O conteúdo foi extraído do meu site de aprendizagem: topjavaer.cn
O que é MySQL
MySQL é um banco de dados relacional que armazena dados na forma de tabelas. Você pode pensar nisso como uma tabela do Excel. Como os dados são armazenados na forma de uma tabela, eles possuem uma estrutura de tabela (linhas e colunas). As linhas representam cada linha de dados e as colunas representam cada valor dessa linha. Os valores na coluna possuem tipos de dados, como inteiros, strings, datas, etc.
Três paradigmas principais de banco de dados
Primeira forma normal 1NF
Garanta a atomicidade dos campos da tabela do banco de dados. Um site de entrevistas Java muito abrangente
Por exemplo, o campo userInfo: 广东省 10086'deve ser dividido em userInfo: 广东省 userTel: 10086dois campos de acordo com a primeira forma normal.
Segunda forma normal 2NF
Em primeiro lugar, deve atender à primeira forma normal e também inclui duas partes: primeiro, a tabela deve ter uma chave primária; segundo, as colunas da chave não primária devem depender completamente da chave primária e não podem depender apenas de parte da chave primária.
por exemplo. Suponha que a tabela de relacionamento de seleção de curso seja student_course(student_no, student_name, idade, course_name, nota, crédito) e a chave primária seja (student_no, course_name). Os créditos são totalmente dependentes do nome do curso, e o nome e a idade são totalmente dependentes do número do aluno, o que não obedece ao segundo paradigma e levará à redundância de dados (os alunos escolhem n cursos, e há n registros de nome e idade) e anomalias de inserção (inserir um novo curso, porque não há carteira de aluno, novos registros de turma não podem ser salvos) e outros problemas.
Deve ser dividido em três tabelas: alunos: student(nº_aluno, nome_aluno, idade); cursos: course(nome_curso, crédito); relações de seleção de cursos: student_course_relation(nº_aluno, nome_curso, nota).
Terceira forma normal 3NF
Em primeiro lugar, deve satisfazer a segunda forma normal.Além disso, as colunas de chave não primária devem depender diretamente da chave primária e não pode haver dependências transitivas. Ou seja, não pode existir: a coluna A de chave não primária depende da coluna B de chave não primária e a coluna B de chave não primária depende da chave primária.
Suponha que a tabela de relacionamento do aluno seja Aluno (student_no, student_name, age, academy_id, academy_telephone) e a chave primária seja "student number".O ID da faculdade depende do número do aluno, e o local da faculdade e o número de telefone da faculdade dependem do id da faculdade. Existe uma dependência transitiva, que não é consistente. Terceiro paradigma.
A tabela de relacionamento dos alunos pode ser dividida nas duas tabelas a seguir: aluno: (nº_aluno, nome_aluno, idade, id_academia); faculdade: (id_academia, telefone_academia).
Qual é a diferença entre 2NF e 3NF?
- 2NF é baseado no fato de a coluna de chave não primária depender inteiramente da chave primária ou de parte da chave primária.
- 3NF é baseado no fato de a coluna da chave não primária depender diretamente da chave primária ou da chave não primária.
Este artigo foi incluído no repositório Github, que inclui noções básicas de informática, noções básicas de Java, multi-threading, JVM, banco de dados, Redis, Spring, Mybatis, SpringMVC, SpringBoot, distribuído, microsserviços, padrões de design, arquitetura, recrutamento escolar e recrutamento social compartilhamento, etc. Pontos de conhecimento básicos, bem-vindo à estrela!
Link (clicável): endereço do Github
Se você não conseguir acessar o Github, poderá acessar o endereço do gitee.
Link (clicável): endereço do gitee
Quais são as quatro principais características das transações?
Características da transação ACID : atomicidade ( Atomicity), consistência ( Consistency), isolamento ( Isolation), durabilidade ( Durability).
- Atomicidade significa que todas as operações incluídas em uma transação são bem-sucedidas ou falham e são revertidas.
- Consistência significa que uma transação deve estar em um estado consistente antes e depois da execução. Por exemplo, as contas de a e b têm um total de 1.000 yuans. Após a transferência entre as duas pessoas ser bem-sucedida ou falhar, a soma de suas contas ainda será de 1.000.
- Isolamento . Relacionado ao nível de isolamento, por exemplo
read committed, uma transação só pode ler as modificações enviadas. - Durabilidade significa que uma vez que uma transação é confirmada, as alterações nos dados do banco de dados são permanentes e a operação de confirmação da transação não será perdida mesmo se o sistema de banco de dados encontrar uma falha.
Quais são os níveis de isolamento da transação?
Primeiro entenda os seguintes conceitos: leitura suja, leitura não repetível e leitura fantasma.
- Leitura suja refere-se à leitura de dados em outra transação não confirmada durante uma transação.
- Leitura não repetível significa que, para uma determinada linha de registros no banco de dados, várias consultas dentro de um intervalo de transações retornam valores de dados diferentes. Isso ocorre porque outra transação modificou os dados e os enviou durante o intervalo de consulta.
- A leitura fantasma ocorre quando uma transação lê registros em um determinado intervalo e outra transação insere um novo registro no intervalo. O entendimento correto da leitura fantasma é que a conclusão de uma operação de leitura dentro de uma transação não pode suportar a execução comercial subsequente. Suponha que a transação deseja adicionar um novo registro, a chave primária é id e a seleção é executada antes de adicionar. Nenhum registro com id xxx foi encontrado, mas ocorre um conflito de chave primária durante a inserção. Esta é uma leitura fantasma. Nenhum registro pode ser lido, mas é encontrado um conflito de chave primária. Isso ocorre porque o registro foi realmente inserido por outras transações, mas não é visível para a transação atual.
A diferença entre leitura não repetível e leitura suja é que a leitura suja ocorre quando uma transação lê os dados sujos não confirmados de outra transação, enquanto a leitura não repetível ocorre quando os dados enviados pela transação anterior são lidos.
O isolamento da transação visa resolver os problemas de leituras sujas, leituras não repetíveis e leituras fantasmas mencionadas acima.
Os quatro níveis de isolamento fornecidos pelo banco de dados MySQL são:
- Serializable : Resolva o problema de leitura fantasma forçando as transações a serem ordenadas para que não entrem em conflito umas com as outras.
- Leitura repetível : nível de isolamento de transação padrão do MySQL, que garante que múltiplas instâncias da mesma transação verão as mesmas linhas de dados ao ler dados simultaneamente, resolvendo o problema de leitura não repetível.
- Leitura confirmada : uma transação só pode ver as alterações feitas por transações confirmadas. Leituras sujas podem ser evitadas.
- Leitura não confirmada : todas as transações podem ver os resultados da execução de outras transações não confirmadas.
Verifique o nível de isolamento:
select @@transaction_isolation;
Definir nível de isolamento:
set session transaction isolation level read uncommitted;
Qual nível de isolamento geralmente é usado para bancos de dados de ambiente de produção?
A maioria dos ambientes de produção usa RC . Por que não RR?
Leitura repetível, referida como RR
Read Committed, referida como RC
Razão 1: No nível de isolamento RR, há um bloqueio de lacuna, o que leva a uma probabilidade de impasse muito maior do que RC!
Razão dois: no nível de isolamento RR, se a coluna condicional perder o índice, a tabela será bloqueada! No nível de isolamento RC, apenas as linhas são bloqueadas!
Em outras palavras, RC tem maior simultaneidade que RR.
E na maioria dos cenários, o problema de leitura não repetível é aceitável. Afinal, os dados foram enviados, então não há grande problema em lê-los!
Link (clicável): Um site de entrevistas Java muito abrangente
A relação entre codificação e conjunto de caracteres
Geralmente podemos inserir várias letras em chinês e inglês no editor, mas são para leitura humana, não para computadores. Na verdade, os computadores salvam e transmitem dados no formato binário 0101 .
Então é preciso haver uma regra para converter letras chinesas e inglesas em binário. Dentre eles, d corresponde a 64 em hexadecimal, que pode ser convertido para 01 no formato binário. Portanto, letras e números correspondem um a um, e este é o formato de codificação ASCII .
Ele usa um byte para identificar caracteres.Existem 8位128 símbolos básicos e 128 símbolos estendidos. Ele só pode representar letras e números em inglês .
Obviamente, isso não é suficiente. Portanto, para identificar o chinês , apareceu o formato de codificação GB2312 . Para identificar o grego , apareceu o formato de codificação grego e, para identificar o russo , foi ajustado o formato de codificação cp866 .
Para unificá-los, surgiu o formato de codificação Unicode , que utiliza de 2 a 4 bytes para representar caracteres, para que teoricamente todos os símbolos possam ser incluídos, e também é totalmente compatível com a codificação ASCII, ou seja, a mesma A letra d é representado por 64 em ASCII, mas ainda é representado por 64 em Unicode.
Mas a diferença é que a codificação ASCII é representada por 1 byte, enquanto Unicode é representada por dois bytes.
Eles também são a letra D. O Unicode usa um byte a mais que o ascii, como segue:
D ASCII: 01100100
D Unicode: 00000000 01100100
Como você pode ver, a codificação Unicode acima tem 0 na frente, o que na verdade não é útil, mas ainda ocupa 1 byte, o que é um desperdício. Se pudermos nos esconder quando devemos, podemos economizar muito espaço.De acordo com essa ideia, existe a codificação UTF-8 .
Resumindo, combinar símbolos com códigos binários de acordo com certas regras é chamado de codificação . E reunir n muitos desses caracteres codificados é o que costumamos chamar de conjunto de caracteres .
Por exemplo, o conjunto de caracteres utf-8 é a coleção de todos os caracteres no formato de codificação utf-8.
Eu gostaria de ver quais conjuntos de caracteres o MySQL suporta. Pode ser executadoshow charset;
A diferença entre utf8 e utf8mb4
Como mencionado acima, utf-8 é uma otimização baseada em unicode. Como o unicode tem uma maneira de representar todos os caracteres, utf-8 também pode representar todos os caracteres. Para evitar confusão, irei chamá-lo de utf8 mais tarde .
Os conjuntos de caracteres suportados pelo mysql incluem utf8 e utf8mb4.
Vamos falar primeiro sobre a codificação utf8mb4 . mb4 significa a maioria dos bytes 4. Como você pode ver na imagem mais à direita acima Maxlen, ele suporta um máximo de 4 bytes para representar caracteres. Ele pode ser usado para representar quase todos os caracteres atualmente conhecidos.
Vamos falar sobre utf8 no conjunto de caracteres mysql , que é o conjunto de caracteres padrão do banco de dados . Mas observe que esse utf8 não é aquele utf8 , nós o chamamos de pequeno conjunto de caracteres utf8. Por que você diz isso? Porque pode ser visto no Maxlen que ele suporta até 3 bytes para representar caracteres. De acordo com o método de nomenclatura de utf8mb4, ele deve ser chamado de utf8mb3 com mais precisão .
utf8 é como uma versão castrada do utf8mb4, que suporta apenas alguns caracteres. Por exemplo emoji, não oferece suporte a emoticons.
Nos conjuntos de caracteres suportados pelo mysql, a terceira coluna, collation , refere-se às regras de comparação de conjuntos de caracteres .
Por exemplo, "debug" e "Debug" são a mesma palavra, mas a capitalização é diferente. Devem ser consideradas a mesma palavra?
É quando você precisa usar agrupamento.
Você SHOW COLLATION WHERE Charset = 'utf8mb4';pode verificar utf8mb4quais regras de comparação são suportadas.
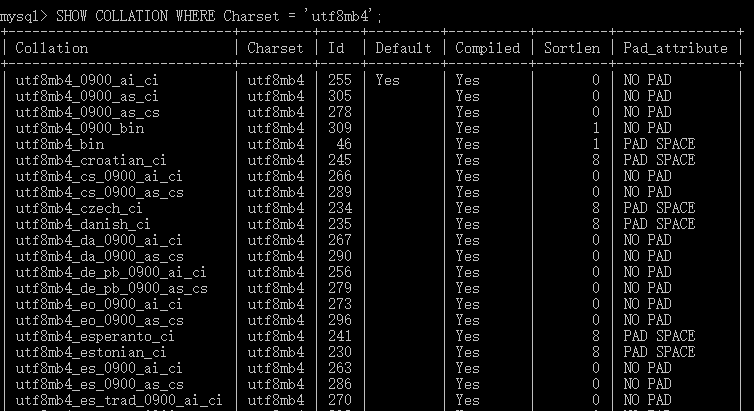
Se collation = utf8mb4_general_ci, significa que sob a premissa de usar o conjunto de caracteres utf8mb4, a comparação é realizada caractere por caractere ( general) e não faz distinção entre maiúsculas e minúsculas ( _ci,case insensitice).
Neste caso, “debug” e “Debug” são a mesma palavra.
Se alterado para collation=utf8mb4_bin, significa comparar os tamanhos dos bits binários um por um .
Portanto, "depurar" e "Depurar" não são a mesma palavra.
Então, quais são as desvantagens do utf8mb4 em comparação com o utf8?
Sabemos que na tabela do banco de dados, se o tipo de campo for char(2), ele 2se refere ao número de caracteres , o que significa que não importa qual conjunto de caracteres de codificação seja usado nesta tabela , 2 caracteres podem ser colocados.
E char tem um comprimento fixo . Para caber 2 caracteres utf8mb4, char reservará 2*4(maxlen=4)= 81 byte de espaço por padrão.
Se for utf8mb3, 2 * 3 (maxlen=3) = 6os bytes de espaço serão reservados por padrão. Ou seja, neste caso, o utf8mb4 utilizará um pouco mais de espaço que o utf8mb3.
índice
O que é um índice?
Um índice é uma estrutura de dados usada por mecanismos de armazenamento para melhorar a velocidade de acesso às tabelas do banco de dados . Ele pode ser comparado ao índice de um dicionário, o que pode ajudá-lo a encontrar rapidamente os registros correspondentes.
Os índices geralmente são armazenados em arquivos em disco, que ocupam espaço físico.
Quais são as vantagens e desvantagens da indexação?
vantagem:
- Acelere pesquisas de dados
- Adicionar índices a campos usados para classificação ou agrupamento pode acelerar o agrupamento e a classificação.
- Acelere junções entre tabelas
deficiência:
- A indexação requer espaço físico
- Isso reduzirá a eficiência de adições, exclusões e modificações na tabela, porque cada vez que um registro da tabela é adicionado, excluído ou modificado, o índice precisa ser mantido dinamicamente, resultando em tempos mais longos de adição, exclusão e modificação .
Deixe-me compartilhar com vocês um repositório Github, que contém mais de 300 PDFs clássicos de livros de informática compilados por Dabin, incluindo linguagem C, C++, Java, Python, front-end, banco de dados, sistema operacional, rede de computadores, estrutura de dados e algoritmo, máquina aprendizagem, Vida de Programação , etc., você pode marcá-lo e pesquisar diretamente nele na próxima vez que procurar um livro. O armazém está sendo atualizado continuamente! Endereço do Github
Qual é a função do índice?
Os dados são armazenados no disco. Ao consultar os dados, se não houver índice, todos os dados serão carregados na memória e recuperados em sequência, e o disco será lido mais vezes. Com o índice, não há necessidade de carregar todos os dados, porque a altura da árvore B+ é geralmente de 2 a 4 camadas, e apenas 2 a 4 leituras de disco são necessárias no máximo, melhorando bastante a velocidade da consulta.
Em que circunstâncias é necessário criar um índice?
- Campos frequentemente usados em consultas
- Campos de indexação usados com frequência para conexões podem acelerar a conexão
- A indexação geralmente é necessária para campos que precisam ser classificados, porque o índice já está classificado, o que pode acelerar as consultas de classificação.
Em que circunstâncias a indexação não é criada?
whereCampos não utilizados em condições não são adequados para indexação- A tabela tem menos registros. Por exemplo, se houver apenas algumas centenas de dados, não há necessidade de adicionar um índice.
- Adições, exclusões e modificações frequentes são necessárias. Necessidade de avaliar se a indexação é adequada
- As colunas que participam dos cálculos de colunas não são adequadas para a construção de índices
- Campos que não são altamente distinguíveis não são adequados para indexação, como gênero, que possui apenas três valores: masculino/feminino/desconhecido. Adicionar um índice não melhorará a eficiência da consulta.
estrutura de dados de índice
As estruturas de dados do índice incluem principalmente árvore B+ e tabela hash, e os índices correspondentes são índice de árvore B+ e índice hash, respectivamente. Os tipos de índice do mecanismo InnoDB incluem índice de árvore B+ e índice hash. O tipo de índice padrão é índice de árvore B+.
Índice de árvore B+
A árvore B + é implementada com base em ponteiros de acesso sequencial de árvore B e nó folha. Possui o equilíbrio da árvore B e melhora o desempenho da consulta de intervalo por meio de ponteiros de acesso sequencial.
Na árvore B+, os nós do nó keysão organizados em ordem crescente da esquerda para a direita. Se os vizinhos esquerdo e direito de um ponteiro keyforem a chave i e a chave i+1 respectivamente , então o ponteiro aponta para todos os nós do nó que keysão maiores ou iguais à chave i e menores ou iguais à chave i+ 1 .
[Falha na transferência da imagem do link externo. O site de origem pode ter um mecanismo anti-leeching. Recomenda-se salvar a imagem e carregá-la diretamente (img-sBews5yP-1691456619394) (http://img.topjavaer.cn/img/ B + índice de árvore 0.png)]
Ao realizar uma operação de pesquisa, primeiro execute uma pesquisa binária no nó raiz para encontrar keyo ponteiro e, em seguida, pesquise recursivamente no nó apontado pelo ponteiro. Até que o nó folha seja encontrado, execute uma pesquisa binária no nó folha para encontrar keyo item de dados correspondente.
O tipo de índice mais comumente usado no banco de dados MySQL é BTREEo índice, que é implementado com base na estrutura de dados em árvore B+.
mysql> show index from blog\G;
*************************** 1. row ***************************
Table: blog
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: blog_id
Collation: A
Cardinality: 4
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
Índice de hash
O índice hash é implementado com base na tabela hash. Para cada linha de dados, o mecanismo de armazenamento fará o hash da coluna do índice para obter o código hash, e o algoritmo hash deve tentar garantir que o valor do código hash seja calculado para diferentes valores de coluna. É diferente, o valor do código hash é usado como o valor-chave da tabela hash, e o ponteiro para a linha de dados é usado como o valor do valor da tabela hash. A complexidade de tempo da pesquisa de dados dessa forma é O(1), que geralmente é usada para pesquisas precisas.
Qual é a diferença entre o índice Hash e o índice de árvore B+?
- Os índices hash não suportam classificação porque as tabelas hash não são ordenadas.
- Os índices hash não suportam pesquisas de intervalo .
- Os índices hash não suportam consultas difusas e correspondência de prefixo mais à esquerda para índices de várias colunas.
- Como haverá conflitos de hash na tabela hash , o desempenho do índice hash é instável, enquanto o desempenho do índice da árvore B + é relativamente estável.Cada consulta vai do nó raiz ao nó folha.
Por que a árvore B+ é mais adequada para implementar o índice de banco de dados do que a árvore B?
-
Como os dados da árvore B+ são todos armazenados em nós folha, e os nós folha são todos índices, é conveniente verificar o banco de dados. Você só precisa verificar os nós folha uma vez. No entanto, a árvore B também armazena dados porque é nós de ramificação, precisamos encontrar Dados específicos que precisam ser verificados em ordem por uma travessia em ordem, então a árvore B+ é mais adequada para consultas de intervalo. No banco de dados, as consultas baseadas em intervalo são muito frequentes, então a árvore B+ é geralmente usado para índices de banco de dados.
-
Os nós da árvore B+ armazenam apenas o valor da chave do índice, e o endereço da informação específica existe no endereço do nó folha. Isso permite que mais nós sejam armazenados no índice baseado em página. Reduza mais despesas de E/S.
-
A eficiência da consulta da árvore B+ é mais estável. Qualquer pesquisa por palavra-chave deve seguir um caminho do nó raiz até o nó folha. O comprimento do caminho de todas as consultas de palavras-chave é o mesmo, resultando em eficiência de consulta igual para cada dado.
Quais são as categorias de índices?
1. Índice de chave primária : O único índice não vazio denominado primário, nenhum valor nulo é permitido.
2. Índice exclusivo : O valor na coluna do índice deve ser único, mas valores nulos são permitidos. A diferença entre um índice exclusivo e um índice de chave primária é que o campo de índice exclusivo pode ser nulo e pode haver vários valores nulos, enquanto o campo de índice de chave primária não pode ser nulo. O objetivo do índice exclusivo: identificar exclusivamente cada registro na tabela do banco de dados, principalmente para evitar a inserção repetida de dados. A instrução SQL para criar um índice exclusivo é a seguinte:
ALTER TABLE table_name
ADD CONSTRAINT constraint_name UNIQUE KEY(column_1,column_2,...);
3. Índice combinado : Um índice criado em uma combinação de vários campos da tabela será usado somente quando os campos à esquerda desses campos forem usados nas condições de consulta. Ao usar um índice combinado, o princípio do prefixo mais à esquerda deve ser seguido.
4. Índice de texto completo : O índice de texto completo só pode ser usado em campos de tipo CHARe .VARCHARTEXT
5. Índice comum : O índice comum é o índice mais básico, não tem restrições e o valor pode estar vazio.
Qual é o princípio de correspondência mais à esquerda?
Se o índice mais à esquerda no índice combinado for usado na instrução SQL, essa instrução SQL poderá usar esse índice combinado para realizar a correspondência. Quando uma consulta de intervalo ( >, <, between, like) for encontrada, a correspondência será interrompida e o índice não será usado para campos subsequentes.
Para (a,b,c)indexação, se a condição de consulta for a/ab/abc, o índice será usado, mas se bc for usado, o índice não será usado.
Para (a,b,c,d)indexação, a condição de consulta é a = 1 and b = 2 and c > 3 and d = 4, então os três campos a, b e c podem usar o índice, mas d não pode usar o índice. Porque uma consulta de intervalo foi encontrada.
Como mostrado na figura abaixo, o índice (a, b) é criado, a é ordenado globalmente na árvore de índices, enquanto b é globalmente desordenado e ordenado localmente (quando a é igual, será classificado de acordo com b). Os índices não podem ser usados para executar diretamente b = 2esta condição de consulta.
[Falha na transferência da imagem do link externo. O site de origem pode ter um mecanismo anti-leeching. Recomenda-se salvar a imagem e carregá-la diretamente (img-e4IVib9u-1691456619394) (http://img.topjavaer.cn/img/ prefixo mais à esquerda.png)]
Quando o valor de a é determinado, b é ordenado. Por a = 1exemplo, o valor b é 1 e 2 é um estado ordenado. Nesse a = 2momento, o valor de b é 1 e 4 também está em um estado ordenado. a = 1 and b = 2Os campos aeb podem usar o índice ao executar . Durante a execução a > 1 and b = 2, o campo a pode usar o índice, mas o campo b não pode usar o índice. Como o valor de a é um intervalo neste momento e não é fixo, o valor de b não está ordenado dentro desse intervalo, portanto o índice não pode ser usado para o campo b.
O que é um índice clusterizado?
O InnoDB usa a chave primária da tabela para construir uma árvore de índice de chave primária, e os nós folha armazenam os dados de registro de toda a tabela. O armazenamento de nós folha de índice clusterizado é logicamente contínuo e usa uma conexão de lista duplamente vinculada.Os nós folha são classificados na ordem da chave primária, de modo que a pesquisa de classificação e a pesquisa de intervalo da chave primária são mais rápidas.
Os nós folha do índice clusterizado são os registros de linha de toda a tabela. InnoDB usa um índice clusterizado como chave primária. Os índices clusterizados são muito mais eficientes do que as consultas de índices não clusterizados.
Para InnoDB, o índice clusterizado é geralmente o índice de chave primária na tabela. Se a chave primária especificada não for exibida na tabela, o primeiro NULLíndice exclusivo da tabela que não é permitido será selecionado. Se não houver chave primária e nenhum índice exclusivo adequado, InnoDBuma chave primária oculta será gerada internamente como um índice clusterizado. O comprimento desta chave primária oculta é de 6 bytes e seu valor aumentará automaticamente à medida que os dados forem inseridos.
O que é um índice de cobertura?
selectAs colunas de dados só podem ser obtidas a partir do índice, não havendo necessidade de voltar à tabela para uma segunda consulta, o que significa que a coluna da consulta deve ser coberta pelo índice utilizado. Para innodbo índice secundário da tabela, se o índice puder cobrir a coluna consultada, uma consulta secundária do índice de chave primária poderá ser evitada.
Nem todos os tipos de índices podem cobrir índices. Os índices de cobertura armazenam os valores das colunas de índice, enquanto os índices hash e os índices de texto completo não armazenam os valores das colunas de índice, portanto, o MySQL usa índices de árvore b+ como índices de cobertura.
Para consultas que usam índices de cobertura, se usados na frente da consulta explain, a coluna extra de saída será exibida como using index.
Por exemplo, na user_liketabela de curtidas do usuário, o índice combinado é e (user_id, blog_id)nenhum deles é .user_idblog_idnull
explain select blog_id from user_like where user_id = 13;
explainExtraA coluna do resultado Using indexé que a coluna consultada é coberta pelo índice, e a condição de filtragem onde está em conformidade com o princípio do prefixo mais à esquerda.Você pode encontrar diretamente os dados que atendem às condições por meio da pesquisa de índice, sem voltar à tabela para consultar os dados.
explain select user_id from user_like where blog_id = 1;
explainExtraA coluna do resultado Using where; Using indexé que a coluna consultada é coberta pelo índice. A condição de filtragem onde não está em conformidade com o princípio do prefixo mais à esquerda. Os dados qualificados não podem ser encontrados por meio da pesquisa de índice, mas os dados qualificados podem ser encontrados por meio da varredura de índice, e há não há necessidade de retornar a tabela para consultar os dados .

Princípios de design de índice?
- Para campos que são frequentemente usados como condições de consulta, índices devem ser criados para melhorar a velocidade da consulta.
- Campos de índice que frequentemente exigem operações de classificação, agrupamento e união
- Quanto maior for a discriminação da coluna do índice , melhor será o efeito do índice. Por exemplo, se você usar uma coluna com baixa distinção, como gênero, como índice, o efeito será muito fraco.
- Evite indexar "campos grandes". Tente usar campos com pequenos volumes de dados como índices. Como
MySQLos valores dos campos são mantidos juntos durante a manutenção do índice, isso inevitavelmente fará com que o índice ocupe mais espaço e também levará mais tempo para comparar durante a classificação. - Tente usar índices curtos . Ao indexar strings mais longas, você deve especificar um comprimento de prefixo mais curto, porque índices menores envolvem menos E/S de disco e as velocidades de consulta são mais rápidas.
- Quanto mais índices, melhor. Cada índice requer espaço físico adicional e a manutenção leva tempo.
- Não crie índices para campos que são adicionados, excluídos ou modificados com frequência. Supondo que um determinado campo seja modificado com frequência, isso significa que o índice precisa ser reconstruído com frequência, o que inevitavelmente afetará o desempenho do MySQL.
- Use o princípio do prefixo mais à esquerda .
Quando um índice expirará?
Situações que levam à falha do índice:
- Para índices compostos, se o campo mais à esquerda do índice composto não for utilizado, o índice não será utilizado.
- Como consultas que começam com %, por exemplo
%abc, não podem usar índices; como consultas que não começam com %, por exemploabc%, são equivalentes a consultas de intervalo, e índices serão usados. - O tipo de coluna na condição de consulta é uma string e não são usadas aspas. A conversão implícita pode ocorrer devido a tipos diferentes, tornando o índice inválido.
- Ao determinar se uma coluna de índice não é igual a um determinado valor
- Execute operações em colunas de índice
- Condições de consulta usando
orconexões também causarão falha no índice
O que é um índice de prefixo?
Às vezes é necessário criar um índice em uma coluna de caracteres muito longa, o que torna o índice extremamente grande e lento. O uso de índices de prefixo evita esse problema.
O índice de prefixo refere-se à indexação dos primeiros caracteres de texto ou string, de modo que o comprimento do índice seja menor e a velocidade da consulta seja mais rápida.
A chave para criar um índice de prefixo é escolher um prefixo longo o suficiente para garantir alta seletividade do índice . Quanto maior a seletividade do índice, maior a eficiência da consulta, porque um índice altamente seletivo permite que o MySQL filtre mais linhas de dados durante a pesquisa.
Como criar um índice de prefixo:
// email列创建前缀索引
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
pushdown de índice
Consulte meu outro artigo: Pushdown de índice ilustrado!
Quais são os mecanismos de armazenamento comuns?
Os quatro mecanismos de armazenamento comumente usados no MySQL são: MyISAM , InnoDB , MEMORY e ARCHIVE . O mecanismo de armazenamento padrão após o MySQL 5.5 é InnoDB.
Mecanismo de armazenamento InnoDB
InnoDB é o mecanismo de armazenamento transacional padrão do MySQL , o mais usado e é construído com base em índices clusterizados. O InnoDB fez muitas otimizações internamente, como a capacidade de criar automaticamente índices hash adaptativos na memória para acelerar as operações de leitura.
Vantagens : Suporta transações e recursos de recuperação de falhas; introduz bloqueios em nível de linha e restrições de chave estrangeira.
Desvantagens : O espaço de dados ocupado é relativamente grande.
Cenários aplicáveis : é necessário suporte a transações e há uma alta frequência de leituras e gravações simultâneas.
Mecanismo de armazenamento MyISAM
Os dados são armazenados em um formato compacto. Para dados somente leitura, ou a tabela é relativamente pequena e pode tolerar operações de reparo, o mecanismo MyISAM pode ser usado. MyISAM armazena tabelas em dois arquivos, o arquivo de dados .MYDe o arquivo de índice .MYI.
Vantagens : Acesso rápido.
Desvantagens : MyISAM não oferece suporte a transações e bloqueios em nível de linha, não oferece suporte à recuperação segura após uma falha e não oferece suporte a chaves estrangeiras.
Cenários aplicáveis : Não há exigência de integridade da transação; todos os dados da tabela serão somente leitura.
Mecanismo de armazenamento de MEMÓRIA
O mecanismo MEMORY coloca todos os dados na memória e a velocidade de acesso é mais rápida, mas quando o sistema travar, os dados serão perdidos.
O mecanismo MEMORY usa índices hash por padrão, salvando o valor hash da chave e o ponteiro para a linha de dados no índice hash.
Vantagens : Acesso mais rápido.
Desvantagens :
- Os dados do índice hash não são armazenados na ordem dos valores do índice e não podem ser usados para classificação.
- Pesquisas parciais de correspondência de índice não são suportadas porque os índices hash usam todo o conteúdo da coluna de índice para calcular o valor hash.
- Apenas a comparação de igualdade é suportada, a consulta de intervalo não é suportada.
- Quando ocorre um conflito de hash, o mecanismo de armazenamento precisa percorrer todos os ponteiros de linha na lista vinculada e compará-los linha por linha até encontrar uma linha que atenda às condições.
Mecanismo de armazenamento ARCHIVE
O mecanismo de armazenamento ARCHIVE é muito adequado para armazenar grandes quantidades de dados independentes como registros históricos. ARCHIVE fornece função de compactação e tem velocidade de inserção eficiente, mas esse mecanismo não oferece suporte a índices, portanto, o desempenho da consulta é ruim.
Qual é a diferença entre MyISAM e InnoDB?
- Diferenças nas estruturas de armazenamento . Cada MyISAM é armazenado como três arquivos no disco. O nome do arquivo começa com o nome da tabela e a extensão indica o tipo de arquivo. Os arquivos .frm armazenam definições de tabela. A extensão do arquivo de dados é .MYD (MYData). A extensão do arquivo de índice é .MYI (MYIndex). Todas as tabelas InnoDB são armazenadas no mesmo arquivo de dados (ou em vários arquivos, ou arquivos de espaço de tabela independentes).O tamanho da tabela InnoDB é limitado apenas pelo tamanho do arquivo do sistema operacional, que geralmente é de 2 GB.
- A diferença no espaço de armazenamento . MyISAM suporta três formatos de armazenamento diferentes: tabela estática (padrão, mas observe que não pode haver espaços no final dos dados, eles serão removidos), tabela dinâmica e tabela compactada. Depois que a tabela for criada e os dados importados, nenhuma operação de modificação será executada. Você pode usar tabelas compactadas para reduzir significativamente o uso do espaço em disco. O InnoDB requer mais memória e armazenamento e estabelecerá seu próprio buffer pool dedicado na memória principal para armazenar dados e índices em cache.
- Portabilidade, backup e recuperação . Os dados MyISAM são armazenados na forma de arquivos, por isso são muito convenientes para transferência de dados entre plataformas. Você pode executar operações em uma tabela individualmente durante o backup e a recuperação. Para o InnoDB, as soluções viáveis são copiar arquivos de dados, fazer backup do log binário ou usar mysqldump, o que é relativamente problemático quando o volume de dados atinge dezenas de gigabytes.
- Se o bloqueio em nível de linha é compatível . MyISAM suporta apenas bloqueios em nível de tabela. Quando os usuários operam uma tabela myisam, as instruções select, update, delete e insert bloquearão automaticamente a tabela. Se a tabela bloqueada atender à condição de simultaneidade de inserção, novos dados poderão ser inseridos no final do tabela.dados. InnoDB suporta bloqueios em nível de linha e bloqueios em nível de tabela, e o padrão são bloqueios em nível de linha. Os bloqueios de linha melhoram muito o desempenho de operações simultâneas multiusuário.
- Seja para apoiar a recuperação segura após transações e falhas . MyISAM não oferece suporte a transações. InnoDB fornece suporte a transações e possui recursos de transação, reversão e reparo de falhas.
- Seja para oferecer suporte a chaves estrangeiras . MyISAM não oferece suporte, mas InnoDB sim.
- Seja para oferecer suporte a MVCC . MyISAM não oferece suporte, mas InnoDB sim. Para lidar com transações de alta simultaneidade, o MVCC é mais eficiente do que o simples bloqueio.
- Se os índices clusterizados são suportados . MyISAM não oferece suporte a índices clusterizados, mas o InnoDB oferece suporte a índices clusterizados.
- Índice de texto completo . MyISAM suporta índice de texto completo do tipo FULLTEXT. O InnoDB não oferece suporte ao índice de texto completo do tipo FULLTEXT, mas o innodb pode usar o plug-in sphinx para oferecer suporte ao índice de texto completo, e o efeito é melhor.
- Chave primária da tabela . MyISAM permite que tabelas existam sem quaisquer índices e chaves primárias.Os índices são os endereços onde as linhas são salvas. Para InnoDB, se não houver chave primária ou conjunto de índices exclusivos não vazios, uma chave primária de 6 bytes será gerada automaticamente (não visível para o usuário).
- O número de linhas na tabela . MyISAM salva o número total de linhas da tabela. Se
select count(*) from table; o valor será retirado diretamente. O InnoDB não salva o número total de linhas na tabela. Se você usar select count(*) from table; ele percorrerá a tabela inteira, o que consome muito dinheiro. No entanto, após adicionar a condição where, MyISAM e InnoDB manipulam isso da mesma maneira.
Quais bloqueios o MySQL possui?
Classificados pela granularidade do bloqueio , existem bloqueios em nível de linha, bloqueios em nível de tabela e bloqueios em nível de página.
- Os bloqueios em nível de linha são os bloqueios mais granulares no MySQL. Indica que apenas a linha atualmente operada está bloqueada. O bloqueio em nível de linha pode reduzir significativamente os conflitos nas operações de banco de dados. Sua granularidade de bloqueio é a menor, mas a sobrecarga de bloqueio também é a maior. Existem três tipos principais de bloqueios em nível de linha:
- Record Lock, bloqueio de registro, ou seja, bloquear apenas um registro;
- Gap Lock, gap lock, bloqueia um intervalo, mas não inclui o registro em si;
- Next-Key Lock: Uma combinação de Record Lock + Gap Lock, bloqueia um intervalo e bloqueia o próprio registro.
- O bloqueio em nível de tabela é o bloqueio com maior granularidade no MySQL, o que significa bloquear toda a tabela da operação atual. É simples de implementar, consome menos recursos e é suportado pela maioria dos mecanismos MySQL. O MyISAM e o InnoDB mais comumente usados suportam bloqueio em nível de tabela.
- Os bloqueios em nível de página são um tipo de bloqueio no MySQL cuja granularidade de bloqueio está entre os bloqueios em nível de linha e os bloqueios em nível de tabela. Os bloqueios em nível de tabela são rápidos, mas apresentam muitos conflitos. Os bloqueios em nível de linha apresentam poucos conflitos, mas são lentos. Portanto, é adotado um bloqueio de nível de página comprometido, bloqueando um grupo de registros adjacentes por vez.
Classificados por nível de bloqueio , existem bloqueios compartilhados, bloqueios exclusivos e bloqueios de intenção.
- Os bloqueios compartilhados, também conhecidos como bloqueios de leitura, são bloqueios criados por operações de leitura. Outros usuários podem ler os dados simultaneamente, mas nenhuma transação pode modificar os dados (adquirir um bloqueio exclusivo nos dados) até que todos os bloqueios compartilhados sejam liberados.
- Os bloqueios exclusivos também são chamados de bloqueios de gravação e bloqueios exclusivos.Se a transação T adicionar um bloqueio exclusivo aos dados A, outras transações não poderão adicionar nenhum tipo de bloqueio a A. As transações com bloqueios exclusivos podem ler e modificar dados.
- Os bloqueios de intenção são bloqueios em nível de tabela projetados principalmente para revelar o tipo de bloqueio que será solicitado para a próxima linha em uma transação. Dois bloqueios de tabela no InnoDB:
Bloqueio compartilhado intencional (IS): indica que a transação está se preparando para adicionar um bloqueio compartilhado à linha de dados, o que significa que antes de adicionar um bloqueio compartilhado a uma linha de dados, o bloqueio IS da tabela deve primeiro ser obtido;
Bloqueio exclusivo de intenção (IX): Semelhante ao anterior, indica que a transação está se preparando para adicionar um bloqueio exclusivo à linha de dados, indicando que a transação deve primeiro obter o bloqueio IX da tabela antes de adicionar um bloqueio exclusivo a um dado linha.
Os bloqueios de intenção são adicionados automaticamente pelo InnoDB e não requerem intervenção do usuário.
Para INSERT, UPDATE e DELETE, o InnoDB adicionará automaticamente bloqueios exclusivos aos dados envolvidos; para instruções SELECT gerais, o InnoDB não adicionará nenhum bloqueio e as transações podem adicionar explicitamente bloqueios compartilhados ou bloqueios exclusivos por meio das instruções a seguir.
Bloqueio compartilhado:SELECT … LOCK IN SHARE MODE;
Bloqueio exclusivo:SELECT … FOR UPDATE;
Princípio de implementação do MVCC?
MVCC( Multiversion concurrency control) é uma forma de reter múltiplas versões dos mesmos dados, alcançando assim o controle de simultaneidade. Ao consultar, read viewos dados da versão correspondente são encontrados através da cadeia de versões.
Função: Melhorar o desempenho de simultaneidade. Para cenários de alta simultaneidade, o MVCC é mais barato que os bloqueios em nível de linha.
O princípio de implementação do MVCC é o seguinte:
A implementação do MVCC depende da cadeia de versões, que é implementada através de três campos ocultos da tabela.
DB_TRX_ID: ID da transação atual, a sequência de tempo da transação é avaliada pelo tamanho do ID da transação.DB_ROLL_PTR: O ponteiro de reversão aponta para a versão anterior do registro da linha atual. Por meio desse ponteiro, várias versões dos dados são conectadas entre si para formar umaundo logcadeia de versões.DB_ROW_ID: Chave primária. Se a tabela de dados não tiver uma chave primária, o InnoDB irá gerar automaticamente uma chave primária.
Cada registro da tabela provavelmente se parece com isto:

Quando uma transação é usada para atualizar um registro de linha, uma cadeia de versões será gerada. O processo de execução é o seguinte:
- Bloqueie a linha com cadeado exclusivo;
- Copie o valor original da linha
undo logpara a versão antiga para reversão; - Modifique o valor da linha atual, gere uma nova versão, atualize o ID da transação e faça o ponteiro de rollback apontar para o registro da versão antiga, formando assim uma cadeia de versões.
Aqui está um exemplo para que todos entendam.
1. Os dados iniciais são os seguintes DB_ROW_IDe a soma DB_ROLL_PTRestá vazia.

2. A transação A modificou os dados da linha e alterou age-os para 12. O efeito é o seguinte:

3. Posteriormente, a transação B também modificou o registro da linha e alterou age-o para 8. O efeito é o seguinte:

4. Neste momento, o log de desfazer possui duas linhas de registros e elas são conectadas por meio do ponteiro de reversão.
A seguir, entenda o conceito de visualização de leitura.
read viewPode ser entendido como tirar uma “foto” para registrar o estado dos dados a cada momento. Ao obter dados em um determinado momento t, os dados são obtidos a partir da “foto” tirada no momento t.
read viewUma lista de transações ativas é mantida internamente, indicando as read viewtransações que ainda estão ativas no momento da geração. Esta lista vinculada contém read viewtransações que não foram confirmadas antes da criação, mas não inclui read viewtransações que foram confirmadas após a criação.
Diferentes níveis de isolamento têm tempos diferentes para criar visualizações de leitura.
-
read commited: Cada vez que o select for executado, um novo read_view será criado para garantir que as modificações enviadas por outras transações possam ser lidas.
-
Leitura repetível: Dentro de um escopo de transação, este read_view é atualizado durante a primeira seleção e não será atualizado novamente. Todas as seleções subsequentes reutilizam o read_view anterior. Isso garante que o conteúdo lido no escopo da transação seja sempre o mesmo e possa ser lido repetidamente.
Método de filtragem de registros de visualização de leitura
Premissa : DATA_TRX_IDIndica o ID da transação mais recente de cada linha de dados; up_limit_idindica a transação iniciada mais cedo no instantâneo atual; low_limit_idindica a transação iniciada mais lentamente no instantâneo atual, ou seja, a última transação.

- If
DATA_TRX_ID<up_limit_id: Significa queread viewa transação que modificou a linha de dados foi confirmada quando foi criada e o registro desta versão pode ser lido pela transação atual. - If
DATA_TRX_ID>=low_limit_id: Significa que a transação da versão atual do registro foiread viewgerada após a criação e as linhas de dados desta versão não podem ser acessadas pela transação atual. Neste momento, você precisa encontrar a versão anterior através da cadeia de versões e, em seguida, reavaliar a visibilidade dos registros desta versão para a transação atual. - se
up_limit_id<=DATA_TRX_ID<low_limit_i:- Você precisa descobrir se existe uma transação com o valor de ID na lista de transações ativas
DATA_TRX_ID. - Se existir, o registro não estará visível porque a transação na lista de transações ativas não foi confirmada. Neste momento, você precisa encontrar a versão anterior na cadeia de versões e, em seguida, reavaliar a visibilidade desta versão.
- Se não existir, significa que a transação trx_id foi confirmada e esta linha de registros está visível.
- Você precisa descobrir se existe uma transação com o valor de ID na lista de transações ativas
Resumo : InnoDB é implementado MVCCpor meio de uma cadeia de versões. A cadeia de versões salva registros históricos de versões. Ao julgar se a versão atual dos dados está visível, se não estiver visível, encontre a versão anterior na cadeia de versões e continue a julgar até que ela encontra uma versão visível.read viewread view
Leitura de instantâneo e leitura atual
Existem duas maneiras de ler registros de tabela.
-
Leitura do instantâneo: lê a versão do instantâneo. O comum
SELECTé a leitura de instantâneos. O controle de simultaneidade é feito através do mvcc sem bloqueio. -
Leitura atual: a versão mais recente é lida.
UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATEestá lendo atualmente.
No caso de leitura de snapshots, o InnoDB mvccevita a leitura fantasma por meio de mecanismos. O mecanismo mvccnão pode evitar o fenômeno de leitura fantasma que ocorre na situação de leitura atual. Como a leitura atual lê sempre os dados mais recentes, se houver outras transações inserindo dados entre as duas consultas, ocorrerão leituras fantasmas.
Aqui está um exemplo para ilustrar:
1. Em primeiro lugar, a tabela do usuário possui apenas dois registros, como segue:

2. A transação a e a transação b abrem transações ao mesmo tempo start transaction;
3. A transação A insere dados e depois os envia;
insert into user(user_name, user_password, user_mail, user_state) values('tyson', 'a', 'a', 0);
4. A transação b executa uma atualização de toda a tabela;
update user set user_name = 'a';
5. A transação b então executa a consulta e encontra os dados inseridos na transação a. (O lado esquerdo da figura abaixo é a transação b, e o lado direito é a transação a. Antes do início da transação, havia apenas dois registros. Após a transação a inserir um dado, a transação b consultou três dados)
[Falha na transferência da imagem do link externo. O site de origem pode ter um mecanismo anti-leeching. Recomenda-se salvar a imagem e carregá-la diretamente (img-c6OMxuPD-1691456619399) (http://img.topjavaer.cn/img/ leitura fantasma 1.png)]
O acima é o fenômeno da leitura fantasma que ocorre na leitura atual.
Então, como o MySQL evita leituras fantasmas?
- No caso de leituras de snapshots, o MySQL
mvccevita leituras fantasmas. - Na situação de leitura atual, o MySQL
next-keyevita leituras fantasmas (implementadas adicionando bloqueios de linha e bloqueios de lacuna).
next-key consiste em duas partes: bloqueio de linha e bloqueio de espaço. Os bloqueios de linha são bloqueios adicionados aos índices e os bloqueios de lacuna são adicionados entre os índices.
SerializableO nível de isolamento também pode evitar leituras fantasmas, que bloquearão toda a tabela.A simultaneidade é extremamente baixa e geralmente não é usada.
Bloqueios compartilhados e bloqueios exclusivos
O bloqueio de leitura do SELECT é dividido principalmente em dois métodos: bloqueio compartilhado e bloqueio exclusivo.
select * from table where id<6 lock in share mode;--共享锁
select * from table where id<6 for update;--排他锁
A principal diferença entre esses dois métodos é que LOCK IN SHARE MODE é fácil causar deadlock quando várias transações atualizam o mesmo formulário ao mesmo tempo.
O pré-requisito para solicitar um bloqueio exclusivo é que nenhum thread use um bloqueio exclusivo ou compartilhado para quaisquer dados de linha no conjunto de resultados, caso contrário, o aplicativo será bloqueado. Ao realizar uma operação de transação, o MySQL adicionará um bloqueio exclusivo a cada linha de dados no conjunto de resultados da consulta.Alterações ou exclusões desses dados por outros threads serão bloqueadas (apenas operações de leitura) até que a transação da instrução seja executada pelo declaração ou commitdeclaração rollback... até o fim.
SELECT... FOR UPDATEPrecauções para uso:
for updateAplica-se apenas ao innodb e deve estar dentro do escopo da transação para ter efeito.- Consulta baseada na chave primária. Se a condição da consulta for
likeou não igual, o campo da chave primária gerará um bloqueio de tabela . - Consultas baseadas em campos não indexados gerarão bloqueios de tabela .
log bin/redo log/desfazer log
Os logs do MySQL incluem principalmente logs de consulta, logs de consulta lenta, logs de transações, logs de erros, logs binários, etc. Os mais importantes são bin log(log binário) e redo log(redo log) e undo log(log de reversão).
registro de lixo
bin logÉ um arquivo no nível do banco de dados MySQL. Ele registra todas as operações que modificam o banco de dados MySQL. Ele não registra instruções select e show. Ele é usado principalmente para restaurar e sincronizar o banco de dados.
refazer registro
redo logÉ o nível do mecanismo innodb e é usado para registrar o log de transações do mecanismo de armazenamento innodb.Ele será registrado independentemente de a transação ser enviada para recuperação de dados. Quando ocorre uma falha no banco de dados, o mecanismo de armazenamento innoDB usará redo loga recuperação até o momento anterior à falha para garantir a integridade dos dados. Defina o parâmetro innodb_flush_log_at_tx_commitcomo 1 e o commit será redo loggravado no disco de forma síncrona.
desfazer registro
Além da gravação redo log, quando os dados são modificados undo log, eles também serão gravados undo logpara operações de recuperação de dados.Ele retém o conteúdo antes da modificação do registro. undo logA reversão de transações pode ser alcançada e o MVCC pode ser implementado com base no retrocesso paraundo log uma versão específica dos dados .
Qual é a diferença entre log bin e log de redo?
bin logTodos os registros de log serão registrados, incluindo logs de mecanismos de armazenamento como InnoDB e MyISAM;redo logapenas os logs de transações do próprio innoDB serão registrados.bin logEle só é gravado no disco antes da transação ser confirmada, e uma transação é gravada apenas uma vez; enquanto a transação estiver em andamento, haveráredo loggravações contínuas no disco.bin logÉ um log lógico, que registra a lógica original da instrução SQL;redo logé um log físico, que registra quais modificações foram feitas em uma determinada página de dados.
Conte-me sobre a arquitetura MySQL?
O MySQL é dividido principalmente em camada de servidor e camada de mecanismo de armazenamento:
- Camada de servidor : inclui principalmente conectores, caches de consulta, analisadores, otimizadores, executores, etc. Todas as funções do mecanismo de armazenamento cruzado são implementadas nesta camada, como procedimentos armazenados, gatilhos, visualizações, funções, etc., e há também um geral O módulo de log do módulo de log do binglog.
- Mecanismo de armazenamento : principal responsável pelo armazenamento e leitura de dados. A camada do servidor se comunica com o mecanismo de armazenamento por meio da API.
Componentes básicos da camada de servidor
- Conector: Quando o cliente se conecta ao MySQL, a camada do servidor realizará autenticação de identidade e verificação de permissão.
- Cache de consulta: Ao executar uma instrução de consulta, o cache será consultado primeiro para verificar se o sql foi executado. Se o sql estiver armazenado em cache, ele será retornado diretamente ao cliente. Se não houver acerto, as operações subsequentes serão executadas .
- Analisador: Se o cache não for atingido, a instrução SQL passará pelo analisador, que é dividido principalmente em duas etapas, análise lexical e análise de sintaxe.Primeiro, veja o que a instrução SQL faz e, em seguida, verifique se a sintaxe do SQL afirmação está correta.
- Otimizador: O otimizador otimiza a consulta, incluindo reescrever a consulta, determinar a ordem de leitura e escrita da tabela, selecionar índices apropriados, etc., e gerar um plano de execução.
- Executor: Primeiramente, antes da execução, verificará se o usuário possui permissão. Caso não haja permissão, uma mensagem de erro será retornada. Se houver permissão, a interface do mecanismo será chamada de acordo com o plano de execução e o resultado será devolvida.
Subbanco de dados e subtabela
Quando o volume de dados de uma única tabela atinge 1000 W ou 100 G, a otimização de índices, a adição de bancos de dados escravos, etc., podem não ter um efeito significativo na melhoria do desempenho do banco de dados. Neste momento, é necessário considerar a divisão. O objetivo da segmentação é reduzir a carga no banco de dados e diminuir o tempo de consulta.
A segmentação de dados pode ser dividida em duas formas: particionamento vertical e particionamento horizontal.
divisão vertical
O particionamento vertical do banco de dados é baseado em negócios. Por exemplo, em cenários de compras, as tabelas que envolvem produtos, pedidos e usuários no banco de dados podem ser divididas em um banco de dados, respectivamente, para melhorar o desempenho, reduzindo o tamanho de um único banco de dados. Da mesma forma, o caso de dividir tabelas é dividir uma tabela grande em uma subtabela com base em funções de negócios, como informações básicas do produto e descrição do produto.As informações básicas do produto geralmente são exibidas na lista de produtos, e a descrição do produto está em a página de detalhes do produto. O produto pode ser Informações básicas e a descrição do produto são divididas em duas tabelas.
[Falha na transferência da imagem do link externo. O site de origem pode ter um mecanismo anti-leeching. Recomenda-se salvar a imagem e carregá-la diretamente (img-cSyfknhd-1691456619400) (http://img.topjavaer.cn/img/ divisão vertical.png)]
Vantagens : os registros de linha ficam menores, as páginas de dados podem armazenar mais registros e os tempos de E/S são reduzidos durante as consultas.
Desvantagens :
- A chave primária é redundante e as colunas redundantes precisam ser gerenciadas;
- Isso causará a operação JOIN da conexão da tabela, que pode ser executada no servidor de negócios para reduzir a pressão do banco de dados;
- Ainda existe o problema do volume excessivo de dados em uma única tabela.
Divisão horizontal
O particionamento horizontal consiste em dividir os dados de acordo com certas regras, como tempo ou valores de sequência de identificação. Por exemplo, divida bancos de dados diferentes com base no ano. Cada banco de dados possui a mesma estrutura, mas os dados são divididos para melhorar o desempenho.
[Falha na transferência da imagem do link externo. O site de origem pode ter um mecanismo anti-leeching. Recomenda-se salvar a imagem e carregá-la diretamente (img-Q97IJSOD-1691456619401) (http://img.topjavaer.cn/img/ divisão horizontal.png)]
Vantagens : A quantidade de dados em um único banco de dados (tabela) é reduzida e o desempenho é melhorado; as tabelas divididas têm a mesma estrutura e menos alterações de programa.
Desvantagens :
- Fragmentar a consistência da transação é difícil de resolver
- Baixo desempenho entre nós
joine lógica complexa - A fragmentação de dados precisa ser migrada durante a expansão
O que é uma tabela de partição?
Particionar é dividir os dados de uma tabela em N blocos. Uma tabela particionada é uma tabela lógica independente, mas a camada subjacente é composta por várias subtabelas físicas.
Quando os dados da condição de consulta são distribuídos em uma determinada partição, o mecanismo de consulta consultará apenas uma determinada partição em vez de percorrer a tabela inteira. No nível de gerenciamento, se você precisar excluir dados de uma determinada partição, basta excluir a partição correspondente.
As partições geralmente são colocadas em uma única máquina e o particionamento por intervalo de tempo é mais comumente usado para facilitar o arquivamento. Acontece que o subbanco de dados e a tabela precisam ser implementados em código, e o particionamento é implementado internamente no MySQL. Subbanco de dados, subtabela e partição não entram em conflito e podem ser usados juntos.
Tipo de tabela de partição
O particionamento de intervalo é baseado no particionamento de intervalo. Por exemplo, particionar por intervalo de tempo
CREATE TABLE test_range_partition(
id INT auto_increment,
createdate DATETIME,
primary key (id,createdate)
)
PARTITION BY RANGE (TO_DAYS(createdate) ) (
PARTITION p201801 VALUES LESS THAN ( TO_DAYS('20180201') ),
PARTITION p201802 VALUES LESS THAN ( TO_DAYS('20180301') ),
PARTITION p201803 VALUES LESS THAN ( TO_DAYS('20180401') ),
PARTITION p201804 VALUES LESS THAN ( TO_DAYS('20180501') ),
PARTITION p201805 VALUES LESS THAN ( TO_DAYS('20180601') ),
PARTITION p201806 VALUES LESS THAN ( TO_DAYS('20180701') ),
PARTITION p201807 VALUES LESS THAN ( TO_DAYS('20180801') ),
PARTITION p201808 VALUES LESS THAN ( TO_DAYS('20180901') ),
PARTITION p201809 VALUES LESS THAN ( TO_DAYS('20181001') ),
PARTITION p201810 VALUES LESS THAN ( TO_DAYS('20181101') ),
PARTITION p201811 VALUES LESS THAN ( TO_DAYS('20181201') ),
PARTITION p201812 VALUES LESS THAN ( TO_DAYS('20190101') )
);
/var/lib/mysql/data/Os arquivos de dados correspondentes podem ser encontrados. Cada tabela de partição possui um arquivo de tabela nomeado usando # para separá-lo :
-rw-r----- 1 MySQL MySQL 65 Mar 14 21:47 db.opt
-rw-r----- 1 MySQL MySQL 8598 Mar 14 21:50 test_range_partition.frm
-rw-r----- 1 MySQL MySQL 98304 Mar 14 21:50 test_range_partition#P#p201801.ibd
-rw-r----- 1 MySQL MySQL 98304 Mar 14 21:50 test_range_partition#P#p201802.ibd
-rw-r----- 1 MySQL MySQL 98304 Mar 14 21:50 test_range_partition#P#p201803.ibd
...
partição de lista
O particionamento de lista é semelhante ao particionamento de intervalo. A principal diferença é que lista é uma coleção de listas de valores enumerados e intervalo é uma coleção de valores de intervalo contínuo. Para particionamento de lista, o campo de particionamento deve ser conhecido. Se o campo inserido não estiver no valor de enumeração durante o particionamento, ele não será inserido.
create table test_list_partiotion
(
id int auto_increment,
data_type tinyint,
primary key(id,data_type)
)partition by list(data_type)
(
partition p0 values in (0,1,2,3,4,5,6),
partition p1 values in (7,8,9,10,11,12),
partition p2 values in (13,14,15,16,17)
);
partição hash
Os dados podem ser distribuídos uniformemente em partições predefinidas.
create table test_hash_partiotion
(
id int auto_increment,
create_date datetime,
primary key(id,create_date)
)partition by hash(year(create_date)) partitions 10;
Problema de particionamento?
- Abrir e bloquear todas as tabelas subjacentes pode ser caro. Quando uma consulta acessa uma tabela particionada, o MySQL precisa abrir e bloquear todas as tabelas subjacentes. Esta operação ocorre antes da filtragem de partição, portanto, a filtragem de partição não pode ser usada para reduzir essa sobrecarga, o que afetará a velocidade da consulta. Essa sobrecarga pode ser reduzida por meio de operações em lote, como inserção e
LOAD DATA INFILEexclusão em lote de diversas linhas de dados por vez. - Manter partições pode ser caro. Por exemplo, para reorganizar uma partição, primeiro será criada uma partição temporária, depois os dados serão copiados para ela e, finalmente, a partição original será excluída.
- Todas as partições devem usar o mesmo mecanismo de armazenamento.
Processo de execução da instrução de consulta?
O processo de execução da instrução de consulta é o seguinte: verificação de permissão, cache de consulta, analisador, otimizador, verificação de permissão, executor e mecanismo.
Por exemplo, a instrução de consulta é a seguinte:
select * from user where id > 1 and name = '大彬';
- Primeiro verifique as permissões. Se não houver permissão, um erro será retornado;
- Antes do MySQL 8.0, o cache seria consultado. Se o cache acertar, ele será retornado diretamente. Caso contrário, a próxima etapa será executada.
- Análise lexical e análise sintática. Extraia o nome da tabela e as condições de consulta e verifique se há algum erro de sintaxe;
- Dois planos de execução, verifique primeiro
id > 1ouname = '大彬'o otimizador escolhe aquele com melhor eficiência de execução com base em seu próprio algoritmo de otimização; - Verifique as permissões. Se você tiver permissão, chame a interface do mecanismo de banco de dados e retorne os resultados da execução do mecanismo.
Atualizar processo de execução de instrução?
O processo de execução da instrução de atualização é o seguinte: analisador, verificação de permissão, executor, mecanismo, redo log( preparestatus), binlog, redo log( commitstatus)
Por exemplo, a instrução de atualização é a seguinte:
update user set name = '大彬' where id = 1;
- Primeiro consulte o registro com id 1. Se houver cache, o cache será usado.
- Obtenha os resultados da consulta, atualize o nome para Dabin e, em seguida, chame a interface do mecanismo para gravar os dados atualizados. O mecanismo innodb salva os dados na memória e os registra ao mesmo tempo. Nesse momento, ele entra
redo lognoredo logestadoprepare. - O executor registra a notificação após recebê-la
binlog, então chama a interface do mecanismo e a enviaredo logcomocommitstatus. - atualização completa.
Por que você não o envia diretamente após a gravação redo log, mas insere prepareo estado primeiro?
Suponha que você escreva redo loge envie diretamente primeiro e depois escreva . Depois de binlogescrever redo log, a máquina desliga e binlogo log não é gravado. Depois que a máquina for reiniciada, a máquina restaurará os dados, mas os dados não serão registrados redo logneste momento . O O backup da máquina será binlogfeito mais tarde, esse dado será perdido e, ao mesmo tempo, a sincronização mestre-escravo também perderá esse dado.
Qual é a diferença entre existir e dentro?
existsUsado para filtrar registros de aparência. existsA tabela externa será percorrida e cada linha da tabela de consulta externa será substituída na consulta interna para julgamento. Quando existsa instrução condicional pode retornar linhas de registro, a condição é verdadeira e o registro atual da tabela é retornado. Por outro lado, se existsa instrução condicional interna não puder retornar linhas de registro e a condição for falsa, o registro atual na tabela será descartado.
select a.* from A awhere exists(select 1 from B b where a.id=b.id)
inO método consiste primeiro em descobrir as seguintes instruções e colocá-las na tabela temporária, depois percorrer a tabela temporária e substituir cada linha da tabela temporária na consulta externa para pesquisar.
select * from Awhere id in(select id from B)
Quando a tabela da subconsulta é relativamente grande , usá-la existspode efetivamente reduzir o número total de loops para melhorar a velocidade; quando a tabela da consulta externa é relativamente grande , usá-la inpode efetivamente reduzir a travessia do loop da tabela de consulta externa para melhorar a velocidade.
Qual é a diferença entre int(10) e char(10) no MySQL?
O 10 em int(10) representa o comprimento dos dados exibidos, enquanto char(10) representa o comprimento dos dados armazenados.
Qual é a diferença entre truncar, excluir e descartar?
Mesmo ponto:
-
truncatee semwherecláusulasdeleteedropexcluirá os dados da tabela. -
drop,truncatesão todasDDLinstruções (linguagem de definição de dados), que serão enviadas automaticamente após a execução.
diferença:
- truncar e excluir apenas excluir dados sem excluir a estrutura da tabela; a instrução drop excluirá as restrições, gatilhos e índices dos quais a estrutura da tabela depende;
- De modo geral, velocidade de execução: drop > truncate > delete.
Qual é a diferença entre ter e onde?
- Os objetos sobre os quais eles atuam são diferentes.
whereA cláusula atua em tabelas e visualizações ehavingem grupos. whereFiltre antes do agrupamento de dados ehavingfiltre após o agrupamento de dados.
Por que precisamos fazer a sincronização mestre-escravo?
- A separação entre leitura e gravação permite que o banco de dados suporte maior simultaneidade.
- Os dados em tempo real são gerados no servidor mestre e analisados no servidor escravo, melhorando assim o desempenho do servidor mestre.
- Backup de dados para garantir a segurança dos dados.
O que é sincronização mestre-escravo MySQL?
A sincronização mestre-escravo permite que os dados sejam copiados de um servidor de banco de dados para outros servidores. Ao copiar dados, um servidor atua como servidor mestre ( ) mastere os servidores restantes atuam como servidores escravos ( slave).
Como a replicação é executada de forma assíncrona, o servidor escravo não precisa estar conectado ao servidor mestre o tempo todo. O servidor escravo pode até mesmo ser conectado ao servidor mestre de forma intermitente por meio de discagem. Através do arquivo de configuração, você pode especificar a cópia de todos os bancos de dados, um determinado banco de dados ou até mesmo uma determinada tabela em um determinado banco de dados.
O que são bloqueio otimista e bloqueio pessimista?
O controle de simultaneidade no banco de dados garante que o isolamento e a unidade das transações e a unidade do banco de dados não sejam destruídos quando múltiplas transações acessam os mesmos dados no banco de dados ao mesmo tempo. O bloqueio otimista e o bloqueio pessimista são os principais meios técnicos utilizados para controle de concorrência.
- Bloqueio pessimista: Supondo que ocorrerá um conflito de simultaneidade, os dados operados serão bloqueados. O bloqueio não será liberado até que a transação seja enviada e outras transações possam modificá-lo. Método de implementação: Use o mecanismo de bloqueio no banco de dados.
- Bloqueio otimista: suponha que nenhum conflito de simultaneidade ocorrerá e apenas verifique se os dados foram modificados ao enviar a operação. Adicione um campo à tabela e verifique se ele é igual ao valor original
versionantes de enviar a modificação. Se for igual, significa que os dados não foram modificados e podem ser atualizados. Caso contrário, os dados são dados sujos e não podem ser Atualizada. Método de implementação: O bloqueio otimista geralmente é implementado usando um mecanismo ou algoritmo de número de versão.versionversionCAS
Você já usou lista de processos?
show processlistOu show full processlistvocê pode verificar se o MySQL está atualmente sob pressão, em execução SQLe se SQLestá sendo executado lentamente. Os parâmetros de retorno são os seguintes:
- id : ID do thread, pode ser usado para
kill idencerrar um thread - banco de dados : nome do banco de dados
- usuário : usuário do banco de dados
- host : IP da instância do banco de dados
- comando : o comando atualmente executado, como
Sleep,Query,Connectetc. - tempo : tempo de consumo, unidade de segundos
- estado : estado de execução, incluindo principalmente os seguintes estados:
- Sleep, o thread está aguardando o cliente enviar uma nova solicitação
- Bloqueado, o thread está aguardando o bloqueio
- Envio de dados, processamento
SELECTdos registros da consulta e envio dos resultados ao cliente ao mesmo tempo - Kill, executando
killa instrução, mata o thread especificado - Conecte, um nó escravo está conectado ao nó mestre
- Sair, o tópico está saindo
- Classificando por grupo,
GROUP BYclassificando por - Classificando por ordem,
ORDER BYclassificando por
- info
SQL: instrução sendo executada
O limite de consulta MySQL 1000,10 é tão rápido quanto o limite 10?
Dois métodos de consulta. Corresponde limit offset, sizea duas formas de e limit size.
Na verdade limit size, é equivalente a limit 0, size. Ou seja, comece a obter dados de tamanho a partir de 0.
Em outras palavras, a diferença entre os dois métodos é se o deslocamento é 0.
Vejamos primeiro a lógica de execução interna do limit sql.
O MySQL é dividido internamente em camada de servidor e camada de mecanismo de armazenamento . Em circunstâncias normais, o mecanismo de armazenamento usa innodb.
Existem muitos módulos na camada do servidor, o que precisa de atenção é que o executor é o componente utilizado para lidar com o mecanismo de armazenamento.
O executor pode recuperar linhas de dados chamando a interface fornecida pelo mecanismo de armazenamento.Quando os dados atenderem totalmente aos requisitos (como atender a outras condições where), eles serão colocados no conjunto de resultados e finalmente retornados ao cliente que chama mysql .
Tomemos como exemplo o processo de execução limite do índice de chave primária:
Execução select * from xxx order by id limit 0, 10;, select é seguido por um asterisco , o que significa que todas as informações dos campos dos dados da linha são obrigatórias .
A camada do servidor chamará a interface do innodb, obterá os dados completos da linha de 0 a 10 no índice de chave primária em innodb , os retornará para a camada do servidor, por sua vez, os colocará no conjunto de resultados da camada do servidor e os retornará para o cliente.
Aumente o deslocamento, por exemplo, a execução é:select * from xxx order by id limit 500000, 10;
A camada do servidor chamará a interface do innodb. Como esse deslocamento de tempo = 500000, os dados completos da linha de 0 a (500000 + 10) serão obtidos do índice de chave primária no innodb. Após retornar à camada do servidor , será descartados um por um de acordo com o valor do deslocamento e, finalmente, apenas os itens do último tamanho , ou seja, 10 dados, são deixados no conjunto de resultados da camada do servidor e retornados ao cliente.
Pode-se observar que quando o deslocamento é diferente de 0, a camada do servidor obterá muitos dados inúteis da camada do mecanismo , e obter esses dados inúteis é demorado.
Portanto, o limite 1000,10 na consulta mysql será mais lento que o limite 10. A razão é que o limite 1.000,10 retirará 1.000 + 10 dados e descartará os primeiros 1.000 dados, o que consome mais tempo.
Quantos dados podem ser armazenados em uma árvore B+ com altura 3?
O mecanismo de armazenamento InnoDB possui sua própria unidade de armazenamento mínima - página.
O comando para consultar o tamanho da página do InnoDB é o seguinte:
mysql> show global status like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
Pode-se observar que o tamanho de página padrão do innodb é 16384B = 16384/1024 = 16kb.
No MySQL, é mais apropriado definir o tamanho de um nó na árvore B+ para uma página ou um múltiplo de uma página. Porque se o tamanho de um nó for <1 página, então ao ler esse nó, uma página é realmente lida, o que causa um desperdício de recursos.
Os nós não- folha na árvore B+ armazenam chaves + ponteiros ; os nós folha armazenam linhas de dados .
Para nós folha, se o tamanho dos dados de uma linha for 1k, então 16 dados podem ser armazenados em uma página.
Para nós não-folha, se a chave usar bigint, ela terá 8 bytes e o ponteiro terá 6 bytes no MySQL. São 14 bytes no total, então 16k podem armazenar 16 * 1024/14 = 1170 ponteiros de índice.
Portanto, pode-se calcular que para uma árvore B + com altura 2, o nó raiz armazena o nó ponteiro do índice, então tem 1170 nós folha para armazenar dados, e cada nó folha pode armazenar 16 dados, um total de 1170 x 16 = 18.720 dados. Para uma árvore B+ com altura 3, ela pode armazenar 1170 x 1170 x 16 = 21902400 dados ( mais de 20 milhões de dados ). Ou seja, para mais de 20 milhões de dados, precisamos apenas de um B+ árvore com altura 3.
Portanto, no InnoDB, quando a altura da árvore B+ é geralmente de 3 níveis, ela pode atender às necessidades de dezenas de milhões de armazenamento de dados.
Como otimizar a paginação profunda?
Ou considere o SQL acima como vazio:select * from xxx order by id limit 500000, 10;
Método um :
Como pode ser visto na análise acima, quando o deslocamento é muito grande, a camada do servidor obterá muitos dados inúteis da camada do mecanismo.Quando a seleção é seguida do número *, as informações completas da linha precisam ser copiadas. Em comparação com a cópia dos dados completos , copiar apenas um ou dois campos de coluna nos dados da linha consome mais tempo.
Como os dados de deslocamento anteriores não são necessários no final, não há necessidade de copiar os campos completos, portanto a instrução sql pode ser modificada para:
select * from xxx where id >=(select id from xxx order by id limit 500000, 1) order by id limit 10;
Primeiro execute a subconsulta select id from xxx by id limit 500000, 1. Esta operação irá realmente obter 500000+1pedaços de dados do índice de chave primária no innodb. Em seguida, a camada do servidor descartará os primeiros 500.000 pedaços e reterá apenas o ID do último dado.
Mas a diferença é que no processo de retorno à camada do servidor, apenas a coluna id da linha de dados será copiada, mas nem todas as colunas da linha de dados.Quando a quantidade de dados é grande, o consumo de tempo desta parte é bastante óbvio. .
Depois de obter o id acima, assumindo que esse id é exatamente igual a 500.000, o sql se torna
select * from xxx where id >=500000 order by id limit 10;
Dessa forma, o innodb percorre o índice de chave primária novamente, localiza rapidamente os dados da linha com id=500000 na árvore B+, a complexidade de tempo é lg(n) e, em seguida, busca 10 dados de trás para frente.
Método dois:
Classifique todos os dados de acordo com a chave primária de ID , recupere-os em lotes e use o ID máximo do lote atual como a próxima condição de filtragem para consulta.
select * from xxx where id > start_id order by id limit 10;
Através do índice de chave primária, a posição de start_id é localizada a cada vez e, em seguida, 10 dados são percorridos.Desta forma, não importa o tamanho dos dados, o desempenho da consulta é relativamente estável.
Como otimizar a consulta de tabelas grandes se ela for lenta?
Uma determinada tabela contém quase 10 milhões de dados e a consulta é lenta. Como otimizá-la?
Quando o número de registros em uma única tabela MySQL é muito grande, o desempenho do banco de dados diminuirá significativamente.Algumas medidas de otimização comuns são as seguintes:
- Indexar corretamente. Crie um índice no campo apropriado, por exemplo, crie um índice nas colunas envolvidas nos comandos WHERE e ORDER BY. Você pode usar EXPLAIN para verificar se um índice ou uma varredura completa da tabela é usado.
- Otimização de índice, otimização de SQL. Princípio de correspondência mais à esquerda, etc., consulte: https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E8%A6%86%E7 %9B %96%E7%B4%A2%E5%BC%95
- Crie partições. Estabeleça particionamento horizontal para campos-chave,como campos de tempo.Se as condições de consulta forem frequentemente consultadas através de intervalos de tempo,isto pode melhorar muito o desempenho.
- Aproveite o cache. Use Redis e outros dados de ponto de acesso de cache para melhorar a eficiência da consulta
- Limite o escopo dos dados. Por exemplo: quando os usuários consultam informações históricas, eles podem controlá-las dentro do intervalo de tempo de um mês
- Separação entre leitura e escrita. Esquema clássico de divisão de banco de dados, o banco de dados mestre é responsável pela gravação e o banco de dados escravo é responsável pela leitura
- A otimização é realizada por meio de subbanco de dados e subtabela, incluindo principalmente divisão vertical e divisão horizontal.
- Indexar corretamente. Indexar nos campos apropriados, como indexar nas colunas envolvidas nos comandos WHERE e ORDERBY
- Heterogeneidade de dados para es
- Separação de dados quentes e frios. Os dados que não eram comumente usados há alguns meses são colocados no armazenamento frio e os dados mais recentes são colocados no armazenamento quente.
- Atualize o tipo de banco de dados para um banco de dados compatível com MySQL (OceanBase, tidb)
Qual é o tamanho de uma única tabela no MySQL para dividir bancos de dados e tabelas?
Existem atualmente duas teorias principais:
- Se o volume de dados de uma única tabela MySQL for superior a 20 milhões de linhas, o desempenho será significativamente reduzido. Considere dividir bancos de dados e tabelas.
- O "Manual de Desenvolvimento Java" do Alibaba afirma que a fragmentação de banco de dados e tabelas só é recomendada quando o número de linhas em uma única tabela excede 5 milhões ou a capacidade de uma única tabela excede 2 GB.
Na verdade, esse valor não tem nada a ver com o número real de registros, mas está relacionado à configuração do MySQL e ao hardware da máquina. Porque o MySQL carrega o índice da tabela na memória para melhorar o desempenho. Quando o tamanho do buffer do InnoDB for suficiente, ele poderá ser totalmente carregado na memória e não haverá problemas com a consulta. No entanto, quando um banco de dados de tabela única atinge um limite superior de uma certa magnitude, a memória não consegue armazenar seu índice, fazendo com que consultas SQL subsequentes gerem E/S de disco, resultando em degradação do desempenho. Claro, isso também está relacionado ao design da estrutura específica da tabela, e o problema final é a limitação de memória.
Portanto, para subbancos de dados e tabelas, é necessário combinar as necessidades reais e não projetar demais. Não usamos o design de subbancos de dados e subtabelas no início do projeto. Em vez disso, à medida que o negócio cresce e é impossível continuar a otimizar, considere sub-bancos de dados. Melhore o desempenho do sistema com subtabelas. A este respeito, o "Manual de Desenvolvimento Java" do Alibaba acrescenta: Se não se espera que o volume de dados atinja este nível em três anos, não divida o banco de dados em tabelas ao criar a tabela.
Já o tamanho de uma única tabela MySQL a ser dividida em bancos de dados e tabelas deve ser avaliado com base nos recursos da máquina.
Vamos falar sobre as diferenças entre count(1), count(*) e count(field name)
Bem, vamos primeiro falar sobre a diferença entre count(1) e count(field name).
A principal diferença entre os dois é
- count(1) contará todos os registros da tabela, incluindo registros com campos nulos.
- count(nome do campo) contará o número de vezes que este campo aparece na tabela, ignorando o caso em que o campo é nulo. Ou seja, registros com campos nulos não são contabilizados.
A seguir, vamos dar uma olhada nas diferenças entre os três.
Em termos de efeito de execução:
- count(*) inclui todas as colunas, o que equivale ao número de linhas. Ao calcular os resultados, os valores NULL da coluna não serão ignorados.
- count(1) inclui ignorar todas as colunas, usando 1 para representar linhas de código. Ao contar os resultados, os valores das colunas que são NULL não serão ignorados.
- contagem (nome do campo) inclui apenas o nome da coluna. Ao contar os resultados, a contagem de valores de coluna vazios (o vazio aqui não significa apenas uma string vazia ou 0, mas significa nulo) será ignorada. Ou seja, um determinado valor de campo for NULL, nenhuma estatística será coletada .
Em termos de eficiência de execução:
- O nome da coluna é a chave primária e count(field name) será mais rápido que count(1)
- O nome da coluna não é a chave primária, count(1) será mais rápido que count(column name)
- Se a tabela tiver múltiplas colunas e nenhuma chave primária, count(1) tem melhor desempenho que count(*)
- Se houver uma chave primária, a eficiência de execução da contagem selecionada (chave primária) é ótima
- Se a tabela tiver apenas um campo, select count(*) é o ideal.
Qual é a diferença entre DATETIME e TIMESTAMP no MySQL?
Bem, ambos TIMESTAMPe DATETIMEpodem ser usados para armazenar tempo.Eles têm as seguintes diferenças principais:
1. Faixa de representação
- DATETIME: 1000-01-01 00:00:00.000000 a 9999-12-31 23:59:59.999999
- TIMESTAMP: '1970-01-01 00:00:01.000000' UTC e '2038-01-09 03:14:07.999999' UTC
TIMESTAMPO intervalo de tempo suportado é relativamente DATATIMEpequeno e pode ser facilmente excedido.
2. Ocupação do espaço
- TIMESTAMP: 4 bytes
- DATETIME: Antes do MySQL 5.6.4 ocupa 8 bytes e nas versões subsequentes ocupa 5 bytes.
3.Se o tempo de depósito será convertido automaticamente?
TIMESTAMPPor padrão, ao inserir ou atualizar dados, TIMESTAMPa coluna será preenchida/atualizada automaticamente com a hora atual ( CURRENT_TIMESTAMP). DATETIMEEle não fará nenhuma conversão, nem detectará o fuso horário. Ele armazenará todos os dados que você fornecer.
4. TIMESTAMPÉ mais afetado pelo fuso horário, pela versão MYSQL e pelo SQL MODE do servidor. Como TIMESTAMParmazena carimbos de data/hora, os horários obtidos em diferentes fusos horários são inconsistentes.
5. Se NULL for armazenado, os valores reais armazenados dos dois serão diferentes.
- TIMESTAMP: A hora atual now() será armazenada automaticamente.
- DATETIME: A hora atual não será armazenada automaticamente, mas o valor NULL será armazenado diretamente.
Diga-me por que não é recomendado o uso de chaves estrangeiras?
Uma chave estrangeira é uma restrição. A existência desta restrição garantirá que a relação entre os dados entre as tabelas seja sempre completa. A existência de chaves estrangeiras não é totalmente isenta de vantagens.
As chaves estrangeiras podem garantir a integridade e consistência dos dados, e as operações em cascata são convenientes. Além disso, o uso de chaves estrangeiras pode confiar o julgamento da integridade dos dados ao banco de dados, reduzindo a quantidade de código do programa.
Embora as chaves estrangeiras possam garantir a integridade dos dados, elas podem trazer muitos defeitos ao sistema.
1. Problemas de simultaneidade. Ao usar chaves estrangeiras, toda vez que você modifica os dados, é necessário verificar os dados em outra tabela e adquirir bloqueios adicionais. Se você estiver em um cenário de transações de alta simultaneidade e alto tráfego, é mais provável que o uso de chaves estrangeiras cause conflito.
2. Problemas de escalabilidade. Por exemplo, ao MySQLmigrar para um novo banco de dados Oracle, as chaves estrangeiras dependem das características do próprio banco de dados, portanto a migração pode ser inconveniente.
3. Não é propício para subbancos de dados e subtabelas. No caso de divisão e fragmentação horizontal, as chaves estrangeiras não podem ter efeito. Colocar a manutenção dos relacionamentos entre os dados no aplicativo pode evitar muitos problemas para futuras subdivisões de bancos de dados e tabelas.
Quais são os benefícios de usar chaves primárias com incremento automático?
A chave primária com aumento automático permite que o índice da chave primária mantenha a ordem de inserção incremental tanto quanto possível, evitando divisões de página, para que o índice seja mais compacto e a eficiência seja maior na consulta.
Por que o valor crescente do InnoDB não pode ser reciclado?
Principalmente para melhorar a eficiência e o paralelismo na inserção de dados.
Suponha que haja duas transações executadas em paralelo. Ao solicitar valor de incremento automático, para evitar que as duas transações solicitem o mesmo ID de incremento automático, os bloqueios devem ser bloqueados e aplicados sequencialmente.
Suponha que a transação A se aplique a id = 2 e a transação B se aplique a id = 3. Então, o valor de incremento automático da tabela t é 4 neste momento e a execução continua a partir de então.
A transação B foi confirmada corretamente, mas a transação A teve um conflito de chave exclusivo.
Se a transação A tiver permissão para reverter o ID de incremento automático, ou seja, alterar o valor de incremento automático atual da tabela t de volta para 2, então haverá uma situação como esta: já existe uma linha com id=3 em a tabela e o valor atual do ID de incremento automático é 2.
Em seguida, outras transações que continuam a ser executadas serão aplicadas ao id=2 e, em seguida, ao id=3. Neste momento, um erro de instrução de inserção "conflito de chave primária" aparecerá.
Para resolver este conflito de chave primária, existem dois métodos:
- Antes de cada solicitação de um ID, primeiro determine se o ID já existe na tabela. Se existir, ignore este ID. No entanto, este método é caro. Porque originalmente solicitar um ID era uma operação rápida, mas agora temos que ir para a árvore do índice de chave primária para determinar se o ID existe.
- Para expandir o intervalo de bloqueio do ID de incremento automático, você deve aguardar até que uma transação seja concluída e enviada antes que a próxima transação possa solicitar o ID de incremento automático. O problema com este método é que a granularidade do bloqueio é muito grande e a capacidade de simultaneidade do sistema é bastante reduzida.
Pode-se observar que ambos os métodos causarão problemas de desempenho.
Portanto, o InnoDB desistiu do projeto de "permitir que o ID de incremento automático seja revertido", e o ID de incremento automático não será revertido se a instrução falhar na execução.
Onde a chave primária de incremento automático é armazenada?
Diferentes mecanismos têm diferentes estratégias de armazenamento para valores incrementados automaticamente:
- O valor de incremento automático do mecanismo MyISAM é salvo no arquivo de dados.
- Antes do MySQL 8.0, o valor de incremento automático do mecanismo InnoDB era armazenado na memória. Este valor na memória será perdido após a reinicialização do MySQL. Quando a tabela for aberta pela primeira vez após a reinicialização, ela encontrará o valor máximo do autoincremento max(id) e, em seguida, adicionará 1 ao valor máximo como self -incremento do valor da tabela; MySQL8 A versão .0 registrará as alterações auto-aumentadas no redo log e dependerá do redo log para se recuperar ao reiniciar.
A chave primária de incremento automático precisa ser contínua?
Não necessariamente, existem várias situações que podem fazer com que a chave primária de incremento automático seja descontínua.
1. O conflito de chave exclusiva faz com que a chave primária de incremento automático seja descontínua. Quando inserimos dados em uma tabela InnoDB com uma chave primária de incremento automático, se a restrição exclusiva do índice exclusivo definido na tabela for violada, a inserção de dados falhará. Neste momento, o valor da chave primária de incremento automático da tabela será revertido em 1. Na próxima vez que você inserir dados novamente, você não poderá mais usar os valores-chave gerados pela última rolagem devido à falha na inserção dos dados. Você deve usar os valores-chave gerados pela nova rolagem.
2. A reversão da transação faz com que a chave primária de incremento automático seja descontínua. Quando inserimos dados em uma tabela InnoDB com uma chave primária de incremento automático, se a transação for explicitamente habilitada e então a transação for finalmente revertida por algum motivo, o valor de incremento automático da tabela também será rolado neste momento, e os próximos novos dados inseridos não poderão usar o valor de incremento automático rolado, mas precisarão se inscrever novamente para um novo valor de incremento automático.
3. A inserção em lote resulta em valores de autoincremento descontínuos. O MySQL tem uma estratégia para aplicação em lote de IDs auto-aumentáveis:
- Durante a execução da instrução, na primeira vez que você solicitar um ID de incremento automático, 1 ID de incremento automático será alocado.
- Após o esgotamento de 1, se você se inscrever pela segunda vez, serão alocados 2 IDs auto-aumentáveis.
- Após o esgotamento de 2, se você se inscrever pela terceira vez, serão alocados 4 IDs auto-aumentáveis.
- E assim por diante, cada aplicação tem o dobro do valor da anterior (a última aplicação não pode ser toda aproveitada)
Se a próxima transação inserir dados novamente, eles serão aplicados com base no autoincremento após a aplicação da transação anterior. Neste momento, o valor auto-crescente é descontínuo.
4. Se o tamanho do passo de incremento automático não for 1, isso também fará com que a chave primária de incremento automático seja descontínua.
Como sincronizar dados MySQL com cache Redis?
Referência: https://cloud.tencent.com/developer/article/1805755
Existem duas opções:
1. O Redis é atualizado automaticamente de forma síncrona por meio do MySQL, implementado pelo gatilho MySQL + função UDF .
O processo é aproximadamente o seguinte:
- Defina um gatilho no MySQL para que os dados sejam operados e monitore a operação
- Quando o cliente grava dados no MySQL, o gatilho será acionado. Após o gatilho, a função UDF do MySQL é chamada.
- A função UDF pode gravar dados no Redis para obter efeito de sincronização
2. Analise o log binário do MySQL para sincronizar os dados do banco de dados com o Redis. Isto pode ser conseguido através do canal. Canal é um projeto de código aberto do Alibaba que fornece assinatura e consumo incremental de dados com base na análise de log incremental do banco de dados.
O princípio do canal é o seguinte:
- Canal simula o protocolo de interação do escravo mysql, se disfarça como escravo mysql e envia o protocolo de dump para o mestre mysql.
- mysql master recebe a solicitação de dump e começa a enviar o log binário para o canal
- canal analisa o objeto de log binário (originalmente um fluxo de bytes) e grava os dados no Redis de forma síncrona.
Por que o manual do Alibaba Java proíbe o uso de procedimentos armazenados?
Vejamos primeiro o que é um procedimento armazenado.
Um procedimento armazenado é um conjunto de instruções SQL usadas para completar funções específicas em um grande sistema de banco de dados. Ele é armazenado no banco de dados e é permanentemente válido após ser compilado uma vez. O usuário especifica o nome do procedimento armazenado e fornece parâmetros ( se o procedimento armazenado tiver parâmetros) para executá-lo.
Os procedimentos armazenados apresentam principalmente as seguintes desvantagens.
- Os procedimentos armazenados são difíceis de depurar . O desenvolvimento de procedimentos armazenados sempre careceu de um ambiente IDE eficaz. O SQL em si costuma ser muito longo e a depuração requer a divisão das sentenças e sua execução independente, o que é muito problemático.
- Má portabilidade . É difícil transplantar procedimentos armazenados. Geralmente, os sistemas de negócios inevitavelmente usarão as características e a sintaxe exclusivas do banco de dados. Ao substituir o banco de dados, essa parte do código precisa ser reescrita, o que é caro.
- Dificuldades na gestão . O diretório de procedimentos armazenados é plano, não uma estrutura de árvore como um sistema de arquivos. É fácil de manusear quando há poucos scripts, mas quando há muitos, o diretório cairá no caos.
- Os procedimentos armazenados são otimizados apenas uma vez.Às vezes, à medida que a quantidade de dados aumenta ou a estrutura de dados muda, o plano de execução selecionado pelo procedimento armazenado original pode não ser o ideal, portanto, é necessária intervenção manual ou recompilação neste momento.
Por fim, gostaria de compartilhar com vocês um repositório Github, que contém mais de 300 PDFs de livros clássicos de informática compilados por Dabin, incluindo linguagem C, C++, Java, Python, front-end, banco de dados, sistema operacional, rede de computadores, estrutura de dados e algoritmo e aprendizado de máquina. , Programming Life , etc. Você pode marcá-lo e pesquisar diretamente nele na próxima vez que procurar livros. O armazém está sendo atualizado continuamente! Endereço do Github

Se você não conseguir acessar o Github, poderá acessar o endereço da nuvem de código. endereço de nuvem de código