Diretório de artigos
- Perguntas da entrevista do Redis (46 perguntas)
- Base
-
- 1. O que é Redis?
- 2.Para que o Redis pode ser usado?
- 3.Quais estruturas de dados o Redis possui?
- 4.Por que o Redis é rápido?
- 5. Você pode falar sobre multiplexação de E/S?
- 6. Por que o Redis escolheu o single-threading nos primeiros dias?
- 7.Por que o Redis6.0 usa multithreading?
- 8.Quais são os métodos de persistência do Redis? Qual é a diferença?
- 9.Quais são as vantagens e desvantagens do RDB e do AOF?
- 10.Como escolher entre RDB e AOF?
- 11. Recuperação de dados Redis?
- 12. Você entende a persistência híbrida do Redis 4.0?
- Alta disponibilidade (entenda)
-
- 13. Você entende a replicação mestre-escravo?
- 14.Quantas topologias comuns existem para Redis mestre-escravo?
- 15.Você entende o princípio de replicação mestre-escravo do Redis?
- 16. Fale sobre o método de sincronização de dados mestre-escravo?
- 17. Quais são os problemas da replicação mestre-escravo?
- 18. Você entende o Redis Sentinel?
- 19.Você conhece o princípio de implementação do Redis Sentinel?
- 20. Você entende a eleição do Nó Sentinela líder?
- 21. Como são selecionados os novos nós mestres?
- 22.Você entende o cluster Redis?
- 23. Como os dados do cluster são particionados?
- 24. Você pode falar sobre o princípio do cluster Redis?
- 25. Fale sobre escalonamento de cluster?
- projeto de cache
-
- 26.O que são quebra de cache, penetração de cache e avalanche de cache?
- 27. Você pode falar sobre o filtro Bloom?
- 28. Como garantir a consistência dos dados do cache e do banco de dados?
- 29. Como garantir a consistência entre cache local e cache distribuído?
- 30. Como lidar com teclas de atalho?
- 31. Como fazer o pré-aquecimento do cache?
- 32. Reconstrução da chave do hotspot? pergunta? resolver?
- 33. Existe um problema de poço sem fundo? Como resolver?
- Operação e manutenção do Redis
-
- 34. Como lidar com a memória insuficiente reportada pelo Redis?
- 35.Quais são as estratégias de reciclagem de dados expiradas do Redis?
- 36.Quais estratégias de controle de estouro de memória/eliminação de memória o Redis possui?
- 37. Bloqueio de Redis? Como lidar com isso?
- 38. Você entende a grande questão-chave?
- 39. Problemas e soluções comuns de desempenho do Redis?
- Aplicativo Redis
-
- 40. Como implementar fila assíncrona usando Redis?
- 41.Como o Redis implementa a fila de atraso?
- 42.O Redis oferece suporte a transações?
- 43. Você entende o uso de scripts Redis e Lua?
- 44.Você entende o pipeline do Redis?
- 45.Você entende como o Redis implementa bloqueios distribuídos?
- 46. Se existem 100 milhões de chaves no Redis e 100.000 delas começam com um prefixo fixo e conhecido, como encontrar todas elas?
Perguntas da entrevista do Redis (46 perguntas)
Base
1. O que é Redis?

Redis é um banco de dados NoSQL baseado em pares chave-valor.
Mais poderoso do que bancos de dados de valor-chave gerais, o valor no Redis suporta string (string), hash (hash), lista (lista), conjunto (conjunto), zset (conjunto ordenado), Bitmaps (bitmap), Existem várias estruturas de dados como HyperLogLog e GEO (posicionamento de informações geográficas), para que o Redis possa atender a muitos cenários de aplicação.
E como o Redis armazena todos os dados na memória, seu desempenho de leitura e gravação é excelente.
Além disso, o Redis também pode salvar dados de memória no disco rígido na forma de instantâneos e logs, para que os dados na memória não sejam "perdidos" quando ocorrer uma queda de energia ou falha da máquina.
Além das funções acima, o Redis também oferece funções adicionais, como expiração de chave, publicação e assinatura, transações, pipelines e scripts Lua.
Resumindo, o Redis é uma ferramenta de desempenho poderosa.
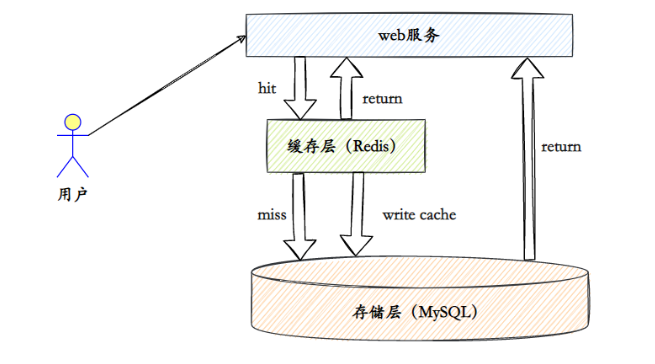
2.Para que o Redis pode ser usado?
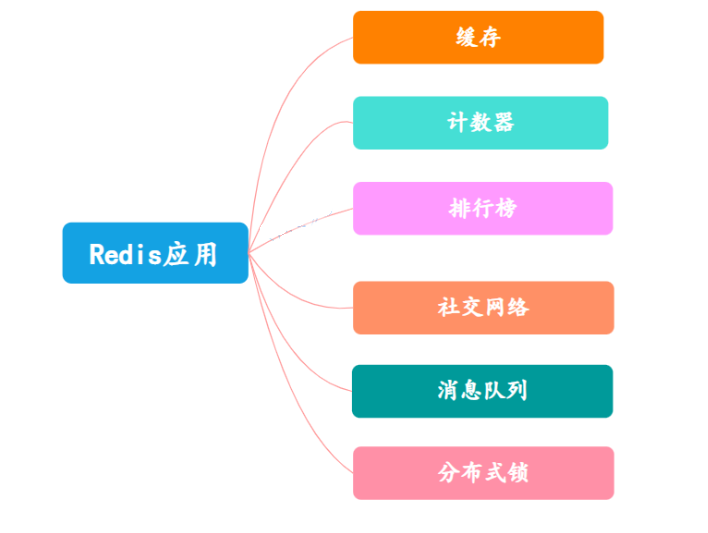
- esconderijo
É aqui que o Redis é mais amplamente usado. Basicamente, todos os aplicativos da Web usam o Redis como cache para reduzir a pressão da fonte de dados e melhorar a velocidade de resposta.
-
O Counter Redis suporta naturalmente a função de contagem e o desempenho da contagem é muito bom, podendo ser usado para registrar o número de visualizações, curtidas, etc.
-
Lista de classificação O Redis fornece estruturas de dados de lista e conjuntos ordenados. O uso adequado dessas estruturas de dados pode facilmente construir vários sistemas de classificação.
-
Gostos/não gostos de redes sociais, fãs, amigos/gostos em comum, empurrar, puxar para baixo para atualizar.
-
Fila de mensagens O Redis fornece funções de publicação e assinatura e funções de fila de bloqueio, que podem atender às funções gerais de fila de mensagens.
-
Bloqueios distribuídos Em um ambiente distribuído, usar o Redis para implementar bloqueios distribuídos também é uma aplicação comum do Redis.
A aplicação do Redis geralmente é combinada com o projeto. Tomemos como exemplo o serviço ao usuário de um projeto de comércio eletrônico:
- Armazenamento de token: depois que o usuário fizer login com sucesso, use o Redis para armazenar o token.
- Contagem de logins com falha: Use o Redis para contar. Se os logins com falha excederem um determinado número de vezes, a conta será bloqueada.
- Cache de endereço: armazenamento em cache de dados de províncias e cidades
- Bloqueio distribuído: Adicione bloqueio distribuído para login, registro e outras operações em um ambiente distribuído
- ……
3.Quais estruturas de dados o Redis possui?
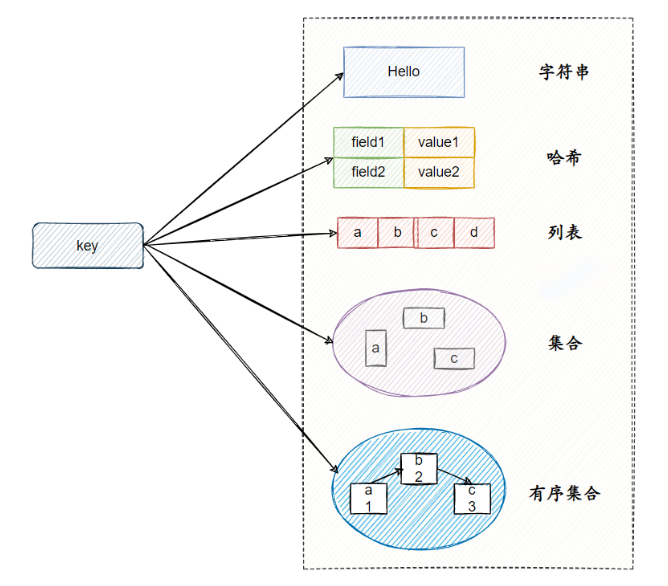
Redis possui cinco estruturas de dados básicas.
corda
String é a estrutura de dados mais básica. O valor do tipo string pode na verdade ser uma string (string simples, string complexa (como JSON, XML)), número (inteiro, número de ponto flutuante) ou mesmo binário (imagem, áudio, vídeo), mas o valor máximo Não pode exceder 512 MB.
As strings têm principalmente os seguintes cenários típicos de uso:
- Função de cache
- contar
- Compartilhar sessão
- limite de velocidade
cerquilha
O tipo hash significa que o valor-chave em si é uma estrutura de par de valores-chave.
O hash tem principalmente os seguintes cenários típicos de aplicação:
- Armazenando informações do usuário em cache
- Objeto de cache
lista
O tipo de lista é usado para armazenar várias strings ordenadas. Lista é uma estrutura de dados relativamente flexível que pode atuar como pilha e fila.
A lista apresenta principalmente os seguintes cenários de uso:
- fila de mensagens
- Lista de artigos
definir
O tipo set também é usado para armazenar vários elementos de string, mas diferentemente do tipo lista, elementos duplicados não são permitidos no conjunto e os elementos do conjunto não são ordenados.
As coleções têm principalmente os seguintes cenários de uso:
- Marcação
- Preocupação comum
conjunto classificado
Os elementos de um conjunto ordenado podem ser classificados. Mas, diferentemente da lista que usa índices subscritos como base para classificação, ela define um peso (pontuação) para cada elemento como base para classificação.
Principais cenários de aplicação de coleções ordenadas:
- Estatísticas semelhantes ao usuário
- Classificação do usuário
4.Por que o Redis é rápido?
O Redis é muito rápido. Um único Redis pode suportar centenas de milhares de simultaneidades por segundo. Comparado ao MySQL, o desempenho é dez vezes maior que o do MySQL. Existem vários motivos principais para a velocidade rápida:
- Totalmente baseado na operação da memória
- Usar um único thread evita o consumo causado pela troca de threads e condições de corrida.
- Baseado em mecanismo de multiplexação IO sem bloqueio
- Implementação da linguagem C, estrutura de dados otimizada, baseada em várias estruturas de dados básicas, redis fez muita otimização e o desempenho é extremamente alto
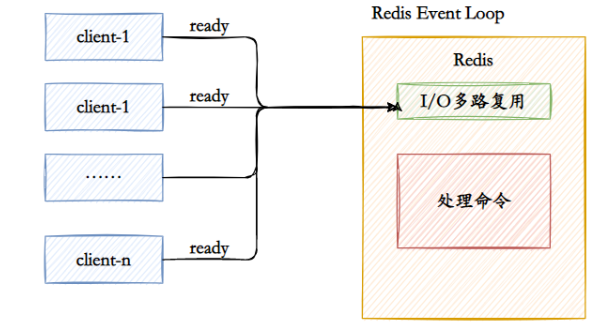
5. Você pode falar sobre multiplexação de E/S?
Citando uma resposta altamente elogiada em Zhihu para explicar o que é multiplexação de E/S. Suponha que você seja um professor e peça a 30 alunos que respondam a uma pergunta e depois verifique se eles responderam corretamente. Você tem as seguintes opções:
- A primeira opção: verifique um por um em ordem, primeiro verifique A, depois B, depois C, D. . . Se um aluno ficar preso no meio, toda a turma se atrasará. Este modelo é como usar um loop para processar soquetes um por um, sem nenhum recurso de simultaneidade.
- Segunda opção: você cria 30 clones, cada um verificando se a resposta do aluno está correta. Isso é semelhante a criar um processo ou thread para cada usuário manipular a conexão.
- A terceira opção é subir no pódio e esperar, quem terminar de responder à pergunta levantará a mão. Nesse momento, C e D levantam as mãos, indicando que terminaram de responder às perguntas. Você desce e verifica as respostas de C e D por sua vez, e então continua voltando ao pódio e espera. Nesse momento, E e A levantaram as mãos novamente e depois foram tratar de E e A.
O primeiro é o modelo de bloqueio de E/S e o terceiro é o modelo de multiplexação de E/S.
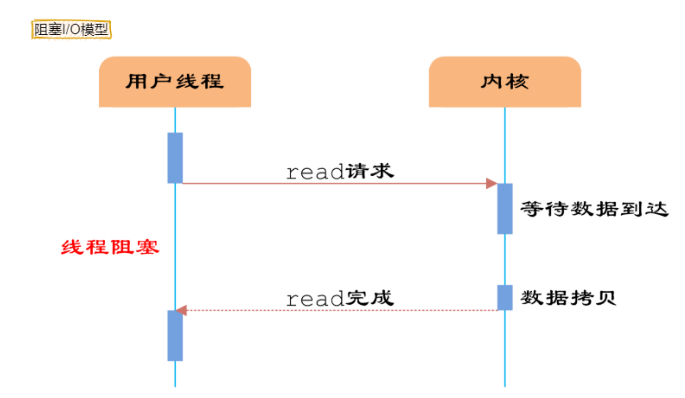
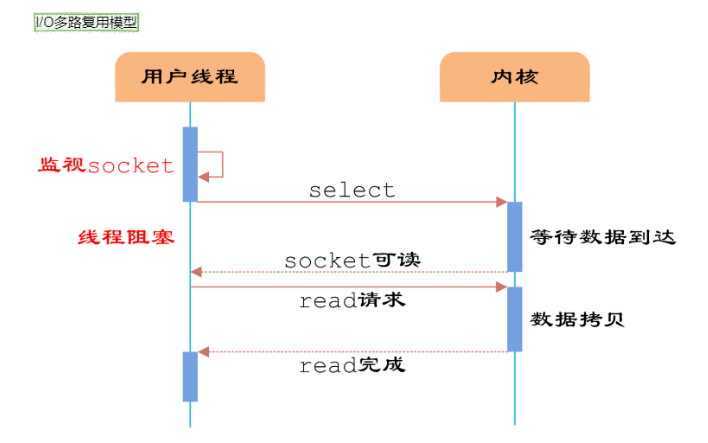
Os sistemas Linux têm três maneiras de implementar a multiplexação IO: select, poll e epoll.
Por exemplo, o método epoll consiste em registrar o fd correspondente ao soquete do usuário no epoll, e então o epoll irá ajudá-lo a monitorar quais soquetes têm mensagens chegando, evitando assim um grande número de operações inúteis. O soquete neste momento deve estar no modo sem bloqueio.
Dessa forma, todo o processo só será bloqueado ao fazer chamadas select, poll e epoll. O envio e recebimento de mensagens do cliente não será bloqueado e todo o processo ou thread será totalmente utilizado. Isso é orientado a eventos, o chamado modo reator.
6. Por que o Redis escolheu o single-threading nos primeiros dias?
O FAQ oficial afirma que, como o Redis é uma operação baseada em memória, é raro que a CPU se torne o gargalo do Redis. O gargalo do Redis é provavelmente o tamanho da memória ou as limitações da rede.
Se quiser maximizar a utilização da CPU, você pode iniciar várias instâncias do Redis em uma máquina.
PS: Existem essas respostas na Internet, e a explicação oficial é um pouco superficial. Na verdade, são razões históricas. Os desenvolvedores acharam o multi-threading problemático e, mais tarde, o problema de utilização da CPU foi deixado para os usuários.
Ao mesmo tempo, o FAQ também mencionou que o Redis começou a se tornar multithread após a versão 4.0. Além do thread principal, ele também possui threads de segundo plano para lidar com algumas operações mais lentas, como limpeza de dados sujos, liberação de conexões inúteis, exclusão de grandes chaves, etc.
7.Por que o Redis6.0 usa multithreading?
Redis não diz para usar thread único? Por que o 6.0 se tornou multithread?
O multithreading do Redis 6.0 usa multithreading para lidar com leitura e gravação de dados e análise de protocolo , mas os comandos de execução do Redis ainda são de thread único.
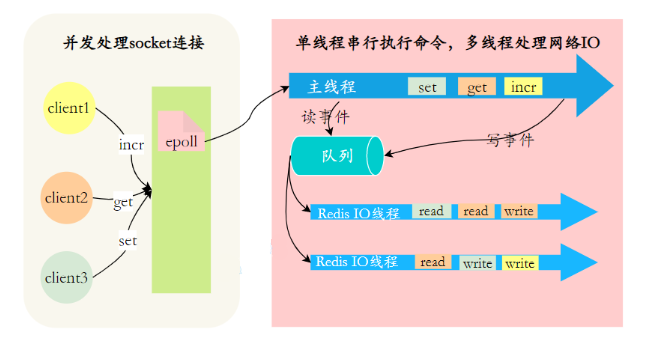
O objetivo disso é porque o gargalo de desempenho do Redis está na E/S da rede, e não na CPU. O uso de multithreads pode melhorar a eficiência da leitura e gravação de E/S, melhorando assim o desempenho geral do Redis.
8.Quais são os métodos de persistência do Redis? Qual é a diferença?
As soluções de persistência Redis são divididas em dois tipos: RDB e AOF.
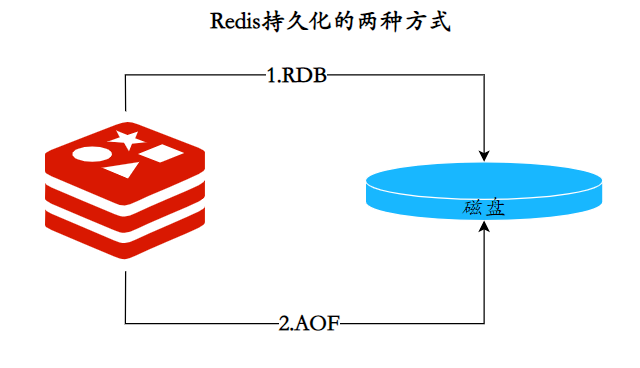
RDB
A persistência RDB é o processo de gerar um instantâneo dos dados do processo atual e salvá-lo no disco rígido. O processo de acionamento da persistência RDB é dividido em acionamento manual e acionamento automático.
O arquivo RDB é um arquivo binário compactado através do qual o estado do banco de dados em um determinado momento pode ser restaurado. Como o arquivo RDB é salvo no disco rígido, mesmo que o Redis trave ou saia, desde que o arquivo RDB exista, ele pode ser usado para restaurar o estado do banco de dados.
O acionamento manual corresponde aos comandos save e bgsave respectivamente:
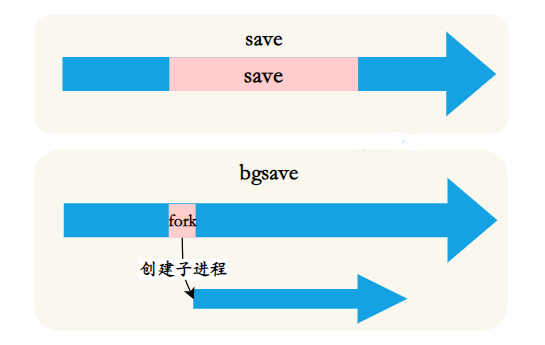
- Comando save: bloqueia o servidor Redis atual até que o processo RDB seja concluído. Para instâncias com memória relativamente grande, causará bloqueio de longo prazo e não é recomendado para uso em ambientes online.
- Comando bgsave: O processo Redis executa uma operação de bifurcação para criar um processo filho. O processo de persistência RDB é responsável pelo processo filho e termina automaticamente após a conclusão. O bloqueio ocorre apenas na fase de bifurcação e geralmente tem vida muito curta.
Os seguintes cenários acionarão automaticamente a persistência RDB:
- Use a configuração relacionada ao salvamento, como "save mn". Indica que o bgsave é acionado automaticamente quando o conjunto de dados é modificado n vezes em m segundos.
- Se o nó escravo executar uma operação de cópia completa, o nó mestre executará automaticamente bgsave para gerar um arquivo RDB e o enviará ao nó escravo.
- Ao executar o comando debug reload para recarregar o Redis, a operação de salvamento também será acionada automaticamente.
- Por padrão, ao executar o comando shutdown, o bgsave é executado automaticamente se a função de persistência AOF não estiver habilitada.
AOF
Persistência AOF (anexar apenas arquivo): registre cada comando escrito em um log independente e, em seguida, execute novamente o comando no arquivo AOF durante a reinicialização para restaurar os dados. A principal função do AOF é resolver o problema de persistência de dados em tempo real e atualmente é o método principal de persistência do Redis.
Operações de fluxo de trabalho AOF: gravação de comandos (anexar), sincronização de arquivos (sincronização), reescrita de arquivos (reescrita), reinicialização de carregamento (carregamento)
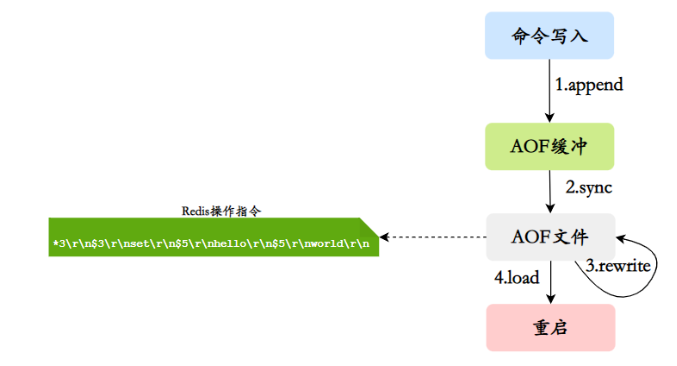
O processo é como se segue:
1) Todos os comandos de gravação serão anexados a aof_buf (buffer).
2) O buffer AOF realiza operações de sincronização com o disco rígido de acordo com a política correspondente.
3) À medida que os arquivos AOF ficam cada vez maiores, os arquivos AOF precisam ser reescritos regularmente para obter compactação.
4) Quando o servidor Redis for reiniciado, o arquivo AOF pode ser carregado para recuperação de dados.
9.Quais são as vantagens e desvantagens do RDB e do AOF?
RDB | Vantagens
- Existe apenas um arquivo binário compacto
dump.rdb, que é muito adequado para cenários de backup e cópia completa. - Possui boa tolerância a desastres e pode copiar arquivos RDB para máquinas remotas ou sistemas de arquivos para recuperação de desastres.
- Velocidade de recuperação rápida , o RDB recupera dados muito mais rápido que o método AOF
RDB |Desvantagens
- O desempenho em tempo real é baixo , o RDB persiste em intervalos e não pode atingir persistência em tempo real/persistência de segundo nível. Se ocorrer uma falha durante esse intervalo, os dados serão perdidos.
- Existem problemas de compatibilidade , durante a evolução do Redis, existem versões RDB em vários formatos, e há um problema de que a versão antiga do Redis não é compatível com a nova versão do RDB.
AOF | Vantagens
- Bom desempenho em tempo real , as propriedades de persistência aof
appendfsyncpodem ser configuradas, simalways, cada operação de comando é registrada no arquivo aof. - Ao gravar arquivos no modo anexado, mesmo que o servidor fique inativo no meio, o problema de consistência dos dados pode ser resolvido por meio da ferramenta redis-check-aof.
AOF | Desvantagens
- Os arquivos AOF são maiores que os arquivos RDB e são mais lentos para serem restaurados .
- Quando o conjunto de dados é grande , a eficiência de inicialização é inferior ao RDB .
10.Como escolher entre RDB e AOF?
- De modo geral, se você deseja obter segurança de dados comparável à de um banco de dados , deve usar as duas funções de persistência ao mesmo tempo . Neste caso, quando o Redis for reiniciado, o arquivo AOF será carregado primeiro para restaurar os dados originais, pois em circunstâncias normais, o conjunto de dados salvo pelo arquivo AOF é mais completo do que o conjunto de dados salvo pelo arquivo RDB.
- Se a perda de dados em poucos minutos for aceitável , você só poderá usar a persistência RDB .
- Muitos usuários usam apenas a persistência AOF, mas esse método não é recomendado porque a geração regular de instantâneos RDB é muito conveniente para backup de dados, e o RDB restaura conjuntos de dados mais rápido que o AOF, exceto. Além disso, o uso do RDB também pode evitar bugs nos programas AOF.
- Se você só precisa que os dados existam quando o servidor estiver em execução, não será necessário usar nenhum método de persistência.
11. Recuperação de dados Redis?
Quando o Redis falha, os dados podem ser recuperados do RDB ou AOF.
O processo de recuperação também é muito simples: copie o arquivo RDB ou AOF para o diretório de dados do Redis. Se você usar a recuperação AOF, habilite AOF no arquivo de configuração e inicie o servidor redis.
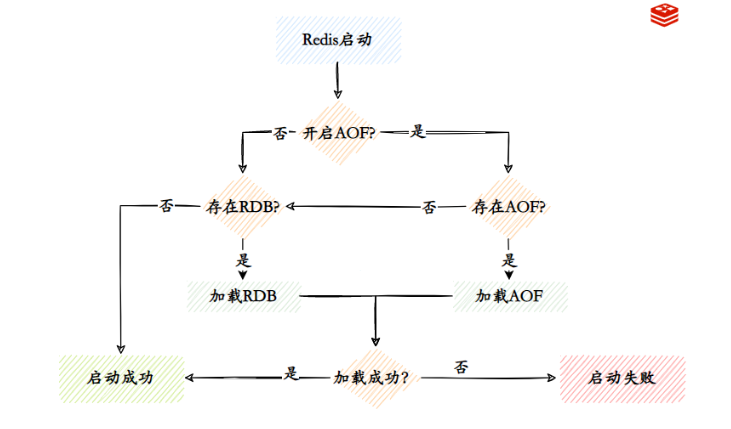
O processo de carregamento de dados quando o Redis é iniciado:
- Quando a persistência AOF está habilitada e existem arquivos AOF, os arquivos AOF são carregados primeiro.
- Quando o AOF é fechado ou o arquivo AOF não existe, o arquivo RDB é carregado.
- Depois que o arquivo AOF/RDB for carregado com sucesso, o Redis será iniciado com sucesso.
- Quando há um erro no arquivo AOF/RDB, o Redis falha ao iniciar e imprime uma mensagem de erro.
12. Você entende a persistência híbrida do Redis 4.0?
Ao reiniciar o Redis, raramente usamos RDBpara restaurar o estado da memória porque uma grande quantidade de dados será perdida. Geralmente usamos a reprodução do log AOF, mas o desempenho da reprodução do log AOF RDBé relativamente lento, portanto, quando a instância do Redis é grande, leva muito tempo para iniciar.
Para resolver este problema, o Redis 4.0 traz uma nova opção de persistência - persistência híbrida . Armazene rdbo conteúdo do arquivo junto com o arquivo de log AOF incremental. O log AOF aqui não é mais o log completo, mas o log AOF incremental que ocorreu durante o período desde o início da persistência até o final da persistência.Geralmente esta parte do log AOF é muito pequena:
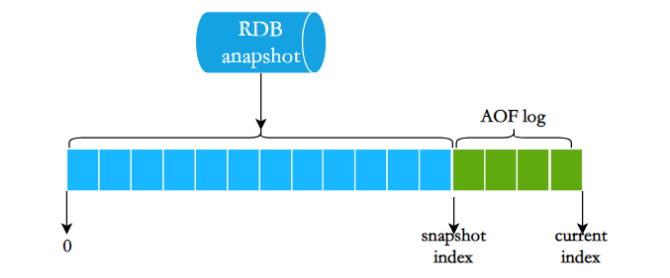
Portanto, quando o Redis é reiniciado, ele pode carregar rdbo conteúdo primeiro e, em seguida, reproduzir o log AOF incremental, que pode substituir completamente a reprodução completa do arquivo AOF anterior, e a eficiência de reinicialização é bastante melhorada.
Alta disponibilidade (entenda)
13. Você entende a replicação mestre-escravo?
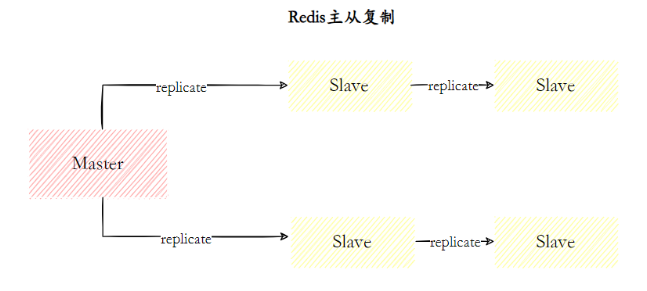
A replicação mestre-escravo refere-se à cópia de dados de um servidor Redis para outros servidores Redis. O primeiro é chamado de nó mestre (mestre) e o último é chamado de nó escravo (escravo) . E a replicação de dados é unilateral , apenas do nó mestre para o nó escravo. A replicação mestre-escravo do Redis suporta sincronização mestre-escravo e sincronização escravo-escravo.Este último é um novo recurso adicionado nas versões subsequentes do Redis para reduzir a carga de sincronização no nó mestre.
Qual é a principal função da replicação mestre-escravo?
- Redundância de dados: a replicação mestre-escravo implementa backup dinâmico de dados, que é um método de redundância de dados além da persistência.
- Recuperação de falhas: Quando ocorre um problema no nó mestre, o nó escravo pode fornecer serviços para obter recuperação rápida de falhas (na verdade, uma espécie de redundância de serviço) .
- Balanceamento de carga: com base na replicação mestre-escravo, combinada com a separação leitura-gravação, o nó mestre pode fornecer serviços de gravação e os nós escravos podem fornecer serviços de leitura (ou seja, ao gravar dados Redis, o aplicativo se conecta ao nó mestre e ao ler os dados do Redis, o aplicativo se conecta ao nó escravo) e compartilha a carga do servidor. Especialmente no cenário de menos escrita e mais leitura, o compartilhamento da carga de leitura por meio de vários nós escravos pode aumentar bastante a simultaneidade do servidor Redis.
- Pedra angular da alta disponibilidade: Além das funções acima, a replicação mestre-escravo também é a base para a implementação de sentinelas e clusters , portanto, a replicação mestre-escravo é a base da alta disponibilidade do Redis.
14.Quantas topologias comuns existem para Redis mestre-escravo?
A topologia de replicação do Redis pode suportar relacionamentos de replicação de camada única ou multicamadas e pode ser dividida nos três tipos a seguir de acordo com a complexidade da topologia: um mestre e um escravo, um mestre e vários escravos e um mestre em forma de árvore. estrutura escravista.
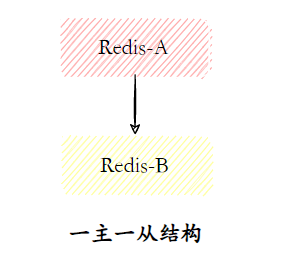
- Uma estrutura mestre e uma estrutura escrava
A estrutura um mestre-escravo é a topologia de replicação mais simples e é usada para fornecer suporte de failover do nó escravo quando o nó mestre fica inativo.
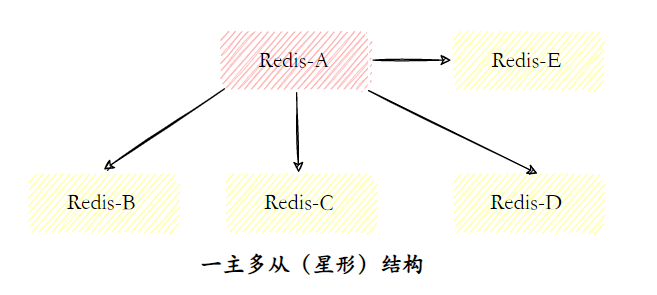
- Estrutura de um mestre e muitos escravos
A estrutura de um mestre-múltiplos-escravos (também conhecida como topologia em estrela) permite que o lado da aplicação use vários nós escravos para obter a separação de leitura e gravação. Para cenários com grande proporção de leituras, comandos de leitura podem ser enviados aos nós escravos para compartilhar a pressão no nó mestre.
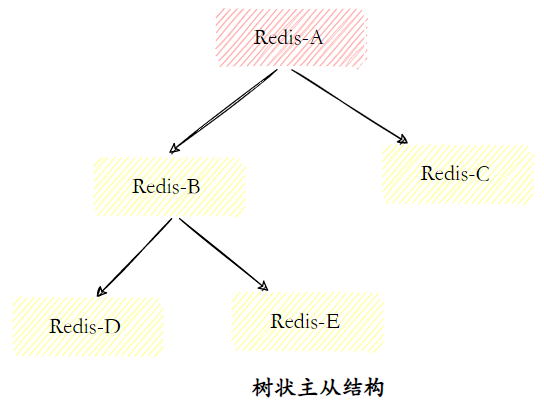
- Estrutura mestre-escravo em árvore
A estrutura mestre-escravo em forma de árvore (também conhecida como topologia em árvore) permite que o nó escravo não apenas copie os dados do nó mestre, mas também sirva como nó mestre de outros nós escravos para continuar a copiar para a camada inferior . Ao introduzir uma camada intermediária de replicação, a carga no nó mestre e a quantidade de dados que precisam ser transferidos para os nós escravos podem ser efetivamente reduzidas.
15.Você entende o princípio de replicação mestre-escravo do Redis?
O fluxo de trabalho da replicação mestre-escravo do Redis pode ser dividido aproximadamente nas seguintes etapas:
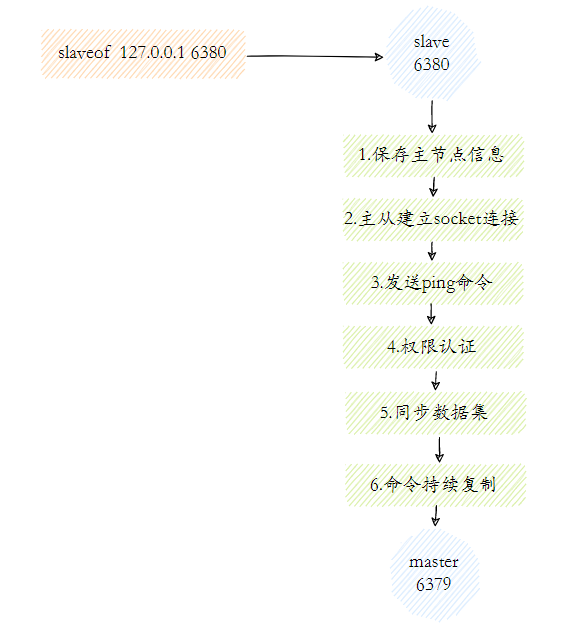
- A etapa de salvar as informações do nó mestre é apenas salvar as informações do nó mestre e salvar o IP e a porta do nó mestre.
- Estabelecimento de conexão mestre-escravo Após o nó escravo (escravo) descobrir o novo nó mestre, ele tentará estabelecer uma conexão de rede com o nó mestre.
- Envie o comando ping. Depois que a conexão for estabelecida com sucesso, o nó escravo envia uma solicitação de ping para a primeira comunicação. É principalmente para detectar se o soquete de rede entre o mestre e o escravo está disponível e se o nó mestre pode atualmente aceitar o processamento comando.
- Verificação de permissão Se o nó mestre exigir verificação de senha, o nó escravo deverá ter a senha correta para passar na verificação.
- Depois que a conexão de replicação mestre-escravo do conjunto de dados sincronizados se comunicar normalmente, o nó mestre enviará todos os dados que contém para o nó escravo.
- Replicação contínua de comandos Em seguida, o nó mestre continuará a enviar comandos de gravação aos nós escravos para garantir a consistência dos dados mestre-escravo.
16. Fale sobre o método de sincronização de dados mestre-escravo?
Redis usa o comando psync nas versões 2.8 e superiores para completar a sincronização de dados mestre-escravo. O processo de sincronização é dividido em: cópia completa e cópia parcial.

A replicação completa é geralmente usada em cenários de replicação inicial. A única função de replicação suportada pelo Redis nos primeiros dias era a replicação completa. Ela enviará todos os dados do nó mestre para o nó escravo de uma vez. Quando a quantidade de dados for grande , causará grandes danos aos nós mestre e escravo e às despesas da rede.
O processo completo de operação da cópia completa é o seguinte:
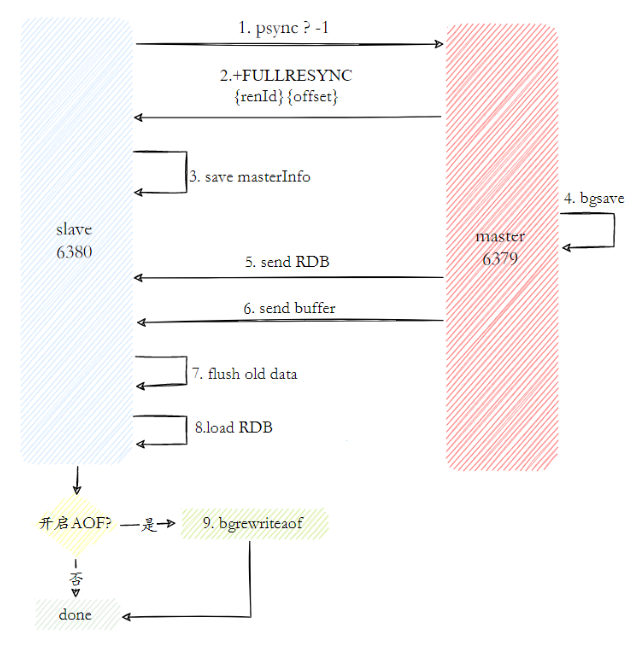
- Envie o comando psync para sincronização de dados. Como esta é a primeira vez para replicar, o nó escravo não possui o deslocamento de replicação e o ID de execução do nó mestre, então o psync-1 é enviado.
- O nó mestre analisa a replicação completa atual com base em psync-1 e responde com uma resposta +FULLRESYNC.
- O nó escravo recebe os dados de resposta do nó mestre e salva o ID de execução e o deslocamento.
- O nó mestre executa bgsave para salvar o arquivo RDB no local
- O nó mestre envia o arquivo RDB para o nó escravo, e o nó escravo salva o arquivo RDB recebido localmente e o utiliza diretamente como o arquivo de dados do nó escravo.
- Durante o período desde o início do recebimento do instantâneo RDB pelo nó escravo até a conclusão da recepção, o nó mestre ainda responde aos comandos de leitura e gravação, portanto, o nó mestre salvará os dados do comando de gravação durante esse período no buffer do cliente de replicação Quando o nó escravo carrega o arquivo RDB, o nó mestre envia os dados do buffer para o nó escravo para garantir a consistência dos dados entre o mestre e o escravo.
- Depois que o nó escravo receber todos os dados enviados do nó mestre, ele limpará seus próprios dados antigos.
- Comece a carregar o arquivo RDB após limpar os dados do nó
- Depois que o RDB for carregado com sucesso do nó, se a função de persistência AOF estiver habilitada no nó atual, ele executará imediatamente a operação bgrewriteaof para garantir que o arquivo de persistência AOF esteja imediatamente disponível após a replicação completa.
Cópia parcial A cópia parcial é principalmente uma medida de otimização feita pelo Redis para lidar com a sobrecarga excessiva da cópia completa. É implementada usando o comando pync{runId}{offset}. Quando o nó escravo (escravo) está replicando o nó mestre (mestre), se houver uma situação anormal, como interrupção da rede ou perda de comando, o nó escravo solicitará ao nó mestre para reemitir os dados de comando perdidos. Se a replicação do nó mestre buffer de backlog Esta parte dos dados na memória é enviada diretamente para o nó escravo, para que a consistência da replicação entre os nós mestre e escravo possa ser mantida.
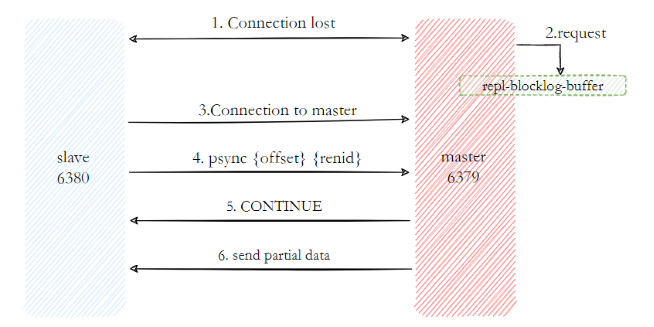
- Quando a rede entre os nós mestre e escravo é interrompida, se o tempo limite de replicação for excedido, o nó mestre considerará o nó escravo com defeito e interromperá a conexão de replicação.
- Durante a interrupção da conexão mestre-escravo, o nó mestre ainda responde aos comandos, mas o comando não pode ser enviado ao nó escravo devido à interrupção da conexão de replicação. No entanto, o buffer de backlog de replicação existente dentro do nó mestre ainda pode salve os dados do comando de gravação do período recente e o cache máximo padrão é 1 MB.
- Quando a rede do nó mestre-escravo for restaurada, o nó escravo se conectará novamente ao nó mestre.
- Quando a conexão mestre-escravo é restaurada, o nó escravo salvou anteriormente seu próprio deslocamento copiado e o ID de execução do nó mestre. Portanto, eles são enviados ao nó mestre como parâmetros psync, exigindo operações de replicação parcial.
- Depois de receber o comando psync, o nó mestre primeiro verifica se o parâmetro runId é consistente consigo mesmo. Se for consistente, significa que o nó mestre atual foi copiado antes; então ele pesquisa em seu próprio buffer de backlog de replicação de acordo com o deslocamento do parâmetro Se os dados após o deslocamento existirem no buffer, então uma resposta +CONTINUE será enviada ao nó escravo, indicando que a replicação parcial pode ser executada.
- O nó mestre envia os dados no buffer da lista de pendências de replicação para o nó escravo com base no deslocamento para garantir que a replicação mestre-escravo entre em um estado normal.
17. Quais são os problemas da replicação mestre-escravo?
Embora a replicação mestre-escravo seja boa, ela também apresenta alguns problemas:
- Uma vez que o nó mestre falha, um nó escravo precisa ser promovido manualmente para o nó mestre. Ao mesmo tempo, o endereço do nó mestre do aplicativo precisa ser modificado e outros nós escravos precisam ser ordenados para copiar o novo nó mestre. todo o processo requer intervenção manual.
- A capacidade de gravação do nó mestre é limitada por uma única máquina.
- A capacidade de armazenamento do nó mestre é limitada por uma única máquina.
O primeiro problema é a alta disponibilidade do Redis, e o segundo e terceiro problemas são problemas distribuídos do Redis.
18. Você entende o Redis Sentinel?
Há um problema com a replicação mestre-escravo e o failover automático não pode ser concluído. Portanto, precisamos de uma solução para completar o failover automático, que é o Redis Sentinel.
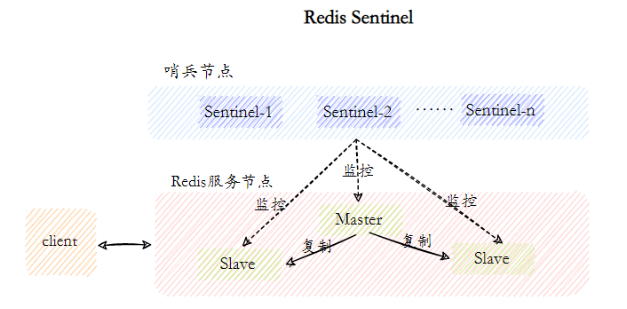
Redis Sentinel, que consiste em duas partes, nós sentinela e nós de dados:
- Nó sentinela: O sistema sentinela consiste em um ou mais nós sentinela. Os nós sentinela são nós Redis especiais que não armazenam dados e monitoram nós de dados.
- Nó de dados: Tanto o nó mestre quanto o nó escravo são nós de dados;
Com base na replicação, o Sentinel implementa a função automatizada de recuperação de falhas . A seguir está a descrição oficial da função do Sentinel:
- Monitoramento: O Sentinel verificará constantemente se o nó mestre e os nós escravos estão operando normalmente.
- Failover automático: quando o nó mestre não funcionar corretamente, o Sentinel iniciará uma operação de failover automático . Ele atualizará um dos nós escravos do nó mestre com falha para o novo nó mestre e permitirá que os outros nós escravos mudem para replicação. Novo nó mestre.
- Provedor de configuração: durante a inicialização, o cliente obtém o endereço do nó mestre do serviço Redis atual conectando-se ao sentinela.
- Notificação: o Sentinel pode enviar resultados de failover ao cliente.
Entre elas, as funções de monitoramento e failover automático permitem que o Sentinel detecte falhas no nó mestre a tempo e conclua a transferência. O provedor de configuração e as funções de notificação precisam ser refletidos na interação com o cliente.
19.Você conhece o princípio de implementação do Redis Sentinel?
O modo Sentinel usa nós sentinela para concluir o monitoramento, off-line e failover de nós de dados.

- Monitoramento regular

O Redis Sentinel conclui a descoberta e o monitoramento de cada nó por meio de três tarefas de monitoramento agendadas:
-
- A cada 10 segundos, cada nó Sentinel enviará o comando info ao nó mestre e ao nó escravo para obter a estrutura de topologia mais recente
- A cada 2 segundos, cada nó Sentinel enviará o julgamento do nó Sentinel sobre o nó mestre e as informações do nó Sentinel atual para o canal __sentinel__:hello do nó de dados Redis.
- A cada 1 segundo, cada nó Sentinel enviará um comando ping ao nó mestre, nó escravo e outros nós Sentinel para uma verificação de pulsação para confirmar se esses nós estão atualmente acessíveis.
-
Offline subjetivo e offline objetivo. Offline subjetivo significa que o nó sentinela pensa que há um problema com um determinado nó. Offline objetivo significa que mais de um certo número de nós sentinela pensam que há um problema com o nó mestre.
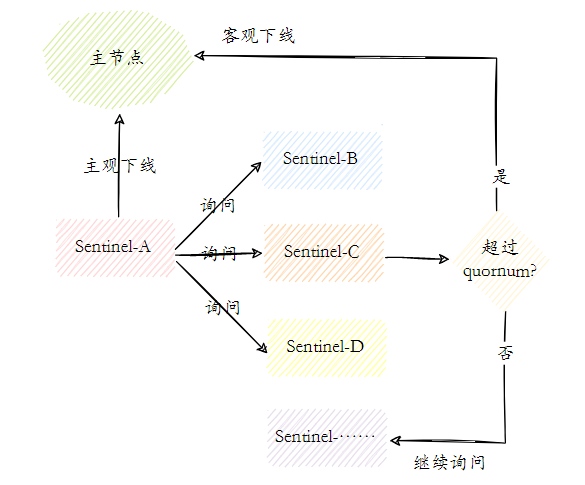
- Cada nó Sentinel que está subjetivamente off-line enviará um comando ping para o nó mestre, nó escravo e outros nós Sentinel a cada 1 segundo para detecção de pulsação. Quando esses nós excederem o tempo de inatividade após milissegundos sem resposta efetiva, o nó Sentinel enviará um ping para o nó mestre, nó escravo e outros nós Sentinel para detecção de pulsação. Fazer uma determinação de falha é chamado de off-line subjetivo.
- Objetivo offline Quando o nó Sentinel subjetivamente offline é o nó mestre, o nó Sentinel usará o comando sentinel is-master-down-by-addr para solicitar a outros nós Sentinel o julgamento do nó mestre. for excedido, o nó Sentinel acredita que realmente há um problema com o nó mestre. Neste momento, o nó Sentinel tomará uma decisão objetiva de ficar offline.
-
Eleição do nó sentinela líder Os nós sentinela executarão um processo de eleição de líder para selecionar um nó sentinela como líder para failover. Redis usa o algoritmo Raft para implementar a eleição de líder.
-
failover
O nó Sentinel eleito pelo líder é responsável pelo failover. O processo é o seguinte:

- Selecionar um nó da lista de nós escravos como o novo nó mestre é uma etapa relativamente complicada.
- O nó líder do Sentinel executará o comando slaveof no one no nó escravo selecionado na primeira etapa para torná-lo o nó mestre.
- O nó líder Sentinel enviará comandos aos nós escravos restantes para torná-los nós escravos do novo nó mestre.
- O conjunto de nós Sentinel atualizará o nó mestre original para um nó escravo, ficará de olho nele e, quando ele se recuperar, ordenará que ele replique o novo nó mestre.
20. Você entende a eleição do Nó Sentinela líder?
Redis usa o algoritmo Raft para implementar a eleição do líder. O processo geral é o seguinte:
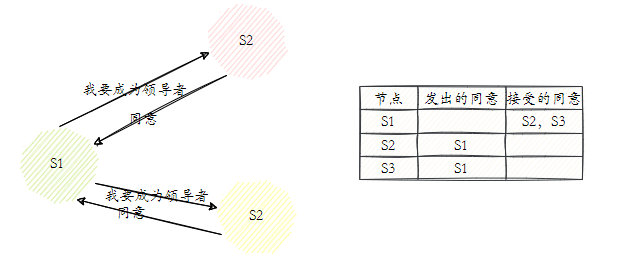
- Cada nó Sentinel online é qualificado para se tornar o líder. Quando confirmar que o nó mestre está subjetivamente offline, ele enviará o comando sentinela is-master-down-by-addr para outros nós Sentinel, exigindo que ele seja definido como líder .
- Se o nó Sentinel que recebe o comando não tiver concordado com o comando sentinela is-master-down-by-addr de outros nós Sentinel, ele concordará com a solicitação, caso contrário, a rejeitará.
- Se o nó Sentinela descobrir que sua contagem de votos é maior ou igual a max(quorum, num(sentinels)/2+1), então ele se tornará o líder.
- Se este processo não eleger um líder, a próxima eleição prosseguirá.
21. Como são selecionados os novos nós mestres?
A seleção de um novo nó mestre é dividida basicamente nas seguintes etapas:
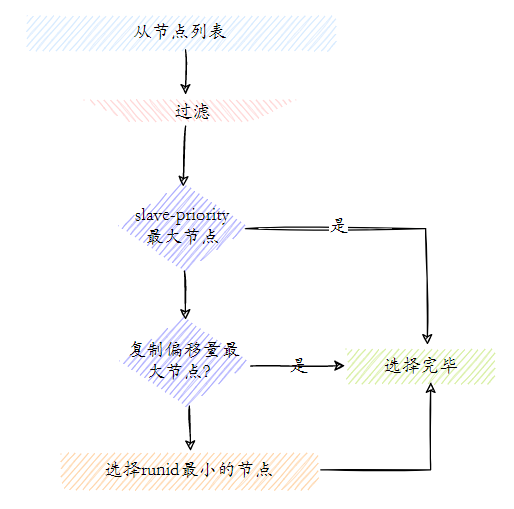
- Filtragem: "não íntegro" (subjetivo off-line, desconectado), nenhuma resposta de ping do nó Sentinel em 5 segundos e perda de contato com o nó mestre por mais de 10 segundos após inatividade.
- Selecione a lista de nós escravos com a maior prioridade de escravos (prioridade do nó escravo). Se existir, retorne-a. Se não existir, continue.
- Selecione o nó escravo com o maior deslocamento de cópia (a cópia mais completa), retorne se existir e continue se não existir.
- Selecione o nó escravo com o menor runid.
22.Você entende o cluster Redis?
Como mencionado anteriormente, existem problemas de alta disponibilidade e distribuição entre mestre e escravo, o Sentinel resolve o problema de alta disponibilidade e o cluster é a solução definitiva, resolvendo os problemas de alta disponibilidade e distribuição de uma só vez.
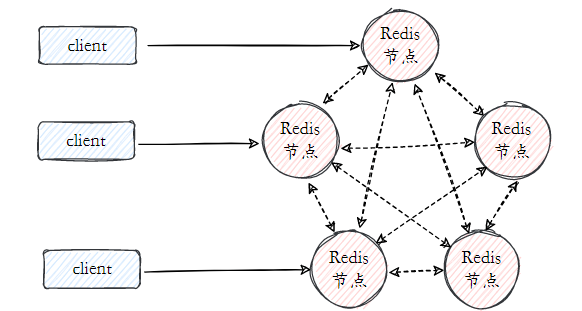
- Particionamento de dados: o particionamento de dados (ou fragmentação de dados) é a função principal do cluster. O cluster dispersa dados em vários nós. Por um lado, ele ultrapassa o limite de tamanho de memória da única máquina Redis e aumenta muito a capacidade de armazenamento . Por outro lado, cada nó mestre pode fornecer serviços externos de leitura e gravação, o que melhora muito . a capacidade de resposta do cluster .
- Alta disponibilidade: O cluster suporta replicação mestre-escravo e failover automático do nó mestre (semelhante ao Sentinel) .Quando qualquer nó falha, o cluster ainda pode fornecer serviços externos.
23. Como os dados do cluster são particionados?
No armazenamento distribuído, os conjuntos de dados devem ser mapeados para vários nós de acordo com as regras de particionamento.Existem três regras comuns de particionamento de dados:
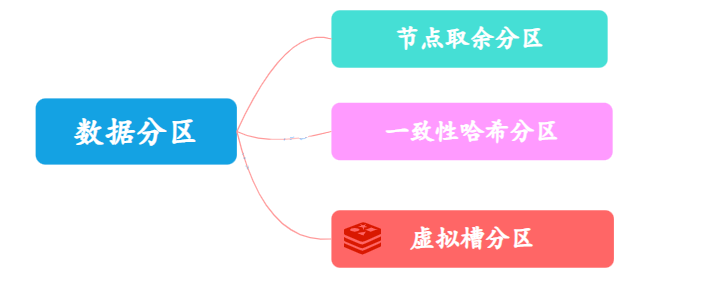
Opção 1: o nó usa partição residual
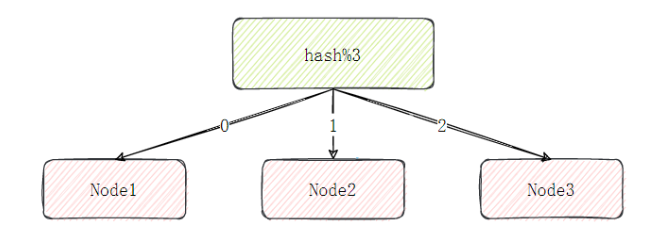
O particionamento restante do nó é muito fácil de entender. Ele usa dados específicos, como chaves Redis ou IDs de usuário, e usa o restante do valor do hash de resposta: hash (chave) %N para determinar para qual nó os dados são mapeados.
No entanto, o maior problema com esta solução é que quando o número de nós muda, como expandir ou diminuir nós, o relacionamento de mapeamento do nó de dados precisa ser recalculado, o que levará à remigração dos dados.
Opção 2: particionamento de hash consistente
Todo o espaço de valor Hash é organizado em um anel virtual e, em seguida, o endereço IP ou nome do host do nó de cache é criptografado e colocado no anel. Quando precisamos determinar qual nó uma determinada chave precisa ser acessada, primeiro fazemos o mesmo valor de hash para a chave, determinamos sua posição no anel e então "caminhamos" no anel no sentido horário. o primeiro nó de cache é o nó a ser acessado.
Por exemplo, na imagem abaixo, a Chave 1 e a Chave 2 cairão no Nó 1, a Chave 3 e a Chave 4 cairão no Nó 2, a Chave 5 cairá no Nó 3 e a Chave 6 cairá no Nó 4. meio.
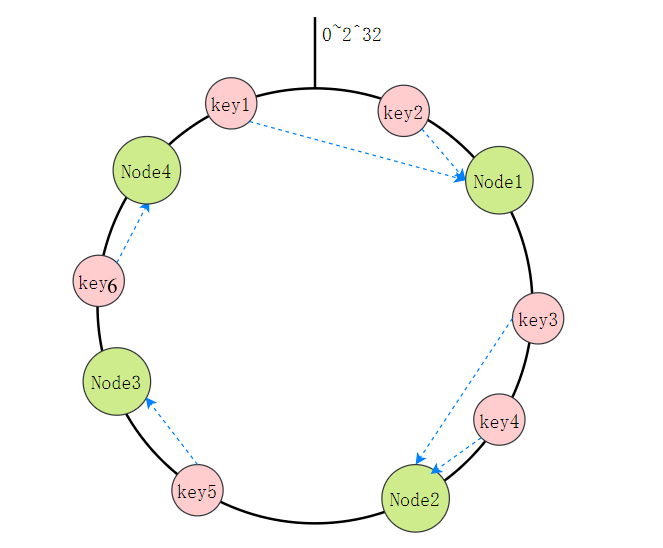
A maior vantagem deste método em comparação com o restante do nó é que a adição e exclusão de nós afeta apenas os nós adjacentes no anel hash e não tem impacto em outros nós.
Mas ainda tem problemas:
- Os nós de cache estão distribuídos de forma desigual no anel, o que causará maior pressão em alguns nós de cache.
- Quando um nó falha, todos os acessos que este nó deve suportar serão movidos para outro nó, o que causará estresse no nó subsequente.
Opção 3: Partição de Slot Virtual
Com base no particionamento hash consistente desta solução, é introduzido o conceito de nós virtuais . O cluster Redis usa esta solução e os nós virtuais nele são chamados de slots . Slots são um conceito virtual entre dados e nós reais. Cada nó real contém um certo número de slots e cada slot contém dados com um valor de hash dentro de um determinado intervalo.
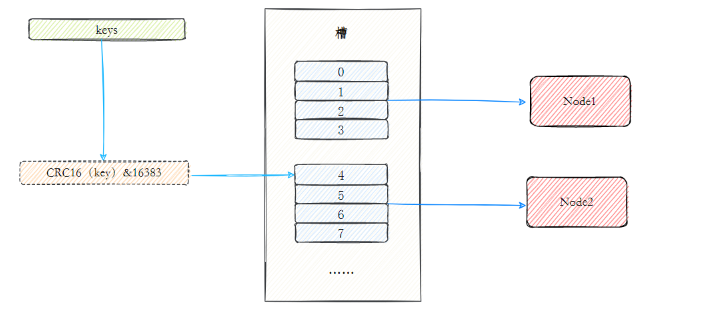
No particionamento de hash consistente usando slots, os slots são a unidade básica de gerenciamento e migração de dados. Os slots separam o relacionamento entre os dados e os nós reais, e adicionar ou remover nós tem pouco impacto no sistema. 4Ainda tomando a figura acima como exemplo, existem nós reais no sistema , assumindo que 16slots (0-15) sejam alocados para eles;
- Os slots 0-3 estão localizados no nó1; 4-7 estão localizados no nó2; e assim por diante...
Se excluído neste momento node2, você só precisa realocar os slots 4 a 7. Por exemplo, o slot 4 a 5 é alocado para node1, o slot 6 é alocado para node3, o slot 7 é alocado para node4e a distribuição de dados em outros nós ainda é relativamente equilibrado.
24. Você pode falar sobre o princípio do cluster Redis?
O cluster Redis realiza armazenamento distribuído de dados por meio de particionamento de dados e atinge alta disponibilidade por meio de failover automático.
Criação de cluster
O particionamento de dados é feito quando o cluster é criado.
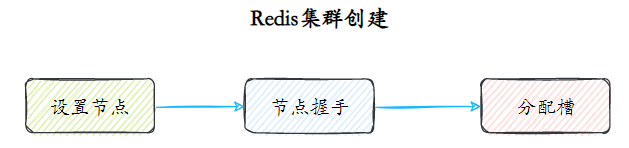
Configurando nós Clusters Redis geralmente consistem em vários nós. O número de nós deve ser pelo menos 6 para garantir um cluster completo e altamente disponível. Cada nó precisa habilitar e configurar sim habilitado para cluster para permitir que o Redis seja executado no modo cluster.
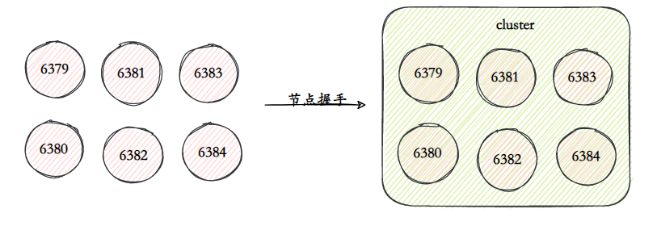
Handshake de nó O handshake de nó refere-se ao processo no qual um grupo de nós em execução no modo cluster se comunica entre si por meio do protocolo Gossip para se perceberem. O handshake do nó é a primeira etapa para os clusters se comunicarem entre si. O cliente inicia o comando: cluster meet{ip}{port}. Depois de concluir o handshake do nó, cada nó Redis forma um cluster de vários nós.
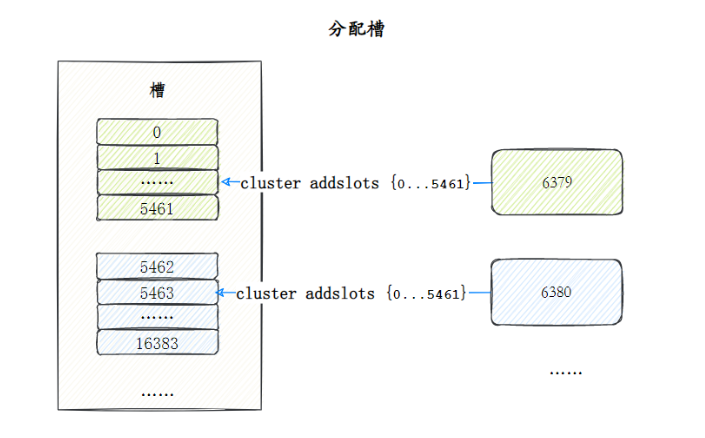
**Slot de alocação (slot)** O cluster Redis mapeia todos os dados para 16.384 slots. Cada nó corresponde a vários slots e somente quando um slot é atribuído ao nó ele pode responder aos comandos de teclas associados a esses slots. Aloque slots para nós por meio do comando cluster addlots.
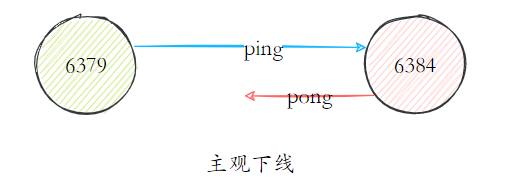
failover
O failover do cluster Redis é semelhante ao failover do Sentinel, mas todos os nós do cluster Redis são responsáveis pelas tarefas de manutenção de estado.
A falha foi descoberta: os nós no cluster Redis implementavam a comunicação dos nós por meio de mensagens ping/pong. Cada nó no cluster enviava regularmente mensagens ping para outros nós, e os nós receptores respondiam com mensagens pong em resposta. Se a comunicação continuar a falhar dentro do tempo limite do nó do cluster, o nó remetente considerará o nó receptor como defeituoso e marcará o nó receptor como offline subjetivo (pfail).
Quando um nó determina que outro nó está subjetivamente offline, o status do nó correspondente seguirá a mensagem e se espalhará dentro do cluster. Através da disseminação de mensagens de fofoca, os nós do cluster coletam continuamente relatórios off-line de nós defeituosos. Quando mais da metade dos nós mestres que possuem slots marcam um nó como subjetivamente offline. Acione o processo off-line objetivo.
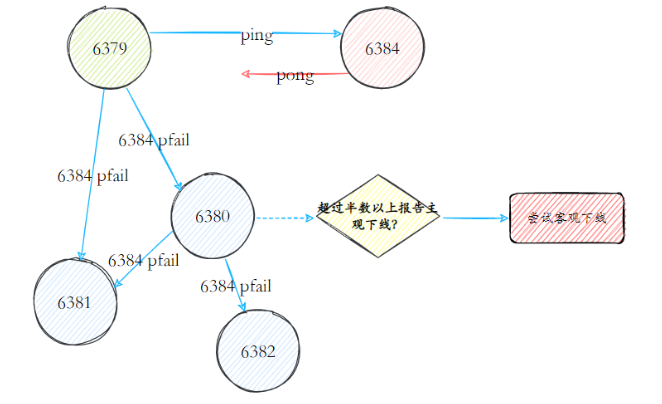
Recuperação
Depois que o nó defeituoso fica objetivamente offline, se o nó offline for o nó mestre que contém o slot, um de seus nós escravos precisa ser selecionado para substituí-lo e garantir a alta disponibilidade do cluster.
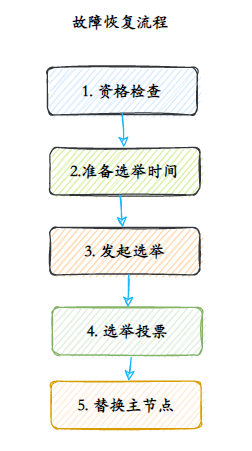
- Verificação de elegibilidade Cada nó escravo deve verificar a última vez que foi desconectado do nó mestre para determinar se está qualificado para substituir o nó mestre com falha.
- Preparação para tempo de eleição: Quando o nó escravo estiver elegível para failover, atualize o tempo para acionamento da eleição de falha, somente após atingir esse tempo os processos subsequentes poderão ser executados.
- Iniciando uma eleição Quando a tarefa agendada do nó escravo detecta que o tempo de eleição de falha (failover_auth_time) chegou, o processo de eleição é iniciado.
- O nó mestre que detém o voto eleitoral trata a mensagem de eleição falhada. O processo de votação é na verdade um processo de eleição de líderes. Por exemplo, se houver N nós mestres com slots no cluster, haverá N votos. Como o nó mestre que detém o slot só pode votar em um nó escravo em cada época de configuração, apenas um nó escravo pode obter N/2+1 votos, garantindo que o único nó escravo possa ser encontrado.
- Substituir o nó mestre Quando votos suficientes são coletados dos nós escravos, a operação de substituição do nó mestre é acionada.
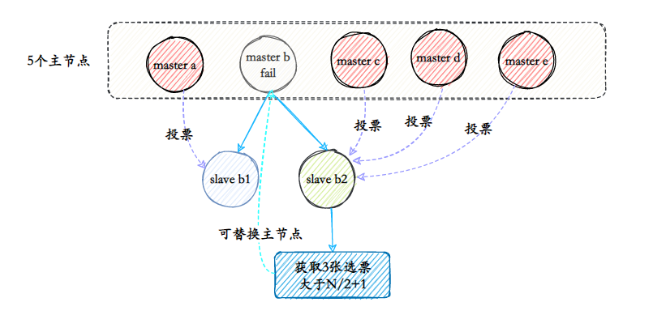
Quantos nós físicos são necessários para implantar um cluster Redis?
No processo de votação, o nó mestre com defeito também é contado no número de votos. Suponha que o número de nós no cluster seja 3 mestres e 3 escravos, e 2 nós mestres sejam implantados em uma máquina. Quando esta máquina fica inoperante, devido ao escravo A falha do nó em coletar 3/2+1 votos do nó mestre causará falha no failover. Este problema também se aplica à descoberta de falhas. Portanto, ao implantar um cluster, todos os nós principais precisam ser implantados em pelo menos três máquinas físicas para evitar problemas pontuais.
25. Fale sobre escalonamento de cluster?
O cluster Redis fornece soluções flexíveis de expansão e contração de nós. Os nós podem ser adicionados ao cluster para expansão ou alguns nós podem ser colocados offline para redução, sem afetar os serviços externos do cluster.
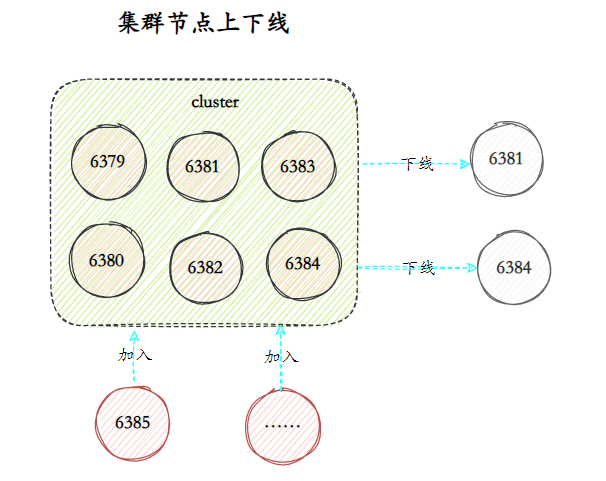
Na verdade, o ponto-chave da expansão e redução do cluster está na relação correspondente entre slots e nós. A expansão e a redução consistem em migrar parte da soma 槽para 数据novos nós.
Por exemplo, no cluster a seguir, cada nó corresponde a vários slots, e cada slot corresponde a uma certa quantidade de dados. Se quiser adicionar um nó para expandir o cluster, você precisa migrar parte dos slots e conteúdo para o novo nó por meio de comandos relevantes.
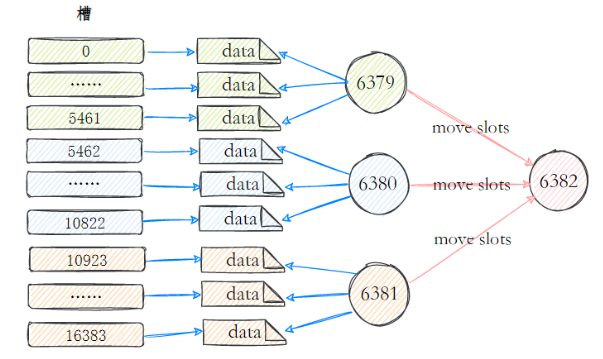
O escalonamento é semelhante: os slots e os dados são primeiro migrados para outros nós e, em seguida, os nós correspondentes são colocados offline.
projeto de cache
26.O que são quebra de cache, penetração de cache e avalanche de cache?
PS: Este é um estereótipo antigo que vem sendo usado há muitos anos, então você deve entendê-lo com clareza.
Divisão de cache
Uma chave com um número relativamente grande de acessos simultâneos expira em um determinado momento, fazendo com que todas as solicitações sejam atingidas diretamente no banco de dados.
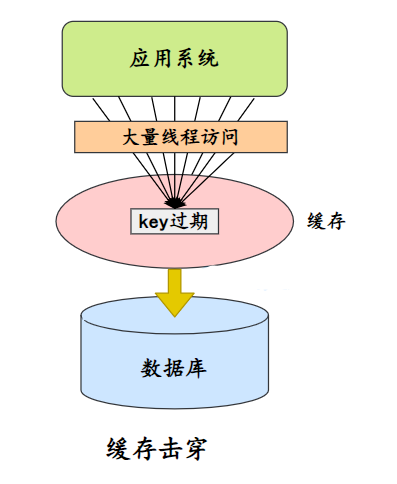
Solução:
- Bloqueio e atualização, por exemplo, se você solicitar a consulta A e descobrir que ela não está no cache, bloqueie a chave A, consulte os dados no banco de dados, grave-os no cache e devolva-os ao usuário, então que as solicitações subsequentes possam obtê-lo do cache.
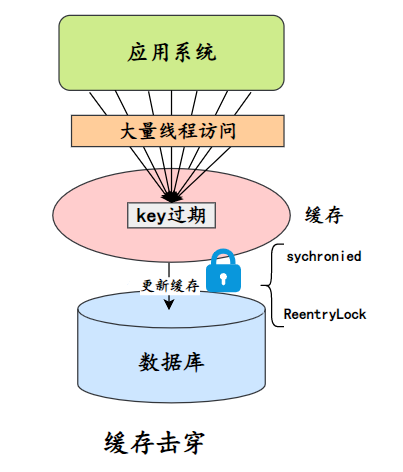
- Escreva a combinação do tempo de expiração em valor e atualize continuamente o tempo de expiração de maneira assíncrona para evitar esse tipo de fenômeno.
penetração de cache
A penetração do cache refere-se à consulta de dados que não existem no cache ou no banco de dados, de modo que cada solicitação chegue diretamente ao banco de dados, como se o cache não existisse.
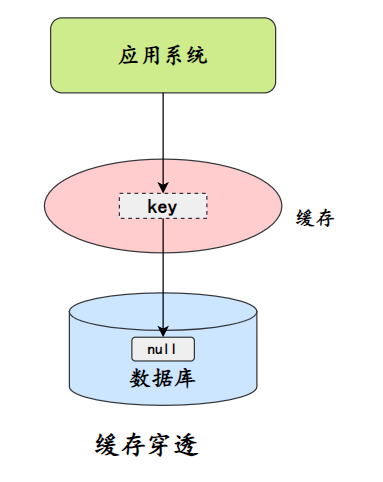
A penetração do cache fará com que dados inexistentes sejam consultados na camada de armazenamento sempre que solicitados, perdendo assim a importância da proteção do cache para armazenamento back-end.
A penetração do cache pode aumentar a carga no armazenamento de back-end. Se for encontrado um grande número de ocorrências vazias na camada de armazenamento, pode haver um problema de penetração do cache.
A penetração do cache pode ocorrer por dois motivos:
- Problemas com o código comercial próprio
- Ataque malicioso, o rastreador causa ocorrências vazias
Possui duas soluções principais:
- Cache vazio/valores padrão
Uma maneira é salvar um objeto vazio ou valor padrão no cache após uma falha no banco de dados. Se você acessar esses dados posteriormente, eles serão obtidos do cache, protegendo assim o banco de dados.
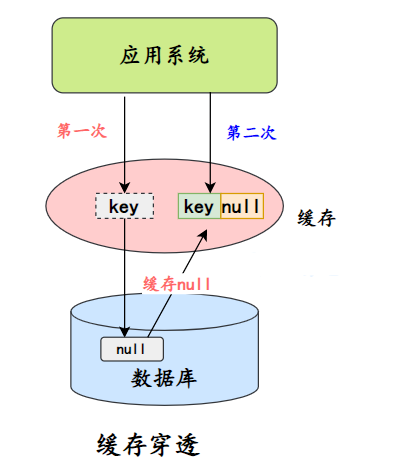
Existem dois problemas principais com o armazenamento em cache de valores nulos:
- Valores nulos são armazenados em cache, o que significa que mais chaves são armazenadas na camada de cache, o que requer mais espaço de memória (se for um ataque, o problema é mais sério).Um método mais eficaz é definir um tempo de expiração mais curto para este tipo de dados., e deixá-los ser eliminados automaticamente.
- Os dados na camada de cache e na camada de armazenamento serão inconsistentes por um período de tempo, o que pode ter um certo impacto nos negócios. Por exemplo, se o tempo de expiração for definido para 5 minutos, se a camada de armazenamento adicionar esses dados neste momento, haverá inconsistências entre a camada de cache e os dados da camada de armazenamento durante esse período. Neste momento, você pode usar a fila de mensagens ou outros métodos assíncronos para limpar objetos vazios no cache.
- Além de armazenar objetos vazios em cache, os filtros Bloom também podem adicionar um filtro Bloom para realizar uma camada de filtragem antes do armazenamento e armazenamento em cache.
O filtro Bloom salvará se os dados existirem. Se for considerado que os dados não estão mais disponíveis, o armazenamento não será acessado.
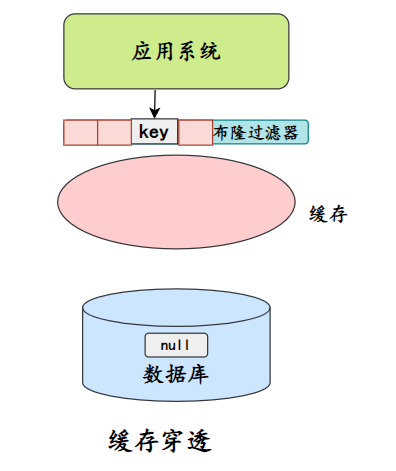
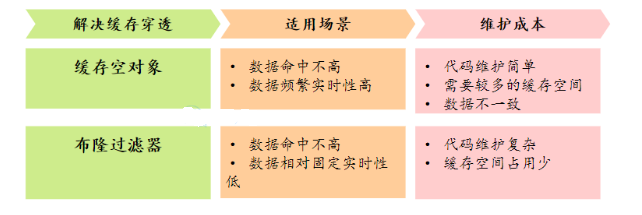
Comparação de duas soluções:
avalanche de cache
Se ocorrer uma falha de cache em grande escala em um determinado momento, como o serviço de cache ficar inativo e um grande número de chaves expirar ao mesmo tempo, a consequência é que um grande número de solicitações chegará e atingirá o banco de dados diretamente, o que pode levar ao colapso de todo o sistema, o que é chamado de avalanche.
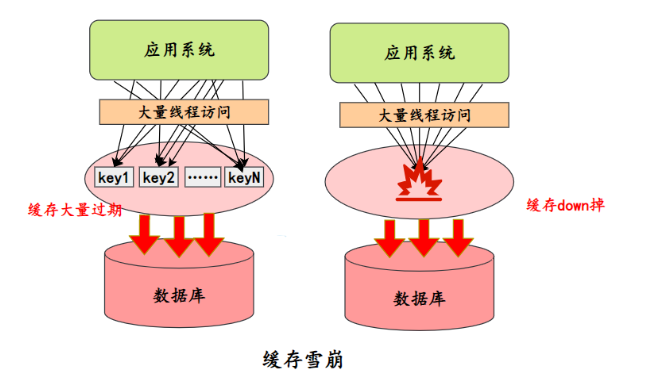
A avalanche de cache é o mais sério dos três principais problemas de cache. Vamos dar uma olhada em como prevenir e lidar com isso.
- Melhore a disponibilidade do cache
- Implantação de cluster: para melhorar a disponibilidade do cache por meio de clustering, você pode usar o Redis Cluster do próprio Redis ou soluções de cluster de terceiros, como Codis.
- Cache multinível: configure o cache multinível. Com base na expiração do cache de primeiro nível, acesse o cache de segundo nível. O tempo de expiração de cada nível de cache é diferente.
- Expiração
- Expiração uniforme: Para evitar que um grande número de caches expirem ao mesmo tempo, diferentes tempos de expiração de chave podem ser gerados aleatoriamente para evitar que o tempo de expiração seja muito concentrado.
- Os dados do hotspot nunca expiram.
- rebaixamento do disjuntor
- Disjuntor de serviço: quando o servidor de cache fica inativo ou responde com um tempo limite, para evitar uma avalanche de todo o sistema, os serviços de negócios são temporariamente impedidos de acessar o sistema de cache.
- Degradação do serviço: quando ocorre um grande número de falhas de cache e sob condições de alta simultaneidade e alta carga, as solicitações de algumas interfaces e dados não essenciais são temporariamente abandonadas no sistema de negócios, e um erro de fallback (recuo) preparado com antecedência é diretamente retornado.Processar informações.
27. Você pode falar sobre o filtro Bloom?
Filtro Bloom, é uma estrutura de dados contínua, cada bit de armazenamento é armazenado como um bit, ou seja, 0ou 1, para identificar se os dados existem.
Ao armazenar dados, use K funções hash diferentes para mapear esta variável para K pontos na lista de bits e defina-os como 1.
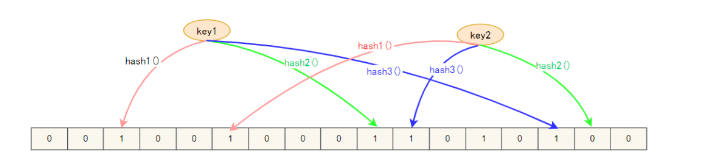
Determinamos se a chave de cache existe. Da mesma forma, K funções hash são mapeadas para K pontos na lista de bits para determinar se é 1:
- Se nem todos forem 1, então a chave não existe;
- Se todos forem 1, significa apenas que a chave pode existir.
Os filtros Bloom também têm algumas desvantagens:
- Tem uma certa probabilidade de erro ao julgar se um elemento está no conjunto, porque o algoritmo hash tem uma certa probabilidade de colisão.
- A exclusão de elementos não é suportada.
28. Como garantir a consistência dos dados do cache e do banco de dados?
De acordo com a teoria CAP, a consistência não pode ser garantida sob a premissa de garantir a disponibilidade e a tolerância a falhas da partição, portanto, a consistência absoluta do cache e do banco de dados é impossível de alcançar, e a consistência final do cache e do banco de dados só pode ser preservada tanto quanto possível.
A teoria CAP refere-se ao fato de que em um sistema distribuído, consistência, disponibilidade e tolerância de partição não podem ser estabelecidas ao mesmo tempo.
Escolha uma estratégia apropriada de atualização de cache
1. Exclua o cache em vez de atualizá-lo
Quando um thread grava em uma chave armazenada em cache, se outros threads vierem para ler o banco de dados, eles lerão dados sujos, causando inconsistência de dados.
Em comparação, excluir o cache é muito mais rápido do que atualizar o cache, leva muito menos tempo e a probabilidade de leitura de dados sujos também é muito menor.
- Atualize os dados primeiro e depois exclua o cache. Atualize o banco de dados primeiro ou exclua o cache primeiro? isto é um problema.
A atualização de dados pode demorar mais de cem vezes mais que a exclusão do cache. Quando a chave correspondente não existe no cache e o banco de dados não foi atualizado, se um thread vier para ler os dados e gravá-los no cache, depois que a atualização for bem-sucedida, a chave será dados sujos.
Não há dúvida de que se você primeiro excluir o cache e depois atualizar o banco de dados, a chave não existirá no cache por um longo período de tempo e há uma maior probabilidade de geração de dados sujos.
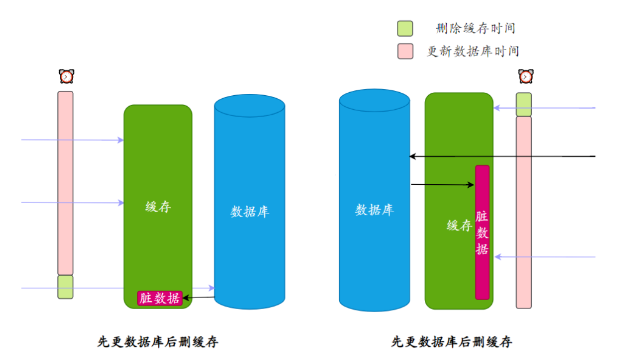
Atualmente, a estratégia de leitura e gravação de cache mais popular, cache-aside-pattern, usa o método de atualizar primeiro o banco de dados e depois excluir o cache.
Tratamento de inconsistência de cache
Se a simultaneidade não for particularmente alta e a dependência do cache for forte, inconsistências em determinados programas serão realmente aceitáveis.
Mas se os requisitos de consistência forem relativamente altos, será necessário encontrar uma maneira de garantir que o cache e os dados no banco de dados sejam consistentes.
Existem dois motivos comuns para inconsistência entre o cache e os dados do banco de dados:
- Falha na exclusão da chave de cache
- A simultaneidade faz com que dados sujos sejam gravados
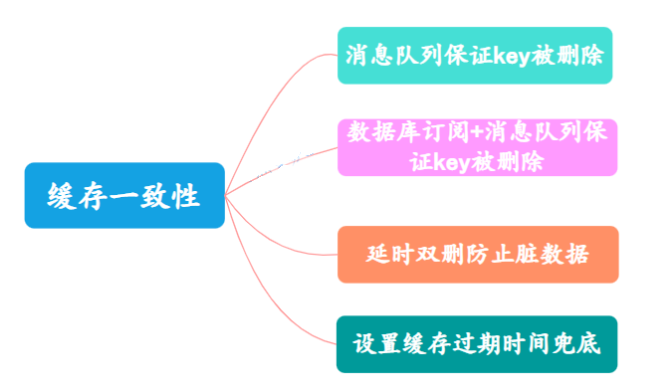
A fila de mensagens garante que a chave seja excluída. Você pode introduzir a fila de mensagens, descartar a chave a ser excluída ou a chave que não foi excluída e usar o mecanismo de nova tentativa da fila de mensagens para tentar excluir novamente a chave correspondente.
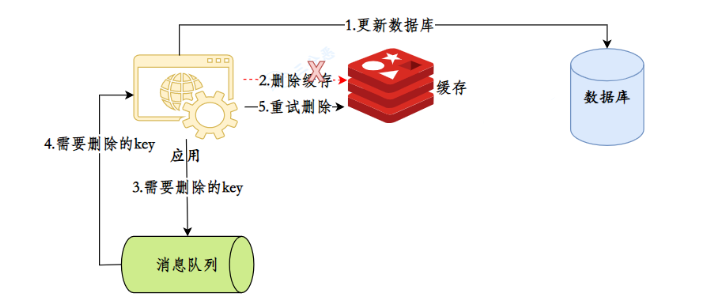
Essa solução parece boa, mas a desvantagem é que ela é intrusiva ao código comercial.
Assinatura do banco de dados + fila de mensagens garantem que, quando a chave for excluída, você possa usar um serviço (como o canal do Alibaba) para monitorar o log binário do banco de dados para obter os dados que precisam ser operados.
Em seguida, use um serviço público para obter as informações do assinante e realizar operações de exclusão de cache.
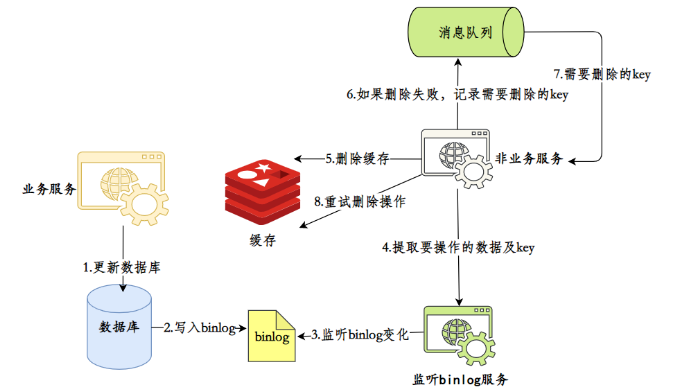
Esse método reduz a intrusão no negócio, mas na verdade a complexidade de todo o sistema aumenta, sendo adequado para grandes fábricas com infraestrutura completa.
Outra situação de exclusão dupla atrasada para evitar dados sujos é que os dados sujos são gravados quando o cache não existe. Essa situação ocorre com mais frequência na estratégia de atualização de cache de primeiro excluir o cache e depois atualizar o banco de dados. A solução é exclusão dupla atrasada .
Simplificando, depois de excluir o cache pela primeira vez, após um período de tempo, exclua o cache novamente.
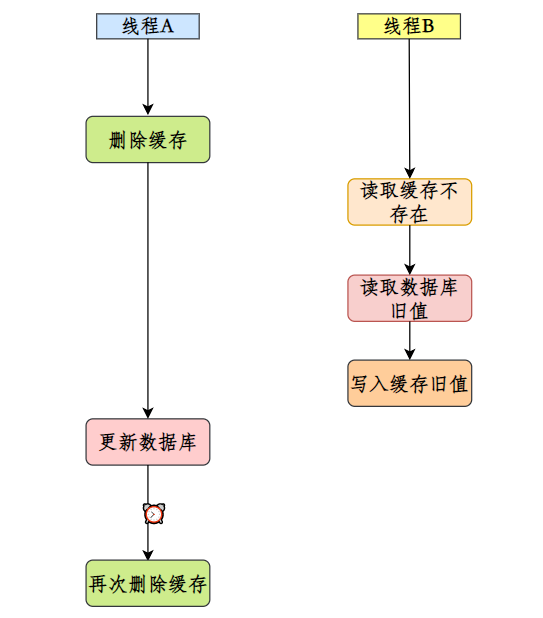
As configurações de tempo de atraso dessa maneira exigem consideração e testes cuidadosos.
Definir tempo de expiração do cache
Este é um método simples, mas útil. Defina um tempo de expiração razoável para o cache. Mesmo que os dados do cache sejam inconsistentes, eles não serão inconsistentes para sempre. Quando o cache expirar, ele naturalmente se tornará consistente novamente.
29. Como garantir a consistência entre cache local e cache distribuído?
PS: Essa pergunta raramente é feita em entrevistas, mas é muito comum no trabalho real.
No desenvolvimento diário, costumamos usar cache de dois níveis: cache local + cache distribuído.
O chamado cache local refere-se ao cache de memória correspondente ao servidor, como o Caffeine, e o cache distribuído usa basicamente Redis.
Portanto, a questão é: como o cache local e o cache distribuído mantêm os dados consistentes?
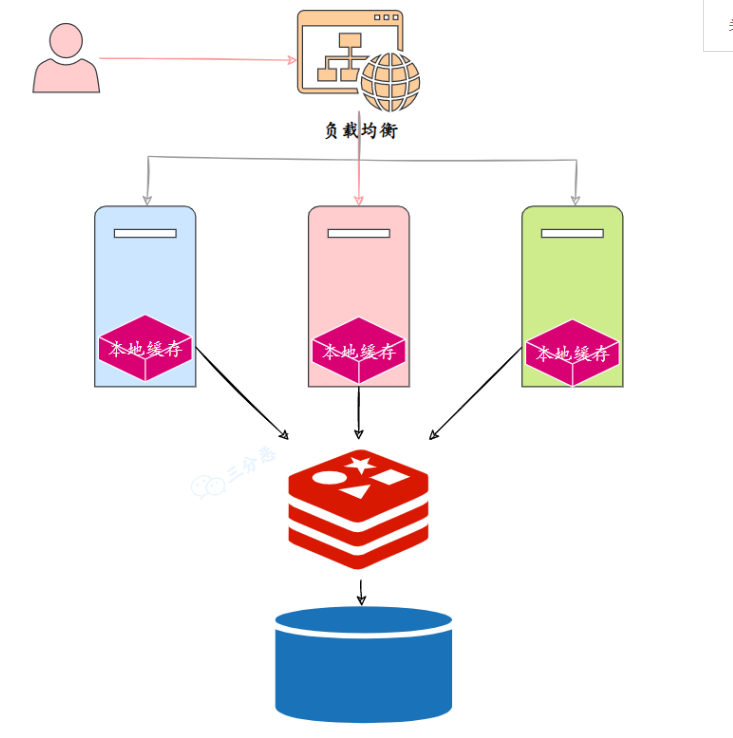
Cache Redis, quando o banco de dados for atualizado, basta excluir diretamente a chave armazenada em cache, pois para o sistema de aplicação é um cache centralizado.
No entanto, o cache local é descentralizado e espalhado em vários nós do serviço distribuído. É impossível deletar a chave do cache local através da solicitação do cliente, então você tem que encontrar uma maneira de notificar todos os nós do cluster para deletar o local correspondente chave de cache.
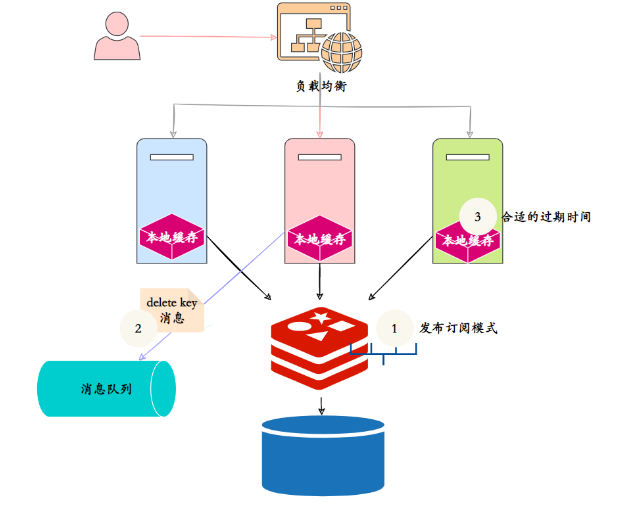
Você pode usar a fila de mensagens:
- Usando o próprio mecanismo Pub/Sub do Redis, todos os nós no cluster distribuído se inscrevem para excluir o canal de cache local, excluir o nó em cache do Redis e publicar a mensagem de exclusão de cache local. Depois que os assinantes assinam a mensagem, a chave local correspondente é excluído. No entanto, a publicação e assinatura do Redis não são confiáveis e não há garantia de que a exclusão será bem-sucedida.
- A introdução de filas de mensagens profissionais, como RocketMQ, garante a confiabilidade das mensagens, mas aumenta a complexidade do sistema.
- Defina um prazo de expiração apropriado. O cache local pode definir um prazo de expiração relativamente curto.
30. Como lidar com teclas de atalho?
**O que é uma tecla de atalho? **A chamada tecla de atalho é a chave para comparação da frequência de acesso.
Por exemplo, notícias ou produtos populares, essas chaves costumam receber grande tráfego, o que coloca muita pressão no Redis, que armazena esse tipo de informação.
Se o cluster Redis for implantado, as teclas de atalho podem causar desequilíbrio no tráfego geral e o OPS dos nós individuais pode ser muito grande. Em casos extremos, as teclas de atalho podem até exceder o OPS que o próprio Redis pode suportar.
Como lidar com teclas de atalho?
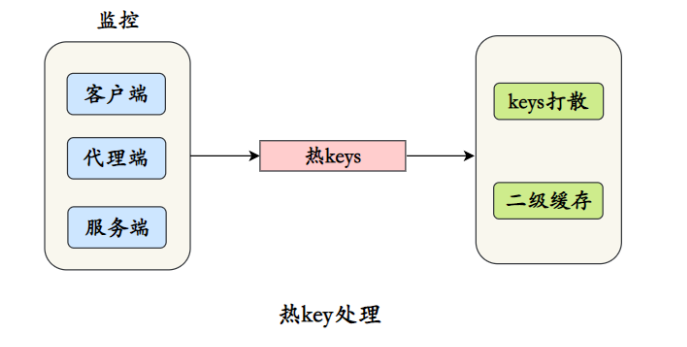
A coisa mais crítica sobre o processamento de teclas de atalho é o monitoramento das teclas de atalho. As teclas de atalho podem ser monitoradas a partir destes terminais:
- Cliente O cliente é na verdade o local "mais próximo" da chave, porque os comandos Redis são emitidos do cliente. Por exemplo, defina um dicionário global (chave e número de chamadas) no cliente e use este dicionário para registrar cada vez que um O comando Redis é chamado.
- O lado do proxy é uma arquitetura distribuída Redis baseada em proxy, como Twemproxy e Codis. Todas as solicitações do cliente são concluídas através do lado do proxy e as estatísticas podem ser coletadas no lado do proxy.
- A primeira coisa que muitos desenvolvedores e pessoal de operação e manutenção pensam é usar o comando monitor no servidor Redis para contar teclas de atalho. O comando monitor pode monitorar todos os comandos executados pelo Redis.
Desde que a tecla de atalho seja monitorada, o processamento da tecla de atalho é simples:
- Distribua teclas de atalho para servidores diferentes para reduzir a pressão
- Adicione cache de nível 2 e carregue os dados das teclas de atalho na memória com antecedência. Se o redis estiver inativo, consulte na memória.
31. Como fazer o pré-aquecimento do cache?
O chamado pré-aquecimento do cache consiste em liberar os dados do banco de dados para o cache com antecedência. Geralmente existem estes métodos:
1. Escreva diretamente uma página ou interface de atualização de cache e faça-o manualmente quando estiver online.
2. A quantidade de dados não é grande e pode ser carregada automaticamente quando o projeto é iniciado.
3. As tarefas agendadas atualizam o cache.
32. Reconstrução da chave do hotspot? pergunta? resolver?
Durante o desenvolvimento, geralmente é usada a estratégia "caching + tempo de expiração", que pode não apenas acelerar a leitura e gravação de dados, mas também garantir atualizações regulares de dados. Este modelo pode basicamente atender à maioria das necessidades.
No entanto, se dois problemas ocorrerem ao mesmo tempo, poderá surgir um problema relativamente grande:
- A chave atual é uma tecla de atalho (como uma notícia de entretenimento popular) e a quantidade de simultaneidade é muito grande.
- A reconstrução do cache não pode ser concluída em pouco tempo e pode ser um cálculo complexo, como SQL complexo, vários IOs, múltiplas dependências, etc. No momento em que o cache se torna inválido, há um grande número de threads para reconstruir o cache, o que aumenta a carga no backend e pode até causar o travamento do aplicativo.
Como lidar com isso?
Resolver este problema não é muito complicado, os pontos-chave para resolver o problema são:
- Reduza o número de reconstruções de cache.
- Os dados são tão consistentes quanto possível.
- Menos perigo potencial.
Portanto, o seguinte método é geralmente usado:
- Chave mutex (chave mutex) Este método permite que apenas um thread reconstrua o cache, e outros threads aguardam que o thread que reconstrói o cache termine a execução e, em seguida, obtenha os dados do cache novamente.
- Nunca expira "Nunca expira" tem dois significados:
- Do ponto de vista do cache, de fato não há tempo de expiração definido, portanto não haverá problemas causados pela expiração da chave do hotspot, ou seja, o “físico” não irá expirar.
- Do ponto de vista funcional, um tempo de expiração lógico é definido para cada valor.Quando for constatado que o tempo de expiração lógico foi excedido, um thread separado será usado para construir o cache.
33. Existe um problema de poço sem fundo? Como resolver?
Qual é o problema do poço sem fundo?
Em 2010, os nós Memcache do Facebook atingiram 3.000, transportando terabytes de dados armazenados em cache. No entanto, o pessoal de desenvolvimento, operação e manutenção descobriu um problema. Para atender aos requisitos de negócios, um grande número de novos nós Memcache foram adicionados. No entanto, eles descobriram que o desempenho não apenas não melhorou, mas também diminuiu. Naquela época, isso O fenômeno foi chamado de fenômeno do cache do "poço sem fundo" .
Então, por que esse fenômeno ocorre?
De modo geral, adicionar nós deve aumentar o desempenho do cluster Memcache, mas não é o caso. Os bancos de dados de valor-chave geralmente usam funções hash para mapear chaves para cada nó, portanto, a distribuição de chaves não tem nada a ver com o negócio.No entanto, devido ao crescimento contínuo do volume de dados e acesso, um grande número de nós precisa ser adicionado para expansão horizontal, resultando na distribuição de valores-chave. Em mais nós, seja Memcache ou Redis distribuídos, as operações em lote geralmente precisam ser obtidas de nós diferentes. Em comparação com operações em lote de máquina única que envolvem apenas uma operação de rede, distribuída as operações em lote envolverão vários tempos de rede.
Como otimizar o problema do poço sem fundo?
Vamos primeiro analisar o problema do poço sem fundo:
- Uma operação em lote no lado do cliente envolverá várias operações de rede, o que significa que a operação em lote demorará cada vez mais à medida que o número de nós aumentar.
- O aumento do número de conexões de rede também terá certo impacto no desempenho do nó.
As ideias comuns de otimização são as seguintes:
- Otimização do próprio comando, como otimização de instruções de operação, etc.
- Reduza o número de comunicações de rede.
- Reduza os custos de acesso, por exemplo, o cliente usa conexões/pools de conexões persistentes, NIO, etc.
Operação e manutenção do Redis
34. Como lidar com a memória insuficiente reportada pelo Redis?
Existem várias maneiras de lidar com memória insuficiente no Redis:
- Modifique o parâmetro maxmemory do arquivo de configuração redis.conf para aumentar a memória disponível do Redis
- Você também pode definir dinamicamente o limite de memória por meio do comando set maxmemory.
- Modifique a estratégia de eliminação de memória e libere espaço de memória em tempo hábil
- Use o modo de cluster Redis para expansão horizontal.
35.Quais são as estratégias de reciclagem de dados expiradas do Redis?
O Redis tem principalmente duas estratégias de reciclagem de dados expiradas:

Exclusão preguiçosa
A exclusão lenta significa que a chave é detectada quando a consultamos. Se o tempo de expiração for atingido, ela será excluída. Obviamente, uma de suas desvantagens é que se essas chaves expiradas não forem acessadas, elas não poderão ser excluídas e continuarão ocupando memória.
Exclua regularmente
A exclusão periódica significa que o Redis verifica o banco de dados de vez em quando e exclui as chaves expiradas. Como é impossível pesquisar todas as chaves para exclusão, o Redis selecionará aleatoriamente algumas chaves para inspeção e exclusão a cada vez.
36.Quais estratégias de controle de estouro de memória/eliminação de memória o Redis possui?
Quando a memória usada pelo Redis atingir o limite superior de maxmemory, a estratégia de controle de estouro correspondente será acionada.O Redis suporta seis estratégias:
- noeviction: A política padrão não excluirá nenhum dado, rejeitará todas as operações de gravação e retornará informações de erro do cliente. Neste momento, o Redis responde apenas às operações de leitura.
- volátil-lru: Exclua chaves com um atributo de tempo limite (expirar) definido de acordo com o algoritmo LRU até que espaço suficiente seja liberado. Se não houver objetos-chave deletáveis, volte para a estratégia noeviction.
- allkeys-lru: Exclua chaves de acordo com o algoritmo LRU, independentemente de os dados terem um atributo de tempo limite definido, até que espaço suficiente seja liberado.
- allkeys-random: Exclua aleatoriamente todas as chaves até que haja espaço suficiente.
- volátil-aleatório: Exclua aleatoriamente as chaves expiradas até que haja espaço suficiente.
- volátil-ttl: Exclui dados que expirarão recentemente com base no atributo ttl do objeto de valor-chave. Caso contrário, recorra à estratégia de não despejo.
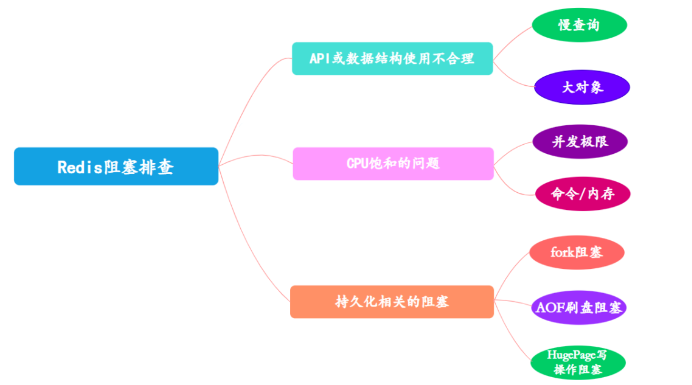
37. Bloqueio de Redis? Como lidar com isso?
Se o Redis estiver bloqueado, você pode verificar isso nos seguintes aspectos:
-
Uso indevido de API ou estruturas de dados
Normalmente, o Redis executa comandos muito rapidamente, mas o uso irracional de comandos pode fazer com que a velocidade de execução seja muito lenta e causar bloqueio. Para cenários de alta simultaneidade, você deve tentar evitar a execução de comandos com complexidade de algoritmo superior a O(n) em objetos grandes.
O processamento de consultas lentas é dividido em duas etapas:
-
- Descubra consultas lentas: o comando slowlog get{n} pode obter os n comandos de consulta lenta mais recentes;
- Depois de descobrir consultas lentas, você pode otimizar consultas lentas em duas direções: 1) Modificar comandos com baixa complexidade de algoritmo, como alterar hgetall para hmget, etc., e desabilitar comandos como chaves e classificação. 2) Ajustar objetos grandes: reduzir grandes dados do objeto ou Divida um objeto grande em vários objetos pequenos para evitar que um comando opere muitos dados.
-
Problema de saturação da CPU
Redis de thread único só pode usar uma CPU ao processar comandos. A saturação da CPU significa que o uso da CPU de núcleo único do Redis chega perto de 100%.
Para esta situação, as etapas de processamento são geralmente as seguintes:
-
- Para determinar se a simultaneidade atual do Redis atingiu o limite, você pode usar o comando estatístico redis-cli-h{ip}-p{port}–stat para obter o uso atual do Redis.
- Se o Redis tiver dezenas de milhares de solicitações, então o OPS do Redis provavelmente atingiu seu limite e a expansão do cluster deve ser feita para compartilhar a pressão do OPS.
- Se houver apenas algumas centenas ou milhares, será necessário verificar o comando e o uso de memória.
-
Bloqueio relacionado à persistência
Para nós Redis com a função de persistência ativada, é necessário verificar se o bloqueio é causado por persistência.
-
- A operação de fork de bloqueio de fork ocorre quando RDB e AOF são reescritos.O thread principal do Redis chama a operação de fork para gerar um processo filho de memória compartilhada, e o processo filho conclui o trabalho de reescrita de arquivo persistente. Se a operação do garfo demorar muito, inevitavelmente fará com que o thread principal seja bloqueado.
- Bloqueio de liberação AOF Quando habilitamos a função de persistência AOF, o método de liberação de arquivo geralmente ocorre uma vez por segundo, e o thread de segundo plano executa uma operação fsync no arquivo AOF a cada segundo. Quando a pressão do disco rígido é muito alta, a operação fsync precisa aguardar até que a gravação seja concluída. Se o thread principal descobrir que já se passaram mais de 2 segundos desde que o último fsync foi bem-sucedido, ele será bloqueado até que o thread em segundo plano conclua a operação fsync para segurança de dados.
- Bloqueio de operação de gravação HugePage Para sistemas operacionais que habilitam HugePages Transparentes, a unidade de páginas de memória copiadas causada por cada comando de gravação muda de 4K para 2MB, que é amplificada 512 vezes, o que diminuirá o tempo de execução das operações de gravação e levará a consultas lentas para um grande número de operações de gravação.
38. Você entende a grande questão-chave?
Durante o uso do Redis, às vezes ocorrem chaves grandes, como:
- O valor armazenado em uma única chave simples é muito grande, com tamanho superior a 10 KB.
- Muitos elementos armazenados em hash, set, zset, list (em milhares)
Que problemas as chaves grandes causarão?
- O cliente leva mais tempo e até expira.
- Ao realizar operações de E/S em chaves grandes, a largura de banda e a CPU ficarão seriamente ocupadas.
- Causa distorção de dados no cluster Redis
- Exclusão ativa, exclusão passiva, etc. podem causar bloqueio
Como encontrar a chave grande?
- Comando bigkeys: use o comando bigkeys para analisar todas as chaves na instância do Redis de maneira transversal e retornar as informações estatísticas gerais e a primeira chave grande em cada tipo de dados.
- redis-rdb-tools: redis-rdb-tools é uma ferramenta escrita em Python para analisar o arquivo de instantâneo rdb do Redis. Ele pode gerar um arquivo json a partir do arquivo de instantâneo rdb ou gerar um relatório para analisar os detalhes de uso do Redis.
Como lidar com chaves grandes?
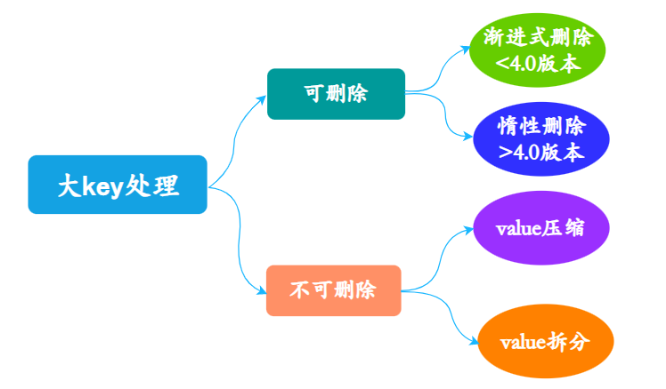
-
Excluir chave grande
-
- Quando a versão do Redis for superior a 4.0, você pode usar o comando UNLINK para excluir chaves grandes com segurança. Este comando pode limpar gradualmente as chaves recebidas de maneira não bloqueadora.
- Quando a versão do Redis for inferior a 4.0, evite usar o comando de bloqueio KEYS. Em vez disso, é recomendado usar o comando SCAN para realizar uma verificação iterativa incremental da chave e, em seguida, determiná-la e excluí-la.
-
Compactar e dividir chaves
-
- Quando o valor é uma string, é mais difícil de dividir, então algoritmos de serialização e compactação são usados para controlar o tamanho da chave dentro de um intervalo razoável.No entanto, tanto a serialização quanto a desserialização consumirão mais tempo.
- Quando o valor é uma string e ainda é uma chave grande após a compactação, ele precisa ser dividido. Uma chave grande é dividida em partes diferentes, a chave de cada parte é registrada e operações como multiget são usadas para implementar a leitura da transação.
- Quando o valor é um tipo de coleção, como lista/conjunto, a fragmentação é executada com base no tamanho estimado dos dados e diferentes elementos são divididos em diferentes fatias após o cálculo.
39. Problemas e soluções comuns de desempenho do Redis?
- É melhor que o mestre não faça nenhum trabalho de persistência, incluindo instantâneos de memória e arquivos de log AOF. Em particular, não habilite instantâneos de memória para persistência.
- Se os dados forem críticos, um Slave habilita os dados de backup AOF e a política é sincronizar uma vez por segundo.
- Para a velocidade da replicação mestre-escravo e a estabilidade da conexão, é melhor que o escravo e o mestre estejam na mesma LAN.
- Tente evitar adicionar bibliotecas escravas à biblioteca principal estressada.
- O mestre chama BGREWRITEAOF para reescrever o arquivo AOF. AOF ocupará uma grande quantidade de recursos de CPU e memória durante a reescrita, fazendo com que a carga do serviço seja muito alta e a suspensão temporária do serviço.
- Por uma questão de estabilidade do Mestre, não use uma estrutura gráfica para replicação mestre-escravo. É mais estável usar uma estrutura de lista vinculada unidirecional, ou seja, o relacionamento mestre-escravo é: Mestre<–Escravo1 <–Slave2<–Slave3…. Esta estrutura também é conveniente para resolver pontos únicos de falha. O problema é realizar a substituição do Master pelo Slave, ou seja, se o Master desligar, você pode habilitar imediatamente o Slave1 como o Mestre, e outras coisas permanecem inalteradas.
Aplicativo Redis
40. Como implementar fila assíncrona usando Redis?
Sabemos que o Redis suporta muitos tipos de dados estruturados, então como usar o Redis como uma fila assíncrona? Geralmente existem as seguintes maneiras:
- Use list como fila, lpush para produzir mensagens e rpop para consumir mensagens.
Dessa forma, o loop consumidor rpop consome mensagens da fila. Mas desta forma, mesmo que não haja mensagem na fila, será executado o rpop, o que causará consumo de CPU do Redis.
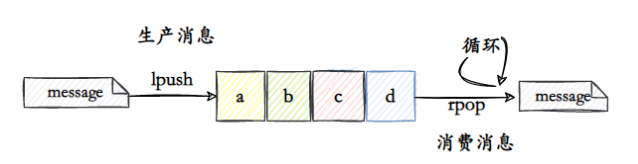
Isso pode ser resolvido deixando o consumidor dormir, mas causará atraso na mensagem.
- Use list como fila, lpush para produzir mensagens e brpop para consumir mensagens.
brpop é uma versão bloqueadora do rpop.Quando a lista estiver vazia, ele será bloqueado até que haja um valor na lista ou expire.
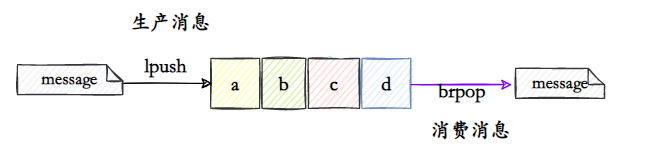
Este método só pode implementar fila de mensagens um para um.
- Use Redis pub/sub para publicar/assinar mensagens
O modo publicar/assinar pode publicar/assinar mensagens em 1:N. O editor publica a mensagem no canal (canal) especificado e os clientes que assinam o canal correspondente podem receber a mensagem.
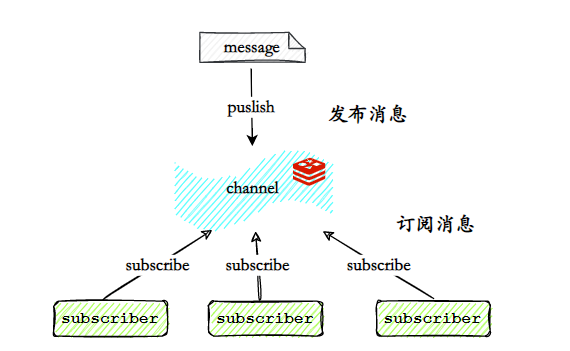
No entanto, este método não é confiável, pois não garante que os assinantes receberão a mensagem, nem armazena a mensagem.
Portanto, a implementação de filas assíncronas gerais ainda é deixada para filas de mensagens profissionais.
41.Como o Redis implementa a fila de atraso?
- Use zset para implementar a classificação
Você pode usar a estrutura zset, usar o carimbo de data/hora definido como pontuação para classificação e usar o comando zadd score1 value1... para continuar produzindo mensagens na memória. Em seguida, use zrangebysocre para consultar todas as tarefas pendentes que atendam às condições e execute as tarefas da fila em um loop.

42.O Redis oferece suporte a transações?
Atomicidade (também chamada de indivisibilidade), consistência (consistência), isolamento (também chamada de independência), durabilidade (durabilidade)
O Redis fornece transações simples, mas seu suporte para transações ACID é incompleto.
O comando multi representa o início de uma transação, e o comando exec representa o fim de uma transação. Os comandos entre eles são executados em ordem atômica:
O princípio das transações Redis é que todas as instruções não são executadas antes da execução, mas são armazenadas em cache em uma fila de transações do servidor. Assim que o servidor recebe a instrução exec, ele começa a executar toda a fila de transações. Após a conclusão da execução, ela retorna à execução de todas as instruções de uma vez.resultado.
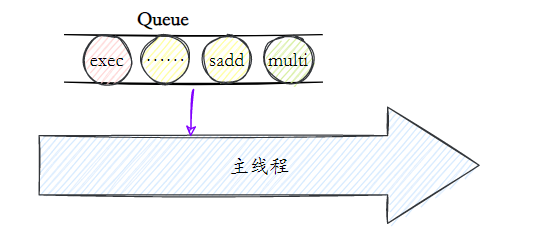
Como os comandos de execução do Redis são de thread único, esse conjunto de comandos é executado sequencialmente e não será interrompido por outros threads.
Quais são os pontos a serem observados nas transações Redis?
Os pontos a serem observados são:
- As transações Redis não suportam reversão, ao contrário das transações MySQL, que são executadas ou não executadas;
- Durante a execução das transações, o servidor Redis não será interrompido por solicitações de comandos enviadas por outros clientes. Os comandos de outros clientes não serão executados até que todos os comandos de transação sejam executados.
Por que a transação Redis não suporta reversão?
As transações do Redis não oferecem suporte à reversão.
Se o comando executado contiver erros de sintaxe, o Redis não será executado.Esses problemas podem ser capturados e resolvidos no nível do programa. Mas se ocorrerem outros problemas, os comandos restantes ainda serão executados.
A razão para isso é porque a reversão requer muito mais trabalho, e não oferecer suporte à reversão mantém as coisas simples e rápidas .
43. Você entende o uso de scripts Redis e Lua?
A função de transação do Redis é relativamente simples.No desenvolvimento diário, os scripts Lua podem ser usados para aprimorar os comandos do Redis.
Os scripts Lua podem trazer estes benefícios para os desenvolvedores:
- Os scripts Lua são executados atomicamente no Redis e nenhum outro comando será inserido durante o processo de execução.
- Os scripts Lua podem ajudar o pessoal de desenvolvimento, operação e manutenção a criar seus próprios comandos personalizados, e esses comandos podem residir na memória Redis para serem reutilizados.
- Os scripts Lua podem empacotar vários comandos ao mesmo tempo, reduzindo efetivamente a sobrecarga da rede.
Por exemplo, este sistema clássico de venda flash usa Lua para deduzir o script de inventário Redis:
-- 库存未预热
if (redis.call('exists', KEYS[2]) == 1) then
return -9;
end;
-- 秒杀商品库存存在
if (redis.call('exists', KEYS[1]) == 1) then
local stock = tonumber(redis.call('get', KEYS[1]));
local num = tonumber(ARGV[1]);
-- 剩余库存少于请求数量
if (stock < num) then
return -3
end;
-- 扣减库存
if (stock >= num) then
redis.call('incrby', KEYS[1], 0 - num);
-- 扣减成功
return 1
end;
return -2;
end;
-- 秒杀商品库存不存在
return -1;
44.Você entende o pipeline do Redis?
O Redis oferece três maneiras de empacotar vários comandos do cliente e enviá-los ao servidor para execução:
Pipelining, Transações e Lua Scripts.
Pipeline _
O pipeline Redis é o mais simples dos três. Quando o cliente precisa executar vários comandos redis, os vários comandos a serem executados podem ser enviados ao servidor de uma só vez através do pipeline. Sua função é reduzir o RTT (Round Trip Time) Impacto no desempenho, por exemplo, usamos o comando nc para enviar duas instruções ao servidor redis.
Depois que o servidor Redis receber vários comandos enviados do pipeline, ele continuará a executar os comandos e armazenar em cache os resultados da execução dos comandos até que a execução do último comando seja concluída e, em seguida, os resultados da execução de todos os comandos serão retornados ao cliente de uma vez só.
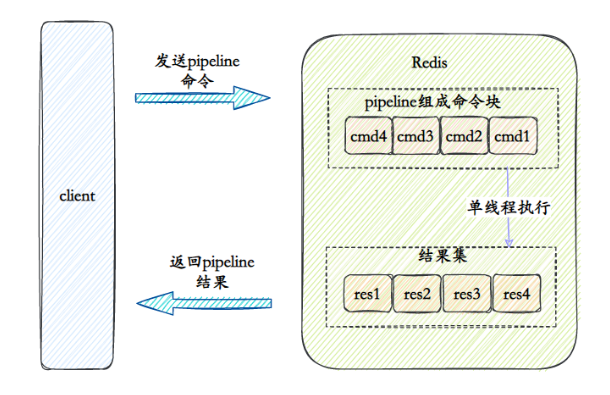
Vantagens do Pipelining
Em termos de desempenho, Pipelining tem as duas vantagens a seguir:
- Salvar RTT : vários comandos são empacotados e enviados ao servidor de uma só vez, reduzindo o número de chamadas de rede entre o cliente e o servidor.
- Troca de contexto reduzida : quando o cliente/servidor precisar ler ou gravar dados da rede, uma chamada do sistema será gerada. As chamadas do sistema são operações muito demoradas. O programa é projetado para alternar do modo de usuário para o modo kernel e, em seguida, do modo kernel.O processo de voltar ao modo de usuário. Quando executamos 10 comandos redis, ocorrerão 10 mudanças de contexto do modo de usuário para o modo kernel. No entanto, se usarmos o Pipeining para empacotar vários comandos em um e enviá-lo ao servidor de uma vez, ocorrerá apenas uma mudança de contexto.
45.Você entende como o Redis implementa bloqueios distribuídos?
O objetivo essencial do Redis como um bloqueio distribuído é ocupar um "buraco" no Redis. Quando outros processos querem ocupá-lo, descobrem que alguém já está ocupado ali, então têm que desistir ou tentar novamente mais tarde.
- V1: comando setnx
Geralmente, o comando setnx (set if not exist) é usado para ocupar a armadilha, e apenas um cliente pode ocupar a armadilha. Primeiro a chegar, primeiro a ser servido, quando acabar, chame o comando del para liberar o poço.
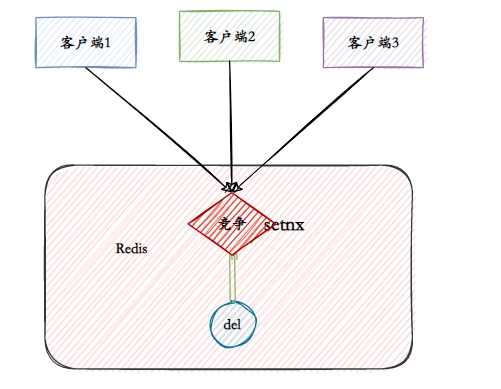
> setnx lock:fighter true
OK
... do something critical ...
> del lock:fighter
(integer) 1
Mas há um problema: se ocorrer uma exceção no meio da execução da lógica, a instrução del pode não ser chamada, o que causará um deadlock e o bloqueio nunca será liberado.
- V2: Liberação do tempo limite de bloqueio
Portanto, após obter o bloqueio, adicione um tempo de expiração ao bloqueio, como 5s, para que mesmo que ocorra uma exceção no meio, o bloqueio possa ser liberado automaticamente após 5 segundos.
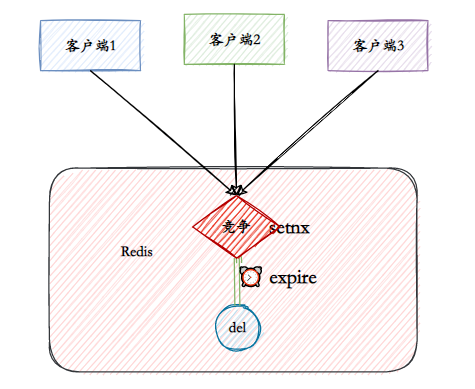
> setnx lock:fighter true
OK
> expire lock:fighter 5
... do something critical ...
> del lock:fighter
(integer) 1
Mas ainda existem problemas com a lógica acima. Se o processo do servidor travar repentinamente entre setnx e expire, pode ser porque a máquina foi desligada ou encerrada manualmente, o que fará com que expire não seja executado e também causará um deadlock.
A raiz deste problema é que setnx e expire são duas instruções em vez de instruções atômicas. Se essas duas instruções puderem ser executadas juntas, não haverá problema.
- V3: definir comando
Este problema foi resolvido no Redis versão 2.8.Esta versão adiciona parâmetros estendidos da instrução set para que as instruções setnx e expire possam ser executadas juntas.
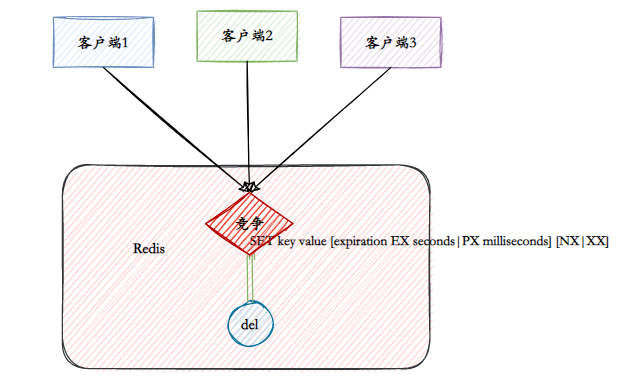
set lock:fighter3 true ex 5 nx
OK
... do something critical ...
> del lock:codehole
A instrução acima é uma instrução atômica composta por setnx e expire, que é um bloqueio distribuído relativamente completo.
É claro que, no desenvolvimento real, ninguém escreverá comandos de bloqueio distribuídos sozinho, porque existe uma roda profissional - Redisson .
46. Se existem 100 milhões de chaves no Redis e 100.000 delas começam com um prefixo fixo e conhecido, como encontrar todas elas?
Use keyso comando para verificar a lista de chaves do padrão especificado. No entanto, deve-se notar que a instrução das chaves fará com que o thread seja bloqueado por um período de tempo e o serviço online será pausado. O serviço não pode ser restaurado até que a instrução seja executada. Neste momento, você pode usar scano comando. scanO comando pode extrair keya lista de padrões especificados sem bloqueio, mas haverá uma certa probabilidade de duplicação. Basta fazer a desduplicação uma vez no cliente, mas o tempo total gasto será maior do que usando o comando diretamente keys.
Fonte de informação: Contra-ataque da escória do macarrão: Cinquenta e duas perguntas da série Redis! Trinta mil palavras + oitenta fotos com explicação detalhada! (qq. com)