Índice
1. Introdução ao ShardingSphere
3. Crie um projeto SpringBoot e introduza dependências
4. Adicione configuração a application.properties
5. Crie classes de entidade correspondentes e use MyBatis-Plus para construir CRUD rapidamente
6. Configuração principal da classe de inicialização
3. Tente sub-banco de dados e subtabela
1. Crie o banco de dados db_device_1. E crie duas tabelas físicas no banco de dados:
2. Ajuste a configuração da fonte de dados
4. Faça consultas em subbancos de dados e subtabelas
1. Consulta baseada em device_id
2. Consulta baseada no intervalo device_id
4. Principais pontos de conhecimento do subbanco de dados e subtabela
2. Estratégia de fragmentação e fragmentação
3. Implementação da estratégia de fragmentação
1) Fragmentação precisa da estratégia de fragmentação padrão padrão
2) Fragmentação do escopo da estratégia de fragmentação padrão padrão
3) Estratégia de fragmentação complexa
4) Sugestão de política de roteamento forçado
5. Conseguir separação entre leitura e escrita
1. Construa um banco de dados de sincronização mestre-escravo
2. Use sharding-jdbc para obter separação de leitura e gravação
6. Princípio de implementação – modo de conexão
6.1.1. Modo limitado de memória
6.1.2. Modo de restrição de conexão
6.2. Mecanismo de execução automatizado
1. Introdução ao ShardingSphere
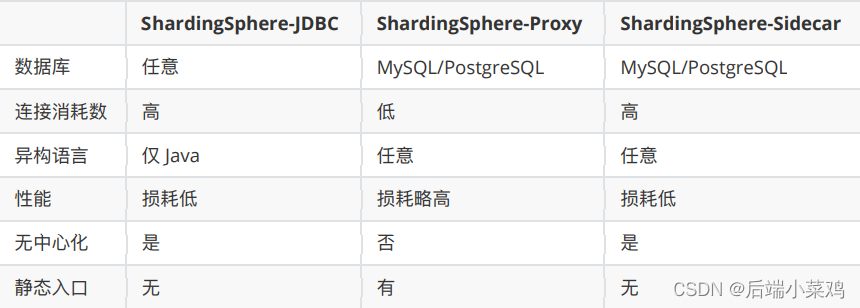
Apache ShardingSphere é um ecossistema de soluções de banco de dados distribuídos de código aberto. Consiste em JDBC, Proxy e Sidecar (em planejamento), três produtos que podem ser implantados de forma independente e suportam implantação híbrida e uso conjunto. Todos eles fornecem funções como expansão horizontal de dados padronizados, transações distribuídas e governança distribuída, e podem ser aplicados a vários cenários de aplicativos diversos, como isomorfismo Java, linguagens heterogêneas e nativos da nuvem.
O Apache ShardingSphere visa utilizar plena e razoavelmente os recursos de computação e armazenamento de bancos de dados relacionais em cenários distribuídos, mas não implementa um novo banco de dados relacional. Os bancos de dados relacionais ainda ocupam uma enorme participação de mercado hoje e são a base dos sistemas centrais da empresa. Eles serão difíceis de abalar no futuro. Nós nos concentramos mais em fornecer incrementos na base original, em vez de subversão.
Site oficial: Apache ShardingSphere
2. Início rápido (subtabela)
1. Crie um banco de dados
Crie um banco de dados chamado db_device_0.
2. Crie uma mesa física
Logicamente, tb_device representa uma tabela que descreve informações do dispositivo. Para refletir o conceito de subtabelas, a tabela tb_device é dividida em duas. Portanto, tb_device é a tabela lógica e tb_device_0 e tb_device_1 são as tabelas físicas da tabela lógica.
CREATE TABLE `tb_device_0` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb3;
CREATE TABLE `tb_device_1` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb33. Crie um projeto SpringBoot e introduza dependências
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>4. Adicione configuração a application.properties
# 配置真实数据源
spring.shardingsphere.datasource.names=ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/db_device_0?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds1.username=db_device_0
spring.shardingsphere.datasource.ds1.password=db_device_0
# 配置物理表
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds1.tb_device_$->{0..1}
# 配置分表策略:根据device_id作为分⽚的依据(分⽚键、分片算法)
# 将device_id作为分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.sharding-column=device_id
# 用device_id % 2 来作为分片算法 奇数会存入 tb_device_1 偶数会存入 tb_device_0
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.algorithm-expression=tb_device_$->{device_id%2}
# 开启SQL显示
spring.shardingsphere.props.sql.show = true
5. Crie classes de entidade correspondentes e use MyBatis-Plus para construir CRUD rapidamente
package com.my.sharding.shperejdbc.demo.entity;
import lombok.Data;
@Data
public class TbDevice {
private Long deviceId;
private Integer deviceType;
}
6. Configuração principal da classe de inicialização
package com.my.sharding.shperejdbc.demo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
// 配置mybatis扫描的mapper!
@MapperScan("com.my.shardingshpere.jdbc.demo.mapper")
@SpringBootApplication
public class MyShardingShpereJdbcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(MyShardingShpereJdbcDemoApplication.class, args);
}
}7. Escreva testes
@SpringBootTest
class MyShardingShpereJdbcDemoApplicationTests {
@Autowired
DeviceMapper deviceMapper;
@Test
void testInitData(){
for (int i = 0; i < 10; i++) {
TbDevice tbDevice = new TbDevice();
tbDevice.setDeviceId((long) i);
tbDevice.setDeviceType(i);
deviceMapper.insert(tbDevice);
}
}
}Execute e visualize o banco de dados:
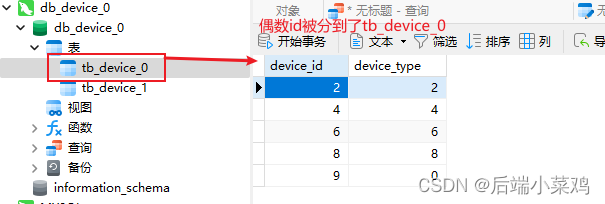
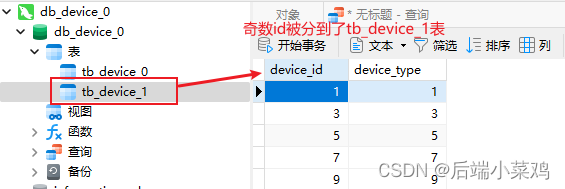
Verifica-se que de acordo com a estratégia de fragmentação, os dados com IDs ímpares entre esses 10 dados serão inseridos na tabela tb_device_1, e os dados com IDs ímpares serão inseridos na tabela tb_device_0.
3. Tente sub-banco de dados e subtabela
1. Crie o banco de dados db_device_1. E crie duas tabelas físicas no banco de dados:
CREATE TABLE `tb_device_0` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb3;
CREATE TABLE `tb_device_1` (
`device_id` bigint NOT NULL AUTO_INCREMENT,
`device_type` int DEFAULT NULL,
PRIMARY KEY (`device_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb32. Ajuste a configuração da fonte de dados
Forneça duas fontes de dados, use os dois bancos de dados MySQL criados anteriormente como fontes de dados e crie uma estratégia de fragmentação
# 配置真实数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/db_device_0?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds0.username=db_device_0
spring.shardingsphere.datasource.ds0.password=db_device_0
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/db_device_1?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.ds1.username=db_device_1
spring.shardingsphere.datasource.ds1.password=db_device_1
# 配置物理表
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds$->{0..1}.tb_device_$->{0..1}
# 配置分库策略
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
# ⾏表达式分⽚策略 使⽤Groovy的表达式
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{device_id%2}
# 配置分表策略:根据device_id作为分⽚的依据(分⽚键、分片算法)
# 将device_id作为分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
# ⾏表达式分⽚策略 使⽤Groovy的表达式
# 用device_id % 2 来作为分片算法 奇数会存入 tb_device_1 偶数会存入 tb_device_0
spring.shardingsphere.sharding.tables.tb_device.table-strategy.inline.algorithm-expression=tb_device_$->{device_id%2}
# 开启SQL显示
spring.shardingsphere.props.sql.show = true
Em comparação com a configuração anterior, desta vez foi adicionada uma estratégia de fragmentação para dois bancos de dados, e qual banco de dados armazenar é determinado com base nas características de paridade de device_id. Ao mesmo tempo, scripts interessantes foram usados para determinar o relacionamento entre o banco de dados e as tabelas.
ds$->{0..1}.tb_device_$->{0..1}Equivalente a:
ds0.tb_device_0
ds0.tb_device_1
ds1.tb_device_0
ds1.tb_device_13. Execute a aula de teste
Resultado: verifica-se que os dados ímpares de device_id serão armazenados na tabela ds1.tb_device_1 e os dados pares serão armazenados na tabela ds0.tb_device_0.
4. Faça consultas em subbancos de dados e subtabelas
1. Consulta baseada em device_id
/**
* 根据device_id查询
*/
@Test
void testQueryByDeviceId(){
QueryWrapper<TbDevice> wrapper = new QueryWrapper<>();
wrapper.eq("device_id",1);
List<TbDevice> list = deviceMapper.selectList(wrapper);
list.stream().forEach(e->{
System.out.println(e);
});
}Resultado: TbDevice(deviceId=1, deviceType=1)
E a biblioteca consultada é tb_device_1
2. Consulta baseada no intervalo device_id
/**
* 根据 device_id 范围查询
*/
@Test
void testDeviceByRange(){
QueryWrapper<TbDevice> wrapper = new QueryWrapper<>();
wrapper.between("device_id",1,10);
List<TbDevice> devices = deviceMapper.selectList(wrapper);
devices.stream().forEach(e->{
System.out.println(e);
});
}resultado:
Error querying database. Cause: java.lang.IllegalStateException: Inline strategy cannot support this type sharding:RangeRouteValue(columnName=device_id, tableName=tb_device, valueRange=[1‥10])Motivo: a estratégia de fragmentação inline não suporta consultas de intervalo.
4. Principais pontos de conhecimento do subbanco de dados e subtabela
1. Conceitos centrais
Antes de compreender a estratégia de fragmentação, vamos primeiro compreender os seguintes conceitos-chave: tabela lógica, tabela real, nó de dados, tabela de ligação e tabela de transmissão.
- tabela lógica
Um termo geral para tabelas com a mesma lógica e estrutura de dados de bancos de dados (tabelas) divididos horizontalmente. Exemplo: Os dados do pedido são divididos em 10 tabelas com base na mantissa da chave primária, ou seja, t_order_0 a t_order_9, e seus nomes de tabelas lógicas são t_order.
- mesa de verdade
Uma tabela física que realmente existe no banco de dados fragmentado. Ou seja, t_order_0 a t_order_9 no exemplo anterior.
- nó de dados
A menor unidade de fragmentação de dados. Consiste no nome da fonte de dados e na tabela de dados, por exemplo: ds_0.t_order_0.
- tabela de ligação
Refere-se à tabela principal e subtabelas com regras de particionamento consistentes. Por exemplo: A tabela t_order e a tabela t_order_item são divididas de acordo com order_id, portanto, as duas tabelas estão vinculadas uma à outra. As consultas de correlação de múltiplas tabelas entre tabelas vinculadas não terão correlações de produto cartesianas e a eficiência das consultas de correlação será bastante melhorada. Por exemplo, se o SQL for:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id
WHERE o.order_id in (10, 11);Quando o relacionamento da tabela de ligação não está configurado, assumindo que a chave dividida order_id roteia o valor 10 para a 0ª fatia e o valor 11 para a 1ª fatia, então o SQL roteado deve ser 4, e eles são apresentados como produtos cartesianos:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);Depois de configurar o relacionamento da tabela de ligação, o SQL de roteamento deverá ser 2:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON
o.order_id=i.order_id WHERE o.order_id in (10, 11);Entre eles, t_order está no lado esquerdo de FROM e o ShardingSphere o usará como a tabela principal de toda a tabela de ligação. Todos os cálculos de roteamento usarão apenas a estratégia da tabela principal, então o cálculo da partição da tabela t_order_item usará as condições de t_order. Portanto, as chaves de partição entre tabelas vinculadas devem ser exatamente as mesmas.
2. Estratégia de fragmentação e fragmentação
1) Chave de fragmentação
O campo do banco de dados usado para fragmentação é o campo-chave para dividir horizontalmente o banco de dados (tabela). Exemplo: Se a mantissa da chave primária do pedido na tabela de pedidos for dividida em módulo, então a chave primária do pedido será o campo de divisão. Se não houver campo de fragmentação no SQL, o roteamento completo será executado e o desempenho será ruim. Além de oferecer suporte a campos de sharding únicos, o ShardingSphere também oferece suporte a sharding baseado em vários campos.
2) Algoritmo de fragmentação
Divida os dados por meio do algoritmo de divisão, suportando a divisão por meio de =, >=, , <, BETWEEN e IN. O algoritmo de fragmentação precisa ser implementado pelos próprios desenvolvedores de aplicativos e a flexibilidade alcançável é muito alta. Atualmente, são fornecidos 4 algoritmos de fragmentação. Como o algoritmo de fragmentação está intimamente relacionado à implementação de negócios, nenhum algoritmo de fragmentação integrado é fornecido. Em vez disso, vários cenários são extraídos por meio de estratégias de fragmentação, fornecendo abstração de nível mais alto e interfaces para os desenvolvedores de aplicativos implementarem a si mesmos. Implemente o algoritmo de fragmentação
- Algoritmo de fragmentação exato
Corresponde ao PreciseShardingAlgorithm, que é usado para lidar com o cenário de divisão = e IN usando uma única chave como chave de divisão. Precisa ser usado com StandardShardingStrategy.
- Algoritmo de particionamento de intervalo
Corresponde ao RangeShardingAlgorithm, usado para lidar com o cenário de uso de uma única chave como chave de divisão ENTRE AND, >, =, <= para realizar a divisão. Precisa ser usado com StandardShardingStrategy.
- Algoritmo de fragmentação composta
Correspondente ao ComplexKeysShardingAlgorithm, ele é usado para lidar com o cenário de uso de múltiplas chaves como chave de sharding para sharding.A lógica que contém múltiplas chaves de sharding é relativamente complexa e os desenvolvedores de aplicativos precisam lidar com a complexidade por conta própria. Precisa ser usado com ComplexShardingStrategy.
- Algoritmo de fragmentação de dica
Corresponde ao HintShardingAlgorithm, usado para lidar com cenários em que Hint é usado para fragmentação. Precisa ser usado com HintShardingStrategy.
3) Estratégia de fragmentação
Contém a chave de fragmentação e o algoritmo de fragmentação. Devido à independência do algoritmo de fragmentação, ele é extraído de forma independente. O que realmente pode ser usado para operações de sharding é a chave de sharding + algoritmo de sharding, que é a estratégia de sharding. Atualmente, são fornecidas 5 estratégias de fragmentação.
-
Estratégia de fragmentação padrão
Corresponde a StandardShardingStrategy. Fornece fragmentação para =, >, =, , =, <= em instruções SQL. Se RangeShardingAlgorithm não estiver configurado, BETWEEN AND em SQL será processado de acordo com o roteamento completo do banco de dados.
- Estratégia de fragmentação composta
Corresponde a ComplexShardingStrategy. Estratégia de fragmentação composta. Fornece suporte para operações de divisão de =, >, =, <=, IN e BETWEEN AND em instruções SQL. ComplexShardingStrategy suporta múltiplas chaves de shard. Devido ao relacionamento complexo entre múltiplas chaves de shard, ele não realiza muito encapsulamento. Em vez disso, ele transmite diretamente de forma transparente a combinação de valores da chave de shard e o operador de shard para o algoritmo de shard, completamente implementado pelo aplicativo desenvolvedores para fornecer flexibilidade máxima.
- Estratégia de fragmentação de expressão de linha
Corresponde a InlineShardingStrategy. Usando expressões Groovy, ele fornece suporte para operações de divisão de = e IN em instruções SQL e oferece suporte apenas a chaves de divisão únicas. Para um algoritmo de fragmentação simples, ele pode ser usado por meio de configuração simples para evitar o tedioso desenvolvimento de código Java, como: t_user_$->{u_id % 8} significa que a tabela t_user é dividida em 8 tabelas de acordo com u_id módulo 8. A tabela Os nomes são t_user_0 a t_user_7.
- Estratégia de fragmentação de dicas
Corresponde a HintShardingStrategy. Uma estratégia para realizar sharding especificando valores de sharding via Hint em vez de extrair valores de sharding do SQL.
- Sem estratégia de fragmentação
Corresponde a NoneShardingStrategy. Uma estratégia não fragmentada.
3. Implementação da estratégia de fragmentação
1) Fragmentação precisa da estratégia de fragmentação padrão padrão
No Standard, as estratégias de fragmentação padrão podem ser configuradas em bancos de dados de fragmentação e tabelas de fragmentação, respectivamente. Ao configurar, você precisa especificar a chave de divisão, divisão precisa ou divisão de intervalo.
- Configure a fragmentação precisa dos fragmentos
# 配置分库策略 为 标准分片策略的精准分片
#standard
spring.shardingsphere.sharding.default-databaswe-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBasePreciseAlgorithm
É necessário fornecer uma classe de implementação que implemente o algoritmo de segmentação exata, em que a lógica da segmentação exata possa ter o mesmo significado que a expressão de linha em linha.
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class MyDataBasePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
*
* 数据库标准分片策略
* @param collection 数据源集合
* @param preciseShardingValue 分片条件
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
// 获取逻辑表明 tb_device
String logicTableName = preciseShardingValue.getLogicTableName();
// 获取分片键
String columnName = preciseShardingValue.getColumnName();
// 获取分片键的具体值
Long value = preciseShardingValue.getValue();
//根据分⽚策略:ds$->{device_id % 2} 做精确分⽚
String shardingKey = "ds"+(value%2);
if(!collection.contains(shardingKey)){
throw new UnsupportedOperationException("数据源:"+shardingKey+"不存在!");
}
return shardingKey;
}
}- Configure a fragmentação precisa da tabela de fragmentação
# 配置分表策略 为 标准分片策略的精准分片
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTablePreciseAlgorithm
Ao mesmo tempo, é necessário fornecer uma classe de implementação para o algoritmo de fragmentação preciso para fragmentação de tabela.
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class MyTablePreciseAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
String logicTableName = preciseShardingValue.getLogicTableName(); // 获取逻辑表名
Long value = preciseShardingValue.getValue(); // 获取具体分片键值
String shardingKey = logicTableName+"_"+(value % 2);
if(!collection.contains(shardingKey)){
throw new UnsupportedOperationException("数据表:"+shardingKey+"不存在!");
}
return shardingKey;
}
}O caso de teste para consultar com precisão com base no ID antes do teste tem o mesmo efeito de antes. Consultar uma tabela em um determinado banco de dados com base no ID
2) Fragmentação do escopo da estratégia de fragmentação padrão padrão
- Configurando a fragmentação de intervalo da biblioteca de fragmentação
spring.shardingsphere.sharding.default-databaswe-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBasePreciseAlgorithm
spring.shardingsphere.sharding.default-database-strategy.standard.range-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.database.MyDataBaseRangeAlgorithm
Fornece uma classe de implementação para o algoritmo de consulta de intervalo.
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
public class MyDataBaseRangeAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* 直接返回所有的数据源
* 由于范围查询,需要在两个库的两张表中查。
* @param collection 具体的数据源集合
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return collection;
}
}
- Configurar a fragmentação de intervalo para tabelas de fragmentação
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.precise-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTablePreciseAlgorithm
spring.shardingsphere.sharding.tables.tb_device.table-strategy.standard.range-algorithm-class-name=com.my.sharding.shperejdbc.demo.sharding.algorithm.table.MyTableRangeAlgorithm
Fornece uma classe de implementação para o algoritmo de consulta de intervalo:
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
public class MyTableRangeAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return collection;
}
}Neste ponto, executei o caso de teste de consulta de intervalo novamente e descobri que foi bem-sucedido.
3) Estratégia de fragmentação complexa
@Test
void queryDeviceByRangeAndDeviceType(){
QueryWrapper<TbDevice> queryWrapper = new QueryWrapper<>();
queryWrapper.between("device_id",1,10);
queryWrapper.eq("device_type", 5);
List<TbDevice> deviceList =
deviceMapper.selectList(queryWrapper);
System.out.println(deviceList);
}Problemas com o código de teste acima:
Ao realizar uma consulta de intervalo no device_id, precisamos fazer uma pesquisa precisa com base no device_type. Descobrimos que também precisamos verificar três tabelas em duas bibliotecas, mas o device_type ímpar estará apenas na tabela ímpar da biblioteca ímpar, que é redundante neste momento. Várias consultas desnecessárias.
Para resolver múltiplas pesquisas redundantes, você pode usar a estratégia de fragmentação complexa.
- Estratégia de fragmentação complexa
Suporta estratégias de fragmentação para vários campos.
# 配置分库策略 complex 传入多个分片键
spring.shardingsphere.sharding.default-database-strategy.complex.sharding-columns=device_id,device_type
spring.shardingsphere.sharding.default-database-strategy.complex.algorithm-class-name=com.sharding.algorithm.database.MyDataBaseComplexAlgorithm
# 配置分表策略 complex 传入多个分片键
spring.shardingsphere.sharding.tables.tb_device.table-strategy.complex.sharding-columns=device_id,device_type
spring.shardingsphere.sharding.tables.tb_device.table-strategy.complex.algorithm-class-name=com.sharding.algorithm.table.MyTableComplexAlgorithm
- Configure a classe de implementação do algoritmo da subbiblioteca
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class MyDataBaseComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
/**
*
* @param collection
* @param complexKeysShardingValue
* @return 这一次要查找的数据节点集合
*/
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
Collection<Integer> deviceTypeValues = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("device_type");
Collection<String> databases = new ArrayList<>();
for (Integer deviceTypeValue : deviceTypeValues) {
String databaseName = "ds"+(deviceTypeValue % 2);
databases.add(databaseName);
}
return databases;
}
}- Configure a classe de implementação do algoritmo da subtabela
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class MyTableComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
String logicTableName = complexKeysShardingValue.getLogicTableName();
Collection<Integer> deviceTypeValues = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("device_type");
Collection<String> tables = new ArrayList<>();
for (Integer deviceTypeValue : deviceTypeValues) {
tables.add(logicTableName+"_"+(deviceTypeValue%2));
}
return tables;
}
}teste:

Consultou o banco de dados apenas uma vez
4) Sugestão de política de roteamento forçado
A dica pode forçar o roteamento para uma determinada tabela em uma determinada biblioteca, independentemente das características da instrução SQL.
# 配置分库策略 ## ⾏表达式分⽚策略 使⽤Groovy的表达式
# inline
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{device_id%2}
Configure a classe de implementação do algoritmo de dica
import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.Arrays;
import java.util.Collection;
public class MyTableHintAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Long> hintShardingValue) {
String logicTableName = hintShardingValue.getLogicTableName();
String tableName = logicTableName + "_" +hintShardingValue.getValues().toArray()[0];
if(!collection.contains(tableName)){
throw new UnsupportedOperationException("数据表:"+tableName + "不存在");
}
return Arrays.asList(tableName);
}
}Caso de teste:
@Test
void testHint(){
HintManager hintManager = HintManager.getInstance();
hintManager.addTableShardingValue("tb_device",0); // 强制指定只查询tb_device_0表
List<TbDevice> devices = deviceMapper.selectList(null);
devices.stream().forEach(System.out::println);
}resultado:

4. Tabela de encadernação
Vamos primeiro simular o surgimento do produto cartesiano.
- Crie tabelas tb_device_info_0, tb_device_info_1 para as duas bibliotecas:
CREATE TABLE `tb_device_info_0` (
`id` bigint NOT NULL,
`device_id` bigint DEFAULT NULL,
`device_intro` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;- Configure a estratégia de fragmentação para as tabelas tb_device e tb_device_info.
#tb_device表的分⽚策略
spring.shardingsphere.sharding.tables.tb_device.actual-data-nodes=ds$->
{0..1}.tb_device_$->{0..1}
spring.shardingsphere.sharding.tables.tb_device.tablestrategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device.tablestrategy.inline.algorithm-expression=tb_device_$->{device_id%2}
#tb_device_info表的分⽚策略
spring.shardingsphere.sharding.tables.tb_device_info.actual-datanodes=ds$->{0..1}.tb_device_info_$->{0..1}
spring.shardingsphere.sharding.tables.tb_device_info.tablestrategy.inline.sharding-column=device_id
spring.shardingsphere.sharding.tables.tb_device_info.tablestrategy.inline.algorithm-expression=tb_device_info_$->{device_id%2}As chaves de particionamento de ambas as tabelas são device_id.
- Escreva casos de teste e insira dados
@Test
void testInsertDeviceInfo(){
for (int i = 0; i < 10; i++) {
TbDevice tbDevice = new TbDevice();
tbDevice.setDeviceId((long) i);
tbDevice.setDeviceType(i);
deviceMapper.insert(tbDevice);
TbDeviceInfo tbDeviceInfo = new TbDeviceInfo();
tbDeviceInfo.setDeviceId((long) i);
tbDeviceInfo.setDeviceIntro(""+i);
deviceInfoMapper.insert(tbDeviceInfo);
}
}- O produto cartesiano aparece na consulta de junção
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.lc.entity.TbDeviceInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface DeviceInfoMapper extends BaseMapper<TbDeviceInfo> {
@Select("select a.id,a.device_id,b.device_type,a.device_intro from tb_device_info a left join tb_device b on a.device_id = b.device_id")
public List<TbDeviceInfo> queryDeviceInfo();
}
@Test
void testQueryDeviceInfo(){
List<TbDeviceInfo> tbDeviceInfos = deviceInfoMapper.queryDeviceInfo();
tbDeviceInfos.stream().forEach(System.out::println);
}resultado:
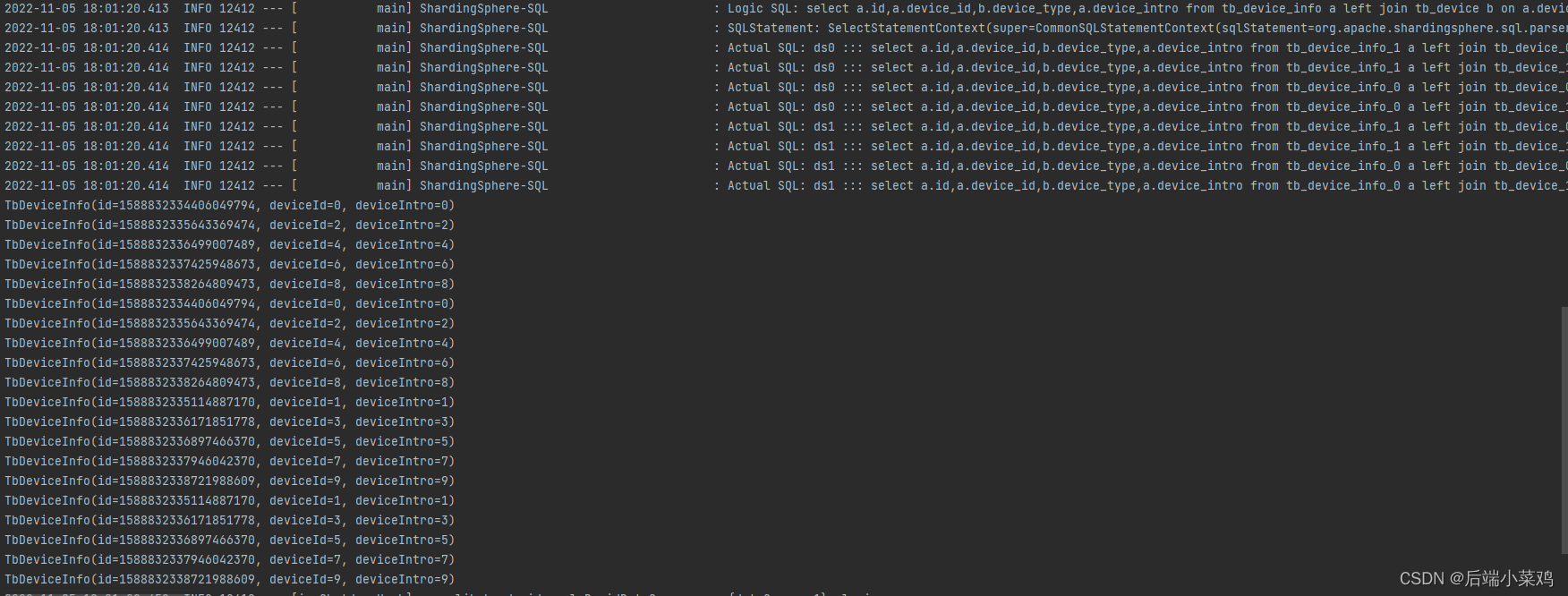
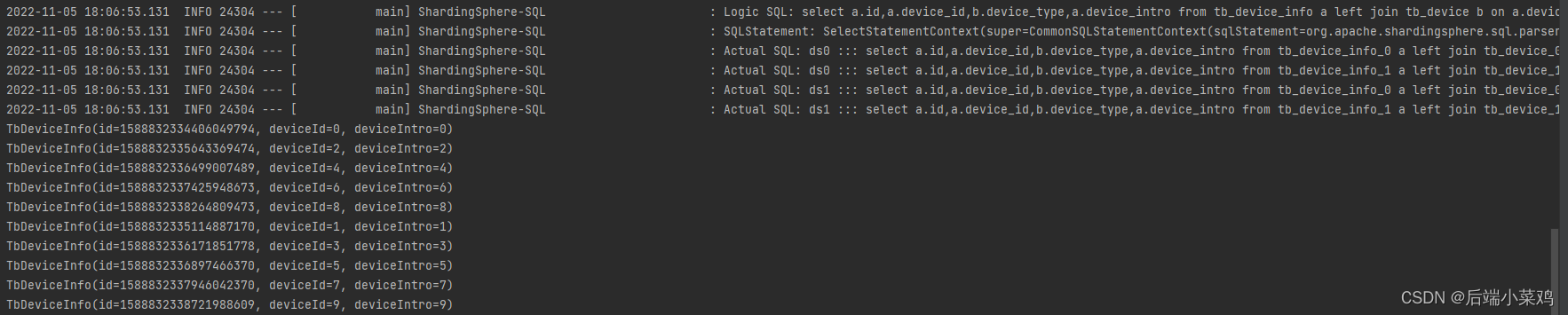
Como você pode ver, foi gerado um produto cartesiano e foram encontrados 20 dados.
- Configurar tabela de vinculação
# 配置 绑定表
spring.shardingsphere.sharding.binding-tables[0]=tb_device,tb_device_infoConsulte novamente e nenhum produto cartesiano aparece:
5. Lista de transmissão
Agora existe um cenário onde os dados da tabela tb_device_type correspondente à coluna device_type não devem ser divididos em tabelas. Ambas as bibliotecas devem ter a quantidade total de dados da tabela.
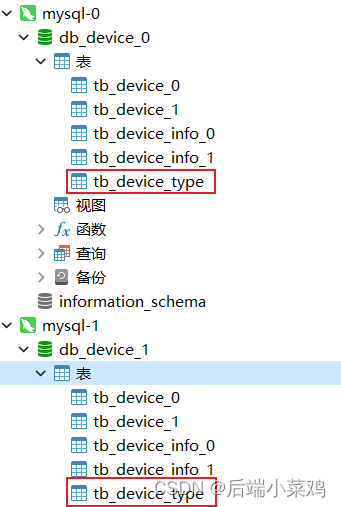
- Crie tabelas tb_device_type em ambos os bancos de dados
CREATE TABLE `tb_device_type` (
`type_id` int NOT NULL AUTO_INCREMENT,
`type_name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`type_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;- Configurar lista de transmissão
#⼴播表配置
spring.shardingsphere.sharding.broadcast-tables=tb_device_type
spring.shardingsphere.sharding.tables.tb_device_type.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.tb_device_type.key-generator.column=type_id- Escreva casos de teste
@Test
void testInsertDeviceType(){
TbDeviceType tbDeviceType = new TbDeviceType();
tbDeviceType.setTypeId(1l);
tbDeviceType.setTypeName("消防器材");
deviceTypeMapper.insert(tbDeviceType);
TbDeviceType tbDeviceType1 = new TbDeviceType();
tbDeviceType1.setTypeId(2l);
tbDeviceType1.setTypeName("健身器材");
deviceTypeMapper.insert(tbDeviceType1);
}resultado:
Ambos tb_device_types das duas bibliotecas inseriram dois dados.
5. Conseguir separação entre leitura e escrita
1. Construa um banco de dados de sincronização mestre-escravo
- Princípio de sincronização mestre-escravo
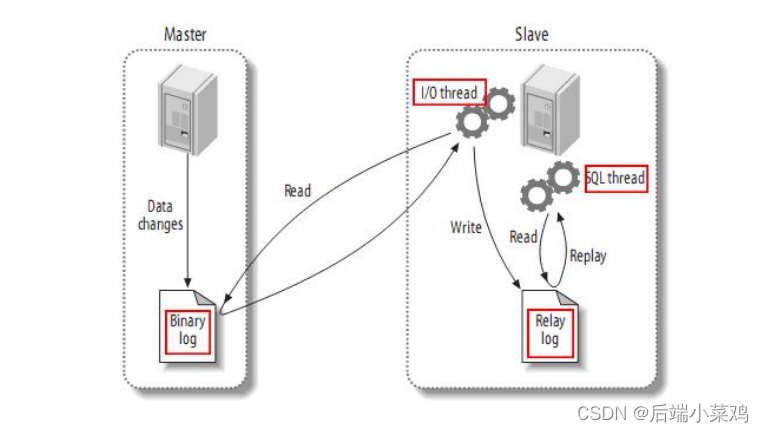
Mestre grava dados no log binário. O Slave lê os dados do Binlog do nó mestre no arquivo de log do relaylog local. Neste momento, o Slave sincroniza continuamente com o Master, e os dados existem no relaylog em vez de caírem no banco de dados. Então o Slave inicia um thread para gravar os dados do relaylog no banco de dados.
- Prepare o banco de dados Master e o banco de dados Slave
Crie docker-compose.yml em usr/local/docker/mysql e escreva:
version: '3.1'
services:
mysql:
restart: "always"
image: mysql:5.7.25
container_name: mysql-test-master
ports:
- 3308:3308
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123456
command:
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
--max_allowed_packet=128M
--server-id=47
--log_bin=master-bin
--log_bin-index=master-bin.index
--skip-name-resolve
--sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO"
volumes:
- mysql-data:/var/lib/mysql
volumes:
mysql-data:
version: '3.1'
services:
mysql:
restart: "always"
image: mysql:5.7.25
container_name: mysql-test-slave
ports:
- 3309:3309
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123456
command:
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
--max_allowed_packet=128M
--server-id=48
--relay-log=slave-relay-bin
--relay-log-index=slave-relay-bin.index
--log-bin=mysql-bin
--log-slave-updates=1
--sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO"
volumes:
- mysql-data:/var/lib/mysql1
volumes:
mysql-data:Comece a usar docker-compose up -d
Preste atenção na configuração:
Biblioteca principal:
ID do serviço: server-id=47
Ativar log binário: log_bin=master-bin
binlog:log_bin-index=master-bin.index
Da Biblioteca:
ID do serviço: server-id=48
Ativar log de retransmissão: relay-log-index=slave-relay-bin.index
Ativar log de retransmissão: relay-log=slave-relay-bin
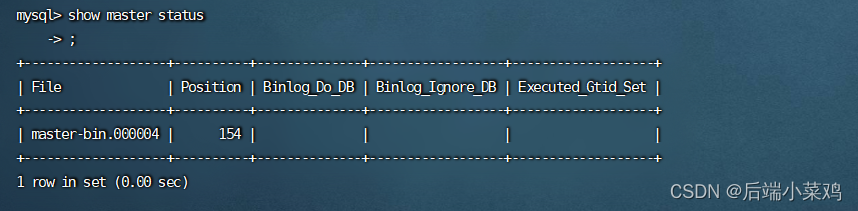
Use o comando bash para entrar no contêiner da biblioteca principal mestre e use show master status para visualizar o nome e o deslocamento do arquivo de registro.
 Use o comando bash para entrar no contêiner escravo e execute os seguintes comandos em sequência:
Use o comando bash para entrar no contêiner escravo e execute os seguintes comandos em sequência:
#登录从服务
mysql -u root -p;
#设置同步主节点:
CHANGE MASTER TO
MASTER_HOST='主库地址',
MASTER_PORT=3306,
MASTER_USER='root',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='master-bin.000006',
MASTER_LOG_POS=154;
#开启slave
start slave;
Neste ponto, o cluster de sincronização mestre-escravo está concluído.
Crie o banco de dados db_device na biblioteca principal e crie tabelas na biblioteca:
CREATE TABLE `tb_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;Verificou-se que a tabela também foi criada de forma síncrona no banco de dados escravo após a atualização.
2. Use sharding-jdbc para obter separação de leitura e gravação
- Gravar arquivo de configuração
spring.shardingsphere.datasource.names=s0,m0
#配置主数据源
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/db_device?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
# 配置从数据源
spring.shardingsphere.datasource.s1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.url=jdbc:mysql://localhost:3306/db_device?serverTimezone=UTC&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.s1.username=root
spring.shardingsphere.datasource.s1.password=123456
# 分配读写规则
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names[0]=s0
# 确定实际表
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds0.tb_user
# 确定主键⽣成策略
spring.shardingsphere.sharding.tables.t_dict.key-generator.column=id
spring.shardingsphere.sharding.tables.t_dict.key-generator.type=SNOWFLAKE
# 开启显示sql语句
spring.shardingsphere.props.sql.show = true- Testar dados de gravação
@Test
void testInsertUser(){
for (int i = 0; i < 10; i++) {
TbUser user = new TbUser();
user.setName(""+i);
userMapper.insert(user);
}
Neste momento, todos os dados serão gravados apenas no banco de dados mestre e depois sincronizados com o banco de dados escravo.
- Teste de leitura de dados
Test
void testQueryUser(){
List<TbUser> tbUsers = userMapper.selectList(null);
tbUsers.forEach( tbUser -> System.out.println(tbUser));
}Neste momento, todos os dados são lidos do banco de dados escravo.
6. Princípio de implementação – modo de conexão
O ShardingSphere usa um conjunto de mecanismos de execução automatizados para enviar com segurança e eficiência o SQL real após roteamento e reescrita para a fonte de dados subjacente para execução. Ele não simplesmente envia SQL diretamente para a fonte de dados para execução por meio de JDBC; nem coloca solicitações de execução diretamente no pool de threads para execução simultânea. Ele presta mais atenção ao equilíbrio do consumo causado pela criação da conexão da fonte de dados e pelo uso da memória, bem como à maximização da utilização razoável da simultaneidade e outros problemas. O objetivo do mecanismo de execução é equilibrar automaticamente o controle de recursos e a eficiência de execução.
6.1.Modo de conexão
Do ponto de vista do controle de recursos , o número de conexões para usuários empresariais acessarem o banco de dados deve ser limitado . Ele pode efetivamente impedir que uma determinada operação comercial ocupe muitos recursos, esgotando assim os recursos de conexão com o banco de dados e afetando o acesso normal de outras empresas. Especialmente quando há muitas tabelas de fragmentos em uma instância de banco de dados, um SQL lógico que não contém uma chave de fragmento gerará um grande número de SQLs reais que caem em tabelas diferentes no mesmo banco de dados.Se cada SQL real ocupar um Se houver um conexão independente, então uma consulta sem dúvida ocupará muitos recursos. ( modo de memória limitada )
Do ponto de vista da eficiência de execução , manter uma conexão de banco de dados independente para cada consulta de fragmento pode tornar o uso mais eficaz do multithreading para melhorar a eficiência da execução. Ao abrir um thread independente para cada conexão de banco de dados, o consumo causado pela E/S pode ser processado em paralelo . Manter uma conexão de banco de dados independente para cada fragmento também pode evitar o carregamento prematuro de dados de resultados de consulta na memória. Uma conexão de banco de dados independente pode conter uma referência à posição do cursor do conjunto de resultados da consulta e mover o cursor quando os dados correspondentes precisarem ser obtidos . ( Modo de restrição de conexão )
O método de mesclagem de resultados movendo o cursor do conjunto de resultados para baixo é chamado de mesclagem de streaming . Ele não precisa carregar todos os dados de resultados na memória , o que pode efetivamente economizar recursos de memória e, assim, reduzir a frequência da coleta de lixo. Quando não é possível garantir que cada consulta fragmentada mantenha uma conexão de banco de dados independente, o conjunto de resultados da consulta atual precisa ser carregado na memória antes de reutilizar a conexão com o banco de dados para obter o conjunto de resultados da consulta da próxima tabela fragmentada . Portanto, mesmo que a mesclagem de streaming possa ser usada, ela degenerará em mesclagem de memória nesse cenário.
Por um lado, é controlar e proteger os recursos de conexão do banco de dados e, por outro lado, é adotar um melhor modo de mesclagem para economizar recursos de memória do middleware.Como lidar com o relacionamento entre os dois é o que o mecanismo de execução ShardingSphere precisa para resolver. Especificamente, se uma parte do SQL precisar operar 200 tabelas em uma determinada instância de banco de dados após ser dividida pelo ShardingSphere. Então, devemos optar por criar 200 conexões e executá-las em paralelo ou optar por criar uma conexão e executá-las em série? Como devemos escolher entre eficiência e controle de recursos?
Para os cenários acima, o ShardingSphere fornece uma solução. Propõe o conceito de Modo de Conexão e o divide em dois tipos: modo de restrição de memória (MEMORY_STRICTLY) e modo de restrição de conexão (CONNECTION_STRICTLY).
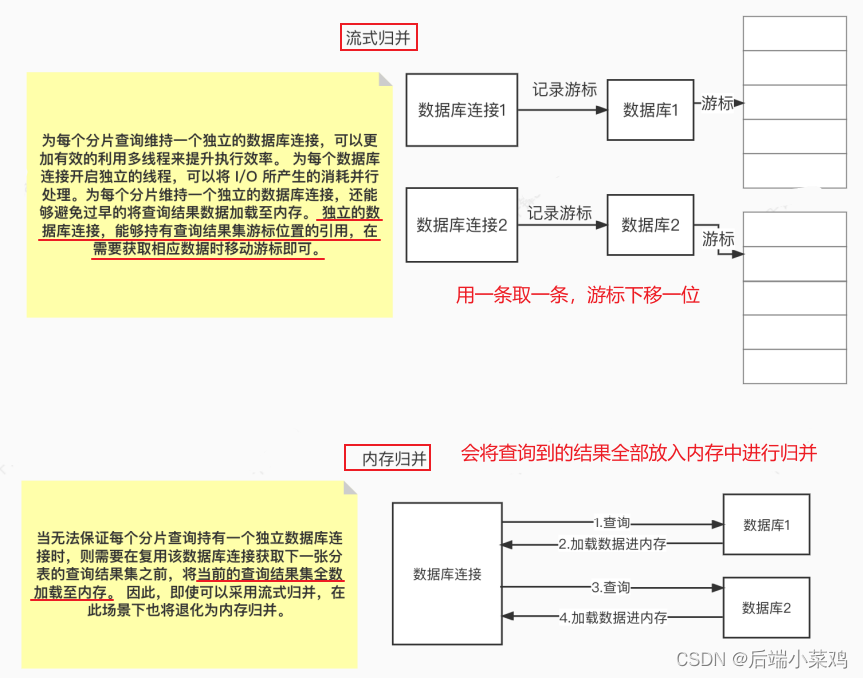
6.1.1. Modo limitado de memória
A premissa para usar esse modo é que o ShardingSphere não limita o número de conexões de banco de dados consumidas por uma operação . Se o SQL realmente executado exigir operações em 200 tabelas em uma instância de banco de dados, crie uma nova conexão de banco de dados para cada tabela e processe-a simultaneamente por meio de multithreading para maximizar a eficiência da execução. E quando as condições SQL são atendidas, a mesclagem de streaming é preferida para evitar estouro de memória ou coleta de lixo frequente.
6.1.2. Modo de restrição de conexão
A premissa para usar este modo é que o ShardingSphere controla estritamente o número de conexões de banco de dados consumidas para uma operação . Se o SQL realmente executado exigir operações em 200 tabelas em uma instância de banco de dados, apenas uma conexão exclusiva com o banco de dados será criada e as 200 tabelas serão processadas serialmente. Se os fragmentos de uma operação estiverem espalhados em bancos de dados diferentes, o multithreading ainda será usado para processar as operações em bibliotecas diferentes, mas cada operação de cada biblioteca ainda criará apenas uma conexão de banco de dados exclusiva. Isso pode evitar problemas causados pela utilização de muitas conexões de banco de dados para uma solicitação. Este modo sempre seleciona a coalescência de memória.
6.2. Mecanismo de execução automatizado
O ShardingSphere inicialmente deixa a decisão de qual modo usar para a configuração do usuário, permitindo que os desenvolvedores escolham usar o modo com memória limitada ou o modo com conexão limitada com base nos requisitos reais do cenário de seus próprios negócios.
Para reduzir os custos de uso do usuário e tornar o modo de conexão dinâmico, o ShardingSphere refinou a ideia de um mecanismo de execução automatizado e digeriu internamente o conceito do modo de conexão. Os usuários não precisam saber o que são os chamados modo de limite de memória e modo de limite de conexão, mas permitem que o mecanismo de execução selecione automaticamente o plano de execução ideal com base no cenário atual.
O mecanismo de execução automatizado refina a granularidade de seleção do modo de conexão para cada operação SQL. Para cada solicitação SQL, o mecanismo de execução automatizado realizará cálculos e compensações em tempo real com base em seus resultados de roteamento e executará de forma autônoma usando o modo de conexão apropriado para alcançar o equilíbrio ideal entre controle e eficiência de recursos. Para motores de execução automatizados, o usuário só precisa configurar maxConnectionSizePerQuery .Este parâmetro indica o número máximo de conexões permitidas para cada banco de dados durante uma consulta.
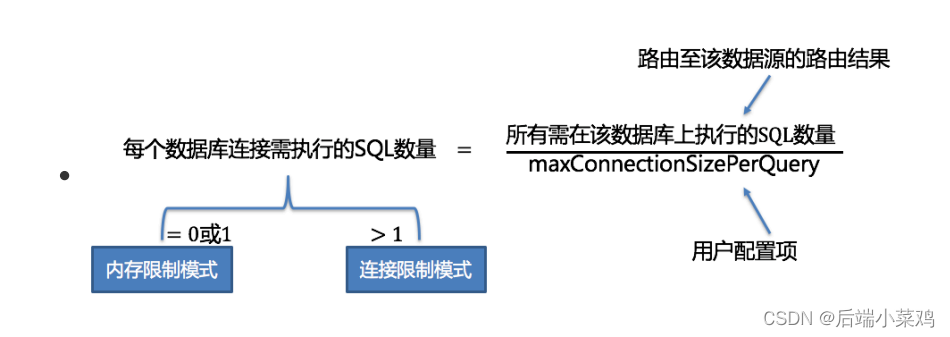
Dentro do intervalo permitido por maxConnectionSizePerQuery , quando o número de solicitações que uma conexão precisa realizar é maior que 1, significa que a conexão atual com o banco de dados não pode conter o conjunto de resultados de dados correspondente e a mesclagem de memória deve ser usada; inversamente, quando um When o número de solicitações que precisam ser executadas pela conexão é igual a 1, significa que a conexão de banco de dados atual pode conter o conjunto de resultados de dados correspondente e a mesclagem de streaming pode ser usada . Cada seleção de modo de conexão é específica para cada banco de dados físico. Ou seja, em uma mesma consulta, caso ela seja roteada para mais de um banco de dados, o modo de conexão de cada banco de dados não é necessariamente o mesmo, podendo existir de forma mista. (Quando o maxConnectionSizePerQuery definido pelo usuário / o número de todos os SQLs que precisam ser executados no banco de dados for igual a 0 ou 1, será utilizado o modo de limite de memória . Se for maior que 1 , o modo de limite de conexão será usado )