Descrição: VITS2: Melhorando a qualidade e a eficiência da conversão de texto em fala de estágio único com aprendizagem adversária e design de arquitetura
Demonstração: https://vits-2.github.io/demo/
Artigo: https://arxiv.org/abs/2307.16430


Problemas que ainda existem:
-
antinaturalidade intermitente
-
baixa eficiência do preditor de duração
-
formato de entrada complexo para aliviar as limitações de modelagem de alinhamento e duração (uso de token em branco)
-
semelhança de alto-falante insuficiente no modelo de vários alto-falantes
-
treinamento lento e forte dependência da conversão fonêmica.
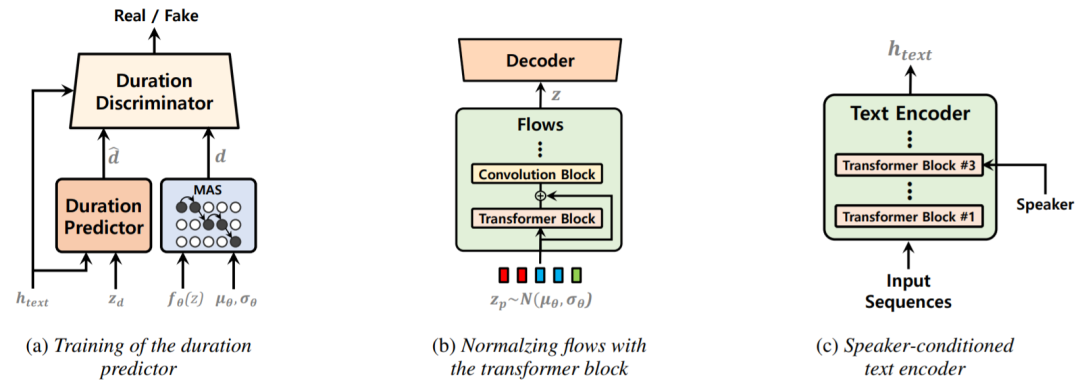
Método proposto:
-
um preditor de duração estocástico treinado por meio de aprendizagem contraditória
-
fluxos de normalização aprimorados ao utilizar o bloco do transformador
-
um codificador de texto condicionado por alto-falante para modelar melhor as características de vários alto-falantes.