Vamos Hello Worldcomeçar com um exemplo de:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
Quando terminamos de digitar o código hello world acima no teclado, o arquivo salvo no disco rígido hello.goé uma sequência de bytes e cada byte representa um caractere.
Abra o arquivo hello.go com vim e, no modo de linha de comando, digite o comando:
:%!xxd
Você pode visualizar o conteúdo do arquivo em hexadecimal no vim:

A coluna mais à esquerda representa o valor do endereço, a coluna do meio representa os caracteres ASCII correspondentes ao texto e a coluna mais à direita é o nosso código. Depois execute no terminal man ascii:
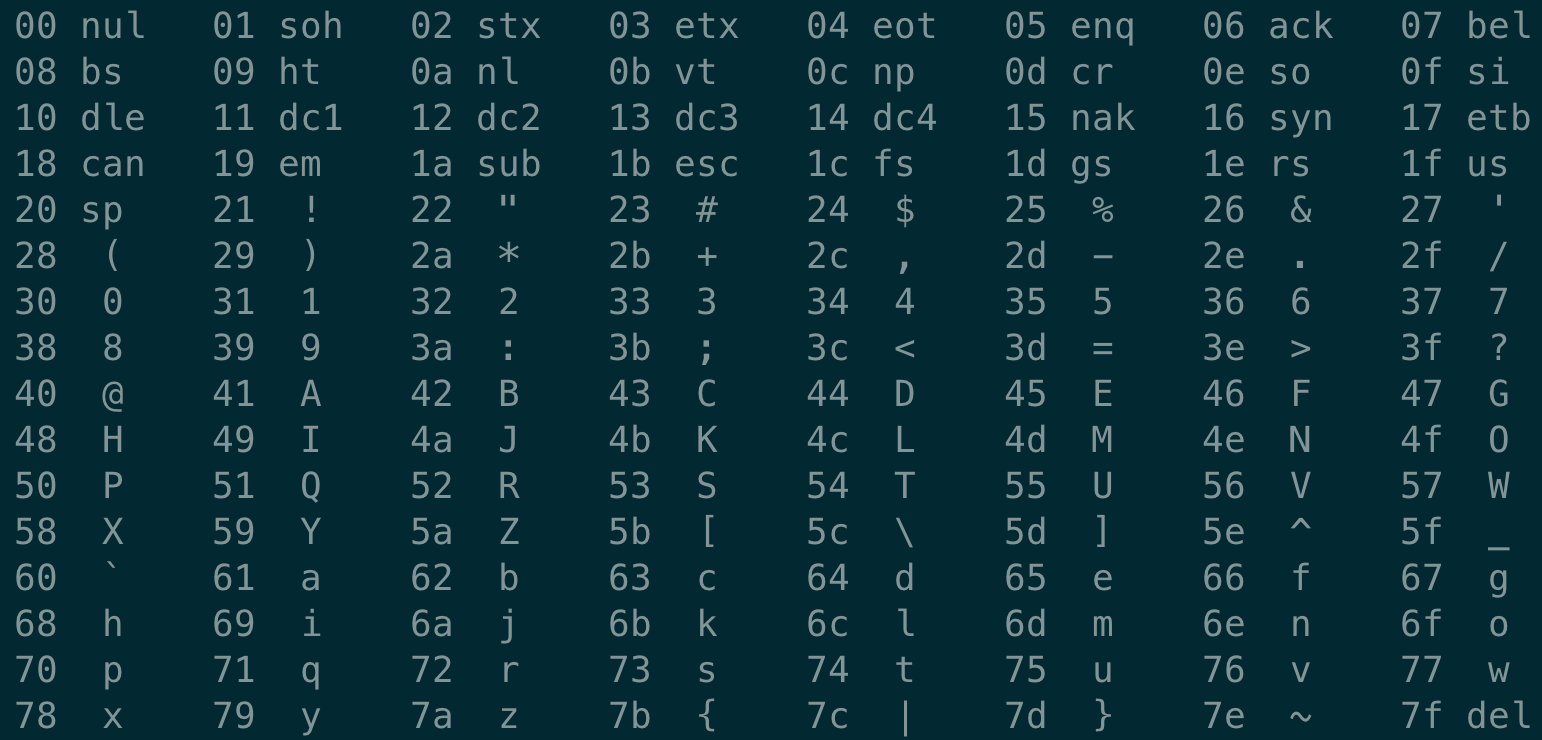
Comparando-a com a tabela de caracteres ASCII, você pode descobrir que a coluna do meio e a coluna mais à direita estão em correspondência um-para-um. Em outras palavras, o arquivo hello.go que acabamos de escrever é representado por caracteres ASCII, é chamado 文本文件e outros arquivos são chamados 二进制文件.
É claro que, olhando mais profundamente, todos os dados no computador, como arquivos de disco e dados na rede, são na verdade compostos de uma sequência de bits, dependendo de como você os encara. Em diferentes situações, a mesma sequência de bytes pode ser representada como um número inteiro, um número de ponto flutuante, uma string ou uma instrução de máquina.
Quanto a arquivos como hello.go, 8 bits, ou seja, um byte é considerado uma unidade (assumindo que os caracteres no programa fonte são todos códigos ASCII) e, em última análise, é interpretado no código-fonte Go que os humanos podem ler.
Os programas Go não podem ser executados diretamente. Cada instrução Go deve ser convertida em uma série de instruções de linguagem de máquina de baixo nível, empacotadas juntas e armazenadas na forma de um arquivo de disco binário, que é um arquivo objeto executável.
O processo de conversão de arquivos de origem em arquivos de destino executáveis:
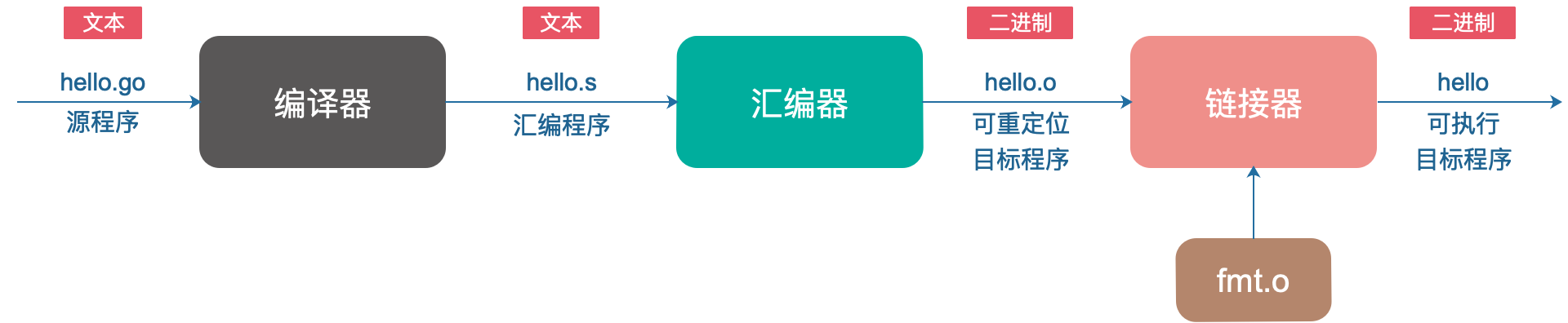
O que completa as etapas acima é o sistema de compilação Go. Você deve conhecer o famoso GCC (GNU Compile Collection), o nome chinês é GNU Compiler Suite, ele suporta C, C++, Java, Python, Objective-C, Ada, Fortran, Pascal e pode gerar código de máquina para muitas máquinas diferentes. .
Arquivos de objetos executáveis podem ser executados diretamente na máquina. De modo geral, algum trabalho de inicialização é executado primeiro; a entrada para a função principal é encontrada e o código escrito pelo usuário é executado; após a conclusão da execução, a função principal é encerrada; então algum trabalho de acabamento é executado e todo o processo está completo.
No próximo artigo, exploraremos o processo de 编译soma 运行.
O código-fonte do compilador no código-fonte Go está localizado src/cmd/compileno caminho e o código-fonte do vinculador está localizado src/cmd/linkno caminho.
Processo de compilação
Eu prefiro usar um IDE (Ambiente de Desenvolvimento Integrado) para escrever código. Goland é usado para código-fonte Go. Às vezes, basta clicar no botão "Executar" na barra de menu do IDE e o programa será executado. Na verdade, isso implica o processo de compilação e vinculação. Geralmente combinamos compilação e vinculação em um processo chamado construção.
O processo de compilação consiste em realizar análise lexical, análise de sintaxe, análise semântica e otimização no arquivo de origem e, finalmente, gerar um arquivo de código assembly como .ssufixo do arquivo.
O montador então converte o código assembly em instruções que a máquina pode executar. Como quase todas as instruções assembly correspondem a uma instrução de máquina, é apenas uma correspondência simples um-para-um, que é relativamente simples.Não há sintaxe, análise semântica ou etapas de otimização.
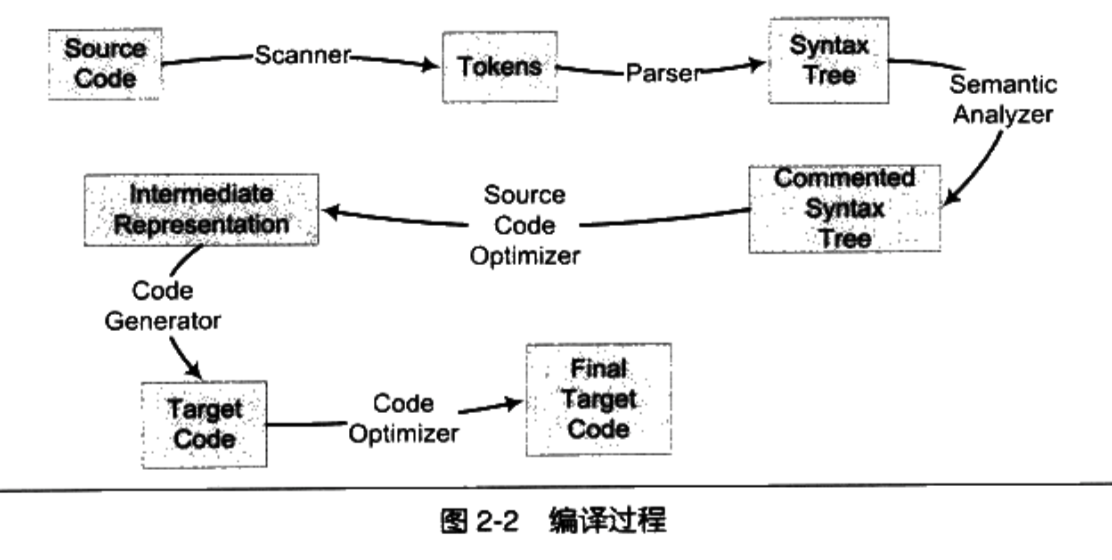
Um compilador é uma ferramenta que traduz linguagens de alto nível em linguagem de máquina. O processo de compilação é geralmente dividido em seis etapas: varredura, análise de sintaxe, análise semântica, otimização do código-fonte, geração de código e otimização do código-alvo. A imagem abaixo é de "Autocultivo do Programador":
análise lexical
Pelo exemplo anterior, sabemos que o arquivo do programa Go nada mais é do que um monte de bits binários aos olhos da máquina. Podemos entender isso porque Goland codifica esse monte de bits binários de acordo com o código ASCII (na verdade, UTF-8). Por exemplo, 8 bits são divididos em um grupo, correspondendo a um caractere, e podem ser encontrados comparando a tabela de códigos ASCII.
Quando todos os bits binários são mapeados para caracteres ASCII, podemos ver strings significativas. Pode ser uma palavra-chave, como pacote; pode ser uma string, como "Hello World".
Isto é o que a análise lexical realmente faz. A entrada é o arquivo original do programa Go. Do ponto de vista do analisador léxico, é apenas um monte de bits binários. Não se sabe o que são. Após sua análise, ele se transforma em tokens significativos. Simplificando, a análise lexical é o processo em ciência da computação de conversão de uma sequência de caracteres em uma sequência de tokens.
Vamos dar uma olhada na definição dada na Wikipedia:
A análise lexical é o processo em ciência da computação de converter uma sequência de caracteres em uma sequência de tokens. O programa ou função que realiza a análise lexical é chamado de analisador léxico (abreviadamente lexer), também chamado de scanner. Os analisadores lexicais geralmente existem na forma de funções para serem chamadas pelo analisador de sintaxe.
.goO arquivo é inserido no scanner (Scanner), que utiliza um 有限状态机algoritmo semelhante ao do código-fonte para dividir a série de caracteres do código-fonte em uma série de tokens (Token).
Os tokens são geralmente divididos nestas categorias: palavras-chave, identificadores, literais (incluindo números e strings) e símbolos especiais (como sinal de mais, sinal de igual).
Por exemplo, para o seguinte código:
slice[i] = i * (2 + 6)
Contém um total de 16 caracteres não vazios. Após a digitalização,
| marca | tipo |
|---|---|
| fatiar | identificador |
| [ | colchete esquerdo |
| eu | identificador |
| ] | colchete direito |
| = | Atribuição |
| eu | identificador |
| * | Sinal de multiplicação |
| ( | parêntese esquerdo |
| 2 | número |
| + | mais |
| 6 | número |
| ) | parêntese direito |
O exemplo acima vem de "Autocultivo do programador", que explica principalmente o conteúdo relacionado à compilação e vinculação. É muito interessante e recomendado para leitura.
Linguagem Go (a versão Go deste artigo é 1.9.2) Token suportado pelo caminho do scanner no código-fonte:
src/cmd/compile/internal/syntax/token.go
Sinta:
var tokstrings = [...]string{
// source control
_EOF: "EOF",
// names and literals
_Name: "name",
_Literal: "literal",
// operators and operations
_Operator: "op",
_AssignOp: "op=",
_IncOp: "opop",
_Assign: "=",
_Define: ":=",
_Arrow: "<-",
_Star: "*",
// delimitors
_Lparen: "(",
_Lbrack: "[",
_Lbrace: "{",
_Rparen: ")",
_Rbrack: "]",
_Rbrace: "}",
_Comma: ",",
_Semi: ";",
_Colon: ":",
_Dot: ".",
_DotDotDot: "...",
// keywords
_Break: "break",
_Case: "case",
_Chan: "chan",
_Const: "const",
_Continue: "continue",
_Default: "default",
_Defer: "defer",
_Else: "else",
_Fallthrough: "fallthrough",
_For: "for",
_Func: "func",
_Go: "go",
_Goto: "goto",
_If: "if",
_Import: "import",
_Interface: "interface",
_Map: "map",
_Package: "package",
_Range: "range",
_Return: "return",
_Select: "select",
_Struct: "struct",
_Switch: "switch",
_Type: "type",
_Var: "var",
}
Ainda é relativamente familiar, incluindo nomes e literais, operadores, delimitadores e palavras-chave.
E o caminho para o scanner é:
src/cmd/compile/internal/syntax/scanner.go
A função mais crítica é a próxima função, que lê continuamente o próximo caractere (não o próximo byte, porque a linguagem Go suporta codificação Unicode, não como o exemplo de código ASCII que demos anteriormente, onde um caractere possui apenas um byte), até que estes personagens podem constituir um Token.
func (s *scanner) next() {
// ……
redo:
// skip white space
c := s.getr()
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
// token start
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
s.ident()
return
}
switch c {
// ……
case '\n':
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
// ……
default:
s.tok = 0
s.error(fmt.Sprintf("invalid character %#U", c))
goto redo
return
assignop:
if c == '=' {
s.tok = _AssignOp
return
}
s.ungetr()
s.tok = _Operator
}
A lógica principal do c := s.getr()obter o próximo caractere não analisado por meiocódigo éswitch-case
O scanner do analisador léxico no pacote atual fornece apenas o próximo método para a camada superior. O processo de análise léxica é lento. O próximo será chamado para obter o token mais recente somente quando o analisador da camada superior precisar dele.
Análise gramatical
A sequência de token gerada na etapa anterior precisa ser processada posteriormente 表达式para nó 语法树.
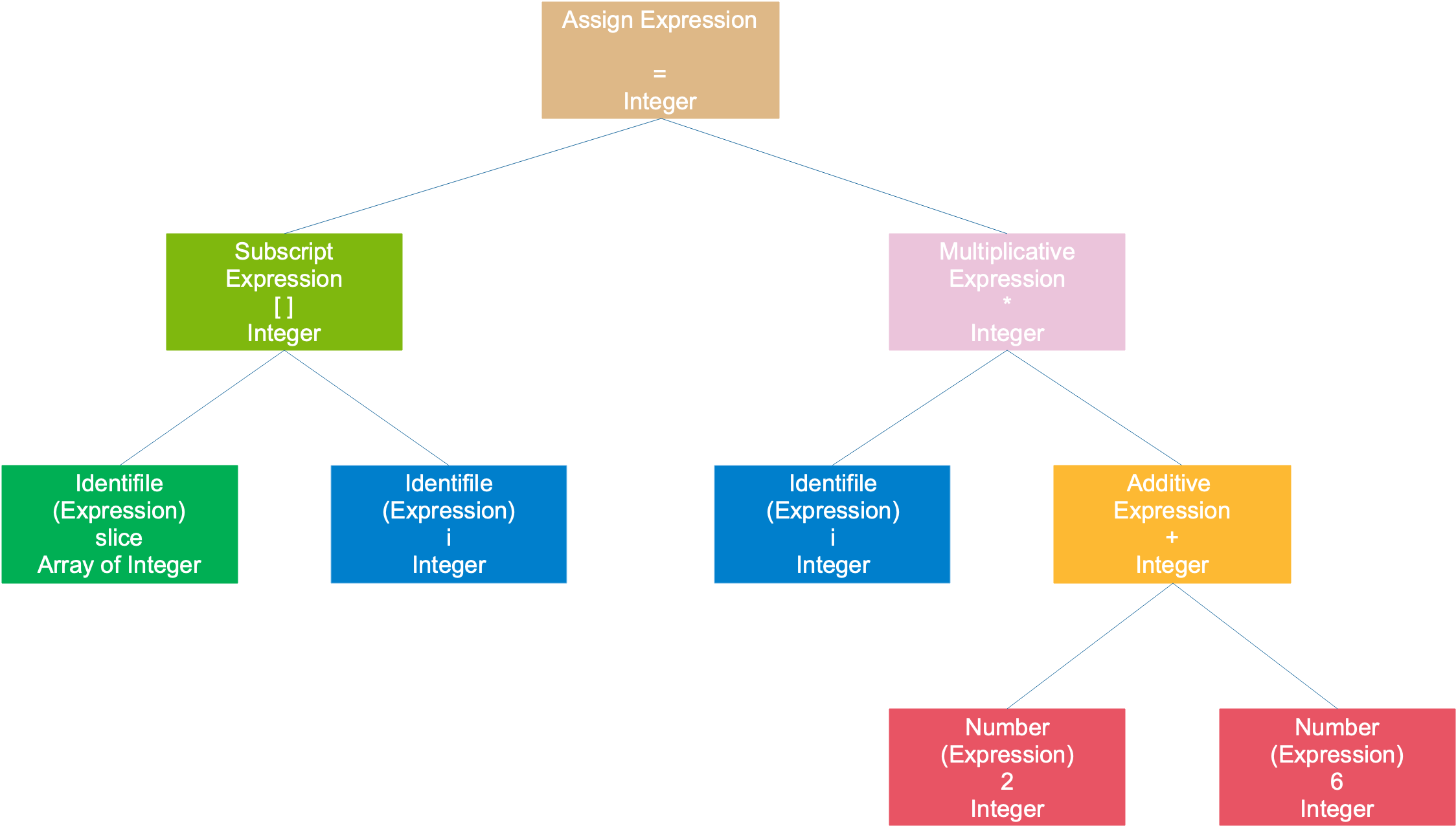
Por exemplo, no primeiro exemplo, slice[i] = i * (2 + 6)a árvore de sintaxe resultante é a seguinte:

A instrução inteira é considerada uma expressão de atribuição, a subárvore esquerda é uma expressão de matriz e a subárvore direita é uma expressão de multiplicação; a expressão de matriz consiste em 2 expressões simbólicas; a expressão de multiplicação é composta por uma expressão simbólica Consiste em uma expressão e uma expressão de sinal de mais; a expressão de sinal de mais consiste em dois números. Símbolos e números são as menores expressões que não podem mais ser decompostas e geralmente servem como nós folhas de uma árvore.
O processo de análise de sintaxe pode detectar alguns erros formais, como falta de metade dos parênteses, +falta de um operando em uma expressão, etc.
A análise gramatical é um processo que analisa o texto de entrada composto por sequências de Token de acordo com uma gramática formal específica (Gramática) e determina sua estrutura gramatical.
Análise Semântica
Após a conclusão da análise gramatical, não sabemos qual é o significado específico da afirmação. Se as duas subárvores do número acima *forem dois ponteiros, isso é ilegal, mas a análise sintática não consegue detectá-lo. É isso que a análise semântica faz.
O que pode ser verificado em tempo de compilação é a semântica estática, que pode ser considerada no estágio de "código", incluindo correspondência de tipo de variável, conversão, etc. Por exemplo, ao atribuir um valor de ponto flutuante a uma variável de ponteiro, se houver uma incompatibilidade óbvia de tipos, um erro de compilação será relatado. Quanto aos erros que ocorrem apenas durante o tempo de execução: se você adicionar acidentalmente um 0, a análise semântica não poderá detectá-lo.
Após a conclusão da fase de análise semântica, cada nó será marcado com um tipo:
Nesta fase, o compilador Go verifica os tipos de constantes, tipos, declarações de função e instruções de atribuição de variáveis e, em seguida, verifica os tipos de chaves no hash. Funções que implementam verificação de tipo são geralmente instruções switch/case gigantescas de vários milhares de linhas.
A verificação de tipo é o segundo estágio da compilação da linguagem Go. Após a análise léxica e sintática, obtemos a árvore de sintaxe abstrata correspondente a cada arquivo. A verificação de tipo subsequente percorrerá os nós na árvore de sintaxe abstrata e executará a verificação de tipo em cada nó. Verifique para encontrar quaisquer erros gramaticais.
A árvore de sintaxe abstrata também pode ser reescrita durante este processo, o que não apenas remove algum código que não será executado para otimizar a compilação e melhorar a eficiência da execução, mas também modifica os tipos de operação dos nós correspondentes a palavras-chave como make e new.
Por exemplo, a palavra-chave make mais comumente usada pode ser usada para criar vários tipos, como fatia, mapa, canal, etc. Nesta etapa, para a palavra-chave make, ou seja, o nó OMAKE, seu tipo de parâmetro será verificado primeiro e, dependendo do tipo, será inserida a ramificação correspondente. Se o tipo de parâmetro for slice, ele entrará na ramificação do caso TSLICE e verificará se len e cap atendem aos requisitos, como len <= cap. Finalmente, o tipo de nó será alterado de OMAKE para OMAKESLICE.
Geração de código intermediário
Sabemos que o processo de compilação geralmente pode ser dividido em front-end e back-end, o front-end gera código intermediário independente da plataforma e o back-end gera diferentes códigos de máquina para diferentes plataformas.
A análise lexical anterior, a análise sintática, a análise semântica, etc., todas pertencem ao front-end do compilador, e os estágios subsequentes pertencem ao back-end do compilador.
Existem muitos links de otimização no processo de compilação, e este link refere-se à otimização no nível do código-fonte. Ele converte árvores sintáticas em códigos intermediários, que são representações sequenciais de árvores sintáticas.
O código intermediário é geralmente independente da máquina de destino e do ambiente de execução e possui vários formatos comuns: código de três endereços e código P. Por exemplo, o mais básico 三地址码é este:
x = y op z
Isso significa que depois que a variável y e a variável z realizam a operação operacional, elas são atribuídas a x. op pode ser uma operação matemática como adição, subtração, multiplicação e divisão.
O exemplo que demos anteriormente pode ser escrito da seguinte forma:
t1 = 2 + 6
t2 = i * t1
slice[i] = t2
Aqui 2 + 6 pode ser calculado diretamente, de modo que a variável temporária t1 seja "otimizada", e a variável t1 possa ser reutilizada, de modo que t2 também possa ser "otimizado". Após a otimização:
t1 = i * 8
slice[i] = t1
A representação de código intermediário da linguagem Go é SSA (Static Single-Assignment, atribuição estática única) É chamada de atribuição única porque cada nome é atribuído apenas uma vez no SSA. .
Nesta fase, as variáveis correspondentes utilizadas para gerar o código intermediário serão definidas de acordo com a arquitetura da CPU, como o tamanho dos ponteiros e registros utilizados pelo compilador, a lista de registros disponíveis, etc. As duas partes, geração de código intermediário e geração de código de máquina, compartilham as mesmas configurações.
Antes de gerar o código intermediário, alguns elementos dos nós da árvore de sintaxe abstrata são substituídos. Aqui está uma foto de um blog relacionado aos princípios de compilação da "Programação Orientada à Fé":
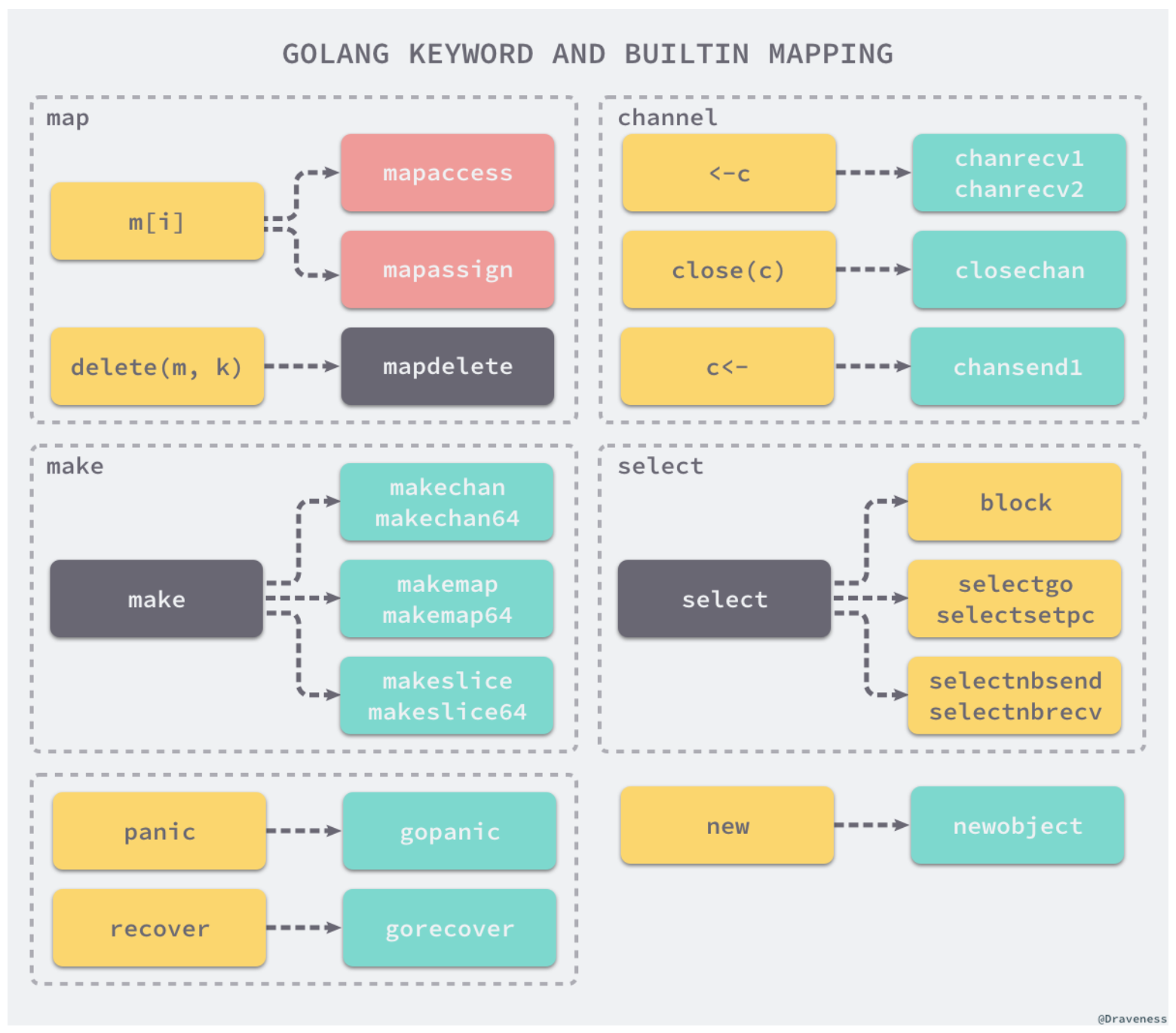
Por exemplo, a operação do mapa m[i] será convertida em mapacess ou mapassign aqui.
O programa principal da linguagem Go chamará funções em tempo de execução quando executado, ou seja, as funções de palavras-chave e funções integradas são realmente concluídas pelo compilador da linguagem e pelo tempo de execução.
O processo de geração de código intermediário é, na verdade, o processo de conversão da árvore de sintaxe abstrata AST para o código intermediário SSA.Durante este período, as palavras-chave na árvore de sintaxe serão atualizadas uma vez, e a árvore de sintaxe atualizada passará por várias rodadas de processamento para transformar o SSA final.código intermediário.
Geração e otimização de código alvo
Máquinas diferentes têm comprimentos de palavras de máquina, registros, etc. diferentes, o que significa que o código de máquina executado em máquinas diferentes é diferente. O objetivo da etapa final é gerar código que possa ser executado em diferentes arquiteturas de CPU.
Para extrair cada gota de óleo e água da máquina, o otimizador de código-alvo otimizará algumas instruções, como usar instruções de mudança em vez de instruções de multiplicação.
Eu realmente não tenho a capacidade de me aprofundar nessa área, mas felizmente não preciso me aprofundar. Para engenheiros de desenvolvimento de software da camada de aplicação, é suficiente entendê-lo.
processo de vinculação
O processo de compilação é realizado para um único arquivo, e os arquivos referem-se inevitavelmente a variáveis globais ou funções definidas em outros módulos, os endereços dessas variáveis ou funções só podem ser determinados nesta fase.
O processo de vinculação consiste em vincular os arquivos objeto gerados pelo compilador em arquivos executáveis. O arquivo final é dividido em vários segmentos, como segmentos de dados, segmentos de código, segmentos BSS, etc., e será carregado na memória durante o tempo de execução. Cada segmento possui diferentes atributos de leitura, gravação e execução, o que protege a operação segura do programa.