CBAM (Convolutional Block Attention Module) é um módulo de mecanismo de atenção para melhorar o desempenho da rede neural convolucional (CNN). Foi proposto por Sanghyun Woo e outros no artigo de 2018 [ 1807.06521] CBAM: Convolutional Block Attention Module (arxiv.org) . O principal objetivo do CBAM é melhorar a capacidade perceptiva do modelo introduzindo atenção de canal e atenção espacial na CNN , de modo a melhorar o desempenho sem aumentar a complexidade da rede.
1. Visão Geral
O CBAM visa superar as limitações das redes neurais convolucionais tradicionais ao lidar com informações de diferentes escalas, formas e direções. Para tanto, o CBAM apresenta dois mecanismos de atenção: atenção de canal e atenção espacial . A atenção do canal ajuda a melhorar a representação de recursos de diferentes canais, enquanto a atenção espacial ajuda a extrair informações importantes em diferentes locais no espaço.
2. Estrutura do modelo
O CBAM consiste em dois componentes principais: módulo de atenção do canal (canal C) e módulo de atenção espacial (canal S) . Esses dois módulos podem ser incorporados respectivamente em diferentes camadas na CNN para aprimorar a representação de recursos.
2.1 Módulo de atenção do canal
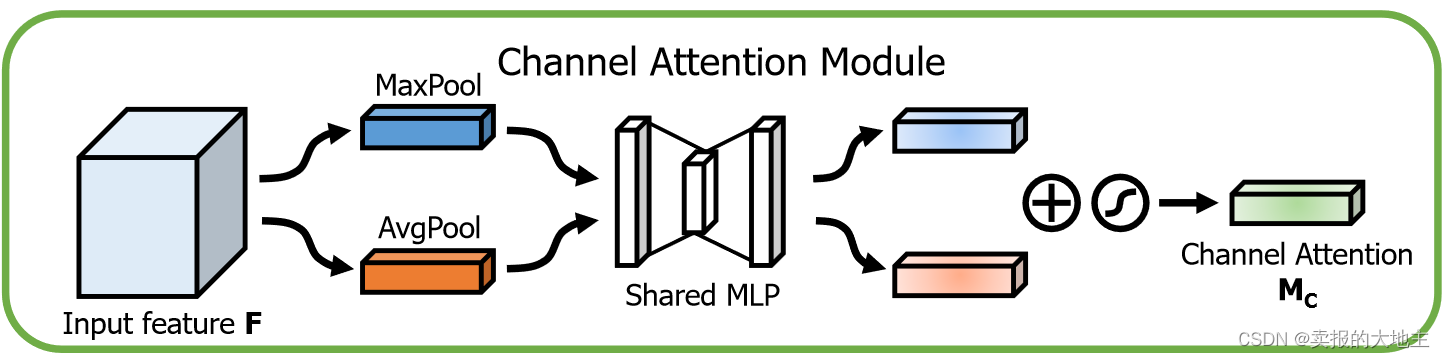
O objetivo do módulo de atenção do canal é aprimorar a representação de recursos de cada canal. A seguir estão as etapas para implementar o módulo de atenção do canal:
-
Agrupamento máximo global e agrupamento médio global: Para o mapa de recursos de entrada, primeiro execute as operações de agrupamento máximo global e agrupamento médio global em cada canal e calcule o valor máximo do recurso e o valor médio do recurso em cada canal. Isso produz dois vetores contendo o número de canais, representando os recursos máximo e médio globais para cada canal, respectivamente.
-
Camada totalmente conectada: Os vetores de recursos após o agrupamento máximo global e o agrupamento médio são inseridos em uma camada totalmente conectada compartilhada. Essa camada totalmente conectada é usada para aprender pesos de atenção para cada canal. Por meio do aprendizado, a rede pode decidir de forma adaptativa quais canais são mais importantes para a tarefa atual. Interseccione o vetor de recursos máximo global e o vetor de recursos médios para obter o vetor de peso de atenção final.
-
Ativação sigmóide: para garantir que os pesos de atenção estejam entre 0 e 1, uma função de ativação sigmóide é aplicada para gerar pesos de atenção do canal. Esses pesos serão aplicados a cada canal do mapa de recursos original.
-
Ponderação de atenção: usando os pesos de atenção obtidos, multiplique-os com cada canal do mapa de recursos original para obter o mapa de recursos do canal ponderado por atenção. Isso enfatizará os canais que são úteis para a tarefa atual e suprimirá os canais irrelevantes.
Implementação do código :
class ChannelAttention(nn.Module):
"""
CBAM混合注意力机制的通道注意力
"""
def __init__(self, in_channels, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
# 全连接层
# nn.Linear(in_planes, in_planes // ratio, bias=False),
# nn.ReLU(),
# nn.Linear(in_planes // ratio, in_planes, bias=False)
# 利用1x1卷积代替全连接,避免输入必须尺度固定的问题,并减小计算量
nn.Conv2d(in_channels, in_channels // ratio, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // ratio, in_channels, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
out = self.sigmoid(out)
return out * x
2.2 Módulo de Atenção Espacial

O objetivo do módulo de atenção espacial é enfatizar a importância de diferentes localizações em uma imagem. A seguir estão as etapas para implementar o módulo de atenção espacial:
- Agrupamento máximo global e agrupamento médio global: Para o mapa de recursos de entrada, execute operações de agrupamento máximo global e agrupamento médio global, respectivamente, para gerar recursos de diferentes escalas de contexto.
- Conexão e convolução: Os recursos após o agrupamento máximo global e o agrupamento médio global são conectados (unidos) ao longo da dimensão do canal para obter um mapa de recursos com diferentes informações de contexto de escala. Em seguida, esse mapa de recursos é processado por meio de camadas convolucionais para gerar pesos de atenção espacial.
- Ativação sigmóide: Semelhante ao módulo de atenção do canal, uma função de ativação sigmóide é aplicada aos pesos de atenção espacial gerados, restringindo os pesos entre 0 e 1.
- Ponderação de atenção: os pesos de atenção espacial resultantes são aplicados ao mapa de recursos original, ponderando recursos em cada localização espacial. Isso destaca áreas importantes da imagem e reduz o impacto de áreas sem importância.
Implementação do código :
class SpatialAttention(nn.Module):
"""
CBAM混合注意力机制的空间注意力
"""
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv1(out))
return out * x
2.3 Módulo de atendimento híbrido
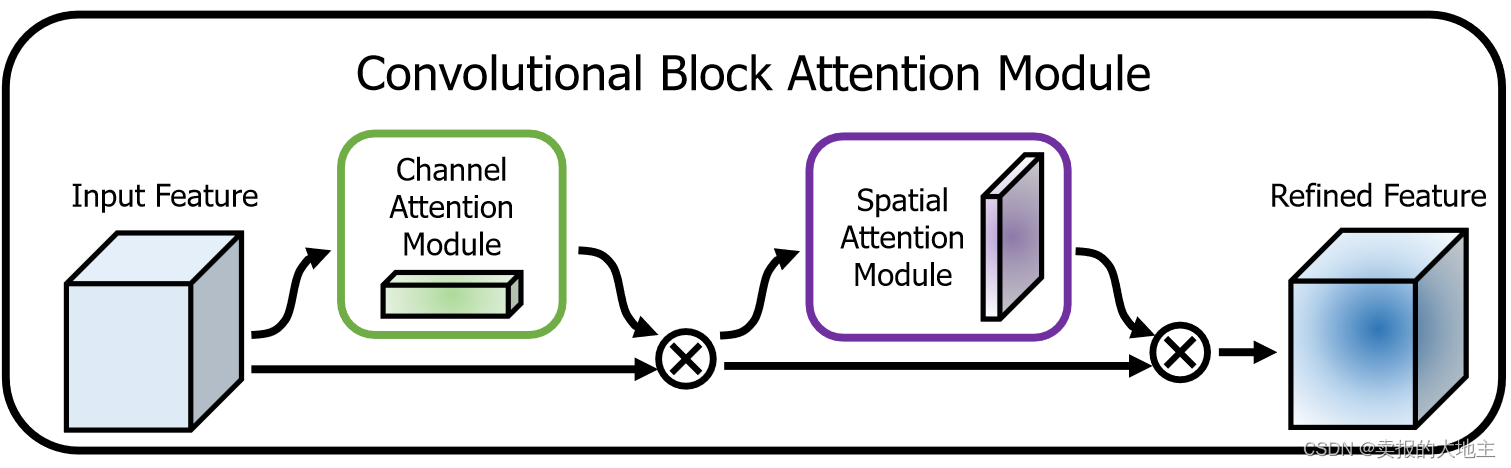
O CBAM deve multiplicar os recursos de saída do módulo de atenção do canal e do módulo de atenção espacial, elemento por elemento, para obter o recurso final de aprimoramento da atenção . Esse recurso aprimorado será usado como entrada para camadas de rede subsequentes para suprimir ruídos e informações irrelevantes, preservando informações importantes. O experimento no texto original prova que a integração da dimensão do canal primeiro, e depois a integração da dimensão do espaço, o efeito do modelo é melhor (a sensação de alquimia metafísica efetiva).
Implementação do código :
class CBAM(nn.Module):
"""
CBAM混合注意力机制
"""
def __init__(self, in_channels, ratio=16, kernel_size=3):
super(CBAM_Block, self).__init__()
self.channelattention = ChannelAttention(in_channels, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = self.channelattention(x)
x = self.spatialattention(x)
return x
Resumir
Em resumo, o módulo CBAM melhora a expressividade de recursos de redes neurais convolucionais por canal de aprendizado adaptativo e pesos de atenção espacial. Ao combinar atenção de canal e atenção espacial, o módulo CBAM é capaz de capturar a correlação entre características em diferentes dimensões, aumentando assim o desempenho das tarefas de reconhecimento de imagem.