1. Coletor de lixo
Se o algoritmo de coleta é a metodologia de recuperação de memória, o coletor de lixo é o praticante da recuperação de memória. A "Especificação da Máquina Virtual Java" não faz nenhum regulamento sobre como o coletor de lixo deve ser implementado. Portanto, os coletores de lixo incluídos em diferentes fabricantes e diferentes versões de máquinas virtuais podem ser muito diferentes. Diferentes máquinas virtuais geralmente Vários parâmetros também serão fornecido para que os usuários combinem os coletores usados por cada geração de memória de acordo com suas próprias características e requisitos de aplicação.
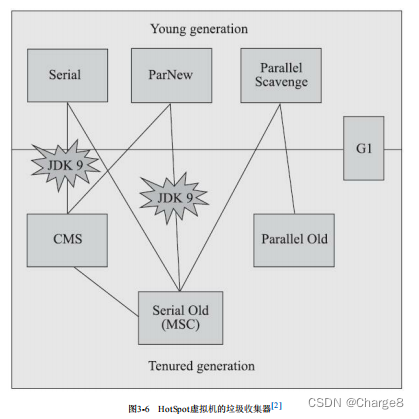
A figura mostra sete coletores que atuam em diferentes gerações. Se houver ligação entre os dois coletores, significa que eles podem ser usados juntos. A área onde o coletor está localizado na figura indica que ele pertence ao coletor de nova geração. Ou o colecionador da velha geração.
1. Coletor serial
O coletor Serial é o coletor mais básico e antigo, costumava ser (antes do JDK1.3.1) a única escolha para o coletor de nova geração da máquina virtual HotSpot.
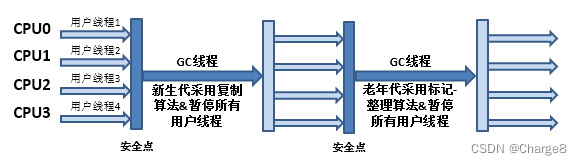
Como você pode adivinhar apenas olhando para o nome, o coletor serial é um coletor de encadeamento único , mas seu significado de "encadeamento único" não significa que ele usa apenas um processador ou um encadeamento de coleta para concluir o trabalho de coleta de lixo e muito mais mais importante, ele enfatiza que, quando está coletando lixo, todos os outros threads de trabalho devem ser suspensos até que termine a coleta. Embora o coletor serial seja antigo, ainda é recomendado no lado do cliente porque é eficiente, simples e o coletor com consumo mínimo de memória adicional.
“Stop The World”Essa palavra pode parecer legal, mas esse trabalho é iniciado e concluído automaticamente pela máquina virtual em segundo plano, e todos os threads de trabalho normais do usuário são interrompidos quando o usuário é desconhecido e incontrolável.
Parâmetros correspondentes:
- -XX:+UsarSerialGC
Usar o coletor serial para reciclagem Este parâmetro fará com que tanto a nova geração quanto a geração antiga usem o coletor serial, a nova geração use o algoritmo de cópia e a geração antiga use o algoritmo mark-sort. O coletor serial é o coletor mais básico e mais antigo e é um coletor de encadeamento único. Assim que o coletor começa a funcionar, todo o sistema para. Ele é ativado por padrão no modo Cliente e desativado por padrão em outros modos.
- -XX: Survivor Ratio
-XX:SurvivorRatio=6, defina a proporção da área de Eden para uma área de Sobrevivente é 6:1, Eden é 6, dois Sobreviventes são 2, Eden responde por 6/8 da nova geração, ou seja, 3/4, cada Survivor responde por 1/8, duas contas por 1/4
- -XX:PretenureSizeThreshold
-XX:PretenureSizeThreshold=1024 1024 10 Quando este valor for excedido, o objeto irá alocar memória diretamente na geração antiga.O valor padrão é 0, o que significa que não importa quão grande seja, a memória será alocada no eden primeiro.
- -XX: HandlePromotionFailure
-XX: HandlePromotionFailure=true/false, alterne para garantia de alocação de espaço:
Antes que ocorra o Minor GC, a máquina virtual primeiro verifica se o espaço contínuo máximo disponível na geração antiga é maior que o espaço total de todos os objetos na nova geração.
Se for maior, execute o Minor GC e, se for menor, verifique se a configuração -XX:+HandlePromotionFailure permite falha de garantia (se não, então direcione o Full GC).
Se for permitido, continuará verificando se o espaço contínuo máximo disponível na geração antiga é maior que o tamanho médio dos objetos promovidos à geração antiga. Se for maior, tente Minor GC (se a tentativa
falhar, Full GC também será acionado), e se for menor, será executado o Full GC.
Nota: Após JDK 6 Update 24, o parâmetro -XX:HandlePromotionFailure não afetará mais a política de garantia de alocação de espaço da máquina virtual.
2. ParNovo coletor
O coletor ParNew é essencialmente uma versão paralela multiencadeada do coletor serial . Além de usar vários encadeamentos para coleta de lixo ao mesmo tempo, os comportamentos restantes incluem todos os parâmetros de controle, algoritmos de coleta, Stop The World e regras de alocação de objetos disponíveis ao coletor Serial. , estratégia de reciclagem, etc. são exatamente os mesmos do coletor Serial.
Falando em ParNew, tenho que falar sobre o CMS com antecedência:
Quando o JDK 5 foi lançado, o HotSpot lançou um coletor de lixo que marcou época, o coletor CMS. Pela primeira vez, é possível fazer com que threads de coleta de lixo funcionem (essencialmente) simultaneamente com threads de usuário. Parâmetros para ativar o CMS: -XX:+UseConcMarkSweepGC. Depois de ativar o CMS, a combinação de CMS+ParNew é usada para coleta de lixo por padrão. Após JDK9, a configuração do switch do coletor ParNew: -XX:+UseParNewGC também foi cancelada! Pode-se dizer que o ParNewGC é o primeiro coletor de lixo a se retirar do palco do HotSpot.
Parâmetros correspondentes:
- -XX:+UsarParNovoGC
Parallel significa paralelo. O coletor ParNew é uma versão multi-thread do coletor Serial. Depois de usar este parâmetro, a coleta paralela será realizada na nova geração, e a coleta serial ainda será usada na geração antiga. A área S da nova geração ainda usa o algoritmo de replicação. O sistema operacional é eficaz em CPUs multi-core, e o coletor serial é recomendado para CPUs single-core.
Ao imprimir detalhes do GC, ParNew indica que o coletor ParNewGC é usado. Desativado por padrão.
Tanto paralelismo quanto concorrência são termos profissionais em programação concorrente. No contexto de falar sobre coletores de lixo, eles podem ser entendidos como:
并行(Parallel): paralelo descreve o relacionamento entre vários encadeamentos do coletor de lixo, indicando que vários desses encadeamentos estão trabalhando juntos ao mesmo tempo. Normalmente, o encadeamento do usuário está em um estado de espera por padrão neste momento.并发(Concurrent): A simultaneidade descreve o relacionamento entre os encadeamentos do coletor de lixo e os encadeamentos do usuário, indicando que os encadeamentos do coletor de lixo e os encadeamentos do usuário estão sendo executados ao mesmo tempo. Como o encadeamento do usuário não está congelado, o programa ainda pode responder às solicitações de serviço, mas como o encadeamento do coletor de lixo ocupa uma parte dos recursos do sistema, o rendimento do processamento do programa aplicativo será afetado até certo ponto.
3. Coletor Scavenge paralelo
O coletor Parallel Scavenge também é um coletor de nova geração.Ele também é um coletor baseado no algoritmo de cópia de marca e um coletor multiencadeado que pode coletar em paralelo.
Muitas características do Parallel Scavenge são superficialmente semelhantes ao ParNew. A característica do coletor Parallel Scavenge é que seu foco é diferente de outros coletores:
- O foco de coletores como o CMS é que
尽可能地缩短垃圾收集时用户线程的停顿时间quanto menor o tempo de pausa, mais adequado para programas que precisam interagir com os usuários ou garantir a qualidade da resposta do serviço.Uma boa velocidade de resposta pode melhorar a experiência do usuário; - E o objetivo do coletor Parallel Scavenge é
达到一个可控制的吞吐量(Throughput).
Taxa de transferência aqui: refere-se à relação entre o tempo que o processador gasta executando o código do usuário e o tempo total consumido pelo processador.
Ou seja: taxa de transferência = tempo de código de usuário em execução / (tempo de código de usuário em execução + tempo de coleta de lixo em execução)
alta taxa de transferência pode fazer o uso mais eficiente dos recursos do processador e concluir as tarefas de cálculo do programa o mais rápido possível, principalmente adequado para cálculos em segundo plano sem muito Múltiplas tarefas de análise interativa.
Parâmetros relacionados ao coletor Parallel Scavenge:
- -XX:+UsarParallelGC
A nova geração usa o coletor paralelo e a velha geração usa o coletor serial. O coletor Parallel Scavenge é semelhante em todos os aspectos ao coletor ParNew e seu objetivo é obter uma taxa de transferência controlável. O modo de servidor é ativado por padrão e outros modos são desativados por padrão.
- -XX: Parâmetro MaxGCPauseMillis
O valor permitido por este parâmetro é um número de milissegundos maior que 0, e o coletor fará o possível para garantir que o tempo gasto na recuperação de memória não exceda o valor definido pelo usuário. Mas não pense que se você definir o valor deste parâmetro para ser menor, a velocidade
de coleta de lixo do sistema será mais rápida . a nova geração seja menor. Coletar 300 MB da nova geração é definitivamente mais rápido do que coletar 500 MB, mas isso também leva diretamente a uma coleta de lixo mais frequente. Costumava ser coletado a cada 10 segundos com uma pausa de 100 milissegundos, mas agora é coletado a cada 5 segundos. Cada pausa é de 70 milissegundos. Os tempos de pausa diminuíram, mas o rendimento também.
-
-XX: Parâmetro GCTimeRatio
O valor deste parâmetro deve ser um número inteiro maior que 0 e menor que 100, ou seja, a razão do tempo de coleta de lixo pelo tempo total, que é equivalente ao recíproco do throughput.
Se este parâmetro for definido como 19, o tempo máximo permitido de coleta de lixo representará 5% do tempo total (ou seja, 1/(1+19)) e o valor padrão é 99, o que permite um máximo de 1% (ou seja, 1/(
1+ 99)) tempo de coleta de lixo. -
-XX: +UseAdaptiveSizePolicy parâmetro
Este é um parâmetro de troca. Quando este parâmetro é ativado, não há necessidade de especificar manualmente o tamanho da nova geração (-Xmn), a proporção de Eden para a área de Sobrevivente (-XX: SurvivorRatio) , e atualizar para o tamanho do objeto de geração antiga (-XX: PretenureSizeThreshold) e outros parâmetros detalhados,
a máquina virtual coleta informações de monitoramento de desempenho de acordo com o status atual da operação do sistema e ajusta dinamicamente esses parâmetros para fornecer o tempo de pausa mais adequado ou rendimento máximo .
4. Coletor Serial Antigo
Serial Old é uma versão antiga do coletor serial , que também é um coletor de encadeamento único que usa um algoritmo de marcação .
O principal significado desse coletor também é usado pela máquina virtual HotSpot no modo cliente. Às vezes, você verá que a implementação padrão do nome PS MarkSweep é, na verdade, uma camada de skin, e o código que realmente faz o trabalho de mark-sweep-compact sob ele e o antigo serial compartilham o mesmo código.

No modo Servidor, há dois usos principais:
(1) Antes do JDK1.5, ele pode ser usado com o coletor Parallel Scavenge (o JDK1.6 possui um coletor Parallel Old);
(2) Como um plano de backup para o coletor CMS , Usado quando ocorre falha no modo simultâneo na coleta simultânea
5. Coletor Antigo Paralelo
Parallel Old é uma versão antiga do coletor Parallel Scavenge , que oferece suporte à coleta simultânea multiencadeada e é implementada com base no algoritmo de classificação de marcas .
Este coletor não foi fornecido até o JDK 6. Antes disso, o coletor Parallel Scavenge da nova geração estava em um estado bastante embaraçoso. A razão é que se a nova geração escolher o coletor Parallel Scavenge, a geração antiga, exceto o coletor Serial Old Não há outra escolha, outros coletores bem comportados da velha geração, como o CMS, não podem funcionar com ele.
A única thread do coletor Serial Old é o gargalo de todo o sistema de coleta. Até o surgimento do coletor Parallel Old, o coletor "throughput priority" finalmente tem uma combinação mais verdadeira.
-XX:+UseParallelOldGC: Especifica o uso do coletor Parallel Old;
6. Coletor CMS
O coletor CMS (Concurrent Mark Sweep) é um coletor que visa obter o menor tempo de pausa de recuperação .
Atualmente, grande parte dos aplicativos Java está concentrada no lado do servidor de sites da Internet ou sistemas B/S baseados em navegadores. Esses aplicativos geralmente prestam mais atenção à velocidade de resposta dos serviços e esperam que o tempo de pausa do sistema seja tão curto possível para trazer aos usuários uma boa experiência interativa.
O coletor CMS é muito adequado para as necessidades deste tipo de aplicação. Pelo nome (incluindo "Mark Sweep"), pode-se perceber que o coletor CMS é implementado com base no algoritmo mark-sweep. Seu processo de operação é mais complicado que o dos coletores anteriores. Todo o processo é dividido em quatro etapas . incluem:
- 1) Marca inicial (marca inicial do CMS)
- 2) Marca concorrente (marca concorrente CMS)
- 3) Observação (observação do CMS)
- 4) Varredura simultânea (varredura simultânea do CMS)
As duas etapas de marcação inicial e remarcação ainda são necessárias "Stop The World".
- Etapa inicial de marcação: basta marcar os objetos com os quais o GC Roots pode se relacionar diretamente, a velocidade é muito rápida;
- A fase de marcação simultânea é o processo de percorrer todo o grafo de objeto dos objetos diretamente associados de GC Roots. Esse processo leva muito tempo, mas não precisa pausar os threads do usuário e pode ser executado simultaneamente com os threads de coleta de lixo;
- A fase de remarcação é para corrigir os registros de marcação da parte do objeto que foi alterada devido à operação contínua do programa do usuário durante o período de marcação concorrente. O tempo de pausa desta fase é geralmente um pouco maior que a marcação inicial fase, mas também é muito mais longa que a marcação concorrente.A duração da fase é curta;
- No estágio de limpeza concorrente , os objetos mortos julgados pelo estágio de marcação são limpos e excluídos.Como não há necessidade de mover objetos sobreviventes, este estágio também pode ser simultâneo com threads de usuário.
Como o encadeamento do coletor de lixo pode trabalhar em conjunto com o encadeamento do usuário durante as fases de marcação e limpeza simultâneas mais demoradas em todo o processo, de um modo geral, o processo de recuperação de memória do coletor CMS está relacionado ao encadeamento do usuário. são executados simultaneamente .

O CMS é um excelente coletor, e suas principais vantagens já estão refletidas no nome: 并发收集、低停顿 .
O coletor CMS é a primeira tentativa bem-sucedida da máquina virtual HotSpot de buscar pausas baixas, mas está longe de ser perfeito e tem pelo menos as três deficiências óbvias a seguir:
- 1) Em primeiro lugar, é muito sensível aos recursos de computação do computador
No estágio de simultaneidade, embora não provoque a paralisação dos threads do usuário, ele desacelerará o aplicativo e reduzirá a taxa de transferência total porque ocupa uma parte do poder de computação do processador.
O número de threads de reciclagem iniciados pelo CMS por padrão é (número de núcleos do processador + 3)/4, ou seja, se o número de núcleos do processador for quatro ou mais, os threads de coleta de lixo ocupam não mais que 25% do processador operações durante recursos de reciclagem simultâneos e diminuirá à medida que o número de núcleos de processador aumentar. Mas quando o número de núcleos do processador é menor que quatro, o impacto do CMS nos programas do usuário pode se tornar muito grande.
- 2) Em segundo lugar, o CMS não pode lidar com "lixo flutuante"
Pode haver "Falha no modo simultâneo", levando a "Parar o mundo" na marcação simultânea e na fase de limpeza simultânea do CMS, o thread do usuário ainda está em execução, o programa está em execução e, naturalmente, novos objetos de lixo continuarão a ser gerados , mas essa parte dos objetos de lixo aparece após o término do processo de marcação e o CMS não pode descartá-los na coleta atual, portanto, deve ser limpo na próxima coleta de lixo. Essa parte do lixo é chamada de "lixo flutuante".
É também porque o thread do usuário precisa continuar rodando durante a fase de coleta de lixo, então é necessário reservar espaço de memória suficiente para o thread do usuário usar, então o coletor do CMS não pode esperar até que a geração antiga esteja quase completamente preenchida como outras coletores. Para coletar, uma parte do espaço deve ser reservada para a operação do programa durante a coleta simultânea.
Na configuração padrão do JDK 5, o coletor CMS será ativado quando 68% do espaço na geração antiga for usado. Esta é uma configuração conservadora. Na época do JDK 6, o limite de inicialização do coletor CMS foi aumentado para 92%. Mas isso facilitará o enfrentamento de outro risco: se a memória reservada durante a operação do CMS não puder atender às necessidades do programa para alocar novos objetos, haverá uma "Falha no Modo Concorrente" e a máquina virtual terá que Inicie o plano de backup: congele a execução do thread do usuário e "Pare o mundo" neste momento e habilite temporariamente o coletor Serial Old para coletar novamente o lixo na idade antiga, mas o tempo de pausa será muito longo.
- 3) Por fim, o CMS usa o algoritmo "mark-clean" e não moverá os objetos sobreviventes, o que gerará fragmentação excessiva do espaço de memória
Quando há muitos fragmentos de espaço, isso trará muitos problemas para a alocação de objetos grandes. Freqüentemente, ainda há muito espaço restante na geração antiga, mas é impossível encontrar um espaço contíguo grande o suficiente para alocar o objeto atual, e tem que acionar um GC Completo em caso avançado. Quando o coletor CMS tiver que executar o GC completo, ele mesclará e organizará os fragmentos de memória por padrão.
Parâmetros de configuração correspondentes:
- -XX:+UsarConcMarkSweepGC
Habilitar CMS: -XX:+UseConcMarkSweepGC
- -XX:ParallelCMSTreads
O número de encadeamentos de reciclagem iniciados pelo CMS por padrão é (ParallelGCThreads + 3)/4). Se precisar defini-lo explicitamente, você pode defini-lo por -XX:ParallelCMSThreads=20, em que ParallelGCThreads é o número de encadeamentos de coleta paralela em a geração jovem
- -XX:+UseCMSCompactAtFullCollection e -XX:CMSFullGCsBeforeCompaction=10 (ativado por padrão, JDK 9 obsoleto)
O CMS não irá desfragmentar o heap, portanto, para evitar o gc completo causado pela fragmentação do heap, a opção de mesclar fragmentos no estágio do CMS será habilitada: -XX:+UseCMSCompactAtFullCollection (
habilitado por padrão, JDK 9 obsoleto), habilitar esta opção irá afetam até certo ponto o desempenho, talvez configurando o apropriado
-XX:CMSFullGCsBeforeCompaction=10 (JDK 9 obsoleto), para ajustar o desempenho.
Após a última execução de GC simultânea do CMS, quantos GCs completos serão executados antes de mesclar os fragmentos. O padrão é 0, ou seja, na configuração padrão, toda vez que o CMS GC não aguentar e quiser transferir para o GC completo, ele mesclará fragmentos.
Se você configurar CMSFullGCsBeforeCompaction como 10, ele só mesclará fragmentos a cada 10 GCs completos reais.
- -XX:+CMSParallelRemarkEnabled
Para reduzir o tempo da segunda pausa, ative a observação paralela: -XX:+CMSParallelRemarkEnabled
Se a observação ainda for muito longa, você pode ativar a opção -XX:+CMSScavengeBeforeRemark para
forçar um gc menor a iniciar antes da observação, reduzindo o tempo de pausa da observação, mas em Outro gc menor começará imediatamente após a observação.
- Para evitar o gc total causado pela área total de Perm, é recomendável habilitar a opção de área de Perm de reciclagem CMS:
-XX:+CMSPermGenSweepingEnabled
-XX:+CMSClassUnloadingEnabled
- -XX: CMSInitiatingOccupancyFraction
O CMS padrão do JDK5 é iniciar a coleta do CMS quando a geração temporária estiver cheia de 68%.
No JDK 6, o limite de inicialização do coletor do CMS foi aumentado para 92% por padrão. Se necessário, você pode ajustar este valor adequadamente:
-XX:CMSInitiatingOccupancyFraction=80 Aqui, a recuperação do CMS será iniciada somente quando 80% estiver cheio.
- -XX:ParallelGCThreads
O número padrão de threads de coleta paralela na geração mais jovem é (cpu <= 8) ? cpu : 3 + ((cpu * 5) / 8). Se você quiser reduzir o número de threads, pode ajustá-lo com -XX :ParallelGCThreads=N
.
7. Coletor G1
O coletor Garbage First (G1 para abreviar) é uma conquista marcante na história do desenvolvimento da tecnologia do coletor de lixo. Ele foi pioneiro na ideia de design do coletor para coleta local e no formulário de layout de memória baseado em região . G1 é um coletor de lixo principalmente para aplicações do lado do servidor.
No dia em que o JDK9 foi lançado, o G1 anunciou a substituição da combinação de Parallel Scavenge e Parallel Old como coletor de lixo padrão no modo servidor, enquanto o CMS foi reduzido a um coletor declarado como não recomendado (Deprecate).
Para todos os outros coletores antes do coletor G1, incluindo CMS, o intervalo de destino da coleta de lixo é toda a nova geração (MinorGC), ou toda a idade antiga (MajorGC), ou todo o heap Java (Full GC). Mas o G1 saltou dessa gaiola, ele pode enfrentar qualquer parte da memória heap para formar uma coleção (Collection Set, geralmente chamada de CSet) para reciclagem, o padrão de medição não é mais a qual geração ele pertence, mas a quantidade de lixo armazenado em qual memória No máximo, o benefício de recuperação é o maior, que é o modo Mixed GC do coletor G1.
O layout de memória heap baseado em região, pioneiro do G1, é a chave para sua capacidade de atingir esse objetivo.
Embora o G1 ainda seja projetado de acordo com a teoria da coleção geracional, seu layout de memória heap é muito diferente de outros coletores:
- O coletor GC tradicional divide o espaço de memória contínua em nova geração, geração antiga e geração permanente
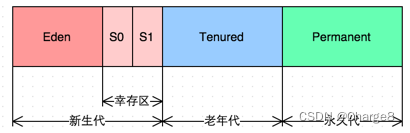
- Os endereços de armazenamento de cada geração de G1 são descontínuos, e cada geração usa n regiões descontínuas de mesmo tamanho, e cada região ocupa um endereço de memória virtual contínuo.
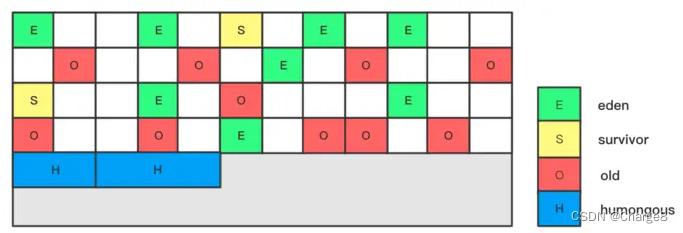
Cada Região pode atuar como o espaço Éden da nova geração, o espaço do Sobrevivente ou o espaço da velha geração de acordo com as necessidades.
O colecionador pode adotar diferentes estratégias para lidar com Regiões que desempenham papéis diferentes, de forma que, seja um objeto recém-criado ou um objeto antigo que sobreviveu por um período de tempo e sobreviveu a várias coleções, pode obter bons resultados de coleta.
Há também uma área especial de Humongous na região, que é usada especialmente para armazenar objetos grandes.
O G1 acredita que desde que o tamanho ultrapasse a metade da capacidade de uma Região, ela pode ser julgada como um objeto grande.
O tamanho de cada região pode ser definido pelo parâmetro -XX: G1HeapRegionSize, o intervalo de valores é de 1 MB ~ 32 MB e deve ser a enésima potência de 2.
Para aqueles objetos supergrandes que excedem a capacidade de toda a Região, eles serão armazenados em Regiões Humongous consecutivas N. A maioria dos comportamentos do G1 considera a Região Humongous como parte da velhice.
Embora o G1 ainda mantenha o conceito de geração jovem e geração antiga, a nova geração e a geração antiga não são mais fixas, mas uma coleção dinâmica de uma série de regiões (não necessariamente contínuas).
A razão pela qual o coletor G1 pode estabelecer um modelo de tempo de pausa previsível é que ele considera a Região como a menor unidade de uma única coleção, ou seja, o espaço de memória coletado a cada vez é um múltiplo inteiro do tamanho da Região, de modo que pode A coleta de lixo em toda a área é executada em todo o heap Java.
Uma ideia de processamento mais específica é deixar o catador do G1 rastrear o "valor" do acúmulo de lixo em cada Região. lista em segundo plano. A cada vez, de acordo com o tempo de pausa de coleta permitido definido pelo usuário (especificado através do parâmetro -XX: MaxGCPauseMilis, o valor padrão é 200 milissegundos), são priorizadas as Regiões com o maior valor de recuperação, que é o origem do nome " Garbage First" . Esse método de usar a região para dividir o espaço de memória e priorizar a reciclagem da região garante que o coletor G1 possa obter a maior eficiência de coleta possível dentro de um tempo limitado.
O modo GC de G1 fornece dois modos GC:
- jovem GC
- GC misto。
7.1 G1 Jovem GC
Ele será acionado quando o espaço Eden estiver esgotado e o GC da área Eden será iniciado. Nesse caso, os dados no espaço Eden serão movidos para o espaço Survivor. Se o espaço Survivor não for suficiente, parte do os dados no espaço Eden serão promovidos diretamente para o espaço antigo.
Os dados na área Survivor são movidos para a nova área Survivor e alguns dados também são promovidos para o espaço de geração anterior.
No final, os dados no espaço Eden estão vazios, o GC para de funcionar e o encadeamento do aplicativo continua a ser executado.
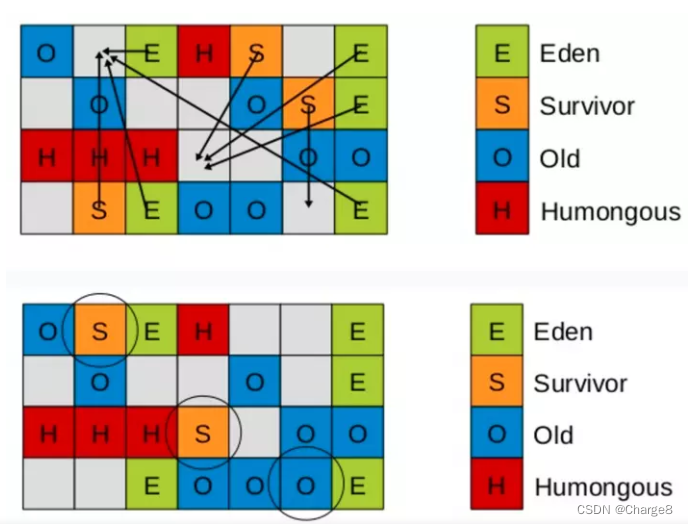
Neste momento, precisamos considerar um problema: se apenas os objetos da nova geração forem GC, os objetos da área Young ainda podem ter referências à área Old: esse é o problema das referências intergeracionais.
Para evitar a varredura de todo o heap, isso levará muito tempo. Assim, o G1 introduziu os conceitos de RSet (Remembered Set) e mesa de cartas.
A ideia básica é trocar espaço por tempo.
7.1.1 Conjunto lembrado
GC de geração jovem (acontece com muita frequência). De um modo geral, o processo de GC é assim:
Primeiro enumere o nó raiz. O nó raiz pode estar na nova geração ou na velha geração.
Aqui, como queremos coletar apenas a nova geração (ou seja, não queremos coletar a geração antiga), não há necessidade de fazer uma análise de acessibilidade abrangente nas raízes do GC localizadas na geração antiga. Mas o problema é que realmente pode haver um GC Root na geração antiga, que se refere a um objeto na nova geração, você não pode limpar esse objeto e o modo G1 é um objeto vivo.
A chave é como julgar rapidamente quais objetos são tais objetos? Uma varredura completa da geração antiga claramente não é econômica.
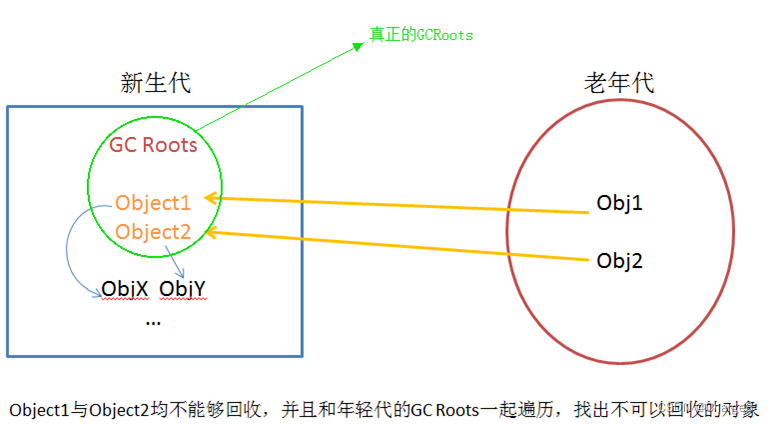
De fato, para a relação de referência entre objetos em idades diferentes, a máquina virtual irá gravá-la durante a execução do programa.
Correspondendo ao exemplo acima, a relação de "objetos na velha geração referenciando objetos na nova geração" será registrada em um espaço especial ao lado da nova geração quando ocorrer a relação de referência. Este é o Conjunto Lembrado, e o Conjunto Lembrado registra a nova geração Os objetos da geração antiga são referenciados pela geração anterior.
Portanto, "GC Roots da nova geração" + "conteúdo armazenado no Conjunto Lembrado" são as raízes GC reais quando a nova geração é coletada. Em seguida, você pode usar isso como base para fazer análises de acessibilidade na nova geração e realizar a coleta de lixo.
O coletor G1 usa a ideia de dividir em partes, e divide uma grande memória em vários domínios (Região).
Mas o problema é que é inevitável que os objetos de uma Região se refiram a objetos de outra Região. Para atingir a finalidade de coleta de lixo em unidades de Regiões, o coletor G1 também utiliza a tecnologia Conjunto Relembrado. Cada Região em G1 possui um Conjunto Lembrado correspondente, que registra a situação em que seus próprios objetos são referenciados por objetos externos em cada Região. Ao executar a recuperação de memória, adicionar Conjunto Lembrado ao intervalo de enumeração do nó raiz do GC pode garantir que todo o heap não seja verificado e que não haja omissões.
O G1 GC depende apenas do RSet em dois cenários:
- Referências da geração antiga para a geração jovem: G1 GC mantém um ponteiro da geração antiga para a geração jovem, que é armazenado no RSet da geração jovem.
- Referências da velha geração para a velha geração: o ponteiro da velha geração para a velha geração é armazenado no RSet da velha geração.
7.1.2 Mesa de Cartas
Se houver muitos relacionamentos de referência entre a geração antiga e a nova geração, cada referência deve ser registrada no Rset, e o Rset vai ocupar muito espaço, então o ganho supera o ganho. Para resolver esse problema, outro conceito é introduziu em G1, a mesa de cartas (Card Table).
A tabela de cartas é uma coleção de bits, e cada bit pode ser usado para identificar se todos os objetos em uma determinada subárea da velha geração (essa área é chamada de cartão. G1 tem 512 bytes) possuem referências à nova geração objetos , para que o GC de nova geração não precise gastar muito tempo examinando os objetos da geração antiga para determinar a referência de cada objeto, mas pode verificar a tabela de cartas primeiro. Somente quando a tabela de cartas é marcada como 1, ela precisa para escanear os objetos da geração antiga nesta área, que é 0 Não deve conter referências à nova geração.
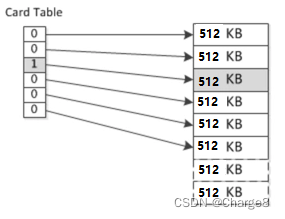
Em geral, este RSet é na verdade uma Tabela Hash, a Chave é o endereço inicial de outras Regiões e o Valor é uma coleção cujos elementos são o Índice da Tabela de Cartas.
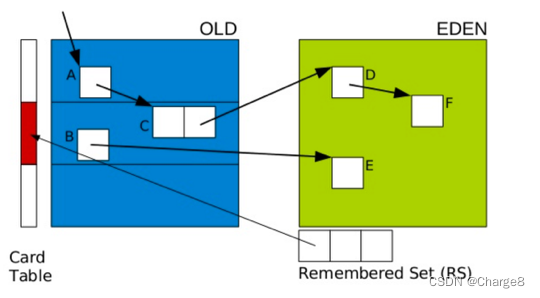
7.2 Mistura G1 GC
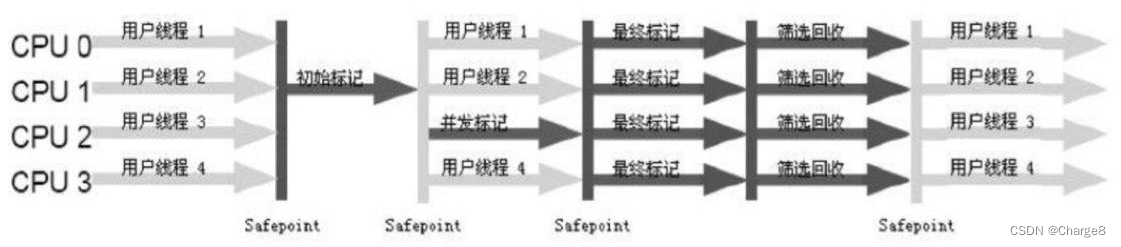
O Mix GC não apenas executa a coleta de lixo normal de nova geração, mas também recupera algumas partições de geração antiga marcadas por threads de verificação em segundo plano. Suas etapas de GC são divididas em 4 etapas:
- 1. Marca inicial (STW): Nesta etapa, G1 GC marca a tônica.
- 2. Marcação Concorrente: G1 GC procura objetos acessíveis (sobreviventes) em todo o heap.
3. Nota final (Remark, STW): Ajuda a completar o ciclo de avaliação.
4. Evacuação (STW): Identificar todas as partições livres, organizar partições de heap e identificar partições de geração antiga com alto valor de recuperação para coleta de lixo mista, classificação RSet.
7.2.1 Algoritmo de rotulagem de três cores
O instantâneo original (Snapshot At The Beginning, SATB), quando se trata de marcação simultânea, é inseparável do SATB.Para esclarecer o STAB, devemos falar sobre o algoritmo de marcação de três cores.
O algoritmo de marcação de três cores é uma maneira útil de descrever o coletor de rastreamento e pode ser usado para deduzir a exatidão da marcação simultânea do coletor.
Primeiro, dividimos os objetos em três tipos:
- Preto: O objeto raiz, ou o objeto e seus filhos, foram verificados e estão determinados como vivos.
- Cinza: O objeto em si foi verificado, mas os subobjetos no objeto não foram verificados, ou seja, o relacionamento referenciado pelos atributos de campo no objeto ainda não foi verificado.
- Branco: Objetos que não foram verificados. Após a verificação de todos os objetos, os objetos que finalmente são brancos são objetos inacessíveis, ou seja, objetos de lixo.
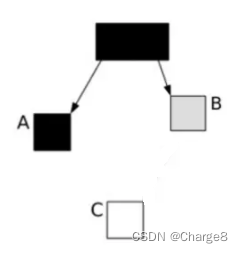
Quando o GC começar a escanear o objeto, escaneie o objeto de acordo com as seguintes etapas:
O objeto raiz é preto e os objetos filhos são cinza.
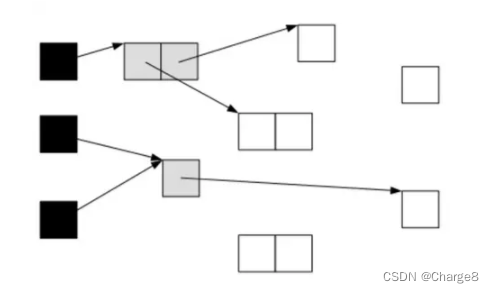
Os resultados após a varredura simultânea do GC são os seguintes:
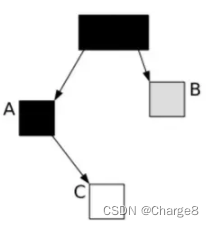
Durante a fase de marcação simultânea, o thread do aplicativo altera esse relacionamento de referência
Ac=C
Os resultados da varredura durante a fase de reetiquetagem são os seguintes:
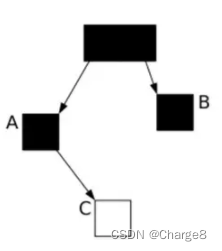
Neste caso, C será coletado como lixo.
Os objetos sobreviventes do Snapshot eram originalmente A e B, mas os objetos sobreviventes reais agora são A, B e C. A integridade do Snapshot é destruída. Obviamente, essa abordagem não é razoável.
O G1 usa uma barreira de pré-gravação para resolver esse problema. Simplificando, na fase de marcação simultânea, quando o relacionamento de referência muda, a função de barreira de pré-gravação registrará e salvará essa mudança em uma fila, chamada satb_mark_queue no código-fonte da JVM.
Na etapa de remark, esta fila será escaneada. Desta forma, o objeto apontado pela referência antiga será marcado, e seus descendentes também serão marcados recursivamente, para que nenhum objeto seja perdido, e a integridade do snapshot será reduzido. Tem garantia.
O design de atualização incremental do CMS torna necessário verificar novamente todas as pilhas de threads e toda a geração jovem como raiz durante a fase de observação; o design SATB do G1 só precisa verificar o satb_mark_queue restante durante a fase de observação, o que resolve o longo fase de observação de termo do coletor de lixo do CMS Riscos potenciais de STW.
O método SATB registra objetos vivos, ou seja, o instantâneo do objeto naquele momento, mas os objetos nele podem se tornar lixo posteriormente, chamados de lixo flutuante, e tais objetos só podem ser coletados e reciclados na próxima vez. Durante o processo de GC, objetos recém-alocados são considerados ativos e outros objetos inacessíveis são considerados mortos.
Como saber quais objetos são recém-alocados após o início do GC?
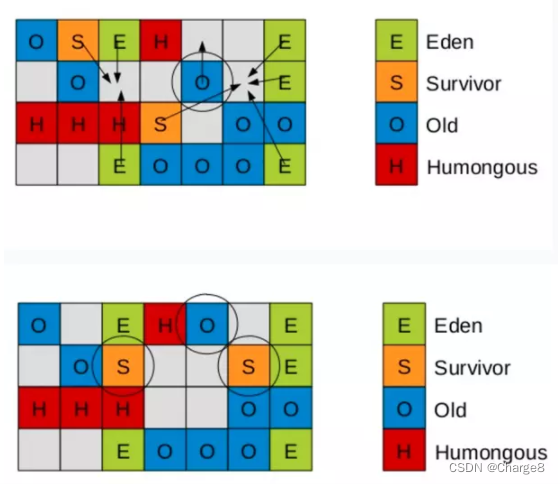
Na região, os objetos recém-configurados são registrados por meio dos ponteiros top-at-mark-start (TAMS), respectivamente prevTAMS e nextTAMS. O diagrama esquemático é o seguinte:
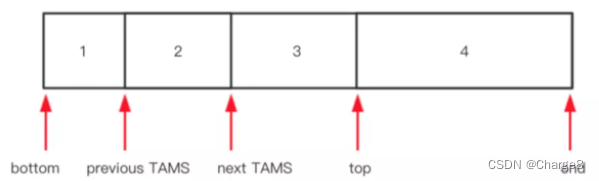
onde top é o ponteiro de alocação atual da região,
- [bottom, top) é a parte atualmente usada da região e [top, end) é o espaço alocável não utilizado (não utilizado).
- (1): [bottom, prevTAMS): Os objetos nesta parte foram marcados pela rodada n-1 de marcação simultânea
- (2): [prevTAMS, nextTAMS): Os objetos nesta parte estão implicitamente vivos na n-1 rodada de marcação simultânea
- (3): [nextTAMS, top): Os objetos nesta parte estão implicitamente vivos na enésima rodada de marcação simultânea
7.2.2 Evacuação
A fase de Evacuação está totalmente suspensa. Ele é responsável por copiar alguns objetos vivos da região para a região vazia (cópia paralela), e então recuperar o espaço da região original. No estágio de Evacuação, você pode selecionar livremente qualquer número de regiões para coletar independentemente. Essas regiões selecionadas constituem um conjunto de coleta (conjunto de coleta, referido como CSet) . A seleção de regiões no conjunto CSet depende do conjunto de tempo de pausa de coleta permitido pelo usuário (usando o parâmetro - XX: MaxGCPauseMilis especificado, o valor padrão é 200 milissegundos), esta fase não escolhe evacuar todas as regiões com objetos vivos, mas apenas seleciona um pequeno número de regiões com alto valor de reciclagem para evacuar, a sobrecarga dessa pausa pode ser (dentro de um certo intervalo) controlada.
7.2.3 GC Completo
O processo de coleta de lixo do G1 é executado simultaneamente com o aplicativo. Quando a velocidade do Mixed GC não consegue acompanhar a velocidade do aplicativo de memória pelo aplicativo, o Mixed G1 fará downgrade para Full GC e usará Serial GC. O GC completo pode levar a um STW longo e deve ser evitado tanto quanto possível.
Pode haver dois motivos para G1 Full GC:
- Durante a Evacuação, não há espaço suficiente para armazenar os objetos promovidos;
- Esgotamento de espaço antes da conclusão do processamento simultâneo
Os parâmetros de configuração principais relacionados usam JDK8 como ambiente:
O G1 GC nos fornece muitas opções de linha de comando, ou seja, parâmetros. Esses parâmetros começam com um tipo booleano, "+" significa habilitar essa opção e "-" significa desabilitar essa opção. O outro tipo usa atribuição numérica e não requer um tipo booleano para iniciar.
-
-XX:+UseG1GC ativa o coletor de lixo G1
-
-XX:G1HeapRegionSize=nM (com unidade)
Esta é uma opção exclusiva do G1GC. O tamanho padrão da região é 1/200 do tamanho do heap e também pode ser definido como 1 MB, 2 MB, 4 MB, 8 MB, 16 MB e 32 MB, que são divididos em seis graus. Aumentar o tamanho do bloco Region é bom para lidar com objetos grandes.
Como mencionado anteriormente, objetos grandes não são gerenciados e alocados da mesma forma que objetos comuns.Se o tamanho do bloco Region for aumentado, alguns objetos grandes que originalmente passaram pelo canal de processamento especial podem ser incluídos no canal de processamento comum.
Isso é como nossa verificação de segurança do aeroporto. Pilotos e comissários de bordo podem usar passagens especiais. Se os passageiros também se especializarem e algumas pessoas forem para passagens especiais, várias passagens especiais devem ser adicionadas e as passagens comuns correspondentes devem ser reduzidas. Reproduziu um papel na redução.
Por outro lado, se o tamanho da região for muito pequeno, a flexibilidade do G1 será reduzida, o que causará problemas de alocação para cada geração de idade.
-
-XX:MaxGCPauseMillis=200 Defina o valor alvo para o tempo máximo de pausa. O padrão é 200 milissegundos.
-
-XX:G1NewSizePercent=5
Configura a porcentagem do heap a ser usada para o mínimo do tamanho da geração jovem. O padrão é 5% do heap Java, que é um sinalizador experimental.
Consulte Como desbloquear sinalizadores de VM experimentais para obter um exemplo. Requer configuração primeiro: -XX:+UnlockExperimentalVMOptions
- -XX:G1MaxNewSizePercent=60
Configura a porcentagem do tamanho de heap a ser usada para o máximo do tamanho da geração jovem. O padrão é 60% do heap Java, que é um sinalizador experimental.
É necessário configurar primeiro: -XX:+UnlockExperimentalVMOptions
- -XX:ParallelGCThreads=n
Defina o valor dos encadeamentos de trabalho STW. Defina o valor de n para o número de processadores lógicos. O valor de n é igual ao número de processadores lógicos, até 8.
Se houver mais de 8 processadores lógicos, defina o valor de n para aproximadamente 5/8 processadores lógicos.
Isso funciona na maioria dos casos, exceto para sistemas SPARC maiores, onde o valor de n é cerca de 5/16 dos processadores lógicos.
- -XX:ConcGCThreads=n
-XX:ConcGCThreads=n Define o número de roscas de marcação paralelas. Defina n como aproximadamente 1/4 do número de encadeamentos de coleta de lixo paralelos (ParallelGCThreads).
- -XX:InitiatingHeapOccupancyPercent=45
Esta opção determina se deve iniciar uma ação de coleta de geração antiga, ou seja, após o término da GC de geração jovem, o G1 avaliará se os objetos restantes atingiram o limite de 45% de todo o heap Java.
- -XX:G1MixedGCLiveThresholdPercent=85
Identifique a região antiga que precisa ser reciclada na fase de marcação simultânea e marque-a como uma região antiga candidata, para que ela possa entrar no CSet e ser reciclada na fase Mixed GC.
É controlado por G1MixedGCLiveThresholdPercent,
Quando a proporção de dados sobreviventes na região não excede o limite, significa que eles serão reciclados e a taxa de ocupação padrão é de 85%.
Durante a fase de marcação simultânea, a proporção de dados sobreviventes em cada região será recalculada. As regiões com uma grande proporção de dados sobreviventes serão relativamente caras para reciclar e também serão marcadas como regiões caras.
Se um grande número dessas regiões entrar no CSet durante a fase MixedGC, isso pode fazer com que o tempo de pausa do MixedGC seja muito longo.
Para diferenciar essas regiões, o G1 fez uma marcação separada. Durante a etapa MixedGC, a região antiga candidata é preferencialmente reciclada, se o custo permitir, tentará reciclar a região cara.
- -XX:G1HeapWastePercent=5
Indica a porcentagem tolerável de espaço de heap desperdiçado. Se a porcentagem reciclável for menor que a porcentagem configurada, a JVM não iniciará um ciclo de coleta de lixo misto.
- -XX:G1MixedGCContagemTarget=8
O tempo de recuperação da região da geração antiga geralmente é um pouco mais longo que o da região da geração mais jovem. Essa opção pode definir quantos GCs mistos são iniciados após uma marca simultânea. O valor padrão é 8. Definir um valor relativamente grande pode fazer com que o G1 GC gaste mais tempo na recuperação da região da geração antiga,
Se o tempo de pausa de um GC misto for muito longo, significa que tem muito o que fazer, então você pode aumentar a configuração desse valor para diminuir o tempo de pausa,
Mas se esse valor for muito grande, ele também causará um aumento correspondente no tempo para o loop paralelo aguardar a conclusão do GC misto.
- -XX:G1OldCSetRegionThresholdPercent=10
Durante a coleta de lixo mista, o limite máximo da região antiga que pode entrar no CSet todas as vezes (entrar no CSet significa coleta de lixo). marcadores de laboratório
O padrão é 10% do heap Java. Se o valor for muito grande, o número de regiões antigas que precisam ser coletadas toda vez que o GC misto aumentará, resultando em um tempo de pausa mais longo.
Esse valor pode limitar o número máximo de regiões antigas que podem ser recicladas em cada GC misto.
- -XX:G1ReservePercent=10
O valor da opção indica que o tamanho total do heap será aumentado de acordo e a quantidade de memória reservada será aumentada para o "espaço de destino"; é relativamente garantido que o objeto promovido não deixará de ser alocado!
- -XX:+DesbloquearExperimentalVMOptions
Para alterar o valor de um sinalizador experimental, ele deve primeiro ser desbloqueado. Defina esse parâmetro explicitamente.
2. Coletor de lixo de baixa latência (entenda)
1. Colecionador de Shenandoah
Shenandoah era originalmente um novo projeto de coletor desenvolvido independentemente pela RedHat. Em 2014, a RedHat contribuiu com Shenandoah para o OpenJDK e o promoveu para se tornar um dos recursos oficiais do OpenJDK 12, mas o OracleJDK não o suporta.
Shenandoah também usa um layout de memória heap baseado em região.Também possui regiões enormes para armazenar objetos grandes.A estratégia de reciclagem padrão também é dar prioridade à região com o maior valor de reciclagem. Mas tem pelo menos três diferenças distintas do G1 em termos de gerenciamento de memória heap .
-
1. Obviamente, o mais importante é oferecer suporte a algoritmos de classificação simultâneos. A fase de recuperação do G1 pode ser multiencadeada em paralelo, mas não pode ser simultânea com os encadeamentos do usuário. No entanto, a função principal do Shenandoah é que a recuperação e os encadeamentos de limpeza não são apenas multiencadeados, mas também compatíveis com a simultaneidade do encadeamento do usuário.
-
2. Shenandoah (atualmente) não usa coleta geracional silenciosamente, e não haverá região de nova geração dedicada e região de geração antiga.
-
3. Shenandoah e G1 possuem diferentes estruturas de dados para registrar a relação de referência da região, utilizando a "matriz de ligação",
Para o processo de trabalho específico do Shenandoah, consulte o paper do coletor de lixo do Shenandoah publicado pela RedHat em 2016.
Endereço do papel: https://www.researchgate.net/publication/306112816_Shenandoah_An_open-source_concurrent_compacting_garbage_collector_for_OpenJDK
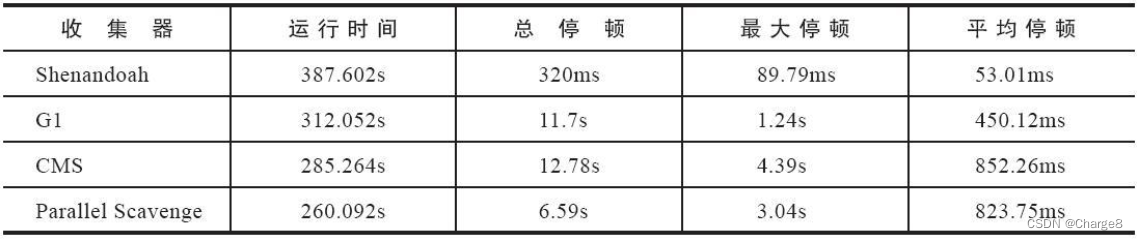
Aqui está uma comparação do desempenho real do aplicativo publicado pela RedHat em 2016:
2. Coletor ZGC
ZGC ("Z"" não é uma abreviação de um termo profissional, o nome desse coletor é Z Garbage Collector) é um coletor de lixo experimental de baixa latência adicionado recentemente no JDK 11, desenvolvido pela Oracle Corporation Developed. Em 2018, ZGC foi submetido ao OpenJDK, colocando-o na lista de lançamentos do OpenJDK 11.
Os objetivos do ZGC e do Shenandoah são muito parecidos, mas a tecnologia de implementação é bem diferente. Vamos entender brevemente as características técnicas do ZGC:
-
1) Primeiro comece com o layout de memória do ZGC. Como Shenandoah e G1, o ZGC também adota um layout de memória heap baseado em região, mas ao contrário deles, a região do ZGC (chamada de página ou ZPage em alguns materiais oficiais) é dinâmica e pode ser criada e destruída dinamicamente. Sob a plataforma de hardware x64, a Região de ZGC pode ter três tipos de capacidade: grande, média e pequena:
- Small Region (Small Region): A capacidade é fixada em 2MB, e é utilizada para colocar objetos pequenos com menos de 256KB.
- Região média (Medium Region): A capacidade é fixada em 32 MB e é usada para colocar objetos maiores ou iguais a 256 KB, mas menores que 4 MB.
- Large Region (Large Region): A capacidade não é fixa e pode ser alterada dinamicamente, mas deve ser um múltiplo inteiro de 2MB, utilizado para colocar objetos grandes de 4MB ou mais.
Apenas um objeto grande será armazenado em cada região grande, o que também indica que, embora o nome seja chamado de "Região grande", sua capacidade real pode ser menor que a de uma região de tamanho médio, e a capacidade mínima pode ser tão baixa quanto 4MB.
- 2) A função principal do ZGC realiza a função de classificação simultânea como Shenandoah, mas o método de implementação é diferente do Shenandoah. Ele usa uma tecnologia chave, tecnologia de ponteiro tingido.
Finalmente, vamos falar sobre desempenho:
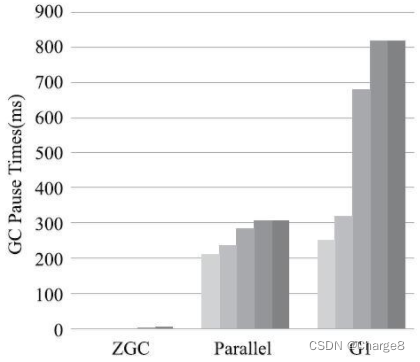
No forte teste de tempo de pausa do ZGC, ele impiedosamente abriu uma lacuna de duas ordens de magnitude com Parallel Scavenge e G1.
Seja a pausa média, pausa de 95%, pausa de 99%, pausa de 99,9% ou o tempo máximo de pausa, o ZGC pode controlá-lo facilmente em dez milissegundos, para que possa ser comparado com outros dois tipos de pausa por centenas ou milhares Quando os coletores de milissegundos são colocados juntos para comparação, a barra da coluna ZGC fica quase invisível:
Parâmetros relacionados:
Ativar ZGC: -XX:+DesbloquearExperimentalVMOptions -XX:Usar ZGC
2. Coletor Epsilon (ε)
Enquanto coletores de lixo cada vez mais complexos e avançados, como G1, Shenandoah ou ZGC, estão aparecendo um após o outro, há também um novo coletor de lixo "oposto" que aparece na lista de recursos do JDK 11—Epsilon, Este é um coletor de lixo cujo " ponto de venda" é não poder catar lixo, catador que "não dá certo" .
O coletor Epsilon foi proposto pela RedHat na PEC 318. Nesta proposta, o Epsilon é descrito como um coletor sem operação, na verdade, enquanto a máquina virtual Java funcionar, o coletor de lixo não pode ser verdadeiramente "sem operação". . A razão é que o nome "coletor de lixo" não descreve todas as suas responsabilidades, e um nome mais apropriado deveria ser "subsistema de gerenciamento automático de memória".
Além de seu trabalho de coleta de lixo, um coletor de lixo também é responsável pelo gerenciamento e layout do heap, alocação de objetos, cooperação com o interpretador, cooperação com o compilador e cooperação com o subsistema de monitoramento. less the heap
A partir do JDK 10, para isolar o relacionamento entre o coletor de lixo e a interpretação, compilação, monitoramento e outros subsistemas da máquina virtual Java, a RedHat propôs uma interface unificada para o coletor de lixo, ou seja, a proposta JEP 304. Epsilon é a verificação de validade e referência dessa implementação de interface, mas também para testes de desempenho e testes de estresse que exigem eliminar o impacto do coletor de lixo.
No ambiente de produção real, o Epsilon, que não pode executar a coleta de lixo, ainda é útil. Por muito tempo, o foco de desenvolvimento do sistema de tecnologia Java foi orientado para aplicativos de nível corporativo de longo prazo e larga escala e aplicativos do lado do servidor. A tendência tornou-se cada vez mais óbvia. estrelas como Golang, Java tem algumas deficiências inerentes a esse respeito e sua taxa de uso está diminuindo gradualmente. O Java tradicional tem as características de grande uso de memória, longo tempo de inicialização no contêiner e otimização lenta da compilação just-in-time. Isso não é um grande problema para aplicativos de grande escala, mas existem muitos aplicativos de curto e pequeno prazo. formulários de serviço de escala desconforto. A fim de lidar com as novas tendências tecnológicas, as versões recentes do JDK gradualmente adicionaram suporte para pré-compilação e compartilhamento de dados de classe orientado a aplicativos.
O Epsilon também tem um objetivo semelhante. Se o aplicativo precisar ser executado apenas por alguns minutos ou mesmo alguns segundos, desde que a máquina virtual Java possa alocar memória corretamente, ele será encerrado antes que o heap se esgote. Obviamente, o Epsilon, que tem uma carga de trabalho muito pequena e nenhum comportamento de reciclagem, é muito bom. Escolha apropriada.
Parâmetros relacionados:
-XX:+DesbloquearExperimentalVMOptions
-XX:+UsarEpsilonGC
3. Escolha o coletor de lixo certo
A máquina virtual HotSpot fornece uma grande variedade de coletores de lixo. Muitas opções tornam difícil decidir. É obviamente impossível escolher os mais avançados para atender a todos os cenários de aplicação. Vamos discutir como escolher um coletor de lixo adequado.
1. A resposta a esta pergunta é influenciada principalmente pelos três fatores a seguir:
1) Qual é o foco principal do aplicativo?
Se for uma tarefa de análise de dados ou computação científica, o objetivo é calcular os resultados o mais rápido possível, então o throughput é o foco principal;
Se for uma aplicação cliente/servidor, o tempo de pausa vai afetar diretamente a qualidade do serviço, e até causar o timeout da transação, então o atraso é a principal preocupação; se for uma aplicação cliente ou uma aplicação embarcada, então a memória uso de coleta de lixo Não pode ser ignorado.
2) E a infraestrutura para rodar o aplicativo?
Por exemplo, especificações de hardware, se a arquitetura do sistema a ser envolvida é X86-32/64, SPARC ou ARM/Aarch64;
O número de processadores e o tamanho da memória alocada;
Escolha o sistema operacional é Linux, Solaris ou Windows.
3) Qual a distribuição do JDK utilizada? Qual é o número da versão?
É ZingJDK/Azul, OracleJDK, Open-JDK, OpenJ9 ou distribuição de outra empresa?
A qual versão da Java Virtual Machine Specification o JDK corresponde?
De um modo geral, a escolha do coletor é considerada a partir dos pontos acima.
2. Dê um exemplo
Supondo que um sistema B/S que fornece serviços diretamente aos usuários vai escolher um coletor de lixo, de modo geral, o tempo de atraso é a principal preocupação desse tipo de aplicação, então,
Se você tem orçamento suficiente, mas não tem muita experiência em tuning, um conjunto de soluções proprietárias de hardware ou software com suporte técnico comercial é uma boa escolha. O sistema Vega que a Azul usou para promover e o Zing VM que agora é o principal impulso são a esse respeito. , para que você possa usar o lendário coletor C4.
Se você não tem orçamento suficiente para usar soluções comerciais, mas pode controlar os modelos de hardware e software, usar versões mais recentes e prestar atenção especial à latência, vale a pena tentar o ZGC.
Se você tiver dúvidas sobre a estabilidade do coletor que ainda está em estado experimental, ou se o aplicativo deve ser executado no sistema operacional Windows, o ZGC está fora de questão, tente Shenandoah.
Se você estiver assumindo um sistema legado e a infraestrutura de software e hardware e a versão do JDK estiverem relativamente atrasadas, meça-a de acordo com o tamanho da memória. Para memória heap de cerca de 4 GB a menos de 6 GB, o CMS geralmente pode lidar melhor com isso e para maior Para memória heap, você pode se concentrar em G1.
Claro, a análise acima é baseada apenas na teoria. No combate real, você não deve falar sobre isso no papel. Testar de acordo com a situação real do sistema é a base final para selecionar um coletor.
As informações acima vêm do livro "In-depth Understanding of JAVA Virtual Machine (JVM Advanced Features and Best Practices 3rd Edition)" autor Zhou Zhiming, aqui está o estudo para fazer os registros correspondentes.
– Se você tem fome de conhecimento, seja humilde se for tolo.