linguagem natural
tarefa de classificação
Categorização de texto
1. tochaTexto
2. Redes Neurais Feed-Forward
O FFN atinge alta precisão em muitas tarefas de TC (classificação de texto). Ele trata o texto como um saco de palavras. Cada palavra é expressa como um vetor de palavras com um modelo de incorporação como word2vec ou Glove e, em seguida, o vetor de palavras é somado ou calculado para representar o texto e, em seguida, passado por uma ou mais camadas de redes neurais de feedforward (por exemplo: MLPs), e então um classificador é usado (Exemplo: Regressão Logística, Naive Bayes ou SVM) para classificar a representação da última camada.
3. Modelos baseados em RNN (modelo baseado em rede neural cíclica)
Os modelos baseados em RNN tratam o texto como uma sequência de palavras e visam capturar dependências de palavras e estrutura de texto para TC. No entanto, o desempenho do modelo RNN tradicional não é bom e não é tão bom quanto o da rede feedforward, por isso surgiram muitas variantes. Entre eles, o LSTM é o mais popular, visando capturar melhor as dependências de longo prazo.
O LSTM lembra o valor de qualquer intervalo de tempo introduzindo uma unidade de memória e controla a entrada, saída e esquecimento através de três portas.
A árvore Tree-LSTM é melhor do que a LSTM encadeada. O autor acredita que a linguagem natural combina palavras em frases para expressar informações semânticas, de modo que a Tree-LSTM pode capturar representações semânticas mais ricas.
A fim de simular a relação de palavras de longo alcance da leitura de máquina, a rede de memória é usada em vez de uma única unidade de memória para aprimorar a arquitetura LSTM
Multi-Timescale LSTM (MT-LSTM) é usado para capturar dependências de longa distância, e o estados ocultos no LSTM são divididos em vários grupos, cada Grupos são ativados e atualizados em diferentes prazos. MT-LSTM supera as linhas de base em TC (incluindo modelos baseados em RNN e LSTM)
TopicRNN, que integra as vantagens dos modelos BNN e de tópicos latentes. Ele usa RNNs para capturar dependências locais e tópicos latentes para capturar dependências globais.
4. Modelos baseados em CNN (modelo baseado em CNN)
Os modelos RNN mencionados acima são treinados para reconhecer padrões ao longo do tempo, enquanto as CNNs aprendem a reconhecer padrões no espaço. Os RNNs são adequados para tarefas de NLP que exigem compreensão de semântica de longo alcance, como marcação de PDV ou controle de qualidade. Enquanto o CNN é mais adequado para detecção local e modo invariante de posição. Na CNN, os vetores de palavras pré-treinados são melhores do que a inicialização aleatória e o maxpooling é melhor do que outros agrupamentos.
DCNN (Dynamic CNN) usa agrupamento k-max dinâmico, que pode selecionar dinamicamente k de acordo com o tamanho da frase e o nível de convolução.
O VDCNN opera no nível de caractere e usa apenas pequenas operações de agrupamento de kernel de convolução. Seu desempenho melhora com a profundidade
5.Redes Neurais da Cápsula (rede da cápsula)
A CNN conseguiu classificar textos e imagens por meio de operações de convolução e agrupamento.Por que precisamos propor uma rede cápsula? A principal razão é que o modelo CNN perde a correlação espacial das informações, ou seja, a posição não está correta, mas também pode ser reconhecida corretamente. Por exemplo, quando as características faciais da pessoa na foto não estão corretas posição, a CNN também pode reconhecer o rosto. (Pot of pooling operation)
Uma rede cápsula é um grupo de neurônios cujos vetores de atividade representam diferentes atributos de uma determinada classe de entidades, o comprimento do vetor representa a possibilidade da existência da entidade e a direção do vetor representa a atributo da entidade.
Ao contrário do pooling máximo que seleciona algumas informações e descarta outras informações, a rede cápsula terá um planejamento de caminho da cápsula inferior até a cápsula de alto nível, procurando a melhor cápsula de alto nível como pai da cápsula de baixo nível.
6. Modelo de TC baseado em uma variante de CapsNets
7. Modelo baseado em CapsNet
8. Modelos com mecanismo de atenção (modelo de mecanismo de atenção)
9. rede de atenção hierárquica rede de atenção em camadas
O modelo tem duas características notáveis: 1. É uma estrutura hierárquica para refletir a estrutura hierárquica dos documentos. 2. Um mecanismo de atenção de dois níveis é aplicado nos níveis de palavra e frase, permitindo que ele se concentre em conteúdo importante e sem importância de maneiras diferentes ao construir representações de documentos.
Aplicado à classificação de sentimento cross-lingual, em cada idioma, uma rede LSTM é usada para modelar documentos e, em seguida, um mecanismo de atenção hierárquico é usado para obter a classificação. O modelo de atenção no nível da frase aprende qual frase no documento é mais importante para julgar o sentimento. O modelo de atenção em nível de palavra aprende qual frase na frase é mais decisiva.
10. rede de auto-atenção direcional para compreensão de linguagem livre de RNN/CNN
Apenas baseado no mecanismo de atenção sem qualquer estrutura RNN/CNN.
11. Modelo LSTM com atenção interna para NLI (raciocínio em linguagem natural)
Este modelo codifica uma frase para o usuário em um processo de dois estágios. Primeiro, o pooling médio é usado com base em Bi-LSTMs de nível de palavra para gerar representações de sentença no primeiro estágio e, em seguida, os mecanismos de atenção são usados em vez do pooling médio para obter melhores representações na mesma frase.
Pense na tarefa TC como uma tarefa de correspondência de rótulo e palavra, e cada rótulo e vetor de palavra são incorporados da mesma maneira.
12. Redes com Memória Aumentada
O estado oculto do mecanismo de atenção mencionado anteriormente no processo de codificação pode ser considerado como a memória interna do modelo, e a rede de aprimoramento de memória pode combinar a rede neural com uma memória externa, e o modelo pode ser lido e gravado no externo memória.
Neural Semantic Encoder (NSE) é aplicado a tarefas de TC e QA, que possui memória de codificação de tamanho variável, evolui ao longo do tempo e pode garantir o entendimento da sequência de entrada por meio de operações de leitura e gravação.
A Rede de Memória Dinâmica (DMN) forma a memória episódica processando sequências de entrada e perguntas para gerar respostas relevantes. Melhor progresso foi feito em QA e conveniência de PDV.
13. Gráfico de redes neurais
O primeiro modelo baseado em gráfico do TextRank. Os nós representam vários tipos de texto, como palavras, colocações, frases, etc. As arestas são usadas para representar diferentes tipos de relacionamentos entre os nós, como relacionamentos lexicais, semânticos, sobreposição contextual, etc.
Abordagens de aprendizado profundo de redes neurais gráficas (GNNs) estendendo os dados do gráfico
Graph Convolutional Networks (GCNs) é uma variante da CNN no gráfico, que pode ser combinada com outras redes neurais de forma mais eficaz e conveniente
graph-CNN, primeiro converte o texto em um gráfico de palavras e, em seguida, usa uma operação de convolução de gráficos para convoluir o gráfico de palavras. Usar gráficos de palavras para representar texto é mais capaz de capturar semântica descontínua e de longa distância.
É demorado construir um GNN para um grande conjunto de texto, e existem alguns estudos para reduzir a complexidade do modelo ou mudar a estratégia de treinamento. O modelo que reduz a complexidade é o Simple Graph Convolution (SGC), que remove a operação não linear da camada adjacente da convolução GNN e reduz a matriz de pesos a uma transformação linear. É conveniente mudar a estratégia de treinamento.O modelo possui GNN em nível de texto, que divide o texto em diferentes blocos com uma janela deslizante e, em seguida, faz gráficos desses blocos para reduzir o consumo de memória.
14. Redes Neurais Siamesas (S2Nets)
S2Nets, também chamados de Deep Structured Semantic Models (DSSMs), são usados para correspondência de texto. Muitas tarefas de PNL, como classificação de texto de perguntas, seleção de respostas de perguntas e respostas extrativas, etc., podem ser consideradas casos especiais de TC.
Conforme mostrado na Figura 12, S2nets contém um par de DNNs, f1 e f2, respectivamente, mapeiam x e y para o mesmo espaço semântico de baixa latitude e, em seguida, usam cosseno para calcular a similaridade de x e y. f1f2 pode ser a mesma estrutura ou estruturas diferentes. f1 e f2 podem escolher diferentes estruturas de acordo com x, y. Por exemplo, para calcular a similaridade do gráfico, f1 pode ser uma rede neural convolucional profunda e f2 pode ser uma rede neural recorrente ou um perceptron multicamada. Portanto, esse modelo pode ser amplamente aplicado a tarefas de PNL.
15. Modelos híbridos modelo híbrido
Muitos modelos híbridos combinam LSTM e CNN para obter características locais ou globais de sentenças e documentos.
A rede LSTM convolucional (C-LSTM) utiliza CNN para obter representação de frase de alto nível, que é então alimentada à rede LSTM para obter representação de frase.
Dependency Sensitive CNN (DSCNN), usado principalmente para modelos de documentos, é um modelo hierárquico. O LSTM aprende vetores de sentenças e, em seguida, os alimenta em camadas convolucionais e camadas de agrupamento máximo para gerar representações de documentos. A abordagem Hierarchical Deep Learning para classificação de texto (HDLTex) é
usado para classificação de texto
Stochastic Answer Network (SAN) para compreensão de leitura de máquina
16. Transformadores e modelos de linguagem pré-treinados modelo de linguagem pré-treinado
O Transformer usa um mecanismo de auto-atenção para resolver o problema de dependência de longa distância e também pode executar computação paralela, o que torna possível treinar grandes modelos e processar grandes dados em GPUs.
Classificação de modelos pré-treinados (de acordo com o tipo de representação, arquitetura do modelo, tarefas de pré-treinamento, tarefas a jusante)
PLMs autorregressivos e autoencoding.
- Modelo de pré-treinamento autorregressivo: OpenGPT O
OpenGPT é um modelo unidirecional que prevê sequências de texto palavra por palavra da esquerda para a direita (ou da direita para a esquerda), e a previsão de cada palavra depende da palavra anterior. A estrutura do OpenGPT é a seguinte:
Contém 12 camadas de blocos Transformer, cada camada contém um módulo de atenção de várias cabeças mascarado. Cada camada é seguida por uma normalização de camada e uma camada de alimentação de posição.
O OpenGPT pode ser adaptado para tarefas downstream, como TC, adicionando classificadores lineares específicos e rótulos de ajuste fino.
- Autocodificação: o BERT é
diferente do OPenGPT na previsão da palavra atual por meio de previsões anteriores. O BERT usa a tarefa MLM para treinamento. A tarefa é mascarar aleatoriamente alguns tokens na sequência de texto e, em seguida, restaurar independentemente o mascarado ajustando o vetor de codificação obtido pelo transformador bidirecional. o token.
Melhorias do BERT:
(1) RoBERTa é mais poderoso que o BERT e pode usar mais dados de treinamento para treinamento.
(2) ALBERT reduz o consumo de memória e melhora a velocidade de treinamento do BERT
(3) DistillBERT reduz o tamanho do BERT para 40% usando destilação de conhecimento durante o pré-treinamento, retém 99% das funções originais do BERT e 60% mais rápido .
(4) O SpanBERT estende o BERT para melhor representar e prever extensões de texto.
(5) Electra usa uma tarefa de pré-treinamento mais simples e eficaz do que MLM - detecção de token eplaced, que não é uma entrada de máscara, mas extrai algumas alternativas razoáveis de uma rede de pequena geração para substituir alguns tokens (6) ERNIE combina de The
knowledge da base de conhecimento externa, como reconhecimento corporal nomeado, é pré-treinado.
(7) ALUM introduz perda contraditória, o que melhora a capacidade de generalização e robustez do modelo para novas tarefas
Um modelo de linguagem pré-treinado combinando autorregressivo e autoencoder:
XLNet
Unified language Model (UniLM)
Além da Aprendizagem Supervisionada
Aprendizagem Não Supervisionada usando Autoencoders.
Treinamento adversário
O treinamento adversário é um desses métodos de regularização usado para melhorar os generalizadores de classificação.
Aprendizagem por Reforço
sistema de resposta a perguntas
BigBird: Transformer para sequências mais longas
O BigBird opera em um mecanismo de atenção esparsa, permitindo superar as dependências quadráticas do BERT enquanto mantém as propriedades de um modelo de atenção total. Os pesquisadores também fornecem exemplos de como os modelos de rede baseados no BigBird superam os níveis de desempenho de modelos anteriores de processamento de linguagem natural e tarefas genômicas.
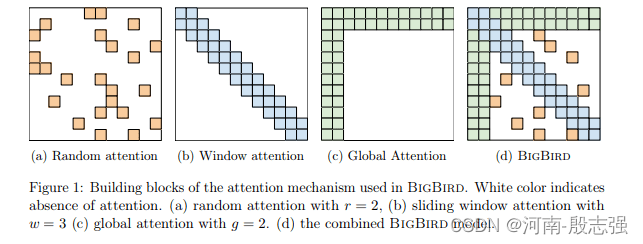
Antes de começarmos a discutir as possíveis aplicações do BigBird, vejamos os principais destaques do BigBird. Principais destaques do BigBird Aqui estão alguns recursos do BigBird que o tornam melhor do que os modelos anteriores baseados em Transformer. Mecanismo de atenção esparsa O BigBird usa um mecanismo de atenção esparsa que permite lidar com sequências 8 vezes mais longas do que o possível com o BERT. Lembre-se de que esse resultado pode ser obtido usando a mesma configuração de hardware do BERT. No artigo do BigBird, os pesquisadores mostraram como o mecanismo de atenção esparsa usado no BigBird é tão poderoso quanto o mecanismo de autoatenção total (usado no BERT). Entre outras coisas, eles mostram "como codificadores esparsos são Turing completos". Simplificando, o BigBird usa atenção esparsa, o que significa que a atenção é aplicada token por token, em vez de BERT, onde a atenção é aplicada apenas uma vez a toda a entrada! Pode lidar com sequências de entrada até 8 vezes mais longas Uma das principais características do BigBird é sua capacidade de lidar com sequências até 8 vezes mais longas do que antes. A equipe de pesquisa projetou o BigBird para atender a todos os requisitos de um Transformer completo como o BERT. Usando o BigBird e seu mecanismo de atenção esparsa, a equipe de pesquisa reduziu a complexidade do BERT para O (n 2) O(n^2)O ( n2 )ChegadaO(n) O(n)O ( n ) . Isso significa que uma sequência de entrada originalmente limitada a 512 tokens pode agora ser aumentada para 4096 tokens (8*512). Philip Pham, um dos pesquisadores do BigBird, declarou em uma discussão do Hacker News: "Na maioria de nossos artigos, usamos 4096, mas podemos usar mais de 16K." Pré-treinamento para grandes conjuntos de dados
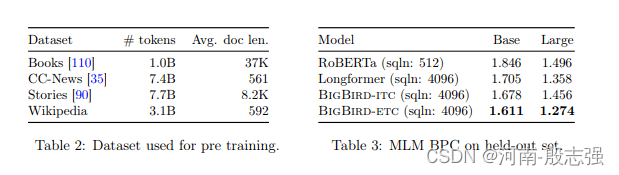
Os pesquisadores do Google usaram 4 conjuntos de dados diferentes no pré-treinamento do BigBird: Natural Questions, Trivia-QA, HotpotQA-ditractor, WikiHop. Embora o conjunto de pré-treinamento do BigBird seja muito menor do que o GPT-3 (175 bilhões de parâmetros para treinamento), a Tabela 3 no trabalho de pesquisa mostra que ele tem um desempenho melhor do que o RoBERTa e o Longformer. O RoBERTa é um método de pré-treinamento BERT robusto e otimizado, e o Longformer é um modelo semelhante ao BERT para documentos longos. Quando um usuário pediu a Philip Pham para comparar o GPT-3 com o BigBird, ele disse: "O GPT-3 usa apenas um comprimento de sequência de 2048. BigBird é apenas um mecanismo de atenção que pode realmente ser complementar ao GPT-3."
tarefa de tradução
1. seq2seq (pode resolver problemas de entrada e saída com comprimentos diferentes), sua busca de feixe é 2, após vários processos end, pode produzir as duas sequências com a maior probabilidade.
Conforme mostrado na figura abaixo, após termos o método de busca de feixe no processo do decodificador, na primeira saída, selecionamos as duas palavras "I" e "am" com maior probabilidade ao invés de selecionar apenas a palavra com maior probabilidade .
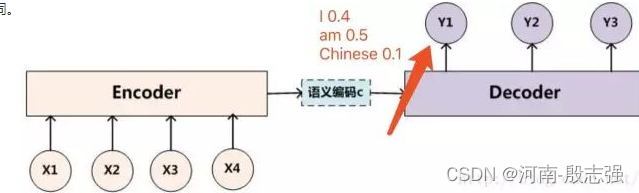
Então, o que temos que fazer a seguir é contar a palavra "I" como a entrada do próximo decodificador para obter a distribuição de probabilidade de saída de y2 e calcular a palavra "am" como a entrada do próximo decodificador para obter a saída distribuição de probabilidade de y2. Por exemplo, a palavra "I" é usada como entrada do próximo decodificador para calcular a distribuição de probabilidade de saída de y2 da seguinte forma:
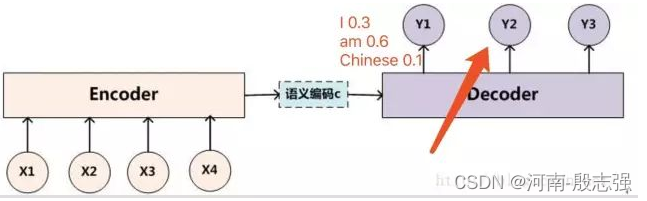
Por exemplo, a palavra "am" é usada como entrada do próximo decodificador para calcular a distribuição de probabilidade de saída de y2 da seguinte forma:
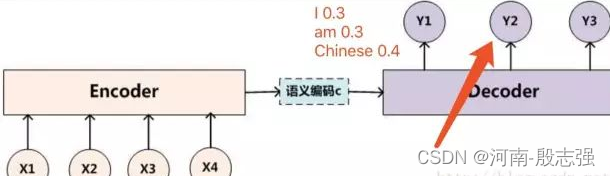
Então, neste momento, como nosso tamanho de feixe é 2, ou seja, podemos manter apenas as duas sequências com maior probabilidade, neste momento podemos calcular todas as probabilidades de sequência: "II" = 0,4 0,3 "I am" = 0,3 0,6 "I am" Chinese" = 0,4 0,1 "am I" = 0,5 0,3 "am am" = 0,5 0,3 "am Chinese" = 0,5 0,4 Podemos facilmente concluir que as duas sequências mais prováveis são "I am" e "am Chinese" , e então Este processo será repetido até que o terminador seja encontrado. Finalmente, imprima as 2 sequências de pontuação mais altas. Este é o processo do algoritmo de busca de feixe em seq2seq, mas alguns alunos podem ter uma pergunta, ou seja, quando as palavras selecionadas no momento i-1 são diferentes, por que a distribuição de probabilidade de saída muda no momento seguinte? Isso ocorre porque durante o processo de decodificação, a entrada do modelo no i-ésimo momento inclui a saída do modelo no i-1º momento, então, naturalmente, quando a saída do modelo no i-1º momento é diferente, é causará o modelo no próximo momento A distribuição de probabilidade de saída será diferente. Porque a saída no momento i-1 é usada como parâmetro para afetar o aprendizado do modelo no momento seguinte.
2.
mapa do conhecimento
O nível atual de desenvolvimento do gráfico de conhecimento: reconhecimento de entidade nomeada, extração de relacionamento, raciocínio em linguagem natural, similaridade semântica de texto, extração de evento, entidade conjunta e extração de relacionamento.
reconhecimento de entidade nomeada
aprendizado de estrutura mect
https://paperswithcode.com/paper/mect-multi-metadata-embedding-based-cross
localizar e rotular
O conteúdo específico do papel
O reconhecimento de entidades nomeadas é um foco de pesquisa no processamento de linguagem natural. A pesquisa NER tradicional lida apenas com entidades planas e ignora entidades aninhadas. Abordagens baseadas em span tratam o reconhecimento de entidade como uma tarefa de classificação de span. Embora esses métodos tenham a capacidade inata de lidar com o NER aninhado, existem problemas como alto custo computacional, ignorar informações de limite, não fazer uso total de partes de entidades correspondentes a spans e dificuldade no reconhecimento de entidades longas. Para resolver esses problemas, propomos um identificador de entidade de dois estágios. Os vãos iniciais são primeiro filtrados e os limites regredidos para gerar propostas de vão, as localizações das entidades são determinadas e, em seguida, as propostas de vão ajustados por limites são classificadas. O método utiliza efetivamente as informações de limite das entidades e o intervalo de correspondências parciais durante o treinamento. Por meio da regressão de limite, entidades de qualquer tamanho podem ser cobertas em teoria, o que melhora a capacidade de reconhecimento de entidades longas. Além disso, muitos spans de sementes de baixa qualidade são filtrados no primeiro estágio, reduzindo a complexidade de tempo da inferência. Os conjuntos de dados NER experimentais aninhados demonstram que nosso método proposto supera os modelos anteriores de última geração.
https://github.com/PaddlePaddle/ERNIE
extração de relação
https://paperswithcode.com/task/relation-extraction/latest
raciocínio em linguagem natural
https://paperswithcode.com/task/natural-language-inference/latest
semelhança semântica de texto
https://paperswithcode.com/task/semantic-textual-similarity
Extração de Informações - Extração de Eventos
https://paperswithcode.com/task/event-extraction/latest
Extração de Informações - Extração de Entidade Conjunta e Relacionamento
https://paperswithcode.com/task/joint-entity-and-relation-extraction/latest