Bem-vindo ao [Weibo Live Room], uma visão geral de 2 minutos das grandes vistas do café
Esta partilha inclui principalmente cinco aspectos:
- Sobre o Alluxio;
- Faça um balanço dos desafios que as empresas enfrentam ao experimentar a IA;
- A posição do Alluxio no stack tecnológico;
- Aplicação do Alluxio em treinamento de modelos e cenários online de modelos;
- Comparação de efeitos: antes de usar Alluxio VS depois de usar Alluxio.
1. Sobre o Alluxio
Alluxio - plataforma de orquestração de dados, camada de acesso a dados de alto desempenho.
2. Faça um balanço dos desafios que as empresas enfrentam ao experimentar a IA
1. Escassez de GPU;
2. O modelo online é lento;
3. Baixo uso de GPU.
3. A posição do Alluxio na pilha de tecnologia
√ Alluxio não é uma camada de armazenamento persistente. O armazenamento persistente depende de armazenamento distribuído como S3 Storage, Ceph ou HDFS na nuvem;
√ Alluxio é uma camada de acesso de alto desempenho na área de IA;
√ Alluxio fez muitas otimizações no desempenho de IO do Pytorch e TensorFlow;
√ Mais acima está a camada de orquestração de AI/ML, como Ray ou MLFlow.
4. Aplicação do Alluxio em treinamento de modelos e cenários online de modelos
√ Inicie o cluster GPU no local necessário;
√ Construir IA/ML em data lake existente;
√ Eliminar a cópia de dados e reduzir custos/complexidade;
√ Obtenha implantação e lançamento de modelo mais rápidos.
5. Comparação de efeitos: antes de usar Alluxio VS depois de usar Alluxio
√ Antes do uso: o tempo gasto no carregamento de dados ultrapassa 80% e o uso da GPU é inferior a 20%;
√ Após o uso: O tempo gasto no processo de carregamento de dados é reduzido de 82% para 1% e a taxa de utilização da GPU aumenta de 17% para 93%.
O texto acima é apenas uma visão geral dos grandes discursos do café, clique no vídeo para assistir ao conteúdo completo:

Anexo: O conteúdo completo da versão em texto compartilhada pelo big coffee pode ser visto abaixo
1. Sobre o Alluxio

A popularidade do treinamento de modelos está cada vez maior. Aproveitando essa popularidade, também compartilharemos a aplicação do Alluxio em cenários de IA/ML. Acredito que todos já tenham um bom conhecimento do Alluxio, Spark e outros ecossistemas, mas ainda quero apresentá-los em detalhes. O Alluxio fornece uma camada virtual de orquestração de dados. Ele não apenas fornece uma camada de acesso a dados de alto desempenho, mas também Além disso, há muitas otimizações upstream e downstream da estrutura de big data - incluindo acesso do armazenamento ao mecanismo de computação superior, desempenho de acesso a dados e facilidade de uso.

Alluxio - plataforma de orquestração de dados, camada de acesso a dados de alto desempenho.
Projeto nascido:
Alluxio (anteriormente conhecido como Tachyon) era originalmente um projeto irmão do Apache Spark no laboratório AMP da UC Berkeley, pesquisando como usar tecnologia distribuída para gerenciar memória externa de maneira unificada e fornecer aceleração de acesso a dados em nível de memória para aplicativos Apache Spark. O projeto foi liderado por Li Haoyuan (na época doutorando no laboratório AMP), e participaram outros professores e alunos do mesmo laboratório.
Alluxio inicialmente focado em big data, e está intimamente integrado com motores de computação como Spark e Presto. De 2020 até agora, vimos que existem muitos problemas no cenário de IA que não podem ser resolvidos pelo atual estrutura de sistema ou combinação A solução ainda é relativamente cara, portanto, enquanto trabalhamos na pilha de tecnologia de big data, também começamos a explorar a tecnologia de ponta dos cenários de IA. Hoje, formamos um produto relativamente solução orientada que pode ser fornecida para uso de todos. Hoje faremos um compartilhamento sistemático baseado nos desafios encontrados pelas empresas nacionais e estrangeiras em cenários de IA:
2. Faça um balanço dos desafios que as empresas enfrentam ao experimentar a IA

1. Escassez de GPU
Na verdade, há alguns anos, descobrimos que seja usando GPUs na nuvem ou comprando GPUs para construir IDCs (data warehouses), a infraestrutura de IA é mais difícil.As razões podem ser divididas em três situações:
1. Muitas empresas não podem comprar GPUs;
2. Mesmo que algumas empresas comprem GPUs, a quantidade não é muito grande e é difícil atender às necessidades do negócio;
3. Algumas empresas podem comprar GPUs no Alibaba Cloud ou Tencent Cloud, mas como transformar essas GPUs em um pool de computação sistemático para uso comercial de nível superior é relativamente difícil.
2. O modelo online é lento
A solução existente de data warehouse/armazenamento de dados da empresa é relativamente antiga e difícil de iterar.Após o treinamento da GPU, como lançar o modelo para o cluster de inferência é um link indispensável e também um link difícil:
1) Muitos armazéns de dados e armazenamento subjacente ainda são soluções de armazenamento relativamente tradicionais na empresa, como o HDFS, que pode ter sido usado há mais de dez anos, e agora é difícil ajustar as configurações de armazenamento;
2) Os dados estão na nuvem, o limite atual é sério e há muitas restrições de uso.
Falaremos em profundidade mais tarde sobre como resolver este problema.
3. Baixo uso de GPU
Hoje em dia, a taxa de utilização de GPUs no processo de treinamento de modelos de muitas empresas é geralmente relativamente baixa. Claro, este não é um problema que o Alluxio possa resolver. O que vimos é que a maior parte dos dados corporativos está no data warehouse. Como importar esses dados para clusters de GPU é muito difícil. Muitos desafios. Posteriormente, também compartilharemos como o Alluxio resolve esse problema entre diferentes fornecedores de nuvem e grandes empresas no país e no exterior.
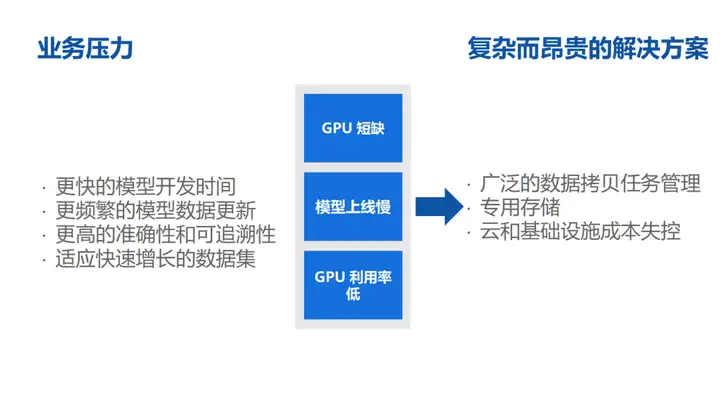
Os itens acima mencionados são principalmente pressões de negócios ou pressões de tomada de decisão de negócios. Essas pressões basicamente se tornarão pressões técnicas para os engenheiros. Para poder desenvolver modelos mais rapidamente, temos algumas expectativas:
1) tempo de desenvolvimento de modelo mais rápido;
2) Atualizações mais frequentes dos dados do modelo;
3) Maior precisão e rastreabilidade;
4) Adapte-se a conjuntos de dados em rápido crescimento.
Estas pressões refletidas no lado técnico podem ser resumidas em três pontos:
- Gerenciamento extensivo de tarefas de cópia de dados
Por exemplo, com nosso aplicativo atual, como fazer este sistema geralmente requer algumas tarefas complexas de cópia de dados, copiando dados do data warehouse para o cluster de treinamento GPU, seja copiado para o NAS local, sistema NFS ou copiando para um local disco para gerenciamento de dados é mais complicado.
2. Armazenamento dedicado
Para atender às necessidades dos cenários de IA, os requisitos de desempenho serão relativamente altos.Pode-se entender que: 20-30 anos atrás, a GPU foi desenvolvida em conjunto com HPC (High Performance Computing), então naquela época todos geralmente tendiam a tem um conjunto de rede IB, e existe um conjunto de armazenamento de alto desempenho (full flash) para apoiar o desenvolvimento de negócios.Na verdade, na nuvem ou IDC, descobrimos que esse problema é muito difícil de resolver, porque a maioria das empresas/ as instalações de nuvem não têm como fornecer um nível tão alto de armazenamento dedicado para dar suporte ao treinamento de modelos ou tarefas de distribuição de modelos.
3. Os custos de nuvem e infraestrutura estão fora de controle
Depois que o modelo é lançado, com o crescimento da escala de negócios, o custo da nuvem e da infraestrutura é muito fácil de sair do controle. Vimos muitos cenários, como um aumento de cinco vezes nos custos da nuvem em três anos, o que é normal.
3. A posição do Alluxio na pilha de tecnologia

Antes de entrar na discussão técnica detalhada, vamos apresentar sistematicamente a posição do Alluxio na pilha de tecnologia AI/ML.
Em primeiro lugar, Alluxio não é uma camada de armazenamento persistente. Nosso armazenamento persistente depende mais de armazenamento distribuído, como S3 Storage, Ceph ou HDFS na nuvem. Todas essas são interfaces do Alluxio e são uma camada de armazenamento persistente. , é não é o mesmo conceito do Alluxio.
Além disso, o Alluxio é uma camada de acesso de alto desempenho na área de IA, porque para a camada de armazenamento persistente, a maioria das empresas busca eficiência de preço e desempenho, e essa eficiência significa ter um pool de armazenamento muito barato. recursos, e não se espera que haja um conjunto de armazenamento de alto desempenho muito caro para armazenamento persistente. A razão para isso é que vimos centenas de volumes de dados em muitos fabricantes de Internet ou empresas tradicionais. PB ou mesmo nível EB, mas ao mesmo tempo, não há tantos dados de treinamento, que podem ser dezenas de TB, ou até um pouco mais de 1 PB. Se você puder colocar esses dados em um armazenamento de alto desempenho para acoplamento ascendente, sim Para os usuários, o preço A relação /desempenho é muito baixa, então contamos com essa camada de armazenamento persistente para fazer um encaixe muito simples, ou agora que existe uma camada de armazenamento persistente, podemos realizar o encaixe de dados diretamente sem alterar sua arquitetura.
Seguindo em frente, fizemos muitas otimizações no desempenho de IO do Pytorch e do TensorFlow, incluindo estratégia de cache, otimização de agendamento/como conectar-se a ele e implantação do Kubernetes. Apresentaremos como conectar em detalhes mais tarde.
Mais acima está a camada de orquestração de AI/ML, como Ray ou MLFlow.
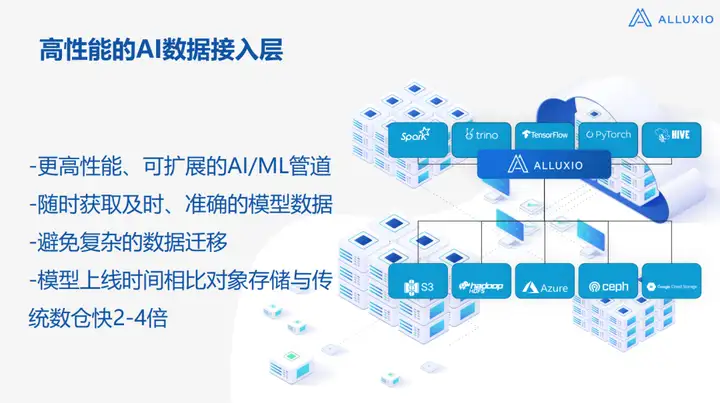
Este é um diagrama relativamente claro, porque Alluxio é uma empresa desenvolvida a partir de um cenário de big data. Fazemos IA há cerca de 4 a 5 anos. Durante esses 4 a 5 anos, usamos Alluxio. Existem muitos valores visto no ambiente cliente/usuário, que pode ser resumido em 4 pontos:
1. Maior desempenho e pipeline de IA/ML escalável
Não alteramos a implantação de cluster existente, como o armazenamento de objetos existente, HDFS, etc., e ao mesmo tempo queremos expandir o negócio. Na verdade, existem dois pontos-chave aqui:
√ Geralmente, embora as duas equipes de big data e IA estejam sob a mesma grande arquitetura, as pilhas de tecnologia são na verdade muito diferentes.Por exemplo, a pilha de tecnologia de big data terá Spark, Trino, Hive, HBase, etc., e o o acoplamento downstream é HDFS, algum armazenamento de objetos na nuvem, etc. Esses dados estão sempre lá, e o volume de dados pode ser de centenas de PB ou até mesmo nível EB. Ao mesmo tempo, uma plataforma AI Infra precisa ser construída. A IA A pilha de tecnologia é, na verdade, Pytorch e TensorFlow.O seguinte acoplamento A maioria deles é armazenamento de objetos, como Ceph, MinIO, etc. Outros terão algum armazenamento dedicado, como fornecer sistemas NFS e NAS para acoplamento ascendente;
√ Na verdade, a existência destes dois sistemas criou um problema de docking, ou seja, os dados estão no data warehouse, mas o processamento está no AI Infra, que se torna um sistema muito complicado, e o Alluxio pode ajudar a passar este sistema, não requer sempre migração de dados muito complicada.
2. Obtenha dados de modelo oportunos e precisos a qualquer momento
Quando os dados do modelo saem do cluster de treinamento, eles precisam ser colocados primeiro no armazenamento e depois puxados para o cluster de inferência. Esse processo geralmente é muito complicado, como o Data Pipeline. Muitas empresas de Internet com as quais nos comunicamos antes tem um armazenamento de ponto de verificação temporário e, em seguida, há um armazenamento de ponto de verificação persistente.É um processo muito complicado para eles puxarem um ao outro com baixo desempenho e alto desempenho.
3. Evite migrações complicadas de dados
4. O tempo online do modelo é 2 a 4 vezes mais rápido do que o armazenamento de objetos e o data warehouse tradicional
O armazenamento subjacente geralmente é o armazenamento de objetos ou HDFS tradicional. Por exemplo, o HDFS tradicional é projetado para armazenamento massivo de dados. Ele não foi projetado para desempenho. Na maioria dos casos, é para garantir tolerância a falhas. Ao mesmo tempo, visa armazenamento na nuvem. Depois de me comunicar com muitos fornecedores de nuvem, aprendi que, em muitos casos, eles não podem usar diretamente o armazenamento de objetos para oferecer suporte a serviços de IA na nuvem.
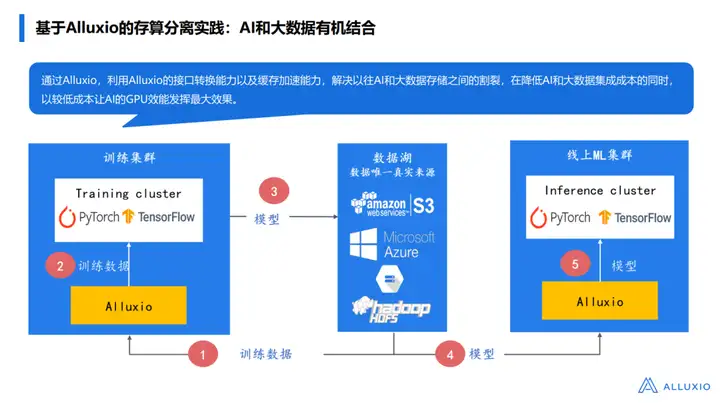
Vamos falar detalhadamente sobre como o Alluxio constrói este sistema. Há muitas cenas nele. Aqui gostaria de compartilhar com vocês a intenção original do projeto de arquitetura do Alluxio:
Em primeiro lugar, vimos em muitos fornecedores de Internet que a maioria dos clientes/usuários tem uma alta probabilidade de seus dados estarem no data lake (90-95%) e seus dados não usam um cluster de dados separado para fazer isso. Em vez disso, há muitos dados, incluindo o tradicional armazenamento Hive Meta, dados no popular data lake e muitos dados de streaming de dados chegando diretamente, e muitos dados não estruturados são armazenados no data lake.
Então, como o Alluxio desempenha um papel nisso?
Agora é mais popular usar a arquitetura Spark ou Ray para pré-processar os dados e colocá-los de volta no data lake. Mais tarde, o TensorFlow e o Pytorch extrairão os dados aqui para treinamento. Por exemplo, observe a imagem à esquerda. Se você não usa Alluxio para puxar O que pode dar errado com os dados?
Por exemplo, o data warehouse original usa um cluster HDFS e o treinamento de IA usa um cluster Ceph:
√ Em primeiro lugar, os dados processados/não processados devem ser puxados para o cluster Ceph e, em seguida, os dados extraídos serão servidos para cima. Haverá alguns problemas aqui: Primeiro, o processo de extração será muito complicado e muitas empresas irão Depois de desenvolver um sistema de gerenciamento de dados por nós mesmos, haverá vários conjuntos de processos diferentes nele. Por exemplo, usamos o meta store para corresponder a onde essas tabelas/dados estão;
√ Em segundo lugar, é necessário extrair dados de forma incremental;
√ Finalmente, os dados precisam ser verificados para ver se há algum problema.
Há um longo atraso neste processo desde a extração até a disponibilidade, por isso queremos usar a função de cache do Alluxio para ajudá-lo a resolver esse problema.
Primeiro, podemos pré-carregar parte dos dados no Alluxio e armazená-los mais perto do cálculo, reduzindo assim o consumo de largura de banda. Ao mesmo tempo, mesmo que não haja dados pré-carregados, o mecanismo de cache do Alluxio pode ajudar a extrair dados rapidamente para o cluster de treinamento. Este método é semelhante à transação T+1 (T+0) na negociação de ações, ou seja, os dados podem ser fornecidos rapidamente a partir do momento em que os dados são acessados pela primeira vez, e não há necessidade de esperar várias horas para transferir o dados, economizando assim muito tempo.
Em segundo lugar, o Alluxio também pode reduzir os problemas de governação de dados causados pelo autodesenvolvimento dos utilizadores. Se o usuário já possui um sistema de governança de dados, também fornecemos uma variedade de APIs, incluindo APIs para atualização de dados brutos, para facilitar o desenvolvimento personalizado para os usuários.
Além disso, também nos concentramos em como reduzir custos e melhorar a eficiência do cluster de formação. No passado, muitas empresas utilizavam clusters de armazenamento de alto desempenho para treinamento, mas esse custo pode ser muito caro, o que limita a expansão dos negócios. Descobrimos que esse custo geralmente não ultrapassa 3-5% em comparação com o custo geral do cluster de GPU se apenas os nós de computação da GPU estiverem equipados com disco. Além disso, muitas empresas possuem muitos recursos de armazenamento, mas como utilizar plenamente esses recursos continua sendo um desafio.
Alluxio oferece muitos pontos de integração nesse sentido. Podemos implantar diretamente o cluster Alluxio nos nós de treinamento, que consome muito pouco (cerca de 30-40 GB de memória), mas pode fornecer suporte de treinamento de alto desempenho. Os usuários só precisam pagar 3-5% do custo de todo o cluster de computação para aproveitar ao máximo o cluster de GPU e ajudar os usuários a superar gargalos de IO para atingir 100% de utilização da GPU.
Além do cluster de treinamento, também prestamos atenção especial ao custo e à eficiência do cluster de inferência. À medida que o cluster de inferência é dimensionado, o custo pode ser muito maior do que o cluster de treinamento. Portanto, estamos empenhados em resolver o problema de como implantar rapidamente o modelo gerado pelo treinamento no cluster online.
Na forma tradicional, o resultado do treinamento será gravado em um armazenamento Ceph, e então o cluster online poderá estar localizado no mesmo IDC ou em outro IDC, envolvendo gerenciamento complexo. Muitas empresas desenvolverão um conjunto de seu próprio gateway de armazenamento (gateway de armazenamento) para resolver problemas de domínio cruzado ou IDC cruzado, mas o gateway tem um problema de tabela, que resolve um problema de domínio cruzado ou IDC cruzado, mas não o faz realmente resolvê-lo É um problema de alto desempenho e de domínio cruzado.Um entendimento simples é que o cluster de treinamento e o ML online podem ser conectados, mas se o Gateway na AWS for completamente incapaz de suportar o cluster de inferência, como expandir para 100 ou até mesmo raciocínio de 1000 nós Após o cluster, ele irá tremer muito quando ficar online. Outro exemplo: Alluxio pode implantar todo o modelo no cluster de inferência dentro de 2 a 3 minutos. Geralmente, esse tipo de sistema leva 10 vezes mais tempo do que , e seu P95 e P99 serão muito longos.
4. Aplicação do Alluxio em treinamento de modelos e cenários online de modelos
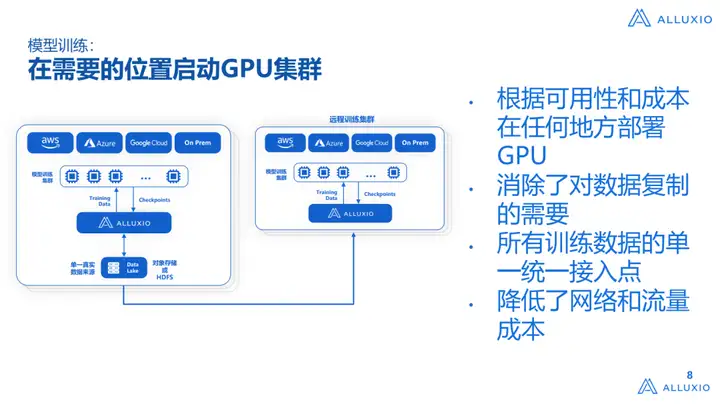
A seguir explicaremos detalhadamente como o Alluxio funciona em diferentes cenários:
O primeiro é o problema que mencionamos antes. No caso de uma grande escassez de GPUs, as empresas que vimos não tinham uma estratégia multi-cloud antes. A implantação é muitas vezes forçada a ficar assim. Por exemplo, vemos que muitos clientes/usuários, cujos dados estão na AWS, não querem usar outras nuvens, como Azure, Google Cloud, etc., mas descobrimos um problema este ano. O Azure comprou todas as GPUs. Nesse caso, é realmente difícil para dizer que todos os clusters podem ser encontrados na AWS. Então, os clusters que vemos devem estar no Azure e deve haver uma maneira de acessar diretamente a AWS. Dados, esse problema leva a um desempenho de dados muito baixo se forem obtidos diretamente. Se o a largura de banda da rede é muito baixa, a taxa de utilização da GPU geralmente não excede 10%.No caso de uma rede melhor (como uma linha dedicada) Down, pode chegar a 20-30%.
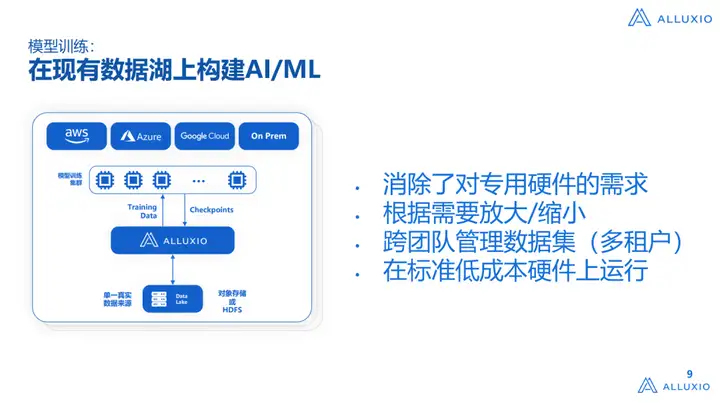
O segundo problema é que se você quiser construir um gerenciamento de dados multi-cluster é muito complicado, inclusive garantir a consistência dos dados, como atualizar e extrair esses dados, mas para o Alluxio fizemos muita integração, você pode usar diretamente o Alluxio para resolver esses problemas. Em segundo lugar, não queremos que todos comprem um conjunto de soluções de hardware. Antes de ingressar na Alluxio, meu laboratório fazia HPC. Um grande problema com HPC é que seu custo é muito alto. Comprar um conjunto de HPC geralmente é Você pode comprar 10 conjuntos de hardware Hadoop, ou hardware de armazenamento na nuvem, então se você precisar comprar um conjunto de hardware proprietário para construir a arquitetura AI Infra, é metade do esforço e o custo é muito caro. Depois de ver essa cena, ainda esperamos que possamos construir diretamente caminhos de dados de IA e ML no data lake, não podemos alterar o sistema de armazenamento e, ao mesmo tempo, podemos usar os existentes, sem comprar hardware adicional, como IDMA, para apoiar as necessidades de treinamento. é a nossa visão. Ao mesmo tempo, não há necessidade de considerar o problema do isolamento dos dados das tarefas no armazém de dados original (o chamado isolamento significa que a migração de dados é necessária e, em seguida, executada em dois sistemas muito independentes, o que é muito problemático para extração e aquisição de dados).

A imagem acima é mencionada acima. Algumas funções fornecidas pelo Alluxio, como carregamento/descarregamento automático de data lake e funções de atualização de dados, podem melhorar a produtividade da equipe de engenharia de dados. Um cenário comum é: se for baseado no sistema original, add Para um Ceph, o cronograma básico será estendido para 3 a 6 meses. É muito comum que empresas estrangeiras estendam o cronograma para mais de 6 meses. Todo o pipeline de dados é construído dentro dele. Se estiver interessado, você pode aprender mais sobre os casos de aplicação de Zhihu.Há interpretações muito detalhadas nele, informando como construir este sistema.
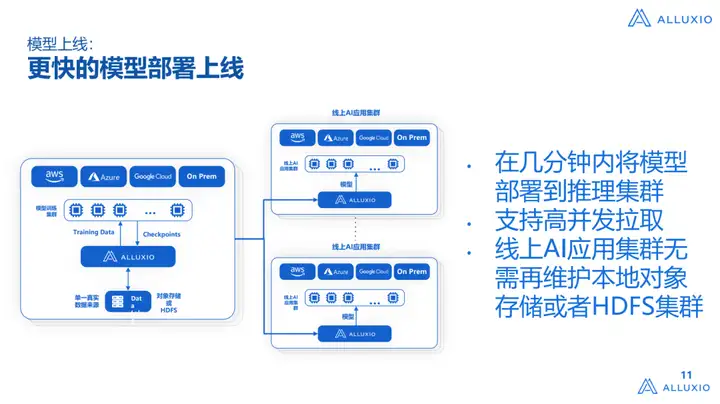
A imagem acima mostra outro problema que mencionamos anteriormente: a implantação do modelo é limitada pelo armazenamento subjacente, incluindo problemas de largura de banda, e também é limitada pelas diferentes localizações do IDC. Nosso Alluxio pode construir uma multiarquitetura multi-cloud, não importa de onde. a nuvem pública Seja uma nuvem privada ou uma implantação de modelo entre diferentes nuvens públicas, esse problema será resolvido muito rapidamente.Forneceremos um sistema de cache de alta simultaneidade para suportar a atração de negócios de alta simultaneidade.
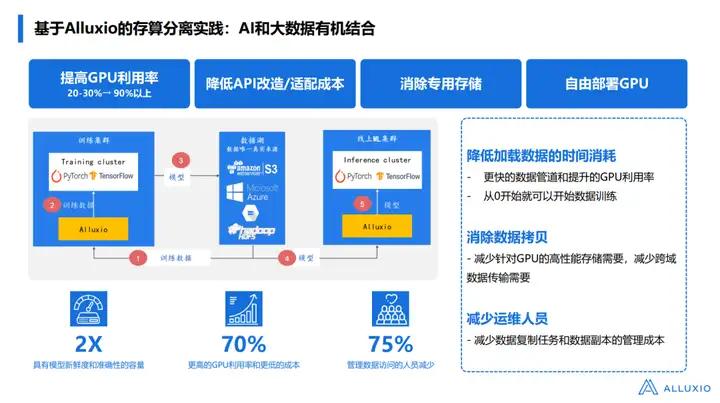
Resumindo, qual é a posição do Alluxio na arquitetura de IA? Quais problemas o Alluxio ajuda você a resolver?
√ A primeira é reduzir o custo de transformação e adaptação e ajudar todos a se concentrarem mais na lógica de lançamento do modelo;
√ A segunda é eliminar a arquitetura de armazenamento dedicada. Por exemplo, sistemas como NAS e NFS devem ser usados no passado. Depois de usar o Alluxio, não é mais necessário. O Alluxio pode ser construído com o HDFS existente e o armazenamento de objetos abaixo. Plataforma de IA;
√ A terceira é que precisamos adicionar um cache para aumentar a utilização da GPU a um nível superior;
√ A quarta é atender às necessidades da empresa de implantação gratuita de GPUs. Seja uma GPU comprada na nuvem ou fora da nuvem, não importa onde os dados estejam, ela pode conseguir uma adaptação de dados muito eficiente. Um caso específico será fornecido mais tarde .
5. Comparação de efeitos: antes de usar Alluxio VS depois de usar Alluxio
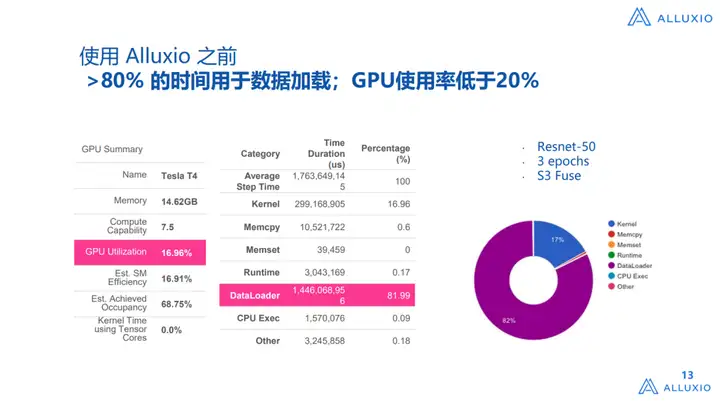
Esses são os dados que extraímos do painel tensor. Acredito que muitos engenheiros que fazem AI Infra usarão esse sistema. Descobrimos que na verdade há um problema relativamente grande na nuvem. Por exemplo, se usarmos o S3 Fuse, podemos extraí-lo diretamente do S3 Fuse. Este é um uso comum nos últimos anos. Por exemplo, se houver um disco local, os dados podem ser recuperados. Para treinamento do modelo, execute uma tarefa de cópia e coloque-os localmente ou use uma exposição semelhante à interface Fuse para extrair os dados localmente e, em seguida, fornecer serviços para cima. Se este método for usado , a proporção do DataLoader é muito alta Sim, se você tiver um bom entendimento da arquitetura de IA, o DataLoader dele faz assim: ele puxa os dados do sistema de armazenamento para a memória da CPU, a CPU realiza o pré-processamento ou reprocessamento , e então coloca os dados na memória da CPU e então a GPU os processa. , os dois últimos são bons na nuvem, porque geralmente a proporção de CPU para GPU é relativamente razoável, e a proporção de memória também é relativamente razoável, então o problema será relativamente pequeno, mas com base no fato de que está originalmente no armazenamento em nuvem, existem O problema de puxar para a CPU leva a um desempenho muito ruim no primeiro estágio do DataLoader. Embora seja um processo assíncrono, o desempenho precisa esperar a conclusão da etapa anterior, pois você pode ver que a proporção do DataLoader pode representar 80%% a mais, o uso da GPU é de apenas cerca de 17%, que é medido com Resnt-50, um benchmark muito padrão.
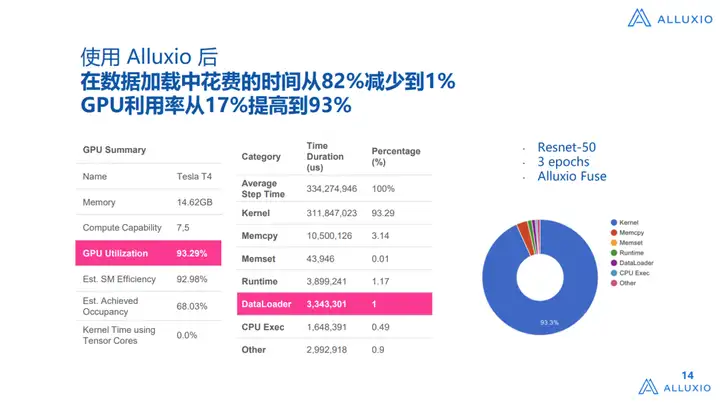
Após implantarmos o Alluxio, o tempo do DataLoader caiu para menos de 1% e a taxa de utilização da GPU aumentou para 93%.Claro, isso não significa que não possa ser maior, mas na verdade, a taxa de utilização da GPU é limitado por IO, por um lado, e por outro lado, também é limitado pelo desempenho da CPU, portanto esta é uma taxa de utilização muito alta.

Além disso, lançamos recentemente alguns projetos no cenário de IA, incluindo o "Plano de Treinamento de Modelo Assistido Alluxio", na verdade, muitos modelos grandes já estão rodando no Alluxio, usando Alluxio como camada de acesso a dados de alto desempenho. Durante o período de 1º de julho a 30 de setembro de 2023, um plano de inscrição também estará aberto a todos.Você pode ter 3 meses de suporte técnico 1V1 da equipe profissional para ajudá-lo a construir um treinamento de modelo em grande escala ou um treinamento em modo dinâmico mais popular. Cenas.
Sobre o autor

Se você quiser saber mais sobre os artigos áridos, eventos populares e compartilhamento de especialistas do Alluxio, clique para entrar no [Alluxio Think Tank] :
