Compreensão visual de redes neurais convolucionais
Visualizando e compreendendo redes convolucionais
Compreensão visual de redes neurais convolucionais
Zeiler, MD, Fergus, R. (2014). Visualizando e compreendendo redes convolucionais. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds) Computer Vision – ECCV 2014. ECCV 2014. Lecture Notes in Computer Science, vol 8689. Springer, Cham. https://doi.org/10.1007/978-3-319-10590-1_53
método
Usando uma rede neural convolucional totalmente supervisionada padrão, através de uma série de camadas, a imagem de entrada é mapeada para o vetor de características da classe de saída.
estrutura da camada:
- A saída da camada anterior é convolvida com uma série de núcleos de convolução que podem ser aprendidos
- Através de uma função de ativação não linear (relu)
- [Opcional] Pool gigante local
- [Opcional] Normalização entre mapas de recursos
Configuração experimental:
- Conjunto de dados: ${x, y}$, y é uma variável discreta com rótulos de classe
- Função de perda de entropia cruzada para comparar a saída da rede com rótulos de verdade
- Os parâmetros de rede (kernel de convolução, deslocamento de peso da camada FC) são treinados por meio de retropropagação de perda e atualizados por meio do método de gradiente descendente
Visualização com desconvolução
- Para compreender o funcionamento de uma rede neural convolucional, é necessário compreender a atividade característica das camadas intermediárias.
- Ao realimentar essas atividades no espaço de pixels de entrada, mostramos que os padrões de entrada causam ativações específicas em mapas de características.
- Redes Deconvolucionais (para aprendizagem não supervisionada). Neste artigo, a desconvolução não tem a capacidade de aprender, mas serve como uma sonda para a rede treinada.
O processo, conforme mostrado na figura abaixo:
- A imagem de entrada é passada para a rede neural convolucional para calcular os recursos
- Para examinar uma determinada ativação de convnet, defina todas as outras ativações na camada como zero e passe o mapa de recursos como entrada para uma camada de desconvolução adicional
- A refatoração subjacente causa a seleção da atividade para uma determinada ativação por meio de (i) operações de unpool, (ii) retificação e (iii) filtragem.
- Repita a operação da etapa anterior até que o espaço de pixels de entrada seja alcançado.
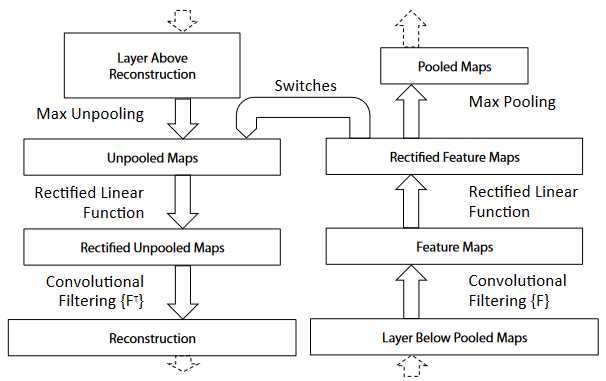
- Unpooling: Anti-pooling. A operação de pooling máximo na rede neural convolucional é irreversível. O inverso aproximado da operação de pooling é obtido registrando-se a posição do valor máximo na região pooled. Como mostrado abaixo:
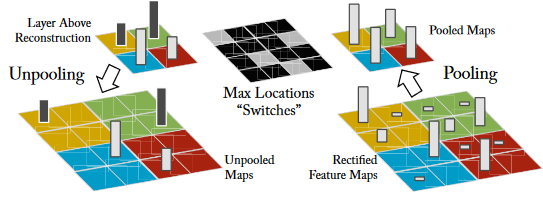
- Retificação: Correção. As redes neurais convolucionais usam a função de não linearidade relu para garantir que os mapas de recursos sejam sempre positivos. Para obter uma reconstrução eficiente de características em cada camada, uma não-linearidade relu também é usada para passar o sinal de reconstrução.
- Filtragem: filtro (kernel de convolução). O kernel de convolução executa a convolução no mapa de recursos da camada anterior. Para inverter esse processo, a deconvolução utiliza a transposição do mesmo kernel para o mapa de correção.
- Além disso, nenhuma operação de normalização é utilizada em todo o processo de reconstrução.
estrutura de rede
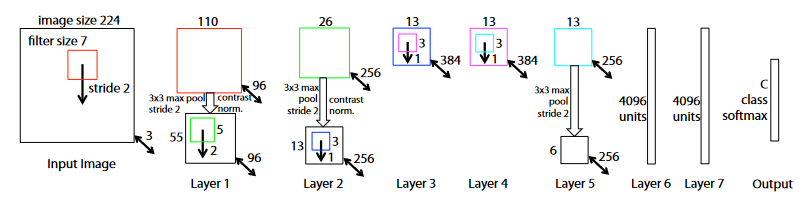
- Entrada 224x224 para operação de convolução
- Camada 1-5:
- função de ativação relu
- Pooling máximo de 3x3 com passada de 2
- operação de normalização
- operação de convolução
- Duas camadas totalmente conectadas
Visualização de Rede Neural Convolucional
visualização de recursos
- Camada 1: Hierarquia de recursos na rede
- A segunda camada: cor, informações de borda
- A terceira camada: invariância mais complexa, captura de textura semelhante, informações de texto
- A quarta camada: mudanças significativas, mais específicas da categoria
- Quinta camada: todo o objeto

Evolução de recursos durante o treinamento
O processo de treinamento para a ativação mais forte (em todas as instâncias de treinamento) retroprojetado no espaço de pixel de entrada em um determinado mapa de recursos
- Recursos de baixo nível podem convergir nas primeiras épocas
- Recursos de alto nível requerem algumas épocas para convergir

escolha de arquitetura
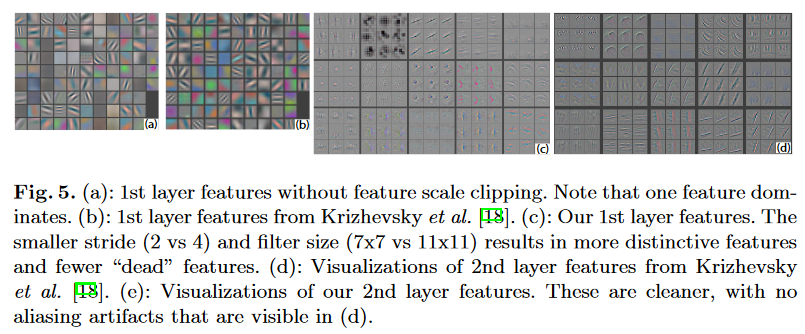
11x11, kernel de convolução stride 4 aparece artefatos de alias. -> 7x7, tamanho do passo 2
Experimento de oclusão
Se o modelo realmente reconhece a posição do objeto na imagem
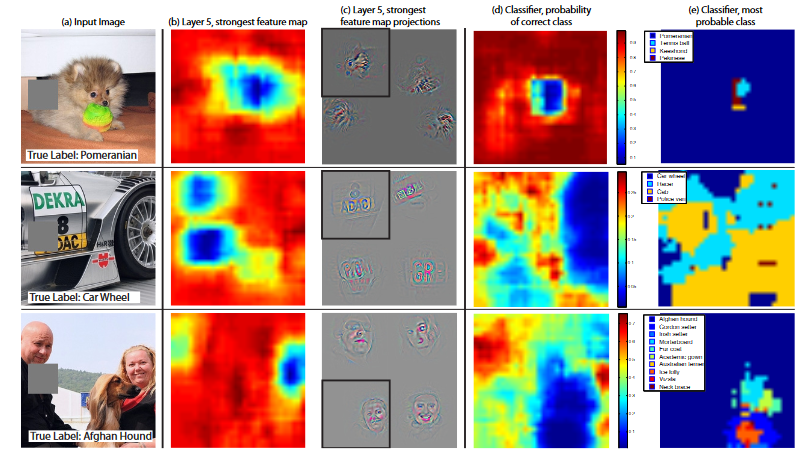
experimentar
1. ImageNet
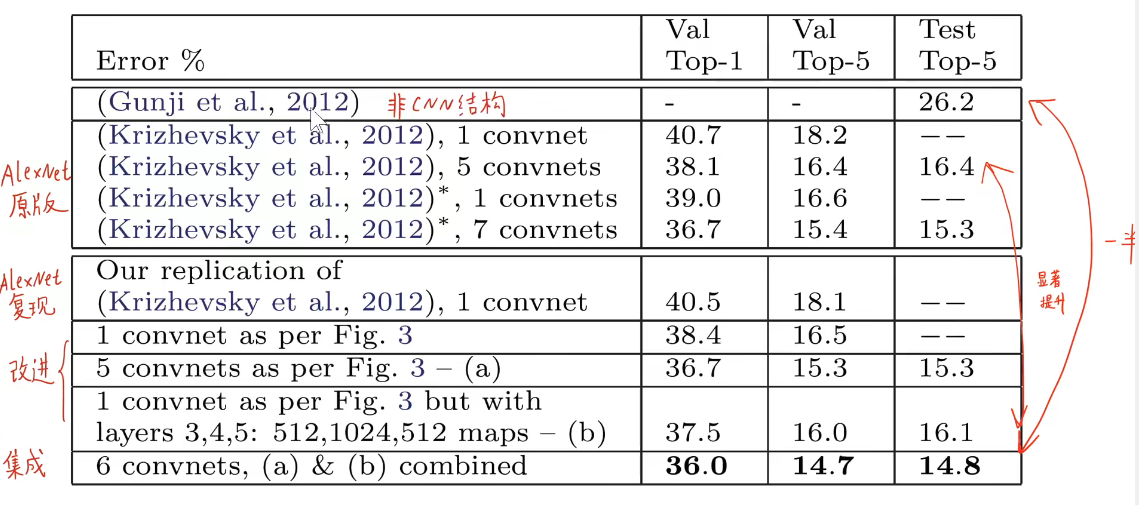
2. Remova algumas camadas
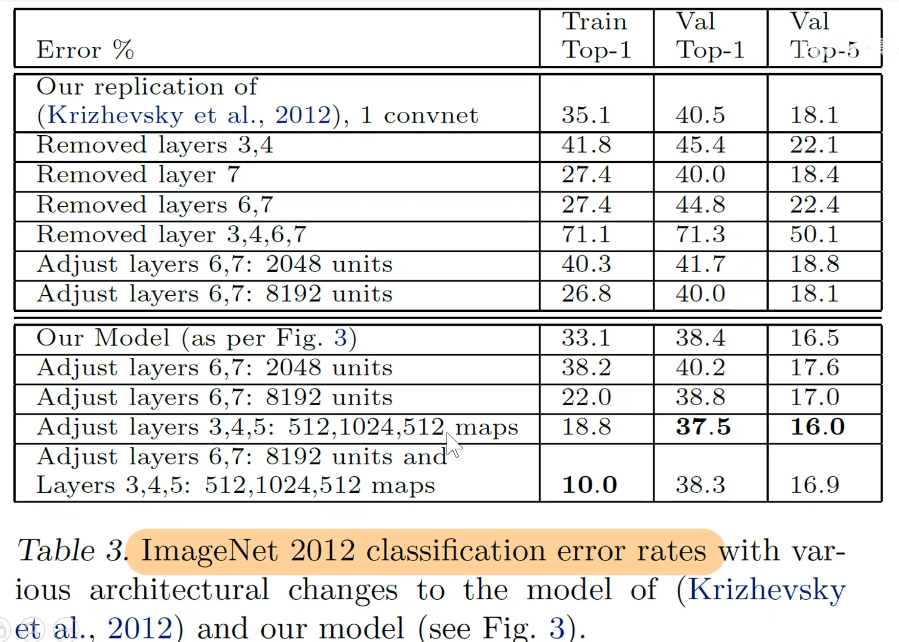
3. Generalização do modelo (aprendizado por transferência)
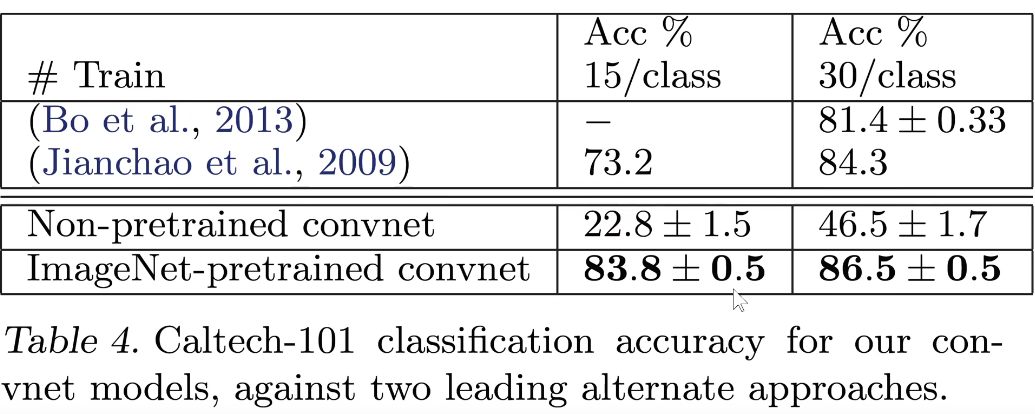
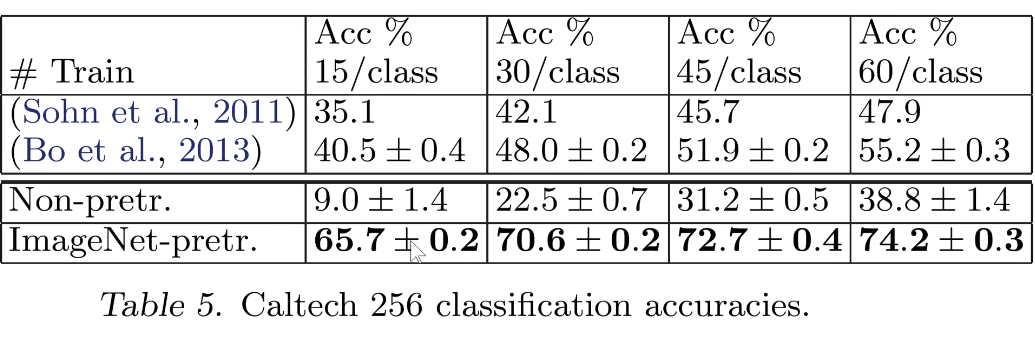
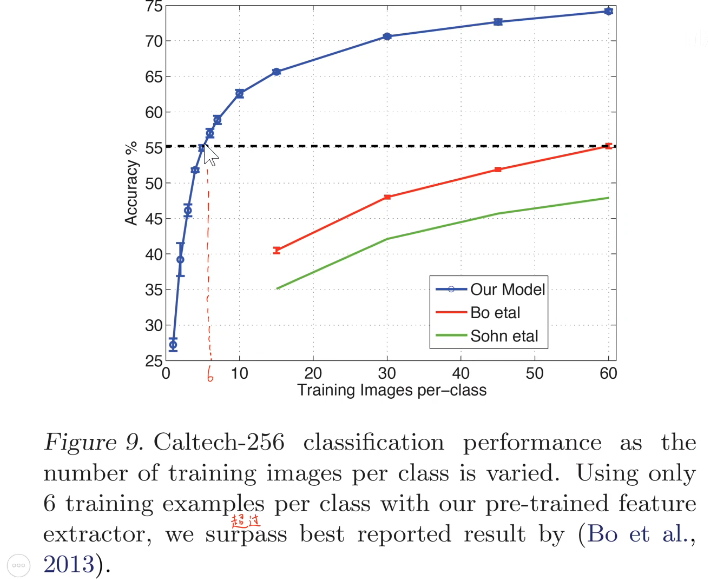
- Uma pequena quantidade de dados pode alcançar um bom desempenho
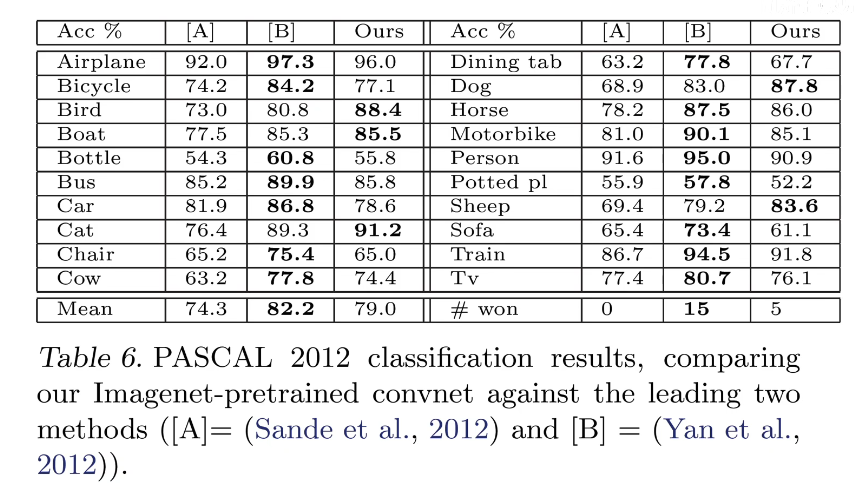
- O procedimento acima não funciona quando os conjuntos de dados têm diferenças
4. Se os recursos das diferentes camadas da rede são eficazes para classificação
- Substitua a camada softmax por SVM
