1 introdução à plataforma AB
A plataforma de experimentos AB tornou-se cada vez mais amplamente utilizada em empresas de Internet nos últimos anos. O uso de experimentos AB para avaliar os efeitos de iterações de produtos e tecnologias também se tornou uma forma comum de avaliar os efeitos de novas funções de negócios. a cultura ganhou popularidade considerável nos últimos anos. Foi amplamente reconhecida por um pequeno número de empresas, e o uso de dados e indicadores para ilustrar os efeitos do produto também foi reconhecido e aplicado por cada vez mais empresas.
O experimento AB é uma ferramenta de avaliação de dados de efeito de produto muito comum e tem sido cada vez mais amplamente utilizado no processo de iteração de produtos de grandes empresas.
2 A Era 1.0 vem do zero
No início do experimento AB, os problemas que precisavam ser resolvidos eram simples:
Divida diferentes usuários em diferentes grupos de tráfego por meio de um determinado método de agrupamento de tráfego de usuários, aplique diferentes estratégias de produtos a diferentes grupos de tráfego, controlando variáveis, e então observe a diferença nos efeitos do produto entre os dois grupos.
Esta idéia experimental muito simples é um desvio do experimento AB mais básico. Deve-se notar que as variáveis de controle e a relação de fluxo estável precisam ser garantidas durante o processo.
2.1 Um exemplo básico de experimento AB

Um experimento AB básico requer os seguintes elementos:
1. Objectivos experimentais e hipóteses experimentais
a. A meta experimental determina que tipo de efeito o experimento alcançará para ser considerado bem-sucedido. Por exemplo, espero que a taxa de pagamento aumente em 5%. Essa é a meta. O indicador experimental é a taxa de pagamento. Você deve ter uma meta experimental antes de fazer o experimento. Não há metas experimentais que não podem determinar se o experimento foi bem-sucedido. As metas experimentais incluem dois elementos: indicadores e amplitude de mudança.
b. A hipótese experimental é adivinhar quais fatores devem ser controlados para atingir o objetivo experimental. Por exemplo, assumimos que a cor do botão de pagamento afetará a disposição do usuário em pagar e, portanto, a taxa de pagamento. Então, a hipótese experimental aqui é que a cor do botão de pagamento afetará a disposição de pagar do usuário.
2. Objetos experimentais (objetos experimentais são usuários ou solicitações ou outros objetos que podem ser usados para aplicar políticas)
a. Os objetos experimentais não se referem apenas aos usuários. Cada solicitação do usuário também pode ser experimentada separadamente. Mesmo cada posição de exposição solicitada por um usuário pode ser considerada como um tráfego experimental. Este objeto depende do negócio específico.
3. Grupo de controle e grupo experimental (o principal requisito dos experimentos AB é controlar variáveis para comparação de efeitos, portanto, há pelo menos uma ou mais estratégias de grupo de controle e estratégias de grupo experimental)
a. Grupo controle: Geralmente um grupo sem qualquer estratégia, que representa o efeito experimental atual.
b. Grupo experimental: Geralmente um grupo ao qual uma nova estratégia é aplicada, representando o efeito experimental da nova estratégia.
c. Eficácia estatística: Preste atenção ao alocar o tráfego entre o grupo experimental e o grupo de controle. Porque nosso experimento AB leva uma parte dos usuários gerais para o experimento e, em seguida, usa métodos estatísticos para avaliar o efeito, então se é o experimental grupo ou grupo de controle, o tamanho da amostra do grupo de controle deve atender ao poder estatístico mais básico para que os experimentos subsequentes sejam significativos. No entanto, o poder estatístico não pode ser calculado após o experimento, e precisamos fazer pesquisas suficientes antes que o experimento seja realizado fora.
2.2 Principais funções do algoritmo AB1.0
1. Conduza experimentos de desvio AB controlando variáveis e forneça informações de agrupamento de experimentos do usuário por meio de regras de desvio de simulação offline, para que a análise de dados possa calcular relatórios de indicadores experimentais.
2. A abertura de links de experimentos básicos de engenharia permite que o algoritmo controle de forma independente o tráfego experimental e as estratégias experimentais por meio de configurações experimentais.
2.3 Processo de validação de política do experimento 1.0 AB
No processo experimental inicial existem os seguintes links:

1. Configure as informações de configuração do experimento AB acordadas por meio do centro de configuração. O serviço on-line altera a configuração experimental em tempo real por meio das informações de alteração no centro de configuração, aplica a nova estratégia de descarregamento do próximo descarregamento e registra o log do experimento no mesmo tempo.
2. Método de cálculo de relatório, sincronize as informações de configuração experimental com o ODPS, use a configuração experimental do dia anterior para redistribuir os usuários de ontem no dia seguinte e obtenha as informações de distribuição experimental dos usuários de ontem (a razão para isso é porque as mudanças experimentais são com base no dia) Como unidade, o cálculo offline pode apoiar análises experimentais subsequentes em aspectos comparativos).
Devido às características do negócio, o descarregamento AB de algoritmos e serviços comuns tem muitos requisitos diferentes. Também conduzimos alguns experimentos de algoritmos especiais e projetos de otimização para abordar as diferenças entre os dois. detalhes como segue:

O projeto inicial do experimento AB resolveu o problema básico de desvio experimental e forneceu um conjunto de indicadores experimentais de apoio e esquemas de cálculo de confiança experimental, que apoiaram o negócio simples inicial de comparar os efeitos do modelo de algoritmo de observação científica por meio de experimentos AB.
3 Era 2.0, da existência até a conclusão, apoiando funções de negócios complexas
3.1 Novas necessidades de negócios
Com o desenvolvimento dos negócios da empresa e a otimização iterativa de vários sistemas, os usuários começaram a derivar alguns requisitos de negócios novos, mais detalhados e complexos para o sistema experimental AB básico. Os usuários também esperam que o sistema AB possa ajudar a apoiar iterações experimentais mais eficientes. .
1. Requisitos de tráfego mais ricos e com grande consumo de tráfego: Na versão 1.0 do experimento AB, os problemas básicos de distribuição e configuração experimentais foram resolvidos.No entanto, devido ao tráfego total de usuários limitado em um cenário, vários experimentos de negócios podem ser realizados ao mesmo tempo. , ao executar um experimento real, é necessário fazer uma compensação entre o número de experimentos executados simultaneamente e o tamanho do tráfego de cada experimento. Durante períodos de rápido desenvolvimento de negócios, os usuários geralmente desejam aumentar o número de experimentos sendo executados simultaneamente, garantindo que cada experimento tenha tráfego suficiente. , então expandimos o design do modelo experimental de desvio de tráfego original e adotamos um método hierárquico de divisão de experimentos de negócios ortogonais baseado em domínio para suportar os requisitos de tráfego acima.
2. Relatórios experimentais mais precisos e em tempo real: Nos primeiros experimentos, os dados do grupo de experimentos do usuário do dia anterior foram obtidos recalculando a configuração do dia seguinte. Este método pode suportar um grande número de usuários e experimentos, mas é urgente e é mais difícil de garantir. Com a rápida iteração dos negócios, a demanda por monitoramento de efeitos experimentais em tempo real de algoritmos aumentou gradualmente.O feedback do cálculo do relatório experimental off-line precisa esperar pelo menos 1 dia antes da observação, e o ciclo de feedback experimental é muito longo. Portanto, ajustamos os links de cálculo de descarregamento e relatório experimental e usamos pontos enterrados de registro de experimento em tempo real para calcular os resultados experimentais em tempo real por meio de plataformas de computação em tempo real, como o flink. Essa abordagem pode capturar as mudanças no tráfego experimental em tempo real tempo, e é de grande ajuda na verificação do efeito de descarga experimental.
3. Formas de experimentos complexos: experimentos conjuntos da vida real, de vários clusters, requisitos específicos de experimentos do usuário: Com a padronização dos links de engenharia de algoritmos, algumas camadas de negócios nos links de negócios começaram a realizar experimentos de ajuste conjunto, dando origem a cruzamentos multiparâmetros. -experimentos de treinamento. O requisito para experimentos conjuntos em camadas requer o suporte do mecanismo de eficácia de parâmetros conjuntos com base em experimentos em camadas, o que é difícil de suportar em projetos experimentais em camadas em geral. Com o progresso do projeto de estabilidade do link de engenharia, a maioria dos serviços possui vários clusters diferentes ao mesmo tempo.Neste momento, o sistema AB é necessário para fornecer suporte funcional para diferentes clusters com diferentes configurações experimentais no mesmo cenário. Além disso, com o desenvolvimento de operações refinadas, cada vez mais experimentos só podem ter efeito para grupos de usuários mais precisos e específicos, o que trouxe demandas e desafios consideráveis ao desvio experimental original e à análise experimental.
3.2 Modelo de shunt maior e mais geral
A fim de atender às necessidades de uma distribuição de tráfego mais rica, projetamos um modelo de distribuição experimental relativamente flexível e universal. Este modelo foi verificado por várias empresas e pode garantir que possa apoiar totalmente todos os nossos negócios por um longo tempo. Vários Necessidades de desvio de experimento AB. Ao mesmo tempo, de acordo com as nossas próprias necessidades de desenvolvimento de negócios, também apoiamos camadas condicionais, mecanismos de desvio personalizados e outros mecanismos de desvio concebidos para negócios mais complexos.
Modelo de tráfego experimental ortogonal multicamadas

O modelo de distribuição de tráfego mencionado acima divide o tráfego de cena em duas estruturas aninhadas: camadas e domínios.Diferentes configurações de negócios são isoladas por meio de camadas e diferentes grupos de usuários são isolados por meio de domínios. O processo de descarregamento do usuário neste modelo adota um processo de acerto passo a passo de fora para dentro e de cima para baixo. Cada vez que uma camada de negócios é inserida, uma lógica de seleção de bucket será acionada. Depois que o bucket for atingido, o a configuração no bucket é lida. Se ainda houver algo no bucket, as configurações de camada continuam a atingir as camadas em sequência, acionando a lógica de seleção interna do bucket.
O modelo pode suportar os seguintes recursos principais:
1. Domínio hierárquico e design de tráfego aninhado mutuamente suportam o tráfego ortogonal de camadas de domínio de negócios. Cada camada é um negócio separado para resolver o problema da fome de tráfego e apoiar a divisão de domínio de tráfego livre. O domínio de tráfego e as camadas de tráfego podem ser aninhados uns nos outros para alcançar métodos de divisão de tráfego extremamente flexíveis.
2. Cada camada de tráfego usa modelo de hash + slot de tráfego. Os experimentos intracamadas determinam a proporção de tráfego do experimento na forma de slots circulares. Os usuários do algoritmo podem personalizar as regras de desvio do experimento e oferecer suporte ao desvio com base nas informações de características do usuário do usuário. Também suporta um mecanismo flexível de alinhamento de tráfego entre camadas. Este método pode implementar um método de distribuição extremamente flexível, suportando vários objetos e métodos de distribuição (como distribuição de usuários, distribuição de solicitações, distribuição de dispositivos, distribuição de autores, distribuição baseada em região, etc.).
3. Suporta lista de permissões, permitindo que os usuários contornem o mecanismo de desvio e especifiquem links experimentais fixos dos usuários para verificação experimental on-line de usuários especiais.
4. Camada de condição de suporte, permitindo que usuários que atendam a certas condições conduzam experimentos específicos de forma independente, como experimentos apenas para novos usuários.
Desde o lançamento do modelo, ele suportou perfeitamente os requisitos de distribuição de tráfego AB de mais de 300 cenários do algoritmo em mais de 2 anos, foi totalmente verificado pela empresa e resolveu muitos problemas encontrados pela empresa de distribuição com necessidades especiais desde o nível de distribuição.
As regras de desvio na camada específica são as seguintes:

Cada camada de tráfego calcula o slot de fluxo de acerto com base nas informações de configuração de distribuição de tráfego e nas informações do usuário na camada e, em seguida, seleciona o experimento do slot de fluxo com base no acerto do slot de fluxo. O experimento determina a proporção de tráfego experimental pelo número de fluxo slots que possui.
3.3 Links de engenharia de experimentos padrão
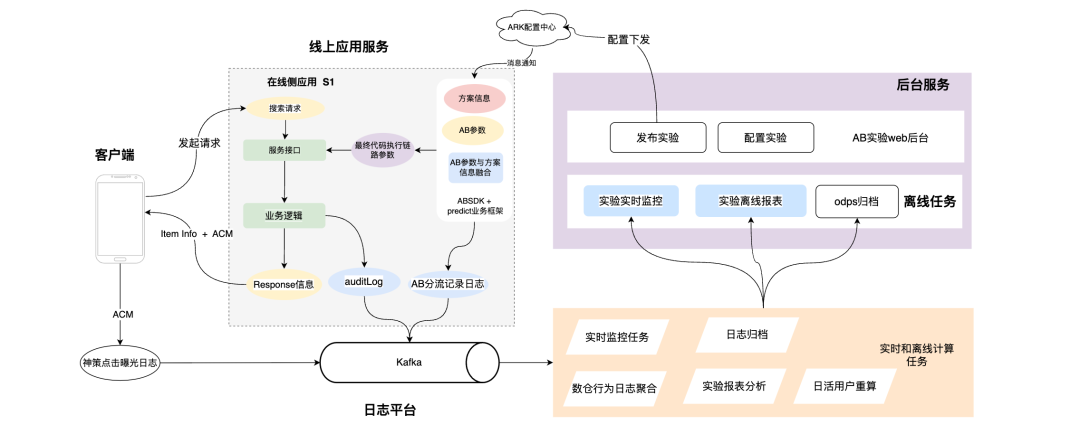
Através da transformação de fundo do experimento AB, repensamos e ajustamos o projeto de engenharia de todo o link experimental.No novo projeto de engenharia, em comparação com a versão anterior, existem principalmente os seguintes aspectos que precisam ser melhorados:
1. Use logs de distribuição experimental em vez de configurações experimentais off-line para calcular as informações de agrupamento experimental dos usuários.
a. O registro do experimento pode capturar a situação de desvio experimental do usuário a cada momento e pode capturar com mais sensibilidade as mudanças experimentais.
b. O log do experimento é altamente observável. Depois de configurar o experimento, o usuário pode observar imediatamente o status de acerto do experimento por meio do log.
c. Mais informações relacionadas ao ambiente experimental podem ser adicionadas ao log para realizar uma análise experimental mais rica, o que pode simplificar a lógica de cálculo do agrupamento experimental off-line.
2. A aplicação on-line adiciona informações enterradas específicas de informações experimentais.Os pontos enterrados são divididos em duas partes:
a. Parte dele é transmitida de forma transparente ao cliente, que contém as informações experimentais atingidas pelo usuário, que é chamado de ponto enterrado ACM. Quando o usuário realiza exposição de clique e outras operações, o cliente reporta o campo ACM emitido pelo servidor , para que possamos através do log de comportamento relatado por Shence, possamos saber claramente quantas vezes cada experimento foi exposto e clicado, e possamos obter o desempenho online do experimento a tempo.Esta parte do log de comportamento também pode nos ajudar calcular o relatório de efeito da estratégia experimental em tempo real.
b. A outra parte serve como registro de histórico da aplicação, registrando as informações relacionadas ao experimento atingido pelo usuário em cada solicitação, e é utilizada para calcular as informações de agrupamento do experimento.
3. Projetada a interface de gerenciamento de operações em segundo plano do experimento AB, de modo que não haja necessidade de modificar manualmente a configuração do centro de configuração para configurar o experimento. E as funções de liberação de experimento, modificação de experimento, reversão de configuração de experimento e outras funções são transformadas em funções de botão específicas, o que melhora muito a experiência de operação experimental do usuário.
4. Os parâmetros experimentais e os links de execução de código são divididos, e os dois conceitos de parâmetros AB e planos de operação de links de código são abstraídos, transformando AB em uma dependência fraca e reduzindo o impacto de erros de configuração de parâmetros experimentais nos negócios online.
Ps: Por que dois links de feedback de informações experimentais são usados ao mesmo tempo? O motivo é que as informações experimentais do usuário relatadas pelo ACM no primeiro tipo dependem dos relatórios do usuário. Se o usuário encontrar uma falha no aplicativo ou relatórios atrasados, ou a condição da rede de repente fica ruim, não temos escolha, obtendo essa parte da informação que não foi reportada, a segunda é óbvia, não há como saber o feedback posterior do conteúdo distribuído com informações experimentais. Nenhum dos links pode cobrir completamente todos os usuários. Somente trabalhando juntos eles podem cobrir completamente todos os usuários. Quanto ao motivo pelo qual os logs off-line são usados para fazer relatórios experimentais, o ACM usa relatórios em tempo real apenas por razões de eficiência de engenharia.
Padrão de enterramento de ponto universal ACM Para resolver o problema de observação de efeitos em tempo real de experimentos, precisamos encontrar uma maneira de passar as informações de identificação de acertos experimentais de fundo para o cliente. Levando em consideração que outros cenários de negócios também terão requisitos de rastreamento semelhantes, a fim de considerar a versatilidade do rastreamento, planejamos um padrão de rastreamento de algoritmo.Queremos principalmente simplificar o processo de rastreamento de algoritmo e fornecer gerenciamento unificado de informações de rastreamento de algoritmo.
Os pontos enterrados ACM concordam principalmente com o cliente em um campo de conteúdo de ponto enterrado fixo ACM por meio do algoritmo.Quando o algoritmo de back-end é desenvolvido, por meio da ferramenta SDK fornecida, as informações e o conteúdo que precisam ser enterrados são formados em uma string por meio de o SDK usando especificações específicas. Conteúdo de string reconhecível, alunos clientes relatam eventos (exposição, cliques, etc.) para o campo acordado do ACM, e o back-end pode obter rapidamente usuários subsequentes de um experimento por meio de ferramentas de cálculo em tempo real com base no relatado registros de comportamento do usuário Feedback.
Exemplo de especificação de ponto enterrado ACM:
版本.业务域.内容资源类型.资源位.实验.自定义值
-
Versão: marque a versão da especificação seguida por este ACM. Versões diferentes têm regras de análise diferentes para facilitar a análise de UDF.
-
Domínio comercial: Nome do sistema comercial, tente ser o mais curto possível, por exemplo, procure por srh.
-
Tipo de recurso de conteúdo: tipo de conteúdo ou recurso, como user_10098, cspu_1020, spu_771, etc.
-
Posição do recurso: posição publicitária, posição no ranking.
-
Experimento: A estratégia de experimento AB adotada pelo recurso desta vez, vários experimentos são separados por -.
-
Valor customizado:
-
Campos que permitem a expansão do lado do aplicativo, como chan_latest-pos_3 significa que o canal é o mais recente e pos é 3.
-
Requisitos especiais: ".", "-", "_" e outros campos não podem aparecer em campos personalizados. Este requisito não se aplica a outras partes.
Exemplo de pontos enterrados:
acm: 1.srh.spu_1009.sh.kka3b.10089-1929-100.channel_hot-position_2acm: 2.srh.spu:1009.sh.kka3b.10089;1929;100.channel:hot;position:2
Cena enterrada:
dimensão de solicitação, cobrindo todos os cenários de pesquisa e recomendação
ação enterrada
dimensão da solicitação
Aqui está um exemplo de retorno de back-end com informações de acm:
{"code": 200,"data": {"total": 3730,"start": 0,"hits": 10,"searchId": "161113175619737242413163","searchTime": 0.024447,"items":[{"spuId":"xxx","acm": "1.ms.prd-10092.v1ss.exp-1.kka.12",}],"facet":[],"cache": false},"requestId": "f2ca7c08693acd54","cost": 0,"time": 1611131759}
3.4 Monitoramento de indicadores experimentais em tempo real
Processo de cálculo de indicadores experimentais em tempo real
1. As informações de desvio do experimento do registro de serviço em segundo plano precisam ser transmitidas de forma transparente ao cliente;
2. O comportamento do usuário cliente é relatado em tempo hábil;
3. Os registros de comportamento são processados em tempo hábil por plataformas de computação em tempo real, como o flink;
4. Desenvolva especificações claras e calculáveis para métricas em tempo real.
Com os quatro processos básicos acima, os indicadores de feedback experimental em tempo real podem ser calculados. No entanto, deve-se notar que os cálculos dos indicadores em tempo real muitas vezes só podem refletir mudanças nas tendências experimentais durante um período de tempo. É difícil obter resultados experimentais precisos. cálculos de indicadores em alguns indicadores complexos, portanto, geralmente é usado para observar a tendência de mudança dos indicadores experimentais e não é usado como base para a tomada de decisão final.
Link de processamento de dados em tempo real
Depois que o link de dados é aberto e os pontos enterrados do ACM são incluídos no log de comportamento do usuário, o algoritmo pode calcular várias informações de indicadores do usuário em tempo real com base no log de comportamento por meio de ferramentas como o flink.
O processo específico do link de monitoramento é mostrado como o link verde na figura abaixo:

Efeitos específicos de monitoramento experimental em tempo real
No final, ele pode obter feedback de segundo nível sobre os resultados experimentais, o que acelera bastante a eficiência do feedback do algoritmo nas estratégias experimentais. O efeito específico é mostrado abaixo. Os usuários podem escolher as informações experimentais às quais prestam atenção para comparar as mudanças do indicador de diferentes experimentos no mesmo intervalo de tempo. As informações de feedback do efeito de novos experimentos on-line podem ser obtidas muito rapidamente, o que encurta bastante o ciclo de feedback do ajuste da estratégia do algoritmo para indicadores experimentais.

4 Na era 3.0, do completo ao ideal, melhorando a experiência do usuário e a eficiência experimental
Na era 2.0, tentamos principalmente atender às necessidades de negócios em termos de vários mecanismos e funções. Depois que as funções de negócios são satisfeitas, realizamos negócios e expansão para incluir os cenários de negócios recomendados do algoritmo. Depois que o negócio recomendado é conectado, embora as funções básicas também possam atender às necessidades, mas as características de negócio de recomendação e pesquisa ainda são um pouco diferentes, por isso fizemos mais otimizações em termos de experiência do usuário e estabilidade do funcionamento experimental da plataforma experimental.
4.1 Construção de facilidade de uso de operações experimentais
Após a implementação dos cenários de negócios, as equipes de negócios e o pessoal utilizado tornaram-se mais complexos, por isso fizemos muitas melhorias funcionais e otimizações para o uso de cenários específicos e os hábitos de uso do pessoal de negócios. Com base nos pontos problemáticos de configuração de parâmetros, configuração de lista de permissões, ajuste de tráfego e outras funções que coletamos do pessoal do algoritmo, fizemos otimizações direcionadas.
Ferramenta de facilidade de uso para parâmetros experimentais
A configuração de parâmetros experimentais é a função mais importante do experimento AB. Para otimizar a experiência do usuário no uso de parâmetros experimentais, coletamos alguns problemas comuns que os usuários costumam encontrar ao usar a configuração de parâmetros e criamos funções e experiências direcionadas.
Cenário 1: Com o desenvolvimento dos negócios, mais e mais camadas de negócios são configuradas para algoritmos. Como a especificação de parâmetros acordada é que os parâmetros experimentais configuráveis da mesma camada devem ser consistentes, a mesma configuração de parâmetros experimentais também deve aparecer na mesma camada , mas à medida que o número de camadas aumenta e alguns parâmetros são usados irregularmente, torna-se difícil estimar o tráfego efetivo real de um determinado parâmetro experimental (os parâmetros substituirão as regras anteriores). É possível que você tenha configurado recallSize = 20 para 10% do tráfego do experimento a, mas o parâmetro foi substituído pelo parâmetro de outra pessoa com o mesmo nome, fazendo com que o tráfego efetivo do parâmetro real não atendesse às expectativas.

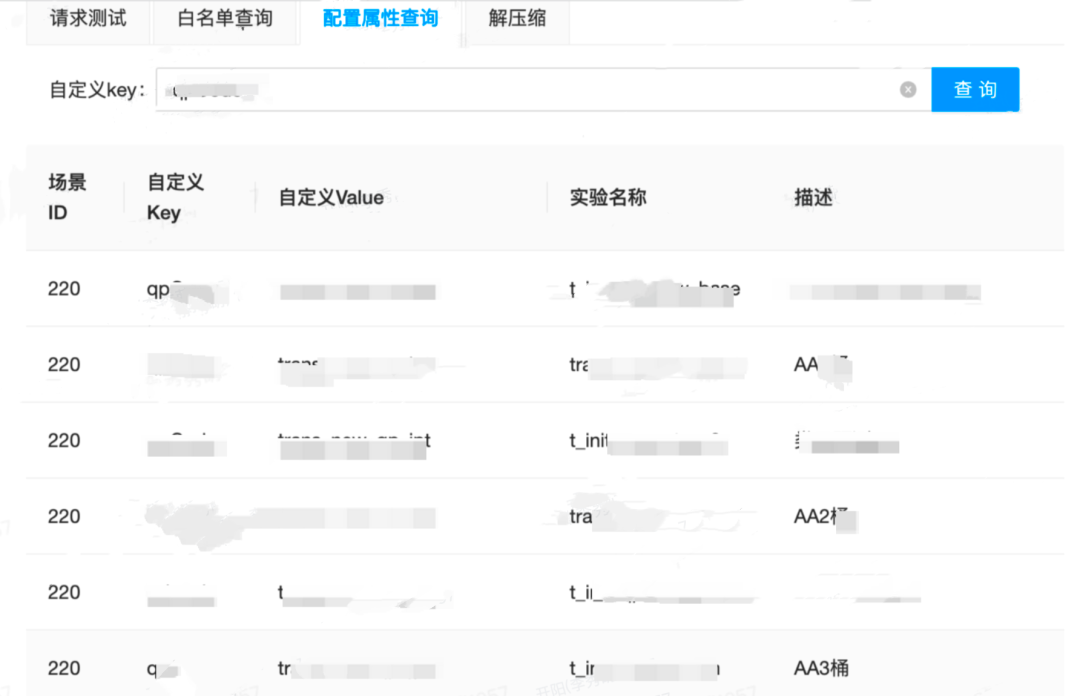
Análise paramétrica de coloração de fluxo
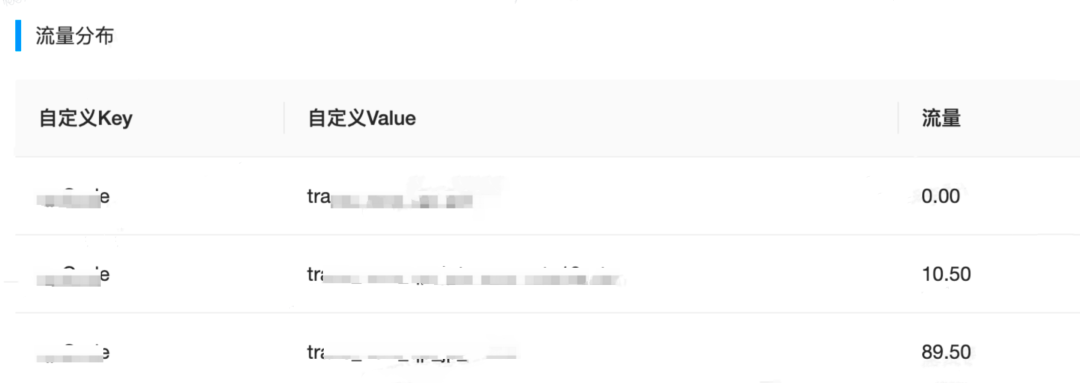
Usando a análise de coloração do tráfego de parâmetros, você pode saber claramente em quais experimentos um determinado parâmetro experimental está configurado. Se esses experimentos pertencerem à mesma camada de negócios, não haverá cobertura de tráfego. Se alguns experimentos não pertencerem à mesma camada de negócios, pode ocorrer cobertura de parâmetros. Coloração de tráfego é um programa que calcula a distribuição do resultado final do tráfego de um determinado parâmetro com um clique. Você pode ver facilmente a proporção final de tráfego real online de um determinado parâmetro.
Contém todas as consultas experimentais para uma determinada configuração de parâmetro:
A distribuição efetiva real do tráfego de um determinado parâmetro:
Cenário 2: Os parâmetros experimentais estão se tornando cada vez mais complexos. Freqüentemente, há várias versões diferentes do mesmo parâmetro que precisam ser observadas ao mesmo tempo. Nesse caso, pode ser devido a muito tempo atrás ou a mudanças frequentes no experimento ou há muitos parâmetros. Observações experimentais são frequentemente realizadas. Ao fazer ajustes, você precisa confirmar as informações de configuração dos parâmetros no experimento. Criamos especialmente uma função de comparação de parâmetros experimentais conveniente para esses cenários que exigem comparação de parâmetros .
Comparação de parâmetros experimentais: você pode comparar claramente os valores do mesmo parâmetro experimental em outros experimentos na mesma camada, o que pode melhorar significativamente a eficiência da verificação de informações experimentais necessária durante o ajuste do fluxo experimental.

Otimização de operação e exibição do layout experimental
Para atender às necessidades de divisão de tráfego experimental flexível, projetamos um conjunto de modelos experimentais gerais de tráfego. No entanto, a visualização desse modelo de tráfego sempre foi um grande problema. O mais básico é que esperamos exibir camadas intuitivamente e camadas, e camadas e buckets.A relação de ordem de acerto entre a estrutura de layout (domínio do usuário) e o tráfego do usuário.
Realizamos algumas explorações que podem refletir de forma mais intuitiva o layout experimental.Atualmente, usamos uma estrutura de árvore padrão para representar um modelo de desvio experimental. Usaremos ícones para distinguir a camada de negócios e os buckets de usuário no modelo experimental. Como a estrutura do bucket da camada pode ser aninhada várias vezes, dividimos o relacionamento estrutural e projetamos a visualização principal da página do bucket e a visualização principal da página da camada separadamente.
-
Visualização principal da página da camada: você pode observar facilmente os diferentes intervalos de tráfego na camada atual e outras camadas de subnegócios no subconjunto. É usado principalmente para encontrar sua própria camada de negócios localizada em um determinado intervalo de usuário e observar o proporção de tráfego e proporção de determinados intervalos. Parâmetros etc. As informações do intervalo de tráfego na camada de subnegócio não são exibidas.

-
Visualização principal da página do bucket: a visualização principal da página do bucket pode observar simultaneamente as informações de cada camada de sub-negócio no bucket e dos buckets de subexperiência dentro da camada de negócios. Pode ser usada para verificar intuitivamente o experimento de cima para baixo para baixo contra o link experimental específico. Acerte o caminho.
A interface é exibida da seguinte forma (dados de teste):

Ao dividir as funções principais da estrutura do balde de camadas, um melhor equilíbrio pode ser alcançado entre a clareza do layout de visualização e a facilidade de uso em cenas complexas.
Melhoria da informação experimental
Experimentos de algoritmo muitas vezes precisam comparar vários indicadores para observar de forma abrangente o efeito experimental ao realizar relatórios de análise experimental.No passado, o pessoal do algoritmo e os analistas alinhavam manualmente informações, como quando um experimento começou e terminou, e quais indicadores precisavam ser observados. A fim de facilitar a análise automatizada subsequente dos efeitos experimentais, melhoramos a duração do experimento, os indicadores principais, os indicadores auxiliares e outras funções do experimento para facilitar aos usuários o gerenciamento das informações de análise do experimento. Posteriormente, contando com essas informações por meio do função automatizada pode realizar o processo de indicador de relatório experimental.Cálculos automatizados.

4.2 Melhoria da estabilidade do serviço
1. Otimização da função de lista branca dinâmica
A operação de lista de permissões é uma função de operação experimental AB frequentemente usada.Depois que os parâmetros experimentais são configurados, muitas vezes é necessário usar a lista de permissões para verificar o efeito da estratégia em pequena escala. No entanto, ao projetar a lista de permissões inicial, considerou-se que a lista de permissões afetaria o desvio de usuários, de modo que as informações da lista de permissões e as informações de configuração do layout experimental eram percebidas pelos usuários em conjunto. Isso também resultou na necessidade de relançar a configuração experimental toda vez que a lista de permissões é alterada e o fornecimento on-line representa uma ameaça à estabilidade da configuração.
solução:
Com base no processo de design e validação da lista de permissões, tentamos melhorar e otimizar o processo e o formato de configuração para que a configuração da lista de permissões possa entrar em vigor em tempo real sem afetar a configuração experimental original, conforme mostrado na figura a seguir:
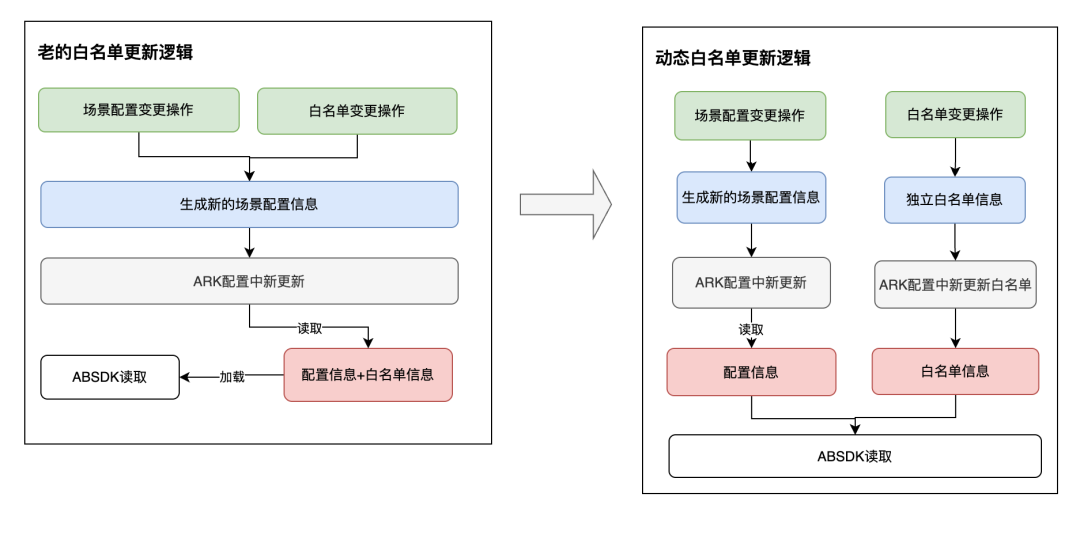
A alteração na função de lista de desbloqueio dinâmica equivale a tornar as informações de configuração da lista de desbloqueio independentes e carregá-las de forma independente quando a lista de desbloqueio é modificada, sem acionar uma atualização das próprias informações de configuração. No entanto, considerando questões de compatibilidade, cada alteração nas nossas informações de configuração também irá desencadear uma atualização adicional da lista branca. A atualização da configuração é equivalente a uma atualização completa, e tanto a configuração como a lista branca serão atualizadas. A atualização da lista de permissões equivale a atualizar apenas as informações da lista de permissões recém-adicionadas em tempo real.
2. Otimização do experimento de lançamento do Ark de operação simultânea
Como o método de distribuição de configuração do experimento AB é implementado por meio da função de notificação de configuração fornecida pelo centro de configuração do Ark, a operação em segundo plano atual do Ark para liberação de configuração é feita por meio da interface http. Ao usar a interface para operar simultaneamente a mesma configuração do Ark definido, um grande número de operações são propensos à simultaneidade, e problemas de simultaneidade podem causar falhas diretas nas operações do Ark. Esta situação dificulta muito a suavidade do processo de liberação da configuração experimental.
As soluções são as seguintes:

Após cuidadosa avaliação e seleção do plano, decidimos prosseguir com os Planos 2, 3 e 4 simultaneamente, o que finalmente resolveu completamente o problema de simultaneidade durante as operações experimentais.
4.3 Exploração e otimização da análise de efeitos experimentais
Nos últimos dois anos de prática e aprimoramento de experimentos AB, também prestamos grande atenção à análise de efeitos experimentais e atribuição de problemas.Com base nos problemas e situações reais de análise experimental encontrados, resumimos algumas experiências comuns relacionadas à análise experimental documentos.Isso envolve padronização de procedimentos experimentais, seleção de indicadores experimentais, análise de poder estatístico de indicadores experimentais, valor p e análise de confiança de indicadores experimentais, bem como problemas comuns encontrados em experimentos.
Problemas comuns de análise experimental Resumimos alguns problemas comuns e possíveis causas na análise de efeitos experimentais, que podem ajudar a solucionar problemas comuns encontrados em experimentos AB. Os detalhes são os seguintes:
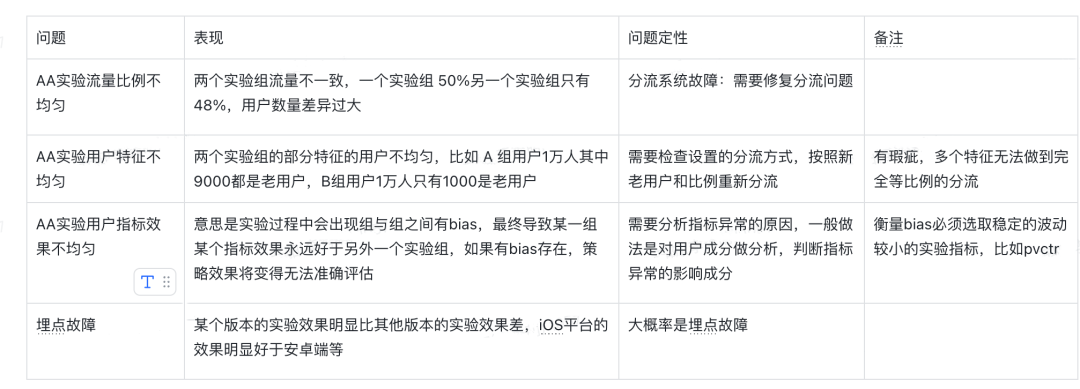
O paradoxo de Simpson em experimentos O paradoxo de Simpson é um fenômeno em probabilidade e estatística em que uma tendência aparece em vários conjuntos de dados, mas desaparece ou se inverte quando os conjuntos são combinados. Este resultado é frequentemente encontrado em estatísticas nas ciências sociais e médicas e é particularmente problemático quando os dados de frequência recebem uma interpretação causal inadequada. Este paradoxo pode ser resolvido quando variáveis perturbadoras e relações causais são tratadas adequadamente na modelagem estatística. O paradoxo de Simpson tem sido usado para ilustrar os resultados enganosos que podem surgir do uso indevido das estatísticas. Implementado em nosso experimento AB, se o índice do experimento A for maior que o do experimento B todos os dias durante um longo período experimental, o índice do período geral do experimento A não pode ser maior que o do experimento B.

Esta imagem pretende ilustrar um problema: se um ciclo experimental se estende por vários dias e o efeito experimental é observado todos os dias, se o número de usuários (ou um determinado indicador) de um determinado grupo experimental é consistentemente maior do que o de outro grupo experimental todos os dias por muito tempo, isso não significa que o desvio não seja bem-sucedido.
No primeiro dia, todos os usuários eram novos no experimento porque haviam acabado de ser redistribuídos. O grupo A era de 5,05 milhões e o grupo B era de 4,95 milhões, com erro normal de 1%.
No dia seguinte, como os usuários antigos precisam manter a mesma distribuição, usuários no grupo = novos usuários + usuários antigos retidos, os novos usuários serão reagrupados e os usuários antigos continuarão a usar o agrupamento anterior. Há duas situações neste momento :
Cenário 1 (razoável) Os usuários antigos são desviados de acordo com a distribuição original e os novos usuários são desviados com um erro de 1%.
Situação 2 (não razoável) Os usuários antigos são divididos de acordo com a distribuição original, e os novos usuários devem garantir um erro de 2% para reverter o erro de agrupamento no dia seguinte. Porém, neste caso, a proporção de novos e antigos usuários no o dia seguinte será seriamente desigual.Ao mesmo tempo, não há como manter a consistência da estratégia de desvio, o que é teoricamente impossível.
5 direções para melhorias futuras
No futuro, esperamos utilizar as capacidades gerais de cálculo e visualização de indicadores da plataforma AB no departamento de armazém de dados.Esperamos melhorar gradualmente as capacidades de visualização de dados da plataforma AB, incluindo análise visual de situações de desvio experimental, análise visual de a distribuição de características experimentais do usuário e indicadores experimentais. Colaborar com colegas analistas na solução de problemas de alterações e outros aspectos para melhorar a eficiência da análise de problemas de relatórios de indicadores em experimentos AB.
Também temos algumas ideias novas em termos de operação de informações experimentais, desempenho e estabilidade da própria plataforma experimental AB.Esperamos que no futuro possamos conectar o ambiente de desenvolvimento, ambiente de teste e ambiente de produção e implementar uma interface que possa operar em vários ambientes, reduzindo a necessidade de estudantes de algoritmo usarem AB em ambientes diferentes. Há uma necessidade de alternar entre diferentes sistemas. Ao mesmo tempo, no futuro, também esperamos usar cartões secundários para melhorar a capacidade de desvio e a estabilidade de desvio de experimentos AB, levando em consideração o desempenho do desvio e a eficiência da iteração da função da plataforma de desvio.
*Texto/ Kaiyang
Este artigo é original da Dewu Technology. Para artigos mais interessantes, consulte: Site oficial da Dewu Technology
A reimpressão sem a permissão da Dewu Technology é estritamente proibida, caso contrário, a responsabilidade legal será processada de acordo com a lei!