Autor: Equipe de Tecnologia de Armazenamento da Vivo Internet - Hang Zhengbo
Este documento apresenta o princípio, o processo e a estratégia de limitação atual da compactação HBase em detalhes, lista vários casos de ajuste online e, finalmente, resume os parâmetros relevantes da compactação.
1. Introdução à Compactação
O HBase foi projetado com base em um modelo de armazenamento da arquitetura LSM-Tree (Log-Structured Merge Tree). condições forem atendidas, a operação Flush será executada para liberar os dados em cache para o disco e gerar um arquivo de dados HFile. À medida que os dados continuam a ser gravados, haverá cada vez mais arquivos HFile. Muitos arquivos aumentarão o número de IOs ao consultar dados, o que afetará o desempenho da consulta do HBase. Para otimizar o desempenho da leitura, é utilizado o método de mesclagem de HFiles pequenos para reduzir o número de arquivos, essa operação de mesclagem de HFiles é chamada de Compactação. A compactação é o processo de seleção de alguns arquivos HFile de um armazenamento em uma região para mesclagem. O princípio da mesclagem é ler o KeyValue sequencialmente dos arquivos de dados a serem mesclados, classificá-los do menor ao maior e gravá-los em um novo arquivo. Posteriormente, esse arquivo recém-gerado substituirá todos os arquivos mesclados anteriormente e fornecerá serviços externos.
1.1 Classificação da Compactação
O HBase divide a compactação em dois tipos de acordo com o tamanho da consolidação: compactação secundária e compactação principal.
-
Compactação secundária refere-se à seleção de alguns HFiles pequenos e adjacentes e sua fusão em um HFile maior;
-
A compactação principal refere-se à fusão de todos os HFiles em um armazenamento em um HFile. Esse processo limpará três dados sem sentido: dados TTL expirados, dados excluídos e dados cujo número de versão excede o número de versão definido.
A figura a seguir descreve vividamente a diferença entre os dois tipos de compactação:
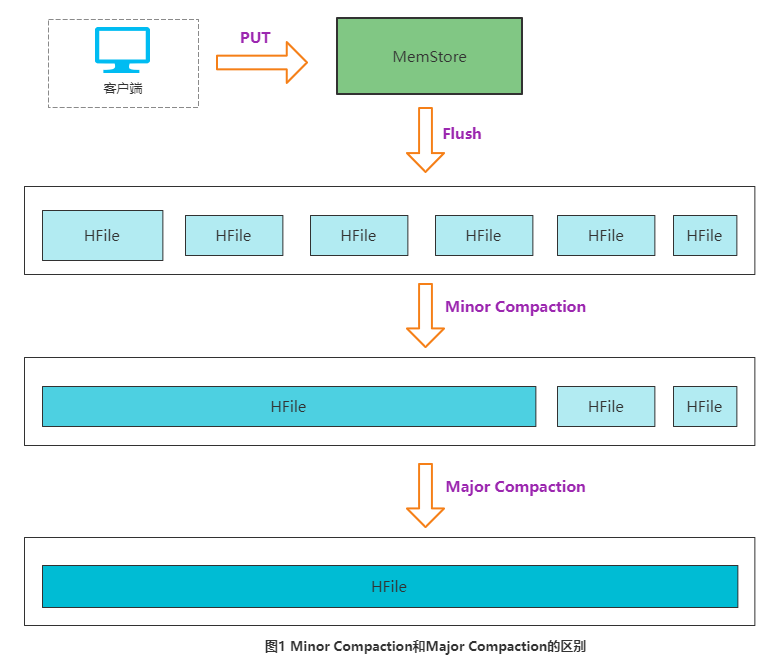
Em circunstâncias normais, a compactação principal dura muito tempo e todo o processo consome muitos recursos do sistema. Portanto, para empresas com uma grande quantidade de dados online, geralmente é recomendável desativar a função de acionar automaticamente a compactação principal e manualmente acioná-lo durante os períodos de baixo pico de negócios (ou definir uma política para disparar automaticamente durante os períodos de baixo pico).
1.2 Significado da Compactação
-
Mescle arquivos pequenos, reduza o número de arquivos, melhore o desempenho de leitura e estabilize atrasos de leitura aleatórios;
-
Ao mesclar, os arquivos no DataNode remoto serão lidos e gravados no DataNode local para melhorar a taxa de localização dos dados;
-
Limpe os dados expirados e os dados excluídos para reduzir a capacidade de armazenamento da tabela.
1.3 Tempo de disparo da compactação
Há muitos tempos para acionar a compactação no HBase, e há três momentos de acionamento mais comuns : acionador de verificação periódica do encadeamento em segundo plano, acionador MemStore Flush e acionador manual.
(1) Verificação periódica do encadeamento em segundo plano : O CompactionChecker do encadeamento em segundo plano verificará periodicamente se a compactação precisa ser executada e o ciclo de verificação é hbase.server.thread.wakefrequency *hbase.server.compactchecker.interval.multiplier. A principal consideração aqui é que não há Flush não pode acionar Compactação devido a uma solicitação de gravação. O valor padrão do parâmetro hbase.server.thread.wakefrequency é 10s, que é o intervalo de ativação do encadeamento do servidor HBase, e o valor padrão do parâmetro hbase.server.compactchecker.interval.multiplier é 1000, que é o multiplicador fator para a verificação periódica da operação de Compactação. 10 * 1000 s é aproximadamente igual a 2 horas e 46 minutos e 40 segundos.
(2) MemStore Flush : A raiz da compactação está no Flush. Quando o MemStore atingir um determinado limite, o Flush será acionado e os dados na memória serão liberados no disco para gerar arquivos HFile. À medida que mais e mais arquivos HFile se tornam disponíveis, A compactação precisa ser executada. Após cada Flush, o HBase julgará se deve realizar a Compactação e, assim que as condições de Compactação Menor ou Compactação Principal forem atendidas, a execução será acionada.
(3) Manual : refere-se à execução de comandos como compact e major_compact por meio da API HBase, HBase Shell ou interface Master UI.
2. Processo de compactação
Depois de entender o background básico, vamos apresentar todo o processo de Compactação.
-
RegionServer inicia um encadeamento de verificação de compactação para verificar o armazenamento da região regularmente;
-
A compactação começa com condições de disparo específicas. Uma vez acionado, o HBase entregará a compactação a um thread independente para processamento;
-
Selecione o arquivo HFile apropriado na loja correspondente. Esta etapa é o núcleo de toda a compactação. Muitas condições precisam ser seguidas ao selecionar arquivos, como o número de arquivos não deve ser muito ou pouco, e o tamanho do arquivo deve não seja muito grande Selecione o máximo possível Hosts IO-heavy filesets. Com base nisso, o HBase implementa uma variedade de estratégias de seleção de arquivos: comumente usadas são
RatioBasedCompactionPolicy, ExploringCompactionPolicy e StripeCompactionPolicy também oferecem suporte a algoritmos de compactação personalizados;
-
Após a seleção dos arquivos a serem mesclados, o pool de threads correspondente será selecionado para processamento de acordo com o tamanho total desses arquivos HFile;
-
Execute operações específicas de compactação nesses arquivos.
A figura abaixo descreve resumidamente o processo acima.
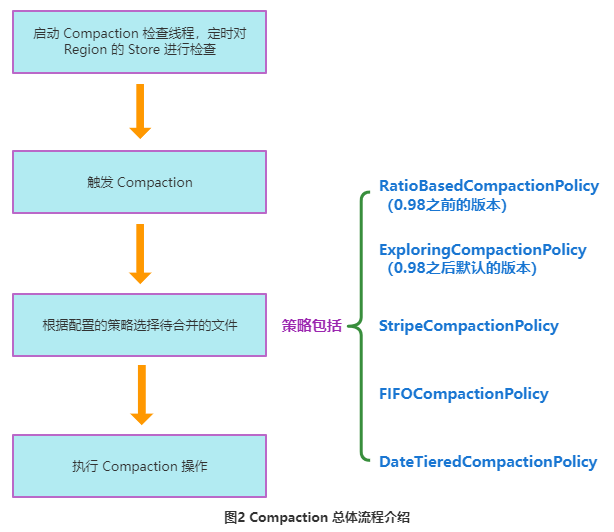
Cada etapa específica na FIG. 2 será descrita em detalhes abaixo.
2.1 Inicie o segmento de sincronização de compactação
Quando o RegionServer for iniciado, ele inicializará o thread CompactSplitThread e o CompactionChecker para verificações regulares, que são executadas a cada 10s por padrão.
// Compaction thread
this.compactSplitThread = new CompactSplitThread(this);
// Background thread to check for compactions; needed if region has not gotten updates
// in a while. It will take care of not checking too frequently on store-by-store basis.
this.compactionChecker = new CompactionChecker(this, this.threadWakeFrequency, this);
if (this.compactionChecker != null) choreService.scheduleChore(compactionChecker);Entre eles, o CompactSplitThread é usado para realizar a classe de processo de compactação e divisão, e o CompactChecker é usado para verificar periodicamente se a compactação deve ser executada.
CompactionChecker é do tipo ScheduledChore e ScheduledChore é uma tarefa que o HBase executa periodicamente.
2.2 Compactação do Gatilho
O tempo de ativação da Compactação foi apresentado acima, e os três mecanismos de ativação serão apresentados em detalhes abaixo.
2.2.1 Verificação periódica do encadeamento em segundo plano
O thread de segundo plano CompactChecker verifica periodicamente se a compactação precisa ser executada e o período de verificação é hbase.regionserver.compaction.check.period (padrão 10s).
(1) Primeiro verifique se o número de arquivos é maior que o número de arquivos que podem executar a compactação e, quando for maior, a compactação será acionada.
(2) Se não for satisfeito, verificará se é o ciclo de execução da Compactação Maior. Se o tempo de atualização mais antigo do HFile no armazenamento atual for anterior a um determinado valor mcTime, a compactação principal será acionada, onde mcTime é um valor flutuante e o intervalo flutuante é padronizado para [7-7*0,2, 7+7*0,2 ], em que 7 é O item de configuração hbase.hregion.majorcompaction está definido e 0,2 é o item de configuração hbase.hregion.majorcompaction.jitter, portanto, uma compactação principal será executada em cerca de 7 dias. Se os usuários quiserem desabilitar a compactação principal, eles só precisam definir o parâmetro hbase.hregion.majorcompaction como 0.
(3) Se tratando do ciclo de execução da Compactação Maior:
-
Primeiro, determine quantos arquivos HFile existem. Se houver apenas um arquivo, ele determinará se há dados expirados e se a taxa de localização é relativamente baixa. Se não for satisfeita, a compactação principal não será feita;
-
Se for maior que 1 arquivo, a compactação principal também será feita.
O fluxo da verificação periódica da thread em segundo plano é mostrado na Figura 3.
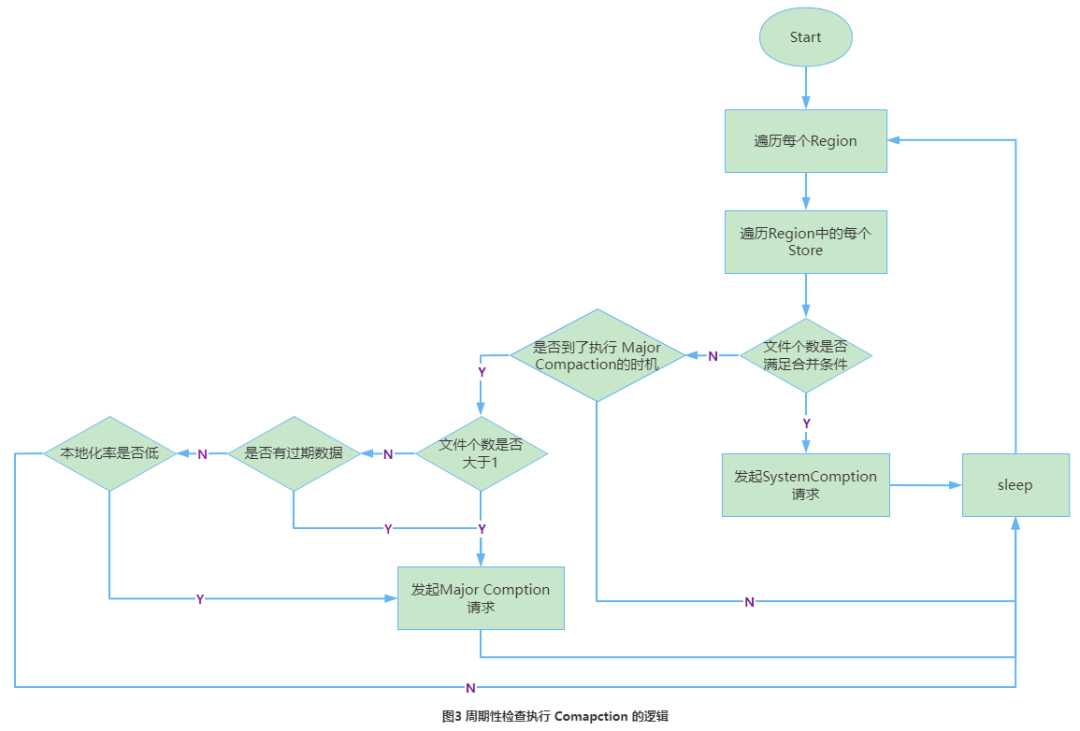
Aqui está o código-chave deste tópico:
//ScheduledChore的run方法会一直调用chore函数
@Override
protected void chore() {
// 遍历instance下的所有online的region 进行循环检测
// onlineRegions是HRegionServer上存储的所有能够提供有效服务的在线Region集合;
for (HRegion r : this.instance.onlineRegions.values()) {
if (r == null)
continue;
// 取出每个region的store
for (Store s : r.getStores().values()) {
try {
// 检查是否需要compact的时间间隔 hbase.server.compactchecker.interval.multiplier * hbase.server.thread.wakefrequency,multiplier默认1000;
long multiplier = s.getCompactionCheckMultiplier();
assert multiplier > 0;
// 未到multiplier的倍数跳过,每当迭代因子iteration为合并检查倍增器multiplier的整数倍时,才会发起检查
if (iteration % multiplier != 0) continue;
// 需要合并的话,发起SystemCompaction请求,此处最终比较的是是否当前hfile数量减去正在compacting的文件数大于设置的compact min值。若满足则执行systemcompact
if (s.needsCompaction()) {
// Queue a compaction. Will recognize if major is needed.
this.instance.compactSplitThread.requestSystemCompaction(r, s, getName()
+ " requests compaction");
} else if (s.isMajorCompaction()) {
if (majorCompactPriority == DEFAULT_PRIORITY
|| majorCompactPriority > r.getCompactPriority()) {
this.instance.compactSplitThread.requestCompaction(r, s, getName()
+ " requests major compaction; use default priority", null);
} else {
this.instance.compactSplitThread.requestCompaction(r, s, getName()
+ " requests major compaction; use configured priority",
this.majorCompactPriority, null);
}
}
} catch (IOException e) {
LOG.warn("Failed major compaction check on " + r, e);
}
}
}
iteration = (iteration == Long.MAX_VALUE) ? 0 : (iteration + 1);
}2.2.2 Gatilho de liberação do Memstore
Memstore Flush irá gerar arquivos HFile, e cada vez mais arquivos requerem Compactação. Portanto, após cada operação de Flush ser executada, o número de arquivos no armazenamento atual será julgado. Assim que o número de arquivos exceder o limite de compactação, a compactação será acionada. O que precisa ser enfatizado aqui é que a compactação é realizada em unidades de lojas, e na condição de acionamento do Flush, todas as lojas de toda a região realizarão a compactação, portanto a compactação poderá ser realizada várias vezes em um curto período de tempo. A seguir está o código para a operação Flush para acionar a Compactação.
/**
* Flush a region.
* @param region Region to flush.
* @param emergencyFlush Set if we are being force flushed. If true the region
* needs to be removed from the flush queue. If false, when we were called
* from the main flusher run loop and we got the entry to flush by calling
* poll on the flush queue (which removed it).
* @param forceFlushAllStores whether we want to flush all store.
* @return true if the region was successfully flushed, false otherwise. If
* false, there will be accompanying log messages explaining why the region was
* not flushed.
*/
private boolean flushRegion(final Region region, final boolean emergencyFlush,
boolean forceFlushAllStores) {
synchronized (this.regionsInQueue) {
FlushRegionEntry fqe = this.regionsInQueue.remove(region);
// Use the start time of the FlushRegionEntry if available
if (fqe != null && emergencyFlush) {
// Need to remove from region from delay queue. When NOT an
// emergencyFlush, then item was removed via a flushQueue.poll.
flushQueue.remove(fqe);
}
}
lock.readLock().lock();
try {
// flush
notifyFlushRequest(region, emergencyFlush);
FlushResult flushResult = region.flush(forceFlushAllStores);
// 检查是否需要compact
boolean shouldCompact = flushResult.isCompactionNeeded();
// We just want to check the size
// 检查是否需要split
boolean shouldSplit = ((HRegion)region).checkSplit() != null;
if (shouldSplit) {
this.server.compactSplitThread.requestSplit(region);
} else if (shouldCompact) {
// 发起compact请求
server.compactSplitThread.requestSystemCompaction(
region, Thread.currentThread().getName());
}
} catch (DroppedSnapshotException ex) {
// Cache flush can fail in a few places. If it fails in a critical
// section, we get a DroppedSnapshotException and a replay of wal
// is required. Currently the only way to do this is a restart of
// the server. Abort because hdfs is probably bad (HBASE-644 is a case
// where hdfs was bad but passed the hdfs check).
server.abort("Replay of WAL required. Forcing server shutdown", ex);
return false;
} catch (IOException ex) {
LOG.error("Cache flush failed" + (region != null ? (" for region " +
Bytes.toStringBinary(region.getRegionInfo().getRegionName())) : ""),
RemoteExceptionHandler.checkIOException(ex));
if (!server.checkFileSystem()) {
return false;
}
} finally {
lock.readLock().unlock();
wakeUpIfBlocking();
}
return true;
}2.2.3 Gatilho manual
O acionamento manual é para acionar manualmente a compactação por meio de comandos ou interfaces API. Há três motivos para o acionamento manual:
-
Muitas empresas estão preocupadas com o fato de que a compactação principal automática afetará o desempenho de leitura e gravação;
-
O usuário deseja entrar em vigor imediatamente após modificar o atributo ttl e aciona manualmente a compactação principal;
-
Quando a capacidade do disco rígido for insuficiente, acione manualmente a compactação principal para excluir uma grande quantidade de dados expirados.
A maioria deles é acionada manualmente com base no primeiro motivo.
2.3 Selecione os arquivos a serem mesclados
O núcleo da compactação é selecionar o arquivo apropriado para mesclar, porque o tamanho do arquivo mesclado e o IO atualmente carregado por ele determinam diretamente o efeito da compactação. Espero encontrar esse arquivo: ele carrega um grande número de solicitações de IO, mas o tamanho do arquivo é pequeno, de modo que a própria compactação não consuma muito IO e o desempenho de leitura será significativamente melhorado após a conclusão da mesclagem. Na realidade, isso pode não ser o caso para a maior parte. Atualmente, o HBase fornece várias estratégias de seleção de arquivo de compactação secundária, que são definidas por meio do item de configuração hbase.hstore.engine.class. Independentemente da estratégia, algumas operações de filtragem devem ser realizadas nos arquivos antes da execução para excluir arquivos não qualificados, de forma a reduzir a carga de trabalho da compactação e reduzir o impacto na leitura e gravação.
-
Excluir arquivos que estão executando compactação no momento;
-
Se todos os registros em um arquivo tiverem expirado, exclua o arquivo diretamente;
-
Exclua um único arquivo que seja muito grande. Se o tamanho do arquivo for maior que hbase.hstore.compaction.max.size (o valor máximo Longo padrão), ele será excluído e uma grande quantidade de consumo de E/S não será excluída.
Os arquivos restantes após a exclusão são chamados de arquivos candidatos e, em seguida, será julgado se as condições de compactação principal foram atendidas e, em caso afirmativo, todos os arquivos serão selecionados para mesclagem. Existem três condições de julgamento a seguir, e a Compactação Maior será executada desde que uma delas seja atendida:
-
Não é aplicável se a execução automática da Compactação Principal for desativada quando o ciclo de execução automática da Compactação for atingido e o número de arquivos candidatos for menor que hbase.hstore.compaction.max (padrão 10);
-
O Store contém um arquivo de referência, que é um arquivo de referência temporário gerado pela região dividida e é excluído durante o processo de compactação;
-
Maior compactação realizada manualmente pelo usuário.
Se as condições de execução acima não forem atendidas, trata-se de compactação Menor. Existem muitas políticas para compactação secundária. As seguintes focarão nas políticas de execução de RationBasedCompactionPolicy (versão anterior a 0.98), ExploringCompactionPolicy (versão padrão após 0.98) e StripeCompactionPolicy.
2.3.1 Modelagem da estratégia de seleção de arquivos de compactação
A chamada estratégia de seleção de arquivos de compactação pode ser modelada como o seguinte problema:
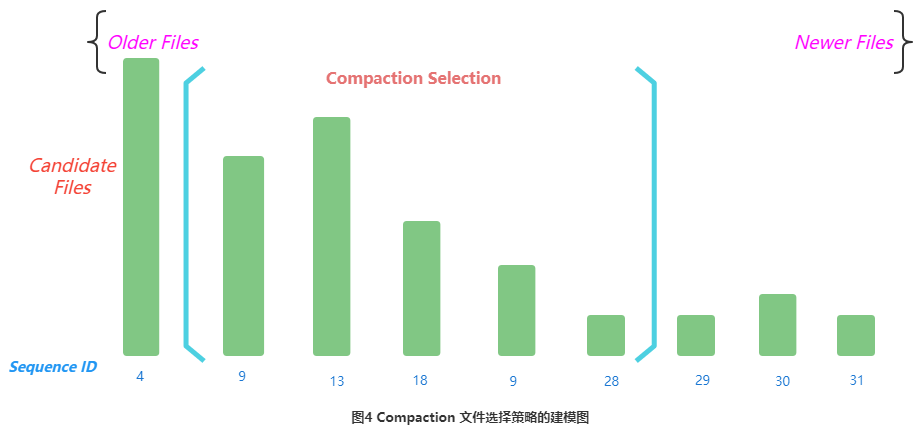
Cada número na figura representa o Sequence ID do arquivo. Quanto maior o número, mais novo o arquivo. É provável que ele tenha acabado de ser liberado, o que significa que o tamanho do arquivo também pode ser menor. Esses arquivos são preferidos durante a compactação, portanto, os arquivos Storefile no armazenamento serão classificados de pequeno a grande de acordo com a ID da sequência e marcados como f[0], f[1]...f[n-1] por vez , e filtrado A estratégia é determinar o Storefile dentro de um intervalo contínuo [Início, Fim] para participar da Compactação.
O objetivo da compactação é reduzir o número de arquivos, excluir dados inúteis e otimizar o desempenho de leitura. A implementação da compactação é reescrever o conteúdo do arquivo original em um novo arquivo. Se o arquivo for muito grande, significa que o A compactação leva muito tempo e o IO gerado durante o processo de compactação é ampliado. O mais óbvio, portanto, o critério para triagem de arquivo é usar o custo mínimo de IO para mesclar e reduzir ao máximo o número de arquivos.
A compactação depende de dois pré-requisitos:
-
Todos os StoreFiles são classificados em ordem (essa ordem é: arquivos antigos primeiro, novos arquivos por último);
-
Os arquivos envolvidos na Compactação devem ser contínuos.
2.3.2 RationBasedCompactionPolicy
A ideia básica é selecionar a premissa de fixar End como o último arquivo (em casos gerais), deslizar do início da fila para encontrar Start e parar a varredura até que Start satisfaça uma das seguintes condições:
-
Tamanho do arquivo atual < soma de todos os tamanhos de arquivo mais recentes que o arquivo atual * proporção, que satisfaz a fórmula f[start].size <= ratio * (f[start+1].size +.....+ f [fim -1]. tamanho). Entre eles, a ração é uma proporção variável, a ração do período de pico é 1,2, a ração do período fora do pico é 5, o período fora do pico permite que arquivos maiores sejam mesclados. Você pode definir o período de pico por meio dos parâmetros hbase.offpeak.start.hour e hbase.offpeak.end.hour.
-
O número atual de arquivos candidatos restantes >= hbase.store.compaction.min (o padrão é 3), porque é necessário assegurar que o número de arquivos nesta compactação seja maior que o valor mínimo configurado de compactação.
O código lógico específico de RationBasedCompactionPolicy está anexado abaixo.
/**
* @param candidates pre-filtrate
* @return filtered subset
* -- Default minor compaction selection algorithm:
* choose CompactSelection from candidates --
* First exclude bulk-load files if indicated in configuration.
* Start at the oldest file and stop when you find the first file that
* meets compaction criteria:
* (1) a recently-flushed, small file (i.e. <= minCompactSize)
* OR
* (2) within the compactRatio of sum(newer_files)
* Given normal skew, any newer files will also meet this criteria
* <p/>
* Additional Note:
* If fileSizes.size() >> maxFilesToCompact, we will recurse on
* compact(). Consider the oldest files first to avoid a
* situation where we always compact [end-threshold,end). Then, the
* last file becomes an aggregate of the previous compactions.
*
* normal skew:
*
* older ----> newer (increasing seqID)
* _
* | | _
* | | | | _
* --|-|- |-|- |-|---_-------_------- minCompactSize
* | | | | | | | | _ | |
* | | | | | | | | | | | |
* | | | | | | | | | | | |
*/
ArrayList<StoreFile> applyCompactionPolicy(ArrayList<StoreFile> candidates,
boolean mayUseOffPeak, boolean mayBeStuck) throws IOException {
if (candidates.isEmpty()) {
return candidates;
}
// we're doing a minor compaction, let's see what files are applicable
int start = 0;
// 获取文件合并比例:取参数hbase.hstore.compaction.ratio,默认为1.2
double ratio = comConf.getCompactionRatio();
if (mayUseOffPeak) {
// 取参数hbase.hstore.compaction.ratio.offpeak,默认为5.0
ratio = comConf.getCompactionRatioOffPeak();
LOG.info("Running an off-peak compaction, selection ratio = " + ratio);
}
// get store file sizes for incremental compacting selection.
final int countOfFiles = candidates.size();
long[] fileSizes = new long[countOfFiles];
long[] sumSize = new long[countOfFiles];
for (int i = countOfFiles - 1; i >= 0; --i) {
StoreFile file = candidates.get(i);
fileSizes[i] = file.getReader().length();
// calculate the sum of fileSizes[i,i+maxFilesToCompact-1) for algo
// tooFar表示后移动最大文件数位置的文件大小,也就是刚刚满足达到最大文件数位置的那个文件,从i至tooFar数目为合并时允许的最大文件数
int tooFar = i + comConf.getMaxFilesToCompact() - 1;
sumSize[i] = fileSizes[i]
+ ((i + 1 < countOfFiles) ? sumSize[i + 1] : 0)
- ((tooFar < countOfFiles) ? fileSizes[tooFar] : 0);
}
// 倒序循环,如果文件数目满足最小合并时允许的最小文件数,且该位置的文件大小大于合并时允许的文件最小大小与下一个文件窗口文件总大小乘以一定比例中的较大者,则继续;
// 实际上就是选择出一个文件窗口内能最小能满足的文件大小的一组文件
while (countOfFiles - start >= comConf.getMinFilesToCompact() &&
fileSizes[start] > Math.max(comConf.getMinCompactSize(),
(long) (sumSize[start + 1] * ratio))) {
++start;
}
if (start < countOfFiles) {
LOG.info("Default compaction algorithm has selected " + (countOfFiles - start)
+ " files from " + countOfFiles + " candidates");
} else if (mayBeStuck) {
// We may be stuck. Compact the latest files if we can.保证最小文件数目的要求
int filesToLeave = candidates.size() - comConf.getMinFilesToCompact();
if (filesToLeave >= 0) {
start = filesToLeave;
}
}
candidates.subList(0, start).clear();
return candidates;
}2.3.3 ExplorandoCompactionPolicy
Esta política é herdada de RatioBasedCompactionPolicy. A diferença é que a política Ration parará de escanear após encontrar uma coleção de arquivos adequada, enquanto a política Exploring dividirá a lista Storefile em várias subfilas e encontrará uma solução ideal para participar da compactação. A solução ótima pode ser entendida como: quando o número de arquivos a serem mesclados é o maior ou o número de arquivos a serem mesclados é o mesmo, os arquivos são menores, o que é benéfico para reduzir o consumo de IO causado pela compactação. O fluxo do algoritmo pode ser descrito como:
-
Percorra o arquivo do começo ao fim e julgue todas as combinações que atendem às condições;
-
Selecione o número de arquivos na combinação >= minFiles e <= maxFiles;
-
Calcule o tamanho total de cada arquivo combinado, selecione o tamanho combinado <= MaxCompactSize e >= minCompactSize;
-
O tamanho de cada arquivo em cada combinação deve satisfazer FileSize(i) <= (sum(0,N,FileSize(_)) - FileSize(i)) * ração, o significado é remover arquivos muito grandes, cada Compactação Você deve tente mesclar alguns arquivos menores;
-
Selecione o maior número de arquivos na combinação que atenda às condições de 1 a 4 acima. Quando o número de arquivos for o mesmo, selecione ainda o menor tamanho total de arquivo. O objetivo é mesclar tantos arquivos quanto possível e a pressão de E/S trazida por compactação deve ser o menor possível.
O código lógico específico de ExploringCompactionPolicy está anexado abaixo.
public List<StoreFile> applyCompactionPolicy(final List<StoreFile> candidates,
boolean mightBeStuck, boolean mayUseOffPeak, int minFiles, int maxFiles) {
final double currentRatio = mayUseOffPeak
? comConf.getCompactionRatioOffPeak() : comConf.getCompactionRatio();
// Start off choosing nothing.
List<StoreFile> bestSelection = new ArrayList<StoreFile>(0);
List<StoreFile> smallest = mightBeStuck ? new ArrayList<StoreFile>(0) : null;
long bestSize = 0;
long smallestSize = Long.MAX_VALUE;
int opts = 0, optsInRatio = 0, bestStart = -1; // for debug logging
// Consider every starting place. 从头到尾遍历文件
for (int start = 0; start < candidates.size(); start++) {
// Consider every different sub list permutation in between start and end with min files.
for (int currentEnd = start + minFiles - 1;
currentEnd < candidates.size(); currentEnd++) {
List<StoreFile> potentialMatchFiles = candidates.subList(start, currentEnd + 1);
// Sanity checks
if (potentialMatchFiles.size() < minFiles) {
continue;
}
if (potentialMatchFiles.size() > maxFiles) {
continue;
}
// Compute the total size of files that will
// have to be read if this set of files is compacted. 计算文件大小
long size = getTotalStoreSize(potentialMatchFiles);
// Store the smallest set of files. This stored set of files will be used
// if it looks like the algorithm is stuck. 总size最小的
if (mightBeStuck && size < smallestSize) {
smallest = potentialMatchFiles;
smallestSize = size;
}
if (size > comConf.getMaxCompactSize(mayUseOffPeak)) {
continue;
}
++opts;
if (size >= comConf.getMinCompactSize()
&& !filesInRatio(potentialMatchFiles, currentRatio)) {
continue;
}
++optsInRatio;
if (isBetterSelection(bestSelection, bestSize, potentialMatchFiles, size, mightBeStuck)) {
bestSelection = potentialMatchFiles;
bestSize = size;
bestStart = start;
}
}
}
if (bestSelection.size() == 0 && mightBeStuck) {
LOG.debug("Exploring compaction algorithm has selected " + smallest.size()
+ " files of size "+ smallestSize + " because the store might be stuck");
return new ArrayList<StoreFile>(smallest);
}
LOG.debug("Exploring compaction algorithm has selected " + bestSelection.size()
+ " files of size " + bestSize + " starting at candidate #" + bestStart +
" after considering " + opts + " permutations with " + optsInRatio + " in ratio");
return new ArrayList<StoreFile>(bestSelection);
}2.3.4 StripeCompactionPolicy
A Compactação Stripe ( HBASE-7667 ) foi proposta para reduzir a pressão da Compactação Maior. A ideia é: a forma mais direta de reduzir a pressão da Compactação Maior é reduzir o tamanho da Região. É melhor que todo o cluster seja composto por muitas Regiões pequenas, de forma que o tamanho total dos arquivos participantes da Compactação não deve ser muito grande. No entanto, se a configuração da região for muito pequena, haverá um grande número de regiões. Por um lado, isso levará a uma grande sobrecarga para o HBase gerenciar regiões. Por outro lado, muitas regiões também exigirão que o HBase gerencie as regiões. aloque mais memória para uso como Memstore, caso contrário, pode causar o nível inteiro do RegionServer.Flush, que por sua vez causa bloqueio de gravação de longo prazo. Portanto, simplesmente definir o tamanho da região muito pequeno não pode resolver o problema.
(1) Nível de Compactação
Os desenvolvedores da comunidade usam a estratégia de compactação do Leveldb, Level Compaction. A ideia do projeto do Level Compaction é dividir todos os dados do Store em várias camadas, e cada camada terá alguns dados, conforme mostra a figura a seguir:
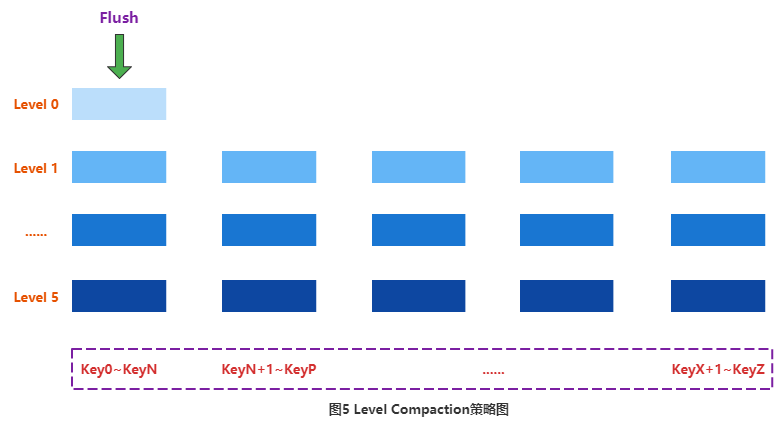
A forma de organização dos dados não é mais organizada de acordo com o tempo, mas sim de acordo com o KeyRange. Cada KeyRange conterá vários arquivos, e as Keys de todos os dados desses arquivos devem estar distribuídas no mesmo intervalo. Por exemplo, todos os dados cuja Key está distribuída entre Key0~KeyN cairão no arquivo do primeiro intervalo KeyRange, e todos os dados cuja Key está distribuída entre KeyN+1~KeyT estarão distribuídos no arquivo do segundo intervalo. analogia.
Todo o sistema de dados será dividido em várias camadas, a camada superior (Nível 0) representa os dados mais recentes e a camada inferior (Nível 6) representa os dados mais antigos. Cada camada consiste em um grande número de blocos KeyRange (exceto Nível 0) e não há sobreposição de chave entre KeyRange. Além disso, quanto maior o número de camadas, maior o tamanho de cada bloco KeyRange na camada correspondente, e o tamanho do bloco KeyRange na camada inferior é 10 vezes o tamanho da camada superior. Quanto mais escura for a cor do intervalo na figura, maior será o bloco de intervalo correspondente.
Depois que os dados forem liberados do Memstore, eles cairão primeiro no Nível 0. Nesse momento, os dados que caem no Nível 0 podem conter todas as chaves possíveis. Neste momento, caso seja necessário realizar a Compactação, basta ler os KV no Nível 0 um a um, e depois inseri-los no arquivo correspondente ao bloco KeyRange no Nível 1 de acordo com a distribuição da Key. Se o tamanho de um bloco KeyRange no Nível 1 passa a ser Se exceder um determinado limite, ele continuará a mesclar para a próxima camada.
A compactação de nível ainda terá o conceito de compactação principal.A compactação principal precisa apenas mesclar os arquivos no bloco Range, em vez de mesclar os arquivos de dados em toda a região.
Pode-se observar que durante o processo de mesclagem desse tipo de compactação, apenas alguns arquivos precisam participar de cima para baixo e não há necessidade de realizar operações de compactação em todos os arquivos. Além disso, a compactação de nível tem outra vantagem: para muitas empresas que leem apenas dados gravados recentemente, a maioria das solicitações de leitura cai para o nível 0, de modo que o SSD pode ser usado como meio de armazenamento de nível superior para otimizar ainda mais a leitura. No entanto, este tipo de compactação aumentou significativamente o número de compactações devido a muitos níveis.Após o teste, verificou-se que este tipo de compactação não melhorou a utilização de IO.
(2)Compactação de Listras
Embora a compactação de nível nativa não seja aplicável ao HBase, a ideia dessa compactação inspirou os desenvolvedores do HBase. Combinada com a estratégia de pequena região mencionada anteriormente, a compactação de faixa é formada.
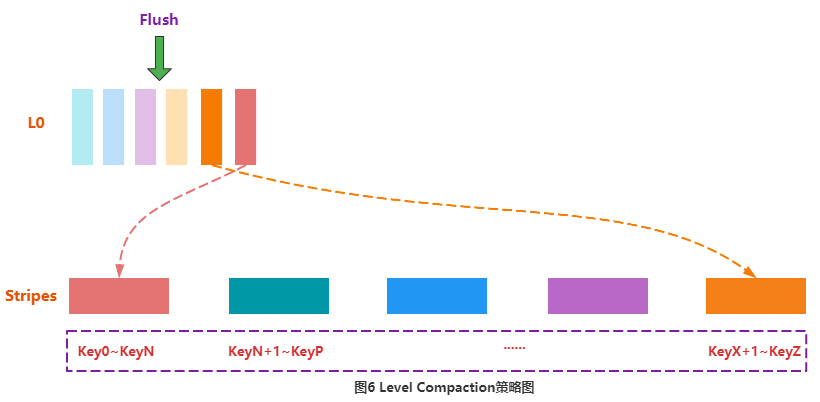
Igual à Compactação de Nível, a Compactação Stripe divide os arquivos em todo o Store em vários Ranges de acordo com a Key, chamados Stripes. O número de Stripes pode ser definido por parâmetros, e as Keys entre Stripes adjacentes não se sobrepõem. Stripe é semelhante ao conceito de Sub-Região, ou seja, uma grande Região é dividida em muitas Sub-Regiões pequenas.
À medida que os dados são gravados, o Memstore executa o Flush para formar HFiles. Esses HFiles não serão gravados no Stripe correspondente imediatamente, mas serão colocados em um local chamado L0. O usuário pode configurar o número de HFiles que podem ser colocados em L0. Assim que o número de arquivos colocados em L0 exceder o valor definido, o sistema gravará esses HFiles no Stripe correspondente: primeiro leia os KVs do HFile, depois localize o Stripe específico de acordo com a Key de cada KV e insira o KV no o arquivo Stripe correspondente, conforme mostrado na Figura 6. Como o Stripe é uma região pequena, a compactação não consome muitos recursos do sistema. Além disso, ao ler os dados, encontre o Stripe correspondente de acordo com a chave correspondente e, em seguida, execute a pesquisa dentro do Stripe. Como a quantidade de dados no Stripe é relativamente pequena, o desempenho da pesquisa de dados também pode ser melhorado até certo ponto.
2.4 Executar operação de compactação
Depois de selecionar os arquivos a serem mesclados, a mesclagem real é realizada. O processo de fusão é dividido principalmente nas seguintes etapas:
-
Leia o KV de todos os HFiles a serem mesclados sequencialmente e grave-os sequencialmente em arquivos temporários localizados no diretório ./tmp;
-
Mova o arquivo temporário para o diretório de dados oficial da Região correspondente;
-
Encapsule o caminho do arquivo de entrada e o caminho do arquivo de saída da compactação como KV, grave-o no log do WAL, marque-o com compactação e, finalmente, execute a sincronização;
-
Exclua todos os arquivos de entrada da compactação no diretório de dados da região correspondente.
O HBase considera toda a Compactação de forma muito abrangente.Se ocorrer um erro em cada uma das quatro etapas acima, ele é altamente tolerante a falhas e idempotente (o resultado é o mesmo para uma execução e várias execuções).
-
Se ocorrer uma exceção no RS no passo 2 ou antes, esta Compactação será considerada uma falha. Se a mesma Compactação continuar, a última exceção não terá impacto na próxima Compactação, nem afetará a leitura e a escrita. impacto é que há mais um dado redundante;
-
Se o RS estiver anormal após o passo 2, passo 3 ou antes do passo 3, haverá apenas mais um dado redundante;
-
Se ocorrer uma exceção após o passo 3 e antes do passo 4, o RS verá o log da última compactação do WAL após reabrir a Região. Como o arquivo de entrada e o arquivo de saída foram persistidos no HDFS neste momento, é necessário apenas remover o arquivo de entrada da compactação de acordo com o log do WAL.
O método compacto de Store está anexado abaixo.
public List<StoreFile> compact(CompactionContext compaction,
CompactionThroughputController throughputController, User user) throws IOException {
assert compaction != null;
List<StoreFile> sfs = null;
CompactionRequest cr = compaction.getRequest();
try {
// Do all sanity checking in here if we have a valid CompactionRequest
// because we need to clean up after it on the way out in a finally
// block below
long compactionStartTime = EnvironmentEdgeManager.currentTime();
assert compaction.hasSelection();
Collection<StoreFile> filesToCompact = cr.getFiles();
assert !filesToCompact.isEmpty();
synchronized (filesCompacting) {
// sanity check: we're compacting files that this store knows about
// TODO: change this to LOG.error() after more debugging
// 再次检查
Preconditions.checkArgument(filesCompacting.containsAll(filesToCompact));
}
// Ready to go. Have list of files to compact.
LOG.info("Starting compaction of " + filesToCompact.size() + " file(s) in "
+ this + " of " + this.getRegionInfo().getRegionNameAsString()
+ " into tmpdir=" + fs.getTempDir() + ", totalSize="
+ TraditionalBinaryPrefix.long2String(cr.getSize(), "", 1));
// Commence the compaction. 开始compact,newFiles是合并后的新文件
List<Path> newFiles = compaction.compact(throughputController, user);
long outputBytes = 0L;
// TODO: get rid of this!
if (!this.conf.getBoolean("hbase.hstore.compaction.complete", true)) {
LOG.warn("hbase.hstore.compaction.complete is set to false");
sfs = new ArrayList<StoreFile>(newFiles.size());
final boolean evictOnClose =
cacheConf != null? cacheConf.shouldEvictOnClose(): true;
for (Path newFile : newFiles) {
// Create storefile around what we wrote with a reader on it.
StoreFile sf = createStoreFileAndReader(newFile);
sf.closeReader(evictOnClose);
sfs.add(sf);
}
return sfs;
}
// Do the steps necessary to complete the compaction.
// 将newFiles移动到新的位置,返回StoreFile列表
sfs = moveCompatedFilesIntoPlace(cr, newFiles, user);
// 在WAL中写入Compaction记录
writeCompactionWalRecord(filesToCompact, sfs);
// 将新生成的StoreFile列表替换到StoreFileManager的storefile中
replaceStoreFiles(filesToCompact, sfs);
// 根据compact类型,累加相应计数器
if (cr.isMajor()) {
majorCompactedCellsCount += getCompactionProgress().totalCompactingKVs;
majorCompactedCellsSize += getCompactionProgress().totalCompactedSize;
} else {
compactedCellsCount += getCompactionProgress().totalCompactingKVs;
compactedCellsSize += getCompactionProgress().totalCompactedSize;
}
for (StoreFile sf : sfs) {
outputBytes += sf.getReader().length();
}
// At this point the store will use new files for all new scanners.
// 归档旧文件
completeCompaction(filesToCompact, true); // Archive old files & update store size.
long now = EnvironmentEdgeManager.currentTime();
if (region.getRegionServerServices() != null
&& region.getRegionServerServices().getMetrics() != null) {
region.getRegionServerServices().getMetrics().updateCompaction(cr.isMajor(),
now - compactionStartTime, cr.getFiles().size(), newFiles.size(), cr.getSize(),
outputBytes);
}
// 记录日志信息并返回
logCompactionEndMessage(cr, sfs, now, compactionStartTime);
return sfs;
} finally {
finishCompactionRequest(cr);
}
}3. Limite atual de compactação
Todas as estratégias acima definem estratégias de seleção de arquivos correspondentes de acordo com diferentes cenários de negócios. O núcleo é reduzir o número de arquivos que participam da compactação, encurtar o tempo de execução de toda a compactação, reduzir indiretamente o efeito de amplificação de E/S da compactação e reduzir o atraso de leitura e escrita para influência empresarial. No entanto, se a taxa de transferência de leitura e gravação na fase de execução da compactação não for limitada, ela também consumirá uma grande quantidade de recursos do sistema em um curto período de tempo, afetando os atrasos de leitura e gravação do usuário. HBase limita o fluxo de compactação limitando a velocidade de compactação e a largura de banda de compactação.
3.1 Limite de Velocidade de Compactação
Este esquema de otimização ajusta automaticamente o rendimento da compactação do sistema, detectando a pressão da compactação, reduzindo o rendimento da consolidação quando a pressão é alta e aumentando o rendimento da consolidação quando a pressão é baixa.
O princípio básico é:
Em circunstâncias normais, os usuários precisam definir o parâmetro de limite inferior de taxa de transferência hbase.hstore.compaction.throughput.lower.bound (padrão 10 MB/seg) e o parâmetro de limite superior hbase.hstore.compaction.throughput.higher.bound (padrão 20 MB/seg ), a taxa de transferência de trabalho real é menor + (maior – menor) * proporção, em que proporção é um valor decimal variando de 0 a 1, que é determinado pelo número de HFiles no armazenamento atual para participar da comparação. Quanto maior o número , quanto maior a proporção, menor e vice-versa.
Se o número de HFiles no armazenamento atual for muito grande e exceder o parâmetro blockingFileCount, todas as solicitações de gravação serão bloqueadas e aguardarão a conclusão da compactação. Nesse cenário, as restrições acima se tornarão automaticamente inválidas.
3.2 Limite de Largura de Banda de Compactação
O princípio é basicamente o mesmo que Limit Compaction Speed, envolvendo principalmente dois parâmetros: compactBwLimit e numOfFilesDisableCompactLimit.
As funções são as seguintes:
-
compactBwLimit : O uso máximo de largura de banda de uma compactação, se a largura de banda usada pela compactação for maior que esse valor, ela será forçada a dormir por um período de tempo.
-
numOfFilesDisableCompactLimit : Obviamente, no caso de solicitações de gravação muito grandes, limitar o uso da largura de banda de compactação inevitavelmente levará ao acúmulo de HFile, o que afetará o atraso de resposta das solicitações de leitura. Portanto, o significado desse valor é óbvio. Uma vez que o número de HFiles na loja exceda o valor definido, o limite de largura de banda se tornará inválido.
// 该方法进行Compaction的动态限制
private void tune(double compactionPressure) {
double maxThroughputToSet;
// 压力大于1,最大限速不受限制
if (compactionPressure > 1.0) {
// set to unlimited if some stores already reach the blocking store file count
maxThroughputToSet = Double.MAX_VALUE;
// 空闲时间,最大限速为设置的Compaction最大吞吐量
} else if (offPeakHours.isOffPeakHour()) {
maxThroughputToSet = maxThroughputOffpeak;
} else {
// compactionPressure is between 0.0 and 1.0, we use a simple linear formula to
// calculate the throughput limitation.
// lower + (higher - lower) * ratio
maxThroughputToSet =
maxThroughputLowerBound + (maxThroughputHigherBound - maxThroughputLowerBound)
* compactionPressure;
}
if (LOG.isDebugEnabled()) {
LOG.debug("compactionPressure is " + compactionPressure + ", tune compaction throughput to "
+ throughputDesc(maxThroughputToSet));
}
this.maxThroughput = maxThroughputToSet;
}Vejamos o método getCompactionPressure para obter a pressão de compactação do RS, na verdade ele percorre cada Loja de cada Região e pega aquela de maior pressão.
@Override
public double getCompactionPressure() {
double max = 0;
for (Region region : onlineRegions.values()) {
for (Store store : region.getStores()) {
double normCount = store.getCompactionPressure();
if (normCount > max) {
max = normCount;
}
}
}
return max;
}@Override
public double getCompactionPressure() {
int storefileCount = getStorefileCount();
int minFilesToCompact = comConf.getMinFilesToCompact();
if (storefileCount <= minFilesToCompact) {
return 0.0;
}
return (double) (storefileCount - minFilesToCompact) / (blockingFileCount - minFilesToCompact);
}O esquema de limitação de corrente do HBase ajusta automaticamente a taxa de transferência de compactação do sistema, detectando a pressão de compactação, reduz a taxa de transferência combinada quando a pressão é alta e aumenta a taxa de transferência combinada quando a pressão é baixa.
O princípio básico é:
Em circunstâncias normais, os usuários precisam definir o parâmetro de limite inferior de taxa de transferência hbase.hstore.compaction.throughput.lower.bound (padrão 10 MB/seg) e o parâmetro de limite superior hbase.hstore.compaction.throughput.higher.bound (padrão 20 MB/seg ), Na prática, funcionará quando o throughput for lower + (higher – lower) * ratio, onde ratio é um valor decimal variando de 0 a 1, que é determinado pelo número de HFiles no Store atual para participar do Comtation Quanto mais, menor a proporção e vice-versa.
Se o número de HFiles no Store atual for muito grande e exceder o valor de blockingFileCount, que é configurado pelo parâmetro hbase.hstore.blockingStoreFiles, todas as solicitações de gravação serão bloqueadas e aguardarão a conclusão da compactação. as restrições acima falharão automaticamente.
4. Problemas encontrados online e métodos de ajuste
Devido à complexidade do ambiente online, mais otimizações foram feitas no módulo Compactação. Dois casos típicos são selecionados abaixo para ilustrar.
4.1 Desligue o acionamento automático da Compactação Principal, mas a fila de Compactação Principal ainda tem valor durante o monitoramento, o que afetará o desempenho de leitura e gravação
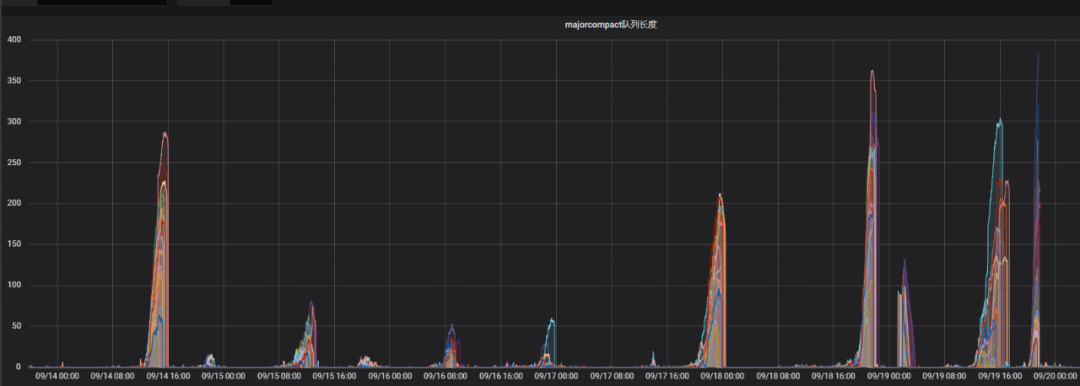
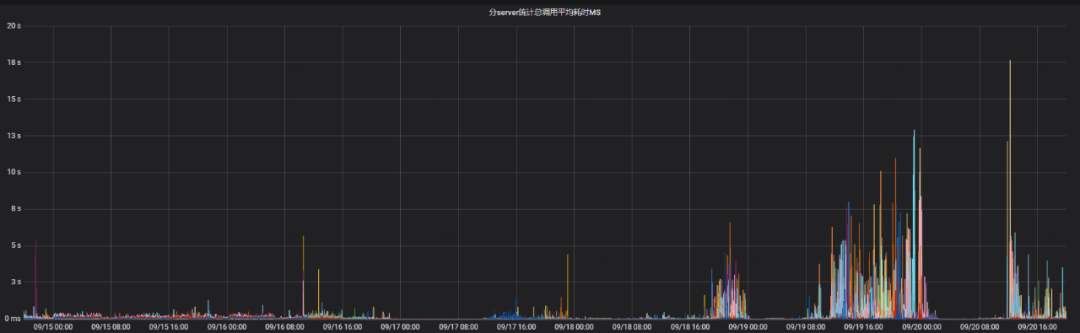
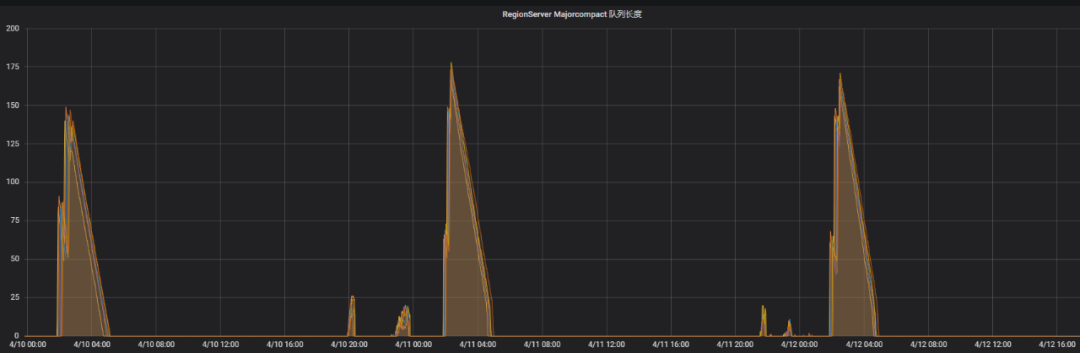
Os clusters on-line desativam a função de acionar automaticamente a compactação principal e acionam manualmente a compactação principal por meio de tarefas agendadas durante os períodos de negócios de baixo pico. Em uma determinada falha, o atraso de desempenho de leitura e gravação do feedback de negócios é relativamente grande durante o período de não execução da compactação principal. Observando o monitoramento, verifica-se que o valor da fila de compactação principal no monitoramento é relativamente grande.
A seguir, o gráfico de monitoramento do comprimento da fila de compactação principal e o tempo médio consumido pelas chamadas de leitura e gravação naquele momento. No gráfico, os seguintes pontos podem ser vistos claramente:
-
Quando o comprimento da fila de compactação principal é relativamente grande, leva muito tempo para ler e gravar;
-
O comprimento da fila de compactação principal está relacionado ao tráfego de entrada.Quando o tráfego de entrada é relativamente grande, o comprimento da fila de compactação principal é relativamente grande.
Uma pergunta surge aqui: quando a compactação principal automática é desativada, quais condições acionam a compactação principal?
Com as perguntas acima em mente, analisamos o problema no nível do código-fonte.
1) Primeiro, verifique o significado do indicador de comprimento da fila de compactação principal, que indica o número de espera na fila de trabalho do pool de encadeamentos longCompaction.
@Override
public int getLargeCompactionQueueSize() {
//The thread could be zero. if so assume there is no queue.
if (this.regionServer.compactSplitThread == null) {
return 0;
}
return this.regionServer.compactSplitThread.getLargeCompactionQueueSize();
}public int getLargeCompactionQueueSize() {
return longCompactions.getQueue().size();
}2) Verifique o log do HBase e descubra se realmente há um comportamento de compactação importante.
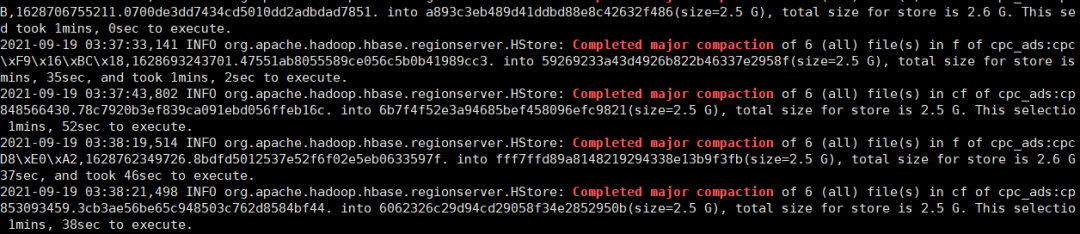
3) Verifique ainda quando o pool de encadeamentos de Compactação longa será chamado e verifique o código-fonte relacionado às filas de compactação longa e compactação pequena selecionadas por Compactação.
/**
* @param candidateFiles candidate files, ordered from oldest to newest. All files in store.
* @return subset copy of candidate list that meets compaction criteria
* @throws java.io.IOException
*/
public CompactionRequest selectCompaction(Collection<StoreFile> candidateFiles,
final List<StoreFile> filesCompacting, final boolean isUserCompaction,
final boolean mayUseOffPeak, final boolean forceMajor) throws IOException {
// Preliminary compaction subject to filters
ArrayList<StoreFile> candidateSelection = new ArrayList<StoreFile>(candidateFiles);
// Stuck and not compacting enough (estimate). It is not guaranteed that we will be
// able to compact more if stuck and compacting, because ratio policy excludes some
// non-compacting files from consideration during compaction (see getCurrentEligibleFiles).
int futureFiles = filesCompacting.isEmpty() ? 0 : 1;
boolean mayBeStuck = (candidateFiles.size() - filesCompacting.size() + futureFiles)
>= storeConfigInfo.getBlockingFileCount();
candidateSelection = getCurrentEligibleFiles(candidateSelection, filesCompacting);
LOG.debug("Selecting compaction from " + candidateFiles.size() + " store files, " +
filesCompacting.size() + " compacting, " + candidateSelection.size() +
" eligible, " + storeConfigInfo.getBlockingFileCount() + " blocking");
// If we can't have all files, we cannot do major anyway
boolean isAllFiles = candidateFiles.size() == candidateSelection.size();
if (!(forceMajor && isAllFiles)) {
// 过滤掉大文件
candidateSelection = skipLargeFiles(candidateSelection, mayUseOffPeak);
isAllFiles = candidateFiles.size() == candidateSelection.size();
}
...
}Entre eles, o método skipLargeFiles filtra os arquivos mesclados e remove os arquivos grandes. O limite é configurado por maxCompactSize = conf.getLong(HBASE_HSTORE_COMPACTION_MAX_SIZE_KEY, Long.MAX_VALUE), e o padrão é Long.MAX_VALUE.
/**
* @param candidates pre-filtrate
* @return filtered subset
* exclude all files above maxCompactSize
* Also save all references. We MUST compact them
*/
private ArrayList<StoreFile> skipLargeFiles(ArrayList<StoreFile> candidates,
boolean mayUseOffpeak) {
int pos = 0;
while (pos < candidates.size() && !candidates.get(pos).isReference()
&& (candidates.get(pos).getReader().length() > comConf.getMaxCompactSize(mayUseOffpeak))) {
++pos;
}
if (pos > 0) {
LOG.debug("Some files are too large. Excluding " + pos
+ " files from compaction candidates");
candidates.subList(0, pos).clear();
}
return candidates;
}Em seguida, escolha o pool de threads de compactação longo ou o pool de threads de compactação pequeno de acordo com o tamanho dos arquivos a serem mesclados.
@Override
public boolean throttleCompaction(long compactionSize) {
return compactionSize > comConf.getThrottlePoint();
}O método de cálculo deste limite é o seguinte, o padrão é 2,5G, ou seja, se o tamanho do arquivo a ser mesclado for maior que 2,5G, ele será colocado no pool de threads de compactação longa para execução.
throttlePoint = conf.getLong("hbase.regionserver.thread.compaction.throttle",
2 * maxFilesToCompact * storeConfigInfo.getMemstoreFlushSize());4) Verifique os logs do ReigonServer para este período de tempo, e descubra que existe um grande número de arquivos maiores que 2.5G em Compactação, o que explica porque não há log de Major Compactation neste período de tempo no log do RS, mas a longa fila de compactação tem valor.
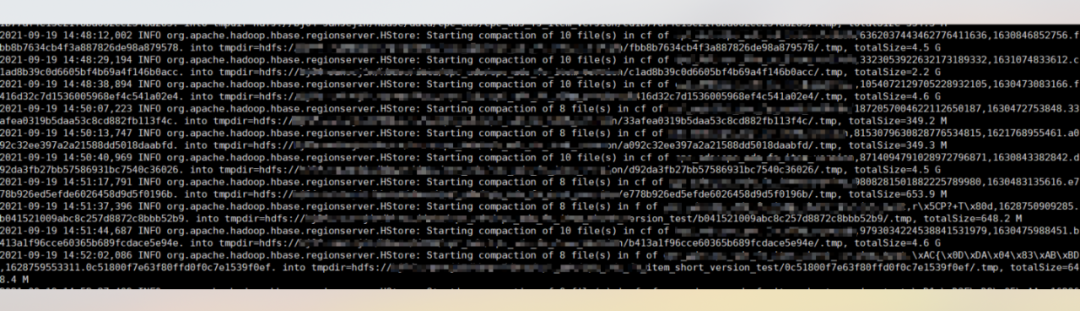
Até agora, a causa do problema foi encontrada. O aumento no tráfego de entrada leva a um único arquivo HFile relativamente grande. Ao fazer a compactação secundária após a descarga, se o tamanho total dos arquivos a serem mesclados for maior que 2,5 G (padrão value), a compactação secundária será colocada em Executar no pool de threads de compactação longa. Arquivos grandes a serem mesclados levam a um alto consumo de E/S de disco, o que, por sua vez, afeta o desempenho de leitura e gravação.
5) Medidas
Ajustamos o parâmetro hbase.hstore.compaction.max.size de Compaction e alteramos o valor para 2G, o que significa que HFiles maiores que 2G serão excluídos durante Minor Compaction e arquivos maiores que 2G serão processados durante o período de pico Mesclar para reduzir o impacto da compactação no disco IO.
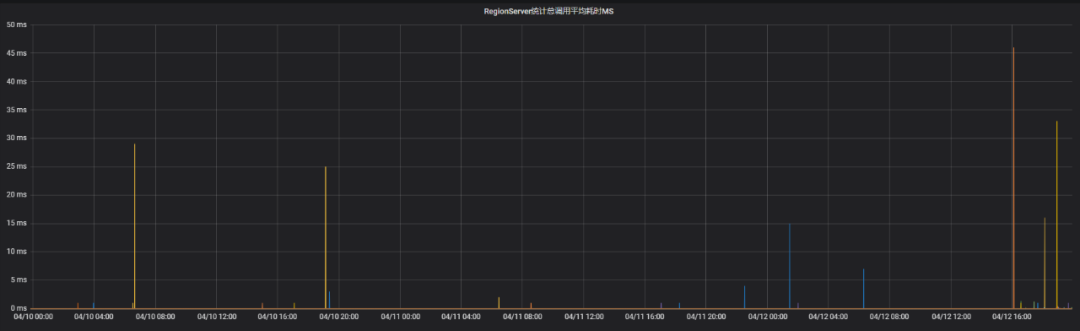
6) Efeito
Após o ajuste, o longo pool de threads de compactação raramente é ocupado durante o acionamento não manual da compactação principal, e o tempo médio de leitura e gravação é reduzido para menos de 50 ms.
4.2 O tempo de execução da tarefa Major Comtation acionada manualmente agendada é muito longo
Comentários de negócios O desempenho de leitura e gravação de uma determinada tabela foi um pouco lento recentemente. Por meio do monitoramento, pode-se ver que o armazenamento da tabela está crescendo e a cópia única do armazenamento atingiu 578 TB. Verifique as informações da tabela, a configuração TTL da tabela é de 15 dias e o tráfego de entrada da tabela não aumentou significativamente. O diagrama de monitoramento é o seguinte:
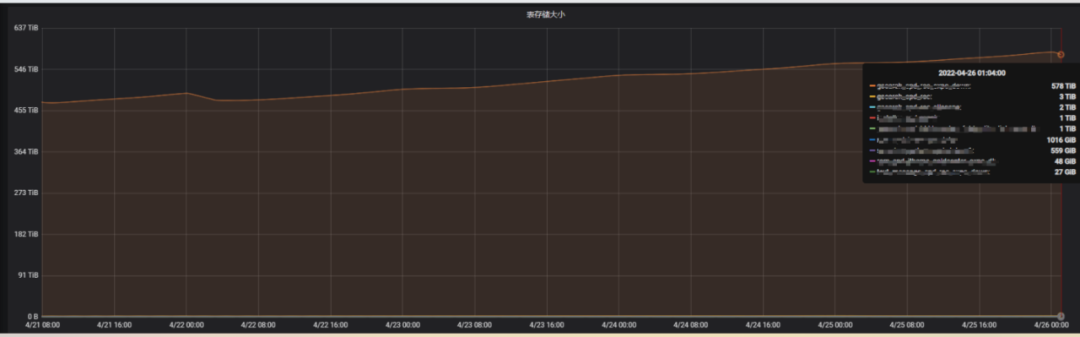
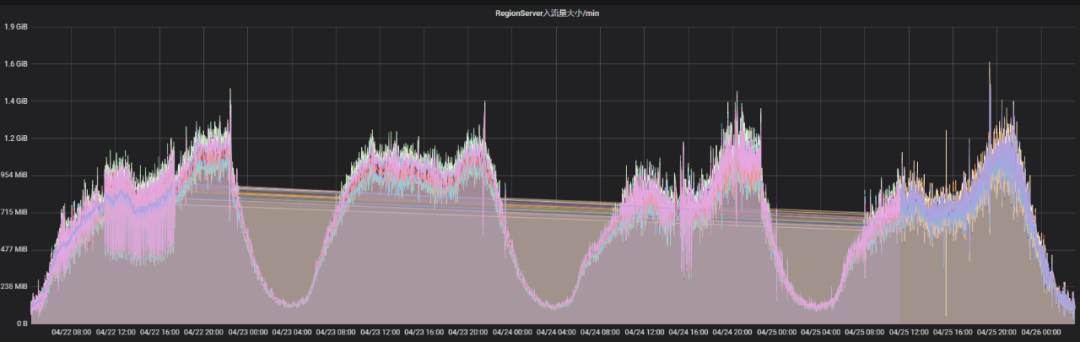
Portanto, suspeita-se que a tarefa de compactação diária não tenha sido concluída, resultando na falha na exclusão completa dos dados expirados. Observando a configuração on-line, o tamanho do conjunto de encadeamentos da compactação principal é 1 e o volume de dados dessa tabela é relativamente grande. Portanto, o tamanho do pool de threads de compactação é ajustado para 10 e o tempo ocioso do cluster é definido como hbase.offpeak.start.hour e hbase.offpeak.end.hour. Durante esse período, o tamanho dos arquivos a serem mescladas pode ser aumentada durante a compactação. Após a conclusão do ajuste, você pode ver que a carga de trabalho da compactação aumentou significativamente ao monitorar o gráfico de comparação de efeitos da compactação.
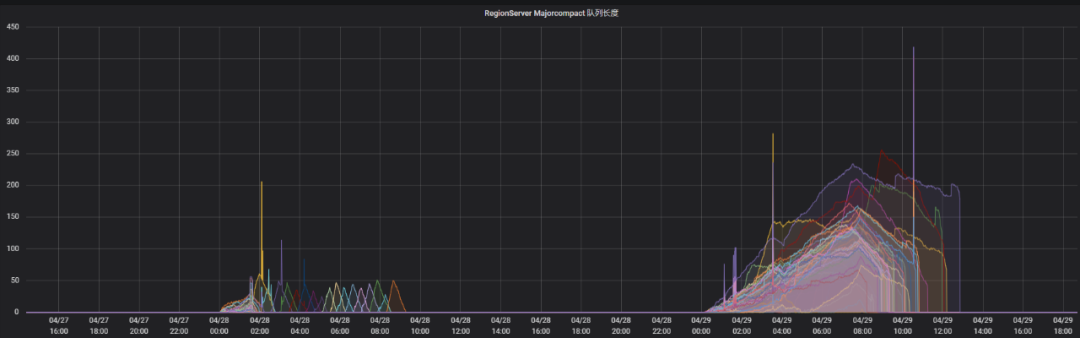
Olhando para o tamanho do armazenamento ocupado pela mesa, podemos ver que a mesa caiu de 578T para 349T, uma queda de 40%. O tempo de leitura e escrita do negócio também voltou ao normal. Os parâmetros de compactação são mais importantes. Ao ajustar, você precisa considerar se isso afetará o negócio. Após o ajuste, você precisa observar a situação demorada do negócio e pode ajustar os parâmetros passo a passo.
5. Introdução de parâmetros relacionados à compactação
Os parâmetros relacionados à Compactação estão anexados abaixo, e o ambiente online pode ser ajustado de acordo com a situação real.
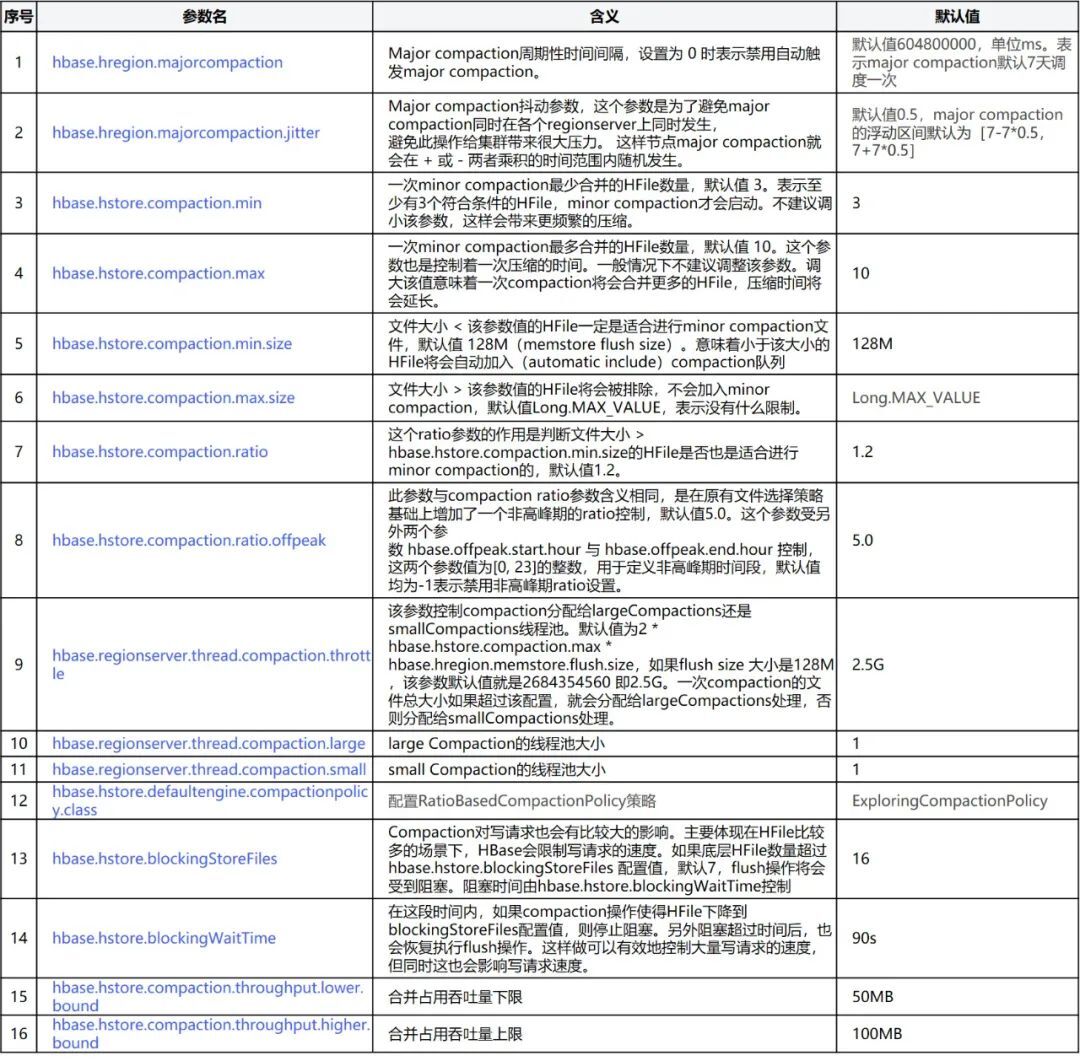
6. Resumo
A compactação é um meio muito importante para o HBase melhorar o desempenho de leitura e gravação, mas a lógica da compactação é mais complicada e o uso inadequado levará à amplificação da gravação, o que afetará as solicitações normais de leitura e gravação. Este artigo enfoca o mecanismo de ativação da compactação, várias estratégias de mesclagem que aparecem durante o desenvolvimento da compactação, o algoritmo de seleção de arquivos a serem mesclados, o limite atual da compactação e os parâmetros relacionados à compactação e faz uma descrição detalhada. , dois casos online são selecionados , apresenta ideias de análise específicas e métodos de ajuste. Após o ajuste, o desempenho foi dobrado, garantindo a operação eficiente e estável do negócio.