Índice
1.3 Selecione subconjuntos por meio do índice de carimbo de data/hora
2. Série temporal de frequência fixa
2.1 Criação de séries temporais de frequência fixa
2.2 Frequência e deslocamento de séries temporais
2.3 Movimento de séries temporais
3.1 Criação de período de tempo
3.2 Transformação de frequência de períodos
4.1 Método de reamostragem (resamostra)
5. Estatísticas de dados - janela deslizante
5.2 Método de janela deslizante
1. Série temporal
1.1 Série temporal
时间序列Refere-se a uma sequência numérica formada em vários momentos, que pode ocorrer de forma regular ou irregular.
Os dados de série temporal incluem principalmente os seguintes tipos:
-
Timestamp: timestamp: representa um momento específico, como agora.
-
Período: período: como 2022 ou março de 2022.
-
Intervalo de tempo: intervalo: representado por um carimbo de data/hora inicial e um carimbo de data/hora final.
1.2 Criar série temporal
No Pandas, o tipo de série temporal mais básico 时间戳é indexado Series对象.
Os carimbos de data e hora são representados usando um objeto Timestamp (subclasse derivada de série), que é altamente compatível com data e hora e pode ser convertido em um objeto diretamente por meio to_datetime()de funções .datetimeTimeStamp
Por exemplo:
import pandas as pd
from datetime import datetime
import numpy as np
print(pd.to_datetime('20200828142123')) # 将datetime转换为Timestamp对象,年月日 时秒分Quando uma lista de vários datetimes é passada, o Pandas irá coagi-la a um objeto de classe DatetimeIndex.
# 传入多个datetime字符串
date_index = pd.to_datetime(['20200820151423', '20200828212325', '20200908152360'])
print(date_index)
按照索引获取时间戳:
for i in range(len(date_index)):
print(date_index[i])timestamp do pandas como objeto de série indexado
# 创建时间序列类型的Series对象
date_index = pd.to_datetime(['20200820151423', '20200828212325', '20200908152360'])
# 创建以时间戳为索引的series对象
date_ser = pd.Series([11, 22, 33], index=date_index)
print(date_ser)Você também pode passar uma lista contendo vários objetos de data e hora para o parâmetro index e também pode criar um objeto Series com um índice de carimbo de data/hora.
# 指定索引为多个datetime的列表
date_list = [datetime(2020, 1, 1), datetime(2020, 1, 15),
datetime(2020, 2, 20), datetime(2020, 4, 1),
datetime(2020, 5, 5), datetime(2020, 6, 1)]
time_se = pd.Series(np.arange(6), index=date_list)
print(time_se)O objeto DataFrame possui índice de carimbo de data/hora
data_demo = [[11, 22, 33], [44, 55, 66],
[77, 88, 99], [12, 23, 34]]
date_list = [datetime(2020, 1, 23), datetime(2020, 2, 15),
datetime(2020, 5, 22), datetime(2020, 3, 30)]
time_df = pd.DataFrame(data_demo, index=date_list)
print(time_df)1.3 Selecione subconjuntos por meio do índice de carimbo de data/hora
# 指定索引为多个日期字符串的列表,要有相同的格式
date_list = ['2017.05.30', '2019.02.01',
'2017.6.1', '2018.4.1',
'2019.6.1', '2020.1.23']
# 将日期字符串转换为DatetimeIndex
date_index = pd.to_datetime(date_list)
# 创建以DatetimeIndex 为索引的Series对象
date_se = pd.Series(np.arange(6), index=date_index)
print(date_se)Selecione um subconjunto:
1. Obtenha dados de subconjunto por meio do índice de posição
print(date_se[3])2. Obtenha dados usando a data construída por datetime
#根据datetime构造日期获取
date_time = datetime(2018,4,1)
print(date_se[date_time])3. Obtenha a sequência de data que atende aos requisitos de formato
#传入相应的符合日期的字符串获取
print(date_se['20180401'])
print(date_se['2018.04.01'])
print(date_se['2018/04/01'])
print(date_se['2018-04-01'])
print(date_se['04/01/2018'])4. Use diretamente o ano ou mês especificado para operar o índice e obter dados para um determinado ano
print(date_se['2017'])5. Use o método truncate() para interceptar objetos Series ou DataFrame
truncate(before = None,after = None,axis = None,copy = True)-
antes – significa truncar todas as linhas antes deste valor de índice.
-
depois – significa truncar todas as linhas após este valor de índice.
-
eixo – representa o eixo truncado, padronizando a direção do índice da linha.
# 扔掉2018-1-1之前的数据
sorted_se = date_se.sort_index()
print(sorted_se.truncate(before='2018-1-1'))
# 扔掉2018-7-31之后的数据
print(sorted_se.truncate(after='2018-7-31'))2. Série temporal de frequência fixa
2.1 Criação de séries temporais de frequência fixa
A função date_range() fornecida no Pandas é usada principalmente para gerar um objeto DatetimeIndex com uma frequência fixa.
Descrição do parâmetro:
-
início: Indica a data de início, o padrão é Nenhum.
-
fim: Indica a data de término, o padrão é Nenhum.
-
períodos: Indica quantos valores de índice de timestamp são gerados.
-
freq: usado para especificar a unidade de temporização.
Perceber:
startPelo endmenos três parâmetros devem ser especificados para periodsesses freqquatro parâmetros, caso contrário ocorrerá um erro.
O uso é o seguinte:
1. Ao chamar a função date_range() para criar um objeto DatetimeIndex, se apenas a data de início (parâmetro inicial) e a data final (parâmetro final) forem passadas, o timestamp gerado por padrão é calculado por dia, ou seja, a frequência parâmetro é D
# 创建DatetimeIndex对象时,只传入开始日期与结束日期
print(pd.date_range('2020/08/10', '2023/08/20'))2. Se apenas a data de início ou de término for informada, você também precisará usar o parâmetro de períodos para especificar quantos carimbos de data/hora serão gerados.
# 创建DatetimeIndex对象时,传入start与periods参数
print(pd.date_range(start='2020/08/10', periods=5))
# 创建DatetimeIndex对象时,传入end与periods参数,往前推
print(pd.date_range(end='2020/08/10', periods=5))3. Se desejar que os carimbos de data e hora na série temporal sejam em domingos fixos todas as semanas, você pode definir o parâmetro freq como "W-SUN" ao criar o DatetimeIndex.
dates_index = pd.date_range('2020-01-01', # 起始日期
periods=5, # 周期
freq='W-SUN') # 频率
print(dates_index)4. Se a data contém informações relacionadas à hora e você deseja gerar um conjunto de carimbos de data/hora normalizados para meia-noite do dia, você pode definir o valor do parâmetro normalize como True.
# 创建DatetimeIndex,并指定开始日期、产生日期个数、默认的频率,以及时区
date_index = pd.date_range(start='2020/8/1 12:13:30', periods=5,
tz='Asia/Hong_Kong')
print(date_index)
#规范化时间戳
date_index2 = pd.date_range(start='2020/8/1 12:13:30', periods=5,
normalize=True, tz='Asia/Hong_Kong')
print(date_index2)2.2 Frequência e deslocamento de séries temporais
1. Os dados da série temporal gerados por padrão são calculados diariamente, ou seja, a frequência é “D”.
-
"D" é uma frequência fundamental, representada por um alias de uma string, como "D" é um alias para "dia".
-
A frequência é composta por uma frequência base e um multiplicador, por exemplo, “5D” significa a cada 5 dias.
Outras descrições de frequência são as seguintes:

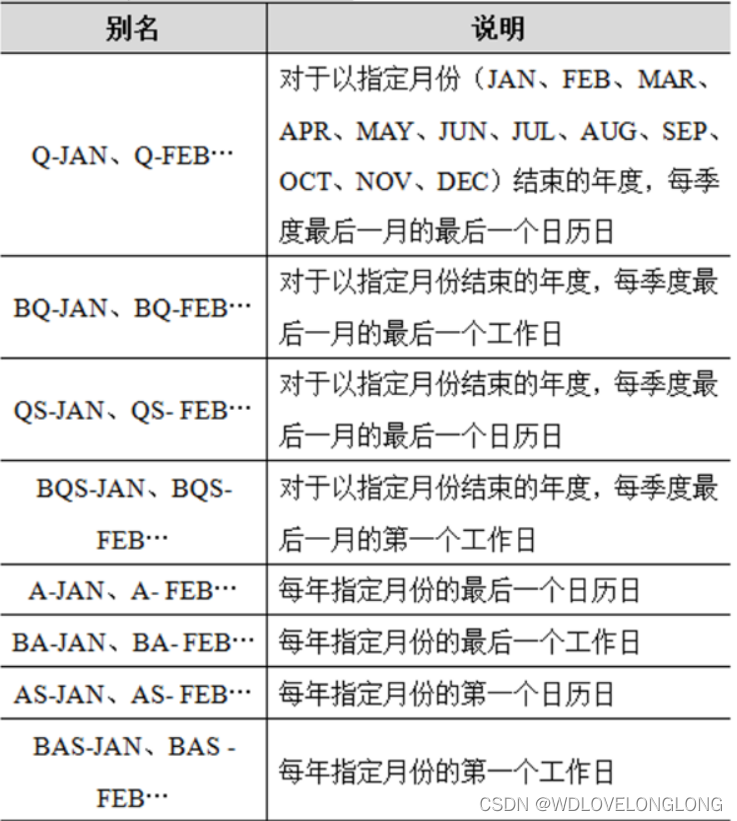
Usado para especificar o atributo freq:
date_time5D = pd.date_range(start='2020/2/1', end='2020/2/28', freq='5D')
print(date_time5D)2. Cada frequência básica também pode ser seguida por um objeto DateOffset chamado deslocamento de data. Se quiser criar um objeto DateOffset, você precisa importar primeiro o módulo pd.tseries.offsets.
Você pode especificar um deslocamento para criar uma série temporal. Ao mesmo tempo, crie um deslocamento de 14 dias e 10 horas, que pode ser convertido em duas semanas e dez horas. A "semana" é representada pelo tipo Semana, e o "hora" é representada pelo tipo Hora. Você pode usar o sinal de mais para conectá-los.
import pandas as pd
from datetime import datetime
import numpy as np
from pandas.tseries.offsets import *
date_offset1 = DateOffset(weekday=2,hour=10)
''' - year
- month
- day
- weekday
- hour
- minute
- second
- microsecond
- nanosecond.'''
date_offset2 = Week(2) + Hour(10)
date_index1 = pd.date_range('2020/3/1',periods=5,freq=date_offset1)
date_index2 = pd.date_range('2020/3/1',periods=5,freq=date_offset2)
print(date_index1)
print(date_index2)2.3 Movimento de séries temporais
Mover refere-se a mover dados para frente ou para trás ao longo do eixo do tempo. Como mostrado abaixo:
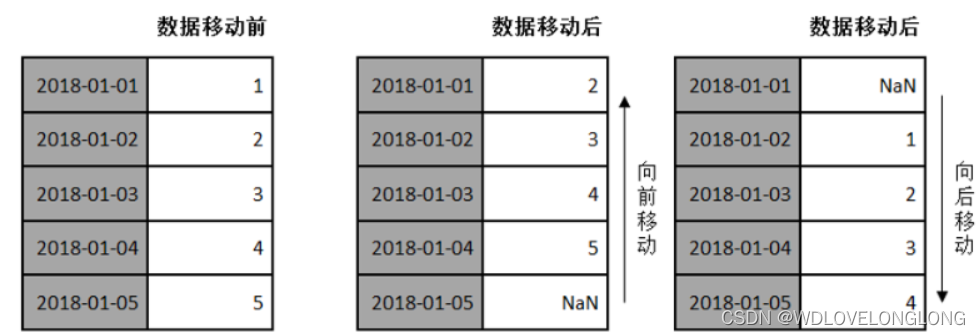
O objeto Pandas fornece um método shift() para mover dados para frente ou para trás, mas o índice de dados permanece inalterado.
O uso é o seguinte:
shift(periods=1, freq=None, axis=0)
#periods – 表示移动的幅度,可以为正数,也可以为负数,默认值是1,代表移动一次。
date_index = pd.date_range('2020/01/01', periods=5)
time_ser = pd.Series(np.arange(5) + 1, index=date_index)
print(time_ser)
# 向后移动一次
print(time_ser.shift(1))
#向前移动一次
print(time_ser.shift(-1))3. Prazo e cálculo
3.1 Criação de período de tempo
1. A classe Período representa um período ou período padrão, como um determinado ano, um determinado mês, um determinado dia, uma determinada hora, etc.
A maneira de criar um objeto da classe Period é relativamente simples: você só precisa passar uma data na forma de uma string ou inteiro no construtor.
# 创建Period对象,表示从2020-01-01到2020-12-31之间的时间段
period = pd.Period(2020)
print(period)
# 表示从2019-06-01到2019-06-30之间的整月时间
period = pd.Period('2019/6')
print(period)2. Objetos de período podem participar de operações matemáticas.
Se o objeto Período for adicionado ou subtraído de um número inteiro, a operação de deslocamento será realizada de acordo com a unidade de tempo específica.
period = period + 1 # Period对象加上一个整数
print(period)Se uma operação matemática for realizada em dois objetos de Período com a mesma frequência, o resultado será o seu número de unidades.
# 表示从2019-06-01到2019-06-30之间的整月时间
period = pd.Period('2019/6')
print(period)
period = period + 1 # Period对象加上一个整数
print(period)
# 创建一个与period频率相同的时期
other_period = pd.Period(201401, freq='M' )
print(period - other_period)3. Se você deseja criar vários objetos Período e eles aparecem regularmente, você pode usar a função period_range().
Retorna um objeto PeriodIndex, que é um índice composto por um conjunto de objetos de período. O exemplo é o seguinte:
period_index = pd.period_range('2014.1.8', '2014.5.31', freq='M')
print(period_index)4. Além de usar o método acima para criar um PeriodIndex, você também pode passar diretamente um conjunto de strings de data no método de construção PeriodIndex.
period_index = pd.period_range('2014.1.8', '2014.5.31', freq='M')
print(period_index)
str_list = ['2012', '2013', '2014']
period_list = pd.PeriodIndex(str_list, freq='A-DEC')
print(period_list)
time_index = pd.Series(np.arange(len(period_index)) + 1,index = period_index)
print(time_index)Nota: DatetimeIndex é uma estrutura de índice usada para se referir a uma série de pontos no tempo, enquanto PeriodIndex é uma estrutura de índice usada para se referir a uma série de períodos de tempo.
3.2 Transformação de frequência de períodos
1.Pandas fornece um método asfreq() para converter a frequência do período.
asfreq(freq,método = Nenhum,como = Nenhum,normalizar = Falso,valor_preenchimento = Nenhum )
Descrição do parâmetro:
-
freq – representa a unidade de temporização.
-
como - pode assumir o valor inicial ou final, e o padrão é final.
-
normalize – Indica se o índice de tempo deve ser redefinido para meia-noite.
-
fill_value – O valor usado para preencher valores ausentes.
# 创建时期对象
period = pd.Period('2019', freq='A-DEC')
print(period)
period_freq_start = period.asfreq('M', how='start')
print(period_freq_start)
period_freq_end = period.asfreq('M',how='end')
print(period_freq_end)4. Reamostragem
4.1 Método de reamostragem (resamostra)
1. resample() no Pandas é um método conveniente para reamostragem e conversão de frequência de dados regulares de séries temporais.
resample(regra, como=Nenhum, eixo=0, fill_method=N
date_index = pd.date_range('2019.7.8', periods=30)
time_ser = pd.Series(np.arange(len(date_index)) + 1, index=date_index)
print(time_ser)
print(time_ser.resample('W-MON').mean())um, fechado=Nenhum, rótulo=Nenhum, ...)
Descrição do parâmetro:
-
regra – uma string ou DateOffset que representa a frequência de reamostragem.
-
fill_method – Indica como interpolar durante o upsampling.
-
fechado – Define qual extremidade da redução da resolução é fechada.
1. Reamostrar os dados através do método resample()
Nota: O parâmetro how não é mais recomendado, mas o novo método ".resample(...).mean()" é usado para calcular a média.
2. Se o parâmetro fechado passado durante a reamostragem for deixado, significa que a faixa de amostragem é fechada à esquerda e aberta à direita.
Ou seja, em uma série temporal dentro de um determinado intervalo, o carimbo de data/hora no início é incluído, mas o carimbo de data/hora no final não é incluído.
print(time_ser.resample('W-MON', closed='left').mean())4.2 Redução da resolução
1. As partículas de tempo de redução da resolução ficarão maiores e a quantidade de dados será reduzida. Para evitar que os dados correspondentes a alguns carimbos de data/hora fiquem ociosos, você pode usar métodos integrados para agregar dados.
Por exemplo, a reamostragem OHLC é mais comum para dados de ações, incluindo o preço de abertura, o preço mais alto, o preço mais baixo e o preço de fechamento.
Pandas fornece um método ohlc() especificamente.
date_index = pd.date_range('2020/06/01', periods=30)
shares_data = np.random.rand(30)
time_ser = pd.Series(shares_data, index=date_index)
print(time_ser)
result = time_ser.resample('7D').ohlc() # OHLC重采样 得到七天中的开盘价,最高价,最低价以及收盘价
print(result)2. A redução da amostragem é equivalente a outra forma de operação de agrupamento: agrupa as séries temporais de acordo com a data e depois aplica o método de agregação a cada agrupamento para obter um resultado.
# 通过groupby技术实现降采样
result = time_ser.groupby(lambda x: x.week).mean()
print(result)4.3 aumento da resolução
1. A granularidade temporal do upsampling torna-se menor e a quantidade de dados aumentará, o que provavelmente fará com que alguns carimbos de data/hora não tenham dados correspondentes.
Ao se deparar com esta situação, a solução comumente usada é a interpolação.Existem vários métodos específicos:
-
Use o método ffill(limit) ou bfill(limit) para preencher o valor antes ou depois do valor nulo. Limit pode limitar o número de preenchimentos.
-
O preenchimento é realizado através de fillna('ffill') ou fillna('bfill') Passar ffill significa preencher com o valor antes de NaN, e passar bfill significa preencher com o valor seguinte.
-
Complete os dados de acordo com o algoritmo de interpolação usando o método interpolate().
data_demo = np.array([['101', '210', '150'], ['330', '460', '580']])
date_index = pd.date_range('2020/06/10', periods=len(data_demo), freq='W-SUN')
time_df = pd.DataFrame(data_demo, index=date_index,
columns=['A产品', 'B产品', 'C产品'])
print(time_df)
#增加采样时间,但没有填充数据
time_df_asfreq = time_df.resample('D').asfreq()
print(time_df_asfreq)
#用前面的数据填充
time_df_ffill = time_df.resample('D').ffill()
print(time_df_ffill)
#用后面的数据 填充
time_df_bfill = time_df.resample('D').bfill()
print(time_df_bfill)5. Estatísticas de dados - janela deslizante
5.1 Janela deslizante
1. A janela deslizante refere-se ao enquadramento da série temporal de acordo com o comprimento unitário especificado para calcular os indicadores estatísticos dentro do quadro.
É equivalente a um controle deslizante com um comprimento especificado deslizando na escala, e os dados no controle deslizante podem ser realimentados sempre que ele desliza uma unidade.
Os exemplos são os seguintes:
Uma determinada filial calculou diariamente os dados de vendas de todo o ano de 2017. Agora o gerente geral quer verificar aleatoriamente as vendas da filial no dia 28 de agosto (Dia dos Namorados Chinês). Se os dados desse dia forem coletados apenas Se forem analisados separadamente, os dados são relativamente absolutos e não podem ser bem utilizados. Refletem as vendas globais em torno desta data.

A fim de melhorar a precisão dos dados, o valor de um determinado ponto pode ser expandido para um intervalo que inclui o ponto, e os dados dentro do intervalo podem ser usados para julgamento.
Você pode retirar os dados de 24 de agosto a 2 de setembro e encontrar o valor médio desse intervalo como resultado da verificação pontual.

Este intervalo é a janela, o seu comprimento unitário é 10, e os dados são calculados diariamente, pelo que o indicador médio é calculado para 10 dias, o que é mais razoável e pode reflectir bem a situação global das actividades chinesas do Dia dos Namorados.
3. Mover a janela significa que ela desliza para uma extremidade.Cada slide não desliza a seção inteira, mas desliza unidade por unidade.
Por exemplo, se a janela deslizar uma unidade para a direita, o intervalo de tempo enquadrado pela janela será de 25/08/2017 a 03/09/2017.
Cada vez que a janela se move, ela moverá apenas uma unidade de comprimento por vez, e o comprimento da janela é sempre de 10 unidades até que ela se mova até o final.
Percebe-se a partir disso que os indicadores calculados através da janela deslizante serão mais estáveis e a faixa de flutuação dos dados será menor.
5.2 Método de janela deslizante
Pandas fornece um método de janela rolante().
rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None)Descrição do parâmetro:
-
janela – representa o tamanho da janela.
-
min_periods – Número mínimo de observações por janela.
-
center – Se o rótulo da janela deve ser centralizado.
-
win_type – representa o tipo de janela.
-
fechado – utilizado para definir a abertura e fechamento do intervalo.
year_data = np.random.randn(365)
date_index = pd.date_range('2017-01-01', '2017-12-31', freq='D')
ser = pd.Series(year_data, date_index)
print(ser.head()) #打印前几个数据 默认为5
#画图观察
import matplotlib.pyplot as plt
ser.plot(style='y--')
ser_window = ser.rolling(window=10).mean()
ser_window.plot(style='b')
plt.show()