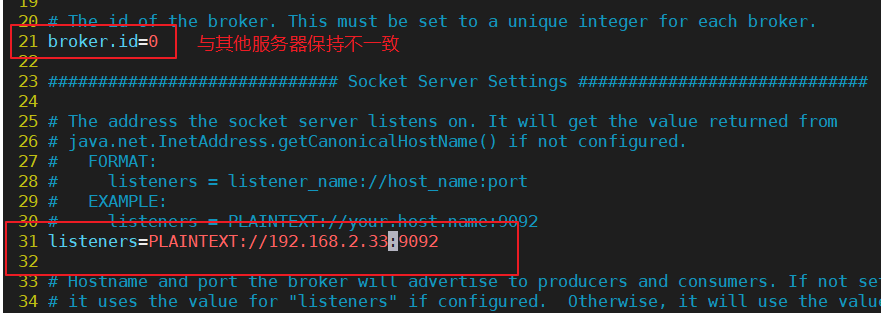
broker.id=0 #21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.2.33:9092 #31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.2.33:2181,192.168.2.77:2181,192.168.2.99:2181 #123行,配置连接Zookeeper集群地址
1.4 Modificar variáveis de ambiente
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
1.5 Configurar script de inicialização do Zookeeper
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
1.6 Configure a inicialização automática na inicialização
chmod +x /etc/init.d/kafka
chkconfig --add kafka
1.7 Inicie o Kafka separadamente
service kafka start
1.8 Operações de linha de comando Kafka
//Criar tópico
kafka-topics.sh --create --zookeeper 192.168.2.33:2181,192.168.23.77:2181,192.168.2.99:2181 --replication-factor 2 --partitions 3 --topic test
-------------------------------------------------------------------------------------
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
------------------------------------
//Ver todos os tópicos no servidor atual
kafka-topics.sh --list --zookeeper 192.168.2.33:2181,192.168.2.77:2181,192.168.2.99:2181
//Ver detalhes de um tópico
kafka-topics.sh --describe --zookeeper 192.168.2.33:2181,192.168.2.77:2181,192.168.2.99:2181
//faz um anúncio
kafka-console-producer.sh --broker-list 192.168.2.33:9092,192.168.2.77:9092,192.168.2.99:9092 --topic test
//Consumir mensagens
kafka-console-consumer.sh --bootstrap-server 192.168.2.33:9092,192.168.2.77:9092,192.168.2.99:9092 --topic test --from-beginning
-------------------------------------------------------------------------------------
--from-beginning:会把主题中以往所有的数据都读取出来
-------------------------------------------------------------------------------------
//Modifica o número de partições
kafka-topics.sh --zookeeper 192.168.2.33:2181,192.168.2.77:2181,192.168.2.99:2181 --alter --topic test --partitions 6
//Exclui tópico
kafka-topics.sh --delete --zookeeper 192.168.2.33:2181,192.168.2.77:2181,192.168.2.99:2181 --topic test
2. Operação da instância: implantar cluster zookeeper + kafka
1.1 Instale o cluster zookeeper
Consulte o artigo acima neste blog para obter detalhes e continue com o experimento acima (operando em todos os servidores de cluster)
1.2 Baixe o pacote de instalação e instale o kafka


1.3 Modificar arquivo de configuração



1.4 Modificar variáveis de ambiente

1.5 Configure o script de inicialização do kafka e defina a inicialização automática na inicialização para iniciar o kafka

1.6 Operações de linha de comando Kafka
Crie um tópico e visualize-o



Postar e ler mensagens

Modifique o número de partições


Excluir tópico

5. Implantar Filebeat + Kafka + ELK
1. Etapas de operação para implantação do Filebeat+Kafka+ELK
1.1. Implantar cluster Zookeeper + Kafka
Veja acima, seguido pelo experimento acima
1.2. Implantar o Filebeat
Para construir ELK, consulte o blog anterior para obter detalhes
cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/*.log
......
#添加输出到 Kafka 的配置
output.kafka:
enabled: true
hosts: ["192.168.2。33:9092","192.168.2.77:9092","192.168.2.99:9092"] #指定 Kafka 集群配置
topic: "filebeat_test" #指定 Kafka 的 topic
#启动 filebeat
./filebeat -e -c filebeat.yml
1.3. Implante o ELK e crie um novo arquivo de configuração do Logstash no nó onde o componente Logstash está localizado.
cd /etc/logstash/conf.d/
vim filebeat.conf
input {
kafka {
bootstrap_servers => "192.168.229.60:9092,192.168.229.50:9092,192.168.229.40:9092"
topics => "filebeat_test"
group_id => "test123"
auto_offset_reset => "earliest"
}
}
output {
elasticsearch {
hosts => ["192.168.229.70:9200"]
index => "filebeat_test-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
1.4 Iniciar logstash
logstash -f filebeat.conf
1.5 Teste de acesso ao navegador
Visite http://192.168.2.22:5601 com o navegador para fazer login no Kibana, clique no botão "Criar padrão de índice" para adicionar o índice "filebeat_test-*", clique no botão "criar" para criar e clique no botão " Botão Descobrir" para visualizar informações do gráfico e informações de registro.