1. Introdução ao XPath
XPath é uma linguagem para encontrar informações em documentos XML. Originalmente projetado para pesquisar documentos XML, mas também pode ser usado para pesquisar documentos HTML.
2. Instale o lxml
lxml é uma biblioteca de análise de terceiros para Python, oferece suporte à análise de HTML e XML e é extremamente eficiente, compensando as deficiências da própria biblioteca padrão xml do Python na análise de XML.
Como instalar bibliotecas de terceiros:
pip install lxml
3. Princípio de análise XPath
- Crie uma instância de um objeto etree e os dados do código-fonte da página analisada precisarão ser carregados no objeto.
- Chame o método xpath no objeto etree combinado com expressões xpath para realizar o posicionamento do rótulo e a captura de conteúdo.
4. Instancie o objeto etree
- Carregue os dados do código-fonte no documento html local no objeto etree:
etree.parse(filePath) - Carregue os dados do código-fonte obtidos da Internet no objeto:
etree.HTML(response.text) - xpath('expressão xpath')
5. Expressão de caminho XPath
| expressão | ilustrar |
|---|---|
| / | Selecione no nó raiz |
| // | Representa vários níveis, começando de qualquer posição |
| . | Selecione o nó atual |
| … | Selecione o nó pai do nó atual |
| @ | selecionar atributo |
| //div[@class='title'] tag[@attrName=“attrValue”] | posicionamento de atributos |
| //div[@class=“zhang”]/p[3] | Posicionamento do índice, o índice começa em 1 |
| /texto() | O que é obtido é o conteúdo de texto direto no rótulo |
| //texto() | Conteúdo de texto não imediato em tags (todo o conteúdo de texto) |
| /@attrName ==>img/src | Pegar atributos |
6. Combinado com a explicação real do combate
Tome o site da CSDN como exemplo para explicar
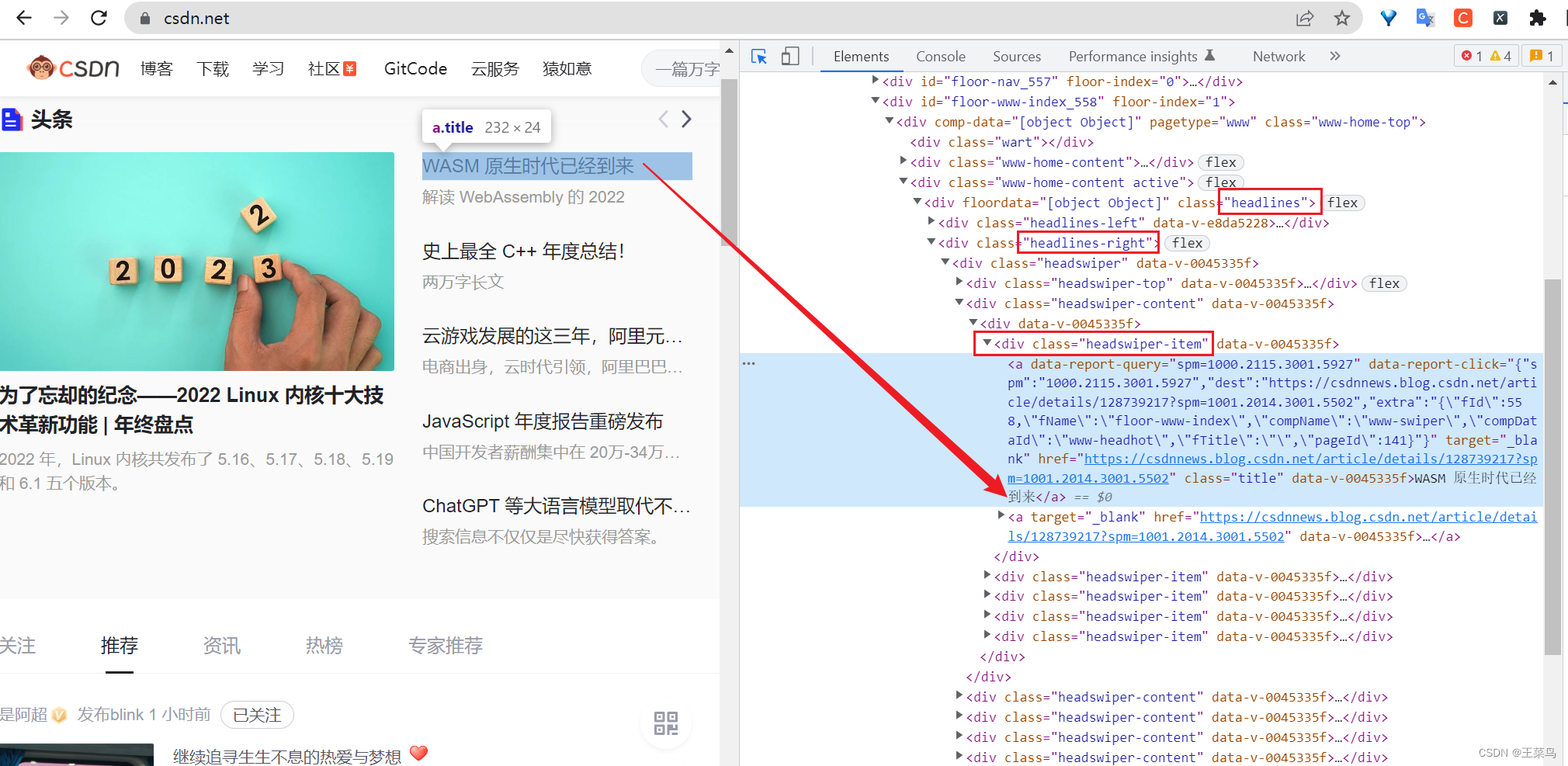
exemplo: Aqui eu quero pegar o título da manchete do blog na página inicial do site oficial, abrir o console (clique na pequena seta no console ou pressione Ctrl+Shift+C ao mesmo tempo), aponte para o título e localize-o de acordo com o valor da classe da tag div (geralmente usamos mais sintaxe xpath.
from lxml import etree
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
url = "https://www.csdn.net/"
response = requests.get(url=url, headers=headers)
# 使用etree解析
data = etree.HTML(response.text)
# //div表示任意路径下的div标签
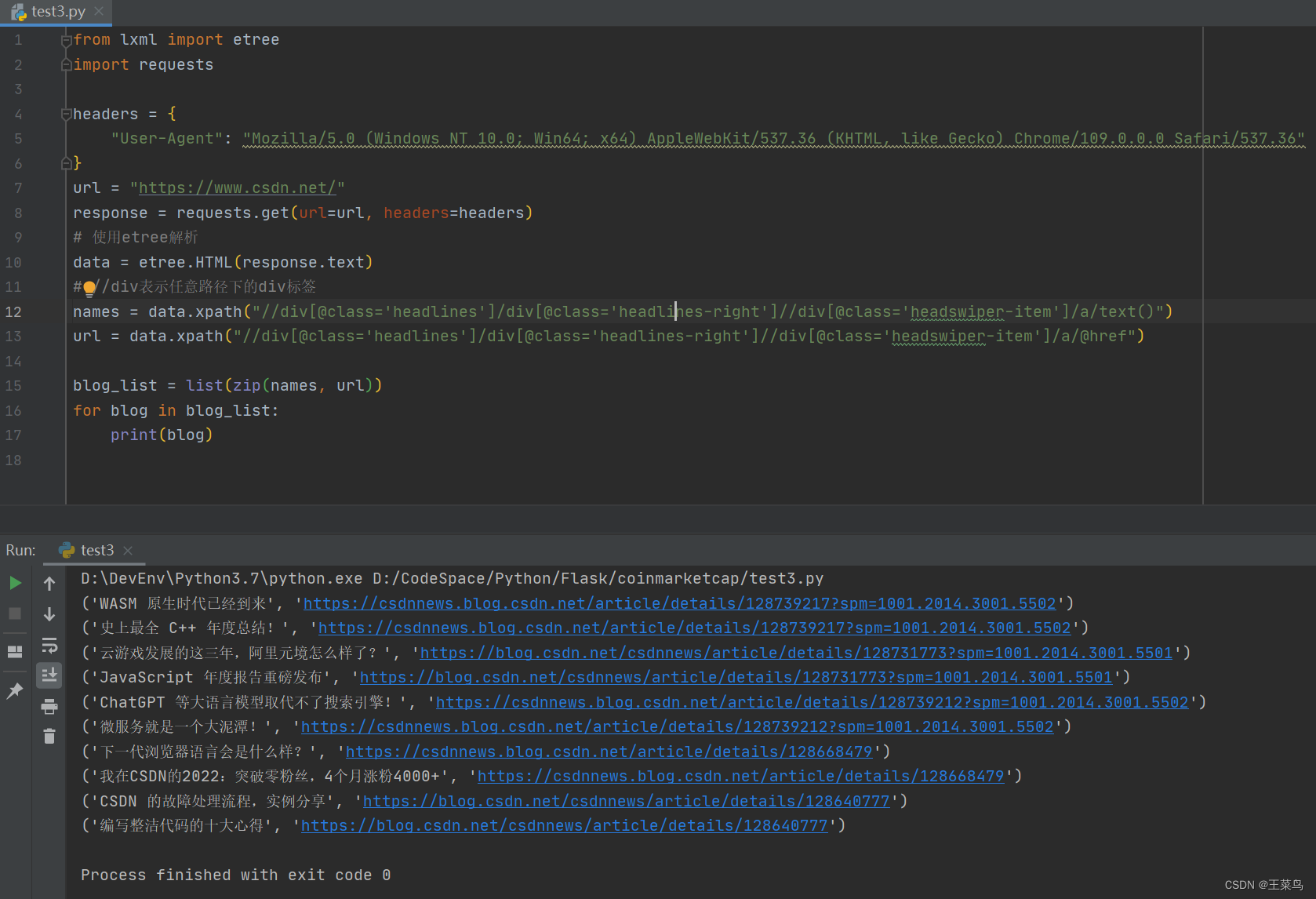
names = data.xpath("//div[@class='headlines']/div[@class='headlines-right']//div[@class='headswiper-item']/a/text()")
url = data.xpath("//div[@class='headlines']/div[@class='headlines-right']//div[@class='headswiper-item']/a/@href")
blog_list = list(zip(names, url))
for blog in blog_list:
print(blog)
Perceba o efeito: