Princípio da árvore de decisão
A árvore de decisão é um algoritmo multifuncional de aprendizado de máquina, que pode realizar tarefas de classificação e regressão e até tarefas de várias saídas. Eles são poderosos e podem caber em conjuntos de dados complexos.
- -Vantagens: simples e intuitivo, basicamente sem pré-processamento, sem necessidade de conferências, lidando com valores ausentes, alta precisão, insensível a outliers, sem suposições de entrada de dados. Pode lidar com valores discretos ou contínuos e com problemas de classificação de saída multidimensional
- Desvantagens: alta complexidade computacional, fácil adaptação e baixa capacidade de generalização.Pode ser que a estrutura da árvore mude drasticamente devido a uma pequena modificação da amostra, e a complexidade do espaço seja alta.
- Intervalo de dados aplicável: tipo numérico e tipo nominal.
A função de pseudocódigo createBranch () que cria uma ramificação é a seguinte:
Detecte se cada subitem no conjunto de dados pertence à mesma categoria:
If so return 类标签;
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
return 分支节点
O pseudocódigo createBranch acima é uma função recursiva que se chama diretamente na penúltima linha.
Seu princípio de funcionamento é muito simples.O fluxograma mostrado na figura é uma árvore de decisão.O retângulo representa o bloco de decisão e a elipse representa o bloco final, indicando que uma conclusão foi alcançada e a operação pode ser encerrada. As setas esquerda e direita desenhadas no módulo de julgamento são chamadas de ramificações, que podem alcançar outro módulo de julgamento ou encerrar o módulo.
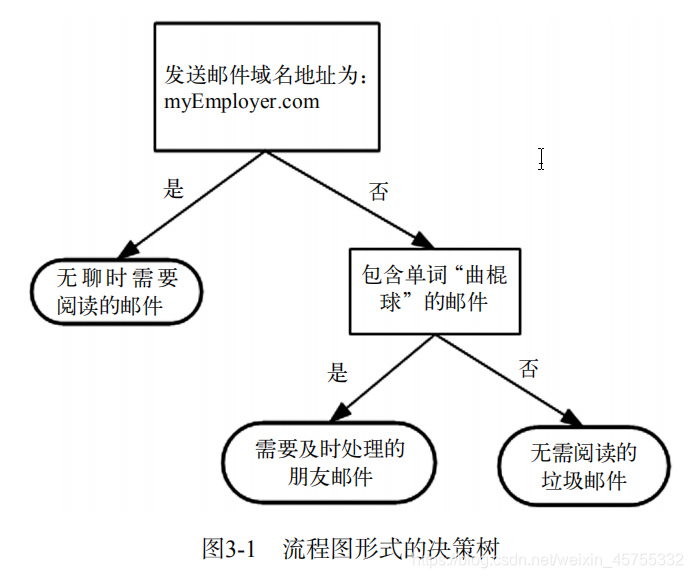
O algoritmo vizinho k-mais próximo pode concluir muitas tarefas de classificação, mas sua maior desvantagem é que não pode dar o significado inerente dos dados.A principal vantagem da árvore de decisão é que o formulário de dados é muito fácil de entender. A árvore de decisão requer muito pouco trabalho de preparação de dados; em particular, não há necessidade de escala ou concentração de recursos.
(1) 收集数据:可以使用任何方法。
(2) 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
(3) 分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。
(4) 训练算法:构造树的数据结构。
(5) 测试算法:使用经验树计算错误率。
(6) 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据
的内在含义。
Faça previsões
Tomando a classificação da íris como exemplo (existem quatro recursos e três categorias), o limite de decisão da árvore de decisão é mostrado na figura. A linha em negrito indica o limite de decisão do nó raiz (profundidade 0): comprimento da pétala = 2,45 cm. Como a área à esquerda é pura (apenas íris Setosa), não pode ser dividida. Mas a área à direita é impura, de modo que o nó à direita da profundidade 1 se divide novamente na largura da pétala = 1,75 cm (mostrado pela linha pontilhada). Como a profundidade máxima max_depth é definida como 2, a árvore de decisão para aqui. Mas se você definir max_depth como 3, dois nós com profundidade 2 gerarão outro limite de decisão (mostrado por linhas pontilhadas).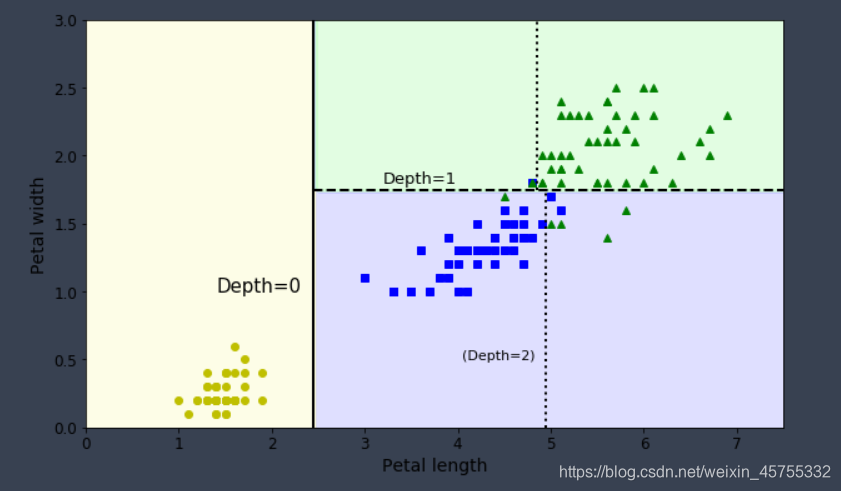
Classificação da árvore de decisão
Algoritmo 1.CLS
O algoritmo de aprendizado CLS (Concept Learning System) foi proposto por Hunt.EB e outros em 1966. Primeiro, propôs o uso de árvores de decisão para o aprendizado de conceitos e, posteriormente, muitos algoritmos de aprendizado de árvores de decisão podem ser considerados como o aprimoramento e a atualização do algoritmo CLS. A idéia principal do CLS é iniciar a partir de uma árvore de decisão vazia e melhorar a árvore de decisão original adicionando novos nós de decisão até que a árvore possa classificar corretamente os exemplos de treinamento. O processo de construção da árvore de decisão também é o processo de assumir especialização, para que o CLS possa ser considerado como um algoritmo de aprendizado com apenas um operador. Esta operação pode ser expressa como: Especialização da hipótese atual adicionando uma nova condição de decisão (novo nó de decisão). O algoritmo CLS chama esse operador recursivamente, atuando em cada nó folha para construir uma árvore de decisão.
2. algoritmo ID3
O algoritmo ID3 (Iterative Dichotomizer3) foi proposto por Quinlan em 1986. É o representante do algoritmo da árvore de decisão e a maioria dos algoritmos da árvore de decisão é aprimorada com base nele. Ele usa uma estratégia de dividir e conquistar. Ao selecionar atributos em todos os níveis da árvore de decisão, o ganho de informações é usado como critério de seleção de atributos, para que, ao testar em cada nó não-folha, seja possível obter o método específico de obter as informações de maior categoria sobre o registro testado. Sim: detecte todos os atributos, selecione o atributo com maior ganho de informações para gerar um nó da árvore de decisão, estabeleça ramificações a partir de diferentes valores desse atributo e chame recursivamente esse método em um subconjunto de cada ramificação para estabelecer ramificações do nó da árvore de decisão até todos os subconjuntos Contém apenas dados da mesma categoria. Finalmente, é obtida uma árvore de decisão, que pode classificar novas amostras.
Algoritmo 3.C4.5
O algoritmo C4.5 foi proposto por Quinlan.JR em 1993. Ele evoluiu do algoritmo ID3 e herdou as vantagens do algoritmo ID3.O algoritmo C4.5 introduziu novos métodos e funções:
- Use o conceito de ganho de informação para superar as deficiências do viés para atributos com vários valores ao selecionar atributos com ganho de informação;
- Poda durante a construção da árvore para evitar sobreajustar a árvore;
- Capacidade de discretizar atributos contínuos;
- Pode lidar com conjuntos de amostras de treinamento com valores de atributo ausentes;
- Capacidade de processar dados incompletos;
- Validação cruzada K-fold;
O algoritmo C4.5 reduz a complexidade do cálculo e aprimora a eficiência do cálculo. Sua melhoria importante no algoritmo ID3 é usar a taxa de ganho de informações para selecionar atributos. Teorias e experimentos mostram que o uso da taxa de ganho de informação é melhor do que o uso de ganho de informação, principalmente porque supera o atributo do método ID3 de escolher mais valores. O algoritmo C4.5 também lidou com os dados do atributo de valor contínuo, compensando o defeito de que o algoritmo ID3 possa lidar apenas com dados discretos de atributos de valor.
No entanto, o algoritmo C4.5 paga um ótimo preço pelo processamento do limite de pesquisa linear em atributos de teste contínuo. Em 2002, Salvatore Ruggieri propôs um algoritmo aprimorado para o algoritmo C4.5: EC4.5. O algoritmo EC4.5 usa pesquisa binária em vez de pesquisa linear para superar essa falha. As experiências mostram que, ao gerar a mesma árvore de decisão, comparado com o algoritmo C4.5, o algoritmo EC4.5 pode melhorar a eficiência em 5 vezes, mas a desvantagem do algoritmo EC4.5 ocupa mais memória. 5. Algoritmo SLIQ O algoritmo acima exige que os conjuntos de amostra de treinamento residam na memória, portanto, não é adequado para o processamento de dados em grande escala. Para esse fim, os pesquisadores da IBM propuseram um algoritmo SLIQ (Supervised Learning In Quest) de classificação de árvore de decisão mais rápido e escalável, adequado para o processamento de dados em larga escala em 1996. Ele usa a tabela de atributos, a tabela de classes e o histograma de classe para construir uma árvore. A tabela de atributos contém dois campos: valor do atributo e número da amostra. A tabela de classes também contém
4. Algoritmo de treinamento CART
O Scikit-Learn usa o algoritmo CART (Classification And Regression Tree) para treinar árvores de decisão (também conhecidas como árvores de "crescimento"). A ideia é muito simples: primeiro, use um único recurso ke um limiar tk (por exemplo, comprimento da pétala ≤ 2,45 cm) para dividir o conjunto de treinamento em dois subconjuntos. Como escolher ke limiar tk? A resposta é que k e tk, que produzem o subconjunto mais puro (ponderado por seu tamanho), são determinados pela pesquisa por algoritmo (t, tk).

Depois que o conjunto de treinamento for dividido com êxito em dois, ele usará a mesma lógica para continuar a dividir o subconjunto e, em seguida, o subconjunto do subconjunto, e iterar por sua vez. Até que a profundidade máxima seja atingida (explicada abaixo pelo hiper parâmetro max_depth control). Reduzir max_depth pode regularizar o modelo, reduzindo assim o risco de sobreajuste. ), Ou se não conseguir mais encontrar uma divisão que possa reduzir a impureza, ela será interrompida.
Complexidade computacional
Fazer previsões requer atravessar a árvore de decisão da raiz para a folha. De um modo geral, a árvore de decisão é aproximadamente equilibrada, portanto, percorrer a árvore de decisão requer cerca de O (log2 (m)) nós. (Nota: log2 é o logaritmo da base 2. É igual a log2 (m) = log (m) / log (2).) E cada nó precisa apenas verificar um valor próprio, portanto, a complexidade geral da previsão é apenas O ( log2 (m)), independentemente do número de recursos. Assim, mesmo ao lidar com grandes conjuntos de dados, as previsões são rápidas. No entanto, em cada nó durante o treinamento, o algoritmo precisa comparar todos os recursos em todas as amostras (se max_features estiver definido, será menor). Isso leva a uma complexidade de treinamento de O (n × m log (m)). Para conjuntos de treinamento pequenos (em milhares de instâncias), o Scikit_learn pode acelerar o treinamento pré-processando os dados (configuração presort = True), mas para conjuntos de treinamento maiores, isso pode atrasar o treinamento.
Hiperparâmetro regularizado
As árvores de decisão raramente fazem suposições sobre os dados de treinamento (por exemplo, o modelo linear é exatamente o oposto, obviamente assume que os dados são lineares). Se não for restrito, a estrutura da árvore mudará com o conjunto de treinamento, ajustará-se de perto e provavelmente superajustará. Esse tipo de modelo geralmente é chamado de modelo não paramétrico, o que não significa que ele não contenha parâmetros (na verdade, geralmente possui muitos parâmetros), mas significa que o número de parâmetros não é determinado antes do treinamento, resultando na estrutura do modelo livre e próxima dos dados. . Modelos de parâmetros correspondentes, como modelos lineares, têm alguns parâmetros predefinidos, portanto seus graus de liberdade são limitados, reduzindo assim o risco de sobreajuste (mas aumentando o risco de sobreajuste). Pode ser otimizado da seguinte maneira.
1. Limite de galhos e folhas
Para evitar o ajuste excessivo, é necessário reduzir o grau de liberdade da árvore de decisão durante o processo de treinamento, chamado de regularização. A escolha dos hiperparâmetros de regularização depende do modelo usado, mas, em geral, pode pelo menos limitar a profundidade máxima da árvore de decisão. Hyper parâmetro max_depth control (o padrão é Nenhum, o que significa ilimitado) Reduzir max_depth pode regularizar o modelo, reduzindo assim o
risco de sobreajuste .
Parâmetro
- min_samples_split (o número mínimo de amostras que um nó deve ter antes da divisão)
- min_samples_leaf (o número mínimo de amostras que um nó folha deve ter)
- min_weight_fraction_leaf (o mesmo que min_samples_leaf, mas expresso como uma porcentagem do número total de instâncias ponderadas)
- max_leaf_nodes (número máximo de nós folha)
- max_features (divida o número máximo de recursos avaliados por cada nó). Aumentar o hiperparâmetro
- Min_ * ou decrescente max_ * regularizarão o modelo.
2. Poda e corte de folhas
Você também pode treinar o modelo sem restrições antes de
remover (excluir) nós desnecessários . Se os nós filhos de um nó forem todos os nós folha, o nó poderá ser considerado desnecessário, a menos que a melhoria da pureza que ele representa tenha significância estatística importante. Testes estatísticos padrão, como o teste do χ2, são usados para estimar a probabilidade de que "a melhoria seja puramente acidental" (conhecida como hipótese falsa). Se essa probabilidade (chamada valor-p) for maior que um determinado limite (geralmente 5%, controlado por hiperparâmetros), esse nó poderá ser considerado desnecessário e seus nós filhos poderão ser excluídos. Até que todos os nós desnecessários sejam excluídos, o processo de remoção termina.
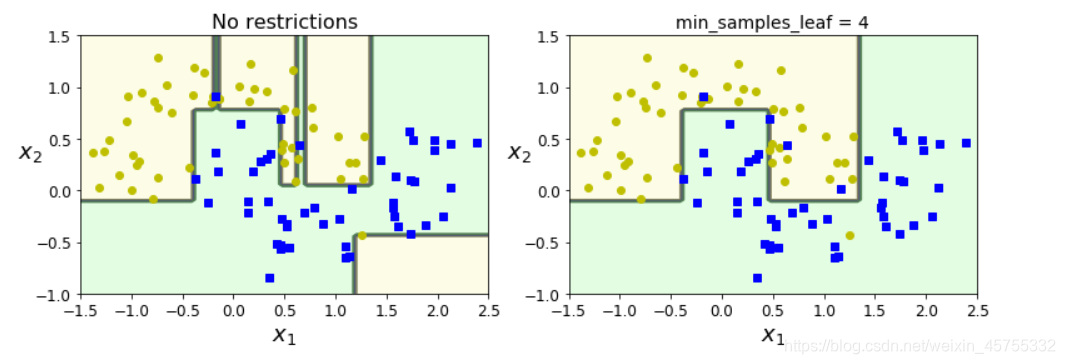
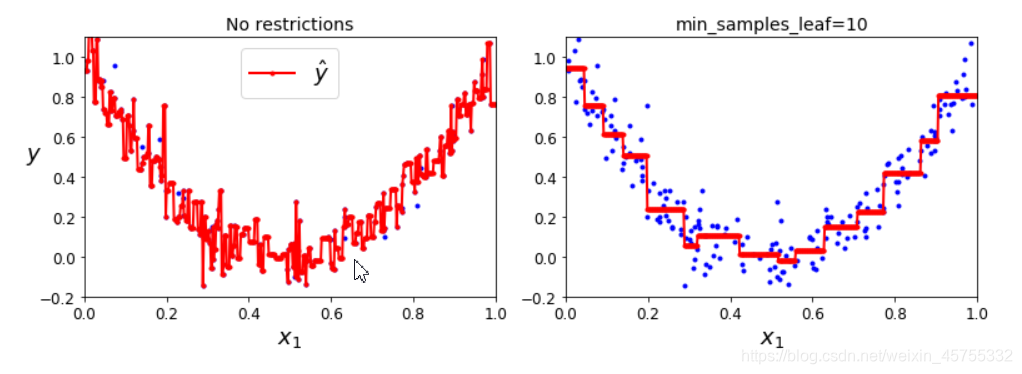
Obviamente, a imagem da esquerda é ilimitada, mas sobreajustada; a imagem da direita é limitada por min_samples_leaf, e seu efeito de generalização é melhor.
Retorno
As árvores de decisão também podem ser usadas para análise de regressão: ao contrário da classificação, a regressão prediz um valor e não uma categoria.
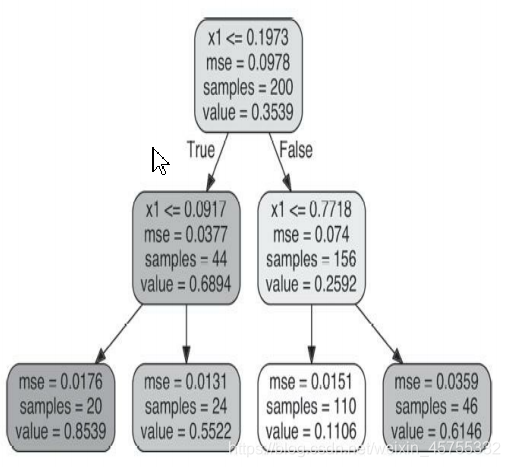
Por exemplo, se você quiser
nova instância da previsão, então atravessado a partir do nó raiz, e finalmente para o valor de previsão = 0,1106 de um nó folha. Esse resultado da previsão é, na verdade, o valor-alvo médio de 110 instâncias associadas a este nó folha. Nestes 110 exemplos, o erro quadrado médio (MSE) gerado pela previsão é igual a 0,0151.
Como as tarefas de classificação, as árvores de decisão também são propensas a sobreajuste ao lidar com tarefas de regressão.
O problema
1. Se o conjunto de treinamento possui 1 milhão de instâncias, qual é a profundidade aproximada da árvore de decisão de treinamento (sem restrições)?
Resposta: A profundidade de uma árvore binária equilibrada contendo m nós de folha é igual a log2 (m) (Nota: log2 representa uma função de log com 2 como base, log2 (m) = log (m) / log (2).) Arredondamento. De um modo geral, o treinamento da árvore de decisão binária geralmente é equilibrado até o final.Se não for restrito, a média de cada nó folha é uma instância. Portanto, se o conjunto de treinamento contiver um milhão de instâncias, a profundidade da árvore de decisão será aproximadamente igual a log2 (106) ≈ 20 camadas (na verdade, será mais porque a árvore de decisão geralmente é impossível de equilibrar perfeitamente).
2. Se a árvore de decisão supera o conjunto de treinamento, é uma boa ideia reduzir a max_depth?
Resposta: Pode ser uma boa idéia reduzir a profundidade_ max, porque isso limitará o modelo e o tornará regular.
3. Se a árvore de decisão não se encaixa bem no conjunto de treinamento, é uma boa idéia tentar escalar os recursos de entrada?
Resposta: Uma das vantagens das árvores de decisão é que elas não se importam se os dados de treinamento são dimensionados ou concentrados; portanto, se a árvore de decisão não estiver bem ajustada ao conjunto de treinamento, dimensionar os recursos de entrada é apenas uma perda de tempo.
4. Se demorar uma hora para treinar uma árvore de decisão em um conjunto de treinamento contendo 1 milhão de instâncias, quanto tempo leva para treinar uma árvore de decisão em um conjunto de treinamento contendo 10 milhões de instâncias?
Resposta: A complexidade do treinamento da árvore de decisão é O (n × mlog (m)). Portanto, se o tamanho do conjunto de treinamento for multiplicado por 10, o tempo de treinamento será multiplicado por K = (n × 10m × log (10m)) / (n × m × log (m)) = 10 × log (10m) / log (m ) Se m = 106, então K≈11,7, leva cerca de 11,7 horas para treinar 10 milhões de instâncias.
Nota
Como sou iniciante, ainda não sei muito sobre os parâmetros do algoritmo, por isso tomo emprestado muito dos trechos e os mesclo para não ter uma fonte famosa aqui. Espero entender. Não escrevi muito código, principalmente porque achava que a escrita tornaria o espaço muito grande e não escrevi muito raciocínio em fórmulas (a chave é que eu era um calouro, a maioria deles não consegue entender), então escrevi alguns conhecimentos básicos de forma concisa.
Além disso, este artigo se refere principalmente ao livro "Aprendizado de máquina prático: baseado no Scikit-Learn e TensorFlow". Se houver uma demanda (ainda há muitas informações sobre Python e aprendizado de máquina), você pode acompanhar e enviar um e-mail para mim em particular, e eles serão entregues um a um.
Afinal, novatos, se você tiver erros, ainda deseja esclarecer e apoiar, não gosta de usar spray e espera encontrar amigos que escrevam com a mesma opinião e aprendam juntos.
