Primeiros passos com Kafka
1. Introdução a Kafka
Apache Kafka é uma plataforma de processamento de fluxo distribuído de alto rendimento desenvolvida pelo LinkedIn e de código aberto em 2011. Possui características de alta escalabilidade , alta confiabilidade e baixa latência , por isso é muito popular em grandes cenários de processamento de dados. Kafka pode processar vários tipos de dados, como eventos, logs, indicadores, etc., e é amplamente utilizado no processamento de fluxo de dados em tempo real, coleta de logs, monitoramento e análise e outros campos.
Geralmente é usado para fila de mensagens e processamento de fluxo.Quando usado como fila de mensagens, os produtos concorrentes incluem RabbitMQ,,, e assim por diante.ActiveMQRocketMQApache Pulsar
2. Arquitetura Kafka
A seguir apresentamos os três participantes mais importantes da arquitetura Kafka:
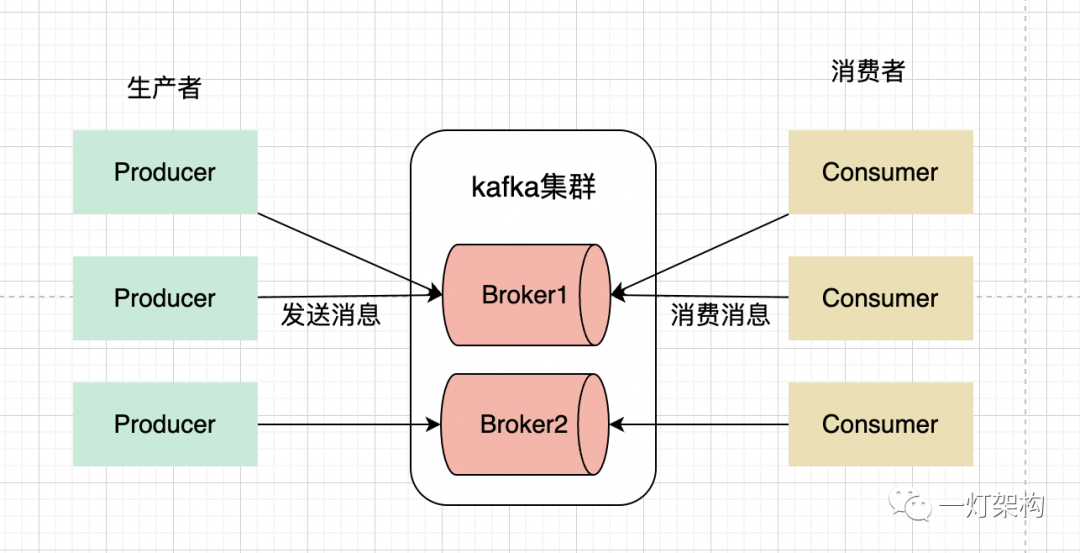
Producer( Produtor ): O produtor é responsável por enviar mensagens ao cluster Kafka.Consumer( Consumidor ): O consumidor é responsável por extrair e consumir mensagens do cluster Kafka.Broker( Nó proxy ): Broker é um nó proxy de serviço no cluster Kafka, que pode ser considerado um servidor. Um cluster Kafka geralmente consiste em vários Brokers para obter balanceamento de carga e tolerância a falhas.
3. Partições e cópias
Kafka introduz o conceito de Topic( tópico ) para classificar mensagens. Quando o produtor envia uma mensagem, ele precisa especificar um tópico para o qual enviar, e então o assinante da mensagem se inscreve neste tópico e consome a mensagem.
Para melhorar o desempenho, Kafka introduziu o conceito de Partition( partição ) com base no Tópico. Tópico é um conceito lógico, enquanto Partição é um agrupamento físico. Um Tópico pode conter múltiplas Partições. Ao enviar uma mensagem, o produtor precisa especificar uma Partição para enviar para um Tópico, e então o assinante da mensagem se inscreve neste Tópico e consome as mensagens nesta Partição.
Para melhorar o rendimento e a escalabilidade do sistema, Kafka coloca diferentes partições de um tópico em vários nós do Broker, aproveitando ao máximo os recursos da máquina e facilitando a expansão das partições.
ReplicaPara garantir a segurança dos dados e a alta disponibilidade dos serviços, Kafka introduz o conceito de ( réplica ) com base na Partição . Uma partição contém várias réplicas. O relacionamento entre as réplicas é um mestre e vários escravos. Existem dois tipos Leader Replica( réplica líder ) e Follower Replica( réplica seguidora ). A réplica é distribuída em diferentes nós do Broker.
A Réplica Líder é responsável pelas solicitações de leitura e gravação, e a Réplica Seguidora é responsável apenas pela sincronização dos dados da Réplica Líder e não fornece serviços externos. Quando a Réplica Líder falha, uma nova Réplica Líder é eleita na Réplica Seguidora para continuar fornecendo serviços externos, realizando failover automático.
A figura a seguir mostra a distribuição de diferentes Partições do mesmo Tópico no nó Broker:
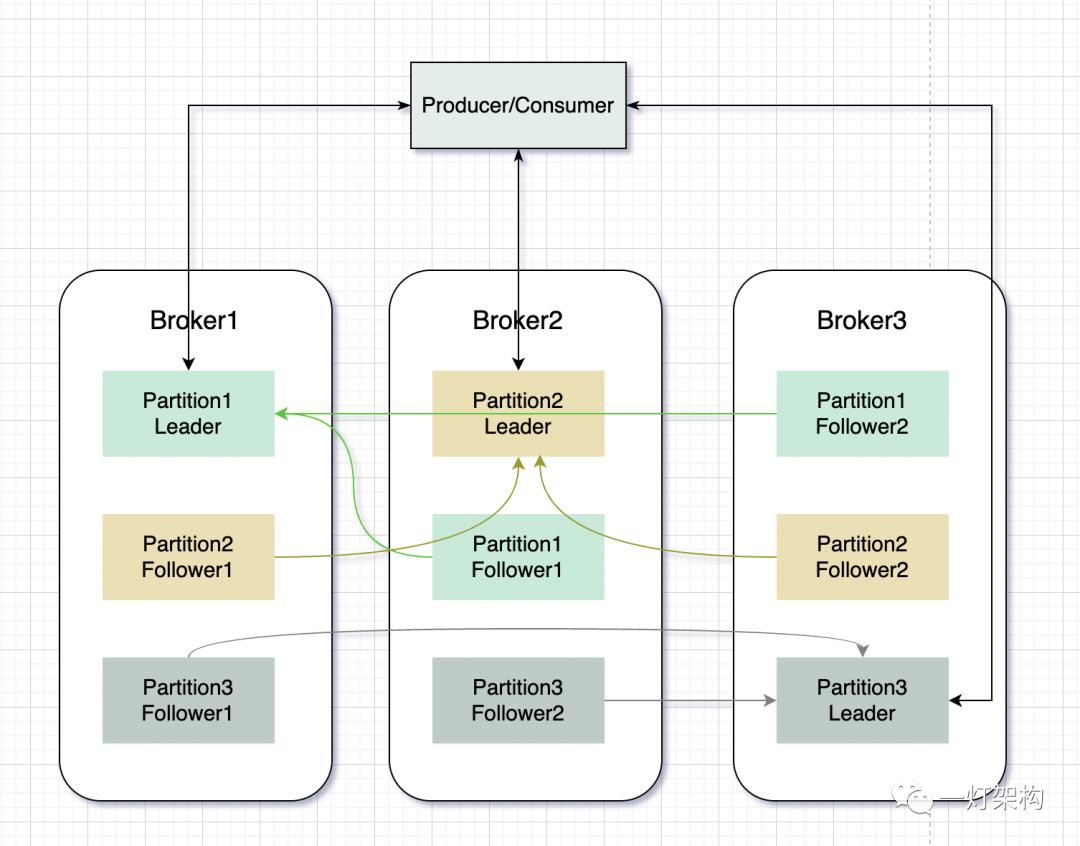
Para melhorar a eficiência de sincronização e a eficiência de gravação de dados do Replica, Kafka classifica o Replica. Todos os conjuntos de réplicas de uma partição são chamados coletivamente de ( réplicasAR alocadas ), incluindo réplica líder e réplica seguidora. O conjunto de réplicas sincronizado com a réplica líder é chamado ( , réplica sincronizada ) e o conjunto de réplicas que está fora de sincronia com a réplica líder é chamado ( , réplica fora de sincronização ) .Assigned ReplicasISRIn-Sync ReplicasOSROut-of-Sync ReplicasAR = ISR + OSR
Antes que a réplica líder grave a mensagem no disco, ela precisa aguardar que todas as réplicas no ISR sejam sincronizadas. Se os dados de sincronização de uma réplica seguidora no ISR estiverem muito atrasados em relação à réplica líder, eles serão transferidos para o OSR. Se os dados de sincronização de uma réplica seguidora no OSR alcançarem a réplica líder, eles serão transferidos para o ISR. Quando a Réplica Líder falhar, apenas uma nova Réplica Líder será eleita no ISR.
4.Deslocamento
Para registrar o status de sincronização das réplicas e controlar o escopo das mensagens consumidas pelos consumidores, Kafka introduziu LEO( Log End Offset, log end offset ) e HW( High Watermark, high water mark ).
- LEO representa o deslocamento da próxima mensagem escrita na partição e também é o deslocamento máximo na partição. LEO é usado para registrar o progresso da sincronização de dados entre a Réplica Líder e a Réplica Seguidora, com uma cópia em cada réplica.
- HW representa o deslocamento mínimo no qual todas as réplicas (Líder e Seguidor) foram replicadas com sucesso e é um valor de dados compartilhado por todas as réplicas. Em outras palavras, as mensagens anteriores ao HW são consideradas comprometidas e os consumidores podem consumir essas mensagens. Usado para garantir consistência e leitura única da mensagem.
O seguinte demonstra o processo de atualização de LEO e HW:
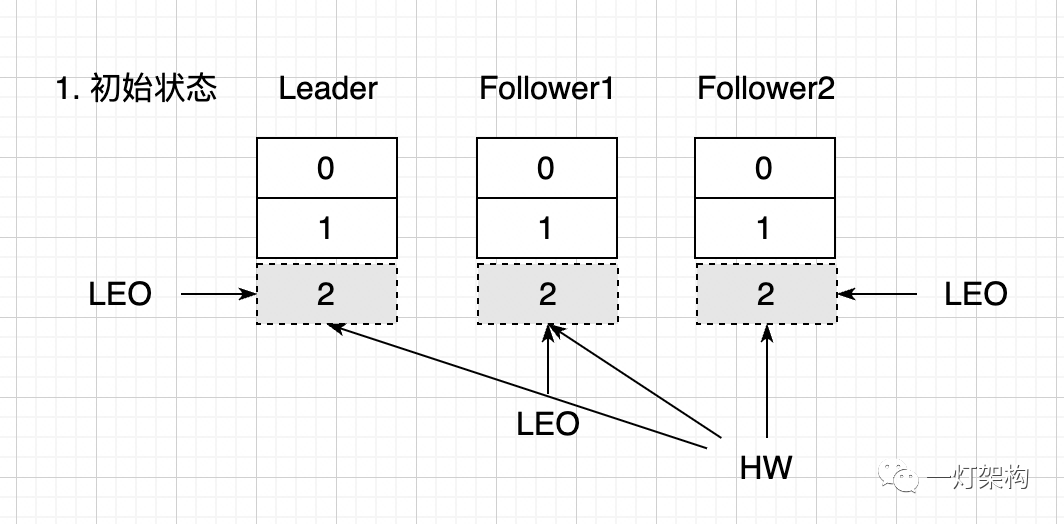
(1) No estado inicial, em cada uma das três cópias existem duas mensagens, 0 e 1. LEO é ambos 2 e a posição 2 está vazia, indicando que é a posição onde a mensagem será escrita. HW também é 2, indicando que todas as mensagens na Réplica Líder foram sincronizadas com a Réplica Seguidora e os consumidores podem consumir duas mensagens, 0 e 1.
(2) O produtor envia duas mensagens para a Réplica Líder. Neste momento, o valor LEO da Réplica Líder aumenta em 2 e passa a 4. Como a sincronização de mensagens com a réplica do seguidor ainda não foi iniciada, o valor de HW e o valor LEO na réplica do seguidor não foram alterados. Porque os consumidores só podem consumir mensagens antes do HW, ou seja, duas mensagens 0 e 1.
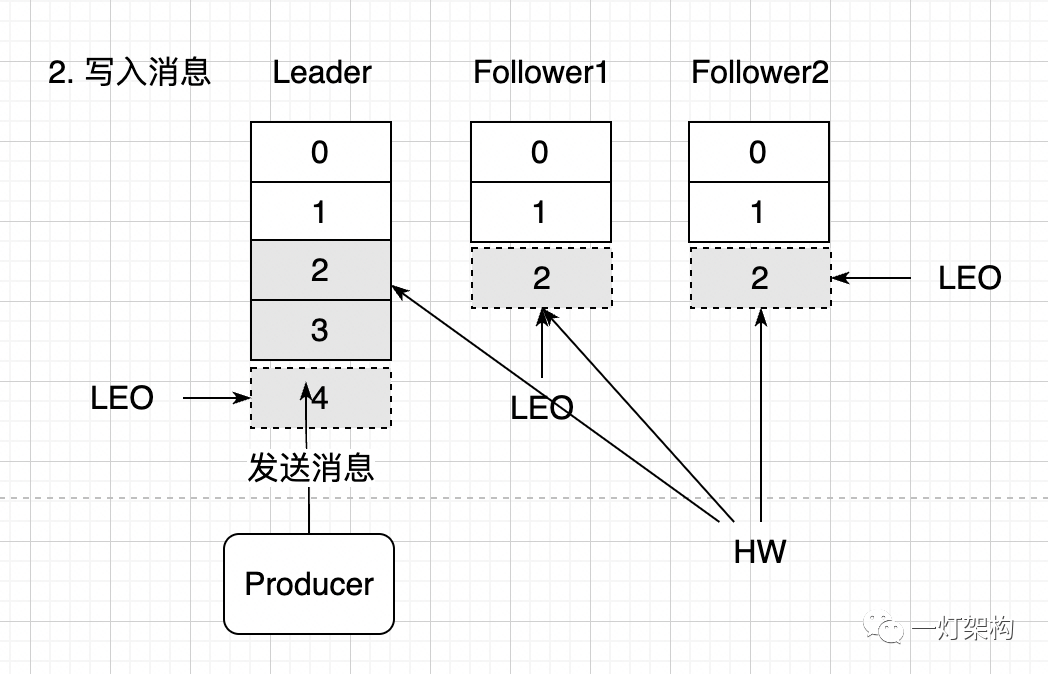
(3) A Réplica Líder começa a sincronizar mensagens com a Réplica Seguidora. As taxas de sincronização são diferentes. Duas mensagens 2 e 3 do Seguidor1 foram sincronizadas, enquanto o Seguidor2 sincronizou apenas uma mensagem 2. Neste momento, o LEO do Líder e do Seguidor1 são ambos 4, enquanto o LEO do Seguidor2 é 3. HW representa o deslocamento mínimo que foi sincronizado com sucesso . O valor é 3, o que significa que o consumidor só pode ler três itens: 0 , 1 e 2 neste momento.
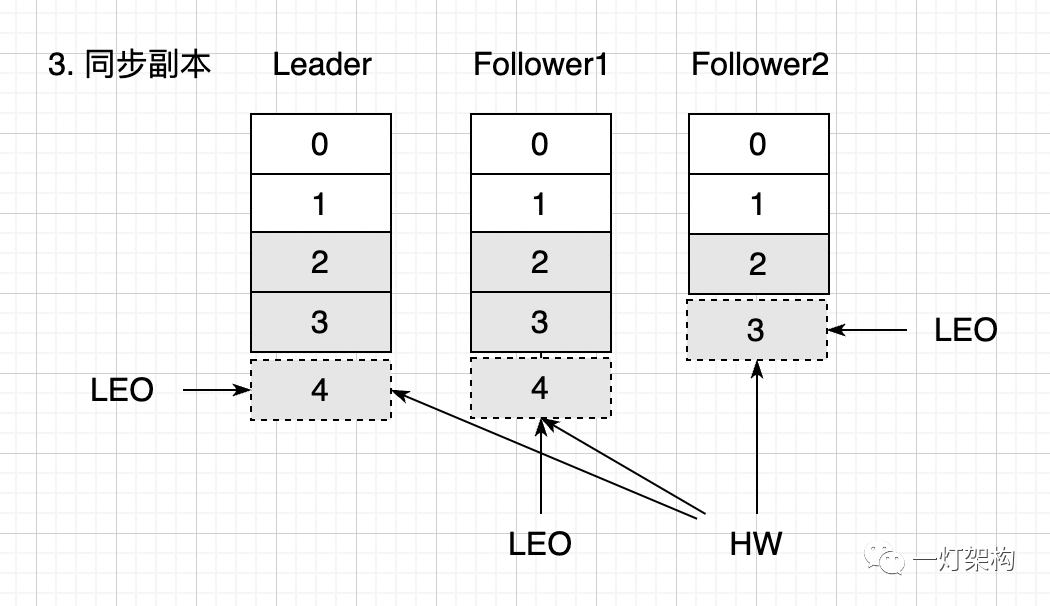
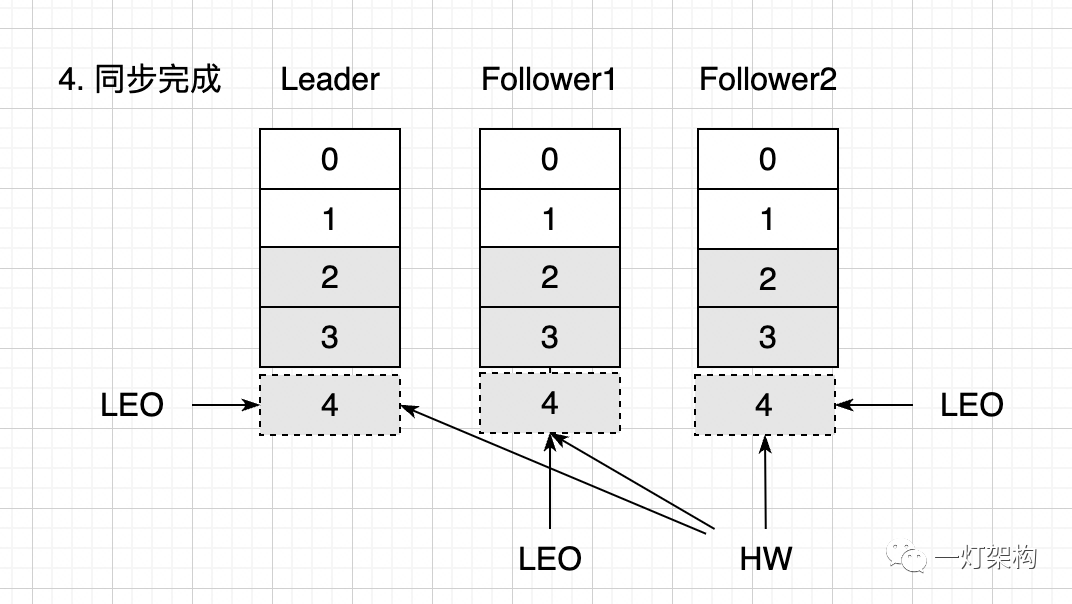
Todas as mensagens são concluídas de forma síncrona, o LEO das três réplicas é 4 e o HW também é 4. O consumidor pode ler quatro mensagens: 0, 1, 2 e 3.
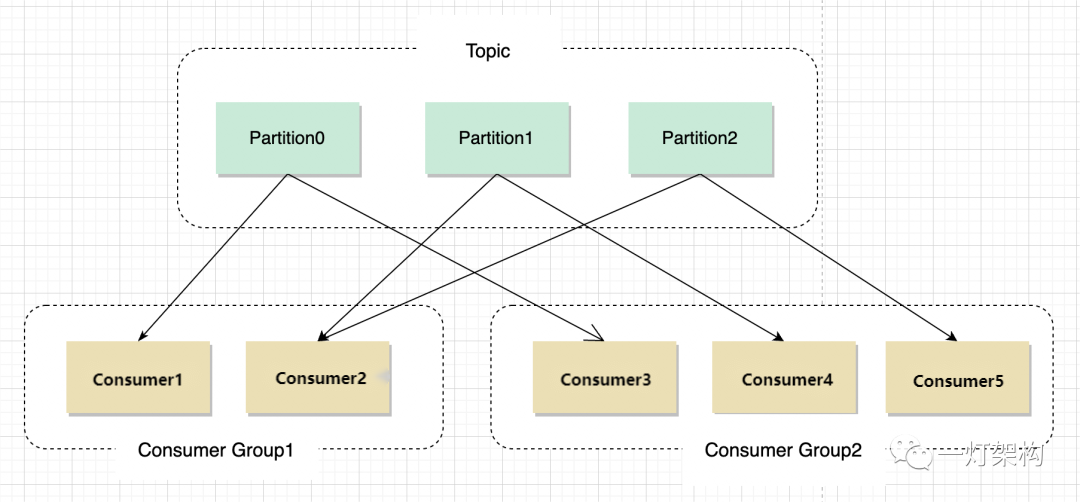
5. Grupo de Consumidores
Para melhorar a eficiência do processamento de mensagens, Kafka introduz o conceito de grupo de consumidores. Um grupo de consumidores ( Consumer Group) contém vários consumidores. Um grupo de consumidores pode assinar vários tópicos ao mesmo tempo, e um tópico também pode ser inscrito em vários grupos de consumidores ao mesmo tempo.
Para garantir que as mensagens da mesma Partição sejam processadas sequencialmente, para um grupo de consumidores, uma mensagem da Partição será entregue apenas a um consumidor deste grupo de mensagens para processamento.
6. Resumo
Este artigo apresenta brevemente a arquitetura Kafka e alguns conceitos substantivos envolvidos na arquitetura, incluindo Producer(produtor), Consumer(consumidor), Broker(nó de agente), Topic(tópico), ( Partitionpartição), Leader Replica(cópia líder), Follower Replica(seguidor) réplica), LEO( Log End Offset, deslocamento final do registro), HW( High Watermark, limite máximo), Consumer Group(grupo de consumidores), etc. O próximo artigo continuará apresentando como Kafka resolve perda de mensagens, consumo repetido, mensagens sequenciais, mensagens persistentes, processo de eleição de líder, etc.