WizardKM: capacitando grandes modelos de linguagem para seguir instruções complexas
Introdução
O autor mostra que os dados de instrução na comunidade nlp atual são relativamente simples, e a maioria deles são tarefas de resumo e tradução, mas em cenários reais, as pessoas têm várias necessidades, o que limita a versatilidade do modelo.
O autor mencionou que, se a qualidade desses dados de qa rotulados por humanos for relativamente alta, liberará muito bem o desempenho do modelo, mas há alguns problemas na obtenção dos dados agora:
- Rotular esse tipo de dados é muito demorado e caro.
- Devido ao profissionalismo limitado do rotulador, é difícil obter dados de alta qualidade.
Com base nos problemas acima, o autor propõe um método que pode construir uma grande quantidade de dados de alta qualidade em um curto período de tempo.
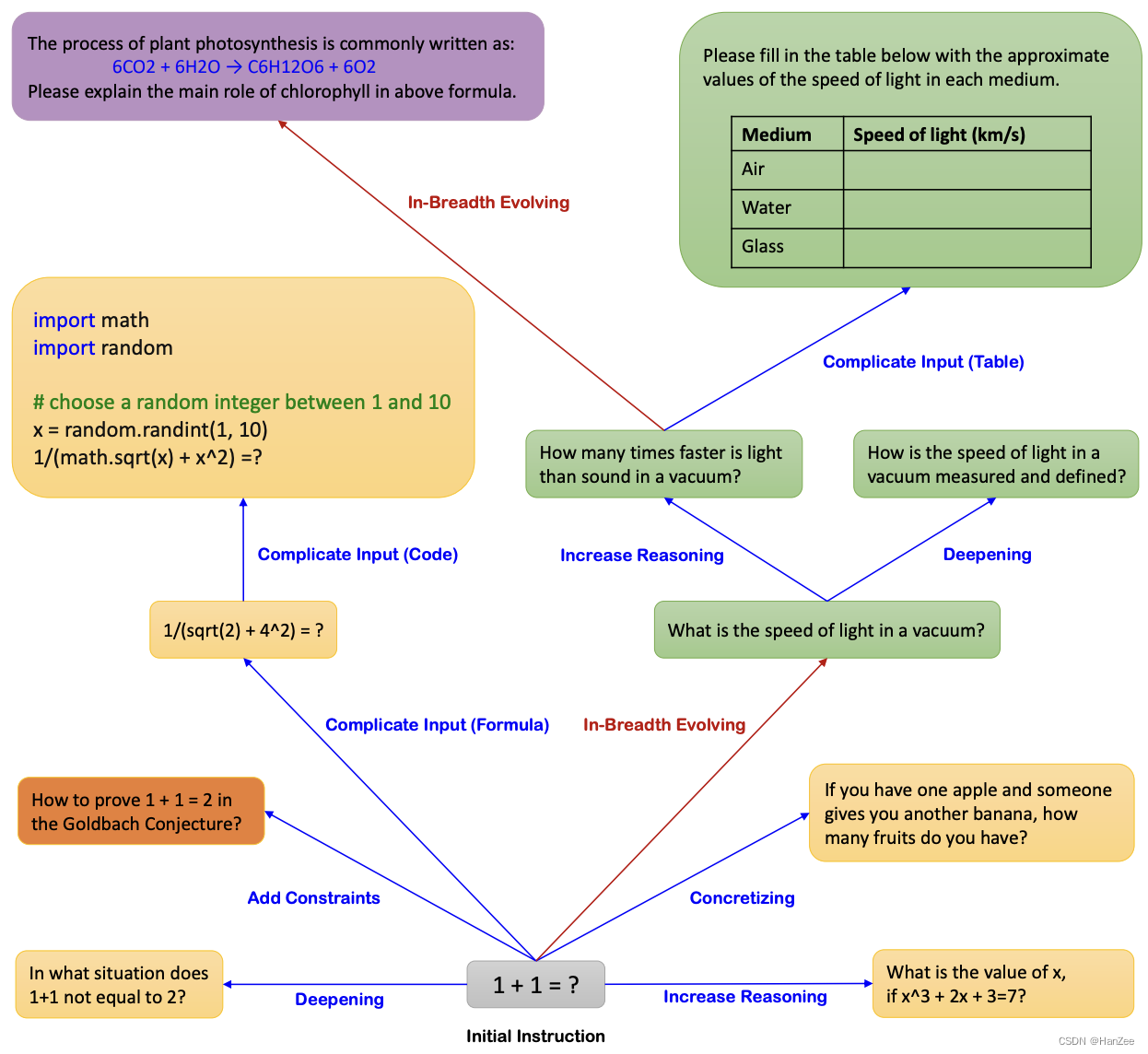
Conforme mostrado na figura acima, o autor chama esse método de Evol-Instruct.Partindo de um 1+1 igual a quê, o autor expande os dados de duas direções: a direção da profundidade e a direção da largura. Em seguida, envie a pergunta para o ChatGPT para obter o par de dados qa e, em seguida, filtre os dados.
Para verificar a eficácia desse método, os dados gerados pelo método acima foram ajustados pelo Llama7B, chamado WizardLM, e comparados com Alpaca e Vicunha. O autor gera 250 mil dados por meio do método Evol-Instrcut por meio dos dados de inicialização do Alpaca 175. Por uma questão de justiça, o autor amostra 70 mil dados nesses dados para comparação.
Descobertas de experimentos:
- Os dados gerados pelo Evol-instruct superam os do ShareGPT.
- Sob instruções de teste complexas, os anotadores preferem a saída do WizardLM à do ChatGPT.
referência
https://arxiv.org/pdf/2304.12244.pdf