Mecanismo de atenção MHSA
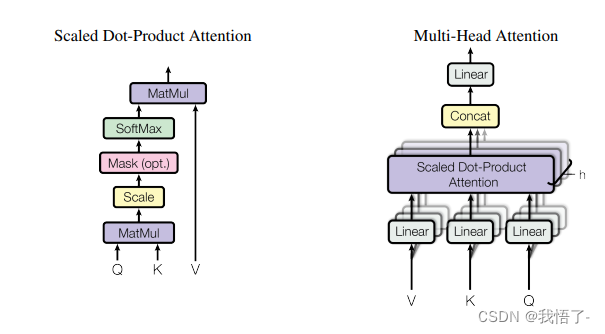
MHSA é Multi-Head Self-Altention, que é um mecanismo especial usado em modelos de linguagem na área de processamento de linguagem natural. Ele permite que o modelo se concentre melhor nas palavras em diferentes posições da frase ao prever a próxima palavra para se adaptar a diferentes cenários linguísticos. A ideia central do MHSA é dividir uma transformação linear em vários cabeçotes, cada cabeçote executa uma operação de autoatenção e unir as saídas de todos os cabeçotes como a representação final. Na operação de autoatenção, cada cabeça computa uma matriz de atenção que realiza um somatório ponderado de palavras em diferentes posições ao longo da sequência para obter uma representação para cada posição. A aplicação do MHSA provou ter bons resultados em muitas tarefas de processamento de linguagem natural.
Endereço do artigo: Artigo original sobre mecanismo de atenção MHSA
Código:
import torch
import torch.nn as nn
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4, pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos = pos_emb
if self.pos:
self.rel_h_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, 1, int(height)]),
requires_grad=True)
self.rel_w_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, int(width), 1]),
requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k) # 1,C,h*w,h*w
c1, c2, c3, c4 = content_content.size()
if self.pos:
content_position = (self.rel_h_weight + self.rel_w_weight).view(1, self.heads, C // self.heads, -1).permute(
0, 1, 3, 2) # 1,4,1024,64
content_position = torch.matmul(content_position, q) # ([1, 4, 1024, 256])
content_position = content_position if (
content_content.shape == content_position.shape) else content_position[:, :, :c3, ]
assert (content_content.shape == content_position.shape)
energy = content_content + content_position
else:
energy = content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2)) # 1,4,256,64
out = out.view(n_batch, C, width, height)
return out
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
mhsa = MHSA(n_dims=512)
output = mhsa(input)
print(output.shape)