1. Принцип

элемента (элемента) связанного списка: содержимое, которое фактически существует в
узле (узле) линейной переменной: структура, введенная для организации связанного списка, помимо сохранения наших элементов, также сохранит ссылку на следующий узел
public class Node {
public int val; //结点内存储的内容
public Node next;//保存指向下一个结点的引用,其中尾结点的next=null
public Node(int val){
this.val=val;
}
}
2. Создайте версию связанного списка
без марионеточных узлов
public static Node createList(){
Node a=new Node(1);
Node b=new Node(2);
Node c=new Node(3);
Node d=new Node(4);
a.next=b;
b.next=c;
c.next=d;
d.next=null;
return a;
}
версия с марионеточным узлом
public static Node creatListWithDummy(){
Node dummy=new Node(0);
Node a=new Node(1);
Node b=new Node(2);
Node c=new Node(3);
Node d=new Node(4);
dummy.next=a;//在原本链表基础上,在头结点的前边创建一个前驱节点
a.next=b;
b.next=c;
c.next=d;
d.next=null;
return dummy;
}
3. Соответствующий код операции и анализ
1. Обход связанного списка
public static void print(Node head)
{
for(Node cur=head;cur!=null;cur=cur.next)
{
System.out.println(cur.val);
}
}
Передайте головной узел в функцию, назначьте головной узел новому узлу nur и судите каждый раз по циклу. Если cur пуст, цикл заканчивается. Если он не пуст, он будет указывать на следующий узел. Согласно характеристикам связанного списка, в последнем узле следующий узел равен нулю, поскольку следующего узла нет. Распечатайте каждый цикл и, наконец, реализуйте обход связанного списка.
2. Узел хвостовой вилки
public static Node insertTail(Node head,int val)
{
Node newNode=new Node(val);//创建一个新结点,初始化为传入的参数值
if(head==null)
{
return newNode;//如果头结点为空,则说明这是一个空链表,则新结点就为这个链表的头结点
}
//1.先找到末尾节点
Node prev =head;
while(prev.next!=null){
prev=prev.next;//经过遍历,找到链表的尾部结点
}
//循环结束,prev就是最后一个节点了
newNode.next= null;
prev.next=newNode;
return head;
}
 Блок-схема реализации кода хвостовой заглушки
Блок-схема реализации кода хвостовой заглушки
 Логическая схема хвостовой заглушки
Логическая схема хвостовой заглушки
3. Удалить узлы по значению
//删除节点,此时按照值来删除
public static Node remove(Node head,int value)
{
if(head==null){
return null;
}
if(head.val==value)
{
//要删除的节点就是头节点
head=head.next;
return head;
}
//1.先找到val这个值对应的值
//同时也要找到val的前一个位置
Node prev=head;
while (prev!=null&&prev.next!=null&&prev.next.val!=value)
{
prev=prev.next;
}
//循环结束之后,prev就指向待删除节点的前一个节点了
if(prev==null||prev.next==null)
{
//没有找到值为val的节点
return head;
}
//2.真正进行删除了,toDelete指向要被删除的节点
Node toDelete=prev.next;
prev.next=toDelete.next;
return head;
}

4. Удалить по местоположению (1)
//删除节点,按照位置来删除
public static Node remove(Node head,Node toDelete)
{
if(head==null)
{
return null;
}
if(head==toDelete)
{
//要删除的就是头节点
head=head.next;
return head;
}
//1.先需要找到toDelete的的前一个节点
Node prev=head;
while(prev!=null&&prev.next!=toDelete)
{
prev=prev.next;
}
if(prev==null)
{
//没找到
return head;
}
//2.进行删除
prev.next=toDelete.next;
return head;
}

По сравнению с удалением по значению, единственная разница в этой идее программирования состоит в том, что условия оценки в процессе обхода для поиска узлов различны.При поиске по местоположению вам необходимо сравнить, равен ли предыдущий.следующий удаляемому узлу, потому что цель состоит в том, чтобы найти предыдущий узел узла, который нужно удалить.
5. Удалить по местоположению (2)
public static Node remove2(Node head,Node toDelete)
{
if(head==null){
return null;
}//如果链表为空,直接返回null
if(head==toDelete){
head=head.next;
return head;
}//如果头节点为要删除的节点,让头节点的后继节点成为新的头节点,实现删除
Node nextNode=toDelete.next;
toDelete.val=nextNode.val;
toDelete.next=nextNode.next;
return head;
}
Этот метод,
6. Рассчитайте функцию длины связанного списка
public static int size(Node head)
{
int size=0;
for (Node cur=head;cur!=null;cur=cur.next)
{
size++;
}
return size;
}
Через головной узел пройдите по связанному списку и используйте целочисленный размер в качестве счетчика.
7. Удалить узлы в соответствии с индексами узла
//给定节点下标来删除
public static Node remove3(Node head,int index){
if(index<0||index>+size(head))
{
return head;
}
//如果index等于0,意味着要删除头节点
if(index==0){
head=head.next;
return head;
}
//1.还是要先找到待删除节点的前一个位置.index-1这个节点就是前一个位置
Node prev=head;
for(int i=0;i<index-1;i++)
{
prev=prev.next;
}
//循环结束之后,prev就指向了待删除节点的前一个位置
//2.真正进行删除
Node toDelete=prev.next;
prev.next=toDelete.next;
return head;
}
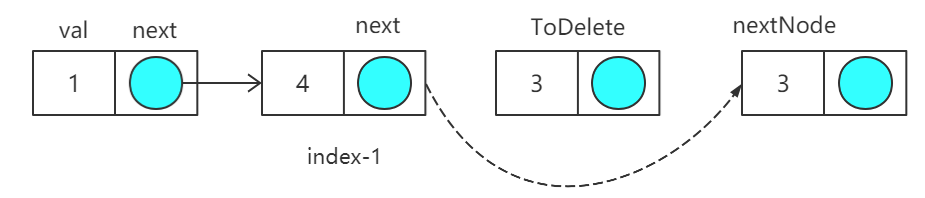
Ключом к удалению в соответствии с нижним индексом узла является то, что условие решения цикла состоит в том, чтобы prev указывал на предыдущий узел удаляемого узла, а последующие операции были такими же, как и у предыдущих функций.
8. Удалить элементы из связанного списка с марионеточными узлами
//针对带傀儡节点的链表,删除指定元素
public static void removeWithDummy(Node head,int val)
{
//此时不必考虑到head引用修改的问题,也不必单独考虑删除第一个节点的事情了
Node prev=head;
while (prev!=null&&prev.next!=null&&prev.next.val!=val)
{
prev=prev.next;
}
//当这个循环结束的时候,要么是prev到达了链表末尾,要么是找到了val匹配的值
if(prev==null||prev.next==null)
{
//没有找到对应的点
return;
}
//找到了对应的点
//如果要删除val正好是第一个节点,此时prev正好是指向head的
Node toDelete=prev.next;
prev.next=toDelete.next;
return;
}
9. Узлы без связанного списка марионеток удаляются хвостом
//针对不带傀儡节点的链表,进行尾删操作
public static Node removeTail(Node head)
{
if(head==null){
return null;
}
if(head.next==null)
{
//链表里只有一个节点,尾删的节点就是这个head本身
//此时删除该节点之后,这个链表就变成空链表了
return null;
}
//一般的情况,需要找到尾部节点的前一个节点
Node prev=head;
Node toDelete=prev.next;
while(prev!=null&&prev.next!=null)
{
toDelete=prev.next;
if(toDelete.next==null)
{
break;
}
prev=prev.next;
}
//接下来删除这个节点即可
//由于toDelete已经是最后一个节点了,他的next一定是null
prev.next=null;
return head;
}

10. Замените массив связным списком
public static Node arrayToLinkedList(int[] array)
{
//遍历数组,把元素进行尾插即可
//每次尾插,都需要知道当前链表的末尾节点
//每次重新找这个末尾节点,太麻烦了
//可以直接用一个引用把尾节点记住
//head就是头节点的引用,初始情况下,链表是空的
Node head=null;
//tail也是空的
Node tail=null;
for(int x:array)
{
Node node=new Node(x);
//把node进行尾插
//需要判定当前链表是否为空
if(head==null)
{
head=node;
tail=node;
}else
{
//链表不为空的时候。再进行新的插入,就不必管head了,直接操作tail即可
tail.next=node;
//一旦插入完成,新节点就成了tail,需要更新tail的指向
tail=tail.next;
}
}
return head;
}