O modelo GPT4 é até agora o inovador, disponível ao público gratuitamente ou através do seu portal comercial (para uso beta público). Inspirou novas ideias de projetos e casos de uso para muitos empreendedores, mas o sigilo em torno da contagem de parâmetros e modelos matou todos os entusiastas que apostavam no primeiro modelo de 1 trilhão de parâmetros para declaração de 100 trilhões de parâmetros!
Segredos do modelo revelados
Em 20 de junho, George Hotz, fundador da startup autônoma Comma.ai, revelou que o GPT-4 não é um modelo denso geral único (como GPT-3 e GPT-3.5), mas um modelo híbrido de 8 x 220 composição de bilhões de parâmetros
Mais tarde naquele dia, o cofundador do PyTorch da Meta reiterou o incidente.
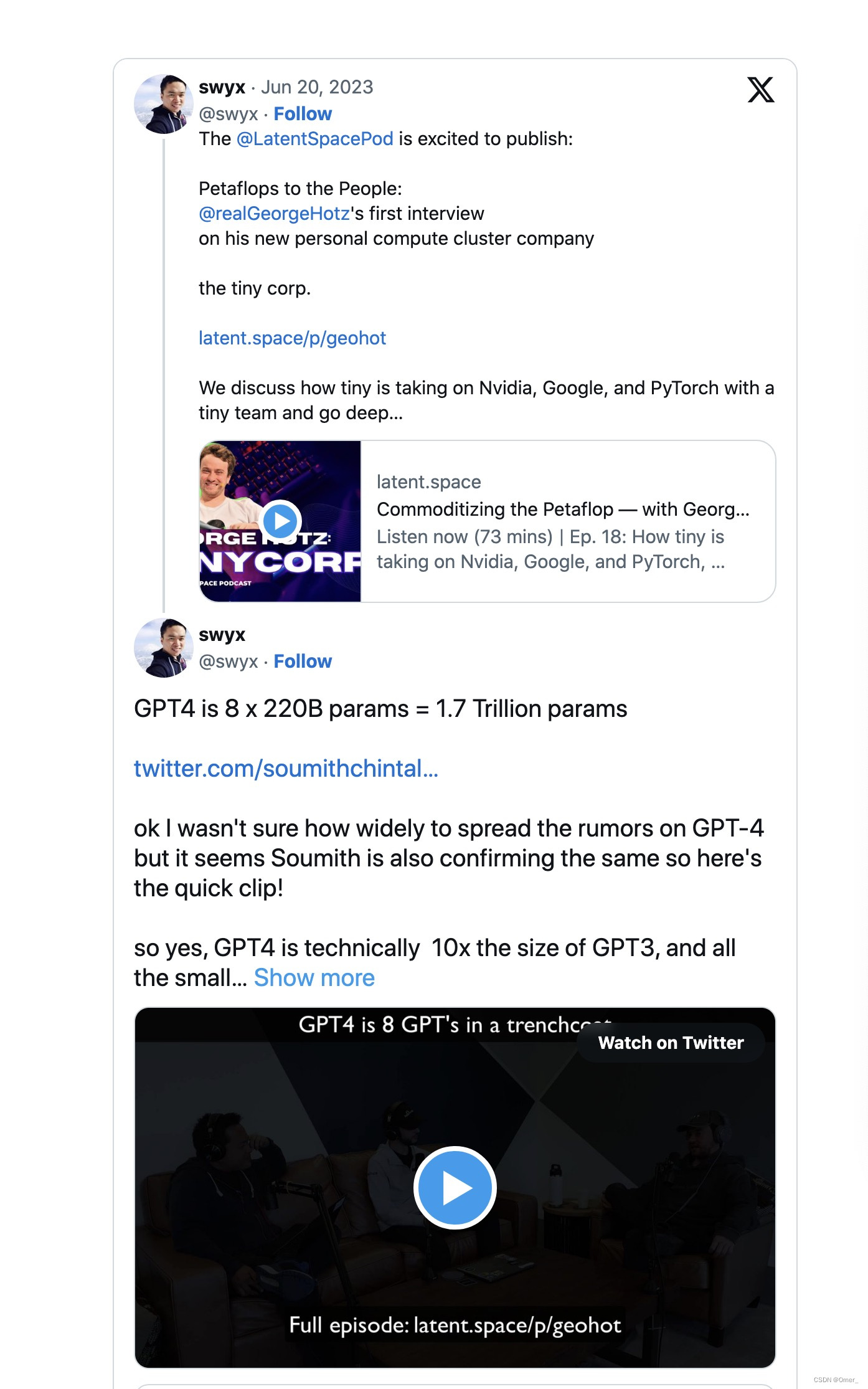
No dia anterior, Mikhail Parakhin , chefe do Bing AI da Microsoft , sugeriu isso.
GPT 4: não é um monólito
O que todos os tweets significam? GPT-4 não é um único modelo grande, mas uma união/conjunto de 8 modelos menores que compartilham conhecimentos. Há rumores de que cada um desses modelos tem 220 bilhões de parâmetros.

A abordagem é conhecida como um híbrido de paradigmas de modelos especialistas (link abaixo). Este é um método bem conhecido, também conhecido como modelo hidra. Isso me lembra a mitologia indiana e eu escolheria Ravana.
Considere isso com cautela, não é uma notícia oficial, mas foi declarada/sugerida por importantes membros de alto nível da comunidade de IA. A Microsoft ainda não confirmou nada disso.
Qual é o Paradigma Misto Especialista?
Agora que discutimos a combinação especializada, vamos dar uma olhada mais profunda no que ela é. Expert Mix é uma técnica de aprendizado em conjunto desenvolvida especificamente para redes neurais. É um pouco diferente da técnica de conjunto geral (a forma é generalizada) da modelagem tradicional de aprendizado de máquina. Portanto, você pode pensar na mistura de especialistas no LL.M. como um caso especial da abordagem de conjunto.
Resumidamente, neste método, a tarefa é dividida em subtarefas, e especialistas em cada subtarefa são utilizados para resolver o modelo. Esta é uma forma de dividir e conquistar ao criar uma árvore de decisão. Também se pode pensar nisso como meta-aprendizagem baseada em modelos especializados para cada tarefa individual.
Modelos menores e melhores podem ser treinados para cada subtarefa ou tipo de problema. O metamodelo aprende qual modelo usar para prever melhor uma tarefa específica. O meta-aluno/modelo atua como um guarda de trânsito. As subtarefas podem ou não se sobrepor, o que significa que combinações de resultados podem ser mescladas para chegar ao resultado final.
Mixture of Experts (MoE ou ME, abreviadamente) é uma técnica de aprendizagem em conjunto que implementa a ideia de treinar especialistas em subtarefas de problemas de modelagem preditiva.
Na comunidade de redes neurais, vários pesquisadores trabalharam em métodos de fatoração. [...] métodos decompõem o espaço de entrada para que cada especialista examine uma parte diferente do espaço. […] A rede fechada é responsável por combinar os especialistas individuais.
- Página 73, Classificação de padrões usando métodos de conjunto , 2010.
O método possui quatro elementos, que são:
- Divida as tarefas em subtarefas.
- Desenvolva um especialista para cada subtarefa.
- Use um modelo de portas para decidir qual especialista usar.
- Previsão de pool e saída do modelo de controle para fazer previsões.
O diagrama abaixo, retirado da página 94 do livro " Métodos Integrados" de 2012 , fornece uma visão geral útil dos elementos arquitetônicos do método

Exemplo de mistura de modelos especialistas com associação especializada e rede de portas
Extraído de: Métodos Ensemble
Subtarefas
A primeira etapa é dividir o problema de modelagem preditiva em subtarefas. Isso geralmente envolve o uso de conhecimento de domínio. Por exemplo, uma imagem pode ser dividida em elementos individuais, como fundo, primeiro plano, objetos, cores, linhas, etc.
...ME emprega uma estratégia de dividir e conquistar, onde uma tarefa complexa é decomposta em várias subtarefas mais simples e menores, e os alunos individuais (chamados especialistas) são treinados em diferentes subtarefas.
- Página 94, Métodos de conjunto , 2012.
Para aqueles problemas onde a divisão de tarefas em subtarefas não é óbvia, métodos mais simples e gerais podem ser usados. Por exemplo, pode-se imaginar um método que particione o espaço de recursos de entrada por grupos de colunas ou separe exemplos no espaço de recursos de acordo com medidas de distância de distribuições padrão, inliers e outliers, etc.
…Em ME, um problema chave é como encontrar uma divisão natural de tarefas e então derivar a solução global das sub-soluções.
- Página 94, Métodos de conjunto , 2012.
modelo especialista
A seguir, designe um especialista para cada subtarefa.
Os métodos de especialistas mistos foram originalmente desenvolvidos e explorados no campo das redes neurais artificiais, portanto, tradicionalmente, os próprios especialistas são os modelos de redes neurais usados para prever valores numéricos no caso de regressão ou rótulos de classe no caso de classificação.
Deve ficar claro que podemos “conectar” qualquer modelo para o especialista. Por exemplo, podemos usar redes neurais para representar funções de portas e especialistas. O resultado é chamado de rede de densidade mista.
- Página 344, Aprendizado de máquina: uma perspectiva probabilística , 2012.
Cada especialista recebe o mesmo padrão de entrada (linhas) e faz uma previsão.
modelo de portão
O modelo é usado para explicar as previsões feitas por cada especialista e para ajudar a decidir em qual especialista confiar para uma determinada informação. Isso é chamado de modelo fechado ou rede fechada porque é tradicionalmente um modelo de rede neural.
A rede de portas toma como entrada os padrões de entrada fornecidos ao modelo especialista e produz a contribuição que cada especialista deve fazer ao fazer previsões sobre a entrada.
…os pesos determinados pela rede de portas são atribuídos dinamicamente de acordo com a entrada, uma vez que o MoE aprende efetivamente qual parte do espaço de características cada membro do conjunto aprendeu
- Página 16, Integrando aprendizado de máquina , 2012.
A rede de portas é a chave do método, e o modelo aprende com eficiência a selecionar subtarefas de tipo para uma determinada entrada e, em seguida, selecionar especialistas confiáveis para fazer previsões sólidas.
A mistura de especialistas também pode ser vista como um algoritmo de seleção de classificadores onde classificadores individuais são treinados para serem especialistas em alguma parte do espaço de recursos.
- Página 16, Integrando aprendizado de máquina , 2012.
Ao usar um modelo de rede neural, a rede de gating é treinada com especialistas para que a rede de gating aprenda quando confiar em cada especialista para fazer previsões. Este processo de treinamento é tradicionalmente implementado usando maximização de expectativas (EM). A rede de portas pode ter uma saída softmax que fornece pontuações de confiança semelhantes a probabilidade para cada especialista.
Em geral, o processo de treinamento tenta atingir dois objetivos: para um determinado especialista, encontrar a função de porta ideal; para uma determinada função de porta, treinar o especialista de acordo com a distribuição especificada pela função de porta.
- Página 95, Métodos de conjunto , 2012.
método de agrupamento
Finalmente, uma mistura de modelos especializados tem de fazer previsões, o que é conseguido através de mecanismos de agrupamento ou agregação. Isto poderia ser tão simples quanto selecionar o especialista com maior rendimento ou confiança fornecida pela rede de gating.
Alternativamente, a ponderação e a previsão podem ser feitas, combinando explicitamente as previsões feitas por cada especialista com a confiança estimada pela rede de gating. Você provavelmente pode pensar em outras maneiras de fazer uso eficiente das saídas de rede preditivas e de controle.
O sistema de agrupamento/combinação pode então escolher o classificador único com o peso mais alto ou calcular uma soma ponderada das saídas do classificador para cada classe e escolher a classe que recebe a soma ponderada mais alta.
- Página 16, Integrando aprendizado de máquina , 2012.
roteamento de comutação
Devemos também discutir brevemente os métodos de roteamento de switch que diferem do documento do MoE. Menciono isso porque a Microsoft parece estar usando roteamento de switch em vez de modelos especializados para economizar alguma complexidade computacional, mas estou feliz por estar errado. Quando existem vários modelos de especialistas, suas funções de roteamento podem ter um gradiente não trivial (quando usar qual modelo). Este limite de decisão é controlado pela camada de comutação.
Os benefícios da camada de comutação são três.
- Os cálculos de roteamento são reduzidos se os tokens forem roteados apenas para um único modelo especialista
- Como um único token entra em um único modelo, o tamanho do lote (capacidade especializada) pode ser reduzido pelo menos pela metade
- Simplifica a implementação de roteamento e reduz a comunicação.
A sobreposição do mesmo token com mais de 1 modelo especialista é chamada de fator de capacidade. Abaixo está uma descrição conceitual de como o roteamento funciona com diferentes fatores de capacidade especializada

Uma ilustração da dinâmica de roteamento de tokens.
Cada especialista processa um tamanho fixo de lote de tokens modulado por um fator de capacidade. Cada token é roteado para o especialista com maior probabilidade de roteamento
, mas cada especialista tem um tamanho de lote fixo
(número total de tokens/especialistas) x fator de capacidade. Se a distribuição dos tokens for desigual
, alguns especialistas irão transbordar (indicado pela linha pontilhada vermelha), fazendo com que
esses tokens não sejam processados pela camada. Fatores de capacidade maiores aliviam
esse problema de overflow, mas também aumentam os custos computacionais e de comunicação
(indicados por slots brancos/vazios preenchidos). (Fonte https://arxiv.org/pdf/2101.03961.pdf )
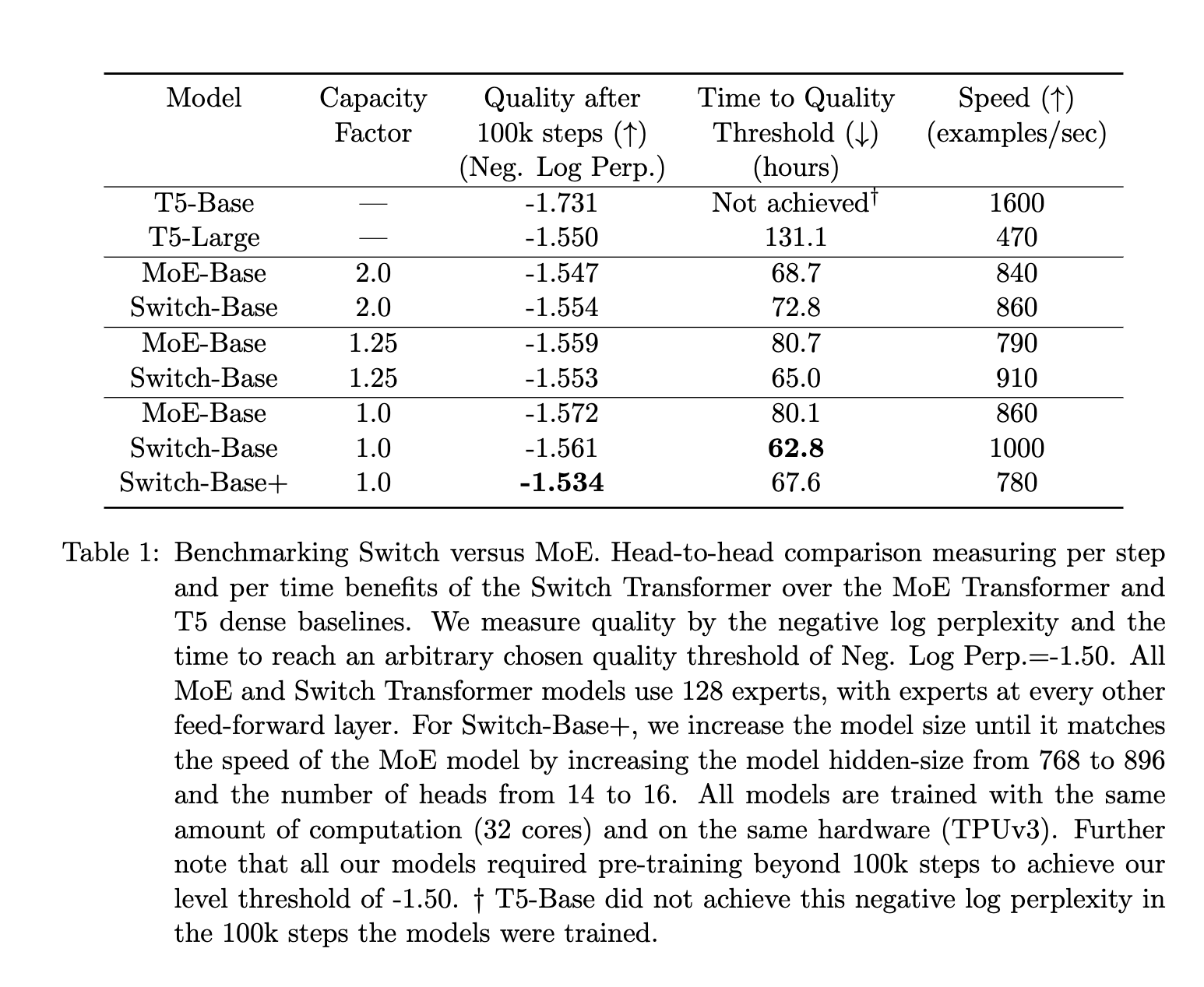
Em comparação com o MoE, as conclusões dos documentos do MoE e da Switch mostram que:
- Os transformadores de comutação superam os modelos densos bem ajustados e os transformadores MoE em termos de velocidade e qualidade.
- Espaço de cálculo menor para comutação de transformadores do que MoE
- Os transformadores de comutação têm melhor desempenho com fatores de capacitância mais baixos (1–1,25).
para concluir
Duas advertências: primeiro, tudo isso vem de boatos e, segundo, minha compreensão desses conceitos é bastante fraca, por isso exorto os leitores a encararem isso com cautela.
Mas o que a Microsoft conseguiu ao esconder essa arquitetura? Bem, eles criaram um rebuliço e geraram suspense. Isso pode ajudá-los a contar melhor suas histórias. Eles guardam suas inovações para si, evitando que outros os alcancem mais rapidamente. A idéia toda é provavelmente o plano usual da Microsoft de lançar 10 bilhões em uma empresa e, ao mesmo tempo, frustrar a concorrência.
O desempenho do GPT-4 é excelente, mas não é um design inovador ou inovador. É uma implementação engenhosa de uma abordagem desenvolvida por engenheiros e pesquisadores, complementada por uma implantação corporativa/capitalista. A OpenAI não nega nem concorda com essas afirmações ( https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed ), o que me faz pensar que esta arquitetura do GPT-4 é muito provavelmente real