introdução de fundo
O WebRTC é atualmente a estrutura de código aberto mais popular no campo de áudio e vídeo em tempo real. Depois que o Google adquiriu o mecanismo GIPS em 2010, ele foi incorporado ao sistema Chrome e de código aberto, denominado "WebRTC". O WebRTC é suportado pelos principais fabricantes de navegadores e incorporado aos padrões W3C, que promove a popularização de áudio e vídeo em tempo real em aplicativos de Internet móvel. Em janeiro de 2021, W3C e IETF, duas grandes organizações de definição de padrões, anunciaram que o WebRTC se tornou um padrão oficial. Os usuários não precisam baixar componentes adicionais ou aplicativos separados para oferecer suporte à comunicação de áudio e vídeo em tempo real na rede. Embora o WebRTC tenha as características de código aberto e gratuito, ele é enorme, complicado, tem um alto limiar de aprendizado e carece de design e implantação de soluções de servidor, deixando espaço para o desenvolvimento de soluções comerciais baseadas no WebRTC. Fornecedores terceirizados de RTC PaaS tornaram-se a primeira escolha dos desenvolvedores devido ao seu efeito de escala e vantagens técnicas, empurrando a indústria de áudio e vídeo em tempo real para a via rápida do desenvolvimento.
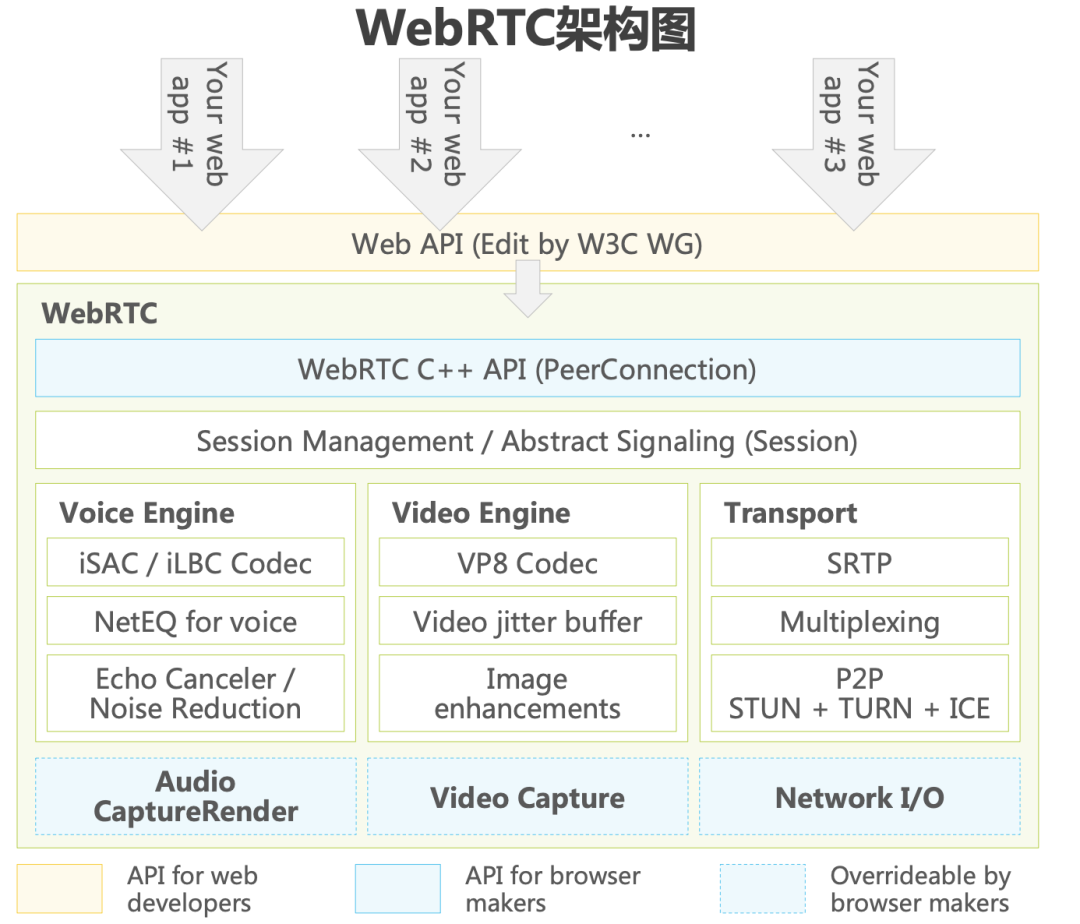
Este artigo se concentrará na arquitetura do mecanismo de áudio do webrtc, analisará os principais pontos técnicos por trás dele que afetam a qualidade do som e apresentará as considerações de seleção sob as soluções técnicas diferenciadas por trás dos diferentes cenários de negócios dos principais fabricantes de RTC do setor e revelará o cenário de link completo A melhor solução de melhoria de qualidade de som em .
1. Introdução à arquitetura de áudio webrtc
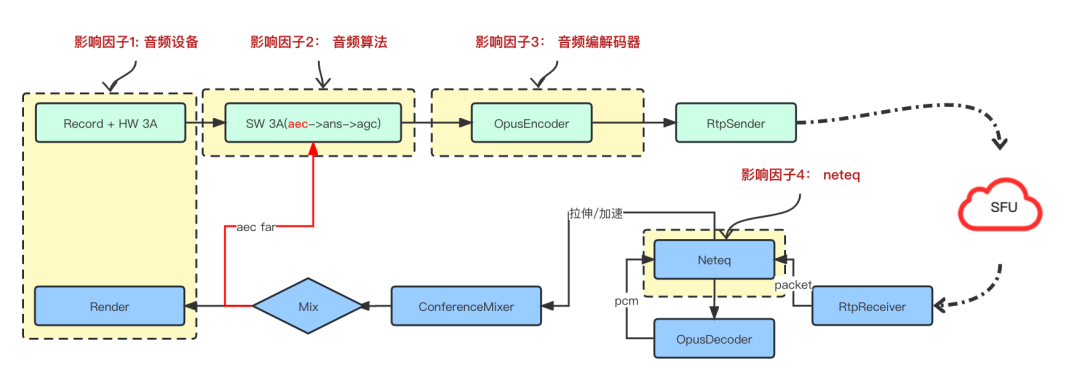
A arquitetura de áudio de todo o RTC é mostrada na figura acima:
Uplink: Após o sinal de áudio ser coletado e chamado de volta pelo dispositivo, ele será processado pelo software 3A (cancelamento de eco acústico (aec), supressão automática de ruído (ANS), controle automático de ganho (AGC)) e, em seguida, codificado pelo codificador de áudio. Faça o empacotamento RTP e envie para o SFU; o final do envio é conduzido pelo thread de aquisição. Depois que o dispositivo de aquisição é iniciado, ele chama de volta os dados de áudio a cada 10 ms. Os dados precisam ser removidos a tempo sem bloquear o thread de aquisição .É um modo push.Geralmente o thread de aquisição e o software 3A estão no processamento do thread de aquisição, para o link de codificação de áudio é um thread assíncrono;
Downlink: Na ponta receptora, devido a fatores como perda de pacote de rede, atraso, jitter e fora de sequência, após receber o pacote RTP de áudio, ele será colocado no neteq para análise e classificação. Após a análise, o áudio o decodificador (Decoder) será chamado para fazer a Decodificação, os dados pcm decodificados, de acordo com diferentes estratégias de julgamento da neteq, realizarão o pós-processamento, como compensação de perda de pacote (PLC) ou reprodução acelerada, e os fluxos de dados de áudio processados de diferentes canais será mixado por um mixer (Mixer) Para reproduzir em um formato adequado para Render, após a Mixagem e antes de enviar para o Render, também será enviado para o módulo 3A AEC do software como um sinal de referência remota para eliminar o eco e evitar o o usuário final de mesmo nível ouça sua própria voz. Diferente do thread de aquisição, o downlink é direcionado pelo thread de renderização (reprodução). Após o thread de renderização ser iniciado, o retorno de chamada de temporização quadro a quadro de 10 ms solicita dados do buffer de reprodução, que é direcionado pelo modo pull.
2. Fatores que afetam a qualidade do som do rtc
De acordo com a descrição da arquitetura de áudio em 1, os fatores de link completo que afetam a experiência de qualidade de som de ponta a ponta do rtc estão concentrados em quatro aspectos, a saber: equipamento de áudio, áudio 3A, codificador de áudio e Neteq.
2.1 Equipamento de áudio
Equipamentos de áudio são a fonte de afetar a qualidade do som, mas equipamentos de áudio em extremidades diferentes têm características e desempenhos diferentes. Portanto, o primeiro passo para melhorar a qualidade do som é entender profundamente as diferenças dos equipamentos de áudio em cada extremidade;
2.1.1 Terminal Android
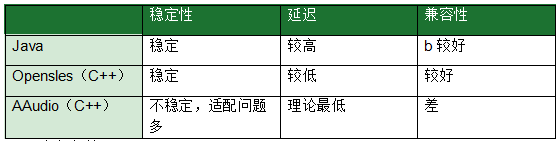
Driver de áudio: o Android fornece diferentes drivers de captura e reprodução de áudio. Os drivers de captura e reprodução de áudio convencionais atuais são os modos AudioRecord e AudioTrack baseados em Java e o driver Opensles baseado em C++; além disso, o Google introduziu uma nova API Android C——AAudio na versão Android O. Informações relacionadas: https:// desenvolvedor .android.com/ndk/guides/audio/aaudio/aaudio, a declaração oficial de que esta API foi projetada para aplicativos de áudio de alto desempenho que requerem baixa latência;
Java: AudioRecord/AudioTrack
Opensles: C++ ——— (baixa latência, mainstream na indústria)
AAudio———Existem muitos problemas, a serem melhorados
Parâmetros de áudio:
Modo de áudio:

Fonte de áudio:
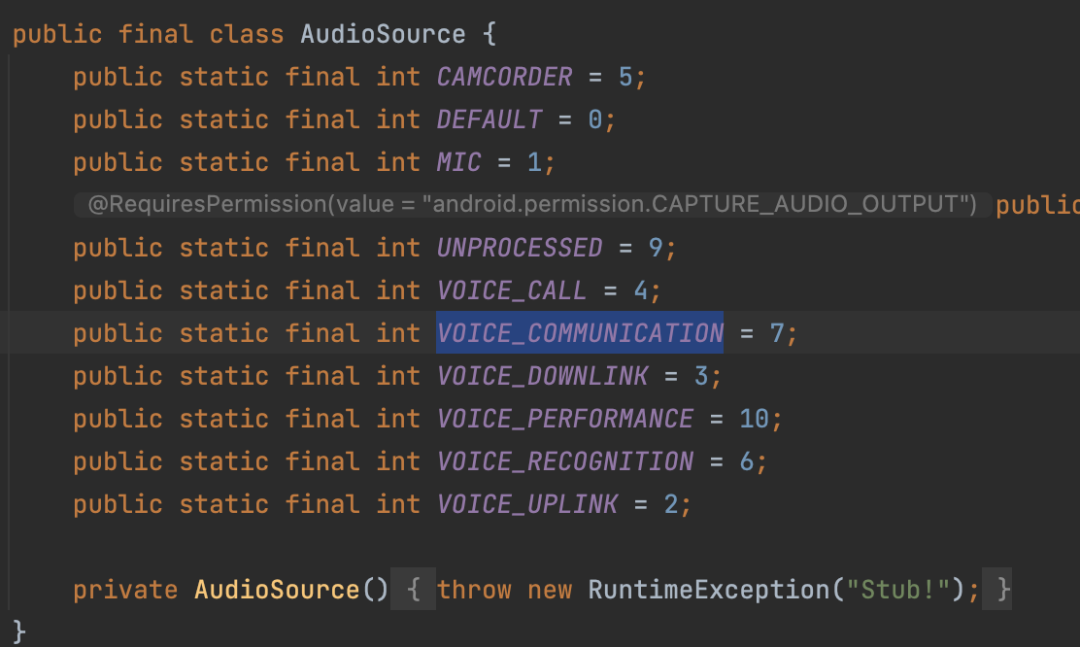
StreamType: afeta a barra de volume

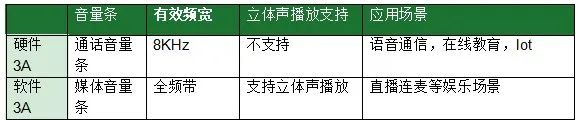
Configurações de parâmetro 3A de hardware e software RTC: AudioMode/AudioSource/StreamType
Seção 3A: audioMode = MODE_IN_COMMUNICATION audioSource = VOICE_COMMUNICATION, streamType = STREAM_VOICE_CALL;
Figura 3A: audioMode = MODE_NORMAL; audioSource = MIC; streamType = STREAM_MUSIC;

A diferença entre o modo 3A de hardware e o modo 3A de software:

Prática comum na indústria: devido à fragmentação do Android, diferentes fabricantes de telefones celulares têm diferentes recursos de suporte para diferentes drivers de áudio e a compatibilidade é bem diferente. Mesmo o modo Java mais comum e o modo Opensles também apresentam problemas de adaptação; portanto, On Do lado do Android, os fabricantes de rtc costumam entregar configurações com base nos parâmetros acima combinados com diferentes modelos de Android para resolver problemas de estabilidade e usabilidade ; conforme mostrado abaixo, é um parâmetro típico de entrega de configuração:
{"audioMode":3,"audioSampleRate":48000,"audioSource":7,"query":"oneplus/default ","useHardwareAEC":true,"useJavaAudioClass":true}
Atualmente, no campo RTC, openles é amplamente utilizado. Uma das razões é que, do ponto de vista da arquitetura, ADM (AudioDeviceModule) é o gerenciamento unificado da camada C++, e o callback de dados da camada C++ é conveniente para reduzir o retorno de chamada de dados demorado de java->jni->c++;
O impacto dos canais na qualidade do som de aquisição: De um modo geral, os componentes espectrais na aquisição binaural são mais ricos do que aqueles na aquisição monofônica
Hardware Android 3A, Android nativo suporta AEC e ANS de hardware para serem ativados e desativados, mas devido à modificação Rom personalizada dos fabricantes de telefones celulares Android domésticos atuais, a maioria dos fabricantes de telefones celulares Android são forçados a habilitar hardware AEC e ANS no hardware 3A e não pode ser verdadeiramente desligado;
https://developer.android.com/reference/android/media/audiofx/AcousticEchoCanceler
https://developer.android.com/reference/android/media/audiofx/NoiseSuppressor
Android AudioKit
Kit de Áudio Huawei:
https://developer.huawei.com/consumer/cn/codelab/HMSAudioKit/#0;https://developer.huawei.com/consumer/cn/doc/development/Media-Guides/introduction_services-0000001053333356;
Benefícios da integração: Pode resolver o problema de perda de largura de banda em alguns sinais de coleta de telefones celulares da fábrica A
fator de limitação:
Sistema Hongmeng
Chip Kirin
O thread de reprodução começa antes do thread de captura
Além do problema da largura de banda, a taxa de amostragem dos dispositivos Andorid também é muito diferente em dispositivos diferentes. Normalmente, a taxa de amostragem de 44100 ou 48000 Hz é mais compatível. Em dispositivos diferentes, essas duas taxas de amostragem podem ser diferentes. O desempenho do suporte é diferente, por exemplo, pode haver situações em que o efeito de cancelamento de eco do hardware 3A não seja bom ou os dados de callback da coleta sejam instáveis, portanto, também é necessário adaptar o modelo de acordo com a taxa de amostragem;
2.1.2 Terminal IOS
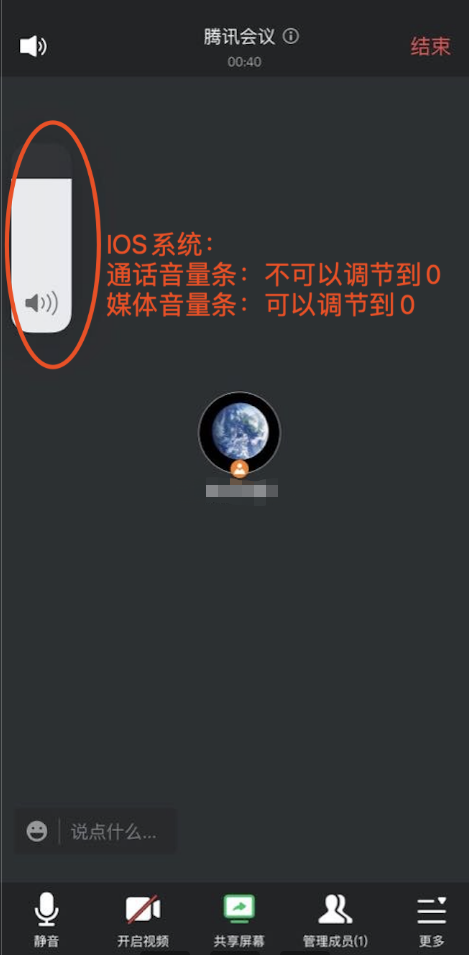
Barra de volume:
O lado do IOS também é dividido em uma barra de volume de chamada e uma barra de volume de mídia. No entanto, a exibição da interface do usuário do sistema ios não é diferenciada e a exibição do ícone da interface do usuário é a mesma. A maneira de distinguir é mostrada na figura abaixo .Pode ser ajustado para 0, barra de volume de mídia, barra de volume pode ser ajustada para 0;
Software e hardware 3A:
No sistema IOS, o mesmo fenômeno é semelhante ao sistema Android:
No cenário RTC, o software do sistema IOS e a colocação de parâmetros de hardware 3A:
Capítulo 3A: kAudioUnitSubType_VoiceProcessingIO + AVAudioSessionModeVoiceChat
Passo 3A: kAudioUnitSubType_RemoteIO + AVAudioSessionModeDefault
A seguir está a descrição da interface do sistema relacionada ao ios:
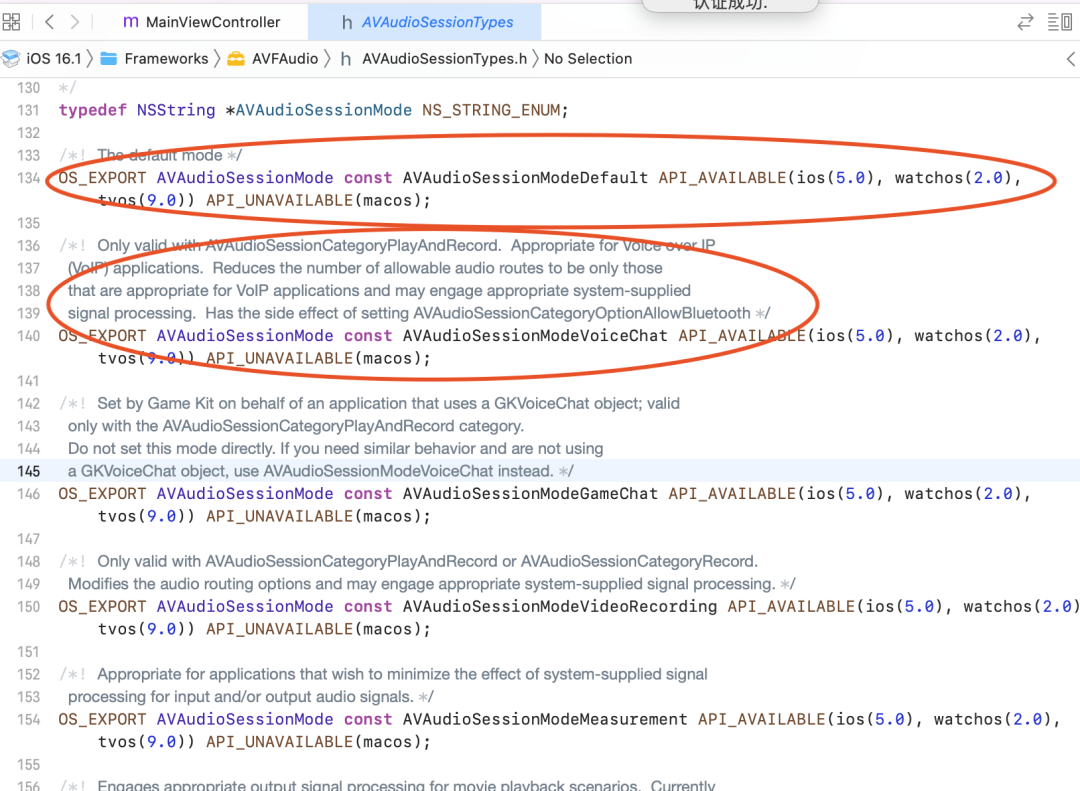
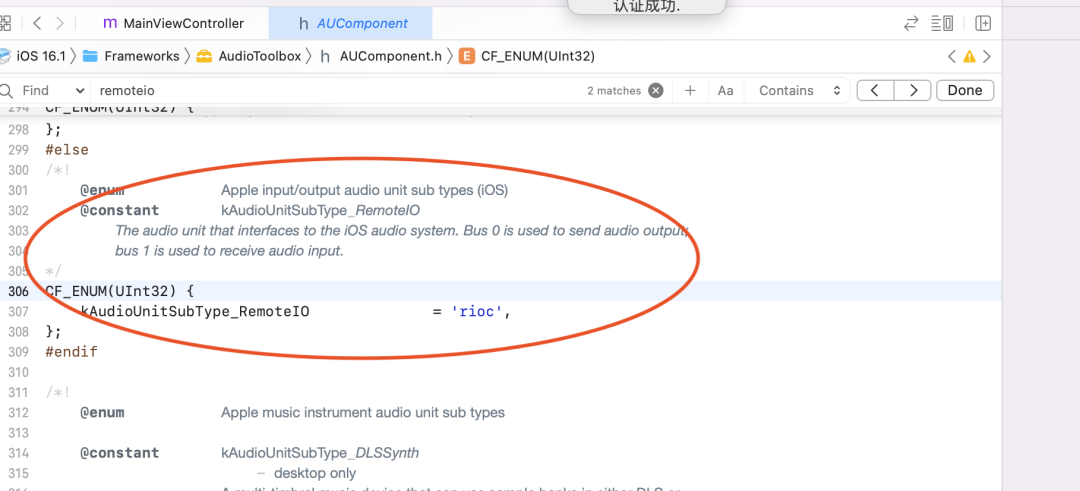
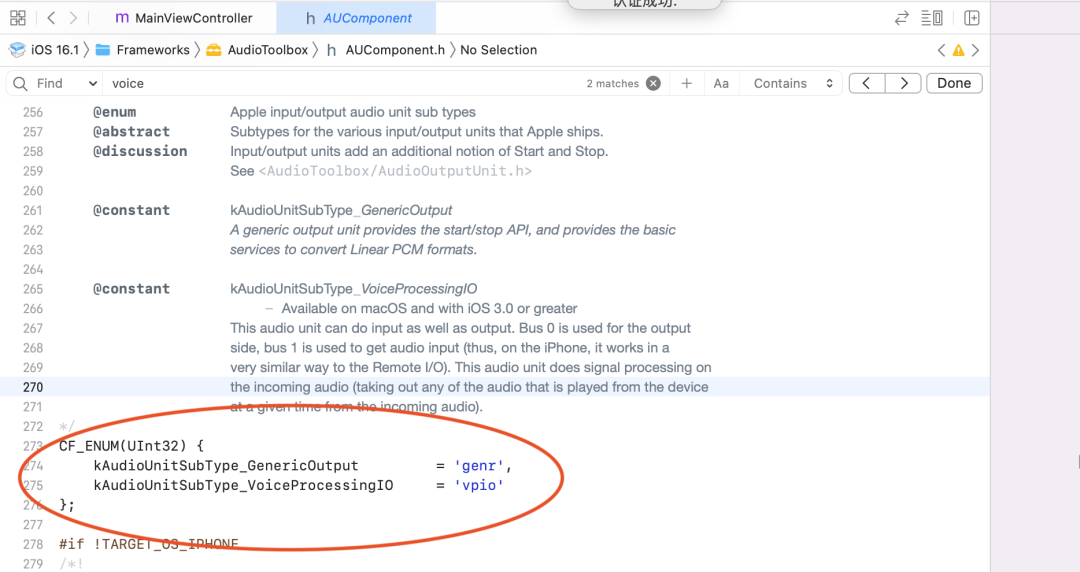
O WebRTC usa a aquisição AudioUnit na plataforma iOS, e os códigos relevantes são os seguintes:
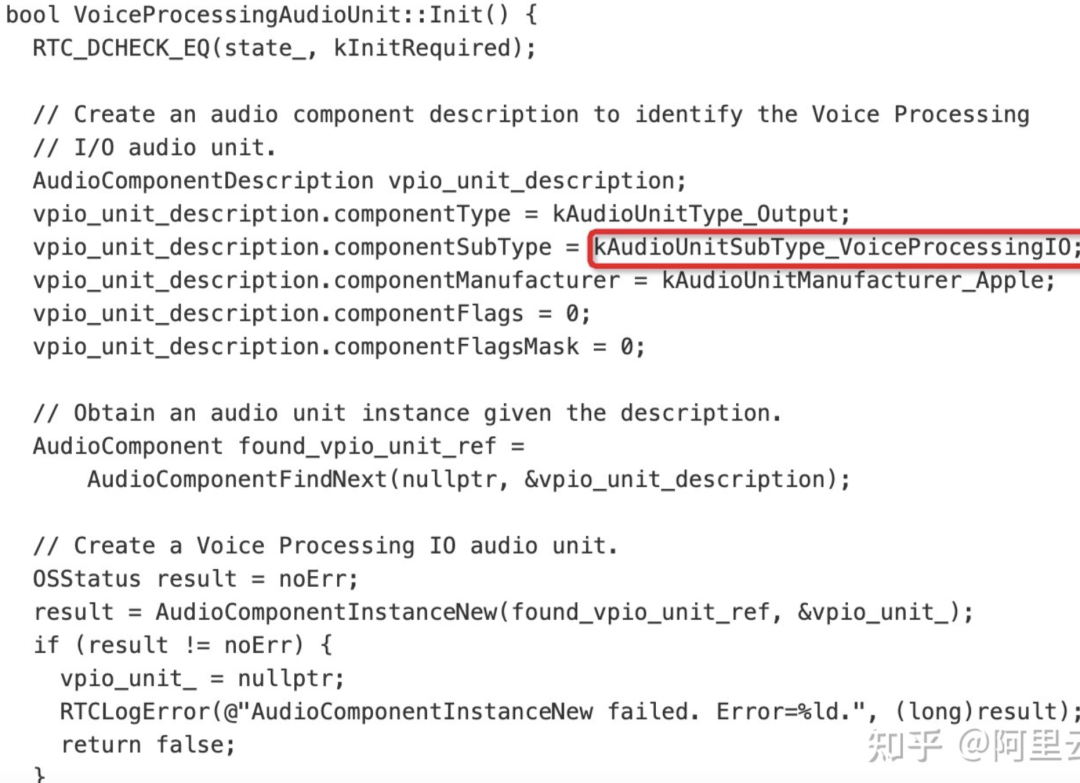
De acordo com a descrição da API da Apple, o iOS fornece três unidades de E/S, das quais a unidade de E/S remota é a mais comumente usada. Conecta-se a hardware de áudio de entrada e saída, fornece acesso de baixa latência a valores de amostra de entrada e saída e fornece conversão de formato entre formatos de áudio de hardware e formatos de áudio de aplicativos. A unidade de E/S de processamento de voz é uma extensão da unidade de E/S remota, que adiciona cancelamento de eco no bate-papo por voz e também fornece recursos como correção automática de ganho, ajuste de qualidade de voz e mudo. A unidade de saída genérica não se conecta ao hardware de áudio, mas fornece um mecanismo para enviar a saída da cadeia de processamento para o aplicativo. Geralmente usado para processamento de áudio offline.
2.1.3 Lado da janela
No lado do Windows, geralmente há três conjuntos de drivers de dispositivos de áudio: dsound, CoreAudio, Wav
Dsound - a melhor compatibilidade, mais uso de desktop
CoreAudio - compatibilidade em segundo lugar
Wav - raramente usado
No momento, muitos dispositivos Windows têm um conjunto de microfone embutido na parte superior da tela para fornecer a função de aprimoramento de áudio. O método de abertura é mostrado na figura abaixo. Esta função é padronizada para a área na frente da tela como a área de captação. A tecnologia de matriz de microfone pode efetivamente melhorar a voz do locutor na área de captação e "isolar" o "ruído" fora da área de captação A principal desvantagem é que abrir esta função Após a função, apenas o espectro de 8k é suportado, e o algoritmo de aprimoramento de cada fabricante é diferente, e o efeito também é desigual. Portanto, o software precisa ter a capacidade de ignorar a função de aprimoramento de áudio do hardware para garantir alta qualidade de som.

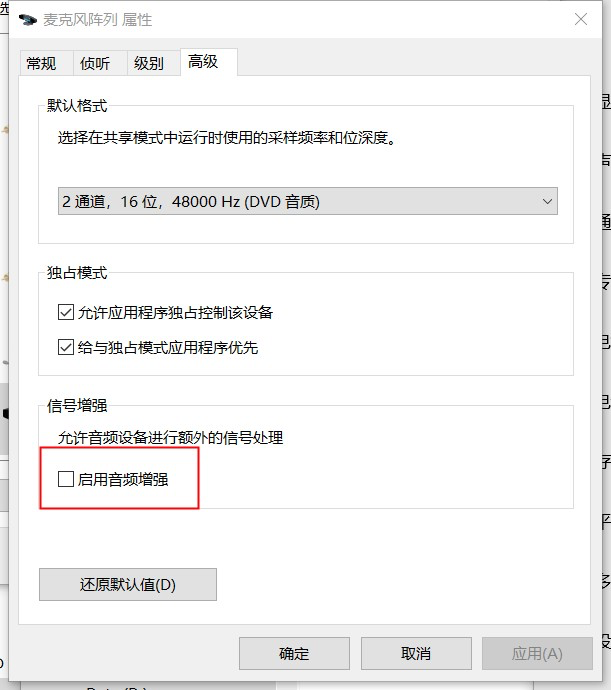
<Interruptor de recurso aprimorado nas configurações de áudio>
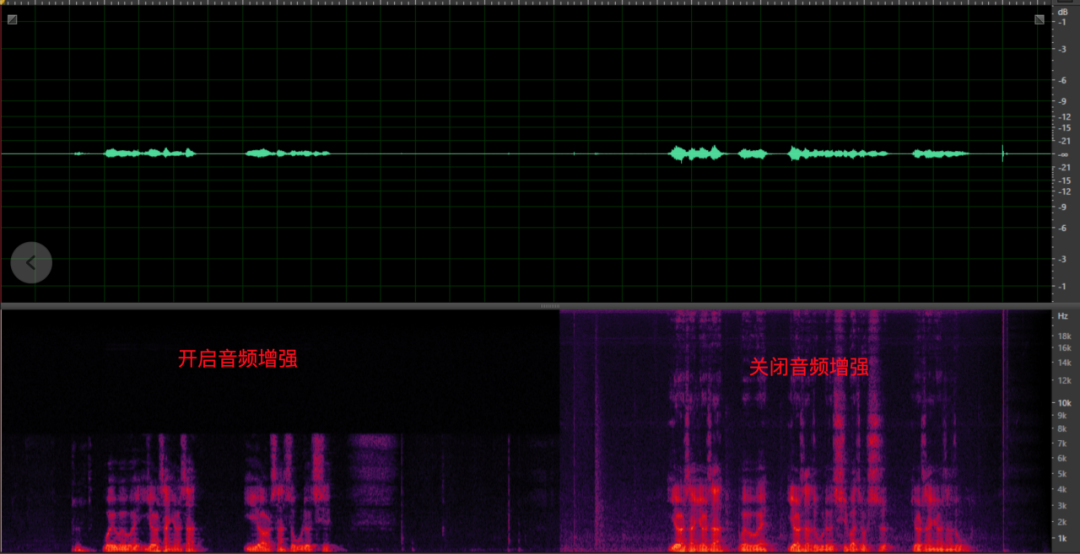
<A perda do espectro de frequência após a ativação do aprimoramento de áudio>
Em termos de volume, os dispositivos do lado do PC oferecem suporte ao ajuste de ganho analógico, e a maioria dos dispositivos Windows com matrizes possui aprimoramento de microfone adicional (conforme mostrado abaixo). O nível de algoritmo de software (AGC em 3A) precisa ter a capacidade de ajustá-los de forma adaptativa para garantir a estabilidade do volume de coleta de áudio para controlar o nível de ruído de fundo de coleta. A configuração inadequada do valor inicial ou o ajuste adaptativo levará a problemas como baixo volume e som de estalo, o que afetará seriamente o efeito de cancelamento de eco e redução de ruído e trará o risco de afetar a usabilidade.
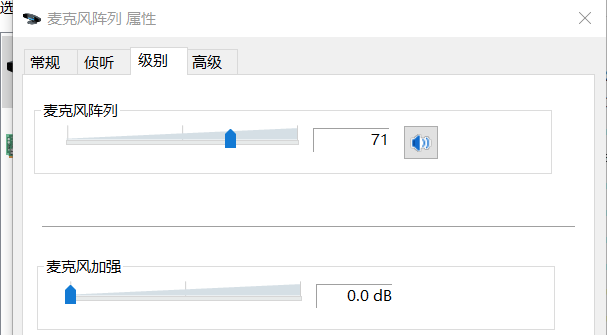
<Ganho analógico e reforço de microfone>
2.1.4 Lado Mac
O lado do Mac é menos usado, então não vou apresentá-lo em detalhes aqui;
O lado do Mac suporta o ajuste dinâmico do volume analógico semelhante ao lado do Windows;
2.1.5 Problemas comuns e soluções de equipamentos de áudio
Devido a diferentes fabricantes de hardware, as soluções de coleta de áudio em diferentes extremidades são desiguais; portanto, a qualidade do áudio coletado afeta diretamente a usabilidade dos materiais de produção obtidos pelo algoritmo 3A e também determina a qualidade do sinal de áudio recebido pelo usuário final .limite superior. De acordo com os problemas de áudio encontrados no trabalho real, os problemas causados pela aquisição de equipamentos podem ser basicamente resumidos nas seguintes categorias:
Para dar alguns exemplos:
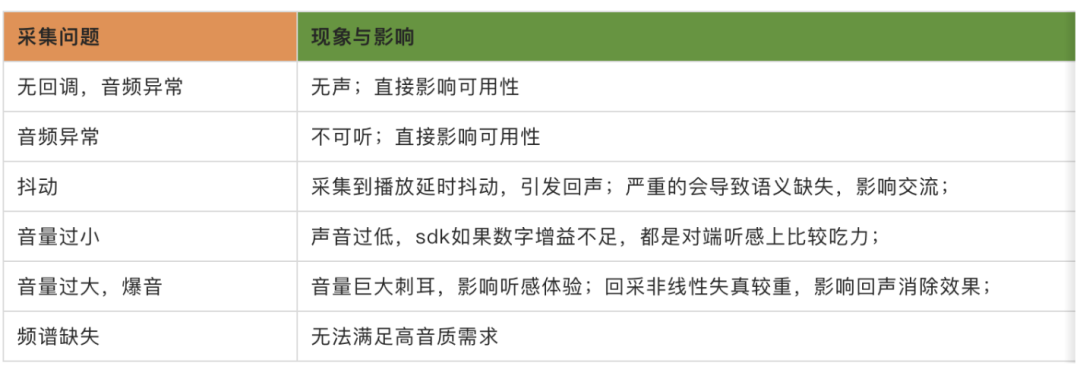
(1) Coleta anormal:
As anormalidades de aquisição são refletidas principalmente no espectro "fuzzy", que pode levar à incapacidade de entender a semântica e afetar a comunicação normal. O espectrograma é o seguinte.
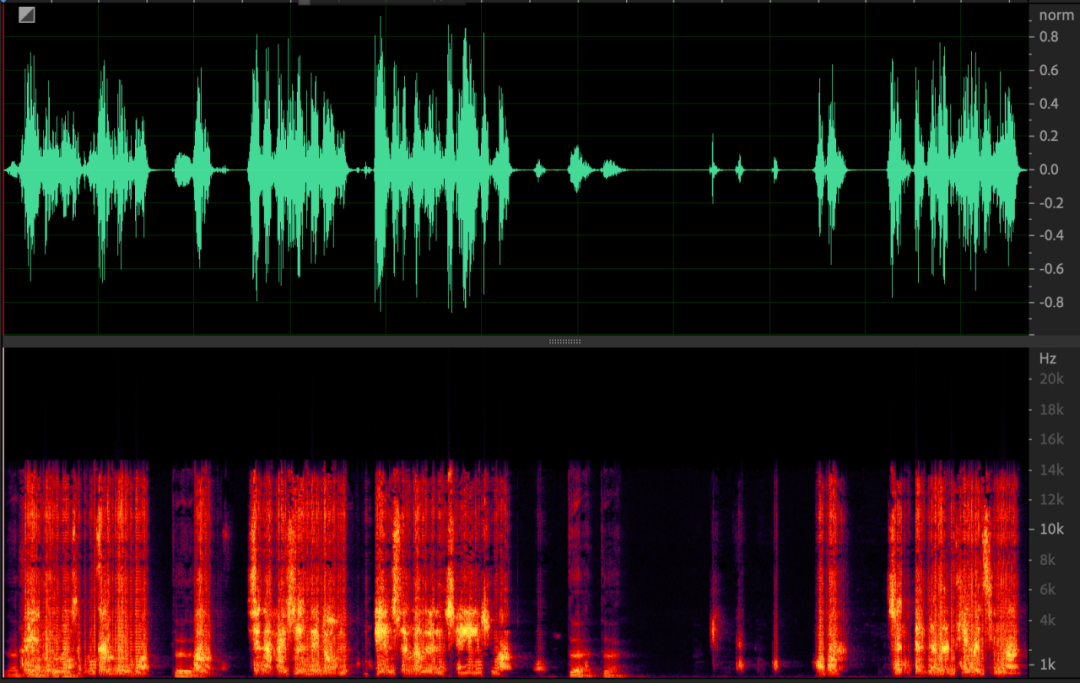
Além disso, após a aquisição ser anormal, o sinal de transmissão também parecerá anormal após ser captado pelo microfone, o que causará séria distorção não linear e afetará o efeito de cancelamento de eco, conforme mostrado na figura abaixo.
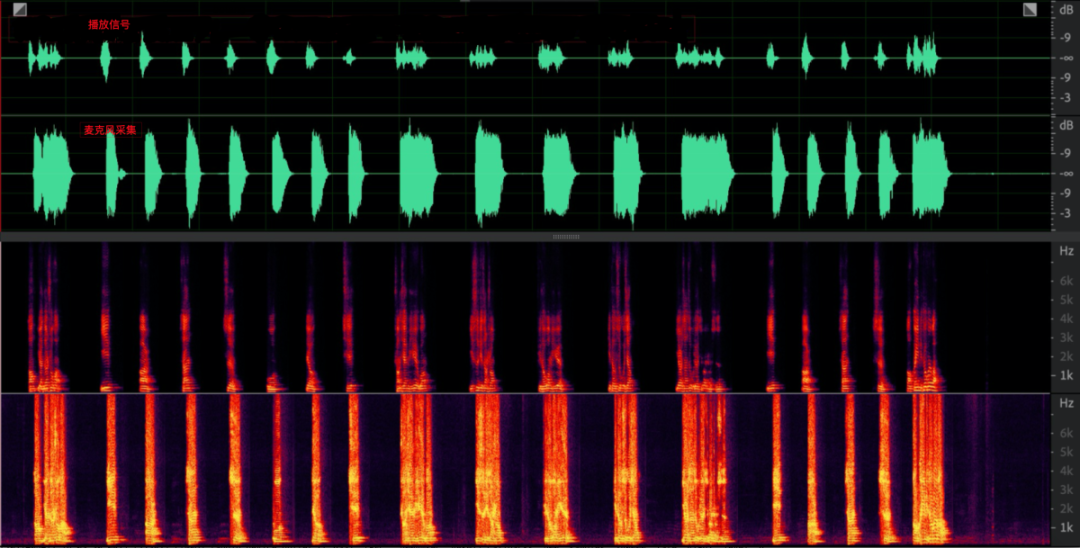
(2) Tremulação de aquisição
O comum é coletar e perder dados, e você ouvirá muito ruído de alta frequência no sentido da audição (a imagem abaixo é a imagem parcial após o ruído na imagem acima ser ampliado), o que afetará seriamente o precisão da estimativa de atraso e não linearidade extremo-próximo no algoritmo AEC.Problemas de causa e efeito, os mais sérios, levarão ao vazamento de eco.

(3) Pequenos problemas com som e volume estourando
O estouro de aquisição ocorre principalmente em PCs e também é um problema que os dispositivos do lado do PC devem evitar. Tem um impacto maior. Além da distorção espectral causada pelo truncamento, a distorção não linear severa afetará o efeito de cancelamento de eco. O problema de popping requer que o algoritmo AGC ajuste de forma adaptativa o ganho analógico no lado do PC e fortaleça o microfone para resolvê-lo.
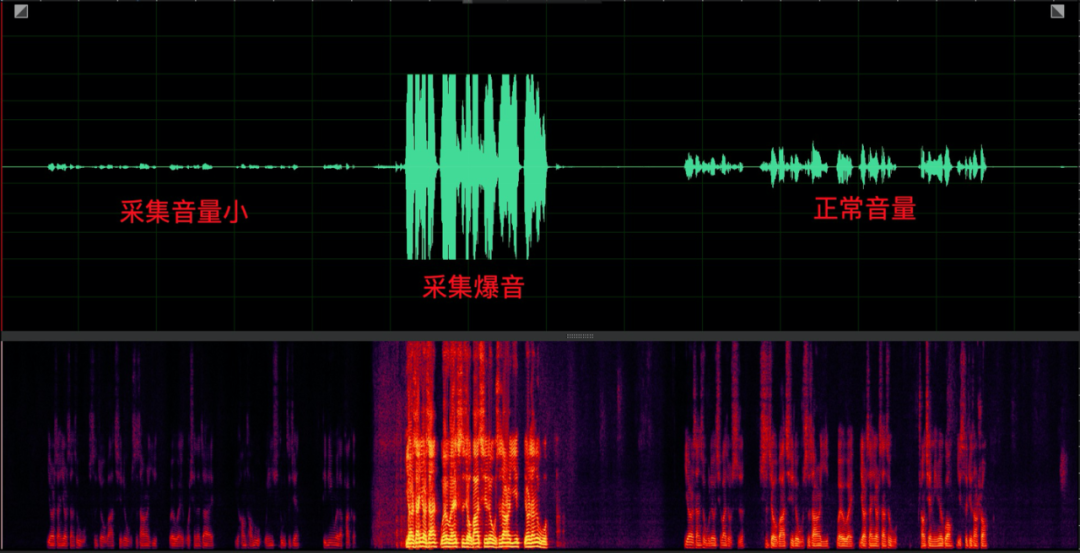
(4) Espectro ausente
A falta de espectro no lado da aquisição do equipamento se deve principalmente ao fato de que a taxa de amostragem de áudio do retorno de chamada do hardware é inconsistente com a distribuição real do espectro. Mesmo que o codificador forneça uma alta taxa de bits de codificação, não há som de alta qualidade efeito no sentido da audição, que foi introduzido aqui;
(5) Solução:
Para resolver a disponibilidade de equipamentos em diversos cenários de negócios e melhorar a precisão dos dados coletados pelos equipamentos, as estratégias comumente utilizadas são as seguintes:
Adaptação do dispositivo:
De acordo com diferentes modelos, o Android adapta a taxa de amostragem de aquisição apropriada samplerate, audiomode, audiosource e se java ou openles é usado através da distribuição de configuração;
Estratégia de cooperação da camada de negócios:
windows: reunião DingTalk, os usuários podem optar por usar dsound ou coreaudio
A estratégia auto-adaptável sdk usa o devicemonitor para monitorar se o dispositivo está disponível ou anormal. Quando ocorre uma anormalidade, o sdk pode adotar as seguintes estratégias:
Reinicie automaticamente os dispositivos de captura/reprodução de áudio, faça
o downgrade e alterne automaticamente os drivers de áudio;
2.2 Áudio 3A
O pré-processamento de áudio é a chave para toda a cadeia de processamento de áudio. Os dados de áudio originais coletados pelo microfone terão vários problemas, como ruído e eco. Por exemplo, em uma cena de videoconferência com várias pessoas, vários dispositivos no mesmo local abrem o microfone ao mesmo tempo, o que causará forte uivo, e o alto-falante está longe do microfone. Ruim. Para melhorar a qualidade do áudio, é necessário realizar operações de cancelamento de eco, redução de ruído e equalização de volume no sinal transmitido em sequência no final do envio, ou seja, processamento 3A de cancelamento de eco AEC, supressão de ruído ANS e ganho automático AGC ao controle. Em diferentes cenários, como chamadas, chats, ensino e jogos, os fabricantes de áudio e vídeo em tempo real precisam considerar as necessidades reais dos cenários e ajustar o algoritmo 3A de acordo para obter bons efeitos de áudio.
No código-fonte aberto webrtc, tomando o lado do Android como exemplo, o webrtc verificará se o hardware possui recursos ANS de hardware e AEC de hardware e, em caso afirmativo, o software aec não será habilitado; Suporte, o software 3A será ativado no ao mesmo tempo que uma solução de baixo para cima. O principal motivo é que os recursos de hardware 3A de diferentes dispositivos são relativamente diferentes. Confiar no hardware 3A não pode obter efeitos totalmente confiáveis e estáveis. O seguinte enfoca a análise do princípio de 3A e os impacto na qualidade do som Influência;
(1) AEC (cancelamento de eco acústico)
Princípio: Conforme mostrado na figura abaixo, o usuário na Room1 fala com o peer Room2 através do rtc, e após ser tocado pelo peer speaker, é captado pelo microfone do peer, e então codificado e transmitido para a Room1, para que a Room1 possa ouvir a própria voz, ou seja, o chamado "eco", o problema que a AEC tem que resolver é eliminar o sinal de eco, de forma a evitar que a outra ponta ouça a própria voz; portanto, na comunicação de áudio e vídeo, o problema comum é o problema "estou ouvindo minha voz". "Eu ouço minha própria voz".


O princípio básico do cancelamento de eco é usar a correlação entre o sinal contendo eco coletado pelo sinal da extremidade próxima (microfone) e o sinal de referência da extremidade distante (o sinal de voz recebido da extremidade oposta antes da reprodução), de acordo com o sinal do alto-falante e seu gerado Com base na correlação do sinal de eco, o modelo de sinal remoto é estabelecido, o caminho do eco é simulado e o algoritmo adaptativo é ajustado para tornar a resposta ao impulso próxima ao caminho do eco real. Em seguida, subtraia o valor estimado do sinal recebido pelo microfone para realizar a função de cancelamento de eco.
Várias dificuldades no cancelamento de eco em cenas rtc:
O efeito do hardware AEC é bem diferente;
pergunta de conversa dupla;
Estimativa de latência;
Vazamento de eco, etc.;
Artigo de referência: https://developer.aliyun.com/article/781449?spm=a2c6h.14164896.0.0.70a21f36aoEDj7
(2) ANS (Supressão Automática de Ruído)
O ANS no webRTC é baseado na filtragem de Wiener para reduzir o ruído. Para cada quadro de sinal de fala com ruído recebido, com base na estimativa de ruído inicial do quadro, a função de probabilidade de fala é definida e o sinal de ruído de cada quadro é medido. Recursos de classificação , usando os recursos de classificação medidos, calcule a probabilidade de fala com base em vários recursos para cada quadro e pondere a probabilidade de fala calculada com fatores dinâmicos (recursos de classificação de sinal e parâmetros de limite), de acordo com o recurso calculado com base em cada quadro Probabilidade de fala , que modifica a função de probabilidade de fala para cada quadro do multiquadro e atualiza a estimativa de ruído inicial (ruído quantil para cada quadro de multiquadros consecutivos) em cada quadro usando a função de probabilidade de fala modificada por quadro.

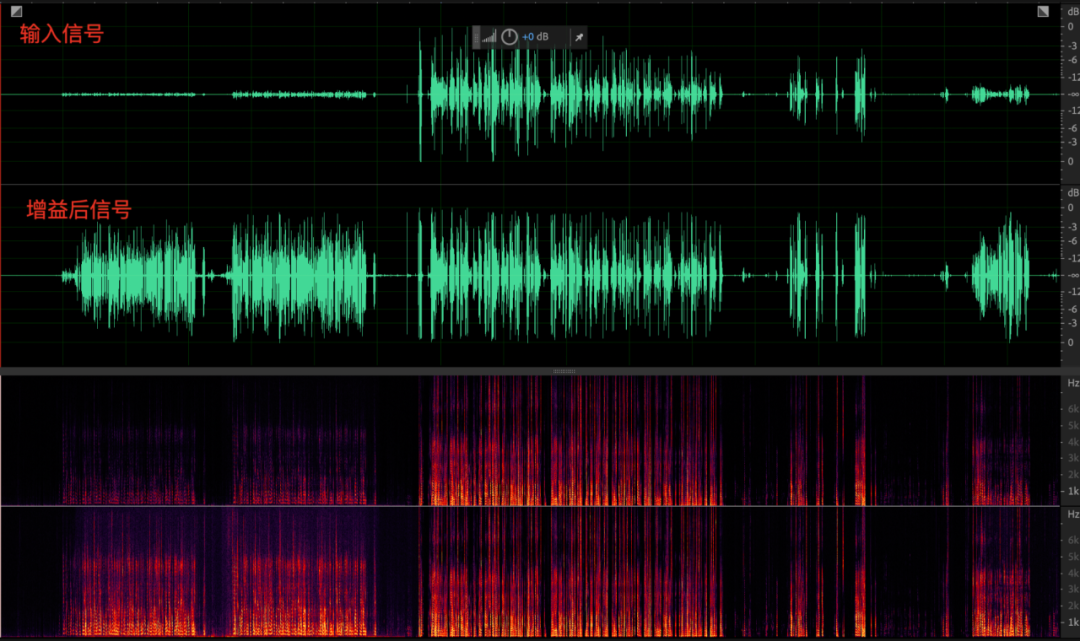
O impacto da redução de ruído na qualidade do som:
O impacto da redução de ruído na qualidade sonora do sinal é maior do que o do módulo de cancelamento de eco. Isso se deve ao fato de que, no início do projeto do algoritmo de redução de ruído, assumimos a priori que o piso de ruído é um sinal estável (pelo menos um sinal estável de curto prazo) e, de acordo com essa suposição, a discriminação entre música e ruído de fundo é significativamente mais fraca do que entre fala e ruído de fundo. Uma peça de música agradável tem detalhes ricos em cada banda de frequência (especialmente a parte de alta frequência), e a perda de qualquer banda de frequência pode afetar o sentido da audição. No entanto, a energia da música na parte de frequência média a alta (especialmente alta frequência) geralmente é baixa, o que leva a uma pequena relação sinal-ruído após a sobreposição de ruído, o que dificulta o processamento do ANS. Os detalhes da música nas frequências média e alta provavelmente serão confundidos com ruído e processados, causando danos. Em contraste, a voz humana é geralmente concentrada nas frequências médias e baixas, com alta energia e relação sinal/ruído, e relativamente menos danos no processamento do SNA.
Em resumo, é mais provável que a música seja danificada acidentalmente pelo ANS. Em cenas musicais com altos requisitos de qualidade de som, é recomendável reduzir o nível de redução de ruído ou até mesmo desligar o processamento de redução de ruído, para reduzir a interferência de ruído do nível ambiental tanto quanto possível.
Áudio gravado:
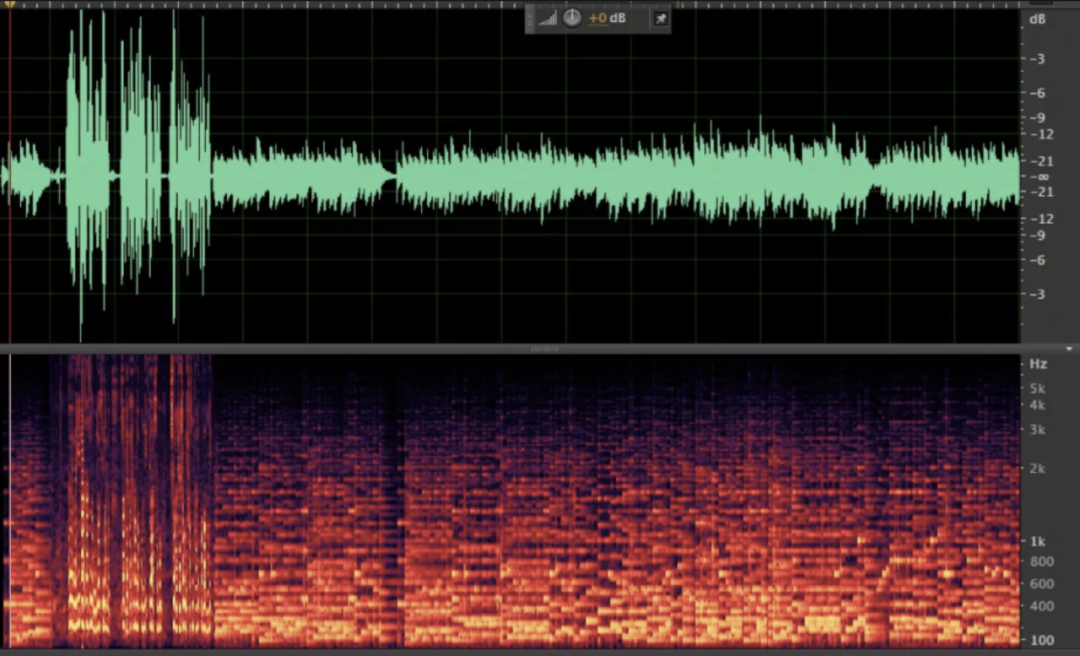
Áudio após ANS:
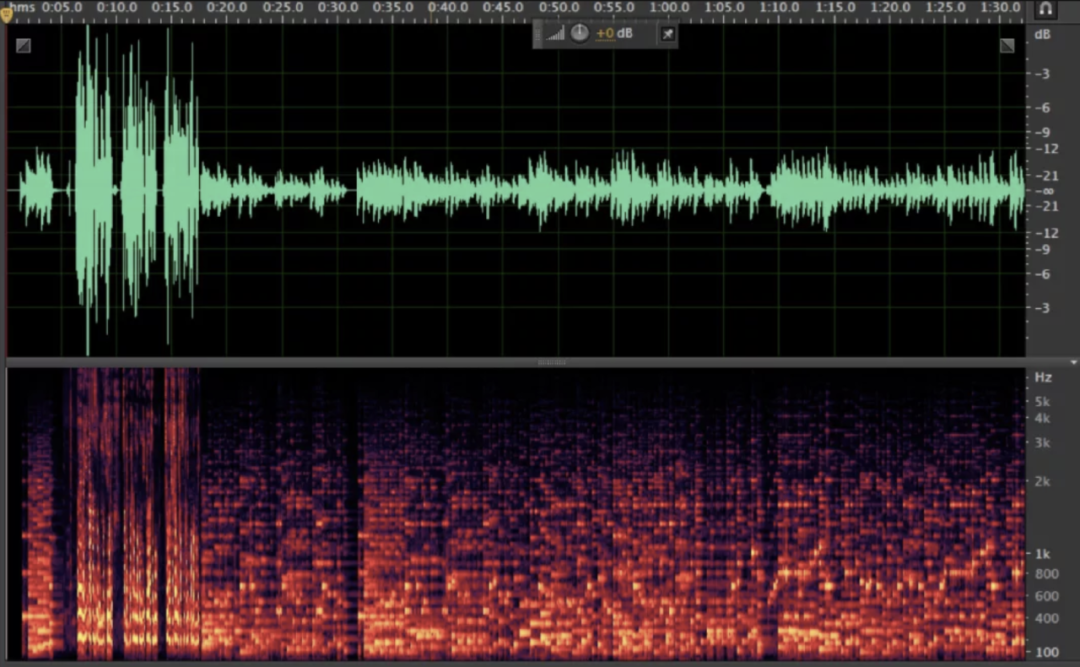
(3) AGC (Controle Automático de Ganho)
Nem todos os sinais estão sujeitos ao controle de ganho de volume. Assim como o ANS/AEC apenas suprime o ruído/eco da extremidade distante e preserva a voz da extremidade próxima, o AGC também precisa filtrar a voz da extremidade próxima no sinal coletado para evitar ruído e eco. e outro ganho de sinal não relacionado. Considerando este ponto, é mais adequado colocar o módulo AGC após o processamento AEC e ANS, pois o ruído e o eco no sinal foram bastante reduzidos neste momento. No entanto, a "vantagem" da localização não significa que a AGC possa realizar o seu trabalho sem preocupações. Para evitar escorregar pela rede, muitas vezes é necessário realizar a detecção de voz (VAD) para distinguir ainda mais os segmentos de fala dos segmentos sem fala.
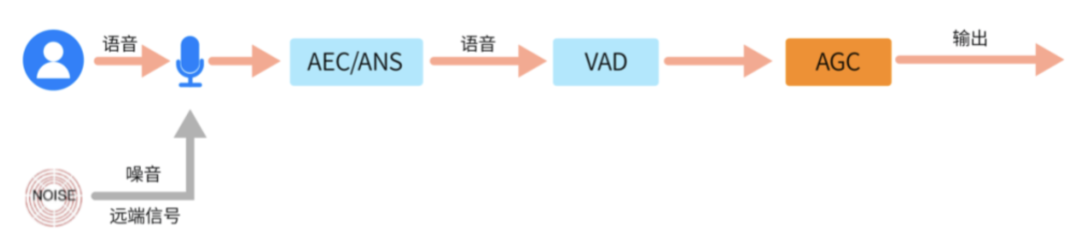
AGC tem vários parâmetros-chave:
Volume alvo - targetLevelDbfs: Indica o valor alvo do resultado da equalização do volume, se for 1, significa que o valor alvo do volume de saída é - 1dB;
Capacidade de ganho - compressãoGaindB: Indica a capacidade máxima de ganho do áudio, se configurado em 12dB, o máximo pode ser aumentado em 12dB;
Três modos de AGC:
enum {
kAgcModeInalterado,
kAgcModeAdaptiveAnalog, // modo analógico adaptativo
kAgcModeAdaptiveDigital, // Modo de ganho digital adaptativo
kAgcModeFixedDigital // modo de ganho digital fixo
};
O lado do PC suporta ajuste de ganho analógico.No lado do PC, geralmente é usado o kAgcModeAdaptiveAnalog, ou seja, o ganho analógico e o ganho digital são ajustados juntos para ajustar o volume;
2.3 Codificador
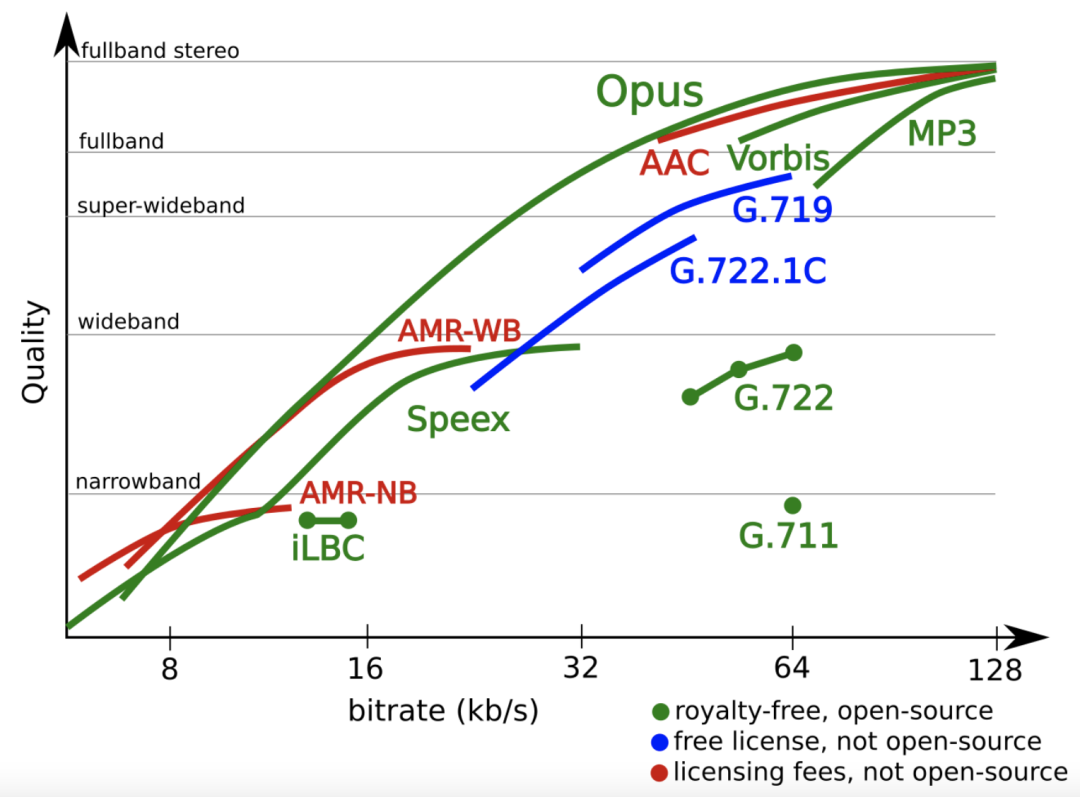
Codificador Opus:
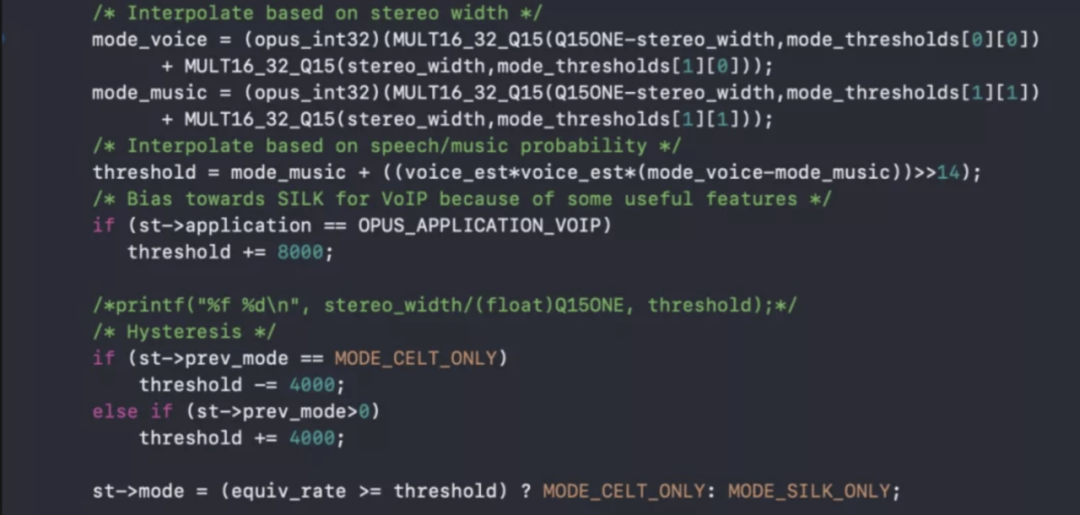
Opus é um codec misturado com SILK+CELT, cujo nome acadêmico é USAC, Unify Speech and Audio Coding, um codec que não faz distinção entre música e fala. Há um detector de música neste codec para julgar se o quadro atual é fala ou música. A fala é codificada no quadro de seda e a música é codificada no quadro celt. Geralmente, é recomendável não limitar o modo que o codificador usa para codificação.
Atualmente, o WebRTC usa kvoip como o aplicativo e o modo de codificação mista é ativado por padrão;
Julgamento do algoritmo de codificação de música e fala no modo de codificação mista no codificador:
A codificação Opus tem as seguintes características:
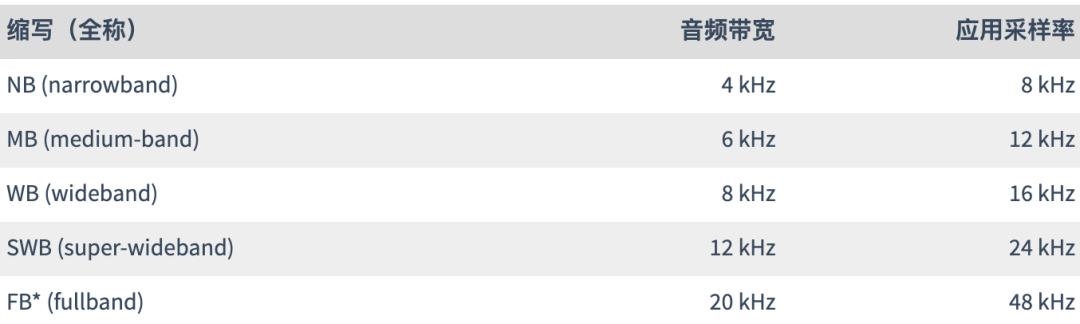
Taxas de bits de 6 kb/s a 510 kb/s
Taxas de amostragem de 8 kHz (banda estreita) a 48 kHz (frequência total)
Tamanho do quadro de 2,5ms a 60ms
Suporta taxa de bits constante (CBR) e taxa de bits variável (VBR)
Largura de banda de áudio de banda estreita a banda completa
Suporta voz e música
Suporte mono e estéreo
Suporta até 255 canais (frames multi-streamed)
Taxa de bits, largura de banda de áudio e tamanho de quadro dinamicamente ajustáveis
Boa robustez à taxa de perda e ocultação de perda de pacotes (PLC
Taxa de código de sobremesa:
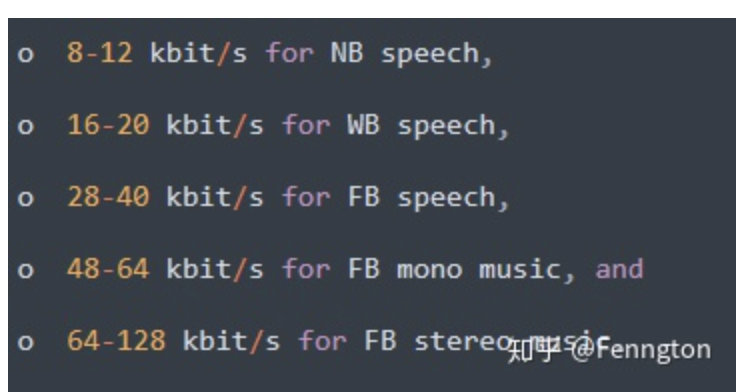
Resumo: Em cenas musicais e outras cenas que exigem alta qualidade de som, a codificação Celt com maior complexidade e taxa de bits mais alta pode ser usada para obter uma experiência musical de alta qualidade; em cenas de voz, a codificação Silk pode ser usada; além disso, a taxa de bits do codificador também é muito importante. Quando a taxa de bits é muito baixa, o Opus automaticamente rebaixará da codificação FB para a codificação WB ou mesmo NB, resultando em um efeito de "truncamento de espectro" no lado do codificador. AAC também tem um fenômeno semelhante. Esta parte pode ser combinada com este artigo Veja a análise de caso em 3.6.
2.4 Neteq
Neteq é uma tecnologia importante do webrtc, principalmente para resistir a jitter de rede, perda de pacotes, etc.; jitter refere-se ao desequilíbrio dos dados que chegam à extremidade receptora em diferentes períodos de tempo devido a motivos de rede; ou a extremidade receptora recebe pacotes de dados. O intervalo de tempo varia de um para outro; e a perda de pacotes é que o pacote de dados é transmitido pela rede e é perdido por vários motivos. Após várias retransmissões, ele é recebido com sucesso como um pacote de recuperação. A retransmissão também falha ou o pacote de recuperação está desatualizado. Isso causará perda de pacote real, e o algoritmo PLC de recuperação de perda de pacote é necessário para gerar alguns dados falsos do nada para compensar. Perda de pacotes e jitter são unificados a partir da dimensão do tempo. Aquele que espera dentro do período de espera é jitter, aquele que chega muito atrasado é retransmissão e aquele que não espera além do período de espera é "perda de pacote real" Otimização da Neteq Um dos objetivos do é minimizar a probabilidade de um pacote se tornar um "true drop".
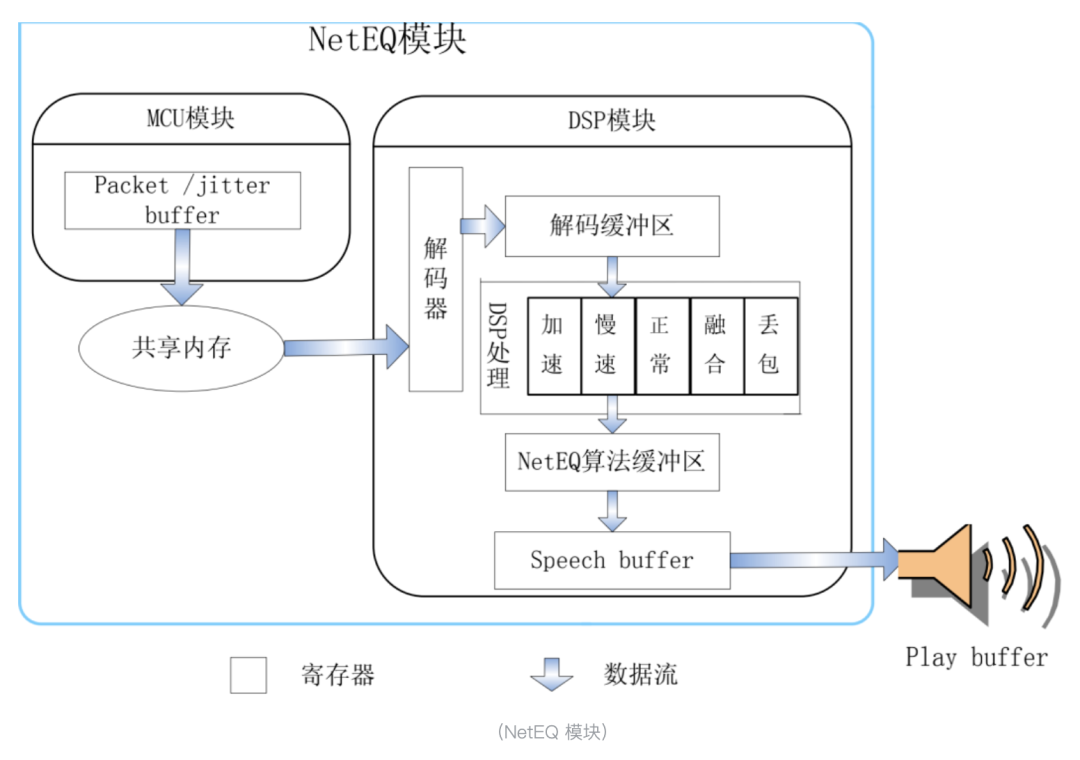
O módulo principal do NetEQ possui módulo MCU e módulo DSP. O módulo MCU é responsável por inserir e buscar dados no cache do buffer de jitter, bem como a operação do DSP; o módulo DSP é responsável pelo processamento de números de informações de voz, incluindo decodificação, aceleração, desaceleração, fusão, PLC, etc. Ao mesmo tempo, o módulo MCU recebe pacotes do buffer de jitter e é afetado pelo feedback relevante do módulo DSP. O módulo MCU inclui pacotes de áudio entrando no buffer, tirando pacotes de áudio do buffer, avaliando o atraso de tempo de transmissão da rede através do intervalo de chegada do pacote de voz e realizando operações no módulo DSP (aceleração, desaceleração, PLC, mesclagem), etc. O módulo DSP inclui decodificação, execução de operações relacionadas nos dados PCM de voz decodificada, avaliação do nível de jitter da rede, entrega de dados reproduzíveis ao buffer de reprodução e assim por diante.
A Neteq usará o algoritmo de compensação de perda de pacote (Packet Loss Concealment, PLC) quando ocorrer uma perda real de pacote. O algoritmo PLC pode compensar adequadamente os pacotes de áudio perdidos usando todas as informações obtidas, dificultando a detecção, garantindo assim a clareza e fluência do áudio do lado receptor e trazendo aos usuários uma melhor experiência de chamada.
Em todo o link rtc, a perda de pacotes é um fenômeno frequentemente encontrado quando os dados são transmitidos na rede, e também é um dos principais motivos da degradação da qualidade de voz nas chamadas VOIP (Voice Over Internet Phone, VOIP). A solução PLC tradicional é baseada principalmente no princípio de processamento de sinal.O princípio básico é usar as informações do parâmetro de decodificação antes da perda do pacote para reconstruir o sinal de voz perdido. A maior vantagem do método PLC tradicional é que é simples de calcular e pode ser compensado online; a desvantagem é que a capacidade de compensação é limitada e só pode efetivamente combater a perda de pacotes de cerca de 40ms. Ao lidar com a perda de pacote de rajada contínua de longo prazo, o algoritmo tradicional causará som mecânico, atenuação rápida da forma de onda e outras situações que não podem ser compensadas com eficácia;
Conforme mostrado na figura abaixo, quando a perda de pacotes é fixada em 120 ms, o algoritmo neteq_plc completa a compensação de perda de pacotes por meio de repetição e atenuação simples do ciclo genético. Quando ocorre perda de pacotes de longo prazo, soa como um som mecânico pesado e afetam o unlost A forma de onda da parte do pacote; a capacidade de compensação do algoritmo opus_plc é limitada, só pode compensar efetivamente cerca de 40ms, e a perda de pacote de mais de 40ms será atenuada em silêncio.
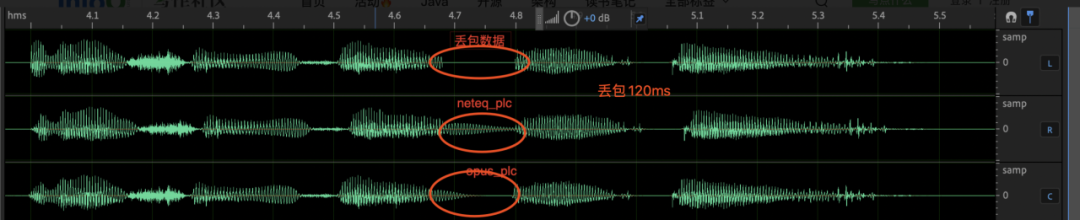
Portanto, para melhorar a qualidade do som de todo o link, existem duas direções técnicas que podem ser otimizadas nos lados da rede e da neteq:
Melhorar a capacidade de resistir a redes fracas através de Red/FEC+Nack;
Melhore a sensação de audição em "perda de pacote real" otimizando o algoritmo PLC na extremidade receptora;
3. Pensando em diferentes cenários de negócios e na seleção de tecnologia por trás deles
3.1 Cena ao vivo:
A cena da transmissão ao vivo é geralmente uma cena baseada em entretenimento. O apresentador geralmente toca música no celular com uma placa de som externa. Este tipo de cena é caracterizado por altos requisitos de qualidade de som, especialmente qualidade de som musical. Portanto, em termos de qualidade soluções técnicas, geralmente é usado software 3A + barra de volume de mídia. +Esquema de codificação de música e rtc geralmente não executa processamento 3A no som quando conectado a uma placa de som externa. Quando não conectado a uma placa de som, ele também usa redução de ruído de modo fraco ou desliga diretamente a redução de ruído;

3.2 Cena do encontro:
A cena da conferência é uma cena típica baseada em chamada de voz. Portanto, Tencent Conference e DingTalk Conference geralmente adotam o modo de hardware 3A, barra de volume de chamada e codificação de voz. A imagem abaixo é o terminal móvel de conferência DingTalk. no entanto, as desvantagens dessa solução também são óbvias, ou seja, a largura de banda efetiva da fonte de som coletada já é muito baixa e foi processada pelo hardware 3A , e depois desligado Software 3A tem pouco benefício;

O cliente da Tencent Conference é a mesma solução:
3.3 Cenários de comunicação:
Tomando como exemplo a chamada de vídeo WeChat, é um cenário típico de comunicação. A seleção de tecnologia de qualidade de som no cenário de comunicação e no cenário de conferência é a mesma solução, ou seja, a solução de hardware 3A + barra de volume de chamada, mas chamada WeChat não fornece a configuração da música na reunião. a função do modo;
3.4 Cenário de Educação Online:
Os cenários de educação online, em termos de subdivisões, dividem-se em cenários de educação online normais e cenários de educação musical, o primeiro centra-se principalmente em aulas de voz, enquanto o segundo foca-se na performance de instrumentos musicais, como ensino de piano, etc.;
Cenário de Educação Geral:
Em cenários de educação geral, do ponto de vista da qualidade sonora, o principal objetivo é garantir uma qualidade de voz clara e inteligível, portanto, uma solução comum é usar soluções de hardware 3A semelhantes a cenários de comunicação;

Cenário de educação musical:

A cena de educação musical é essencialmente semelhante à cena de transmissão ao vivo e também é uma espécie de cena de pan-entretenimento. A seleção de tecnologia por trás desse tipo de cena também precisa focar na qualidade do som. Principal, ou seja, a solução de software Aquisição 3A + redução de ruído musical + codificação musical;
3.5 Cena "Assistindo juntos"
A cena "assistir juntos" refere-se à cena em que várias pessoas assistem ao mesmo vídeo juntas em um bate-papo por voz em tempo real em uma sala. Esse tipo de cena de aplicativo e sua cena estendida incluem "assistir a filmes juntos" ou reproduzir cursos de vídeo no educação professor de sala de aula Pode ser assistido por colegas online juntos, ou em cenas como jogos de matança de roteiro intercalados com enredos de vídeo online.
A imagem abaixo é um típico APP Top1 "Shimmer" nesta cena:
A dificuldade técnica neste cenário é que o player SDK e o rtc SDK são dois SDKs. Como resolver o problema de cancelamento de eco do som do player, caso contrário as pessoas na reunião ouvirão o som do filme duas vezes. E devido ao existência do eco, a voz humana no filme acionará a ativação de voz quando o jogador estiver jogando novamente, fazendo com que a onda sonora da interface do usuário vibre com a voz dos personagens do filme mesmo que o usuário não fale no IU. Portanto, a dificuldade neste cenário é eliminar o eco do filme. Para este cenário, existem atualmente três soluções:
Solução 1: Hardware 3A, esta solução é simples de implementar, contando com o hardware 3A para eliminar o eco do filme, atualmente a versão online do Shimmer utiliza esta solução; mas existem vários problemas com esta solução:
O Android tem barras de volume duplo; o player é a barra de volume de mídia e o rtcsdk do chat de voz é a barra de volume da chamada, então a experiência do usuário não é muito boa. O usuário no microfone ajusta o volume da chamada por padrão, e o o volume da mídia precisa ser ajustado separadamente;
Os efeitos AEC de diferentes modelos de hardware Android 3A são inconsistentes e há problemas de vazamento de eco causados pelo cancelamento de eco ruim de alguns modelos Android, que não podem ser resolvidos e a experiência não é boa;
Embora o lado do IOS também possa usar a solução de hardware 3A, o lado do ios está acima do ios14, porque o ios dá prioridade para garantir o volume da chamada quando o hardware 3A e o volume da mídia existem ao mesmo tempo, mesmo que o volume do player esteja ajustado para no máximo, o som real do filme ainda é muito pequeno A situação afeta seriamente a experiência do usuário;
Opção 2: A ideia central da Opção 2 e da Opção 3 é obter o sinal de referência de áudio antes da renderização do player e enviá-lo ao software aec como um sinal de referência remota para cancelamento de eco, eliminando assim o eco; e Opção 2 e a Opção 3 pode ser unificada Usando a barra de volume de mídia, o rtc é conectado com uma solução 3A suave e pura, que pode resolver muito bem os três problemas de experiência na Solução 1.
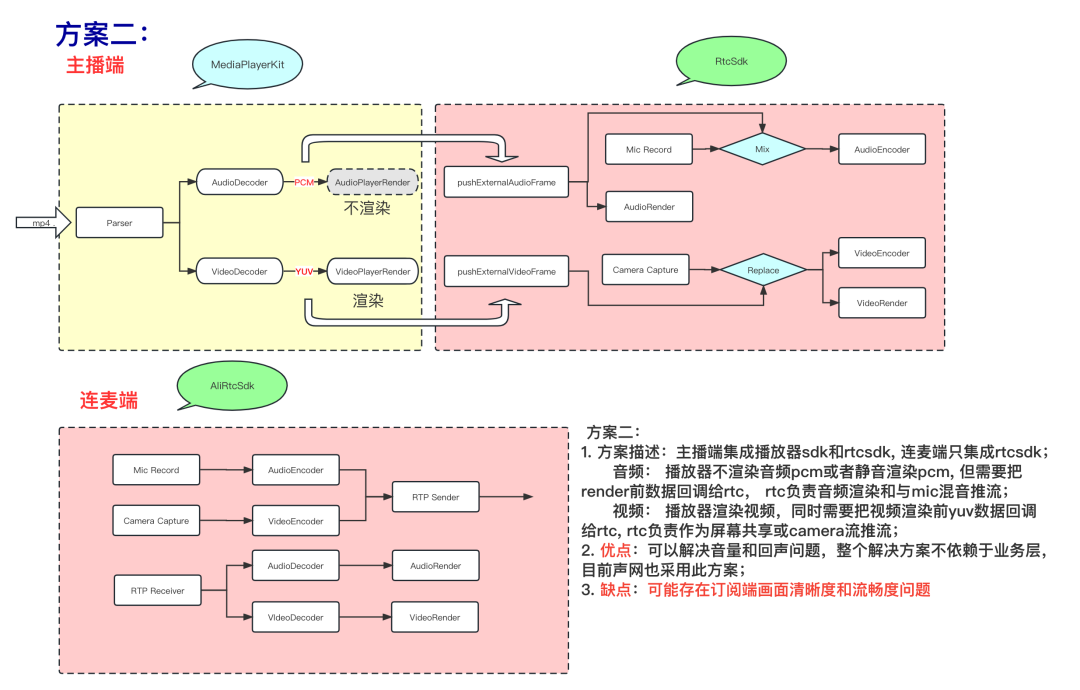
terceira solução:
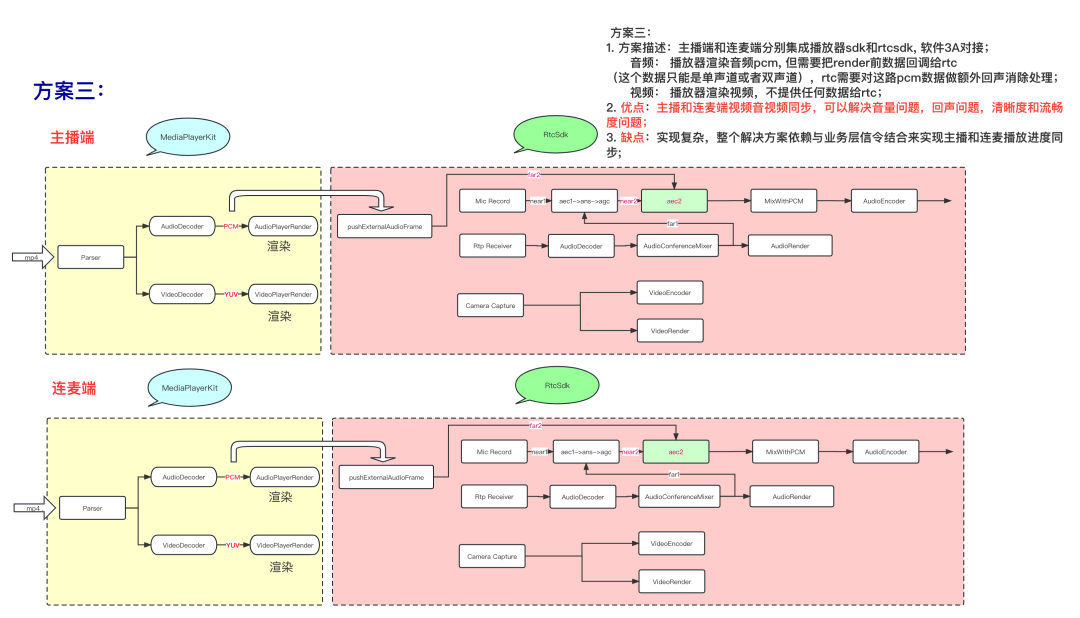
A solução 3 é mais uma solução de evolução. Também é possível sincronizar o andamento da reprodução da âncora com o terminal Lianmai através do canal de sinalização rtc, de modo a obter a sincronização do andamento da reprodução. A lógica da camada de negócios pode ser simplificada e o desempenho também pode ser alcançado.
3.6 Estudo de caso:
Antecedentes: Em uma cena de entretenimento de cabeça, após acessar o rtcsdk, o host relatou que a placa de som externa tocava música, a qualidade do som não era boa e a qualidade do som ouvida pelo público não era boa.
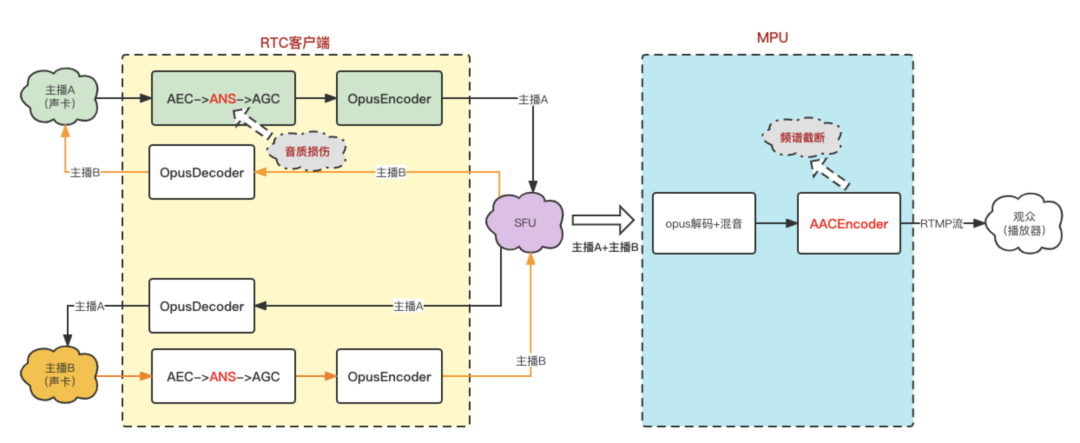
Análise de causa:
Lado do SDK: Quando o âncora A usa uma placa de som externa para enviar música de fundo, a qualidade do som da música ouvida pelo âncora B não é boa. O principal motivo é que o ANS (algoritmo de redução automática de ruído) na biblioteca de algoritmos 3A existe em alguns cenários Auto-teste danifica a música Causado, mas não causará truncamento de espectro, resolvido após otimização;
Lado do servidor: quando o mpu extrai os fluxos de duas âncoras e os mistura e depois os transcodifica em fluxos AAC, os parâmetros AAC Audioprofile definidos são LC, 64kbps, 1ch; a taxa de código desse conjunto de parâmetros levará à largura de banda de AAC Apenas 16kHz, ou seja, truncamento espectral. Quando a entrada é mono, áudio 48000 e a taxa de bits é 64kbps, o modo AAC LC é inferior ao modo AAC HEv1/HEv2 em termos de largura de banda e audição.
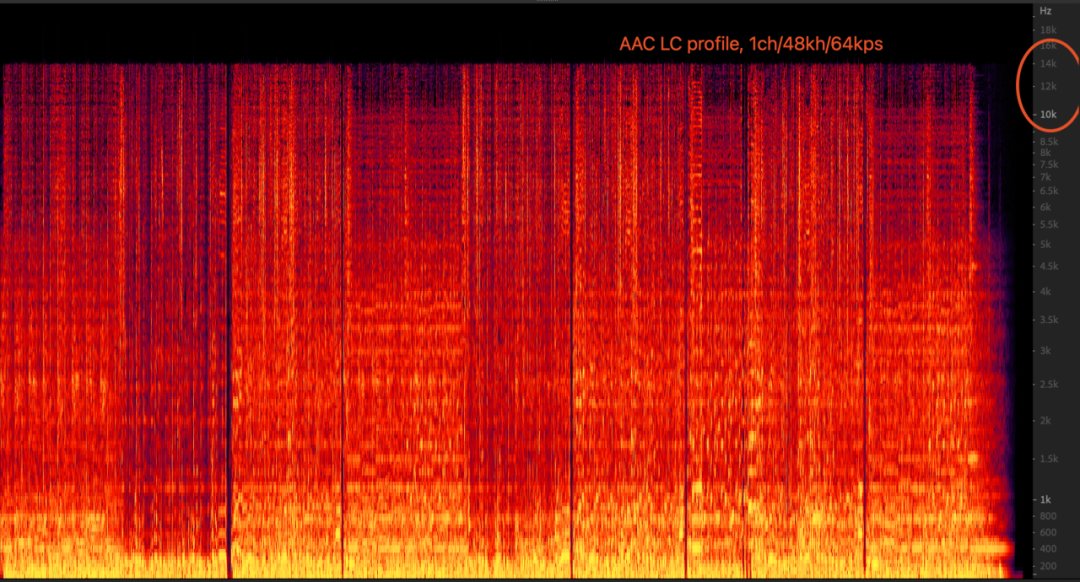
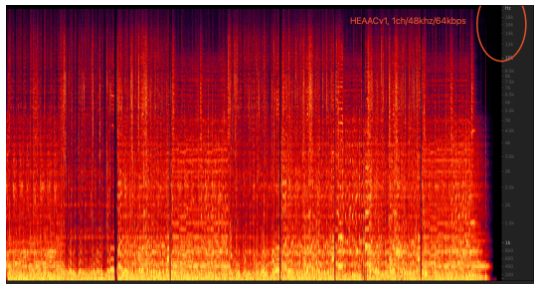
3.7 Tendência de evolução da indústria:
Devido à implementação simples de hardware 3A e consumo de energia relativamente baixo, tem sido a principal solução técnica no campo de rtc por um longo tempo. solução geral de software 3A de ponta já pode ser baseada em conteúdo de voz e música. Adapte-se à estratégia de algoritmo de ajuste, juntamente com a "lesão fatal" sob o hardware 3A - a baixa qualidade do som coletado e a grande diferença na experiência de diferentes dispositivos Android trouxe um grande custo de adaptação, a tendência de tecnologia de ponta do rtc mudou gradualmente para o puro Software 3A evoluiu. O software puro 3A pode oferecer aos usuários uma experiência de som de alta qualidade mais consistente em vários cenários e reduzir bastante a mão de obra de adaptação e os custos técnicos dos fabricantes de rtc, mas também requer suporte de capacidade de algoritmo 3A suficiente.
Para atender a diferentes requisitos de qualidade de som em diferentes cenários de negócios com um conjunto de SDKs, os fabricantes de rtc fornecerão diferentes AudioProfiles para diferenciar e fornecer configurações para usuários, consulte o Apêndice II para obter detalhes.
4. Resumo:
Este artigo combina a arquitetura de mecanismo de áudio comum em cenários RTC, desde a aquisição de equipamentos de áudio, processamento 3A, até codificador e neteq, e analisa os fatores que afetam a qualidade do som da latitude técnica, um por um. Combinando os diferentes requisitos de qualidade de som em vários cenários, como conferências, educação e entretenimento, este artigo expõe a estratégia de áudio e as considerações de seleção de soluções em diferentes cenários de negócios e, finalmente, faz uma análise pessoal e uma previsão da tendência de evolução do setor.
Apêndice 1: Exploração de largura de banda de aquisição de apenas 8Khz no modo VOIP
Fenômeno:
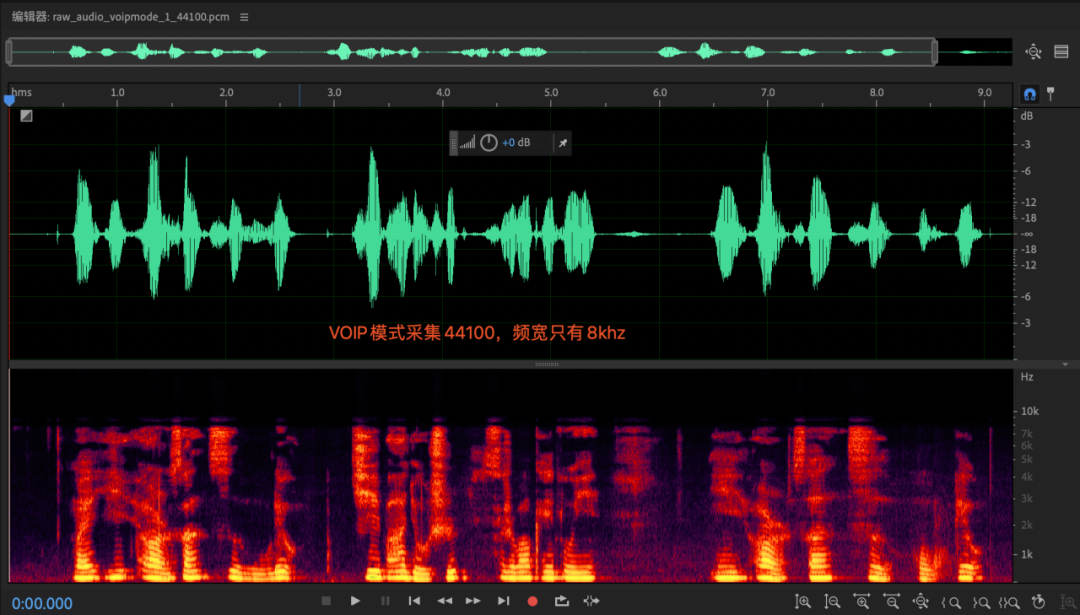
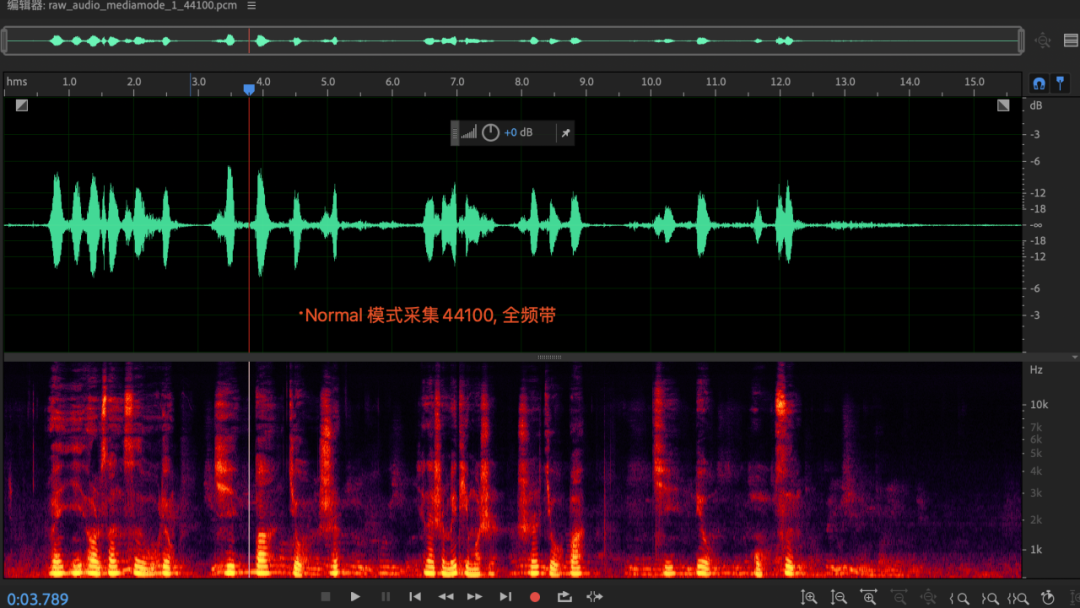
Quando a camada APP cria a coleção AudioRecord, com a mesma configuração de taxa de amostragem, a largura de banda efetiva coletada por diferentes modos de áudio é diferente. No modo voip, a largura de banda efetiva coletada é de apenas 8 khz, enquanto a largura de banda no modo normal é a frequência total normal banda.dados; (esse fenômeno também existe na plataforma ios), não tem nada a ver com celulares e chips;
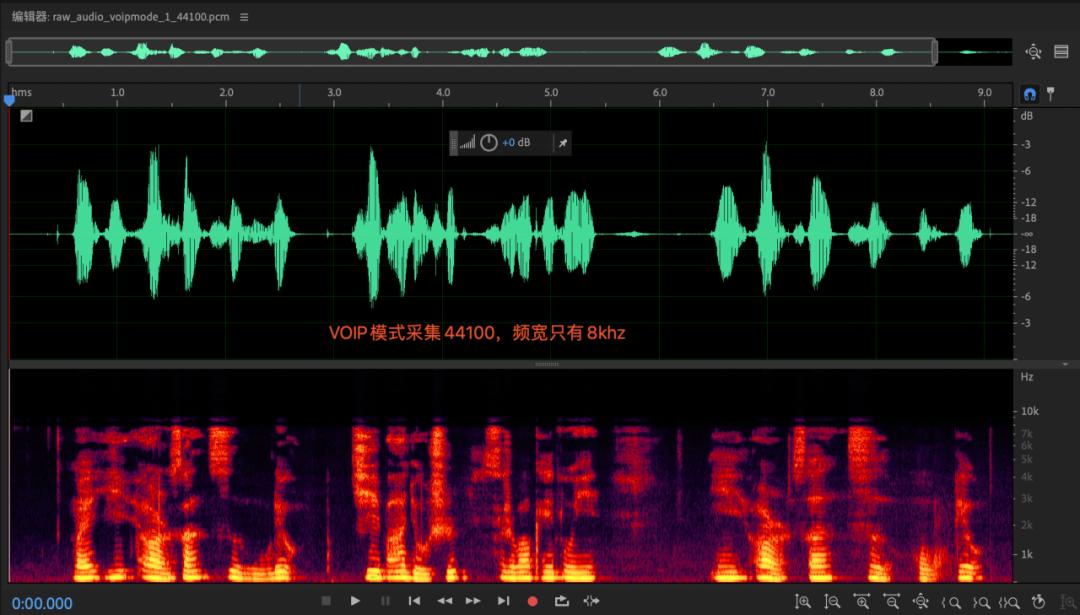
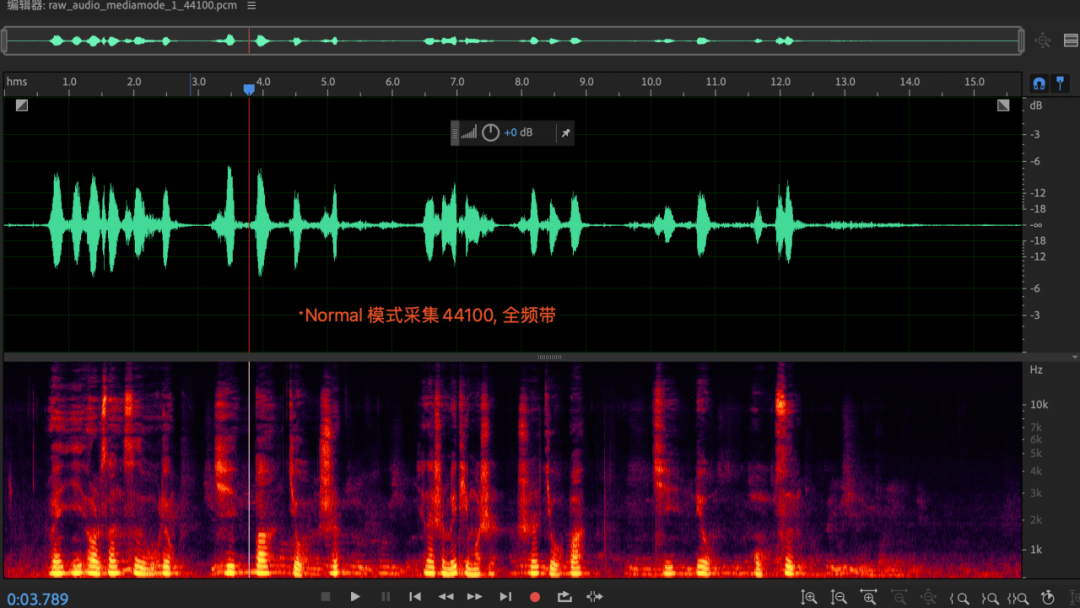
razão
Onde está o rootcase com largura de banda de 8 khz sob voip? (Suspeita-se que o hardware 3a suporta 16khz, e a reamostragem foi feita antes e depois do hardware 3a)
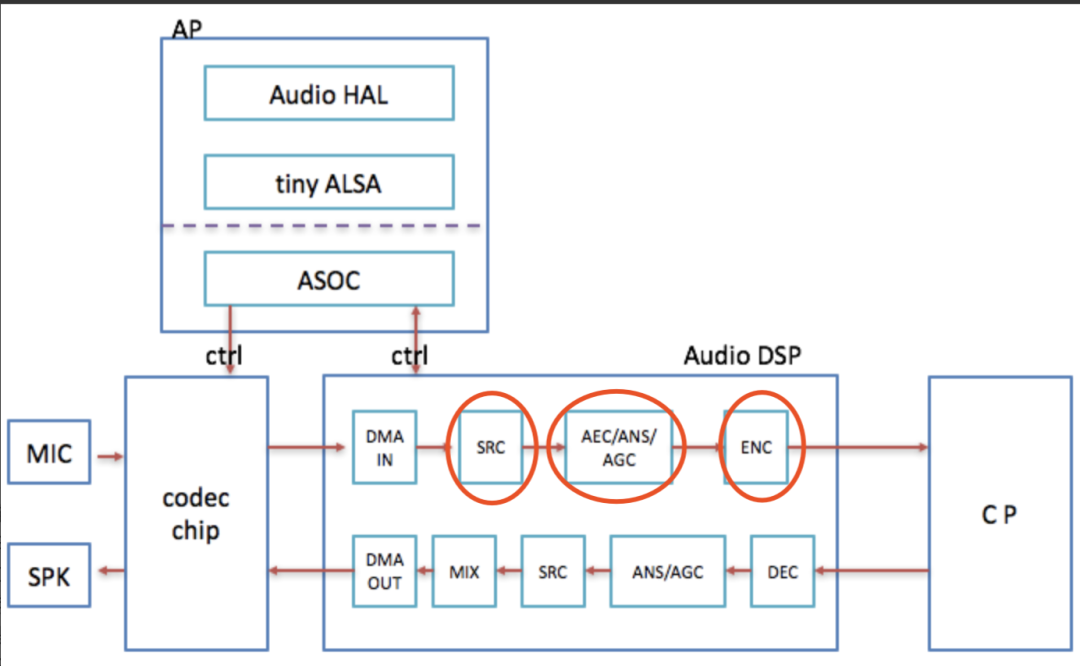
Razão: chip Qualcomm como exemplo, SRC está dentro do AudioDSP, no modo voip, enc é opcional, o SRC frontal será reduzido para 16khz, o audiodsp será aumentado para 48khz e os dados de 48khz serão fornecidos à camada AP ; SRC do chip MTK A lógica está fora do AudioDSP; o principal motivo é que o hardware 3A suporta apenas 16 khz. Por um lado, é devido à consideração do consumo de energia dsp (a complexidade do algoritmo aec é relativamente alta), e por outro lado, porque a codificação de voz do voip geralmente suporta apenas codificação de voz de 8 khz/16 khz;
Informação relevante:
https://www.cnblogs.com/talkaudiodev/p/8996338.html
https://www.cnblogs.com/talkaudiodev/p/8733968.html
exploração da solução
Solução 1: você pode considerar a introdução de um modo de bypass semelhante ao ios: kAUVoiceIOProperty_BypassVoiceProcessing
https://developer.apple.com/documentation/audiotoolbox/1534007-voice-processing_i_o_audio_unit_proper
O problema resolvido pelo modo bypass do ios: No modo voip, sob a barra de volume da chamada, o hardware 3A não está habilitado;
Solução 2: Adapte a lógica de controle do sistema Android nativo ao switch 3A do hardware
renda
A estratégia de hardware 3A pode ser controlada separadamente para obter a melhor configuração de qualidade de som em uma barra de volume (barra de volume de chamada), fornecendo aos desenvolvedores de APP mais maneiras de jogar;
Cenários específicos de aplicação: cenários que requerem a barra de volume (não pode ser ajustada para 0) e alta qualidade de som, por exemplo: cenários de educação musical;
Diferenças de equipamento
Huawei companheiro30:
modo de áudio: MODE_IN_COMMUNICATION + fonte de áudio: VOICE_COMMUNICATION a gravação é de 8 khz de largura de banda, (talvez devido a considerações de consumo de energia)
Oneplus 10R 5G:
audiomode: MODE_IN_COMMUNICATION + audiosouce: VOICE_COMMUNICATION, habilite hardware aec, a banda não será prejudicada, mas se houver uma thread de audiotrack iniciada, a lógica aec será acionada, resultando em banda reduzida;
Apêndice II: Definições relacionadas de AudioProfile
Consulte os documentos de interface relevantes da rede de som: https://docportal.shengwang.cn/cn/All/API%20Reference/java_ng/API/toc_audio_process.html#ariaid-title36
resumo público int setAudioProfile(perfil int, cenário int);
modo de codificação (perfil)
A relação correspondente entre a taxa de código de envio instantâneo é apenas um intervalo aproximado e é apenas para referência.Geralmente, o qos ajustará dinamicamente o número de pacotes redundantes e a taxa de código de destino de codificação de acordo com as condições da rede.

modo de cena:

O modo de cenário (cenário) afetará os parâmetros do dispositivo de áudio, estratégia de software 3A e estratégia de Qos relacionada, etc., e não tem nada a ver com a taxa de codificação; diferentes modos de cenário têm ênfase diferente no processamento de dados de áudio e correspondem a diferentes barras de volume Diferentes cenários de negócios e diferentes qualidade de som e indicadores técnicos relacionados são usados para seleção.
Apêndice III: Referências:
WebRTC AEC simples (cancelamento de eco acústico: https://developer.aliyun.com/article/781449?spm=a2c6h.14164896.0.0.70a21f36aoEDj7
Interpretação de áudio WebRTC NetEQ e prática de otimização em vernáculo: https://developer.aliyun.com/article/782756
Melhore a experiência de áudio RTC - comece entendendo o hardware: https://developer.aliyun.com/article/808257
Explicação detalhada sobre baixa latência e alta qualidade de som|Cancelamento de eco e redução de ruído: https://www.rtcdeveloper.cn/cn/community/blog/21147