o que é mapa
A Wikipedia define mapa assim:
Na ciência da computação, uma matriz associativa, mapa, tabela de símbolos ou dicionário é um tipo de dados abstrato composto por uma coleção de pares (chave, valor), de modo que cada chave possível apareça no máximo uma vez na coleção.
Uma breve explicação: Na ciência da computação, é chamado de array associado, mapa, tabela de símbolos ou dicionário, que é uma <key, value>estrutura de dados abstrata composta por um conjunto de pares, e a mesma chave aparecerá apenas uma vez.
Existem dois pontos-chave: o mapa é composto key-valuede pares; keyele aparece apenas uma vez.
As principais operações relacionadas ao mapa são:
- Adicionar um par kv - Adicionar ou inserir;
- Excluir um par kv - Remover ou excluir;
- Modifique v correspondente a um determinado k - Reatribuir;
- Consultar o v correspondente a um determinado k - Lookup;
Simplificando, é o mais básico 增删查改.
O design do mapa também é chamado de "O problema do dicionário", sua tarefa é projetar uma estrutura de dados para manter os dados de uma coleção e realizar operações de adição, exclusão, consulta e modificação na coleção ao mesmo tempo. Existem duas estruturas de dados principais: 哈希查找表(Hash table), 搜索树(Search tree).
A tabela de pesquisa hash usa uma função hash para atribuir chaves a diferentes buckets (ou seja, diferentes índices da matriz). Dessa forma, o overhead está principalmente no cálculo da função hash e no tempo de acesso constante do array. Em muitos cenários, o desempenho das tabelas de pesquisa hash é muito alto.
As tabelas de pesquisa de hash geralmente apresentam problemas de "colisão", o que significa que chaves diferentes são criptografadas no mesmo intervalo. Geralmente há duas maneiras de lidar com isso: 链表法e 开放地址法. 链表法Implemente um bucket como uma lista vinculada e as chaves que estiverem no mesmo bucket serão inseridas nesta lista vinculada. 开放地址法Após a colisão ocorrer, de acordo com certas regras, “vagas” são selecionadas no final do array para colocar novas chaves.
O método da árvore de pesquisa geralmente usa árvores de pesquisa com autoequilíbrio, incluindo: árvores AVL e árvores vermelho-pretas. Durante as entrevistas, muitas vezes somos solicitados e até mesmo solicitados a escrever o código da árvore vermelho-preto à mão, muitas vezes o entrevistador não consegue escrevê-lo sozinho, o que é muito excessivo.
A pior eficiência de pesquisa do método de árvore de pesquisa de autoequilíbrio é O(logN), enquanto a pior eficiência de pesquisa da tabela de pesquisa de hash é O(N). Obviamente, a eficiência média de pesquisa de uma tabela de pesquisa de hash é O (1).Se a função hash for bem projetada, o pior cenário basicamente não ocorrerá. Outro ponto é que ao percorrer a árvore de busca de auto-equilíbrio, a sequência de chaves retornada geralmente estará em ordem crescente; enquanto a tabela de pesquisa de hash está fora de ordem.
Como implementar a camada inferior do mapa
Primeiro declare a versão Go que uso:
go version go1.9.2 darwin/amd64
Como mencionado anteriormente, existem várias maneiras de implementar o mapa. A linguagem Go usa tabelas de pesquisa de hash e listas vinculadas para resolver conflitos de hash.
A seguir exploraremos os princípios básicos do mapa e teremos uma ideia de sua estrutura interna.
modelo de memória de mapa
No código-fonte, a estrutura que representa o mapa é hmap, que é a “abreviatura” de hashmap:
// A header for a Go map.
type hmap struct {
// 元素个数,调用 len(map) 时,直接返回此值
count int
flags uint8
// buckets 的对数 log_2
B uint8
// overflow 的 bucket 近似数
noverflow uint16
// 计算 key 的哈希的时候会传入哈希函数
hash0 uint32
// 指向 buckets 数组,大小为 2^B
// 如果元素个数为0,就为 nil
buckets unsafe.Pointer
// 等量扩容的时候,buckets 长度和 oldbuckets 相等
// 双倍扩容的时候,buckets 长度会是 oldbuckets 的两倍
oldbuckets unsafe.Pointer
// 指示扩容进度,小于此地址的 buckets 迁移完成
nevacuate uintptr
extra *mapextra // optional fields
}
Para explicar, Bé o logaritmo do comprimento da matriz de baldes, o que significa que o comprimento da matriz de baldes é 2 ^ B. A chave e o valor são armazenados no bucket, que será discutido mais tarde.
buckets é um ponteiro que aponta para uma estrutura:
type bmap struct {
tophash [bucketCnt]uint8
}
Mas esta é apenas a estrutura da superfície (src/runtime/hashmap.go). Ela será adicionada durante a compilação e uma nova estrutura será criada dinamicamente:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
bmapÉ o que costumamos chamar de "balde". Um balde pode conter até 8 chaves. A razão pela qual essas chaves caem no mesmo balde é porque depois de terem sido hash, os resultados do hash são do mesmo tipo. No balde, os 8 bits superiores do valor de hash calculado pela chave serão usados para determinar onde a chave cai no balde (há até 8 posições em um balde).
Aqui está uma visão geral:
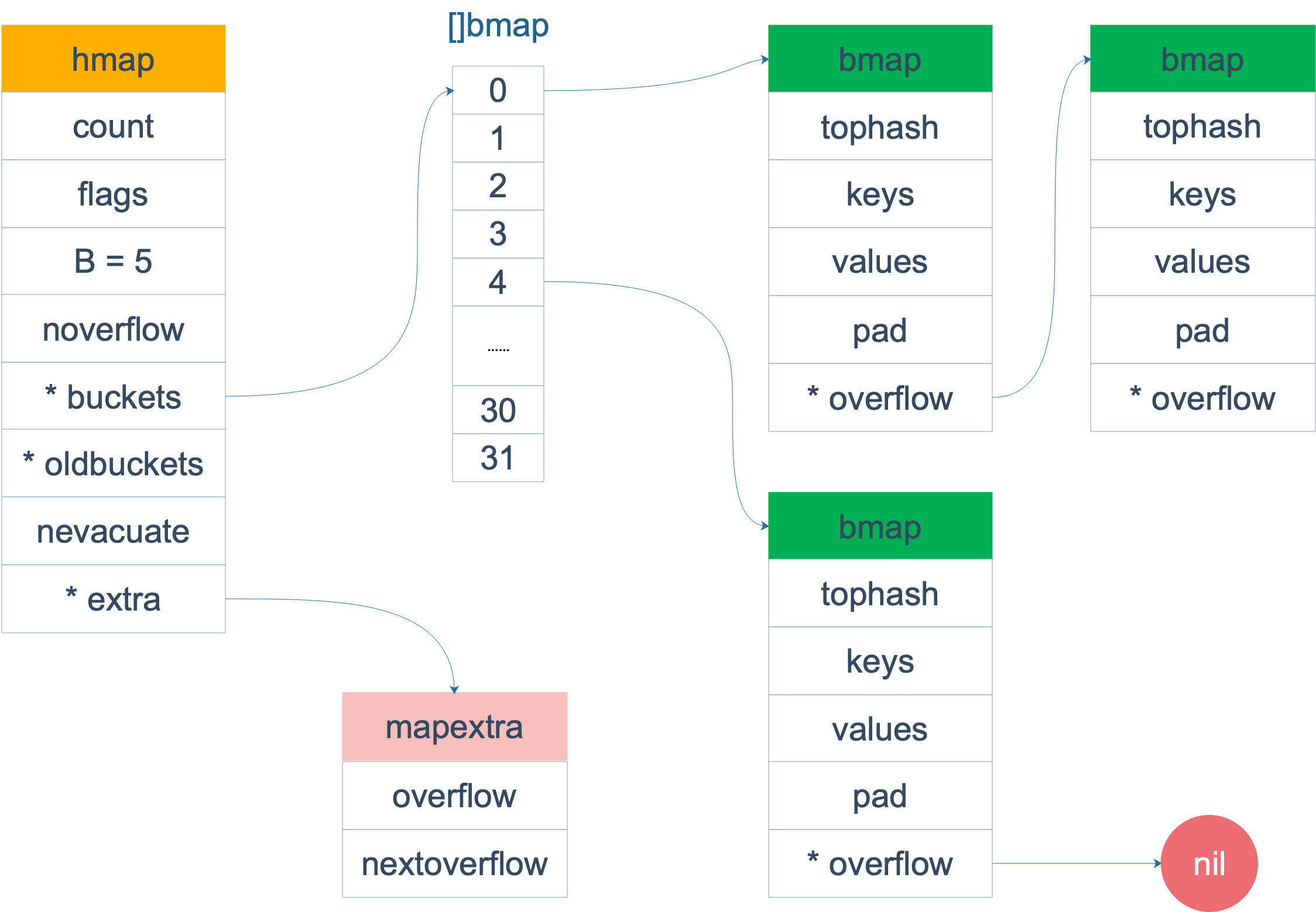
Quando a chave e o valor do mapa não são ponteiros e o tamanho é menor que 128 bytes, o bmap será marcado como não contendo ponteiros, o que pode evitar a varredura de todo o hmap durante o gc. Porém, vemos que o bmap na verdade possui um campo overflow, que é do tipo ponteiro, o que destrói a ideia de que o bmap não contém ponteiros. Nesse caso, o overflow será movido para o campo extra.
type mapextra struct {
// overflow[0] contains overflow buckets for hmap.buckets.
// overflow[1] contains overflow buckets for hmap.oldbuckets.
overflow [2]*[]*bmap
// nextOverflow 包含空闲的 overflow bucket,这是预分配的 bucket
nextOverflow *bmap
}
bmap é onde o kv é armazenado. Vamos ampliar e dar uma olhada mais de perto na composição interna do bmap.

A imagem acima é o modelo de memória do balde, HOB Hashque se refere ao hash superior. Observe que chave e valor são reunidos separadamente, não desta key/value/key/value/...forma. O código-fonte afirma que a vantagem disso é que em alguns casos o campo de preenchimento pode ser omitido para economizar espaço de memória.
Por exemplo, existe um mapa deste tipo:
map[int64]int8
Se key/value/key/value/...armazenado neste modo, 7 bytes adicionais de preenchimento serão adicionados após cada par chave/valor; e todas as chaves e valores serão vinculados separadamente. Neste formulário, apenas o preenchimento precisa ser adicionado no final key/key/.../value/value/....
Cada intervalo é projetado para conter até 8 pares de valores-chave. Se um nono valor-chave cair no intervalo atual, outro intervalo precisará ser construído e conectado por meio de ponteiros overflow.
Criar mapa
Sintaticamente, criar um mapa é simples:
ageMp := make(map[string]int)
// 指定 map 长度
ageMp := make(map[string]int, 8)
// ageMp 为 nil,不能向其添加元素,会直接panic
var ageMp map[string]int
Pode-se ver na linguagem assembly que a makemapfunção subjacente é realmente chamada, e sua principal tarefa é inicializar hmapvários campos da estrutura, como calcular o tamanho de B, definir a semente de hash hash0 e assim por diante.
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {
// 省略各种条件检查...
// 找到一个 B,使得 map 的装载因子在正常范围内
B := uint8(0)
for ; overLoadFactor(hint, B); B++ {
}
// 初始化 hash table
// 如果 B 等于 0,那么 buckets 就会在赋值的时候再分配
// 如果长度比较大,分配内存会花费长一点
buckets := bucket
var extra *mapextra
if B != 0 {
var nextOverflow *bmap
buckets, nextOverflow = makeBucketArray(t, B)
if nextOverflow != nil {
extra = new(mapextra)
extra.nextOverflow = nextOverflow
}
}
// 初始化 hamp
if h == nil {
h = (*hmap)(newobject(t.hmap))
}
h.count = 0
h.B = B
h.extra = extra
h.flags = 0
h.hash0 = fastrand()
h.buckets = buckets
h.oldbuckets = nil
h.nevacuate = 0
h.noverflow = 0
return h
}
[Extensão 1] Qual é a diferença entre fatia e mapa quando são usados como parâmetros de função?
Observe que o resultado retornado por esta função é: *hmap, que é um ponteiro, enquanto makeslicea função que falamos antes retorna Sliceuma estrutura:
func makeslice(et *_type, len, cap int) slice
Vamos revisar a definição da estrutura de fatia:
// runtime/slice.go
type slice struct {
array unsafe.Pointer // 元素指针
len int // 长度
cap int // 容量
}
A estrutura contém ponteiros de dados subjacentes.
A diferença entre makemap e makeslice traz uma diferença: quando map e slice são usados como parâmetros de função, a operação de map dentro dos parâmetros de função afetará o próprio map; mas não para slice (como mencionado no artigo anterior sobre slice).
O principal motivo: um é um ponteiro ( *hmap) e o outro é uma estrutura ( slice). Os parâmetros de função na linguagem Go são todos passados por valor. Dentro da função, os parâmetros serão copiados localmente. *hmapDepois que o ponteiro é copiado, ele ainda aponta para o mesmo mapa, portanto a operação do mapa dentro da função afetará os parâmetros reais. Após a fatia ser copiada, ela se tornará uma nova fatia e as operações realizadas nela não afetarão os parâmetros reais.
Função hash
Um ponto chave do mapa é a escolha da função hash. Quando o programa for iniciado, ele detectará se a CPU suporta aes. Nesse caso, use o hash aes, caso contrário, use o memhash. Isso é alginit()feito em function , localizado src/runtime/alg.goem path:.
A função hash possui tipos criptografados e não criptografados.
O tipo criptografado é geralmente usado para criptografar dados, resumos digitais, etc. Os representantes típicos são md5, sha1, sha256, aes256; o
tipo não criptografado é geralmente usado para pesquisa. No cenário de aplicação do mapa, a pesquisa é utilizada.
Existem dois pontos principais a serem considerados ao escolher uma função hash: desempenho e probabilidade de colisão.
Já falamos sobre isso antes, a estrutura que representa o tipo:
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
alg *typeAlg
gcdata *byte
str nameOff
ptrToThis typeOff
}
O algcampo está relacionado ao hash, que é um ponteiro para a seguinte estrutura:
// src/runtime/alg.go
type typeAlg struct {
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
}
typeAlg contém duas funções, a função hash calcula o valor hash do tipo e a função equal calcula se os dois tipos são "hash iguais".
Para o tipo string, suas funções hash e equal são as seguintes:
func strhash(a unsafe.Pointer, h uintptr) uintptr {
x := (*stringStruct)(a)
return memhash(x.str, h, uintptr(x.len))
}
func strequal(p, q unsafe.Pointer) bool {
return *(*string)(p) == *(*string)(q)
}
De acordo com o tipo de chave, o campo alg da estrutura _type será definido com as funções hash e iguais do tipo correspondente.
processo de posicionamento de chave
Após o hash da chave, o valor do hash é obtido, com um total de 64 bits (máquinas de 64 bits e máquinas de 32 bits não serão discutidas. Agora o mainstream são máquinas de 64 bits). Ao calcular qual balde ele cairá em, apenas os últimos bits B são usados. Lembra do B mencionado anteriormente? Se B = 5, então o número de buckets, ou seja, o comprimento da matriz de buckets é 2 ^ 5 = 32.
Por exemplo, depois que uma chave é calculada por uma função hash, o resultado hash é:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
Use os últimos 5 bits, ou seja 01010, o valor é 10, que é o intervalo nº 10. Esta operação é na verdade uma operação restante, mas a operação restante é muito cara, então a implementação do código usa operações de bit.
Em seguida, use os 8 bits mais altos do valor hash para encontrar a localização dessa chave no bucket. Isso procura uma chave existente. A princípio não há chave no balde, e a chave recém-adicionada encontrará o primeiro slot vazio e o colocará nele.
O número do bucket é o número do bucket. Quando duas chaves diferentes caem no mesmo bucket, ocorre um conflito de hash. O método de resolução de conflitos é usar o método de lista vinculada: no balde, encontre o primeiro slot vazio da frente para trás. Dessa forma, ao pesquisar uma determinada chave, primeiro encontre o intervalo correspondente e, em seguida, percorra as chaves no intervalo.
Aqui está uma referência a uma imagem no blog do github de Cao Da. A imagem original é uma imagem ASCII, cheia de sabor geek. Você pode encontrar o blog de Cao Da nos materiais de referência. Recomendo a todos que dêem uma olhada.
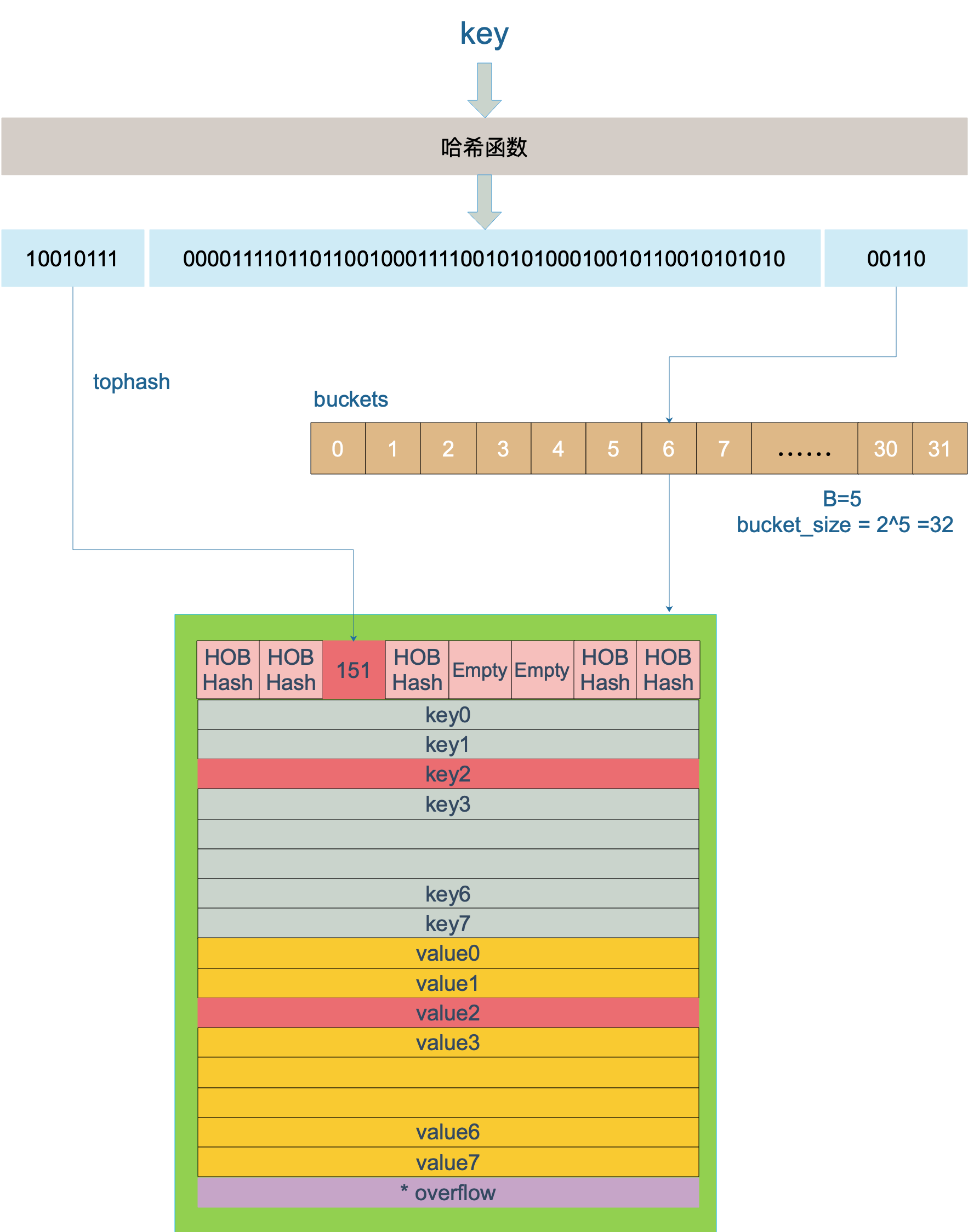
Na figura acima, assume-se que B = 5, então o número total de baldes é 2 ^ 5 = 32. Primeiro, calcule o hash da chave a ser encontrada. Use os 5 bits inferiores 00110para encontrar o balde correspondente nº 6. Use os 8 bits superiores 10010111, que correspondem ao decimal 151. Encontre a chave com um valor tophash (hash HOB) de 151 no balde nº 6 e encontre-o, slot 2, e todo o processo de pesquisa estará concluído.
Se não for encontrado no bucket e o overflow não estiver vazio, ele continuará pesquisando no bucket de overflow até ser encontrado ou até que todos os slots de chave tenham sido pesquisados, incluindo todos os buckets de overflow.
Vamos dar uma olhada no código fonte, haha! Através da linguagem assembly, podemos ver que a função subjacente para encontrar uma determinada chave é mapacessuma série de funções.As funções das funções são semelhantes e as diferenças serão discutidas na próxima seção. Aqui olhamos diretamente para mapacess1a função:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ……
// 如果 h 什么都没有,返回零值
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
// 写和读冲突
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 不同类型 key 使用的 hash 算法在编译期确定
alg := t.key.alg
// 计算哈希值,并且加入 hash0 引入随机性
hash := alg.hash(key, uintptr(h.hash0))
// 比如 B=5,那 m 就是31,二进制是全 1
// 求 bucket num 时,将 hash 与 m 相与,
// 达到 bucket num 由 hash 的低 8 位决定的效果
m := uintptr(1)<<h.B - 1
// b 就是 bucket 的地址
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// oldbuckets 不为 nil,说明发生了扩容
if c := h.oldbuckets; c != nil {
// 如果不是同 size 扩容(看后面扩容的内容)
// 对应条件 1 的解决方案
if !h.sameSizeGrow() {
// 新 bucket 数量是老的 2 倍
m >>= 1
}
// 求出 key 在老的 map 中的 bucket 位置
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果 oldb 没有搬迁到新的 bucket
// 那就在老的 bucket 中寻找
if !evacuated(oldb) {
b = oldb
}
}
// 计算出高 8 位的 hash
// 相当于右移 56 位,只取高8位
top := uint8(hash >> (sys.PtrSize*8 - 8))
// 增加一个 minTopHash
if top < minTopHash {
top += minTopHash
}
for {
// 遍历 bucket 的 8 个位置
for i := uintptr(0); i < bucketCnt; i++ {
// tophash 不匹配,继续
if b.tophash[i] != top {
continue
}
// tophash 匹配,定位到 key 的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// key 是指针
if t.indirectkey {
// 解引用
k = *((*unsafe.Pointer)(k))
}
// 如果 key 相等
if alg.equal(key, k) {
// 定位到 value 的位置
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
// value 解引用
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
// bucket 找完(还没找到),继续到 overflow bucket 里找
b = b.overflow(t)
// overflow bucket 也找完了,说明没有目标 key
// 返回零值
if b == nil {
return unsafe.Pointer(&zeroVal[0])
}
}
}
A função retorna o ponteiro de h[chave].Se não existir tal chave em h, ela retornará um valor zero do tipo de chave correspondente e não retornará nulo.
O código é relativamente simples em geral e não há nada difícil de entender. Basta seguir os comentários acima para entender o passo a passo.
Aqui, vamos falar sobre o método de localização de chave e valor e como escrever o loop inteiro.
// key 定位公式
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// value 定位公式
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
b é o endereço de bmap. Aqui, bmap ainda é uma estrutura definida no código-fonte. Ela contém apenas uma matriz tophash. A estrutura expandida pelo compilador contém apenas campos de chave, valor e overflow. dataOffset é o deslocamento da chave em relação ao endereço inicial do bmap:
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
Portanto, o endereço inicial da chave no bucket é inseguro.Pointer(b)+dataOffset. O endereço da i-ésima chave abrangerá o tamanho das i chaves com base nisso; e também sabemos que o endereço do valor está depois de todas as chaves, portanto, o endereço do i-ésimo valor também precisa adicionar os deslocamentos de todas as chaves. . Depois de entender isso, as fórmulas de posicionamento de chave e valor acima são fáceis de entender.
Vamos falar sobre o método de escrita de todo o grande loop. A camada mais externa é um loop infinito. Através
b = b.overflow(t)
Percorra todos os buckets, o que equivale a uma lista vinculada de buckets.
Quando um bucket específico é localizado, o loop interno percorre todas as células do bucket, ou todos os slots, ou seja, bucketCnt=8 slots. Todo o processo do ciclo:
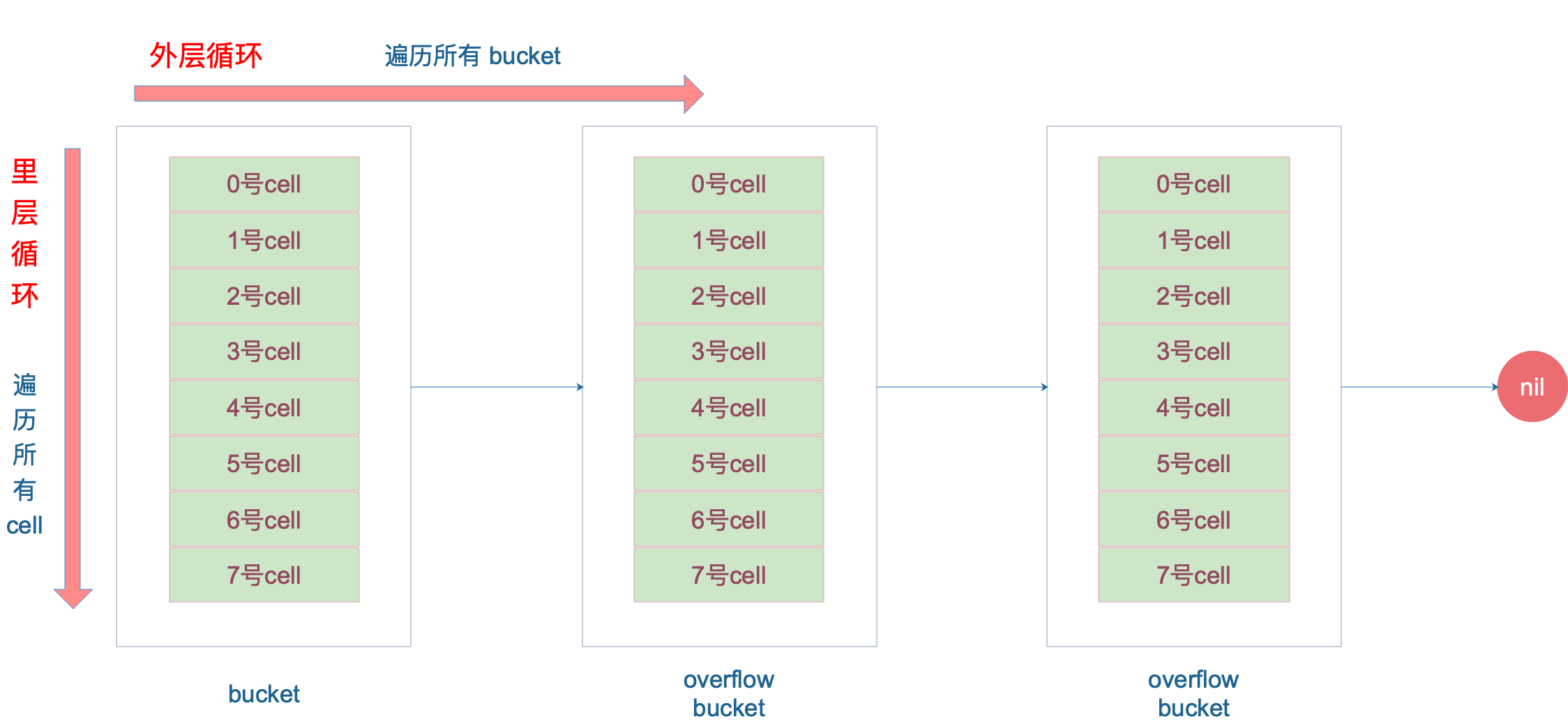
Vamos falar sobre minTopHash novamente: quando o valor tophash de uma célula é menor que minTopHash, ele marca o status de migração desta célula. Como esse valor de status é colocado na matriz tophash, para distingui-lo do valor hash normal, o valor hash calculado pela chave será incrementado: minTopHash. Isso distingue entre valores de hash superiores normais e valores de hash que representam status.
Os seguintes estados caracterizam a situação do balde:
// 空的 cell,也是初始时 bucket 的状态
empty = 0
// 空的 cell,表示 cell 已经被迁移到新的 bucket
evacuatedEmpty = 1
// key,value 已经搬迁完毕,但是 key 都在新 bucket 前半部分,
// 后面扩容部分会再讲到。
evacuatedX = 2
// 同上,key 在后半部分
evacuatedY = 3
// tophash 的最小正常值
minTopHash = 4
A função usada no código-fonte para determinar se o bucket foi realocado:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash
}
Apenas o primeiro valor da matriz tophash é usado para determinar se está entre 0-4. Comparando as constantes acima, quando o hash superior é um dos três valores ,,,, significa que todas as chaves neste balde foram movidas para o novo balde evacuatedEmpty.evacuatedXevacuatedY