YOLOv5-Face
Diretório de artigos
- YOLOv5-Face
-
- 1. Por que detecção facial = detecção geral?
- 2. Objetivos de design e principais contribuições do YOLOv5Face
- 3. Arquitetura YOLOv5Face
- 4. Treinamento de modelo

Nos últimos anos, a CNN tem sido amplamente utilizada na detecção de rostos. No entanto, muitos detectores faciais requerem o uso de detectores faciais especialmente projetados para detectar rostos, e o autor do YOLOv5 trata a detecção facial como uma tarefa geral de detecção de alvos.
YOLOv5Face adiciona um cabeçote de regressão de ponto de referência de 5 pontos (regressão de ponto-chave) baseado em YOLOv5 e usa perda de asa para restringir o cabeçote de regressão de marco. YOLOv5Face projeta detectores com diferentes tamanhos de modelos, desde modelos grandes até modelos ultrapequenos, para obter detecção em tempo real em dispositivos incorporados ou móveis.
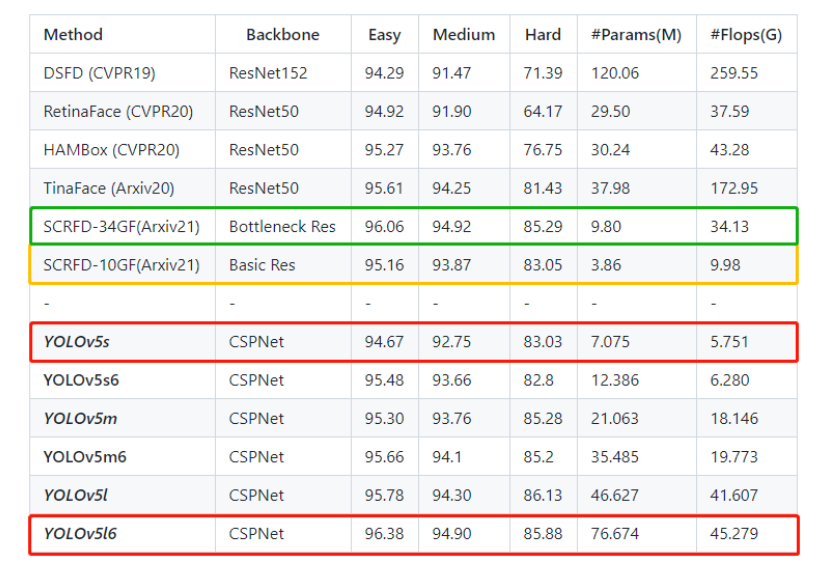
Resultados experimentais no conjunto de dados WiderFace mostram que o YOLOv5Face pode alcançar desempenho de última geração em quase todos os subconjuntos Fácil, Médio e Difícil, superando detectores faciais especificamente projetados.
Endereço do Github: https://www.github.com/deepcam-cn/yolov5-face
1. Por que detecção facial = detecção geral?
1.1 Detecção de rosto YOLOv5Face
No método YOLOv5Face, a detecção de rosto é considerada uma tarefa geral de detecção de alvo. Semelhante ao TinaFace, o rosto humano é usado como alvo. Conforme discutido no TinaFace:
- Do ponto de vista dos dados, características do rosto humano como postura, escala, oclusão, iluminação e desfoque também aparecerão em outras tarefas gerais de detecção;
- Ver o gênero a partir dos atributos únicos do rosto, como expressão e maquiagem, também pode corresponder a mudanças de forma e de cor em problemas gerais de detecção.
1.2 Marco YOLOv5Face
Landmark é uma existência relativamente especial, mas não é a única. Eles são apenas pontos-chave de um objeto. Por exemplo, na detecção de placas de veículos, o Landmark também é usado. Adicionar regressão Landmark ao Head do modelo de previsão de destino é relativamente simples com um clique. Portanto, do ponto de vista dos desafios enfrentados pela detecção de rostos, rostos pequenos, multiescala, cenas densas, etc., todos existem na detecção de alvos em geral. Portanto, a detecção de rosto pode ser considerada uma subtarefa geral de detecção de alvo.
2. Objetivos de design e principais contribuições do YOLOv5Face
2.1 Objetivos de projeto
YOLOv5Face redesenhou e modificou o YOLOv5 para detecção de rosto, levando em consideração as diferentes complexidades e aplicações de rostos grandes, rostos pequenos, supervisão de pontos de referência, etc. O objetivo do YOLOv5Face é fornecer uma combinação de modelos para diferentes aplicações, desde as muito complexas até as muito simples, para obter a melhor relação entre desempenho e velocidade em dispositivos embarcados ou móveis.
2.2 Principais Contribuições
- O YOLOV5 foi redesenhado como um detector facial e denominado YOLOv5Face. Principais modificações foram feitas na rede para melhorar o desempenho em termos de precisão média média (mAP) e velocidade;
- Uma série de modelos de diferentes tamanhos são projetados, desde modelos grandes, modelos de médio porte e modelos ultrapequenos, para atender às necessidades de diferentes aplicações. Além do Backbone usado no YOLOv5, também é implementado um Backbone baseado em ShuffleNetV2, que oferece desempenho de última geração e velocidade rápida para dispositivos móveis;
- O modelo YOLOv5Face é avaliado no conjunto de dados WiderFace. Em imagens com resolução VGA, quase todos os modelos alcançam desempenho e velocidade SOTA. Isso também comprova a conclusão anterior: não há necessidade de redesenhar um detector facial, porque o YOLO5 pode completá-lo.
3. Arquitetura YOLOv5Face
3.1 Arquitetura do modelo
3.1.1 Diagrama do modelo
YOLOv5Face usa YOLOv5 como linha de base para melhorar e redesenhar para se adaptar à detecção facial. O objetivo principal aqui é detectar modificações em faces pequenas e faces grandes.
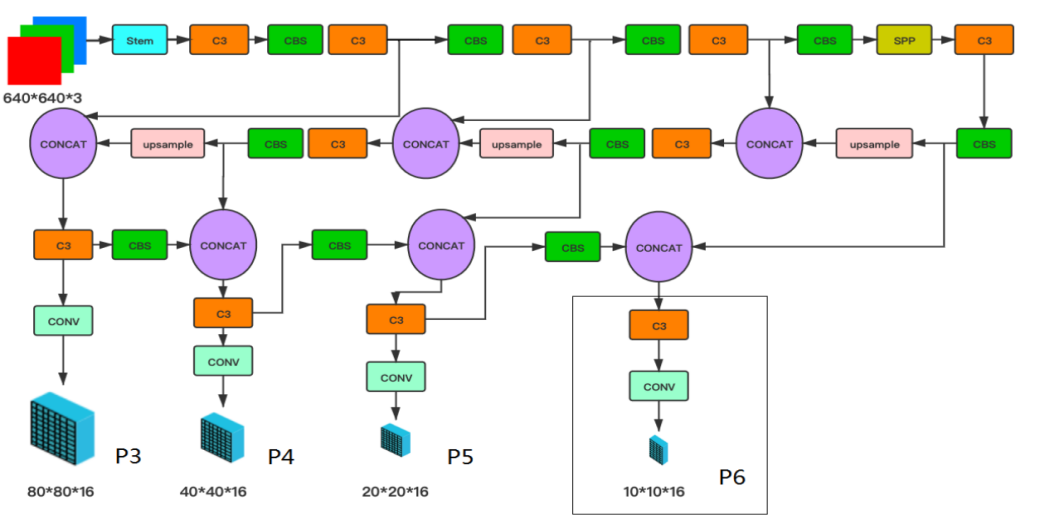
A arquitetura de rede do detector facial YOLO5 é mostrada na Figura 1. Consiste em Backbone, Neck e Head e descreve a arquitetura geral da rede. No YOLOv5, o backbone CSPNet é usado. SPP e PAN são usados no Neck para fundir esses recursos. Regressão e classificação também são usadas em Head.
3.1.2 Módulo CBS
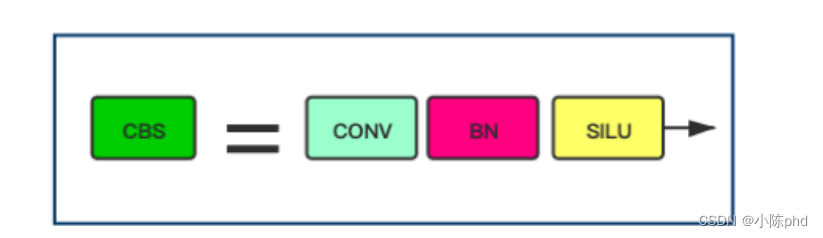
Na figura é definido um Bloco CBS, que consiste nas funções de ativação Conv, BN e SiLU. O Bloco CBS também é usado em muitos outros blocos.
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
# 卷积层
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
# BN层
self.bn = nn.BatchNorm2d(c2)
# SiLU激活层
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
3.1.3 Saída principal

Exibe os rótulos de saída do Head, que incluem caixas delimitadoras (bbox), confiança (conf), classificação (cls) e marcos de 5 pontos. Esses pontos de referência são melhorias no YOLOv5, tornando-o um detector facial com saída de pontos de referência. Sem Marcos, o comprimento do último vetor deverá ser 6 em vez de 16. Caixa (4) + Confiança (1) + Pontos-chave (5*2) + cls (categoria)
O tamanho de saída é 80×80×16 em P3, 40×40×16 em P4, 20×20×16 em P5 e opcionalmente 10×10×16 em P6 para cada âncora. O tamanho real deve ser multiplicado pelo número de âncoras.
3.1.4 estrutura do caule
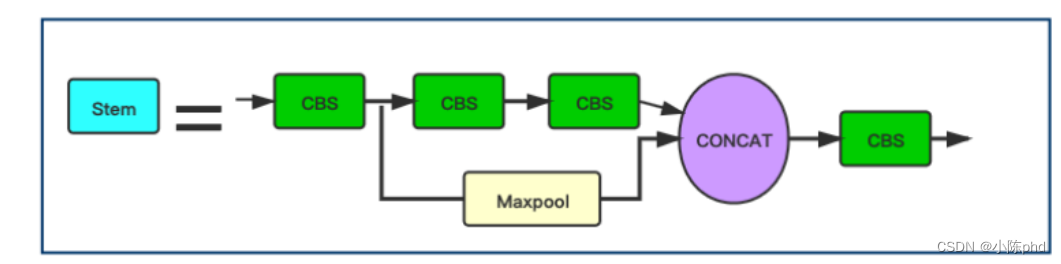
A imagem mostra a estrutura da haste, que é usada para substituir a camada Focus original no YOLOv5. A introdução de blocos Stem para detecção de rosto no YOLOv5 é uma das inovações do YOLOv5Face.
class StemBlock(nn.Module):
def __init__(self, c1, c2, k=3, s=2, p=None, g=1, act=True):
super(StemBlock, self).__init__()
# 3×3卷积
self.stem_1 = Conv(c1, c2, k, s, p, g, act)
# 1×1卷积
self.stem_2a = Conv(c2, c2 // 2, 1, 1, 0)
# 3×3卷积
self.stem_2b = Conv(c2 // 2, c2, 3, 2, 1)
# 最大池化层
self.stem_2p = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
# 1×1卷积
self.stem_3 = Conv(c2 * 2, c2, 1, 1, 0)
def forward(self, x):
stem_1_out = self.stem_1(x)
stem_2a_out = self.stem_2a(stem_1_out)
stem_2b_out = self.stem_2b(stem_2a_out)
stem_2p_out = self.stem_2p(stem_1_out)
out = self.stem_3(torch.cat((stem_2b_out, stem_2p_out), 1))
return out
Substituir o módulo Focus original na rede pelo módulo Stem melhora a capacidade de generalização da rede e reduz a complexidade computacional sem reduzir o desempenho . Embora o CBS seja usado nas ilustrações do módulo Stem, olhando o código você pode ver que o 2º e o 4º CBS são convoluções 1×1, o 1º e o 3º CBS são 3×3, passada=2 de convolução. Com o arquivo yaml, você pode ver que o tamanho da imagem mudou de 640×640 para 160×160 após o caule.
3.1.5 Estrutura do CSP
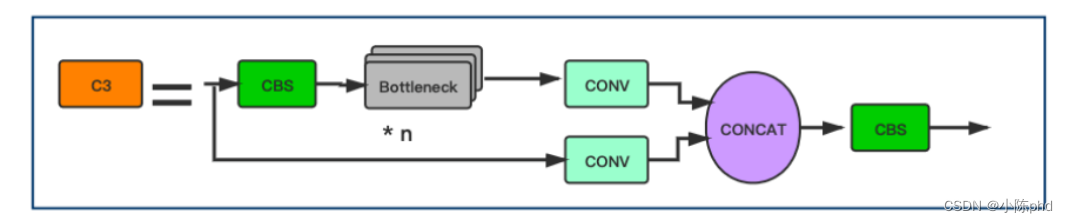
O design do CSP Block é inspirado no DenseNet. No entanto, em vez de adicionar a entrada e a saída completas após algumas camadas CNN, a entrada é dividida em 2 partes. Metade dele passa por um Bloco CBS, ou seja, alguns Blocos Gargalo, e a outra metade é calculada através da camada Conv:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
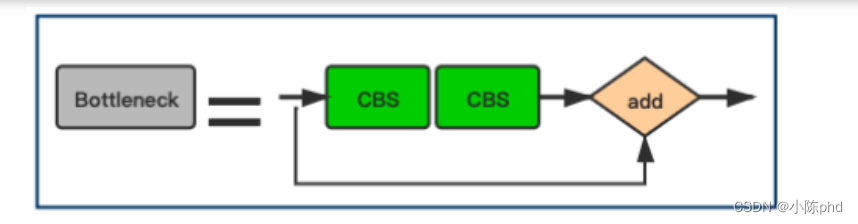
A camada de gargalo é expressa como:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
#第1个CBS模块
self.cv1 = Conv(c1, c_, 1, 1)
#第2个CBS模块
self.cv2 = Conv(c_, c2, 3, 1, g=g)
#元素add操作
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
3.1.9 Estrutura do SPP
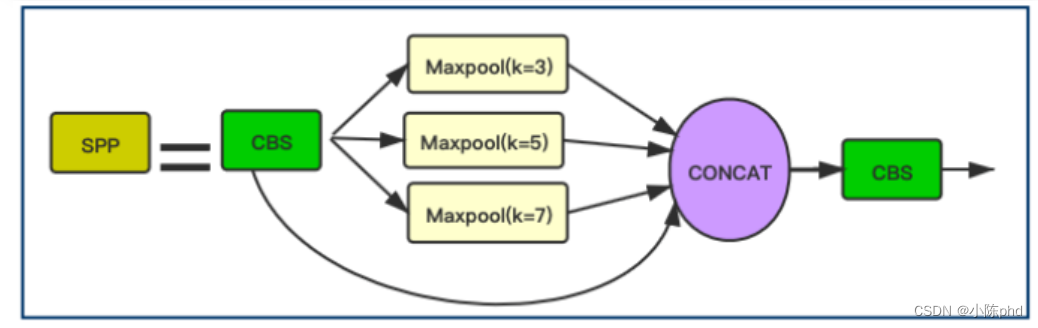
Neste bloco, YOLOv5Face modificou os tamanhos de kernel de 13 × 13, 9 × 9 e 5 × 5 em YOLOv5 para 7 × 7, 5 × 5 e 3 × 3. Esta melhoria é mais adequada para detecção de rosto e melhora o desempenho da detecção de rosto. Precisão da detecção de rosto.
class SPP(nn.Module):
# 这里主要是讲YOLOv5中的kernel=(5,7,13)修改为(3, 5, 7)
def __init__(self, c1, c2, k=(3, 5, 7)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
# 对应第1个CBS Block
self.conv1 = Conv(c1, c_, 1, 1)
# 对应第2个 cat后的 CBS Block
self.conv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
# ModuleList=[3×3 MaxPool2d,5×5 MaxPool2d,7×7 MaxPool2d]
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.conv1(x)
return self.conv2(torch.cat([x] + [m(x) for m in self.m], 1))
Ao mesmo tempo, YOLOv5Face adiciona um bloco de saída P6 com passada = 64. P6 pode melhorar o desempenho de detecção de rostos grandes. (Os modelos anteriores de detecção de rosto focavam principalmente em melhorar o desempenho de detecção de rostos pequenos. Aqui, o autor se concentra no efeito de detecção de rostos grandes e melhora o desempenho de detecção de rostos grandes para melhorar o desempenho geral de detecção do modelo). O tamanho do mapa de recursos do P6 é 10x10.
Observe que apenas imagens de entrada com resolução VGA são consideradas aqui. Para ser mais preciso, as bordas mais longas da imagem de entrada são dimensionadas para 640 e as bordas mais curtas são dimensionadas de acordo. Bordas mais curtas também são ajustadas para serem múltiplos da passada máxima do bloco SPP. Por exemplo, quando não estiver usando P6, o lado mais curto precisa ser um múltiplo de 32; ao usar P6, o lado mais curto precisa ser um múltiplo de 64.
3.2 Melhorias no lado dos insumos
Alguns métodos de aumento de dados para detecção de objetos não são adequados para uso na detecção de rostos, incluindo inversão de cima para baixo e aumento de dados Mosaic.
- A remoção da inversão pode melhorar o desempenho do modelo .
- O aumento de dados do Mosaic para faces pequenas reduzirá o desempenho do modelo , mas o Mosaic para faces de média e grande escala pode melhorar o desempenho .
- O corte aleatório ajuda a melhorar o desempenho .
Nota: Existem diferenças de escala entre o conjunto de dados COCO e o conjunto de dados WiderFace. O conjunto de dados WiderFace possui relativamente mais dados em pequena escala.
3.3 Retorno ao marco
3.3.1 Marco de Saída
O marco é uma característica importante do rosto humano. Eles podem ser usados para tarefas como comparação facial, reconhecimento facial, análise de expressão facial e análise de idade. Marco Tradicional consiste em 68 pontos. Quando foram simplificados para 5 pontos, esses Landmarks de 5 pontos foram amplamente utilizados no reconhecimento facial. A qualidade da identificação facial afeta diretamente a qualidade do alinhamento e reconhecimento facial.
- Os detectores de objetos gerais não incluem Landmark. Ele pode ser adicionado diretamente como um Head de retorno. Portanto, o autor o adicionou ao YOLO5Face. A saída do Landmark será usada para alinhar as imagens faciais e depois enviá-las para a rede de reconhecimento facial.
3.3.2 Função de perda de marco Asa
As funções de perda geral usadas para regressão Landmark são L2, L1 ou smooth-L1. MTCNN usa a função de perda L2. No entanto, os autores descobriram que estas funções de perda não são sensíveis a pequenos erros. Para superar este problema, a perda de asa é proposta:
wing ( x ) = { w ln ( 1 + ∣ x ∣ / ϵ ) if ∣ x ∣ < w ∣ x ∣ − C caso contrário \operatorname{wing}(x)= \begin{cases}w \ln (1+|x| / \epsilon) & \text { if }|x|<w \\ |x|-C & \text { caso contrário }\end{cases}asa ( x )={
cEm ( 1+∣ x ∣/ ϵ )∣ x ∣-C se ∣ x ∣<ccaso contrário
: u:c: número positivowww limita o intervalo da parte não linear a[ − w , w ] [-w, w][ − C ,w ] dentro do intervalo;
ϵ \epsilonϵ : Restringe a curvatura da região não linear, eC = w − w ln ( 1 + x ϵ ) C=ww \ln \left(1+\frac{x}{\epsilon}\right)C=c-cEm( 1+ϵx) é uma constante que pode ser usada com suavização para conectar as partes lineares e não lineares da peça. ϵ \épsilonO valor de ϵ é um valor muito pequeno porque tornará o treinamento da rede instável e causará problemas de explosão de gradiente devido a pequenos erros.
Na verdade, a parte não linear da função de perda de Wing simplesmente levaln ( x ) \ln (x)ln ( x )在[ ϵ/w , 1 + ϵ/w ] [\epsilon/w, 1+\epsilon/w][ ϵ / C ,1+ϵ / w ] e ao longo do eixo X eYYO eixo Y dimensiona para W. Além disso, ao longo deYYUma translação é aplicada ao eixo Y de modo que asa(0) = 0 (0)=0( 0 )=0 e impõe continuidade à função de perda.
Vetor de ponto de referências = { si } s=\left\{s_i\right\}é={
seu}与其verdade básicas ′ = { si } s^{\prime}=\left\{s_i\right\}é'={
seu}的损失函数为:
perda L ( s ) = ∑ i asa ( si − si ′ ) \operatorname{loss}_L(s)=\sum_i \operatorname{wing}\left(s_i-s_i^{\prime }\certo)perdaeu( s )=eu∑asa( seu-éeu')
ondei = 1, 2, …, 10 i=1,2, \ldots, 10eu=1 ,2 ,…,10 .
Deixe a função geral de perda de detecção de alvo em YOLOv5 serperda O los s_Oeu sou _Ó, então a nova função de perda total é:
perda ( s ) = perda O + λ L ⋅ perda L \operatorname{loss}(s)=\operatorname{loss}_O+\lambda_L \cdot \operatorname{loss}_Lperda ( s )=perdaÓ+ eueu⋅perdaeu
onde λ L \lambda_Leueué o fator de peso da função de perda de regressão Landmark.
Aquisição de ponto de referência: onde i = 1, 2, …, 10 i=1,2, \ldots, 10eu=1 ,2 ,…,10 .
Deixe a função geral de perda de detecção de alvo em YOLOv5 serperda O los s_Oeu sou _Ó, então a nova função de perda total é:
perda ( s ) = perda O + λ L ⋅ perda L \operatorname{loss}(s)=\operatorname{loss}_O+\lambda_L \cdot \operatorname{loss}_Lperda ( s )=perdaÓ+ eueu⋅perdaeu
onde λ L \lambda_Leueué o fator de peso da função de perda de regressão Landmark.
Aquisição de marco:
#landmarks
lks = t[:,6:14]
lks_mask = torch.where(lks < 0, torch.full_like(lks, 0.), torch.full_like(lks, 1.0))
#应该是关键点的坐标除以anch的宽高才对,便于模型学习。使用gwh会导致不同关键点的编码不同,没有统一的参考标准
lks[:, [0, 1]] = (lks[:, [0, 1]] - gij)
lks[:, [2, 3]] = (lks[:, [2, 3]] - gij)
lks[:, [4, 5]] = (lks[:, [4, 5]] - gij)
lks[:, [6, 7]] = (lks[:, [6, 7]] - gij)
A perda de asa é calculada da seguinte forma:
class WingLoss(nn.Module):
def __init__(self, w=10, e=2):
super(WingLoss, self).__init__()
# https://arxiv.org/pdf/1711.06753v4.pdf Figure 5
self.w = w
self.e = e
self.C = self.w - self.w * np.log(1 + self.w / self.e)
def forward(self, x, t, sigma=1): #这里的x,t分别对应之后的pret,truel
weight = torch.ones_like(t) #返回一个大小为1的张量,大小与t相同
weight[torch.where(t==-1)] = 0
diff = weight * (x - t)
abs_diff = diff.abs()
flag = (abs_diff.data < self.w).float()
y = flag * self.w * torch.log(1 + abs_diff / self.e) + (1 - flag) * (abs_diff - self.C) #全是0,1
return y.sum()
class LandmarksLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=1.0):
super(LandmarksLoss, self).__init__()
self.loss_fcn = WingLoss()#nn.SmoothL1Loss(reduction='sum')
self.alpha = alpha
def forward(self, pred, truel, mask): #预测的,真实的 600(原来为62*10)(推测是去掉了那些没有标注的值)
loss = self.loss_fcn(pred*mask, truel*mask) #一个值(tensor)
return loss / (torch.sum(mask) + 10e-14)
Analise e compare as funções de perda L1, L2 e Smooth L1
perda ( s , s ′ ) = ∑ i = 1 2 L f ( si − si ′ ) \operatorname{loss}\left(\mathbf{s}, \mathbf{ s }^{\prime}\right)=\sum_{i=1}^{2 L} f\left(s_i-s_i^{\prime}\right)perda( é ,é' )=eu = 1∑2 litrosf( seu-éeu')
ondesss é a verdade dos pontos-chave da face, a funçãof ( x ) f(x)f ( x ) é equivalente a:
perda L1
L 1 ( x ) = ∣ x ∣ L 1(x)=|x|eu 1 ( x )=∣ x ∣
perda L2
L 2 ( x ) = 1 2 x 2 L 2(x)=\frac{1}{2} x^2eu 2 ( x )=21x2
Suave L 1 ( x ): suave L 1 ( x ) = { 1 2 x 2 se ∣ x ∣ < 1 ∣ x ∣ − 1 2 caso contrário \operatorname{Smooth}_{L 1}(x): \operatorname {suave}_{L 1}(x)= \begin{casos}\frac{1}{2} x^2 & \text { if }|x|<1 \\ |x|-\frac{1} {2} & \text { caso contrário }\end{casos}Suaveeu 1( x ):suaveeu 1( x )={ 21x2∣ x ∣-21 se ∣ x ∣<1caso contrário
Função de perda para xxAs derivadas de x são:
d L 2 ( x ) dx = x \frac{d L_2(x)}{dx}=xd xd eu2( x )=x
d L 1 ( x ) dx = { 1 se x ≥ 0 − 1 caso contrário \frac{d L_1(x)}{dx}= \begin{cases}1 & \text { if } x \geq 0 \\ -1 & \text { caso contrário }\end{casos}d xd eu1( x )={ 1− 1 se x≥0caso contrário
d suave L 1 ( x ) dx = { x se ∣ x ∣ < 1 ± 1 caso contrário \frac{d \operatorname{smooth}_{L 1}(x)}{dx}= \begin{cases}x & \text { if }|x|<1 \\ \pm 1 & \text { caso contrário }\end{casos}d xdsuaveeu 1( x )={ x± 1 se ∣ x ∣<1caso contrário
-
Função de perda L2, quando xxPerda L2 versusxx quando x aumentaA derivada de x também aumenta, o que leva ao estágio inicial do treinamento, quando a diferença entre o valor previsto e a verdade fundamental é muito grande, o gradiente da função de perda em relação ao valor previsto é muito grande, resultando em treinamento instável.
-
A derivada da perda L1 é uma constante. No estágio posterior do treinamento, quando a diferença entre o valor previsto e a verdade fundamental é muito pequena, o valor absoluto da derivada da perda em relação ao valor previsto ainda é 1. Em desta vez, se a taxa de aprendizagem permanecer inalterada, a função de perda flutuará perto do valor estável, tornando difícil continuar a convergir para obter maior precisão.
-
função de perda L1 suave, quando x é pequeno, para xxO gradiente de x também ficará menor, e emxxQuando x é muito grande, paraxxO valor absoluto do gradiente de x atinge o limite superior de 1, que não será tão grande a ponto de destruir os parâmetros da rede. suave L1 evita perfeitamente os defeitos das perdas L1 e L2.
Além disso, de acordo com fast rcnn, "...perda L1 que é menos sensível a outliers do que a perda L2 usada em R-CNN e SPPnet." Ou seja, L1 suave torna a perda mais robusta a outliers, ou seja, em comparação com L2 A função de perda é insensível a outliers e outliers, as mudanças de gradiente são relativamente menores e não é fácil fugir durante o treinamento.
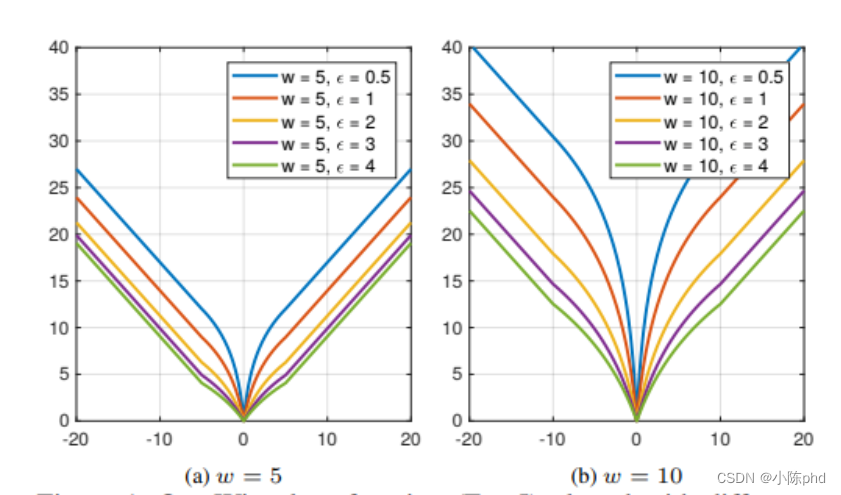
A figura acima mostra gráficos dessas funções de perda. Deve-se notar que a perda Smoolth L1 é um caso especial de perda de Huber. A função de perda L2 é amplamente utilizada na detecção de pontos-chave faciais. No entanto, a perda L2 é sensível a outliers.
3.3.3 Perda de Asa
Todas as funções de perda funcionam bem na presença de grandes erros. Isso mostra que o treinamento de redes neurais deve focar mais em amostras com erros pequenos ou médios. Para atingir este objetivo, é proposta uma nova função de perda, nomeadamente Wing Loss baseada em CNN para localização de marcos faciais.

Quando NME está em 0,04, a proporção dos dados de teste é próxima de 1, então na seção de 0,04 a 0,05, que é a chamada seção de erros grandes, não há mais dados distribuídos, indicando que cada função de perda tem um desempenho muito bom em a seção de erros grandes. ótimo.
O desempenho inconsistente do modelo reside nos segmentos de erros pequenos e erros médios.Por exemplo, uma linha vertical é desenhada onde o NME é 0,02, o que é muito diferente. Portanto, o autor propõe que mais atenção seja dada às amostras com erros pequenos ou médios durante o processo de treinamento.
Você pode usar ln x \ln xEmx para aumentar o impacto de pequenos erros, seu gradiente é1 x \frac{1}{x}x1, para valores próximos a 0, quanto maior o valor, o tamanho ideal do passo é x 2 x^2x2 , de modo que o gradiente seja “dominado” por pequenos erros e o tamanho do passo seja “dominado” por grandes erros. Isso restaura o equilíbrio entre erros de tamanhos diferentes. Contudo, para evitar grandes etapas de atualização em direções potencialmente erradas, é importante não compensar excessivamente os efeitos de erros de posicionamento menores. Isto pode ser conseguido escolhendo uma função logarítmica com deslocamento positivo.
Mas este tipo de função de perda é adequada para lidar com erros de posicionamento relativamente pequenos. Na detecção de pontos-chave de face selvagem, pode-se lidar com poses extremas onde os erros de posicionamento inicial podem ser muito grandes, caso em que a função de perda deve facilitar a recuperação rápida desses grandes erros. Isto sugere que a função de perda deveria se comportar mais comoL 1 L 1L 1 ouL 2 L 2L2 . _ DesdeL 2 L 2L2 é sensível a outliers, então L1 é escolhido.
Portanto,Wing Lossdeve se comportar como uma função logarítmica com deslocamento para erros pequenos, e comoL 1 L 1L1。 _
3.4 Pós-processamento NMS
3.4.1 yolov5
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()):
"""Performs Non-Maximum Suppression (NMS) on inference results
Returns:
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
"""
nc = prediction.shape[2] -5 # number of classes
3.4.2 cara de yolov5s
def non_max_suppression_face(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()):
"""Performs Non-Maximum Suppression (NMS) on inference results
Returns:
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
"""
# 不同之处
nc = prediction.shape[2] - 15 # number of classes
4. Treinamento de modelo
4.1 Baixe o código-fonte
git clone https://github.com/deepcam-cn/yolov5-face
4.2 Baixe um conjunto de dados mais amplo
Após o download, descompacte o local e coloque-o na pasta wideface na pasta de dados do projeto yolov5-face-master.
https://drive.google.com/file/d/1tU_IjyOwGQfGNUvZGwWWM4SwxKp2PUQ8/view?usp=sharing
4.3 Execute train2yolo.py e val2yolo.py
Crie uma nova pasta widefaceyolo na pasta de dados e defina os subdiretórios para treinar, testar e val
python train2yolo.py ./widerface/train ../data/widerfaceyolo/train
python val2yolo.py ./widerface ../data/widerfaceyolo/val
Converta o conjunto de dados no formato usado para treinamento yolo. Após a conclusão, a pasta aparecerá da seguinte forma:

4.4 trem
4.4.1 Alterar arquivo de configuração de treinamento
wideface.yaml muda o diretório para o diretório do conjunto de dados
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ./data/widerfaceyolo/train # 16551 images
val: ./data/widerfaceyolo/val # 16551 images
#val: /ssd_1t/derron/yolov5-face/data/widerface/train/ # 4952 images
# number of classes
nc: 1
# class names
names: [ 'face']
4.4.2 Visualização do treinamento
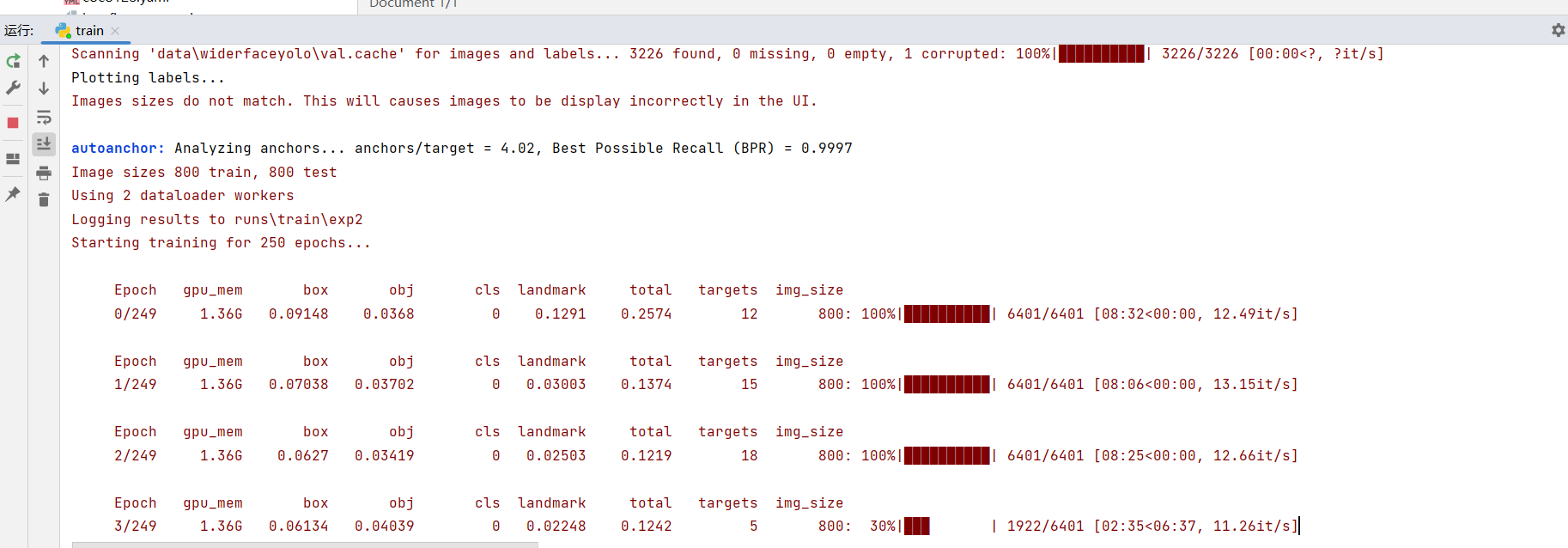
tensorboard --logdir runs/train
4.4.3 Relatórios de erros relacionados
- Não é possível desenhar a imagem
Traceback (most recent call last):
File "D:\yolov5-face\train.py", line 523, in <module>
train(hyp, opt, device, tb_writer, wandb)
File "D:\yolov5-face\train.py", line 410, in train
plot_results(save_dir=save_dir) # save as results.png
File "D:\yolov5-face\utils\plots.py", line 393, in plot_results
assert len(files), 'No results.txt files found in %s, nothing to plot.' % os.path.abspath(save_dir)
Solução Comente esta linha de código:
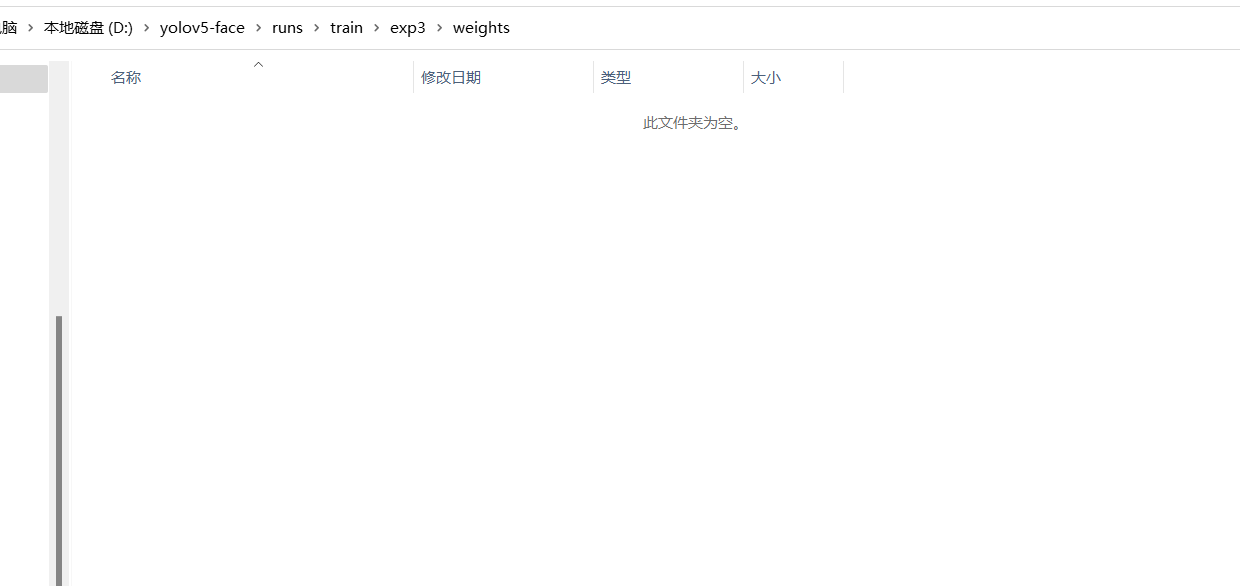
- pesos não são salvos
Depois de muito tempo de treinamento, descobri que os pesos salvos estavam vazios. Observe que a época relevante é maior que 20 antes de salvar o código de peso.
4,5 detectar
Alterar código
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 更改权重,指定权重类型
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s-face.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--save-img', action='store_true', help='save results')
parser.add_argument('--view-img', default=True,action='store_true', help='show results')
opt = parser.parse_args()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = load_model(opt.weights, device)
detect(model, opt.source, device, opt.project, opt.name, opt.exist_ok, opt.save_img, opt.view_img)
4.6 Exportação ONNX e configuração do ambiente TensorRT
"""Exports a YOLOv5 *.pt model to ONNX and TorchScript formats
Usage:
$ export PYTHONPATH="$PWD" && python models/export.py --weights ./weights/yolov5s.pt --img 640 --batch 1
"""
import argparse
import sys
import time
sys.path.append('./') # to run '$ python *.py' files in subdirectories
import torch
import torch.nn as nn
import models
from models.experimental import attempt_load
from utils.activations import Hardswish, SiLU
from utils.general import set_logging, check_img_size
import onnx
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='./yolov5s-face.pt', help='weights path') # from yolov5/models/
parser.add_argument('--img_size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
parser.add_argument('--batch_size', type=int, default=1, help='batch size')
parser.add_argument('--dynamic', action='store_true', default=False, help='enable dynamic axis in onnx model')
parser.add_argument('--onnx2pb', action='store_true', default=False, help='export onnx to pb')
parser.add_argument('--onnx_infer', action='store_true', default=True, help='onnx infer test')
#=======================TensorRT=================================
parser.add_argument('--onnx2trt', action='store_true', default=True, help='export onnx to tensorrt')
parser.add_argument('--fp16_trt', action='store_true', default=True, help='fp16 infer')
#================================================================
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
print(opt)
set_logging()
t = time.time()
# Load PyTorch model
model = attempt_load(opt.weights, map_location=torch.device('cpu')) # load FP32 model
delattr(model.model[-1], 'anchor_grid')
model.model[-1].anchor_grid=[torch.zeros(1)] * 3 # nl=3 number of detection layers
model.model[-1].export_cat = True
model.eval()
labels = model.names
print(labels)
# exit()
# Checks
gs = int(max(model.stride)) # grid size (max stride)
opt.img_size = [check_img_size(x, gs) for x in opt.img_size] # verify img_size are gs-multiples
# Input 给定一个输入
img = torch.zeros(opt.batch_size, 3, *opt.img_size) # image size(1,3,320,192) iDetection
# Update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
# elif isinstance(m, models.yolo.Detect):
# m.forward = m.forward_export # assign forward (optional)
if isinstance(m, models.common.ShuffleV2Block):#shufflenet block nn.SiLU
for i in range(len(m.branch1)):
if isinstance(m.branch1[i], nn.SiLU):
m.branch1[i] = SiLU()
for i in range(len(m.branch2)):
if isinstance(m.branch2[i], nn.SiLU):
m.branch2[i] = SiLU()
y = model(img) # dry run
# ONNX export
print('\nStarting ONNX export with onnx %s...' % onnx.__version__)
f = opt.weights.replace('.pt', '.onnx') # filename
model.fuse() # only for ONNX
input_names=['input']
output_names=['output']
torch.onnx.export(model, img, f, verbose=False, opset_version=12,
input_names=input_names,
output_names=output_names,
dynamic_axes = {
'input': {
0: 'batch'},
'output': {
0: 'batch'}
} if opt.dynamic else None)
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
print('ONNX export success, saved as %s' % f)
# Finish
print('\nExport complete (%.2fs). Visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))
# exit()
# onnx infer
if opt.onnx_infer:
import onnxruntime
import numpy as np
providers = ['CPUExecutionProvider']
session = onnxruntime.InferenceSession(f, providers=providers)
im = img.cpu().numpy().astype(np.float32) # torch to numpy
y_onnx = session.run([session.get_outputs()[0].name], {
session.get_inputs()[0].name: im})[0]
print("pred's shape is ",y_onnx.shape)
print("max(|torch_pred - onnx_pred|) =",abs(y.cpu().numpy()-y_onnx).max())

4.7 Raciocínio OnnXruntime
código mostrado abaixo:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/5/30 23:24
# @Author : 陈伟峰
# @Site :
# @File : onnxruntime_infer.py
# @Software: PyCharm
import time
import numpy as np
import argparse
import onnxruntime
import os, torch
import cv2, copy
from detect_face import scale_coords_landmarks, show_results
from utils.general import non_max_suppression_face, scale_coords
def allFilePath(rootPath, allFIleList): # 遍历文件
fileList = os.listdir(rootPath)
for temp in fileList:
if os.path.isfile(os.path.join(rootPath, temp)):
allFIleList.append(os.path.join(rootPath, temp))
else:
allFilePath(os.path.join(rootPath, temp), allFIleList)
def my_letter_box(img, size=(640, 640)): #
'''
将输入的图像img按照指定的大小size进行缩放和填充,
使其适应指定的大小。
具体来说,
它首先获取输入图像的高度h、宽度w和通道数c,然后计算出缩放比例r,并根据缩放比例计算出新的高度new_h和宽度new_w。
接着,它计算出在新图像中上、下、左、右需要填充的像素数,并使用cv2.resize函数将输入图像缩放到新的大小。最后,
它使用cv2.copyMakeBorder函数在新图像的上、下、左、右四个方向进行填充,
并返回填充后的图像img、缩放比例r、左侧填充像素数left和上方填充像素数top
Args:
img:
size:
Returns:
'''
h, w, c = img.shape
# cv2.imshow("res",img)
# cv2.waitKey(0)
r = min(size[0] / h, size[1] / w)
new_h, new_w = int(h * r), int(w * r)
top = int((size[0] - new_h) / 2)
left = int((size[1] - new_w) / 2)
bottom = size[0] - new_h - top
right = size[1] - new_w - left
img_resize = cv2.resize(img, (new_w, new_h))
# print(top,bottom,left,right)
# exit()
img = cv2.copyMakeBorder(img_resize, top, bottom, left, right, borderType=cv2.BORDER_CONSTANT,
value=(114, 114, 114))
# cv2.imshow("res",img)
# cv2.waitKey(0)
return img, r, left, top
def xywh2xyxy(boxes): # xywh坐标变为 左上 ,右下坐标 x1,y1 x2,y2
xywh = copy.deepcopy(boxes)
xywh[:, 0] = boxes[:, 0] - boxes[:, 2] / 2
xywh[:, 1] = boxes[:, 1] - boxes[:, 3] / 2
xywh[:, 2] = boxes[:, 0] + boxes[:, 2] / 2
xywh[:, 3] = boxes[:, 1] + boxes[:, 3] / 2
return xywh
def detect_pre_precessing(img, img_size): # 检测前处理
img, r, left, top = my_letter_box(img, img_size)
# cv2.imwrite("1.jpg",img)
img = img[:, :, ::-1].transpose(2, 0, 1).copy().astype(np.float32)
img = img / 255
img = img.reshape(1, *img.shape)
return img, r, left, top
def restore_box(boxes, r, left, top): # 返回原图上面的坐标
boxes[:, [0, 2, 5, 7, 9, 11]] -= left
boxes[:, [1, 3, 6, 8, 10, 12]] -= top
boxes[:, [0, 2, 5, 7, 9, 11]] /= r
boxes[:, [1, 3, 6, 8, 10, 12]] /= r
return boxes
def post_precessing(dets, r, left, top, conf_thresh=0.3, iou_thresh=0.5): # 检测后处理
"""
这段代码是一个用于检测后处理的函数。它的输入包括检测结果(dets)、
图像的缩放比例(r)、左上角坐标(left和top)、置
信度阈值(conf_thresh)和IoU阈值(iou_thresh)。
函数的主要功能是对检测结果进行筛选和处理,包括去除置信度低于阈值的检测框、将检测框的坐标从中心点和宽高格式转换为左上角和右下角格式、
计算每个检测框的得分并选取最高得分的类别作为输出、对输出进行非极大值抑制(NMS)处理、最后将输出的检测框坐标还原到原始图像中
Args:
dets:
r:
left:
top:
conf_thresh:
iou_thresh:
Returns:
"""
# 置信度
choice = dets[:, :, 4] > conf_thresh
dets = dets[choice]
dets[:, 13:15] *= dets[:, 4:5]
# 前四个值为框
box = dets[:, :4]
boxes = xywh2xyxy(box)
score = np.max(dets[:, 13:15], axis=-1, keepdims=True)
index = np.argmax(dets[:, 13:15], axis=-1).reshape(-1, 1)
output = np.concatenate((boxes, score, dets[:, 5:13], index), axis=1)
reserve_ = nms(output, iou_thresh)
output = output[reserve_]
output = restore_box(output, r, left, top)
return output
def nms(boxes, iou_thresh): # nms
index = np.argsort(boxes[:, 4])[::-1]
keep = []
while index.size > 0:
i = index[0]
keep.append(i)
x1 = np.maximum(boxes[i, 0], boxes[index[1:], 0])
y1 = np.maximum(boxes[i, 1], boxes[index[1:], 1])
x2 = np.minimum(boxes[i, 2], boxes[index[1:], 2])
y2 = np.minimum(boxes[i, 3], boxes[index[1:], 3])
w = np.maximum(0, x2 - x1)
h = np.maximum(0, y2 - y1)
inter_area = w * h
union_area = (boxes[i, 2] - boxes[i, 0]) * (boxes[i, 3] - boxes[i, 1]) + (
boxes[index[1:], 2] - boxes[index[1:], 0]) * (boxes[index[1:], 3] - boxes[index[1:], 1])
iou = inter_area / (union_area - inter_area)
idx = np.where(iou <= iou_thresh)[0]
index = index[idx + 1]
return keep
if __name__ == "__main__":
begin = time.time()
parser = argparse.ArgumentParser()
parser.add_argument('--detect_model', type=str, default=r'yolov5s-face.onnx', help='model.pt path(s)') # 检测模型
# parser.add_argument('--rec_model', type=str, default='weights/plate_rec.onnx', help='model.pt path(s)')#识别模型
parser.add_argument('--image_path', type=str, default='imgs', help='source')
parser.add_argument('--img_size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--output', type=str, default='result1', help='source')
parser.add_argument('--device', type=str, default='cpu', help='device ')
# parser.add_argument('--device', type=str, default='cpu', help='device ')
# parser.add_argument('--device', type=str, default='cpu', help='device ')
opt = parser.parse_args()
device = opt.device
file_list = []
allFilePath(opt.image_path, file_list)
providers = ['CPUExecutionProvider']
clors = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (0, 255, 255)]
img_size = (opt.img_size, opt.img_size)
sess_options = onnxruntime.SessionOptions()
# sess_options.optimized_model_filepath = os.path.join(output_dir, "optimized_model_{}.onnx".format(device_name))
session_detect = onnxruntime.InferenceSession(opt.detect_model, providers=providers)
# session_rec = onnxruntime.InferenceSession(opt.rec_model, providers=providers )
if not os.path.exists(opt.output):
os.mkdir(opt.output)
save_path = opt.output
count = 0
for pic_ in file_list:
count += 1
print(count, pic_, end=" ")
img = cv2.imread(pic_)
img0 = copy.deepcopy(img)
img, r, left, top = my_letter_box(img0, size=img_size)
img = img.transpose(2, 0, 1).copy()
img = torch.from_numpy(img).to(device)
img = img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
im = img.cpu().numpy().astype(np.float32) # torch to numpy
pred = session_detect.run([session_detect.get_outputs()[0].name], {
session_detect.get_inputs()[0].name: im})[0]
pred = non_max_suppression_face(torch.tensor(pred, dtype=torch.float), 0.3, 0.5)
for i, det in enumerate(pred): # detections per image
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
det[:, 5:15] = scale_coords_landmarks(img.shape[2:], det[:, 5:15], img0.shape).round()
for j in range(det.size()[0]):
xyxy = det[j, :4].view(-1).tolist()
conf = det[j, 4].cpu().numpy()
landmarks = det[j, 5:15].view(-1).tolist()
class_num = det[j, 15].cpu().numpy()
img0 = show_results(img0, xyxy, conf, landmarks, class_num)
cv2.imshow('result', img0)
k = cv2.waitKey(0)
# print(len(pred[0]), 'face' if len(pred[0]) == 1 else 'faces')
# outputs = post_precessing(y_onnx,r,left,top) #检测后处理
# print(f"总共耗时{time.time() - begin} s")

- Links de implantação relacionados yolov5face-toolkit
- yolov5-face-landmarks-opencv-v2