Diretório de artigos
- Guia de primeiros passos do Python OpenCV
Guia de primeiros passos do Python OpenCV
OpenCV é uma poderosa biblioteca de visão computacional que pode ser usada para processar dados de imagem e vídeo, bem como realizar tarefas como detecção e rastreamento de alvos. , você aprenderá como usar Python para escrever código OpenCV para processamento e análise de imagens básicas e avançadas.
Aprender OpenCV pode ajudá-lo a dominar tecnologias básicas de processamento de imagens, incluindo leitura e processamento de imagens, processamento de limites, funções morfológicas, correspondência de modelos, filtros, processamento gráfico, processamento de vídeo e detecção de rosto. Essas tecnologias são conteúdos básicos nas áreas de visão computacional e processamento de imagens, sendo também a base das redes neurais convolucionais. Ao aprender OpenCV, você pode compreender melhor os princípios de funcionamento e aplicações das redes neurais convolucionais. Ao mesmo tempo, OpenCV também é uma biblioteca de processamento de imagem muito popular, dominá-la pode ajudá-lo a processar e analisar melhor os dados da imagem.
Livros de referência: Python Opencv da entrada ao domínio
Instale o OpenCV
Antes de começarmos a escrever o código OpenCV, precisamos primeiro instalar a biblioteca OpenCV. Podemos instalá-lo através do gerenciador de pacotes pip:
pip install opencv-python
Você pode usar conda ou micromamba para instalar o ambiente virtual e instalar o ambiente de notebook
Imprimir versão opencv
import cv2
print("OpenCV version:")
print(cv2.__version__)
Versão OutputOpenCV
:
4.7.0
Fundamentos
Leitura e exibição de imagens
Antes de começarmos a trabalhar com imagens, precisamos aprender a lê-las e exibi-las. O código abaixo demonstra como ler e exibir uma imagem usando a biblioteca OpenCV:
import cv2
leia a imagem
img = cv2.imread('image.jpg')
mostrar imagem
exibição opencv
cv2.imshow('Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()`
No código acima, primeiro cv2.imread()lemos um image.jpgarquivo de imagem nomeado usando a função. Em seguida, usamos cv2.imshow()uma função para exibir esta imagem e usamos cv2.waitKey()a cv2.destroyAllWindows()função e para esperar que o usuário pressione qualquer tecla e então feche a janela de exibição.
Observe que se você usar notebook para executar a exibição waitKey(0), haverá um problema de que ele não poderá ser exibido durante a segunda execução. Você pode definir cv2.waitKey(3) para encerrar automaticamente o horário especificado.
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
img = cv2.imread('image.jpg')
rgbimg = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) #opencv像素顺序是bgr
plt.title(title)
plt.imshow(img, cmap=cmap)
plt.show()
Cortar imagem
Começando nas coordenadas (200, 100) do canto superior esquerdo, corte uma área retangular com largura de 400 pixels e altura de 400 pixels.
cropped = img[100:500, 200:600]
Operações de pixels
No OpenCV, uma imagem pode ser representada como um array tridimensional, onde cada elemento é um número que representa um valor de pixel. As dimensões da matriz de imagens dependem do tamanho da imagem e do número de canais. Para um tamanho de altura×largura altura×larguraolá _ _ _ _ _×A imagem colorida de largura , seu formato de matriz é (altura, largura, 3), onde 3 representa três canais de cores, ou seja , BGR . BGR refere-se aos três canais azul, verde e vermelho, porque os canais de cores da imagem no OpenCV são organizados na ordem B, G e R.
Para acessar e modificar valores de pixels em uma imagem, você pode usar a indexação de array numpy, por exemplo:
import numpy as np
img = cv2.imread("image.jpg")
# 获取图像宽高
height, width = img.shape[:2]
# 获取某个像素的BGR值
# 在OpenCV中,通常使用img[y,x]的方式来访问图像的像素值,其中y是像素的行坐标,x是像素的列坐标。因此,在你# 提到的img[20, 100]中,20是y坐标,100是x坐标。
b, g, r = img[20, 100]
# 设置某个像素的BGR值
img[100, 100] = (255, 255, 255)
# 获取某个通道的所有像素值
blue_channel = img[:, :, 0]
green_channel = img[:, :, 1]
red_channel = img[:, :, 2]
# 修改某个通道的所有像素值
img[:, :, 0] = 0 # 将蓝色通道设为0`
Observe que no OpenCV, a ordem dos canais é BGR em vez de RGB.
Espaços de cores e canais
OpenCV suporta vários espaços de cores, como RGB, HSV, YCrCb, Lab, etc. Diferentes espaços de cores correspondem a diferentes canais. Por exemplo, o espaço de cores RGB possui três canais, nomeadamente canais vermelho, verde e azul. Para realizar o processamento de imagens, geralmente precisamos converter o espaço de cores e os canais da imagem.
A seguir estão algumas funções de espaço de cores e conversão de canal comumente usadas no OpenCV:
- cv2.cvtColor(src, code[, dst[, dstCn]]): Converte uma imagem de um espaço de cores para outro. Entre eles, src é a imagem de entrada, code é o código de conversão do espaço de cores, dst é a imagem de saída e dstCn é o número de canais da imagem de saída.
Por exemplo, converta uma imagem no formato BGR em uma imagem em tons de cinza:
img = cv2.imread('test.jpg')
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- cv2.split(src[, mv]): Divida imagens multicanal em imagens de canal único. Entre eles, src é a imagem de entrada e mv é uma lista de imagens de saída de canal único.
Por exemplo, divida uma imagem no formato BGR em três canais:
img = cv2.imread('test.jpg')
b, g, r = cv2.split(img)
- cv2.merge(mv[, dst]): Mescla várias imagens de canal único em uma imagem multicanal. Entre eles, mv é uma lista de imagens de canal único e dst é a imagem de saída multicanal.
Por exemplo, mescle três imagens de canal único em uma imagem no formato BGR:
b = cv2.imread('test_b.jpg', cv2.IMREAD_GRAYSCALE)
g = cv2.imread('test_g.jpg', cv2.IMREAD_GRAYSCALE)
r = cv2.imread('test_r.jpg', cv2.IMREAD_GRAYSCALE)
img = cv2.merge([b, g, r])
- cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst]): Fusão de duas imagens de acordo com uma determinada proporção. Entre eles, src1 e src2 são duas imagens de entrada, alfa e beta são os pesos das duas imagens, gama é o valor de ajuste de brilho e dst é a imagem fundida de saída.
Por exemplo, fundir duas imagens em tons de cinza em uma proporção de 1:2:
img1 = cv2.imread('test1.jpg', cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread('test2.jpg', cv2.IMREAD_GRAYSCALE)
img = cv2.addWeighted(img1, 1, img2, 2, 0)
O espaço de cores BGR é baseado nas três cores primárias, que se referem ao vermelho, verde e azul.
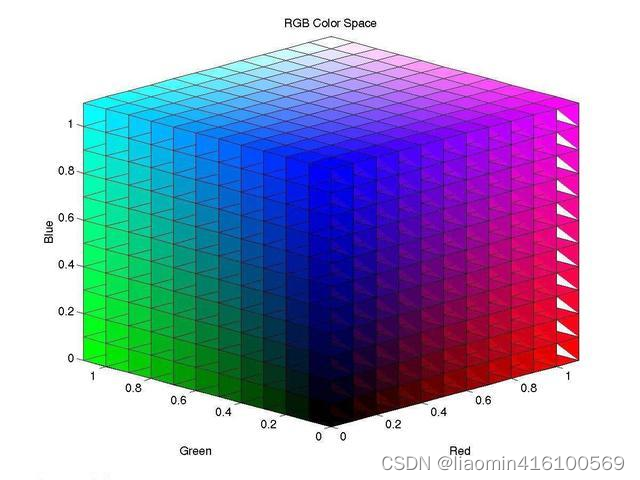
O espaço de cores HSV é baseado em matiz, saturação e brilho.

Entre eles, matiz (H) refere-se à cor da luz. Por exemplo, vermelho, laranja, amarelo, verde, ciano, azul e roxo no arco-íris representam matizes diferentes. No OpenCV, o matiz é obtido no intervalo [0 , 180] valor. Por exemplo, os valores de matiz que representam vermelho, amarelo, verde e azul são 0, 30, 60 e 120, respectivamente.
Saturação (S) refere-se à profundidade de uma cor. No OpenCV, a saturação assume valores no intervalo [0, 255]. Quando a saturação é 0, a imagem se torna uma imagem em tons de cinza.
Brilho (V) refere-se ao brilho ou escuridão da luz. Assim como a saturação, no OpenCV o brilho assume valores no intervalo [0, 255]. Quanto maior o valor do brilho, mais brilhante será a imagem; quando o valor do brilho for 0, a imagem ficará em preto puro
Transformação geométrica de imagem
OpenCV fornece muitas funções básicas de transformação de imagem, que podem ser usadas para redimensionamento, rotação, tradução, corte de imagem e outras operações. O código a seguir demonstra como usar essas funções:
Ampliar imagem
Reduziu o objeto de imagem img pela metade e atribuiu-o para redimensionamento
resized = cv2.resize(img, (int(img.shape[1]/2), int(img.shape[0]/2)))
Transformação afim
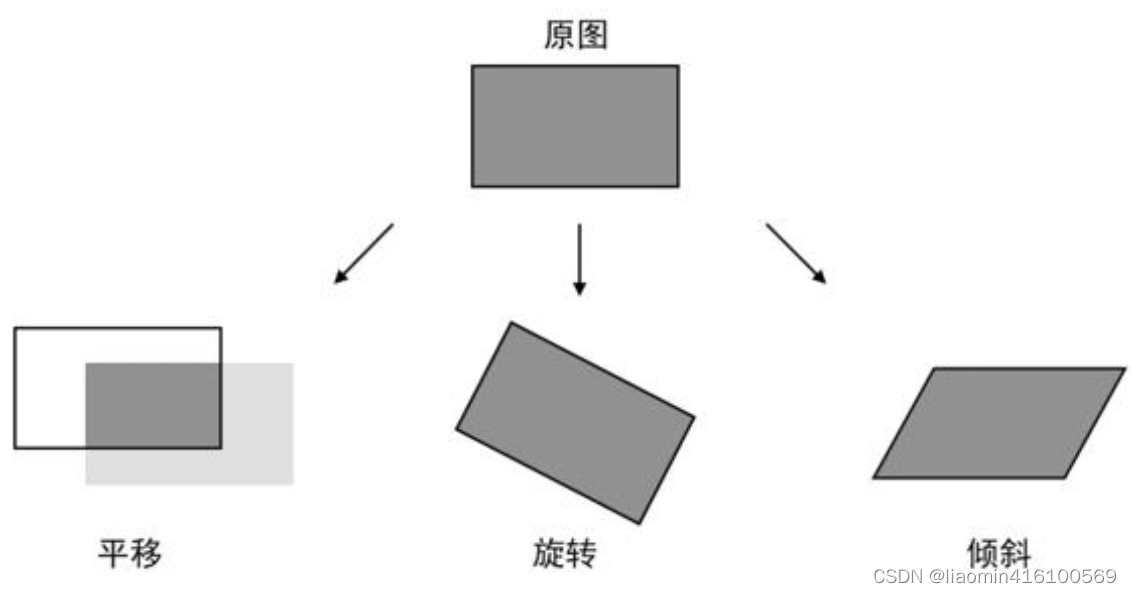
A transformação afim é uma deformação geométrica que ocorre apenas em um plano bidimensional. A imagem transformada ainda pode manter a "retidão" e o "paralelismo" das linhas retas. Ou seja, as linhas retas originais ainda são linhas retas e linhas paralelas após a transformação. Após a transformação, eles ainda são linhas paralelas. Os efeitos comuns de transformação afim são mostrados na figura, incluindo translação, rotação e inclinação.
OpenCV usa o método cv2.warpAffine() para obter o efeito de transformação afim. Sua sintaxe é a seguinte:
dst = cv2.warpAffine(src, M, dsize, flags, borderMode, borderValue)
Descrição do parâmetro:
- src: imagem original.
- M: Uma matriz com 2 linhas e 3 colunas. A posição do pixel na imagem original é transformada de acordo com o valor desta matriz.
- dsize: O tamanho da imagem de saída.
- flags: parâmetro opcional, método de interpolação, valor padrão é recomendado.
- borderMode: parâmetro opcional, tipo de borda, recomenda-se utilizar o valor padrão.
- borderValue: parâmetro opcional, valor da borda, o padrão é 0, é recomendado usar o valor padrão.
Descrição do valor de retorno:
- dst: Imagem de saída após transformação de reflexão.
M também é chamada de matriz afim. Na verdade, é uma lista 2×3 com o seguinte formato:
M = [[a, b, c],[d, e, f]]
O tipo de transformação afim realizada na imagem depende inteiramente do valor de M. A saída da imagem pela transformação afim é calculada de acordo com a seguinte fórmula:
新x = 原x × a + 原y × b + c
新y = 原x × d + 原y × e + f
O x original e o y original representam a abcissa e a ordenada do pixel na imagem original, e o novo x e o novo y representam a abcissa e a ordenada do mesmo pixel na nova imagem após a transformação afim.
Panorâmica da imagem
A tradução move todos os pixels da imagem horizontalmente ou verticalmente ao mesmo tempo. Para conseguir este efeito, você só precisa definir o valor de M de acordo com o seguinte formato:
M = [[1, 0, distância de movimento horizontal], [0, 1, distância de movimento vertical]] Os
pixels da imagem original serão estar de acordo com a seguinte fórmula Transformar:
novo x = original x × 1 + original y × 0 + distância de movimento horizontal = original x + distância de movimento horizontal
novo y = original x × 0 + original y × 1 + distância de movimento vertical = original y + distância vertical movida
M = np.float32([[1, 0, 100], [0, 1, 50]])
translated = cv2.warpAffine(img, M, (img.shape[1], img.shape[0]))

Girar imagem
Primeiro, o número de linhas e colunas do objeto de imagem img é obtido e atribuído às variáveis rows e cols respectivamente. Em seguida, use a função cv2.getRotationMatrix2D para gerar uma matriz de rotação M,
na qual o primeiro parâmetro são as coordenadas do ponto central de rotação, aqui é o ponto central da imagem (cols/2, rows/2); o segundo parâmetro é
o ângulo de rotação, aqui é 30 graus;
o terceiro parâmetro é a taxa de escala após a rotação, aqui é 1, indicando que não há escala. Finalmente, use a função cv2.warpAffine para girar o objeto de imagem original img de acordo com a matriz de rotação M e atribua o resultado a girado. O primeiro parâmetro da função warpAffine é o objeto de imagem original que precisa ser girado. O segundo parâmetro é a matriz de rotação. O terceiro parâmetro é o tamanho da imagem de saída. A largura e a altura da imagem original são usadas aqui. A função retorna o objeto de imagem girado.
rows, cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols/2, rows/2), 30, 1)
rotated = cv2.warpAffine(img, M, (cols, rows))

inclinar imagem
O OpenCV precisa localizar três pontos da imagem para calcular o efeito de inclinação. As posições dos três pontos são mostradas na figura. Esses três pontos são o ponto A do "canto superior esquerdo", o ponto B do "canto superior direito" e o "canto inferior esquerdo" ponto C. OpenCV calculará as mudanças de posição de outros pixels com base nas mudanças de posição desses três pontos. Por ser necessário garantir a "linearidade" e o "paralelismo" da imagem, não há necessidade de utilizar o ponto no "canto inferior direito" como quarto parâmetro. A posição do ponto no canto inferior direito é automaticamente calculado com base nas mudanças nos três pontos A, B e C. fora.
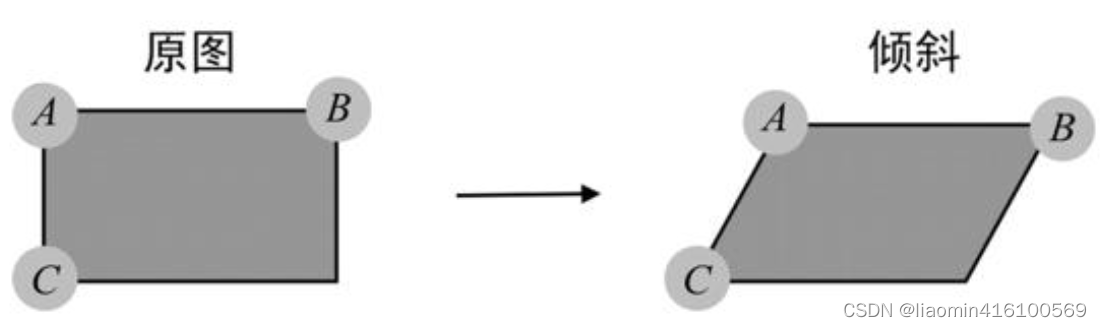
"Planicidade" significa que as linhas retas na imagem ainda são linhas retas após a transformação afim. "Paralelismo" significa que as linhas paralelas em uma imagem ainda são linhas paralelas após a transformação afim.
A inclinação da imagem também precisa ser obtida por meio da matriz M, mas a obtenção dessa matriz requer operações muito complexas, portanto, o OpenCV fornece o método getAffineTransform() para calcular automaticamente a matriz M da imagem inclinada. A sintaxe do método getRotationMatrix2D() é a seguinte:
M = cv2.getAffineTransform(src, dst)
descrição do parâmetro:
- src: coordenadas de 3 pontos da imagem original, formatadas como uma lista de números de ponto flutuante de 32 bits com 3 linhas e 2 colunas, por exemplo: [[0, 1], [1, 0], [1, 1] ].
- dst: coordenadas de 3 pontos da imagem inclinada, o formato é igual ao src.
Descrição do valor de retorno:
- M: Matriz afim calculada pelo método getAffineTransform().

rows,cols=len(image),len(image[0])
src=np.float32([[0,0],[cols-1,0],[0,rows-1]])
dst=np.float32([[0,50],[cols-1,0],[0,rows-1]])
M=cv2.getAffineTransform(src,dst)
destImg =cv2.warpAffine(image,M=M,dsize=(len(image[0]),len(image)))
plt.title("图像倾斜")
plt.imshow(cv2.cvtColor(destImg, cv2.COLOR_BGR2RGB))
plt.show()
imagem em perspectiva
Se o afim permite que a imagem se deforme em um plano bidimensional, então a perspectiva permite que a imagem se deforme em um espaço tridimensional. Observando objetos de diferentes ângulos, você verá diferentes imagens de deformação: por exemplo, um retângulo se tornará um quadrilátero irregular, um ângulo reto se tornará um ângulo agudo ou obtuso, um círculo se tornará uma elipse e assim por diante. A imagem após esta deformação é uma vista em perspectiva.
Visto da parte inferior da imagem), o olho está mais próximo da parte inferior da imagem, então a largura da parte inferior da imagem permanece a mesma, mas se o olho estiver mais distante do topo da imagem, a largura do a parte superior da imagem diminuirá proporcionalmente, de modo que o observador verá a perspectiva mostrada. Efeito.
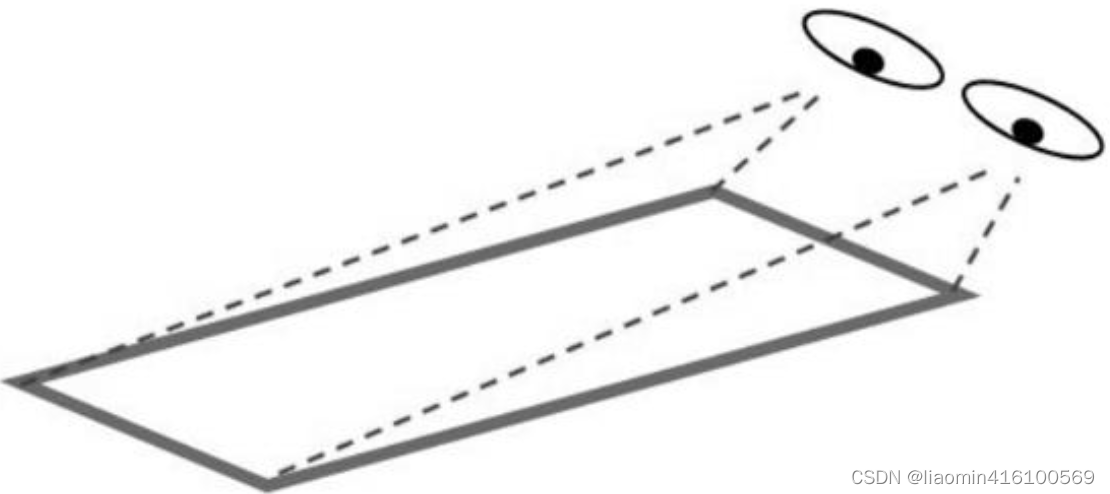
No OpenCV, o efeito de perspectiva precisa ser calculado localizando 4 pontos da imagem. As posições dos 4 pontos são mostradas na Figura 7.16. OpenCV calcula as mudanças de posição de outros pixels com base nas mudanças de posição desses 4 pontos. O efeito de perspectiva não pode garantir a “retidão” e o “paralelismo” da imagem.
O método warpPerspective() também precisa calcular o efeito de perspectiva através da matriz M, mas obter essa matriz requer operações muito complexas, então OpenCV fornece o método getPerspectiveTransform() para calcular automaticamente a matriz M. A sintaxe do método getPerspectiveTransform() é a seguinte:
M = cv2.getPerspectiveTransform(src, dst,)
Descrição do parâmetro:
- src: coordenadas de 4 pontos da imagem original, formatadas como uma lista de números de ponto flutuante de 32 bits com 4 linhas e 2 colunas, por exemplo: [[0, 0], [1, 0], [0, 1] ,[1, 1]] .
- dst: coordenadas de 4 pontos da vista em perspectiva, o formato é igual ao src.
Descrição do valor de retorno:
- M: Matriz afim calculada pelo método getPerspectiveTransform().
rows=len(image)
cols=len(image[0])
M=cv2.getPerspectiveTransform(np.array([[0,0],[cols-1,0],[0,rows-1],[cols-1,rows-1]],dtype=np.float32),
np.array([[100,0],[cols-1-100,0],[0,rows-1],[cols-1,rows-1]],dtype=np.float32)
)
dImag=cv2.warpPerspective(image,M,(cols,rows))
plt.imshow(dImag)
plt.title("透视")
plt.show()

Limiar
Limiar é um conceito muito importante no processamento de imagens, semelhante a uma “linha padrão de valores de pixel”. Todos os valores de pixel são comparados com esta "linha padrão" e, finalmente, três resultados são obtidos: o valor do pixel é maior que o limite, o valor do pixel é menor que o limite ou o valor do pixel é igual ao limite. O programa agrupa todos os pixels com base nesses resultados e depois “queima” ou “clareia” um determinado grupo de pixels, tornando o contorno de toda a imagem mais distinto e mais fácil de identificar por um computador ou a olho nu.
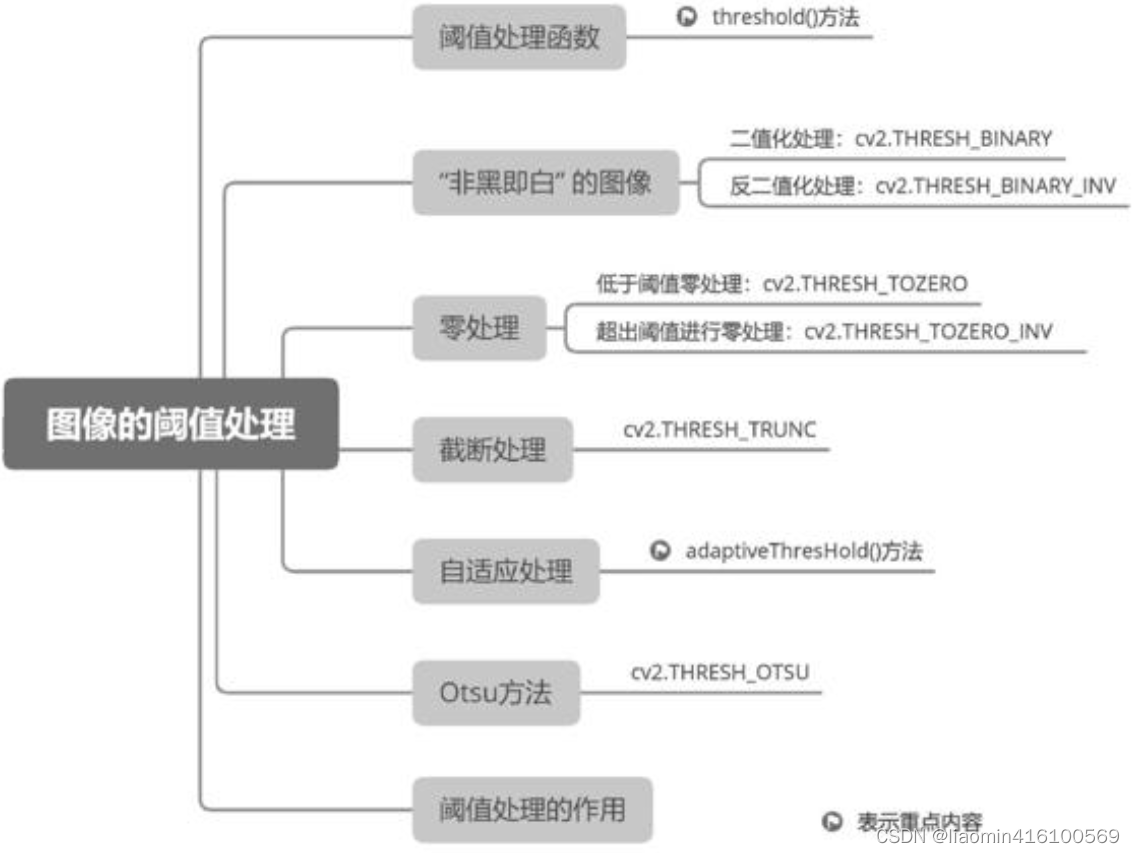
função de processamento de limite
No processo de processamento de imagens, o uso de limites torna os valores dos pixels da imagem mais uniformes, simplificando assim o efeito da imagem. Primeiro, converta uma imagem colorida em uma imagem em tons de cinza, para que a faixa de valores de pixel da imagem possa ser simplificada para 0 ~ 255. Em seguida, um valor limite é usado para fazer com que a imagem convertida em escala de cinza apresente um efeito visual apenas de preto puro e branco puro. Por exemplo, quando o limite é 127, todos os valores de pixels menores que 127 são convertidos em 0 (ou seja, preto puro) e todos os valores de pixels maiores que 127 são convertidos em 255 (ou seja, branco puro). Embora alguns detalhes da escala de cinza sejam perdidos, o contorno do objeto da imagem em escala de cinza será preservado de forma mais evidente.
O processamento de limites ocupa uma posição muito importante na tecnologia de visão computacional e é uma das lógicas de processamento subjacentes de muitos algoritmos avançados. Como as imagens binárias ignoram detalhes e ampliam recursos, e muitos algoritmos avançados analisam recursos de objetos com base em seus contornos, as imagens binárias são muito adequadas para operações complexas de reconhecimento. Antes de realizar a operação de reconhecimento, a imagem deve ser convertida em uma imagem em tons de cinza e depois binarizada, para que seja obtida a imagem de contorno (áspero) do objeto exigida pelo algoritmo.
O método limiar() fornecido pelo OpenCV é usado para limitar a imagem. A sintaxe do método limiar() é a seguinte:
retval, dst = cv2.threshold(src, thresh, maxval, type)
Descrição do parâmetro:
- src: A imagem que está sendo processada, que pode ser uma imagem multicanal.
- Thresh: Limite, o valor limite está entre 125 e 150 para o melhor efeito.
- maxval: o valor máximo usado para processamento de limite.
- type: tipo de processamento de limite. Tipos e significados comuns.
Descrição do valor de retorno:
- retval: o limite usado durante o processamento.
- dst: imagem com limite.
No OpenCV, existem os seguintes tipos de processamento de limite, bem como valores de enumeração correspondentes:
- THRESH_BINARY: Processamento de limite de binarização, pixels maiores que o limite são definidos como o valor máximo e pixels menores ou iguais ao limite são definidos como 0. O valor de enumeração é 0.
- THRESH_BINARY_INV: Processamento de limite de antibinarização, pixels menores que o limite são definidos como o valor máximo e pixels maiores ou iguais ao limite são definidos como 0. O valor da enumeração é 1.
- THRESH_TRUNC: Trunca o processamento do limite, define pixels maiores que o limite para o limite e pixels menores ou iguais ao limite permanecem inalterados. O valor da enumeração é 2.
- THRESH_TOZERO: O limite de processamento é 0, os pixels menores que o limite são definidos como 0 e os pixels maiores ou iguais ao limite permanecem inalterados. O valor da enumeração é 3.
- THRESH_TOZERO_INV: O processamento do limite inverso é 0, os pixels maiores que o limite são definidos como 0 e os pixels menores ou iguais ao limite permanecem inalterados. O valor da enumeração é 4.
Binarização
O processamento de binarização também é chamado de processamento de limite de binarização. Esse processamento permite que a imagem retenha apenas dois valores de pixel, ou todos os pixels só podem assumir valores de dois valores.
Ao realizar o processamento de binarização, cada valor de pixel será comparado com o limite, e o valor do pixel maior que o limite será alterado para o valor máximo, e o valor do pixel menor ou igual ao limite será alterado para 0. O cálculo a fórmula é a seguinte:
if 像素值 <= 阈值: 像素值 = 0
if 像素值 > 阈值: 像素值 = 最大值
Normalmente, o processamento de binarização usa 255 como valor máximo, porque em imagens em tons de cinza, 255 representa branco puro e 0 representa preto, que pode ser claramente distinguido do preto puro, de modo que a imagem em tons de cinza aparece "não preta" após a binarização. Efeito "instantaneamente branco" .
import matplotlib
import matplotlib.pyplot as plt
import cv2
grayimage=cv2.imread("../../images/demo1.png",0) #直接读取灰度图
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_BINARY)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("二值化图")
plt.show()

Observe que quanto maior o valor do pixel, mais branco ele é, e quanto menor o valor do pixel, mais escuro ele é.
Processamento anti-binarização
O processamento anti-binarização também é chamado de processamento de limite anti-binarização e seu resultado é o resultado oposto do processamento de binarização. Altere os valores de pixel maiores que o limite para 0 e altere os valores de pixel menores ou iguais ao limite para o valor máximo. As partes brancas da imagem original tornam-se pretas e as partes pretas tornam-se brancas. Calculado da seguinte forma:
if 像素值 <= 阈值: 像素值 = 最大值
if 像素值 > 阈值: 像素值 = 0
código
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_BINARY_INV)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("二值化图")
plt.show()

Se o OCR normalmente destaca o texto por meio de antibinarização, ele exibe o texto branco sobre um fundo preto e depois se expande (porque o branco é um número relativamente grande).

Processamento zero
manipulação abaixo do limite zero
O processamento abaixo do limite zero também é chamado de processamento zero de baixo limite. Esse processamento altera o valor do pixel abaixo ou igual ao limite para 0, e o valor do pixel acima do limite mantém o valor original. A fórmula de cálculo é a seguinte:
if 像素值 <= 阈值: 像素值 = 0
if 像素值 > 阈值: 像素值 = 原值
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_TOZERO)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("低于阈值零[置黑]处理")
plt.show()

Manuseio zero além do limite
O processamento zero acima do limite também é chamado de processamento zero superlimite.Esse processamento altera os valores dos pixels maiores que o limite para 0, e os valores dos pixels menores ou iguais ao limite permanecem em seus valores originais. Calculado da seguinte forma:
if 像素值 <= 阈值: 像素值 = 原值
if 像素值 > 阈值: 像素值 = 0
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_TOZERO_INV)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("超阈值零[置黑]处理")
plt.show()

Truncamento
O processamento de truncamento também é chamado de processamento de limite de truncamento. Esse processamento altera os valores de pixel na imagem que são maiores que o limite para o mesmo valor do limite, e os pixels que são menores ou iguais ao limite mantêm seus valores originais . A fórmula é a seguinte:
if 像素 <= 阈值: 像素 = 原值
if 像素 > 阈值: 像素 = 阈值
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_TRUNC)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("截断阈值处理")
plt.show()

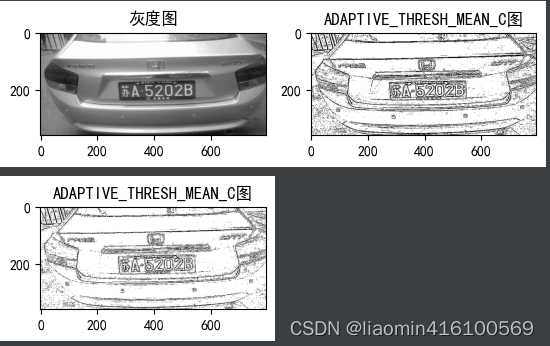
processamento adaptativo
OpenCV fornece uma técnica de limite aprimorada: diferentes limites são usados para diferentes áreas da imagem. Essa tecnologia aprimorada de processamento de limite é chamada de processamento de limite adaptativo, também conhecido como processamento adaptativo. O limite adaptativo é calculado de acordo com um algoritmo especificado com base em todos os valores de pixel em uma área quadrada da imagem. Comparado com os cinco tipos de processamento de limite explicados anteriormente, o processamento adaptativo pode lidar melhor com imagens com distribuição irregular de claro e escuro e obter efeitos de imagem mais simples.
OpenCV fornece o método adaptiveThresHold() para processamento adaptativo de imagens. A sintaxe do método adaptiveThresHold() é a seguinte:
dst = cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, limiarType, blockSize, C)
Descrição do parâmetro:
- src: a imagem que está sendo processada. Deve-se observar que a imagem precisa ser uma imagem em tons de cinza.
- maxValue: o valor máximo usado para processamento de limite.
- adaptiveMethod: Método de cálculo do limite adaptativo. O método de cálculo e o significado do limite adaptativo são mostrados na Tabela 8.2.
Método de cálculo de limite adaptativo e seu significado
ADAPTIVE_THRESH_MEAN_C: pondera igualmente todos os pixels em uma área quadrada.
ADAPTIVE_THRESH_GAUSSIAN_C: Todos os pixels em uma área quadrada são ponderados de acordo com a distância entre o pixel e o ponto central com base na função Gaussiana. - limiarType: tipo de processamento de limite; deve-se observar que o tipo de processamento de limite deve ser cv2.THRESH_BINARY ou cv2.THRESH_BINARY_INV.
- blockSize: O tamanho de uma área quadrada. Por exemplo, 5 refere-se a uma área 5×5.
- C: constante. O limite é igual à média ou valor ponderado menos esta constante.
Descrição do valor de retorno: - dst: imagem após processamento de limite.
O processamento adaptativo retém informações mais detalhadas na imagem e preserva de forma mais óbvia o contorno do assunto da imagem em tons de cinza.
plt.subplot(221)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(222)
meanImg=cv2.adaptiveThreshold(grayimage,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,5,3)
plt.imshow(meanImg,cmap="gray")
plt.title("ADAPTIVE_THRESH_MEAN_C图")
plt.show()
plt.subplot(223)
guassImg=cv2.adaptiveThreshold(grayimage,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,5,3)
plt.imshow(guassImg,cmap="gray")
plt.title("ADAPTIVE_THRESH_MEAN_C图")
plt.show()
Método Otsu
No processo dos cinco tipos de processamento de limite anteriores, o limite definido para cada instância é 127, que não é calculado pelo algoritmo. Para algumas imagens, quando o limite é definido como 127, o efeito obtido não é bom, neste caso é necessário tentar uma por uma até encontrar o limite mais adequado.
Encontrar os limites mais apropriados, um por um, não é apenas muito trabalhoso, mas também ineficiente. Para isso, OpenCV disponibiliza o método Otsu. O método Otsu pode percorrer todos os limites possíveis e encontrar o limite mais apropriado.
A sintaxe do método Otsu é basicamente a mesma do método limiar(), exceto que ao passar parâmetros para o tipo, mais um parâmetro deve ser passado, ou seja, cv2.THRESH_OTSU. A função de cv2.THRESH_OTSU é implementar o processamento de limite do método Otsu. A sintaxe do método Otsu é a seguinte:
retval, dst = cv2.threshold(src, thresh, maxval, type)
descrição do parâmetro:
- src: a imagem que está sendo processada. Deve-se observar que a imagem precisa ser uma imagem em tons de cinza.
- thresh: Limite e defina o limite como 0.
- maxval: O valor máximo usado para processamento de limite, que é 255.
- type: tipo de processamento de limite. Além de selecionar um tipo de processamento limite na Tabela 8.1, mais um parâmetro deve ser passado, nomeadamente cv2.THRESH_OTSU. Por exemplo, cv2.THRESH_BINARY+cv2.THRESH_OTSU.
Descrição do valor de retorno:
- retval: O limite mais adequado calculado e utilizado pelo método Otsu.
- dst: imagem com limite.
plt.subplot(221)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(222)
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_BINARY)
plt.imshow(dst,cmap="gray")
plt.title("二值化图")
plt.show()
plt.subplot(223)
_,ostuImg=cv2.threshold(grayimage,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
plt.imshow(ostuImg,cmap="gray")
plt.title("OTSU图")
plt.show()

Capítulo avançado
correspondência de modelo
O modelo é a imagem do alvo que está sendo pesquisado, e o processo de encontrar a posição do modelo na imagem original é chamado de correspondência de modelo. O método matchTemplate() fornecido pelo OpenCV é o método de correspondência de modelos e sua sintaxe é a seguinte:
result = cv2.matchTemplate(image, templ, method, mask)
Descrição do parâmetro:
- imagem: imagem original.
- templ: Imagem modelo, o tamanho deve ser menor ou igual à imagem original.
- método: método de correspondência, os valores dos parâmetros disponíveis são mostrados na Tabela 10.1.
- máscara: parâmetro opcional. Máscara, apenas cv2.TM_SQDIFF e cv2.TM_CCORR_NORMED suportam este parâmetro, é recomendado usar o valor padrão.
Descrição do valor de retorno: - resultado: resultado de correspondência calculado. Se a largura e a altura da imagem original forem W e H respectivamente, e a largura e a altura da imagem do modelo forem w e h respectivamente, o resultado será uma matriz de ponto flutuante de 32 bits com colunas W-w+1 e H- h+1 linhas. Cada número de ponto flutuante na matriz é o resultado correspondente da posição do pixel correspondente na imagem original e seu significado precisa ser interpretado de acordo com o parâmetro do método.
Durante o cálculo da correspondência do modelo, o modelo é movido dentro da imagem original. Compare o modelo e os pixels na área sobreposta, um por um, e finalmente salve o resultado da comparação na posição da matriz correspondente à posição do índice de pixel no canto superior esquerdo do modelo
A função matchTemplate do OpenCV é usada para encontrar correspondências em uma imagem com outra imagem. Durante o processo de correspondência, você pode escolher diferentes métodos de correspondência, que são os parâmetros do método. Os parâmetros de método comumente usados incluem os seguintes:
- cv2.TM_SQDIFF: método de correspondência de diferenças quadradas, o método de correspondência mais simples, que calcula a soma das diferenças quadradas. Quanto menor o valor, melhor a correspondência.
- cv2.TM_SQDIFF_NORMED: Método padrão de correspondência de diferenças quadradas, que também calcula a soma das diferenças quadradas, mas padroniza os resultados. Observe que a distância usada para calcular a imagem correspondente deve ser menor que a imagem original
- cv2.TM_CCORR: método de correspondência de correlação, #, quanto maior o valor, melhor será a correspondência.
- cv2.TM_CCORR_NORMED: Método de correspondência de correlação padrão, padroniza os resultados. Quanto maior o valor de retorno, maior o grau de correspondência, e quanto menor o valor, menor o grau de correspondência.
Este parâmetro utiliza o modo de correspondência de coeficiente de correlação normalizado e
retorna o coeficiente de correlação entre a imagem correspondente e a imagem do modelo. O intervalo de valores está entre 0 e 1, com 1 indicando uma correspondência perfeita e 0 indicando nenhuma correspondência.
- cv2.TM_CCOEFF: Método de correspondência do coeficiente de correlação, calcula o coeficiente de correlação de duas imagens. Quanto maior o valor, melhor a correspondência.
- cv2.TM_CCOEFF_NORMED: Método de correspondência de coeficiente de correlação padrão para padronizar os resultados.
Suponha a imagem original
Gráfico correspondente

#多目标匹配
image=cv2.imread("./images/2.jpg");
grayImg=cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
matchImg=cv2.imread("./images/2_match_1.jpg",0);
height,width=matchImg.shape
result=cv2.matchTemplate(grayImg,matchImg,cv2.TM_CCORR_NORMED)
showImage=image.copy()
for y in range(len(result)):
for x in range(len(result[y])):
if result[y][x]>0.999:
cv2.rectangle(showImage, (x,y), (x + width, y + height), (255, 0, 0), 1)
plt.imshow(showImage,cmap="gray")
Combine o resultado
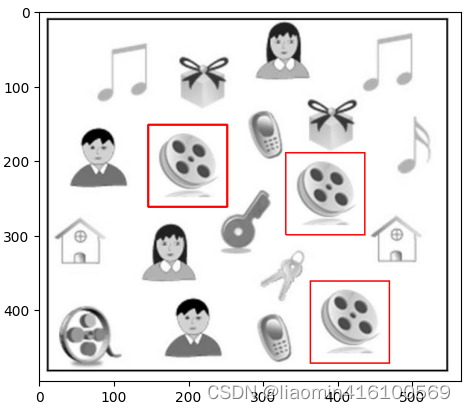
filtro
Uma série de processos, como remover o ruído da imagem e reduzir o nível de informações detalhadas, mantendo ao máximo as informações originais da imagem, é chamada de suavização da imagem (ou desfoque da imagem). A ferramenta mais comumente usada para suavização é o filtro. Ao ajustar os parâmetros do filtro, você pode controlar a suavidade da imagem. OpenCV oferece uma ampla variedade de filtros, cada filtro usa algoritmos diferentes, mas eles podem ajustar os valores dos pixels na imagem para dar à imagem um efeito suave. Este capítulo apresentará o uso de filtro médio, filtro mediano, filtro gaussiano e filtro bilateral.
Pode haver um pixel que seja tão diferente dos pixels circundantes que pode ser visto visualmente que o pixel não consegue formar informações de imagem identificáveis com os pixels circundantes, reduzindo a qualidade de toda a imagem. Esse pixel “fora do lugar” é o ruído da imagem. Se o ruído na imagem for composto apenas por pixels pretos puros aleatórios ou pixels brancos puros, esse ruído será chamado de "ruído de sal e pimenta" ou "ruído de sal". Por exemplo, a imagem mostrada na Figura 7.1 é uma imagem apenas com ruído, muitas vezes chamada de “pontos de floco de neve”.
filtro médio
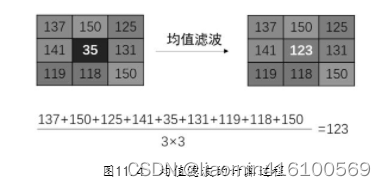
Com um pixel como núcleo, seus pixels circundantes podem formar uma matriz de n linhas en colunas (referida como n×n).Essa estrutura de matriz é chamada de "kernel de filtro" nas operações de filtragem. O número de linhas e colunas da matriz determina o tamanho do kernel do filtro. O tamanho do kernel do filtro é 3×3 e contém 9 pixels, o tamanho do kernel do filtro de imagem é 5×5 e contém 25 pixels.

O filtro médio (também chamado de filtro passa-baixa) pode tratar cada pixel da imagem como o núcleo do kernel do filtro, depois calcular a média de todos os pixels no kernel e, finalmente, tornar o valor do pixel central igual a essa média.
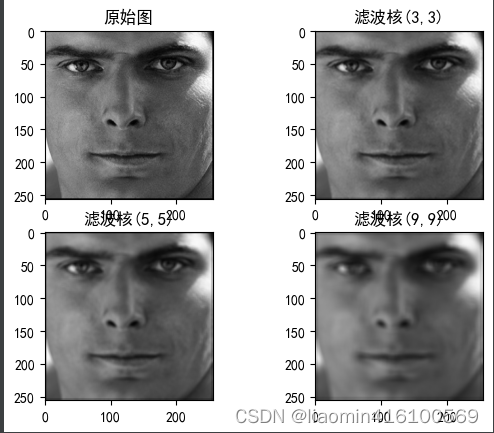
OpenCV encapsula o filtro médio no método blur(), cuja sintaxe é a seguinte:
dst = cv2.blur(src, ksize, anchor, borderType)
Descrição do parâmetro:
- src: a imagem que está sendo processada.
- ksize: Tamanho do kernel do filtro, seu formato é (altura, largura).Recomenda-se usar comprimentos laterais ímpares como (3, 3), (5, 5), (7, 7) com largura e altura iguais. Quanto maior o núcleo do filtro, mais desfocada será a imagem processada.
- Âncora: Parâmetro opcional, ponto de ancoragem do kernel do filtro. Recomenda-se usar o valor padrão, que pode calcular automaticamente o ponto de ancoragem.
- borderType: parâmetro opcional, estilo de borda, o valor padrão é recomendado.
Descrição do valor de retorno: - dst: Imagem após filtragem média.
import matplotlib.pyplot as plt
import matplotlib
import cv2
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.png");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("滤波核(3,3)")
plt.imshow(cv2.cvtColor(cv2.blur(image,(3,3)), cv2.COLOR_BGR2RGB))
plt.subplot(223)
plt.title("滤波核(5,5)")
plt.imshow(cv2.cvtColor(cv2.blur(image,(5,5)), cv2.COLOR_BGR2RGB))
plt.subplot(224)
plt.title("滤波核(9,9)")
plt.imshow(cv2.cvtColor(cv2.blur(image,(9,9)), cv2.COLOR_BGR2RGB))
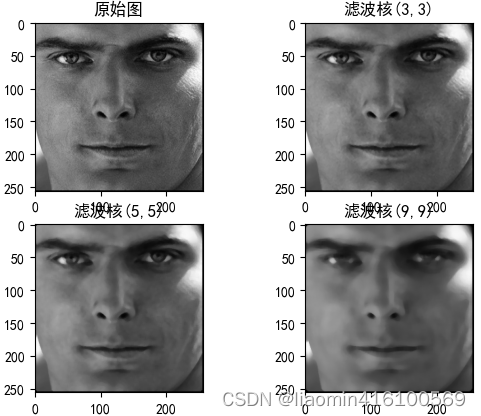
filtro mediano
O princípio do filtro mediano é muito semelhante ao filtro médio, a única diferença é que ele não calcula a média dos pixels, mas classifica todos os valores dos pixels, retira o valor do pixel do meio e atribui-o ao pixel central.
OpenCV encapsula o filtro mediano no método medianBlur(), cuja sintaxe é a seguinte:
dst = cv2.medianBlur(src, ksize)
Descrição do parâmetro:
- src: a imagem que está sendo processada.
- ksize: O comprimento lateral do kernel do filtro, que deve ser um número ímpar maior que 1, como 3, 5, 7, etc. Este método cria automaticamente um kernel de filtro quadrado com base neste comprimento lateral.
Descrição do valor de retorno: - st: imagem após filtragem mediana.
import matplotlib.pyplot as plt
import matplotlib
import cv2
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.png");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("滤波核(3,3)")
plt.imshow(cv2.cvtColor(cv2.medianBlur(image,3), cv2.COLOR_BGR2RGB))
plt.subplot(223)
plt.title("滤波核(5,5)")
plt.imshow(cv2.cvtColor(cv2.medianBlur(image,5), cv2.COLOR_BGR2RGB))
plt.subplot(224)
plt.title("滤波核(9,9)")
plt.imshow(cv2.cvtColor(cv2.medianBlur(image,9), cv2.COLOR_BGR2RGB))
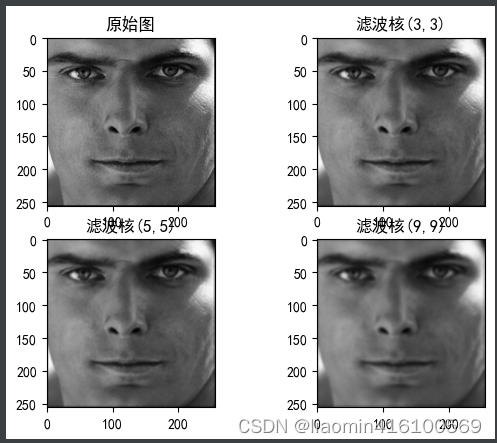
Filtro gaussiano
A filtragem gaussiana, também conhecida como desfoque gaussiano ou suavização gaussiana, é atualmente o algoritmo de suavização mais utilizado. A filtragem gaussiana pode efetivamente reduzir o ruído da imagem e os níveis de detalhes, ao mesmo tempo que retém mais informações da imagem.A imagem processada apresenta um efeito de filtro de "vidro fosco".
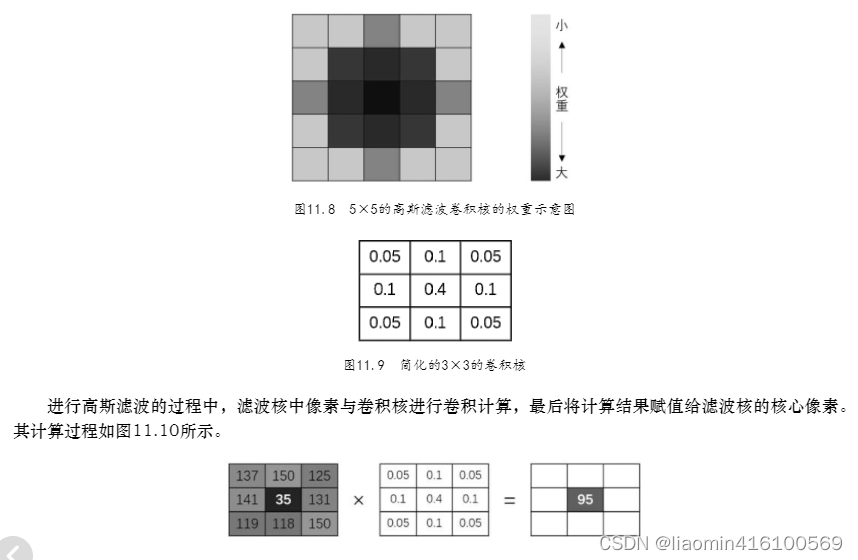
Ao realizar a filtragem média, o peso de cada pixel ao redor do núcleo é igual, ou seja, cada pixel é igualmente importante, então basta calcular a média. No entanto, na filtragem gaussiana, o peso dos pixels mais próximos do núcleo é maior e o peso dos pixels mais distantes do núcleo é menor.Por exemplo, o diagrama de peso de um kernel de convolução de filtro gaussiano 5×5 é mostrado na Figura 11.8 . Se os pesos dos pixels forem diferentes, a média não pode ser obtida. Mais informações devem ser obtidas dos pixels com maior peso e menos informações devem ser obtidas dos pixels com menor peso. Um resumo simples é “quem de quem você está mais próximo é mais parecido com quem você está mais próximo”.
O processo de cálculo do filtro gaussiano envolve operação de convolução, e haverá um kernel de convolução igual ao tamanho do kernel do filtro. Esta seção toma apenas o kernel do filtro 3×3 como exemplo para descrever brevemente o processo de cálculo da filtragem gaussiana.
O valor salvo no kernel de convolução é o valor do peso da área coberta pelo kernel, que segue a regra da Figura 11.8. A soma de todos os valores de peso no kernel de convolução é 1. Por exemplo, um kernel de convolução 3 × 3 pode ter o valor mostrado na Figura 11.9. À medida que o tamanho do kernel e o desvio padrão σ mudam, o valor no kernel de convolução também muda bastante. A Figura 11.9 é apenas o caso mais simples.
import matplotlib.pyplot as plt
import matplotlib
import cv2
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.png");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("滤波核(3,3)")
plt.imshow(cv2.cvtColor(cv2.GaussianBlur(image,(3,3),0,0), cv2.COLOR_BGR2RGB))
plt.subplot(223)
plt.title("滤波核(5,5)")
plt.imshow(cv2.cvtColor(cv2.GaussianBlur(image,(5,5),0,0), cv2.COLOR_BGR2RGB))
plt.subplot(224)
plt.title("滤波核(9,9)")
plt.imshow(cv2.cvtColor(cv2.GaussianBlur(image,(9,9),0,0), cv2.COLOR_BGR2RGB))
filtro bilateral
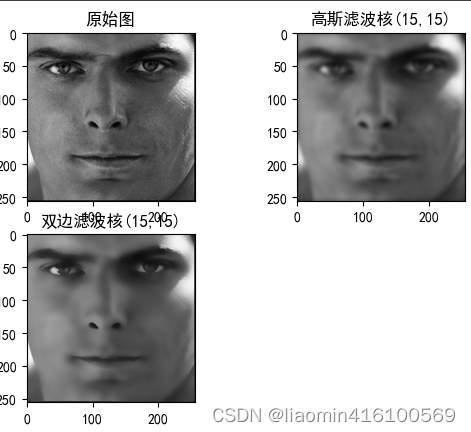
Quer se trate de filtragem média, filtragem mediana ou filtragem gaussiana, toda a imagem será suavizada e os limites da imagem ficarão desfocados. A filtragem bilateral é um método de operação de filtragem que pode proteger efetivamente as informações de limite durante a suavização.
O filtro bilateral determina automaticamente se o núcleo do filtro está na área "plana" ou na área "borda": se o núcleo do filtro estiver na área "plana", um algoritmo semelhante à filtragem gaussiana será usado para filtragem; se o filtro kernel está na área de "borda", o filtro será aumentado.O peso dos pixels de "borda", mantendo esses valores de pixel tão constantes quanto possível.

import matplotlib.pyplot as plt
import matplotlib
import cv2
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.png");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("高斯滤波核(15,15)")
plt.imshow(cv2.cvtColor(cv2.GaussianBlur(image,(15,15),0,0), cv2.COLOR_BGR2RGB))
plt.subplot(223)
plt.title("双边滤波核(15,15)")
plt.imshow(cv2.cvtColor(cv2.bilateralFilter(image,15,120,100), cv2.COLOR_BGR2RGB))
Operações morfológicas
Corrosão e expansão são as operações básicas da morfologia.Além das operações de abertura e fechamento, existem várias outras operações distintas na morfologia. OpenCV fornece um método de morfologia morphologyEx(), que inclui todas as operações comumente usadas. Sua sintaxe é a seguinte:
dst = cv2.morphologyEx(src, op, kernel, âncora, iterações, borderType, borderValue)
Descrição do parâmetro:
- src: imagem original.
- op: tipo de operação, valores específicos são mostrados na Tabela 12.1.
Os valores de enumeração específicos são os seguintes:
- MORPH_ERODE: operação de corrosão
- MORPH_DILATE: operação de expansão
- MORPH_OPEN: operação aberta
- MORPH_CLOSE: Fechar operação
- MORPH_GRADIENT: gradiente morfológico
- MORPH_TOPHAT: operação de cartola
- MORPH_BLACKHAT: operação de chapéu preto
- kernel: O núcleo usado durante a operação.
- âncora: parâmetro opcional, posição do ponto de ancoragem do kernel.
- iterações: parâmetro opcional, número de iterações, o valor padrão é 1.
- borderType: parâmetro opcional, estilo de borda, padrão recomendado.
- borderValue: parâmetro opcional, valor da borda, padrão recomendado.
Descrição do valor de retorno: - dst: A imagem obtida após a operação.
corrosão
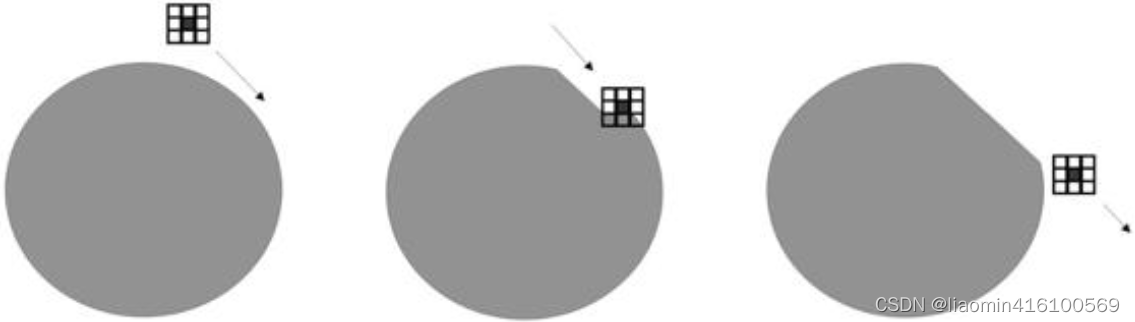
A operação de erosão faz com que a imagem encolha para dentro ao longo de seus próprios limites. OpenCV implementa cálculos de redução por meio de "kernels". O nome inglês de "core" é kernel, que pode ser entendido em morfologia como "um bloco de pixels composto por n pixels".O bloco de pixels contém um núcleo (o núcleo geralmente está no centro, mas também pode ser definido em outras posições ). O bloco de pixels se move na borda da imagem. Durante o movimento, o kernel apagará todos os pixels na borda da imagem que coincidem com o kernel, mas não cruzam o kernel. O efeito é semelhante ao processo mostrado na Figura 12.1, como descascar uma batata, "diluir" a imagem camada por camada.
OpenCV encapsula a operação de corrosão no método erode(). A sintaxe deste método é a seguinte:
dst = cv2.erode(src, kernel, anchor, iterations, borderType, borderValue)
Descrição do parâmetro:
- src: imagem original.
- kernel: O kernel usado pela corrosão.
- âncora: parâmetro opcional, posição do ponto de ancoragem do kernel.
- iterações: parâmetro opcional, o número de iterações da operação de corrosão, o valor padrão é 1.
- borderType: parâmetro opcional, estilo de borda, padrão recomendado.
- borderValue: parâmetro opcional, valor da borda, padrão recomendado.
Descrição do valor de retorno: - dst: imagem após corrosão.
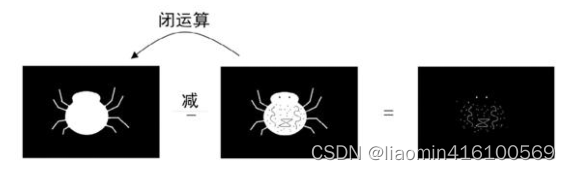
Depois que a imagem for corroída, alguns detalhes externos podem ser apagados. Como mostrado na Figura 12.2, é uma aranha de desenho animado. Se um bloco de 5×5 pixels for usado como uma verificação para a aranha ser corroída, você pode obter algo como mostrado na Figura 12.3.resultado. As pernas da aranha foram apagadas como detalhes externos, enquanto os olhos da aranha ficaram maiores porque o núcleo foi “afiado” por dentro.

Depois da corrosão

import matplotlib.pyplot as plt
import matplotlib
import cv2
import numpy as np
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.jpg");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("腐蚀")
zeroArray=np.ones((3,3))
plt.imshow(cv2.erode(image, zeroArray))
plt.subplot(223)
plt.title("腐蚀")
dst = cv2.morphologyEx(image, cv2.MORPH_ERODE, zeroArray) #也可以使用这个形态学方法,效果和erode一致
plt.imshow(dst)
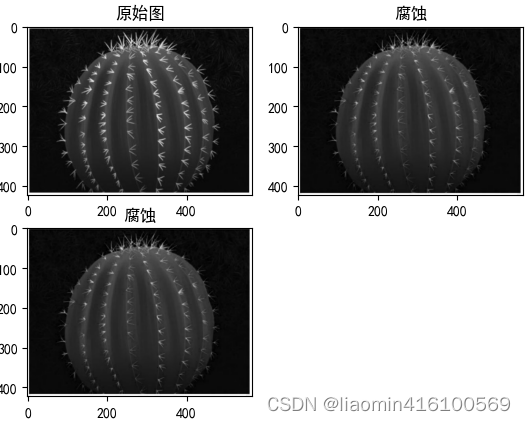
Expansão
A operação de dilatação é o oposto da operação de erosão, que faz com que a imagem se expanda para dentro ao longo dos seus próprios limites. Também é calculado através do kernel. Quando o kernel se move na borda da imagem, o kernel preencherá a borda da imagem com novos pixels. O efeito é semelhante ao processo mostrado na Figura 12.6, assim como aplicar cimento em um parede repetidamente, fazendo com que a parede fique cada vez mais espessa.

OpenCV encapsula a operação de expansão no método dilate(). A sintaxe deste método é a seguinte:
dst = cv2.dilate(src, kernel, âncora, iterações, borderType, borderValue)
Descrição do parâmetro:
- src: imagem original.
- kernel: O kernel usado para expansão.
- âncora: parâmetro opcional, posição do ponto de ancoragem do kernel.
- iterações: parâmetro opcional, o número de iterações da operação de corrosão, o valor padrão é 1.
- borderType: parâmetro opcional, estilo de borda, padrão recomendado.
- borderValue: parâmetro opcional, valor da borda, padrão recomendado.
Descrição do valor de retorno: - dst: imagem após dilatação.
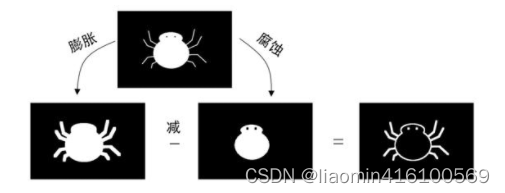
Após a imagem ser expandida, alguns detalhes externos podem ser ampliados, como a aranha de desenho animado mostrada na Figura 12.7(a).Se um bloco de 5×5 pixels for usado como verificador para expandir a aranha, você pode obter a imagem mostrada em Figura 12.7(b). ), não apenas as pernas da pequena aranha ficaram mais grossas, mas seus olhos também perderam peso.

matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/2.jpg");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("膨胀")
zeroArray=np.ones((9,9))
plt.imshow(cv2.dilate(image, zeroArray))
plt.subplot(223)
plt.title("膨胀")
dst = cv2.morphologyEx(image, cv2.MORPH_DILATE, zeroArray) #也可以使用这个形态学方法,效果和erode一致
plt.imshow(dst)

Operação aberta
A operação de abertura consiste primeiro em realizar uma operação de erosão na imagem e, em seguida, realizar uma operação de dilatação. A operação de abertura pode ser usada para apagar detalhes (ou ruído) fora da imagem.
import matplotlib.pyplot as plt
import matplotlib
import cv2
import numpy as np
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/2.jpg");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("开运算")
zeroArray=np.ones((5,5))
#腐蚀掉噪音,然后在膨胀特点
dest=cv2.erode(image, zeroArray)
dest=cv2.dilate(dest, zeroArray)
plt.imshow(dest)
plt.subplot(223)
plt.title("开运算")
dst = cv2.morphologyEx(image, cv2.MORPH_OPEN, zeroArray) #也可以使用这个形态学方法,效果和erode一致
plt.imshow(dst)
renderizações

operação fechada
A operação de fechamento consiste primeiro em realizar uma operação de dilatação na imagem e, em seguida, realizar uma operação de erosão. As operações de fechamento podem apagar detalhes (ou ruído) dentro da imagem.

Operação gradiente
O gradiente aqui se refere ao gradiente da imagem, que pode ser entendido simplesmente como o grau de mudança dos pixels. Se a extensão do valor do pixel de vários pixels consecutivos for maior, o valor do gradiente será maior.
O processo de operação da operação gradiente é mostrado na Figura 12.15, que consiste em subtrair o mapa de erosão da imagem original do mapa de expansão da imagem original. Como o mapa de expansão é maior que a imagem original e o mapa de corrosão é menor que a imagem original, o mapa de corrosão é usado para esvaziar o mapa de expansão para obter o contorno da imagem original.
operação de cartola
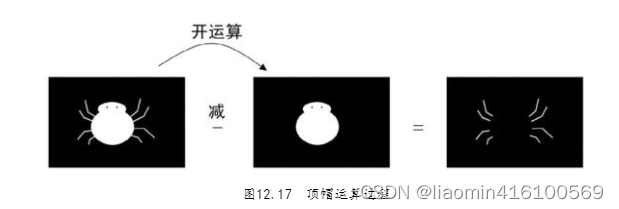
O processo de operação da operação cartola é mostrado na Figura 12.17.Deixe a imagem original ser reduzida pelo gráfico de operação aberta da imagem original. Como a operação de abertura apaga os detalhes externos da imagem, e a imagem com "detalhes externos" subtrai a imagem com "sem detalhes externos", o resultado terá apenas detalhes externos. Portanto, após a operação de cartola, a pequena aranha irá seja apenas uma aranha.
computação de chapéu preto
O processo de operação da operação black hat é mostrado na Figura 12.19.Seja a imagem original subtraída do gráfico de operação fechado da imagem original. Como a operação fechada apaga os detalhes internos da imagem, a imagem sem "detalhes internos" é subtraída da imagem com "detalhes internos", e o resultado são apenas os detalhes internos. Portanto, após a operação de chapéu preto, o pequeno a aranha fica com manchas, padrões e olhos.
Detecção gráfica
contorno da imagem
Contornos referem-se às linhas das bordas externas de figuras ou objetos em uma imagem. O contorno de uma figura geométrica simples é composto por linhas suaves e é fácil de identificar, mas o contorno de uma figura irregular pode ser composto por muitos pontos, dificultando sua identificação.
O método findContours() fornecido pelo OpenCV pode determinar as bordas da imagem calculando o gradiente da imagem e, em seguida, encapsular os pontos da borda em uma matriz e retorná-los. A sintaxe do método findContours() é a seguinte:
contours, hierarchy = cv2.findContours(image, mode, methode)
Descrição do parâmetro:
- imagem: A imagem que está sendo detectada deve ser uma imagem binária de canal único de 8 bits. Se a imagem original for colorida, ela deverá ser convertida em escala de cinza e binarizada.
- modo: o modo de recuperação do contorno, os valores específicos são mostrados na tabela.
cv2.RETR_EXTERNAL: Recupera apenas contornos externos.
cv2.RETR_LIST: Recupera todos os contornos e armazena-os em uma lista.
cv2.RETR_CCOMP: Recupera todos os contornos e organiza-os em uma hierarquia de dois níveis. Na camada superior existem apenas contornos externos, enquanto na segunda camada existem contornos internos. Se o contorno interno também possuir furos, é considerado nível 3.
cv2.RETR_TREE: Recupera todos os contornos e organiza-os em uma árvore hierárquica completa. - método: O método usado na detecção de contornos. Os valores específicos são mostrados na Tabela 13.2.
cv2.CHAIN_APPROX_NONE: Armazene todos os pontos de contorno e a diferença de posição do pixel entre dois pontos de contorno adjacentes não exceda 1.
cv2.CHAIN_APPROX_SIMPLE: Comprime pontos redundantes nas direções horizontal, vertical e diagonal, mantendo apenas os pontos finais adjacentes.Por exemplo, um contorno retangular só precisa armazenar seus quatro vértices.
cv2.CHAIN_APPROX_TC89_L1 ou cv2.CHAIN_APPROX_TC89_KCOS: A aplicação de um dos algoritmos de aproximação da cadeia Teh-Chin pode reduzir ainda mais o número de pontos no contorno, mas requer mais tempo de cálculo.
Descrição do valor de retorno:
- ontours: Todos os contornos detectados, tipo lista, cada elemento é uma matriz de coordenadas de pixel de um determinado contorno.
- hierarquia: relação hierárquica entre contornos.
Após encontrar os contornos da imagem através do método findContours(), para facilitar a observação do desenvolvedor, é melhor desenhar os contornos, então o OpenCV fornece o método drawContours() para desenhar esses contornos. A sintaxe do método drawContours() é a seguinte:
image = cv2.drawContours(image, contours, contourIdx, color, thickness, lineTypee, hierarchy, maxLevel, offse)
Descrição do parâmetro:
- imagem: A imagem original do contorno desenhado, que pode ser uma imagem multicanal.
- contornos: a lista de contornos obtidos pelo método findContours().
- contornoIdx: o índice de desenho do contorno, se for -1, todos os contornos são desenhados.
- color: Desenhe cores, usando o formato BGR.
- espessura: Parâmetro opcional, a espessura do pincel. Se o valor for -1, um contorno sólido será desenhado.
- lineTypee: Parâmetro opcional, tipo de linha para desenhar o contorno.
- hierarquia: parâmetro opcional, relacionamento hierárquico obtido pelo método findContours().
- maxLevel: Parâmetro opcional, a profundidade da camada para desenhar o contorno, o desenho mais profundo é a camada maxLevel.
- offset: Parâmetro opcional, offset, que pode alterar a posição do resultado do desenho.
Descrição do valor de retorno:
- imagem: igual à imagem do parâmetro. Após a execução, a imagem original conterá o contorno desenhado. Você pode salvar o resultado sem usar este valor de retorno.
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
img=cv2.imread("./images/2.jpg")
grayImg=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.title("灰度图")
plt.subplot(221)
plt.imshow(grayImg,cmap="gray")
#二值化
_,dst=cv2.threshold(grayImg,127,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(dst, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
plt.subplot(222)
plt.imshow(cv2.drawContours(img.copy(), contours, 2, (0, 0, 255), 5))
"""
矩形包围框是指图像轮廓的最小矩形边界。OpenCV提供的boundingRect()方法可以自动计算轮廓最小矩形边界的坐标、宽和高。boundingRect()方法的语法如下:
retval = cv2.boundingRect (array)
参数说明:
array:轮廓数组。
返回值说明:
retval:元组类型,包含4个整数值,分别是最小矩形包围框的:左上角顶点的横坐标、左上角顶点的纵坐标、矩形的宽和高。所以也可以写成x, y, w, h = cv2.boundingRect (array)的形式。
"""
x,y,w,h = cv2.boundingRect (contours[2])
print(x,y,w,h)
dstImg=img.copy()
plt.subplot(223)
cv2.rectangle(dstImg,(x,y),(x+w,y+h),(0,0,255),2)
plt.imshow(cv2.cvtColor(dstImg, cv2.COLOR_BGR2RGB))
plt.show()
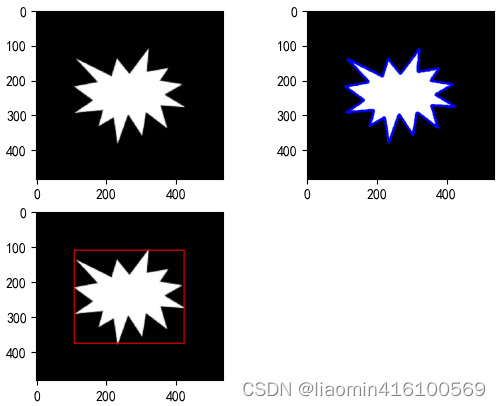
Ajuste de contorno
Ajustar refere-se à conexão de uma série de pontos no plano com uma curva suave. O ajuste de contorno serve para expressar contornos irregulares com figuras geométricas planas. Esta seção explica como desenhar caixas delimitadoras retangulares e circulares de acordo com seus contornos.
caixa delimitadora retangular
A caixa delimitadora retangular refere-se ao menor limite retangular do contorno da imagem. O métodoboundingRect() fornecido pelo OpenCV pode calcular automaticamente as coordenadas, largura e altura do limite retangular mínimo do contorno. A sintaxe do métodoboundingRect() é a seguinte:
retval = cv2.boundingRect (array)
descrição do parâmetro:
- array: matriz de contorno.
Descrição do valor de retorno:
- retval: tipo tupla, contendo 4 valores inteiros, que são a caixa delimitadora retangular mínima: a abscissa do vértice superior esquerdo, a ordenada do vértice superior esquerdo e a largura e altura do retângulo. Portanto, também pode ser escrito na forma de x, y, w, h = cv2.boundingRect (array).
Igual ao exemplo de contorno da imagem acima
caixa delimitadora circular
Uma caixa delimitadora circular, como uma caixa delimitadora retangular, é o menor limite circular do contorno da imagem. O método minEnclosingCircle () fornecido pelo OpenCV pode calcular automaticamente o centro e o raio do limite circular mínimo do contorno. A sintaxe do método minEnclosingCircle() é a seguinte:
center, radius = cv2.minEnclosingCircle(points)
descrição do parâmetro:
- pontos: matriz de contorno.
Descrição do valor de retorno:
- enter: tipo tupla, contendo 2 valores de ponto flutuante, que são a abcissa e a ordenada do centro da caixa delimitadora circular mínima.
- raio: tipo de ponto flutuante, o raio da caixa delimitadora circular mínima.
Efeito

caixa delimitadora poligonal
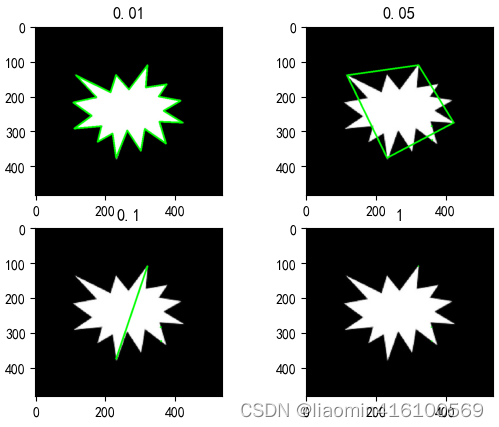
A função cv2.approxPolyDP é uma função para aproximação de contorno no OpenCV, que pode aproximar os pontos do contorno de acordo com certos requisitos de precisão, simplificando assim o número de pontos no contorno e facilitando o processamento subsequente.
A sintaxe desta função é a seguinte:
epsilon = cv2.arcLength(curve, closed)
approx = cv2.approxPolyDP(curve, epsilon, closed)
Entre eles, curva representa o contorno de entrada, épsilon representa a precisão aproximada e fechado representa se o contorno está fechado. A função retorna um contorno aproximado.
O princípio de funcionamento da função cv2.approxPolyDP é implementado através do algoritmo Douglas-Peucker. A ideia básica deste algoritmo é encontrar o segmento de linha mais longo do contorno, usá-lo como um segmento de linha aproximado do contorno e dividir o contorno em duas partes. As duas partes são então processadas recursivamente até que os requisitos de precisão sejam atendidos. Após esse processamento, o número de pontos de contorno obtidos será bastante reduzido, mas a forma do contorno ainda poderá ser mantida.
Deve-se notar que quanto menor o valor de épsilon, mais pontos de contorno aproximados são obtidos, mas a precisão da forma do contorno é maior; inversamente, quanto maior o valor de épsilon, menos pontos de contorno são obtidos, mas a forma do contorno é A precisão também é menor. Portanto, a escolha de um valor épsilon apropriado é muito importante para o efeito da aproximação do contorno.
img=cv2.imread("./images/2.jpg")
grayImg=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_,dst=cv2.threshold(grayImg,127,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(dst, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
#近似轮廓
# 对每个轮廓进行近似
for i,e in enumerate([0.01,0.05,0.1,1]):
img1=img.copy()
for cnt in contours:
epsilon = e * cv2.arcLength(cnt, True) #获取轮廓的周长
approx = cv2.approxPolyDP(cnt, epsilon, True)
# 绘制近似的轮廓
cv2.drawContours(img1, [approx], 0, (0, 255, 0), 3)
plt.subplot(int("22"+str(i+1)))
plt.title(e)
plt.imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
plt.show()
casco convexo
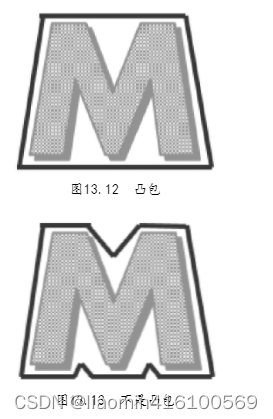
Já introduzimos caixas delimitadoras retangulares e caixas delimitadoras circulares. Embora essas duas caixas delimitadoras tenham se aproximado das bordas dos gráficos, para manter a forma geométrica, essas caixas delimitadoras não se ajustam bem aos contornos reais dos gráficos. Se você puder encontrar os pontos extremos da figura e conectá-los, poderá formar uma caixa delimitadora mínima ao redor da figura. Essa caixa delimitadora é chamada de casco convexo.
O casco convexo é o polígono que mais se aproxima do contorno. Cada parte do casco convexo é convexa, ou seja, o ângulo interno formado por quaisquer três pontos é menor que 180°. Por exemplo, a Figura 13.12 é um casco convexo, mas a Figura 13.13 não é um casco convexo.
O método convexHull() fornecido pelo OpenCV pode encontrar automaticamente a casca convexa do contorno. A sintaxe deste método é a seguinte:
hull = cv2.convexHull(points, clockwise, returnPoints)
Descrição do parâmetro:
- pontos: matriz de contorno.
- sentido horário: parâmetro opcional, tipo booleano. Quando o valor é True, os pontos no casco convexo são organizados no sentido horário e quando é False, os pontos são organizados no sentido anti-horário.
- returnPoints: parâmetro opcional, tipo booleano. Quando o valor for True, as coordenadas do ponto serão retornadas, e quando for False, o índice do ponto será retornado. O valor padrão é verdadeiro.
Descrição do valor de retorno:
- casco: matriz de estrutura de casco convexo
img=cv2.imread("./images/2.jpg")
grayImg=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_,dst=cv2.threshold(grayImg,127,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(dst, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
# 根据轮廓面积从大到小排序
sorted_contours = sorted(contours, key=cv2.contourArea, reverse=True)
hull=cv2.convexHull(sorted_contours[0])
cv2.polylines(img1,[hull],True,(0,0,255),2)
plt.imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
plt.show()

Detecção inteligente de bordas
O algoritmo de detecção de bordas Canny é um algoritmo de detecção de bordas multinível desenvolvido por John F. Canny em 1986. Este algoritmo encontra bordas de imagens com base nas mudanças de gradiente de pixels e pode, em última análise, desenhar imagens de bordas binárias muito finas.
OpenCV encapsula o algoritmo de detecção de borda Canny no método Canny(). A sintaxe deste método é a seguinte:
edges = cv2.Canny(image, threshold1, threshold2, apertureSize, L2gradient)
Descrição do parâmetro:
- imagem: A imagem original da detecção.
- limite1: O primeiro limite usado no processo de cálculo, que pode ser o limite mínimo ou o limite máximo. Geralmente é usado para definir o limite mínimo.
- limite2: O segundo limite usado no processo de cálculo, geralmente usado para definir o limite máximo.
- apertureSize: Parâmetro opcional, tamanho de abertura do operador Sobel.
- L2gradient: Parâmetro opcional, identificador para cálculo do gradiente da imagem, o valor padrão é False. Quando o valor é True, um algoritmo mais preciso é usado para cálculo.
Descrição do valor de retorno:
- dges: A imagem da borda calculada é uma imagem binária em tons de cinza.
import cv2
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
img=cv2.imread("./images/1.jpg")
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
#二值化
r1=cv2.Canny(img,10,50)
plt.subplot(222)
plt.title("Canny")
plt.imshow(cv2.cvtColor(r1, cv2.COLOR_BGR2RGB))

Linha Hough
A transformação Hough é um tipo de detecção de recursos que usa um algoritmo para identificar recursos de uma imagem para determinar formas especiais na imagem, como linhas retas e círculos.
Detecção linear
A transformação da linha reta Hough determina se os pontos na imagem formam uma linha reta através da relação de mapeamento entre a linha reta do sistema de coordenadas Hough e os pontos do sistema de coordenadas cartesianas. OpenCV encapsula este algoritmo em dois métodos, nomeadamente cv2.HoughLines() e cv2.HoughLinesP(). O primeiro é usado para detectar linhas retas infinitamente estendidas e o último é usado para detectar segmentos de linha. O nome do método HoughLinesP() tem
um P maiúsculo no final., este método só pode detectar imagens binárias em tons de cinza, ou seja, imagens em preto e branco com apenas dois valores de pixel. Este método finalmente salva as coordenadas dos dois pontos finais de todos os segmentos de linha encontrados em uma matriz.
A sintaxe do método HoughLinesP() é a seguinte:
lines = cv2.HoughLinesP(image, rho, theta, threshold, minLineLength, maxLineGap)
Descrição do parâmetro:
- imagem: A imagem original da detecção.
- rho: O passo do raio usado para detectar linhas retas.Quando o valor é 1, significa detectar todos os passos de raio possíveis.
- theta: Pesquise o ângulo da linha reta. Quando o valor é π/180°, significa detectar todos os ângulos.
- limite: Valor limite. Quanto menor o valor, mais linhas retas serão detectadas.
- minLineLength: O comprimento mínimo do segmento de linha. Segmentos de linha menores que esse comprimento não são registrados no resultado.
- maxLineGap: A distância mínima entre segmentos de linha.
Descrição do valor de retorno: - linhas: uma matriz cujos elementos são todos segmentos de linha detectados. Cada segmento de linha é uma matriz, representando as coordenadas horizontais e verticais dos dois pontos finais do segmento de linha. O formato é [[[x1, y1, x2, y2], [ x1, y1, x2, y2]]].
import cv2
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
from utils import common
def show(dilate, title, cmap=None, debug=False):
if debug:
plt.title(title)
plt.imshow(dilate, cmap=cmap)
plt.show()
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
img=cv2.imread("./images/1.jpg")
grayImg=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
common.show(grayImg,"原图",cmap="gray",debug=True)
edges = cv2.Canny(grayImg, 20, 40)
common.show(edges,"边缘检测图",cmap="gray",debug=True)
lines = cv2.HoughLinesP(edges, 1, np.pi/180, 15, 100, 18)
img1=img.copy()
for line in lines:
x1,y1,x2,y2=line[0]
cv2.line(img1,(x1,y1),(x2,y2),(0,0,255),2)
common.show(img1,"直线",cmap="gray",debug=True)

Detecção de anel
O princípio da transformada em anel de Hough é semelhante à transformada em linha reta de Hough. O método HoughCircles() fornecido pelo OpenCV é usado para detectar círculos na imagem. Este método realiza duas rodadas de triagem durante o processo de detecção: a primeira rodada de triagem encontra as coordenadas do centro do círculo que pode ser o círculo, e a segunda rodada de triagem calcula as possíveis coordenadas correspondentes do centro do círculo, o comprimento do raio. Este método finalmente encapsula as coordenadas do centro do círculo e o raio em uma matriz de ponto flutuante.
A sintaxe do método HoughCircles() é a seguinte:
circles = cv2.HoughCircles(image, method, dp, minDist, param1, param2, minRadius, maxRadius)
Descrição do parâmetro:
- imagem: A imagem original da detecção.
- método: método de detecção. OpenCV 4.0.0 e versões anteriores fornecem apenas cv2.HOUGH_GRADIENT como o único método disponível.
- dp: O inverso da razão entre a resolução do acumulador e a resolução da imagem original. Um valor de 1 dá ao acumulador a mesma resolução da imagem original; um valor de 2 faz com que o acumulador tenha metade da resolução da imagem original. Normalmente 1 é usado como parâmetro.
- minDist: Distância mínima entre os centros do círculo.
- param1: parâmetro opcional, o limite máximo usado pela detecção de borda Canny.
- param2: Parâmetro opcional, o número de votos para detectar o resultado do anel. Apenas os anéis com mais votos que este valor na primeira ronda de triagem entrarão na segunda ronda de triagem. Quanto maior o valor, menos anéis serão detectados, mas a precisão será maior.
- minRadius: Parâmetro opcional, raio mínimo do anel.
- maxRadius: Parâmetro opcional, o raio máximo do anel.
Descrição do valor de retorno:
- círculos: uma matriz cujos elementos são todos círculos detectados. Cada círculo também é uma matriz. O conteúdo são as coordenadas horizontais e verticais e o comprimento do raio do centro do círculo. O formato é: [[[x1,y1, r1], [x2, y2, r2]]].
processamento de vídeo
OpenCV não é apenas capaz de processar imagens, mas também vídeos. Os vídeos são compostos por um grande número de imagens retiradas do vídeo em intervalos regulares. Desta forma, essas imagens podem ser processadas utilizando métodos de processamento de imagem para atingir o objetivo de processamento de vídeos. Para processar um vídeo, você precisa primeiro realizar operações relacionadas, como ler, exibir e salvar o vídeo. Para este propósito, OpenCV fornece métodos relacionados da classe VideoCapture e da classe VideoWriter.
A classe VideoCapture fornece o construtor VideoCapture() para completar a inicialização da câmera. Sintaxe VideoCapture()
apture = cv2.VideoCapture(index|caminho do arquivo de vídeo)
descrição do parâmetro:
- video: o vídeo a ser aberto.
- filename: O nome do arquivo do vídeo aberto. Por exemplo, promoção da empresa.avi, etc.
import cv2
# 打开视频文件
cap = cv2.VideoCapture('video.avi')
while True:
# 读取视频帧
ret, frame = cap.read()
# 如果视频结束或者读取失败,退出循环
if not ret:
break
# 显示当前帧
cv2.imshow('frame', frame)
# 等待按键输入
key = cv2.waitKey(1) & 0xFF
# 如果按下 'q' 键,退出循环
if key == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
Detecção de rosto
O reconhecimento facial é uma tecnologia de identificação biométrica baseada nas informações das características faciais das pessoas. É também uma tecnologia focada no desenvolvimento da visão computacional. Após o nascimento dos algoritmos de aprendizado de máquina, os computadores podem analisar automaticamente as informações de conteúdo contidas nas imagens por meio de dispositivos de entrada, como câmeras.Com o desenvolvimento contínuo da tecnologia, existe agora uma variedade de algoritmos de reconhecimento facial. Este capítulo apresentará o uso de várias tecnologias de rastreamento de imagem e três tecnologias de reconhecimento facial que acompanham o OpenCV.

Classificador em cascata
Uma série de classificadores simples são colocados em cascata em uma determinada ordem para formar um classificador em cascata.Os programas que usam classificadores em cascata podem identificar amostras por meio de uma série de julgamentos simples. Por exemplo, uma amostra que atenda às três condições de "tem 6 pernas", "tem asas" e "tem cabeça, tórax e abdômen" pode ser inicialmente considerada um inseto. condições não forem atendidas, não será considerado um inseto.
OpenCV fornece alguns classificadores em cascata treinados.Esses classificadores em cascata são salvos como arquivos XML no seguinte caminho: ...
\Python\Lib\site-packages\cv2\data
Minha janela é: D:/ condaenv/tensorflowcpu/Library/etc/ haarcascades/
OpenCV requer duas etapas para implementar a detecção de rosto: carregar o classificador em cascata e usar o classificador para identificar a imagem. Existem métodos correspondentes para essas duas etapas.
A primeira é carregar o classificador em cascata. OpenCV cria um objeto classificador através do método CascadeClassifier(). A sintaxe é a seguinte:
<Objeto CascadeClassifier> = cv2.CascadeClassifier(filename)
descrição do parâmetro:
- filename: nome do arquivo XML do classificador em cascata.
Descrição do valor de retorno: - objeto: objeto classificador.
Em seguida, use o classificador criado para identificar a imagem. Este processo requer a chamada do método detectMultiScale() do objeto classificador. Sua sintaxe é a seguinte:
objects = cascade.detectMultiScale(image, scaleFactor, minNeighbors, flags, minSize, maxSize)
Descrição do objeto:
cascata: objeto classificador existente.
Descrição do parâmetro:
- imagem: A imagem a ser analisada.
- scaleFactor: parâmetro opcional, a taxa de escala ao digitalizar a imagem.
- minNeighbors: parâmetro opcional, quantos resultados de detecção devem ser retidos em cada área candidata antes que possa ser determinada como uma face. Quanto maior o valor, menor o erro da análise.
- flags: parâmetros opcionais, parâmetros da versão antiga do OpenCV, recomenda-se usar os valores padrão.
- minSize: parâmetro opcional, tamanho mínimo do alvo.
- maxSize: parâmetro opcional, o tamanho máximo do alvo.
Descrição do valor de retorno: - objetos: Matriz de áreas alvo capturadas. Cada elemento na matriz é uma área alvo. Cada área alvo contém 4 valores, a saber: abscissa do ponto do canto superior esquerdo, ordenada do ponto do canto superior esquerdo, largura da área e altura da área. . O formato do objeto é: [[244 203 111 111] [432 81 133 133]].
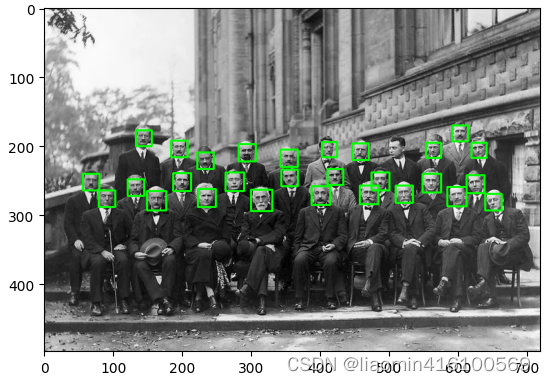
Imagem original:

#%%
import cv2
import matplotlib.pyplot as plot
#加载人脸模型
xml_dir="D:/condaenv/tensorflowcpu/Library/etc/haarcascades/"
# 加载人脸检测器
face_cascade = cv2.CascadeClassifier(xml_dir+'haarcascade_frontalface_alt2.xml')
print(face_cascade)
# 读取要处理的图片
img = cv2.imread('../images/people.png')
# 转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray)
# 在图像中框出人脸
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示结果
plot.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plot.show()