1. Resumo
O produto Catálogo de Dados, ao resumir metadados de tecnologia e negócios, resolve cenários de negócios onde produtores de big data organizam e organizam dados, e consumidores de dados encontram e entendem dados, e atendem ao sistema de produto de desenvolvimento e governança de dados. Este artigo apresenta o processo de construção e iteração do sistema Data Catalog no conjunto Volcano Engine DataLeap e apresenta brevemente o design principal e algumas implementações principais.
2. Antecedentes
1. Metadados e Catálogo de Dados
Metadados geralmente se referem a dados que descrevem dados, informações descritivas sobre dados e recursos de informação. No contexto atual de big data, geralmente pode ser subdividido em metadados técnicos e metadados de negócios.
O Catálogo de Dados é um serviço de gerenciamento de metadados que coleta metadados técnicos e fornece contexto de negócios e semântica mais ricos com base neles. Geralmente oferece suporte a funções como catalogação de metadados, pesquisa e navegação detalhada.
Os metadados são a base do sistema Data Catalog, e o Data Catalog permite que os metadados exerçam melhor valor comercial.
2. O valor comercial do Catálogo de Dados
O sistema Data Catalog do conjunto Volcano Engine DataLeap atende principalmente a dois cenários principais para dois tipos de usuários.
Para os produtores de dados, eles usam o sistema Catálogo de Dados para organizar e classificar todos os tipos de metadados pelos quais são responsáveis. A maioria dos produtores são estudantes de desenvolvimento de big data. Normalmente, o produtor organiza um determinado lote de metadados relacionados na forma de um diretório para facilitar a manutenção. Além disso, os produtores continuarão a enriquecer atributos relacionados aos negócios com base em metadados técnicos, como rotulagem de negócios, adição de descrições de cenários de aplicação, explicações de campo, etc.
Para consumidores de dados, eles encontram e entendem os dados de que precisam por meio do Catálogo de Dados. Em termos de número de usuários e funções, há muito mais consumidores do que produtores, abrangendo estudantes com diversas funções, como analistas de dados, produtos e operações. Normalmente, os consumidores usarão a pesquisa por palavra-chave ou a navegação no catálogo para encontrar dados que resolvam seus próprios cenários de negócios e navegarão por introduções detalhadas, descrições de campos, relações de saída, etc., para compreender melhor e confiar nos dados.
Além disso, todos os tipos de metadados no sistema de Catálogo de Dados também servirão aos dois principais sistemas de produtos de desenvolvimento e governança de dados.
No campo dos big data, todos os tipos de sistemas de computação e armazenamento estão florescendo, e os conceitos e princípios variam amplamente, o que traz grandes desafios à recolha, organização, compreensão e confiança dos metadados. Portanto, criar um produto do Catálogo de Dados bem feito é um trabalho com um limite baixo e um limite superior alto e requer um processo contínuo de polimento e atualização.
3. Pontos problemáticos da versão antiga
Para resolver rapidamente o trabalho de coleta e recuperação de metadados do Hive, o produto ByteDance Data Catalog foi reconstruído com base no LinkedIn Wherehows. A arquitetura do Wherehows é relativamente simples, utilizando o modelo Backend + ETL. A versão inicial usa principalmente o design de armazenamento e a estrutura ETL do Wherehows, e desenvolve automaticamente os módulos funcionais de front-end e back-end.
Com o rápido desenvolvimento dos negócios da ByteDance e a introdução contínua de vários mecanismos de armazenamento na empresa, os pontos fracos dos produtores e consumidores de dados estão se tornando cada vez mais óbvios. Os problemas de design do sistema anterior também atingiram o estágio que precisa ser resolvido. Especificamente:
Pontos problemáticos no nível do usuário:
○ Produtores de dados: Em um ambiente multimotor, não existe uma forma conveniente e amigável de organização de dados para gerenciar metadados técnicos e de negócios de vários mecanismos de armazenamento e computação em uma única parada
○ Consumidores de dados: É difícil encontrar dados entre vários mecanismos, e a interpretação empresarial fragmentada dos metadados torna difícil a compreensão e a confiança
Pontos problemáticos técnicos:
○ Escalabilidade: Quando um novo tipo de metadados é adicionado, todo o sistema será danificado e o custo de desenvolvimento será mensal
○ Capacidade de manutenção: após um período de reparos, todo o sistema fica muito frágil e o pessoal de P&D não ousa alterá-lo casualmente; o armazenamento é fortemente dependente e MySQL, ElasticSearch, banco de dados gráfico e outros sistemas são usados para armazenar metadados ao mesmo tempo, e o custo de manutenção é alto; O acesso a um tipo de metadados aumentará 2 a 3 tarefas ETL, e os custos de operação e manutenção aumentarão acentuadamente
4. Alvo da nova versão
Com base nos pontos problemáticos acima, os desenvolvedores do Volcanic Engine DataLeap redesenharam e implementaram o sistema Data Catalog, na esperança de atingir os seguintes objetivos:
Em termos de recursos do produto, ajuda os produtores de dados a organizar os metadados de maneira conveniente e rápida, e os consumidores de dados a encontrar e compreender melhor os dados
Em termos de capacidades do sistema, o custo de acesso a novos metadados é reduzido de mensal para semanal ou mesmo diário, com uma arquitetura simplificada que pode ser operada e mantida por uma única pessoa nas horas vagas.
3. Pesquisa e Ideias
1. Pesquisa de produtos na indústria
Apoiados nos ombros de gigantes, os desenvolvedores do Volcanic Engine DataLeap conduziram funções de produto e pesquisas técnicas nos principais produtos DataCatalog do setor antes de fazê-lo. Como cada sistema itera com frequência, os dados são apenas para referência.
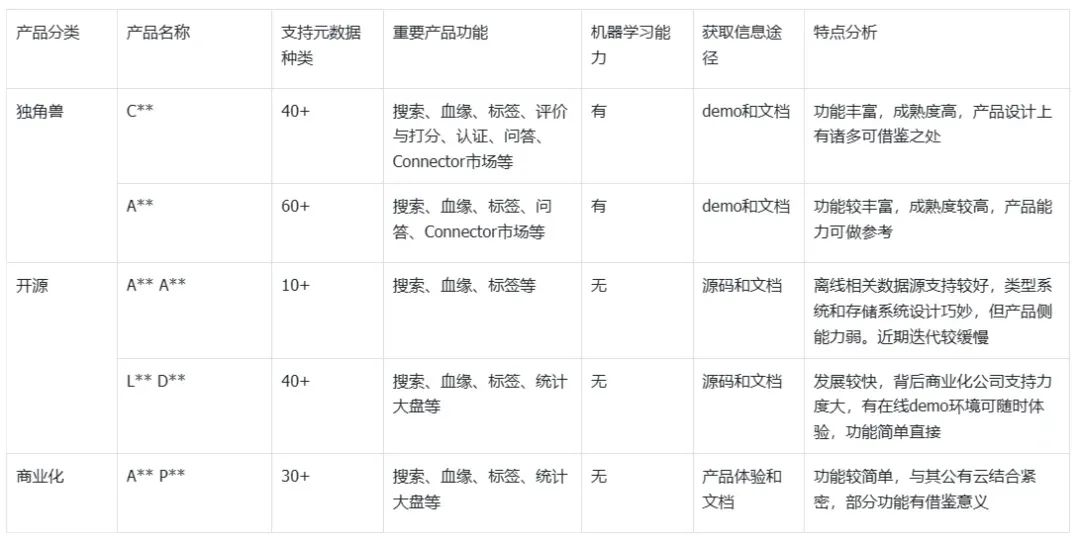
2. Ideia de atualização
De acordo com as conclusões da pesquisa, combinadas com as características comerciais existentes da Byte, os desenvolvedores do motor vulcão DataLeap finalizaram as seguintes ideias de desenvolvimento:
• Para capacidades essenciais, como busca e relacionamento sanguíneo, aprofundar e fortalecer para alinhar com os níveis líderes do setor
• Para as funções características de cada produto, selecione aquele que se adequa às características do byte business para integração
• Em termos de sistema técnico, os recursos de armazenamento e modelo são transformados com base no Apache Atlas, e a camada de aplicação suporta uma migração tranquila da versão antiga
4. Visão geral da tecnologia e do produto
1. Projeto de arquitetura
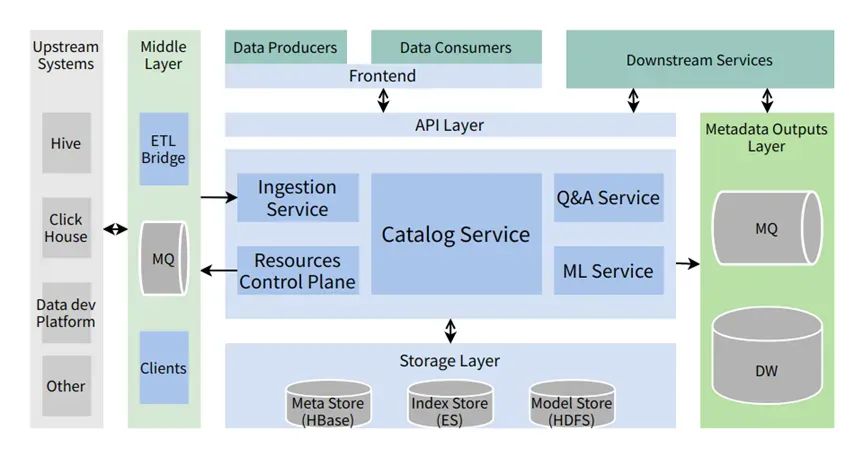
(1) Acesso aos metadados
• O acesso a metadados suporta modos T+1 e quase em tempo real
• Sistema upstream: incluindo vários sistemas de armazenamento (como Hive, Clickhouse, etc.) e sistemas de negócios (como plataforma de desenvolvimento de dados, plataforma de qualidade de dados, etc.)
• camada média:
○ Ponte ETL: operação T+1, geralmente extrai os metadados mais recentes de sistemas externos, compara-os com os metadados do sistema de Catálogo atual e atualiza a diferença
○ MQ: usado para armazenar temporariamente várias mensagens incrementais de metadados para consumo quase em tempo real pelo sistema Catalog
○ Todos os tipos de clientes que lidam com sistemas upstream encapsulam a capacidade de operar recursos subjacentes
(2) Camada de serviço principal
Os serviços principais do sistema são subdivididos nos seguintes subserviços de acordo com diferentes responsabilidades:
• Serviço de catálogo: oferece suporte a serviços essenciais, como pesquisa, detalhes e modificação de metadados
• Serviço de ingestão: aceite chamadas externas do sistema, grave metadados ou consuma ativamente metadados incrementais do MQ
• Plano de controle de recursos: interaja com armazenamento subjacente ou sistemas de negócios por meio de vários clientes para operar recursos subjacentes, como a construção de bancos de dados e tabelas, com recursos conectáveis
• Serviço de perguntas e respostas: recursos relacionados ao sistema de perguntas e respostas, perguntas e respostas de suporte sobre significados de campos de metadados, cenários de uso, etc.
• Serviço de ML: responsável por encapsular recursos relacionados ao aprendizado de máquina, que são conectáveis
• Camada API: Integra vários recursos no sistema na forma de API RESTful
(3) Camada de armazenamento
Diferentes opções de armazenamento são usadas para diferentes cenários:
• Meta Store: armazena a quantidade total de metadados e parentesco sanguíneo, atualmente usando HBase
• Index Store: armazena índices usados para acelerar consultas e dar suporte a cenários como indexação de texto completo, atualmente usando ElasticSearch
• Model Store: armazena informações do modelo de algoritmo, como recomendação e marcação, usa HDFS e é usado quando o serviço de ML está ativado
(4) Consumo de metadados
• Produtores e consumidores de dados interagem com o sistema por meio do front-end do Catálogo de Dados
• Os serviços online downstream podem acessar metadados por meio do OpenAPI e interagir com o sistema
• Camada de saída de metadados: fornece outro método de consumo downstream além da API
○ MQ: usado para armazenar temporariamente várias mensagens de alteração de metadados, o formato é oficialmente definido pelo sistema de Catálogo
○ Data warehouse: a quantidade total de metadados apresentados na forma de uma tabela de data warehouse
2. Atualização da função do produto
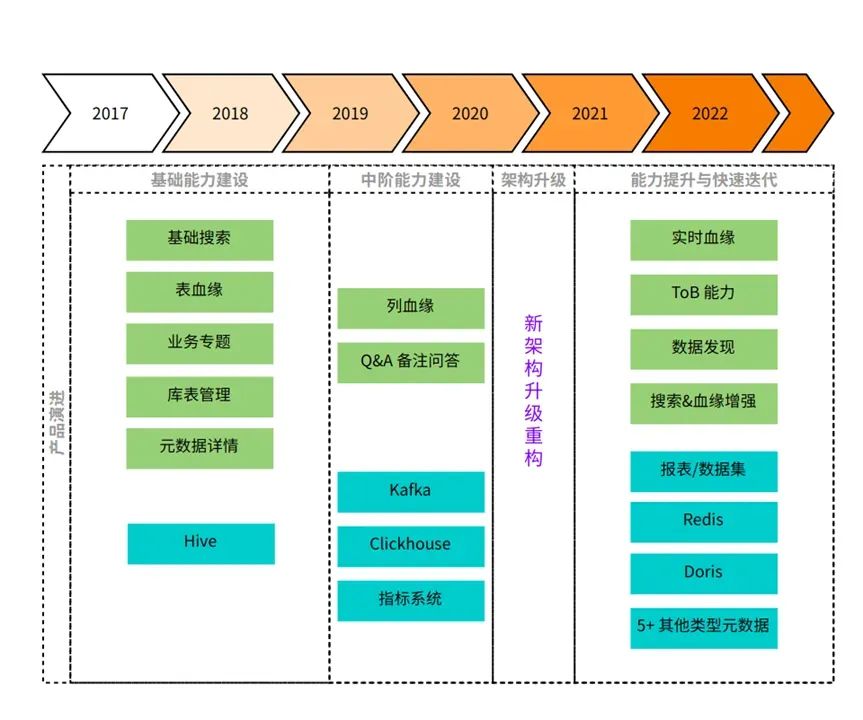
A atualização e iteração dos recursos do produto podem ser divididas aproximadamente nas seguintes etapas:
• Capacitação básica (2017-2019): A fonte de dados é principalmente o armazém de dados off-line Hive, que suporta a criação de tabelas de banco de dados relacionadas ao Hive, pesquisa de metadados e exibição detalhada, relacionamento sanguíneo entre tabelas e organização de tabelas relacionadas em tópicos de dados de uma perspectiva de negócios, espere
• Capacitação de nível médio (2019-2020, meados do ano): a fonte de dados expande Clickhouse e Kafka, suporta linhagem de colunas Hive, sistema de perguntas e respostas de perguntas e respostas, etc.
• Atualização da arquitetura (meados de 2020 até início de 2021): a iteração da capacidade do produto fica mais lenta, atualização da arquitetura com base no novo design
• Melhoria da capacidade e iteração rápida (de 2021 até agora): A fonte de dados foi expandida para incluir sistemas off-line, quase em tempo real, de negócios e outros sistemas de ponta a ponta, os recursos de pesquisa e relacionamento sanguíneo foram significativamente aprimorados, o os recursos de aprendizado de máquina foram explorados e a forma do produto tornou-se mais madura e estável. Além disso, também temos a capacidade de vender ToB.
5. Tecnologias-chave
Para construir um bom sistema de Catálogo de Dados, há muitos projetos de produtos principais e projetos técnicos que precisam ser considerados. Devido a limitações de espaço, este artigo apresenta apenas brevemente as partes mais importantes do projeto técnico. Para mais detalhes, consulte os artigos subsequentes.
1. Modelo de dados unificado
Unificar os modelos de dados de diferentes metadados é um pré-requisito importante para reduzir os custos de acesso e manutenção. Para o modelo de dados do sistema, os desenvolvedores do motor vulcão DataLeap referem-se basicamente ao design e implementação do Apache Atlas. Alguns conceitos básicos são brevemente introduzidos a seguir:
• Tipo: descreve um tipo de metadados e consiste em vários atributos. Por exemplo, hive table é um tipo de metadados e hive_db também é um tipo de metadados. O tipo pode ter um relacionamento de herança. De acordo com a ideia da programação orientada a objetos, type pode ser entendido como uma Classe.
• Instância (Entidade): representa uma instância específica de um tipo. Uma entidade pode existir como um atributo em outra entidade, como o atributo db em hive_table, e o próprio banco de dados também é uma entidade. No pensamento de programação orientada a objetos, uma entidade pode ser considerada uma instância de uma classe.
• Atributo (Atributo): Uma coleção de atributos é combinada para formar um Tipo. O tipo (typeName) do próprio atributo pode ser um tipo personalizado ou um tipo básico, incluindo data, string, etc. Por exemplo, db é um atributo de hive_table e coluna também é um atributo de hive_table.
• Relacionamento (Relacionamento): Uma Entidade especial usada para descrever o modo de associação entre duas Entidades.
Na aplicação real deste tipo de sistema, temos duas características:
Uso extensivo de herança e composição
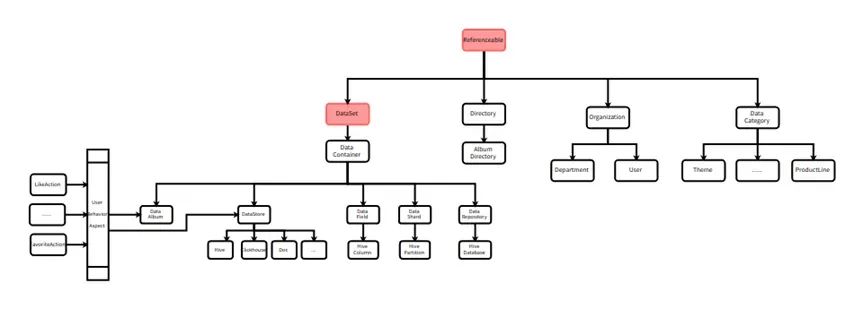
Os cenários de negócios da Byte são muito complexos. Para reutilizar totalmente as capacidades semelhantes entre vários tipos de metadados e obter flexibilidade de personalização suficiente, os desenvolvedores do mecanismo vulcão DataLeap projetaram um tipo pai para cada tipo de metadados. Por exemplo, Hive Table e Clickhouse Table contêm atributos como nome, descrição e campos, e todos herdam do tipo pai de DataStore.
Em outro caso, alguns tipos de entidades podem atuar em diversas outras entidades, como uma tabela Hive e vários relatórios de negócios organizados juntos, todos os quais podem ser favoritos ou apreciados pelos usuários. Também abstraímos comportamentos como favoritos e curtidas em entidades e os associamos a tabelas Hive e coleções de relatórios de negócios por meio de relacionamentos. Essa ideia é semelhante ao conceito de combinação ou aspecto na programação.
Mecanismo de carregamento de tipo ajustado
Na prática, percebemos que as capacidades associadas a uma determinada fonte de dados devem ser convergidas tanto quanto possível, o que pode reduzir significativamente os custos de manutenção subsequentes. Para uma definição de tipo de metadados, também está dentro do escopo desta consideração. Os desenvolvedores do mecanismo vulcão DataLeap ajustaram o mecanismo de carregamento de arquivos do tipo Apache Atlas, para que possam ser carregados a partir de vários pacotes na estrutura e sequência de diretórios que definimos. Isso também lançou as bases para a padronização subsequente.
2. Padronização do acesso aos dados
Para finalmente atingir o objetivo de redução dos custos de acesso e manutenção, após a unificação do sistema de tipos, o segundo passo é padronizar o processo de acesso.
Os desenvolvedores do mecanismo vulcão DataLeap encapsulam a lógica de acesso de um determinado tipo de metadados em um conector e simplificam o custo de gravação do conector fornecendo um SDK.
Tomando como exemplo o SDK do conector mais amplamente usado conectado pela ponte T+1, implementamos o seguinte modelo referindo-se à popular estrutura de processamento de fluxo Flink e combinando as características de negócios da ponte T+1:
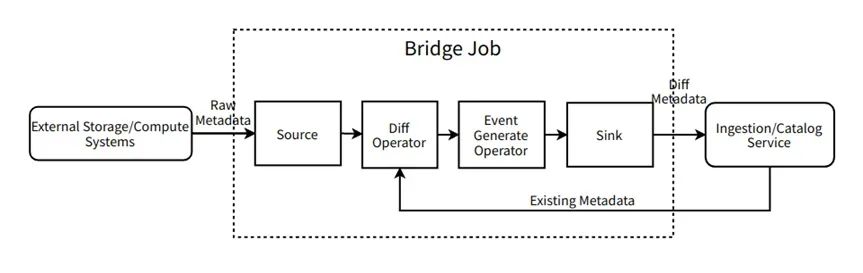
• Fonte: Extraia os metadados completos mais recentes em lotes de sistemas de computação de armazenamento externo, etc. As estruturas e campos de dados são geralmente determinados por sistemas externos. Alinhável conceitualmente com o operador de origem do Flink.
• Operador Diff: Recebe a saída da origem e extrai a quantidade total de metadados no sistema atual do Serviço de Catálogo, compara as diferenças e gera a diferença. Alinhe-se conceitualmente com um ProcessFunction personalizado no Flink.
• Operador Gerar Evento: Receba a saída do Operador Diff, converta os metadados da diferença para o formato do evento de acordo com o formato definido pelo sistema do Catalog, por exemplo, converta os novos metadados em CreateEvent. Alinhe-se conceitualmente com um ProcessFunction personalizado no Flink.
• Sink: Recebe a saída do Operador de Geração de Evento e grava os metadados de diferença no Serviço de Ingestão. Alinhado conceitualmente com o operador sink do Flink.
• Bridge Job: Montar o pipeline e fazer controle de tempo de execução. Alinhe conceitualmente o trabalho de Flink.
Quando novos metadados precisam ser acessados, geralmente apenas os operadores Source e Diff precisam ser reescritos e outros componentes são diretamente reutilizáveis. Conectores padronizados economizam muito acesso e custos de operação e manutenção.
3. Otimização de pesquisa
A pesquisa é a função mais utilizada no Catálogo de Dados, além da navegação detalhada, e também é o meio mais importante para os consumidores de dados encontrarem números. No sistema DataLeap do motor vulcão, mais de 70% dos usuários usam a função de pesquisa todos os dias.
A pesquisa é um campo técnico relativamente maduro e a recuperação de metadados pode ser considerada um mecanismo de pesquisa vertical. Esta seção apresenta brevemente a colheita ao projetar e implementar um mecanismo de busca de metadados. Mais detalhes serão expandidos e haverá artigos de acompanhamento.
Em cenários reais, os desenvolvedores do mecanismo vulcão DataLeap descobriram que a pesquisa de metadados dentro da empresa tem dois recursos muito significativos em comparação com os mecanismos de pesquisa gerais:
• Existem alguns padrões fortes na pesquisa: quando os usuários pesquisam metadados, eles têm alguns hábitos implícitos. Ao explorar os padrões fixos nos pontos enterrados, temos a oportunidade de otimização direcionada.
• A escala dos dados comportamentais é limitada: os usuários internos de pesquisa de metadados da empresa geralmente têm milhares de usuários e o número de cliques por dia é de 10.000. Isso também nos dá a oportunidade de simplificar o problema até certo ponto.
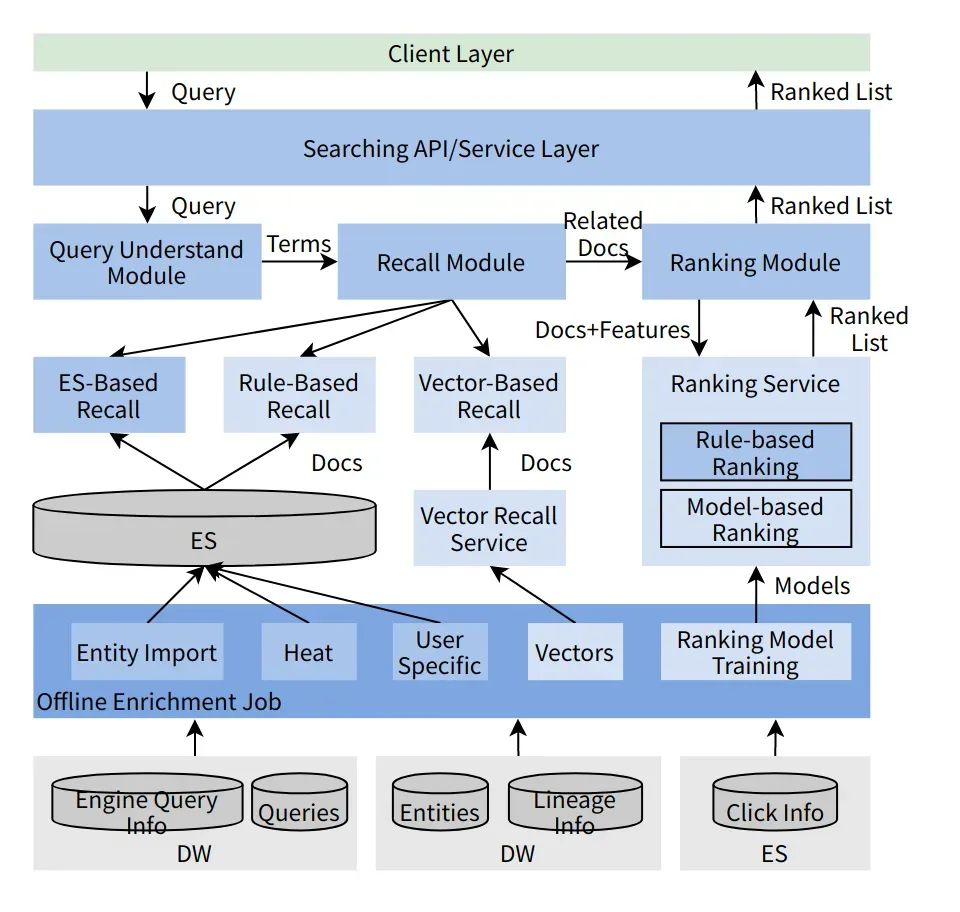
A busca de metadados projetada pelos desenvolvedores do motor vulcão DataLeap, a arquitetura é mostrada na figura acima. Grosso modo, pode ser dividido em duas partes:
• Parte offline: responsável por coletar todos os tipos de dados relacionados à pesquisa, fazer limpeza de dados ou treinamento de modelo e gravar em diferentes armazenamentos de acordo com diferentes finalidades para uso pelo módulo de pesquisa online.
• Parte online: dividida em três etapas principais: compreensão, recall e refinamento da pesquisa.As etapas e conceitos estão alinhados aos mecanismos de busca gerais.
Tendo em vista as características da análise acima, os desenvolvedores do motor vulcão DataLeap possuem duas estratégias correspondentes ao pesquisar e otimizar:
• Para padrões fortes, métodos de otimização baseados em regras são amplamente usados: por exemplo, os desenvolvedores do mecanismo de vulcão DataLeap descobriram que um grande número de usuários usaria o padrão "nome da biblioteca. nome da tabela" ao pesquisar por Hive. .", os desenvolvedores do mecanismo vulcão DataLeap tentarão primeiro pesquisar com base no nome da biblioteca e no nome da tabela
• Personalização radical: como a escala do usuário é controlável e um determinado usuário costuma usar metadados com frequência em um determinado campo, os desenvolvedores do mecanismo vulcão DataLeap registraram os detalhes históricos do comportamento de muitos usuários. Quando há uma certa relevância do texto, a pontuação de relevância personalizada será bastante melhorada
4. Habilidade sanguínea
A capacidade de relacionamento sanguíneo é outra capacidade central do sistema Data Catalog. Recursos de linhagem automatizados e completos são os destaques de muitos sistemas industriais. Construir uma capacidade de linhagem completa pode não apenas ajudar os produtores a classificar e organizar os metadados pelos quais são responsáveis, mas também ajudar os consumidores de dados a encontrar números e compreender o contexto dos dados.
A Byte se preocupa muito com o valor dos dados, e o negócio também é complexo, o que também impõe elevados requisitos para a construção de nosso link de linhagem de dados. Esta seção apresenta apenas brevemente as principais questões consideradas pelos desenvolvedores do mecanismo vulcão DataLeap ao construir um link de linhagem. Para obter mais detalhes, consulte o artigo anterior: Casos de uso e design de linhagens de dados dentro do ByteDance.
Em primeiro lugar, o limite do sistema da linhagem de dados é: começando com RDS e MQ, passando por vários cálculos e armazenamento e, finalmente, importado para indicadores, relatórios e sistemas de serviços de dados.
Em segundo lugar, ao projetar o sistema, os desenvolvedores do motor vulcânico DataLeap consideraram totalmente a diversidade e complexidade das ligações sanguíneas. Conforme mostrado na figura abaixo, o pessoal de P&D do Volcanic Engine DataLeap obtém informações de vários sistemas de tarefas por meio de métodos T + 1 e quase em tempo real, chama diferentes serviços de análise de acordo com o tipo de tarefa e grava os dados de relacionamento sanguíneo formatados no Data Sistema de Catálogo, para chamadas de API downstream ou MQ, consumo de data warehouse offline.
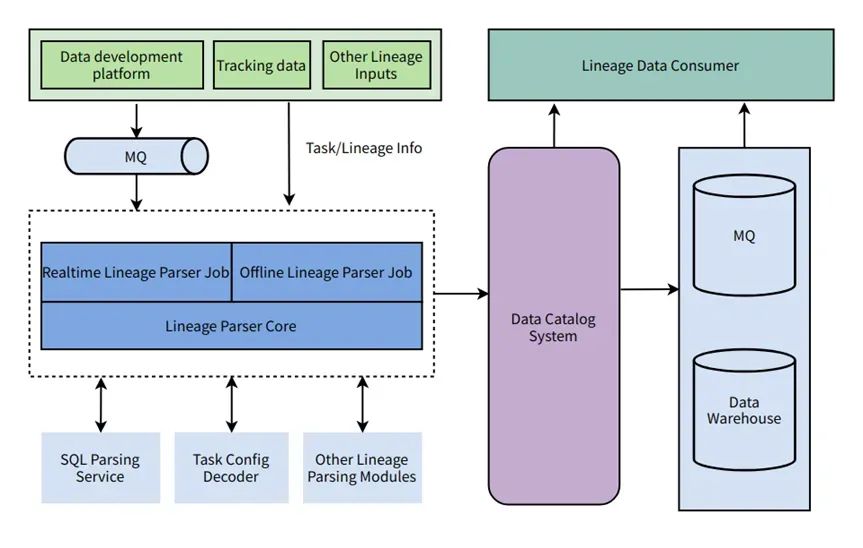
Finalmente, em termos de medição da qualidade da linhagem, os desenvolvedores do mecanismo vulcão DataLeap garantem a precisão, a abrangência e a atualidade das informações da linhagem, definindo a precisão, a cobertura e a oportunidade efetivas da linhagem.
Atualmente, nossos recursos de linhagem têm sido amplamente utilizados nos ativos de dados, desenvolvimento de dados e governança de dados da Byte.
5. Otimização da camada de armazenamento
Conforme mencionado anteriormente, na camada de armazenamento, os desenvolvedores do mecanismo vulcão DataLeap pegaram emprestado o design e a implementação do Atlas. A camada inferior do Atlas usa JanusGraph como mecanismo gráfico. JanusGraph é um mecanismo de computação baseado na semântica de consulta de gráfico Gremlin. Seu armazenamento subjacente suporta o armazenamento de estruturas KCV, como HBase/Cassadra/BerkeleyDB. Ao mesmo tempo, ele usa ElasticSearch como suporte de consulta de índice.
Quando os desenvolvedores do mecanismo vulcão DataLeap conectaram mais e mais metadados ao sistema, os pontos e arestas no armazenamento do gráfico atingiram a ordem de milhões e dezenas de milhões, respectivamente, e o desempenho de leitura e gravação encontrou problemas relativamente grandes. Fizemos algumas modificações no código-fonte e aqui estão duas das mais importantes. Para obter mais detalhes, consulte os artigos subsequentes.
(1) Otimização de leitura: habilite o recurso MutilPreFetch
Em nossa biblioteca existem muitos superpontos, ou seja, metadados com relacionamentos muito grandes. Para mencionar dois casos, um é uma tabela grande e larga com muitas colunas e, para algumas tabelas de aprendizado de máquina, pode até exceder 10.000 colunas; o outro caso é uma tabela inferior amplamente referenciada, como a relação sanguínea de primeiro nível da tabela inferior do ponto enterrado A jusante é mais de 10.000. Ao ler esse tipo de dados, vemos um desempenho extremamente ruim.
Semelhante à otimização de consulta lenta de bancos de dados relacionais, coletamos instruções de consulta lenta monitorando pontos ocultos, analisamos problemas no plano de consulta com a ajuda da função de perfil do gremlin e fazemos otimizações correspondentes construindo índices ou reescrevendo instruções e configurações.
Ativar a opção de consulta MutilPreFetch do JanusGraph é um dos casos. O princípio geral de implementação deste recurso é que quando a filtragem de atributos é realizada, os atributos de todos os vértices associados são obtidos em lotes em paralelo e, em seguida, a filtragem de atributos é realizada na memória. Quando este recurso não está habilitado, após os vértices pares serem encontrados , cada vértice é individualmente Obtenha o atributo e depois faça a condição de filtro.

Deve-se notar que os pré-requisitos deste mecanismo ao acionar a otimização

(2) Otimização de gravação: remova a verificação de exclusividade global do Guid
Existem também sérios problemas de desempenho para solicitações de gravação de metadados muito grandes. Por exemplo, ao escrever mais de 3.000 colunas, os desenvolvedores do mecanismo de vulcão DataLeap descobriram que isso leva quase 15 minutos.
Ao simular a escrita de uma única tabela supergrande e usar o gráfico em chama arthas para rastrear códigos relacionados, os desenvolvedores do mecanismo vulcão DataLeap descobriram que quando cada vértice do JanusGraph é escrito, a exclusividade global do GUID será verificada, o que é muito demorado.

Por meio de análise, os desenvolvedores do mecanismo de vulcão DataLeap descobriram que os GUIDs são globalmente exclusivos por padrão e não há necessidade de fazer essa verificação de exclusividade. Ao mesmo tempo, definimos um nome qualificado globalmente exclusivo em termos de semântica de negócios para reduzir duplicatas desnecessárias. verificações de exclusividade.
Com outras otimizações, economizamos muita sobrecarga ao gravar em um grande número de nós ao mesmo tempo, e o desempenho final é aproximadamente o seguinte:

6. Trabalho futuro
Algumas das tecnologias e funções do produto do Catálogo de Dados descritas neste artigo foram abertas ao público por meio do DataLeap, o conjunto de gerenciamento de P&D de big data do motor vulcão.
A seguir, os desenvolvedores do motor vulcão DataLeap irão melhorar o sistema de Catálogo de Dados, concentrando-se nos seguintes aspectos:
Primeiro, ele converte metadados em ativos de dados. Atualmente, a equipe coletou uma grande quantidade de metadados técnicos e alguns metadados de negócios. Como associar vários metadados a cenários de negócios reais e converter metadados sem valor comercial direto em ativos de dados com valor comercial direto? é a direção que a equipe está explorando.
Em segundo lugar, está a aplicação mais ampla das capacidades de inteligência. Existem muitos cenários inteligentes que podem ser implementados no Catálogo de Dados, como recomendação de pesquisa, marcação automática, etc. A equipe fez algumas tentativas básicas e realizará uma promoção mais ampla no futuro.
Finalmente, crie capacidades abertas. Em termos de acesso a metadados, a equipe planeja empacotá-lo em um recurso de produto e fornecer funções semelhantes ao mercado de conectores para facilitar uma cooperação e promoção mais ágil no mercado ToB; além disso, planeja conectar-se melhor com código aberto e agilidade comercial relatórios, etc., que podem exibir recursos do sistema em vários sistemas de relatórios.