Dans l'article précédent ARM Basics (3) : MPU Memory Protection Unit Detailed Explanation and Examples , j'ai présenté le MPU. Nous savons que le MPU permet de modifier les attributs du Cache de premier niveau par région. Ce Cache est généralement le Cache L1, qui est situé à l'intérieur du CPU. , utilisé pour accélérer l'accès aux instructions et aux données. Dans le même temps, le CPU doit assurer la cohérence des données entre le CPU et la mémoire principale lors du traitement des données partagées. Cet article présentera en détail le concept et l'utilisation du cache L1.
Annuaire d'articles
1 Le concept de cache L1 et de cache L2
(1) Cache L1
Dans l'architecture ARM, le Level 1cache L1 ( ) est le cache de premier niveau situé à l'intérieur du processeur pour stocker les instructions et les données. Le cache L1 est en outre divisé en cache d'instructions ( I-Cache) et en cache de données ( D-cache), qui sont respectivement dédiés au stockage des instructions et des données. I-CacheStocke les instructions exécutées par le CPU, tandis que D-cachestocke les données lues et écrites par le CPU.
I-CacheLe but de et D-cacheest de réduire l'accès à la mémoire principale en fournissant un accès plus rapide aux données. Lorsqu'un cœur de processeur doit exécuter une instruction, il la I-Cacherecherche d'abord en mémoire, et si l'instruction est déjà mise en cache en I-Cachemémoire, il peut l'exécuter immédiatement. De même, lorsqu'un cœur de processeur a besoin de lire ou d'écrire des données, il D-cacheles recherche d'abord, et si les données y sont déjà mises en cache D-cache, elles peuvent être consultées rapidement.
(2) Cache L2
Le cache L2 est situé entre le CPU et la mémoire principale en tant que cache de second niveau. Sa capacité est supérieure à celle du cache L1 et peut stocker plus de données, et le cache L2 est partageable. Il existe pour améliorer encore les taux d'accès au cache et les performances globales, ainsi que pour réduire la latence d'accès à la mémoire principale.
- Comparé au cache L2, le cache L1 est plus proche du cœur du processeur, il a donc une latence d'accès plus faible et une bande passante plus élevée, mais en fait la vitesse d'accès L2 n'est pas faible.
2 Cache L1 dans Cortex-M7
2.1 Lignes de cache
Le cache L1 du processeur Cortex-M7 est divisé en lignes de 32 octets et chaque ligne est marquée d'une adresse. Autrement dit, la taille de chaque ligne de cache est de 32 octets et la ligne de cache est l'unité de base du cache L1. Parmi eux, D-Cacheil s'agit d'un groupe associatif à 4 voies (chaque groupe de cache peut stocker quatre lignes de cache, et chaque ligne de cache a une marque pour indiquer l'emplacement de la ligne de cache dans la mémoire principale), et chaque groupe a quatre lignes , alors I-Cachequ'il est un ensemble associatif à 2 voies. Un cache plus grand augmentera le coût, et une associativité d'ensemble plus élevée peut améliorer le taux de réussite, mais cela augmentera également le coût et la complexité, donc le D-Cacherégler sur 4 voies et I-Cachele régler sur 2 voies est un compromis matériel.
2.2 Accès au cache et remplacement
S'il y a un accès au cache, les données sont soit lues à partir du cache, soit utilisées pour mettre à jour la mémoire principale. S'il y a un manque de cache, une nouvelle ligne de cache est allouée et marquée, et les données de lecture ou d'écriture sont remplies dans le cache. Si toutes les lignes de cache sont allouées, le contrôleur de cache exécute le processus de remplacement de ligne de cache, qui sélectionne une ligne pour le nettoyage et la réallocation. D-Cacheet I-Cachemet en œuvre un algorithme de remplacement pseudo-aléatoire pour sélectionner la ligne de cache à remplacer. Cet algorithme peut améliorer le caractère aléatoire du processus de remplacement de la ligne de cache, utilisant ainsi efficacement l'espace de cache et améliorant le taux de réussite du cache.
2.3 Cache L1 du RT1170
Dans le Cortex-M7, le cache L1 est Advanced eXtensible Interfaceconnecté au bus AXI ( ) du CPU, et la récupération des données de la mémoire ou l'écriture des données dans la mémoire est réalisée par ce bus.
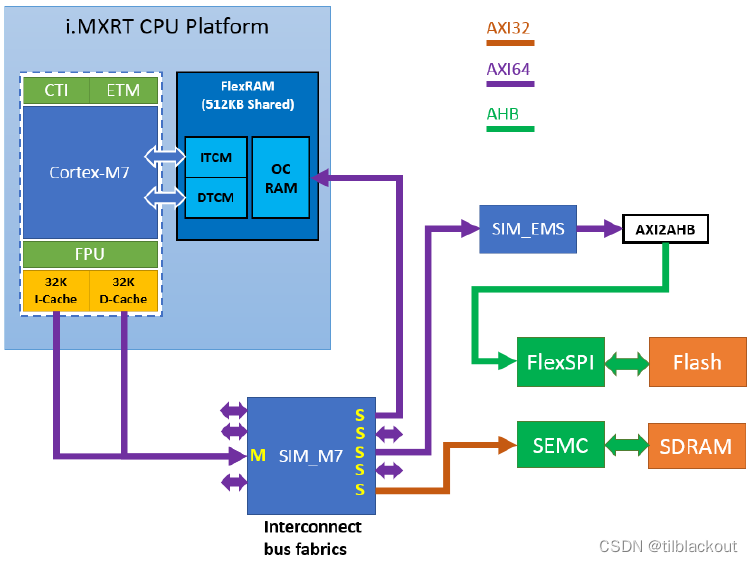
Prenons I.MX RT1170 comme exemple. Il s'agit d'un processeur double cœur. Pour CM7 , il existe un I-Cache de 32 Ko et un D-cache de 32 Ko. ITCMet DTCMson accès n'a pas besoin de passer par le Cache L1, et la vitesse est très rapide, il est donc recommandé de mettre le code et les données dans la section critique TCM, comme une table vectorielle. Il convient de noter que la mémoire TCM est toujours non-Cacheableadditionnée non-Shareable, quels que soient les paramètres MPU.
3 Fonctions liées au cache
Les fonctions associées de l'opération de cache sont toutes basées sur la norme de développement CMSIS, et les fonctions sont définies dans core_cm7.h, comme indiqué dans le tableau suivant :
| Fonction CMSIS | Description |
|---|---|
| annuler SCB_EnableICache (annuler) | Invalider puis activer le cache d'instructions |
| annuler SCB_DisableICache (annuler) | Désactiver le cache d'instructions et invalider son contenu |
| annuler SCB_InvalidateICache (annuler) | Invalider le cache d'instructions |
| annuler SCB_EnableDCache (annuler) | Invalider puis activer le cache de données |
| annuler SCB_DisableDCache (annuler) | Désactivez le cache de données, puis nettoyez et invalidez son contenu |
| annuler SCB_InvalidateDCache (annuler) | Invalider le cache de données |
| annuler SCB_CleanDCache (annuler) | Nettoyer le cache de données |
| annuler SCB_CleanInvalidateDCache (annuler) | Nettoyer et invalider le cache de données |
Cache clean: écrivez la ligne de cache avec le drapeau sale dans la mémoire, ce qui peut être compris commeflushInvalidate cache: marquez toutes les données valides dans le cache comme invalides, ce qui signifie que lors du prochain accès aux données, le système ne lira pas à partir du cache, mais obtiendra les dernières données de la mémoire principale ou d'autres caches de niveau inférieur. Le cache d'invalidation peut garantir que les dernières données sont lues, en particulier lorsque d'autres appareils ou processeurs modifient les données dans la zone de stockage.
Les utilisateurs doivent uniquement définir les propriétés des différentes régions de mémoire dans le MPU, puis activer la mise en cache via les fonctions CMSIS répertoriées ci-dessus. Par exemple, l'utilisateur peut configurer si le MPU est utilisé write-backou write-throughpour opérer sur le cache.
write-back: Avant la fin de l'opération de nettoyage, les données du cache ne seront pas écrites dans la mémoire principalewrite-through: Une fois que le contenu de la ligne de cache est écrit, il est mis à jour dans la mémoire principale. Ceci est plus sûr pour la cohérence des données, mais nécessite plus d'accès au bus.- En pratique,
write-throughil n'y a qu'un faible impact, à moins que le même jeu de cache ne soit accédé de manière répétée et très rapidement. La manière d'utiliser est donc un compromis.
- En pratique,
write-alloction: Lorsqu'il y a un manque de cache, une nouvelle ligne de cache doit être allouée pour les opérations d'écriture et de lecture.
4 Comment assurer la cohérence des données du Cache
Le cache peut grandement améliorer les performances du processeur, mais les utilisateurs doivent faire attention à la maintenance du cache et à la cohérence des données.
4.1 Exemple : Lecture audio dans Flash
Supposons que nous voulions lire un fichier audio stocké dans Flash externe. L'organigramme de données et la relation de connexion sont les suivants :
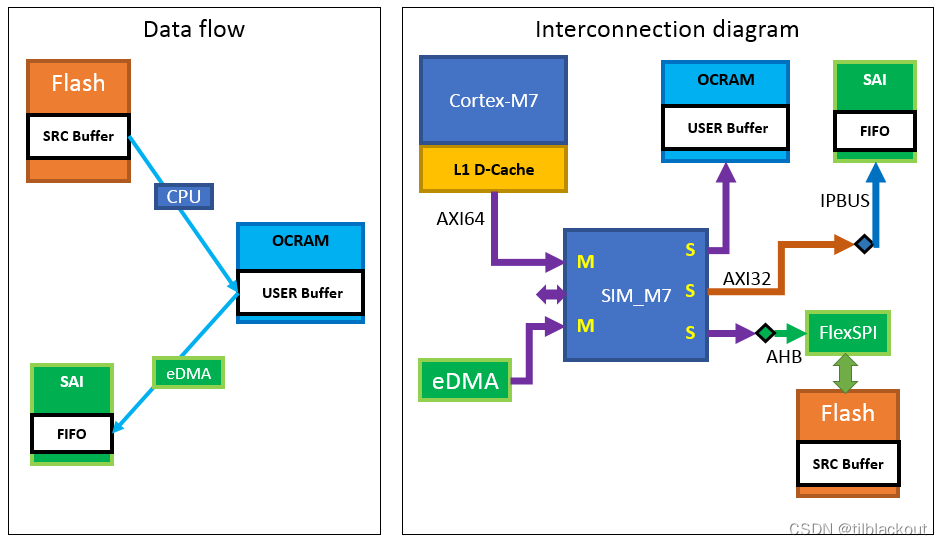
la CPU L1 D-Cachelit le contenu du fichier audio dans le tampon SRC, décode les Pulse Code Modulationdonnées de trame PCM ( ) et les écrit dans le tampon USER d'OCRAM. Une fois la mémoire tampon utilisateur pleine, l'eDMA commence à copier les données de trame PCM dans la FIFO à l'intérieur du bloc IP SAI. Le SAI utilise ensuite une opération de décalage pour déplacer les données FIFO vers le bus SAI pour la lecture audio. Lorsque le processeur écrit des données de trame dans OCRAM avec le cache L1 activé, puisque la politique de cache par défaut d'OCRAM est write-back, les données ne peuvent être écrites que dans le cache. Les données transférées par eDMA vers SAI FIFO sont incorrectes, ce qui entraîne des problèmes de cohérence des données. Il existe plusieurs solutions pour résoudre ce problème :
- Une fois que le CPU a écrit les données dans OCRAM, il effectue l'opération de nettoyage du D-Cache
- Avant le début de l'opération d'écriture, définissez la stratégie de cache de la zone de mémoire OCRAM
write-backà partir dewrite-through - Configurez la stratégie de cache de la zone de mémoire OCRAM comme
non-cacheable - Configurez la zone de mémoire OCRAM en tant que
shareable, ce qui corrigera la politique de cache en tant quenon-cacheable.
4.2 Utilisation de tampons pouvant être mis en cache
Pour le tampon défini dans OCRAM et SRAM, c'est généralement Cacheableet la stratégie Cache est write-back. Si le tampon défini ici doit être utilisé comme source de DMA, l'utilisateur doit effectuer une D-Cacheopération d'effacement avant le démarrage du DMA, c'est-à-dire SCB_CleanDCache(), si le tampon est utilisé comme cible du DMA, après la fin du DMA et avant le CPU ou un autre hôte lit les données, doit être exécuté SCB_InvalidateDCache.
- L'adresse du tampon doit être alignée en fonction de la taille de la ligne de cache L1, qui est de 32 octets dans Cortex-M7
4.3 Utilisation de tampons non cachables
L'utilisation du buffer défini dans non-cacheablela zone mémoire résout directement le problème de cohérence des données, mais comme aucun cache n'est utilisé, la vitesse d'accès à ce buffer sera beaucoup plus lente.
Enfin, prenez MCUXPresso IDE comme exemple pour voir comment en définir un non-cacheable buffer: (1) Le segment mémoire
ajouté dans le script de liennon-cacheable
Pour MCUXPresso IDE, il peut être modifié directement dans l'interface graphique :
①Ajouter NCACHE_REGION dans les détails de la mémoire
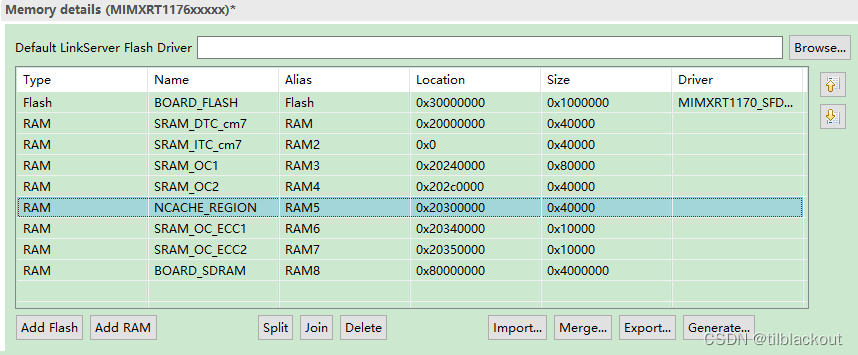
②Ajouter une section d'entrée dans le script de lien

(2) Configuration MPU
Pour DTCM, la configuration de 16 groupes de MPU peut être remplacée en fonction de la priorité. Ainsi dans le code ci-dessus, nous configurons d'abord la politique de cache de DTCM par défaut Write-back, no write allocate, le code est le suivant :
MPU->RBAR = ARM_MPU_RBAR(5, 0x20000000U);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 0, 0, 1, 1, 0, ARM_MPU_REGION_SIZE_256KB);
Ensuite, nous devons configurer non-cacheablele MPU dans la zone, le code est le suivant :
extern uint32_t __base_NCACHE_REGION;
extern uint32_t __top_NCACHE_REGION;
uint32_t nonCacheStart = (uint32_t)(&__base_NCACHE_REGION);
uint32_t size = (uint32_t)(&__top_NCACHE_REGION) - nonCacheStart;
volatile uint32_t i = 0;
while ((size >> i) > 0x1U)
{
i++;
}
if (i != 0)
{
/* The MPU region size should be 2^N, 5<=N<=32, region base should be multiples of size. */
assert(!(nonCacheStart % size));
assert(size == (uint32_t)(1 << i));
assert(i >= 5);
/* Region 10 setting: Memory with Normal type, not shareable, non-cacheable */
MPU->RBAR = ARM_MPU_RBAR(10, nonCacheStart);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 1, 0, 0, 0, 0, i - 1);
}
evkmimxrt1170_freertos_hello_cm7_Debug_memory.ldExaminons d'abord les définitions pertinentes dans le fichier de script de lien :
__base_NCACHE_REGION = 0x20300000 ; /* NCACHE_REGION */
__base_RAM5 = 0x20300000 ; /* RAM5 */
__top_NCACHE_REGION = 0x20300000 + 0x40000 ; /* 256K bytes */
En langage C, vous pouvez directement utiliser extern pour obtenir les variables définies dans le script de lien, donc __base_NCACHE_REGION et __top_NCACHE_REGIONcorrespondent en fait à celles que nous venons d'ajouter dans Memory details NCACHE_REGION. Ensuite, le code précédent consiste à trouver le plus petit entier isupérieur 2^iou égal à la variable size, puis à juger de la légalité des paramètres : si la taille de la zone entière est un multiple de 2, si la taille est supérieure à un ligne de cache, etc. En même temps ARM_MPU_RASR, le dernier paramètre, la taille de la zone mémoire, peut i-1être exprimé en 2^ioctets.
La dernière consiste à appeler ARM_MPU_RASRet configurer le MPU, où TEX1 Cet B0 indiquent que le type de cette mémoire est Normal, et la politique de cache est non-cacheable.
(3) Définir des variables et un lien vers NCACHE_REGION
Nous pouvons utiliser __attribute(section())des mots-clés pour spécifier à quel segment la variable est liée, et cette macro est fournie dans MCUXPresso IDE :
#define AT_NONCACHEABLE_SECTION_ALIGN(var, alignbytes) \
__attribute__((section("NonCacheable,\"aw\",%nobits @"))) var __attribute__((aligned(alignbytes)))
Il nobitsindique que ce segment est un segment bss et n'a pas besoin d'être écrit dans Flash. L'attribut d'alignement des octets est également ajouté ici. Généralement, nous avons un alignement sur 4 octets, mais certains cas d'utilisation particuliers ont des exigences d'alignement d'octets particulières, par exemple, un alignement sur eLCDIF8 framebufferoctets est requis.