Original | Robô Wen BFT

01 Introdução
definição
Inteligência Artificial (A): Uma disciplina ampla cujo objetivo é criar máquinas inteligentes diferentes da inteligência natural exibida por humanos e animais.
Inteligência Geral Artificial (AlamosGold): Um termo usado para descrever um futuro em que as máquinas podem igualar ou mesmo superar toda a gama de habilidades cognitivas dos humanos em todas as tarefas economicamente valiosas.
Segurança da Inteligência Artificial: Um campo de pesquisa e tentativas de mitigar os riscos catastróficos que a futura inteligência artificial pode representar para a humanidade.
Machine Learning (ML): Um subconjunto de inteligência artificial que geralmente usa técnicas estatísticas para permitir que uma máquina "aprenda" com os dados sem receber instruções explícitas sobre como fazê-lo. O processo é chamado de "treinamento" de um "modelo", usando um algoritmo de aprendizado que melhora gradualmente o desempenho do modelo em uma determinada tarefa.
Aprendizado por Reforço (RL): Um campo de aprendizado de máquina no qual os agentes de software aprendem o comportamento direcionado a objetivos por meio de tentativa e erro em um ambiente que fornece recompensas ou punições em resposta às ações que eles executam para atingir um objetivo (chamadas de "políticas") .
Deep Learning (DL): Um campo de aprendizado de máquina que tenta imitar a atividade de camadas de neurônios no cérebro para aprender a reconhecer padrões complexos em dados. "Deep" refere-se ao grande número de neurônios em modelos contemporâneos, o que facilita o aprendizado de representações de dados ricas para melhores ganhos de desempenho.
Modelo: depois que um algoritmo de ML é treinado com dados, a saída do processo é chamada de modelo. Isso pode então ser usado para fazer previsões.
Visão computacional (CV): permitindo que as máquinas analisem, entendam e processem imagens e vídeos
Arquitetura de modelo de transformador: no centro da maioria das pesquisas de ML de última geração (SOTA). Consiste em várias camadas de "atenção" que aprendem qual parte dos dados de entrada é mais importante para uma determinada tarefa. Transformers começou com modelagem de linguagem e depois expandiu para visão computacional, áudio e outras modalidades.
Pesquisar
Os modelos difusos conquistaram o mundo da visão computacional com seus impressionantes recursos de geração de texto para imagem
A IA estuda mais problemas científicos, incluindo reciclagem de plástico, controle de reator de fusão nuclear e descoberta de produtos naturais.
A lei do dimensionamento Reorientando os dados: talvez o dimensionamento do modelo não seja tudo o que você precisa. O código-fonte aberto de grandes modelos conduzido pela comunidade está acontecendo em uma velocidade vertiginosa, permitindo que os coletivos concorram com grandes laboratórios.
indústria
As novas startups de semicondutores estão avançando contra a NVIDIA? As estatísticas de uso de alumínio mostram que a NVIDIA está 20 a 100 vezes à frente. Grandes empresas de tecnologia expandem suas nuvens de IA e formam grandes parcerias com startups A(G)L
A empresa de pesquisa e desenvolvimento de medicamentos MaiorAl possui 18 ativos clínicos e a primeira marca CE foi premiada .
política
A lacuna entre a academia e a indústria no trabalho de IA em larga escala pode não ser superada: a academia não está fazendo quase nada A academia está passando o bastão para um coletivo de pesquisa fragmentado financiado por fontes não tradicionais.
O grande renascimento das capacidades dos semicondutores americanos está começando para valer.
- A IA continua a ser infundida em mais categorias de produtos de defesa, as startups de IA de defesa obtêm mais segurança de financiamento
- A conscientização, o talento e o financiamento para a pesquisa de segurança da IA aumentaram, mas ainda estão muito atrás da pesquisa de capacidade.
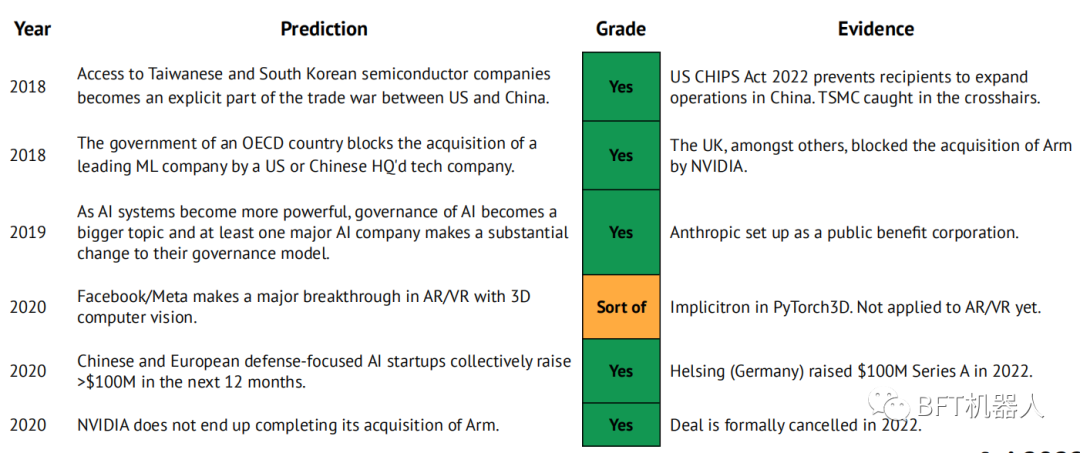
Nossas previsões para 2021
-
Transformers substituem RNNs para aprender modelos de mundo, e agentes RL excedem o desempenho humano em jogos grandes e ricos.
-
A ASML tem uma capitalização de mercado de US$ 50 bilhões.
-
A Anthropic publica artigos no nível de GPT e DotaAlphaGo, tornando-se o terceiro pólo de pesquisa da AlamosGold.
-
Tem havido uma onda de consolidação na indústria de semicondutores de alumínio, já que pelo menos uma das empresas Graphcore, Cerebras, SambaNova, Groq ou Mythic foi adquirida por uma grande empresa de tecnologia ou de semicondutores.
-
O modelo híbrido Small Transformer+CNN corresponde ao SOTA atual no imageNet (CoAtNet-7, 90,88%, parâmetros 244B) com 10 vezes menos parâmetros
-
DeepMind mostra grande avanço na ciência física
-
Conforme medido pela PapersWithCode, o volume de repo criado pelos frameworks JAX cresceu de 1% para 5% ao mês.
-
Uma nova empresa de pesquisa focada na AlamosGold é lançada com apoio significativo e um roteiro que se concentra em um setor vertical (por exemplo, ferramentas de desenvolvedor, ciências da vida).

02Pesquisa de investigação
Previsões para 2021: os avanços da DeepMind na ciência física (1/3)
Em 2021, prevemos: "A DeepMind lançou um grande avanço de pesquisa nas ciências físicas. Desde então, a empresa fez grandes avanços em matemática e ciência dos materiais."
Um dos momentos decisivos na matemática é formular uma conjectura ou hipótese sobre a relação entre as variáveis de interesse. Isso geralmente é obtido observando um grande número de instâncias dos valores dessas variáveis e, possivelmente, usando uma abordagem baseada em dados para geração de estimativas. Mas eles estão limitados a objetos matemáticos de baixa dimensão, lineares e geralmente simples.
Em um artigo na Nature, os pesquisadores da DeepMind propõem um fluxo de trabalho alternativo envolvendo matemáticos e um modelo de ML supervisionado (normalmente um NN). Os matemáticos assumem que uma função envolve duas variáveis (entrada X() e saída Y()). Um computador gera um grande número de instâncias variáveis e dados para um ajuste de rede neural. Métodos de saliência de gradiente são usados para determinar as entradas mais relevantes em X >. Os matemáticos podem, então, refinar suas hipóteses e/ou gerar mais dados até que a conjectura seja válida para uma grande quantidade de dados.

Previsões para 2021: os avanços da DeepMind na ciência física (2/3)
Em 2021, foi previsto: "DeepMind lançou um grande avanço de pesquisa nas ciências físicas." Desde então, a empresa fez grandes avanços em matemática e ciência de materiais.
Pesquisadores da DeepMind, trabalhando com professores de matemática nas Universidades de Sydney e Oxford, usaram sua estrutura (i) para criar um algoritmo que poderia resolver uma conjectura de 40 anos na teoria da representação.
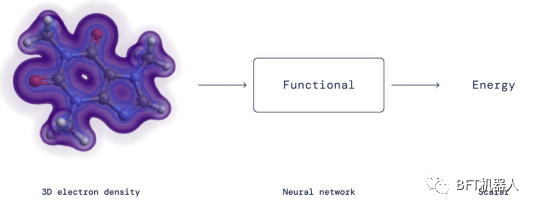
DeepMind também fez importantes contribuições na ciência dos materiais. Os resultados mostram que o funcional exato na teoria do funcional da densidade é uma ferramenta importante para calcular a energia do elétron e pode ser aproximado eficientemente por redes neurais. Vale a pena notar que os pesquisadores não restringiram a rede neural para verificar as restrições matemáticas da função DFT, mas apenas as incorporaram aos dados de treinamento adequados para a rede neural.

Previsões para 2021: os avanços da DeepMind na ciência física (3/3)
Em 2021, prevemos: "A DeepMind publica uma importante descoberta de pesquisa nas ciências físicas." Desde então, a empresa fez grandes avanços em matemática e ciência de materiais
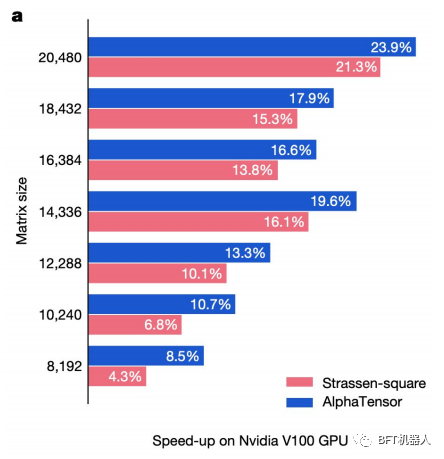
A DeepMind reaproveitou o AlphaZero (seu modelo RL treinado para derrotar os melhores jogadores humanos no xadrez, go e shogi) para fazer a multiplicação de matrizes. Este modelo AlphaTensor é capaz de encontrar novos algoritmos determinísticos para multiplicar duas matrizes. Para usar o AlphaZero, os pesquisadores reformularam o problema de multiplicação de matrizes como um jogo single-player, onde cada passo corresponde a uma instrução algorítmica, e o objetivo é zerar um tensor para medir a correção do algoritmo preditivo.
Encontrar algoritmos mais rápidos para a multiplicação de matrizes, um problema enganosamente simples e bem estudado, tem sido banal há décadas. A abordagem da DeepMind não só ajudou a acelerar a pesquisa neste campo, como também avançou técnicas baseadas na multiplicação de matrizes, nomeadamente inteligência artificial, imagem e tudo o que acontece nos telemóveis.
O aprendizado por reforço pode ser um componente central do próximo avanço da fusão nuclear
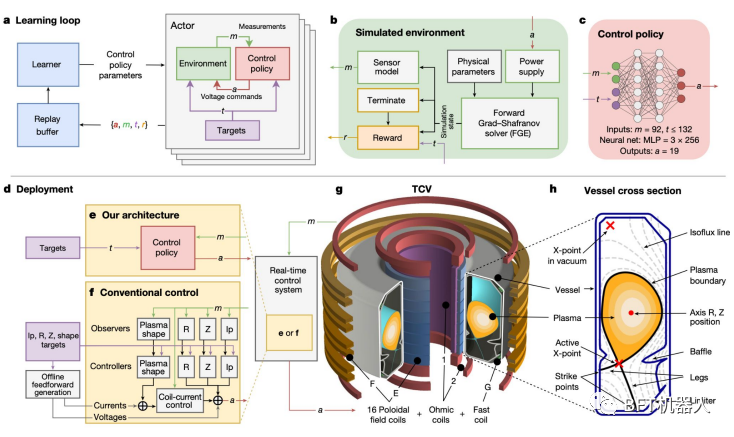
A DeepMind treinou um sistema de aprendizado por reforço para sintonizar as bobinas magnéticas do Lausanne TCV (tokamak de configuração variável). A flexibilidade do sistema significa que ele também pode ser usado no ITER, o tokamak de última geração sendo construído na França.
Uma rota popular para a fusão nuclear é usar um tokamak para confinar um plasma extremamente quente por tempo suficiente.
Um grande obstáculo é que o plasma é instável, perdendo calor e degradando materiais quando atinge as paredes do tokamak. Estabilizá-lo requer ajustar as bobinas magnéticas milhares de vezes por segundo.
O sistema deep RL da DeepMind fez exatamente isso: primeiro em um ambiente simulado e depois implantado no TCV em Lausanne. O sistema também é capaz de moldar o plasma de novas maneiras, inclusive tornando-o compatível com o projeto do ITER.
Prevendo a estrutura de todo o proteoma conhecido: o que será revelado a seguir?
Desde o código aberto, o AlphaFold2 da DeepMind tem sido usado em centenas de trabalhos de pesquisa. A empresa já implantou o sistema para prever as estruturas tridimensionais de 200 milhões de proteínas conhecidas de plantas, bactérias, animais e outros organismos. Avanços a jusante possibilitados por essa tecnologia - da descoberta de medicamentos à ciência básica - levarão anos para se materializar.
Hoje, existem 190.000 estruturas 3D determinadas empiricamente no banco de dados de proteínas. Estes foram obtidos por cristalografia de raios X e microscopia crioeletrônica.
· O AlphaFoldDB lançou pela primeira vez 1 milhão de estruturas de proteínas previstas em julho de 2022.
O tamanho do banco de dados desta nova versão é 200x. Mais de 500.000 pesquisadores de 190 países usaram o banco de dados.
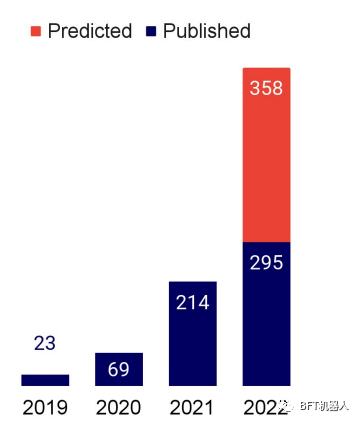
O número de menções do AlphaFold na literatura de pesquisa de IA está crescendo significativamente e deve triplicar a cada ano (gráfico à direita).
Modelos de linguagem para proteínas: uma história familiar de código aberto e modelos em escala
Os pesquisadores aplicaram independentemente modelos de linguagem para geração de proteínas e problemas de previsão de estrutura, enquanto calibravam os parâmetros do modelo. Todos relataram benefícios substanciais ao dimensionar seus modelos.
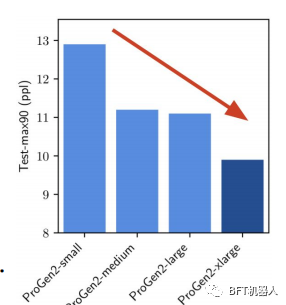
Os pesquisadores da Salesforce descobriram que estender o LM permitiu capturar melhor a distribuição de treinamento das sequências de proteínas. Usando o parâmetro 6B ProGen2, eles geraram proteínas com dobras semelhantes às proteínas nativas, mas com sequências que exibiam uma identidade diferente. No entanto, para liberar todo o potencial da escala, os autores insistem que mais ênfase deve ser colocada na distribuição de dados.
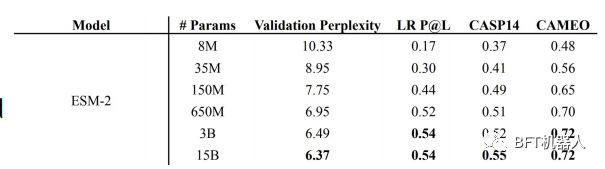
superpoderes etc A família ESM de LMs de proteína variando em tamanho de 8M a 15B (denominado ESM-2) parâmetros são introduzidos. Usando o ESM-2, eles construíram o ESMFold para prever as estruturas das proteínas e mostraram que o ESMFold produzia previsões semelhantes ao ALphaFold2 e ao RoseTTAFold, mas uma ordem de magnitude mais rápida.
Isso ocorre porque o ESMFold não depende do uso de alinhamentos de sequência múltipla (MSA) e modelos, como AlphaFold2 e RoseTTAFold, mas usa apenas sequências de proteínas.
OpenCell: Compreendendo a localização de proteínas com a ajuda do aprendizado de máquina
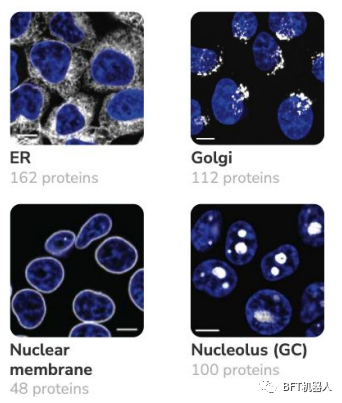
Os pesquisadores usam marcadores endógenos baseados em CRISPR para modificar genes para determinar a localização de proteínas nas células, elucidando aspectos específicos da função da proteína. Eles então usaram algoritmos de agrupamento para identificar comunidades de proteínas e formular hipóteses mecanísticas sobre proteínas não caracterizadas.
Um objetivo importante da pesquisa genômica é entender onde as proteínas estão localizadas e como elas interagem nas células para atingir funções específicas. A iniciativa OpenCell possui um conjunto de dados de 1.310 proteínas marcadas em aproximadamente 5.900 imagens 3D, permitindo que os pesquisadores mapeiem ligações importantes entre a distribuição espacial, a função e as interações das proteínas.
O agrupamento de Markov de interações de proteínas em um gráfico delineou proteínas funcionalmente relacionadas com sucesso. Isso ajudará os pesquisadores a entender melhor as proteínas até então não caracterizadas.
Muitas vezes, esperamos que o ML forneça previsões inequívocas. Mas aqui, como na matemática, o aprendizado de máquina primeiro dá uma resposta parcial (aqui, agrupamento), depois os humanos interpretam, formulam e testam hipóteses e, finalmente, dão uma resposta definitiva.
Reciclagem de plástico obtém enzima de engenharia de ML muito necessária
Pesquisadores da UTAustin desenvolveram uma enzima que pode degradar o PET, um plástico que representa 12% dos resíduos sólidos do mundo.
A PET hidrolase, denominada Fast PETase, é mais ativa que as enzimas existentes para diferentes temperaturas e valores de pH.
O FAST-PETase foi capaz de degradar quase completamente 51 produtos diferentes em 1 semana.
Eles também mostraram que poderiam ressintetizar o PET a partir de monômeros recuperados da degradação enzimática do FAST-PET, o que poderia abrir caminho para a reciclagem de PET em circuito fechado em escala industrial.


Cuidado com erros complexos.
Como ML é usado cada vez mais em ciência quantitativa, erros metodológicos em ML podem vazar para essas disciplinas. Pesquisadores de Princeton alertam que a crescente crise de reprodutibilidade na ciência baseada em aprendizado de máquina se deve em parte a um desses erros metodológicos: vazamento de dados.
Vazamento de dados é um termo abrangente que abrange todas as situações em que os dados que não deveriam estar disponíveis para o modelo estão realmente disponíveis. O exemplo mais comum é quando os dados de teste são incluídos no conjunto de treinamento. No entanto, o vazamento pode ser ainda mais prejudicial quando os recursos usados pelo modelo são proxies para a variável de resultado ou quando os dados do teste vêm de uma distribuição diferente do que a ciência afirma.
Os autores argumentam que a falha de reprodutibilidade na ciência do aprendizado de máquina de backbone é sistêmica: eles analisaram 20 revisões em 17 campos científicos, examinaram a ciência do aprendizado de máquina básico em busca de erros e descobriram que em cada uma das 329 revisões, os dados ocorreram erros de vazamento. Inspirados pelos cartões de modelo cada vez mais populares em ML, os autores recomendam que os pesquisadores usem planilhas de informações de modelo projetadas para evitar problemas de vazamento de dados.

OpenAl usa Minecraft como um testbed para agentes de uso de computador
A OpenAl treinou um modelo (Video PreTraining, VPT) para reproduzir Minecraft a partir de vídeo usando um pequeno número de interações rotuladas de mouse e teclado. O VPT é o primeiro modelo de aprendizado de máquina a aprender a fazer diamantes, "uma tarefa que normalmente leva mais de 20 minutos (24.000 operações) para um humano qualificado.
A OpenAl coletou 2.000 horas de vídeo rotuladas com ações de mouse e teclado e treinou um modelo de dinâmica inversa (IDM) para prever ações passadas e futuras — essa é a parte pré-treinamento.
Eles então usaram o IDM para rotular 70 horas de vídeo, sobre as quais treinaram um modelo para prever ações com base apenas em vídeos anteriores.
Os resultados mostram que o modelo pode ajustar o modelo (a) com aprendizado por simulação e aprendizado por reforço (RL) para obter desempenho difícil de usar RL do zero.

Laboratórios corporativos de IA lutam para entrar na IA para pesquisa de código
O Codex da OpenAl, que impulsiona o GitHub Copilot, impressionou a comunidade de ciência da computação com sua capacidade de concluir o código em várias linhas de código ou diretamente de instruções em linguagem natural. Esse sucesso estimulou mais pesquisas nessa área, inclusive da Salesforce, Google e DeepMind.
· Com o CodeGen de conversação, os pesquisadores do Salesforce podem aproveitar os recursos de compreensão de linguagem do LLM para especificar os requisitos de codificação em interações de idiomas em vários turnos. É o único modelo de código aberto que compete com o Codex.
Uma conquista ainda mais impressionante é o LLMPaLM do Google, que atinge desempenho semelhante ao Codex, mas com 50x menos código em seus dados de treinamento (o PaLM foi treinado em um conjunto de dados sem código maior). Ao ajustar o código Python, o PaLM supera suas contrapartes no SOTA (82% vs 717%) no Depfix, uma tarefa de reparo de código.
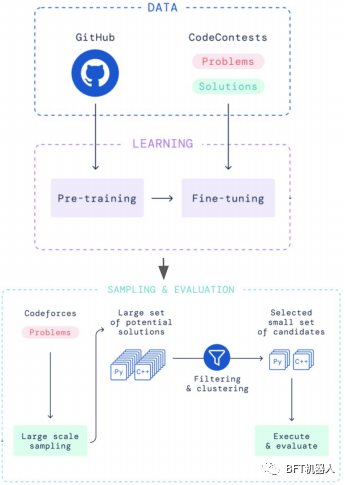
O AlphaCode da DeepMind aborda um problema diferente: gerar programas inteiros em uma tarefa de programação competitiva. Ele se classificou na metade superior do Codeforces, uma plataforma de competição de codificação. Ele é pré-treinado nos dados do GitHub e ajustado nos problemas e soluções do Codeforces. Milhões de soluções possíveis são então amostradas, filtradas e agrupadas para obter 10 candidatos finais.
Cinco anos depois do Transformer, deve haver algumas alternativas eficientes.
A camada de atenção no centro do modelo Transformer é conhecida por sua dependência quadrática de entradas. Uma infinidade de papéis promete resolver esse problema, mas não faz nada.
SOTALLM vem em diferentes tipos (autoencoder, autoregressive, codificador-decodificador), mas todos contam com o mesmo mecanismo de atenção.
Nos últimos anos, uma frota de transformadores Googol foi treinada, custando milhões e bilhões?) para laboratórios e empresas em todo o mundo. Mas os chamados "Transformadores Eficientes" (EfficientTransformers) não são encontrados em estudos LM em grande escala (eles fazem a maior diferença!) GPT-3PaLMLaMDA, Gopher, OPT, Bloom, GPT-Neo elétron gigante - Turing-NLG, GLM -130B, etc. todos usam camadas de atenção primitivas em seus transformadores.
Há várias razões para essa falta de adoção: (i) o aumento de velocidade linear potencial só se aplica a grandes sequências de entrada, (ii) o novo método introduz restrições adicionais que tornam a arquitetura menos geral, (ii) as medidas de eficiência relatadas não traduzem em custo computacional real e economia de tempo.

As capacidades matemáticas dos modelos de linguagem excedem em muito as expectativas
Com base no parâmetro LM PaLM de 540B do Google, o Minerva do Google alcançou uma pontuação de 503% no benchmark matemático (43,4% superior ao SOTA anterior), superando a melhor pontuação dos analistas em 2022 (13%). Enquanto isso, a OpenAl treinou uma rede para resolver dois problemas da Olimpíada de Matemática (IMO).
O Google usa LaTeX e MathJax para treinar seu LLM PaLM (pré-treinado) usando um conjunto de dados adicional de 118 GB de artigos científicos do arXiv e da web. Ao usar outras técnicas, como dicas de cadeia de pensamento (incluindo etapas intermediárias de raciocínio em dicas, em vez de apenas a resposta final) e votação por maioria, o Minerva melhora o SOTA em pelo menos porcentagens de dois dígitos na maioria dos conjuntos de dados.
O Minerva usa apenas modelos de linguagem e não codifica explicitamente a matemática formal. É mais flexível, mas avalia automaticamente apenas sua resposta final, e não todo o seu raciocínio, o que pode justificar alguma inflação de pontuação. Em contraste, o OpenAl constrói um provador de teorema (baseado em transformador) em um ambiente formal enxuto. Diferentes versões de seu modelo são capazes de resolver alguns problemas em AMC12(26), AIME(6) e IMO(2) (em ordem crescente de dificuldade).

Para conteúdo mais emocionante, preste atenção à conta oficial: BFT Robot
Este artigo é um artigo original e os direitos autorais pertencem ao BFT Robot. Se você precisar reimprimir, entre em contato conosco. Se você tiver alguma dúvida sobre o conteúdo deste artigo, entre em contato conosco e responderemos prontamente.