Na seção anterior, nós aprendemos sobre a coleção de gerações de JVM, e sabemos que JVM coleta de lixo adota principalmente 标记-复制algoritmos na nova geração , e, principalmente, adota 标记-清除e 标记-整理algoritmos na velha geração . A seguir, vamos dar uma olhada na implementação de alguns coletores de lixo do HotSpot da máquina virtual padrão JDK.
1. Coletores de lixo comuns
Vejamos primeiro todos os coletores de lixo disponíveis antes do JDK 11.

Existem sete tipos de coletores de lixo listados na figura.A conexão indica que eles podem ser usados juntos, e a área indica se pertence ao coletor de nova geração ou ao coletor de geração anterior.
O algoritmo de coleta usado pelo coletor de lixo também é marcado aqui. O coletor G1 é bastante especial. Ele usa o 标记-整理algoritmo como um todo e o algoritmo localmente 标记-复制, o que será discutido em detalhes posteriormente.
1.1, coletor serial
O coletor serial é o coletor mais básico e mais antigo.
Como seu nome (serial), é um coletor de thread único que usa um processador ou um thread de coleta para concluir a coleta de lixo. E durante a coleta de lixo, todos os outros threads de trabalho devem ser suspensos até que a coleta de lixo termine - isso é chamado de "Pare o mundo".
O processo de execução do coletor Serial / Serial Antigo é mostrado na figura:
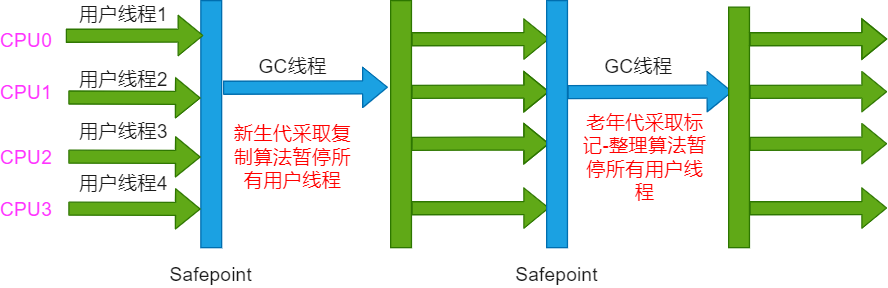
1.2, coletor ParNew
O coletor ParNew é essencialmente uma versão paralela multithread do coletor Serial, que usa vários threads para a coleta de lixo.
O processo de trabalho do coletor ParNew é mostrado na figura:
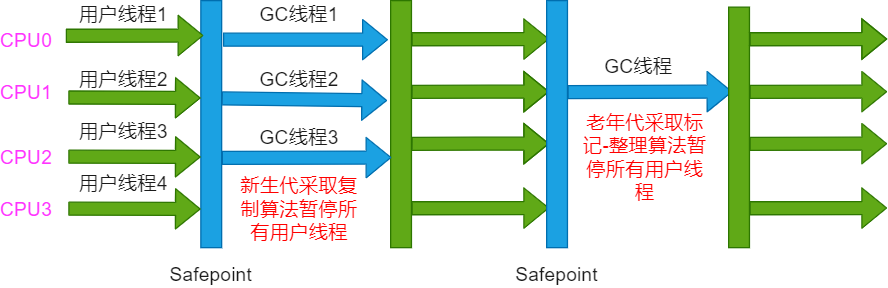
Vale a pena mencionar aqui que Par é Parallel(并行)a abreviatura, mas deve-se notar que esta é 并行(Parallel)apenas uma descrição de vários threads de GC trabalhando juntos ao mesmo tempo, em vez de threads de GC e threads de usuário em execução ao mesmo tempo. A coleta de lixo ParNew também requer Stop The World.
1.3, coletor de eliminação paralela
O coletor Parallel Scavenge é um coletor de nova geração, baseado no algoritmo de marcação e cópia, e também pode ser coletado em paralelo. Um pouco semelhante ao ParNew, mas o Parallel Scavenge está relacionado principalmente à taxa de transferência da coleta de lixo.
A chamada taxa de transferência refere-se à razão entre o tempo de execução do código do usuário e o tempo total consumido pelo processador. Quanto maior a proporção, menor a proporção da coleta de lixo em todo o programa.
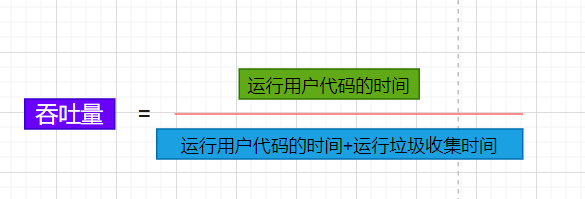
O coletor Parallel Scavenge fornece dois parâmetros para controle preciso da taxa de transferência:
-
-XX: MaxGCPauseMillis , o tempo máximo de pausa da coleta de lixo. O princípio deste parâmetro é o espaço para o tempo, o coletor controlará o tamanho da área da nova geração, de forma a garantir que a recuperação seja menor que o tempo máximo de pausa. Simplificando, quanto menor a área de reciclagem, menos tempo leva.
Portanto, este parâmetro não é o menor possível. Se a configuração for muito pequena, o espaço da nova geração será muito pequeno, acionando o GC com mais frequência. -
-XX: GCTimeRatio , a proporção do tempo de coleta de lixo em relação ao tempo total. Este é o recíproco da taxa de transferência e o princípio é o mesmo que MaxGCPauseMillis.
Devido à sua estreita relação com a taxa de transferência, o coletor Parallel Scavenge é frequentemente referido como o "coletor de prioridade de taxa de transferência".
1.4, coletor serial antigo
Serial Old é a versão antiga do coletor Serial. Também é um coletor de thread único, usando um algoritmo de marcação e classificação.
O processo de trabalho do coletor Serial Old é mostrado na figura:
1.5, coletor antigo paralelo
Parallel Old é a versão antiga do coletor Parallel Scavenge. Ele oferece suporte à coleta simultânea multithread e é implementado com base no algoritmo de classificação de marcação.
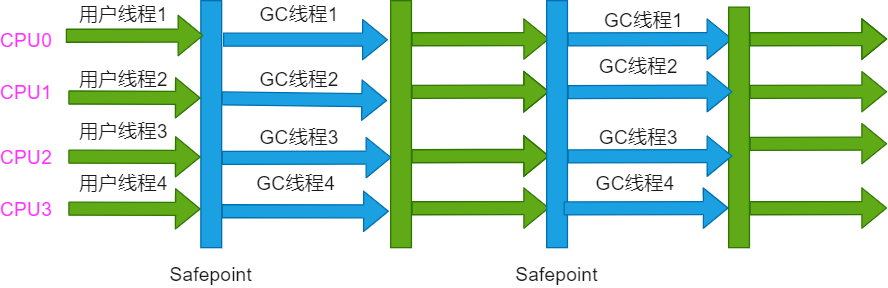
1.6, coletor CMS
O coletor CMS (Concurrent Mark Sweep) é um coletor cujo objetivo é obter o menor tempo de pausa de recuperação, é também um coletor da velhice e utiliza um 标记-清除algoritmo.
A coleta de lixo da coleta de CMS é dividida em quatro etapas:
初始标记(CMS initial mark): A operação de thread único requer Stop The World para marcar os objetos que o GC Roots pode alcançar diretamente.并发标记((CMS concurrent mark): Sem pausa, executando ao mesmo tempo que o encadeamento do usuário, percorrendo todo o gráfico do objeto desde o GC Roots diretamente até o objeto.重新标记(CMS remark): A operação multithread requer Stop The World para gerar objetos na fase de marcação simultânea.并发清除(CMS concurrent sweep): Sem pausa, execute simultaneamente com a thread do usuário e limpe os objetos mortos marcados na fase de marcação.
Envolvido no processo de marcações múltiplas, insira um pouco de
三色抽象conhecimento aqui . A abstração de três cores é usada para descrever o estado do objeto no processo de coleta de lixo.Normalmente, branco significa que o objeto não foi verificado, cinza significa que o objeto foi verificado, mas não foi processado, e preto significa que o objeto e seus descendentes foram processados. Esta abstração é usada no processo de marcação e remoção do CMS. Para detalhes, consulte [5].
O diagrama de operação do coletor de varredura de marca simultânea é o seguinte:
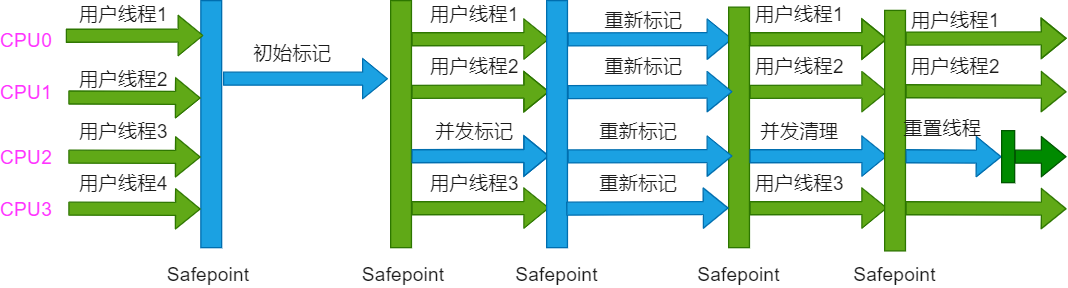
优点: As principais vantagens do CMS foram refletidas na coleção de nomes simultâneos, pausa baixa.
缺点: CMS também tem três deficiências óbvias.
-
O algoritmo Mark Sweep causará mais fragmentação da memória
-
A capacidade de simultaneidade do CMS depende mais dos recursos da CPU. Durante a coleta simultânea, o encadeamento de coleta de lixo pode prejudicar os recursos do encadeamento do usuário e prejudicar o desempenho do programa do usuário.
-
Na fase de limpeza simultânea, os threads do usuário ainda estão em execução e o chamado "lixo flutuante" (Floating Garbage) será gerado. Essa coleta de lixo não pode processar o lixo flutuante e deve ser processada na próxima coleta de lixo. Se houver muito lixo flutuante, isso acionará uma nova coleta de lixo, resultando na degradação do desempenho.
1.7, Coletor de lixo primeiro
O coletor Garbage First (G1 para abreviar) é um produto subversivo do coletor de lixo, foi pioneiro na ideia de projeto de coleta parcial e na forma de layout de memória baseado em Região.
Embora G1 ainda seja projetado de acordo com a teoria de coleção geracional, o layout de sua memória heap é muito diferente de outros coletores. A geração anterior de colecionadores foi dividida em geração jovem, geração antiga, geração persistente, etc.
G1 divide o heap Java contínuo em várias regiões independentes (regiões) de tamanho igual. Cada região pode atuar como o espaço do Éden, espaço do sobrevivente da nova geração ou o espaço da velha geração, conforme necessário. O coletor pode usar estratégias diferentes para lidar com regiões que desempenham funções diferentes.
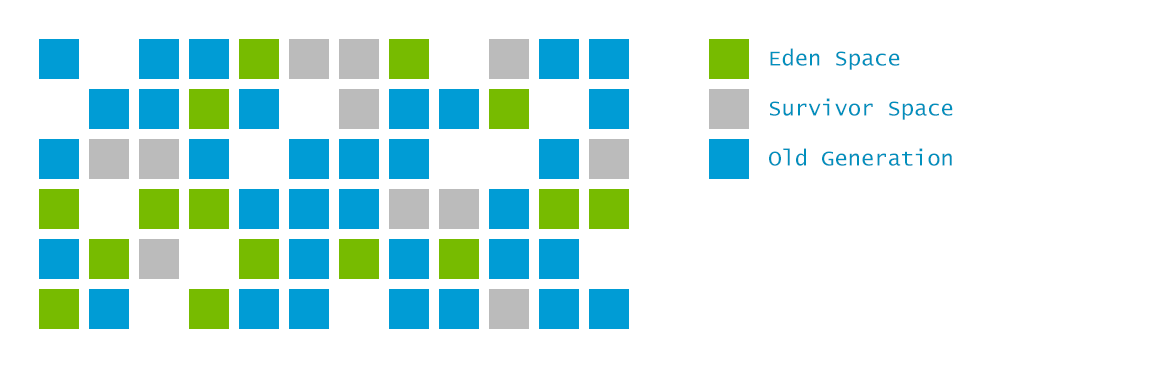
Isso evita coletar o heap inteiro, mas coleta de acordo com vários conjuntos de regiões, enquanto mantém uma lista de prioridades, rastreando o "valor da recuperação de cada região e priorizando a coleta de regiões com alto valor".
O processo operacional do coletor G1 pode ser dividido, grosso modo, nas quatro etapas a seguir:
-
A marca inicial (marca inicial) marca os objetos alcançáveis diretamente a partir do GC Root. Implementação STW (Stop the World).
-
A marcação simultânea (marcação simultânea) é executada simultaneamente com os threads do usuário. A análise de acessibilidade de objetos no heap começa na raiz do GC e o gráfico do objeto em todo o heap é verificado recursivamente para encontrar os objetos a serem reciclados.
-
A marca final (Observação), STW, marca o lixo gerado no processo de marcação simultânea.
-
Triagem e reciclagem (Live Data Counting and Evacuation), formulando um plano de reciclagem, selecionando várias regiões para formar uma coleção, copiando os objetos sobreviventes das regiões no conjunto de reciclagem para as regiões vazias e, em seguida, limpando todo o espaço do antigo região. STW é obrigatório.
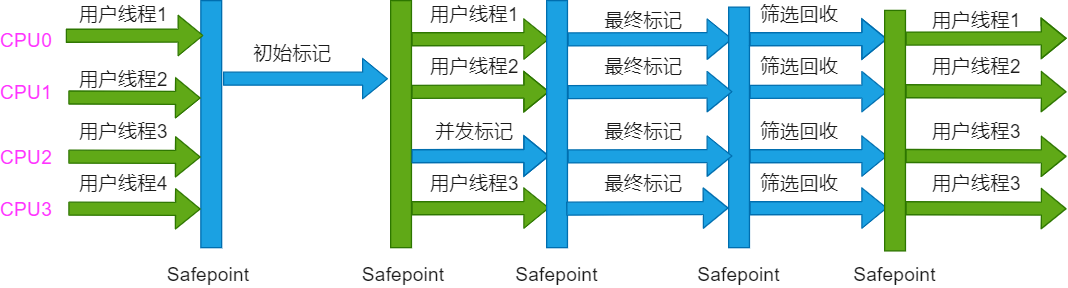
Comparado com o CMS, o G1 tem muitas vantagens: você pode especificar o tempo máximo de pausa, o layout da memória da região e determinar dinamicamente a arrecadação de acordo com a receita.
Da perspectiva da memória apenas, ao contrário do algoritmo "marcar e varrer" do CMS, G1 é um coletor baseado no algoritmo "marcar e classificar" como um todo, mas de um ponto parcial (entre duas regiões) de É implementado com base no algoritmo "marcar-cópia". Em qualquer caso, esses dois algoritmos significam que não haverá fragmentação do espaço de memória durante a operação G1, e a memória disponível regular pode ser fornecida após a coleta de lixo ser concluída.
2. Coletor de lixo de fronteira
2.1, coletor ZGC
No JDK 11, um ZGC experimental foi adicionado. Sua reciclagem leva em média menos de 2 milissegundos. É um coletor com baixa pausa e alta simultaneidade.
Semelhante ao ParNew e G1 no CMS, o ZGC também usa o algoritmo de marca-cópia, mas o ZGC fez melhorias significativas no algoritmo: o ZGC é quase simultâneo nas fases de marcação, transferência e realocação, que é a realização do tempo de pausa do ZGC menos de 10ms O motivo mais crítico para o objetivo.
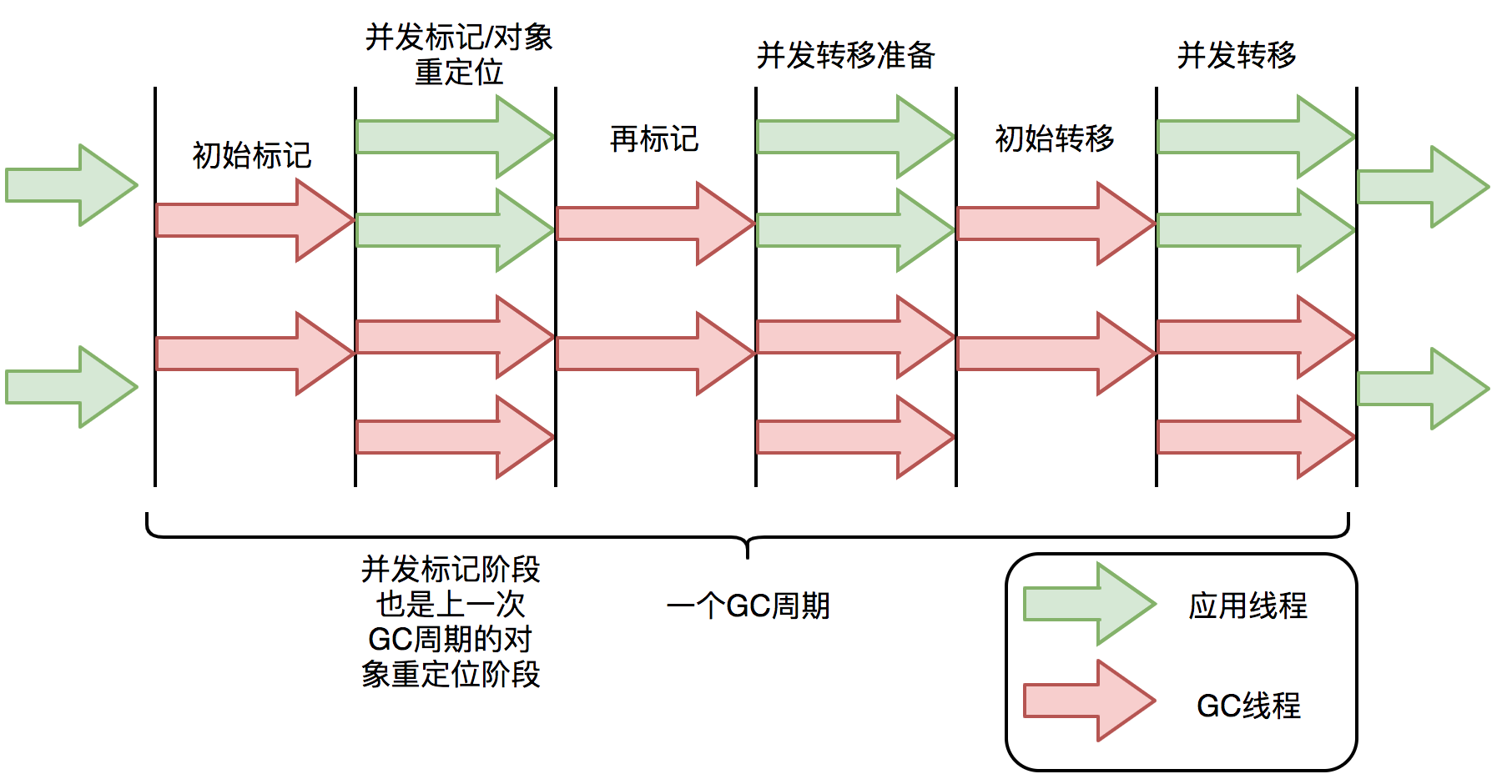
Embora o ZGC ainda esteja em estágio experimental no JDK 11, porque o algoritmo e as idéias são uma grande melhoria, acredita-se que as perspectivas futuras sejam muito amplas.
3. Seleção do coletor de lixo
3.1. Troca de seleção de coletor
Ainda existem muitas desvantagens na escolha do coletor de lixo - por exemplo, qual é a infraestrutura para executar o aplicativo? Quem é o editor que usa o JDK? e assim por diante……
Aqui está uma breve lista de cenários aplicáveis para alguns dos coletores mencionados acima:
- Serial : se o aplicativo tiver um pequeno espaço de memória (aproximadamente 100 MB) ou estiver sendo executado em um processador de thread único sem requisitos de tempo de pausa.
- Paralelo : se o desempenho de pico do aplicativo for priorizado e não houver requisito de tempo, ou um tempo de pausa de 1 segundo ou mais pode ser aceito.
- CMS / G1 : Se o tempo de resposta for maior que a prioridade de transferência ou a pausa da coleta de lixo deve ser mantida em cerca de 1 segundo.
- ZGC : se o tempo de resposta for de alta prioridade ou o espaço de heap for relativamente grande.
3.1, configurar o coletor de lixo
Os parâmetros para definir o coletor de lixo (combinados) são os seguintes:
| Cenozóico | Velhice | Parâmetros JVM |
|---|---|---|
| Incremental | Incremental | -Xincgc |
| Serial | Serial | -XX: + UseSerialGC |
| Eliminação paralela | Serial | -XX: + UseParallelGC -XX: -UseParallelOldGC |
| Novo Paralelo | Serial | N / D |
| Serial | Paralelo Antigo | N / D |
| Eliminação paralela | Paralelo Antigo | -XX: + UseParallelGC -XX: + UseParallelOldGC |
| Novo Paralelo | Paralelo Antigo | N / D |
| Serial | CMS | -XX: -UseParNewGC -XX: + UseConcMarkSweepGC |
| Eliminação paralela | CMS | N / D |
| Novo Paralelo | CMS | -XX: + UseParNewGC -XX: + UseConcMarkSweepGC |
| G1 | -XX: + UseG1GC |
referência:
[1]: "Deep Understanding of Java Virtual Machine: Advanced Features and Best Practices of JVM" por Zhou Zhipeng
[2]: "A arte do gerenciamento automático de memória no manual do algoritmo de coleta de lixo"
【3】 :Coleta de lixo em Java - O que é GC e como funciona na JVM
[4]: Algumas tecnologias-chave do Java Hotspot G1 GC
【5】 :Algoritmos GC: Implementações
[6]: Exploração e prática de uma nova geração de coletores de lixo ZGC