论文解读:O canto da sereia no oceano de IA: uma pesquisa sobre alucinações em grandes modelos de linguagem

pontos centrais
- Este artigo revisa o problema dos grandes modelos de alucinações e o apresenta sob três aspectos: detecção, explicação e mitigação;
- Resuma os fenômenos de alucinação e os parâmetros de avaliação, analise os métodos existentes para aliviar as alucinações e discuta possíveis desenvolvimentos de pesquisas futuras.
- Compilação de literatura relevante: https://github.com/HillZhang1999/llm-hallucination-survey
1. Qual é a ilusão dos modelos grandes?
Três tipos de ilusões de grandes modelos:
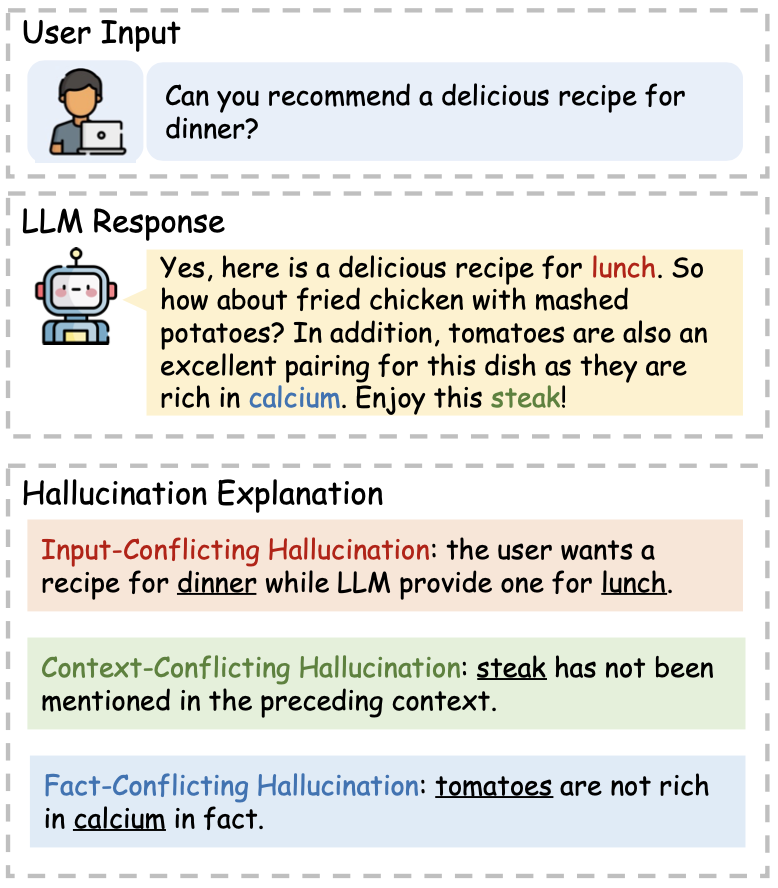
- Alucinação conflitante de entrada, onde LLMs geram conteúdo que se desvia da fonte de entrada fornecida pelos usuários;
- Alucinação conflitante de contexto, onde LLMs geram conteúdo que entra em conflito com informações geradas anteriormente;
- Alucinação conflitante com fatos, onde os LLMs geram conteúdo que não é fiel ao conhecimento mundial estabelecido.
Mais exemplos são mostrados na tabela a seguir:
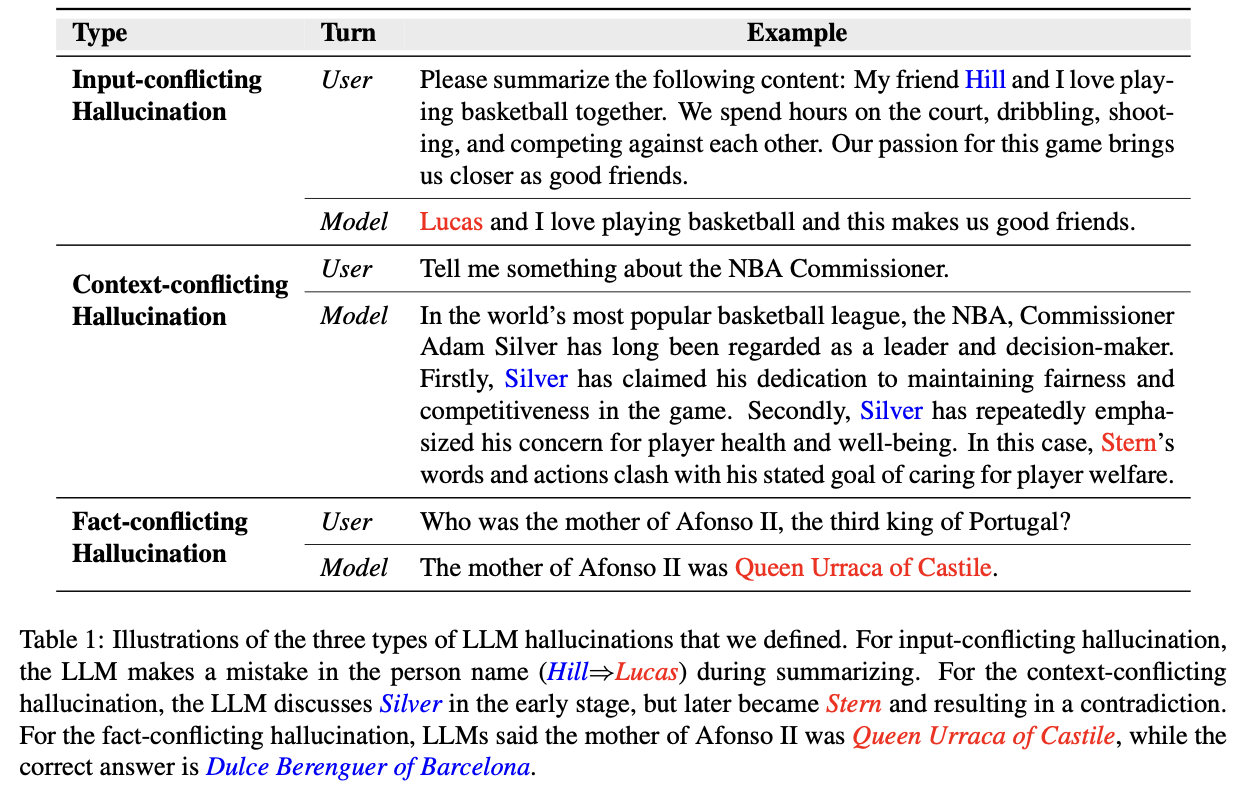
(1) A alucinação com conflito de entrada
geralmente apresenta duas situações:
- A entrada de entrada é uma instrução do usuário e os resultados fornecidos pelo modelo grande não estão relacionados à instrução ou há alguns conflitos;
- A entrada de entrada é um documento, como tarefas de resumo de texto e tradução automática, e os resultados fornecidos pelo modelo grande entram em conflito com o conteúdo do documento ;
Por exemplo, na tabela abaixo, Lucas e Hill têm conflitos.

(2) Alucinação conflitante com o contexto
significa que o conteúdo gerado pelo grande modelo é contraditório. Isso geralmente acontece porque:
- Modelos grandes apresentam falhas no rastreamento e na consistência do estado do contexto;
- Deficiências na memória de longo prazo;
Conforme mostra a tabela abaixo, continuo falando de Silver, mas quando falo sobre isso, menciono Stern.

(3) Alucinação conflitante com os fatos
O conteúdo gerado pelo grande modelo contém alguns erros factuais, ou seja, entra em conflito com o conhecimento factual e o bom senso.
Conforme mostrado na tabela abaixo: Ao fazer uma pergunta factual, os resultados fornecidos pelo modelo grande estão errados.

Comparado com outras tarefas específicas (como resumo e tradução), o grande problema de alucinação de modelo tem as seguintes três novas características:
- Os dados de treinamento para modelos grandes são extremamente grandes e é difícil eliminar informações fabricadas, desatualizadas e tendenciosas;
- Grandes modelos têm amplas capacidades: Grandes modelos de uso geral funcionam bem em ambientes de tarefas cruzadas, de idiomas diferentes e de domínios cruzados, o que representa desafios para avaliação abrangente e mitigação de alucinações;
- Erros são difíceis de detectar: modelos grandes podem gerar informações falsas que parecem muito verossímeis, dificultando a detecção de alucinações por modelos e até mesmo por humanos.
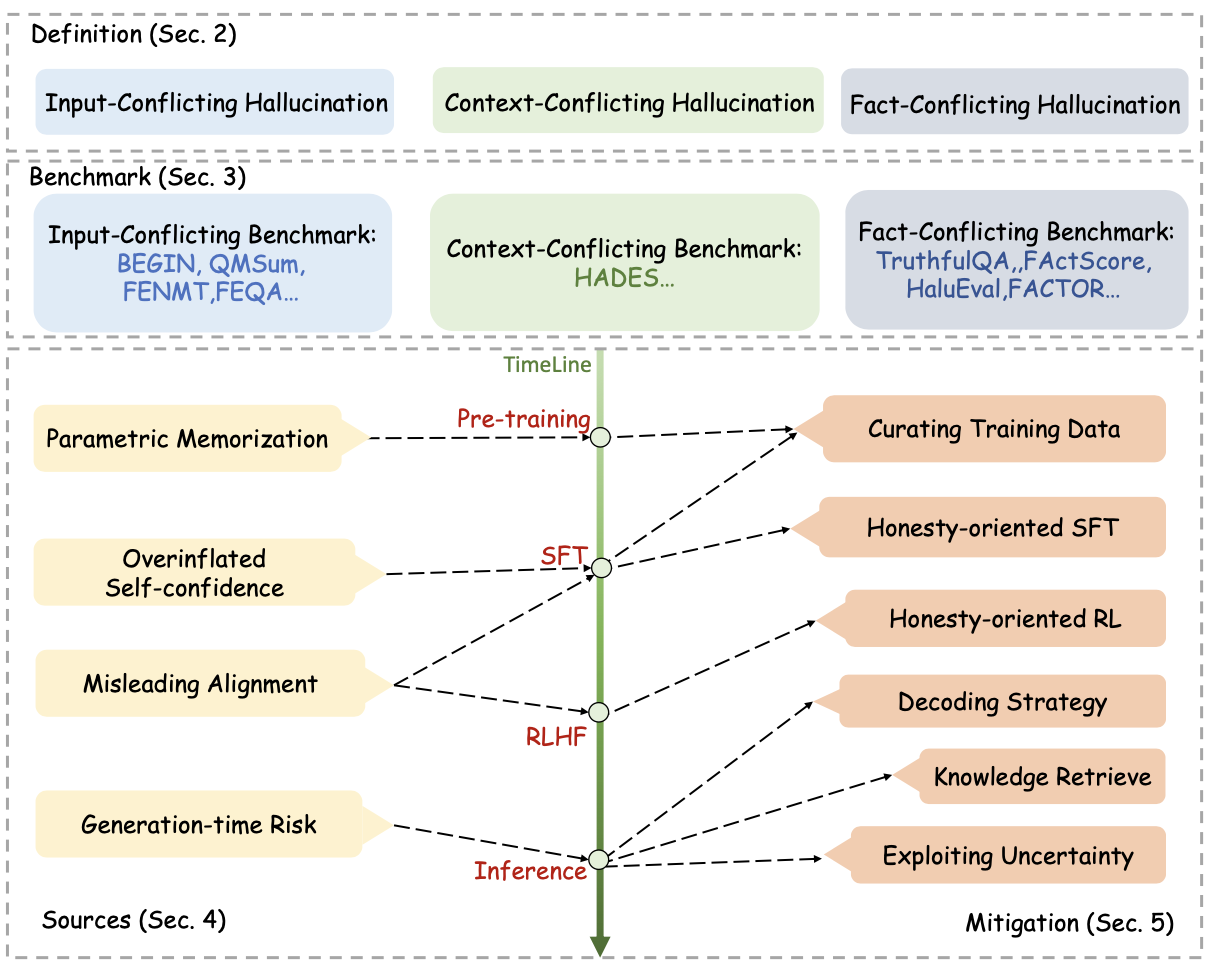
Uma visão geral da definição de alucinações de grandes modelos, parâmetros de avaliação e métodos para aliviar alucinações em cada estágio:
2. Métodos de avaliação de ilusão e indicadores de avaliação de grandes modelos
Dois modos principais de avaliação de alucinações:
(1) Geração: Avaliar diretamente se as declarações factuais no texto gerado pelo modelo grande estão corretas.
Geralmente é uma questão factual, deixar diretamente o grande modelo gerar os resultados e depois julgar se os resultados gerados estão corretos;

Alguns métodos clássicos de avaliação de geração:
- TruthfulQA: Várias perguntas são construídas manualmente, incluindo 437 perguntas difíceis (o GPT-3 não consegue responder com precisão) e 380 perguntas regulares. Durante a avaliação manual, a pontuação manual é realizada com base nas respostas do modelo grande a essas questões; durante a avaliação automática, um modelo GPT-3-6B é treinado nessas questões e, em seguida, esse modelo é usado para pontuar o conteúdo gerado pelo modelo grande . Blog de referência: TruthfulQA: Medindo como os modelos imitam falsidades humanas Interpretação de papel
- FActScore: Use biografias para determinar se o conteúdo gerado pelo modelo é consistente com os fatos.
Há também a Sondagem de Conhecimento, que elabora algumas questões do tipo cloze relacionadas a fatos (ou preenche os espaços em branco no final do texto) e permite que o modelo gere resultados. Pode ser o modo de múltipla escolha ou perguntas de preenchimento de lacunas.
(2) Discriminação: Permita que o grande modelo distinga se é consistente com os fatos.
Geralmente é uma questão de múltipla escolha que determina se o modelo grande pode acertar a questão de múltipla escolha.

Alguns métodos clássicos de discriminação:
- HalEval: Dada uma pergunta e a resposta correta, projete algumas instruções para permitir que o GPT-4 gere texto com alucinações, construa uma pergunta semelhante de múltipla escolha, exclua textos com alucinações de alta dificuldade por meio do modelo e marque o texto com alucinações por meio de intervalo de métodos de anotação manual. Ao avaliar a factualidade do modelo grande, o design pede para permitir que o modelo grande selecione a resposta correta entre todas as opções, ou deixe diretamente o modelo grande determinar se um determinado resultado gerado é consistente com os fatos. Blog de referência: HaluEval: um benchmark de avaliação de alucinações em grande escala para modelos de linguagem grande_China Normal University Data Institute·Wang Jianing's Blog-CSDN Blog
- FATOR: Semelhante a uma escolha múltipla, determina se a probabilidade dada pelo modelo grande para a opção correta é a maior;
- TruthfulQA: também oferece modo de múltipla escolha;
A tabela a seguir mostra vários métodos de referência de avaliação:
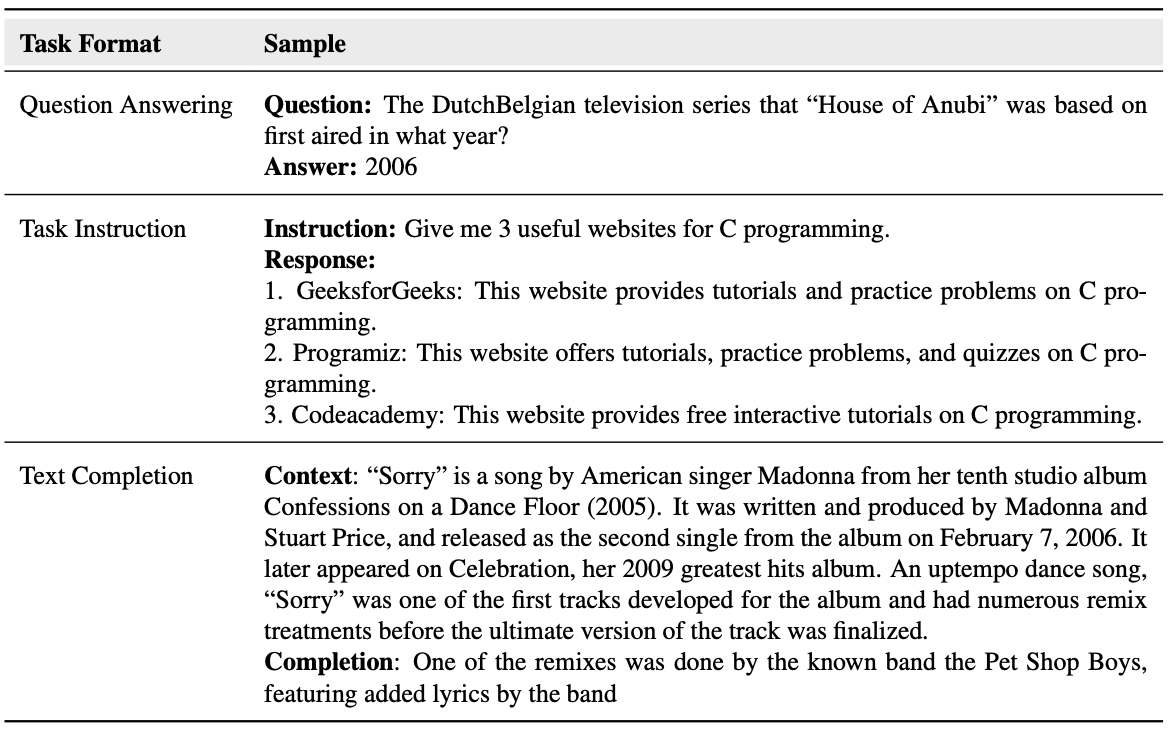
- Controle de qualidade: crie algumas perguntas, deixe o modelo grande gerá-las e, em seguida, pontue-as por meio de métodos de avaliação manuais ou automáticos. Representante típico: TruthfulQA;
- Instruções da tarefa: Projete algumas instruções para permitir que o modelo grande gere resultados; representante típico: HalEval
- Classe de conclusão: forneça algum prefixo, deixe o modelo grande ser gerado e determine se o conteúdo gerado está de acordo com os fatos e se entra em conflito com o prefixo. Representante típico: FATOR
Geralmente existem dois tipos de indicadores de avaliação:
(1) Avaliação manual,
que geralmente envolve o treinamento de anotadores. Ao receber uma pergunta e uma resposta do candidato, o anotador é solicitado a pontuar a resposta do candidato com base em requisitos específicos. Representantes típicos: TruthfulQA, FactScore.
No entanto, os métodos de avaliação manual são tendenciosos e dispendiosos.
(2) A avaliação automática baseada em modelos
geralmente envolve o treinamento de um modelo de pontuação baseado em um benchmark de avaliação construído.
- TruthfulQA: em centenas de benchmarks de anotação de projeto, GPT-3-6.7B é usado para treinar um modelo de duas classificações GPT-Judge. A precisão desse modelo de duas classificações pode atingir 90 a 96% de precisão. Portanto, quando uma nova pergunta e as respostas dos candidatos podem receber pontuações factuais com mais precisão.
- AlignScore: Uma função Align é proposta para determinar se o conteúdo gerado pelo modelo grande é factualmente consistente com o conteúdo de entrada. Ele treina um modelo de duas classificações a partir de um grande número de NLI, QA, paráfrase e outras tarefas para determinar se existe uma relação de implicação entre dois textos;
- FactScore: Quando é dada uma pergunta e a resposta gerada por um modelo grande. Primeiro, use um modelo T5 geral como recuperador para recuperar conhecimento relevante com base na pergunta. Em segundo lugar, use um modelo LLaMA-65B para determinar se as respostas geradas pelo modelo grande são factuais com base no conhecimento recuperado. Finalmente, F1 e taxa de erro são usados para julgar a confiabilidade deste método de avaliação, e a análise de correlação com a avaliação humana é realizada.
- Autocontraditório: deixe o modelo grande gerar uma pergunta duas vezes e use um ChatGPT para determinar se os dois conteúdos gerados estão em conflito.
(3) Avaliação automática baseada em regras
Para o método de avaliação de discriminação, a precisão pode ser usada diretamente como índice de avaliação. Se, para o método de geração, a taxa de sobreposição de entidades no conteúdo gerado e no conteúdo de entrada puder ser avaliada, isso pode ser feito usando o indicador Rouge-L ou F1.
3. Fatores que causam a ilusão de modelos grandes
(1) Modelos grandes carecem de conhecimento relacionado ao domínio ou conhecimento incorreto é injetado durante o treinamento
- Existem diferenças de distribuição entre os dados de treinamento e as questões do teste alvo, e o conteúdo gerado pelo modelo é mais tendencioso em relação aos dados de treinamento, mas é o conteúdo errado;
- Os dados de treinamento podem ser tendenciosos, desatualizados ou cheios de mentiras
(2) Grandes modelos superestimam suas próprias capacidades de geração.
Grandes modelos geralmente dão um alto grau de confiança no conteúdo que geram, mas na verdade é conteúdo errado.
Grandes modelos às vezes não têm a capacidade de rejeitar o conhecimento e os seus limites de conhecimento são relativamente vagos.
(3) Estratégias de alinhamento problemáticas podem degradar o modelo
- O alinhamento de modelos grandes requer certos conhecimentos necessários. Se você não tiver esse conhecimento, o alinhamento pode fazer com que o modelo gere problemas de alucinação;
- Grandes modelos podem sofrer interferências e ser enganados pelos utilizadores, gerando assim conteúdos alucinatórios;
(4) Existem deficiências na estratégia de geração de grandes modelos
- Ilusão de bola de neve: a geração de modelos grandes é um modo autorregressivo, e o modelo grande pode não ser capaz de corrigir informações errôneas geradas anteriormente, levando a erros que se somam a erros;
- Existem diferenças entre as fases de treinamento do modelo e de inferência;
- Problema de amostragem Top-p, quanto maior o valor de p, mais criativo é o modelo e mais fácil é produzir alucinações;
4. Métodos para aliviar a ilusão de modelos grandes
De acordo com os quatro ciclos de vida do treinamento de grandes modelos, são introduzidos métodos para aliviar as alucinações, respectivamente.
4.1 Fase pré-treinamento
Durante o processo de treinamento do modelo, se houver conhecimento errado, causará alucinações no modelo grande.
Portanto, o método de mitigação é processar os dados de pré-treinamento e filtrar dados potencialmente errôneos. (a curadoria dos corpora pré-treinamento)
Penso que outro elemento-chave é a necessidade de injetar conhecimento factual na fase de pré-formação.
4.2 Estágio SFT
(1) curadoria de dados SFT
O método para aliviar alucinações no estágio SFT também consiste em processar os dados e filtrar dados errôneos. Experimentos no TruthfulQA mostram que o treinamento em dados ajustados com instruções de curadoria é significativamente melhor do que a operação original.
(2) Clonagem comportamental
Outra explicação do SFT é a clonagem comportamental, ou seja, o SFT apenas ensina ao modelo como responder a uma pergunta (semelhante à ação na aprendizagem por reforço), mas não sabe responder com mais precisão (equivalente a não ter um estratégia para orientar).
O estágio SFT permite essencialmente que o modelo grande use o conhecimento dentro dos parâmetros para interagir com os humanos. No entanto, o conhecimento contido nos dados de treinamento SFT pode não ser visto no estágio de pré-treinamento do modelo grande, ensinando indiretamente o modelo grande a fabricar, e o modelo grande pode procurar informações semelhantes ao gerar. Isto é, o grande modelo precisa ter a capacidade de reconhecer os limites do autoconhecimento (a capacidade de rejeitar o reconhecimento).
forçando os LLMs a responder perguntas que ultrapassam seus limites de conhecimento.
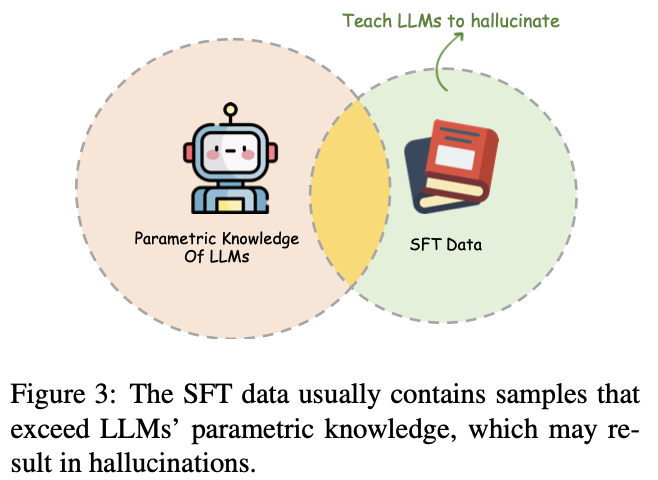
A solução é o SFT orientado para a honestidade, ou seja, adicionar alguns dados do tipo "Desculpe, não sei" aos dados do SFT.
Acho que os dados de rejeição precisam ser divididos em duas categorias:
- Rejeição da própria pergunta: Incorporar algumas perguntas que não têm respostas, como "Qual é o diâmetro do universo?"
- Rejeição do modelo: Existe uma resposta correta para a pergunta em si, mas se o próprio modelo não aprendeu esse conhecimento, não pode inventá-lo. Por exemplo, se você pedir a um grande modelo médico que responda a uma pergunta literária, ele não poderá inventá-la aleatoriamente.
Além disso, é necessário evitar a rejeição excessiva do modelo.
4.3 Estágio RLHF
O objetivo do estágio de alinhamento é alinhar o modelo grande com valores humanos em aspectos como útil, honesto e inofensivo. Um modelo de recompensa geralmente é treinado para avaliar as pontuações do texto nesses aspectos, e o algoritmo PPO é usado para otimizar continuamente o modelo SFT.
Uma ideia simples para aliviar as alucinações no estágio RLHF é projetar separadamente uma pontuação de recompensa para alucinações e otimizá-la diretamente no estágio RLHF, conforme mostrado abaixo:
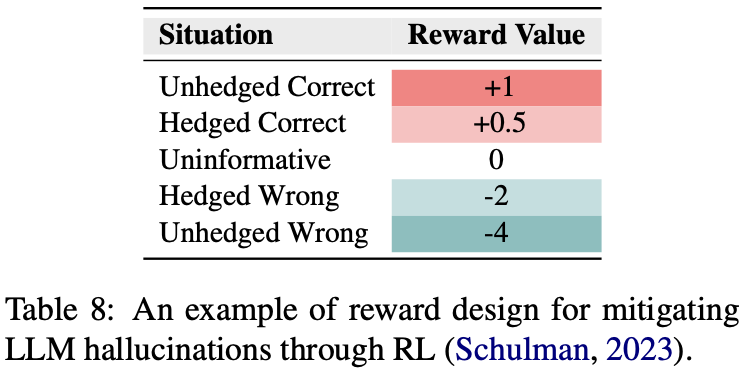
Isso é semelhante a realizar a rejeição de reconhecimento no estágio SFT.
No entanto, existem alguns desafios com RLHF:
- Pode tornar o modelo excessivamente conservador
- Evitação excessiva de responder a algumas questões que o próprio grande modelo conhece, ou geração repetida;
4.4 Estágio de inferência do modelo
(1) Estratégia de decodificação
- O método de amostragem Top-p (amostragem de kernel) é um método de amostragem ganancioso, o que fará com que os resultados gerados pelo modelo sejam mais criativos, mas também reduzirá a factualidade. Uma abordagem é projetar amostragem dinâmica top-p. O método representativo é "Modelos de linguagem aprimorados com factualidade para geração de texto aberto".
probabilidade de núcleo dinâmico ppp :
pt = max { ω , p × λ t − 1 } p_t=\max\{\omega, p\times\lambda^{t-1}\}pt=máximo { ah ,p×eut - 1 }
- λ \lambdaλ -decay: com o número de tokens geradosttÀ medida que t aumenta, ppdecai gradualmenteO valor de p ;
- pp.p -reset: Depois que uma frase é gerada,ppO valor de p será devido atttorna-se muito pequeno à medida que t aumenta, ao gerar novas sentenças, espera-se queppp pode ser restaurado ao seu valor original;
- ω \omega ω -bound: Para evitarppp é muito pequeno após o decaimento, defina um limite inferior;
- Tecnologia de intervenção de raciocínio: "Intervenção no tempo de inferência: extraindo respostas verdadeiras de um modo de linguagem"
Quando o modelo prevê antecipadamente a resposta correta, cada token corresponde aos logits de cada cabeça em cada camada do Transformer.
1) Instale um classificador binário no topo de cada cabeça de atenção do LLM para identificar um conjunto de cabeças que exibem precisão de detecção linear superior ao responder a questões factuais
2) Durante o processo de raciocínio, ao longo desses fatos, o modelo de movimento direcional é ativado.
- Decodificador sensível ao contexto: Integração de dois modos de decodificador em "Confiando em suas evidências: menos alucinações com decodificação sensível ao contexto" :
- p ( y ∣ c , x ) p(y|c, x)p ( y ∣ c ,x ) representa o contexto ccpara uma determinada recuperaçãoc e consultaxxNas condições de x , a probabilidade de gerar cada resultado;
- p ( y ∣ x ) p(y|x)p ( y | x ) significa que apenas a consulta xxé fornecidaNas condições de x , a probabilidade de gerar cada resultado;
- Se as duas probabilidades forem muito diferentes para a previsão de uma determinada resposta, significa que a resposta vem mais do contexto do que do conhecimento dos parâmetros do modelo, e é mais provável que a resposta esteja correta.
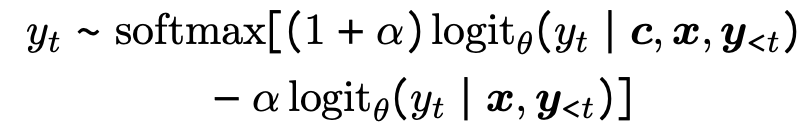
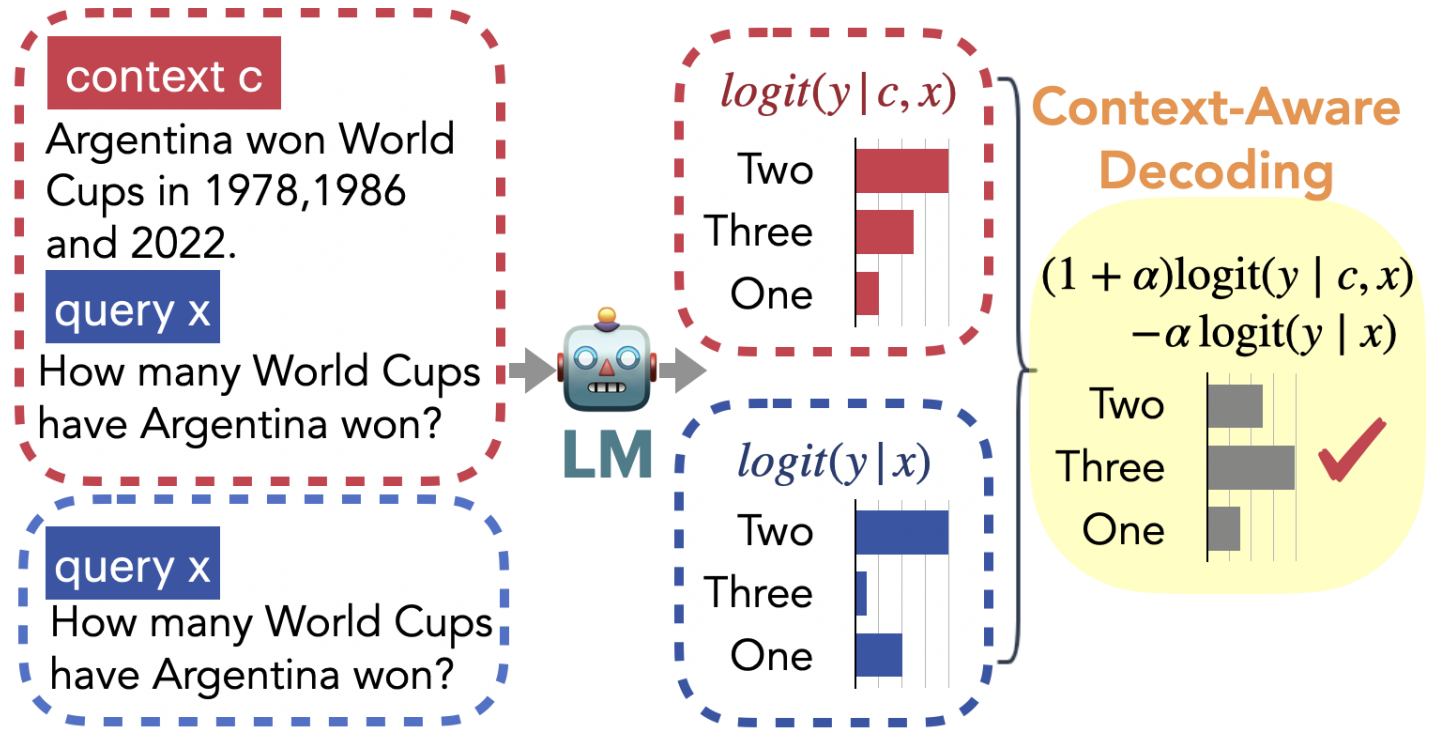
(2) Recuperação de conhecimento externo
A recuperação de conhecimento externo para alcançar o aprimoramento da recuperação é um método direto para aliviar alucinações.
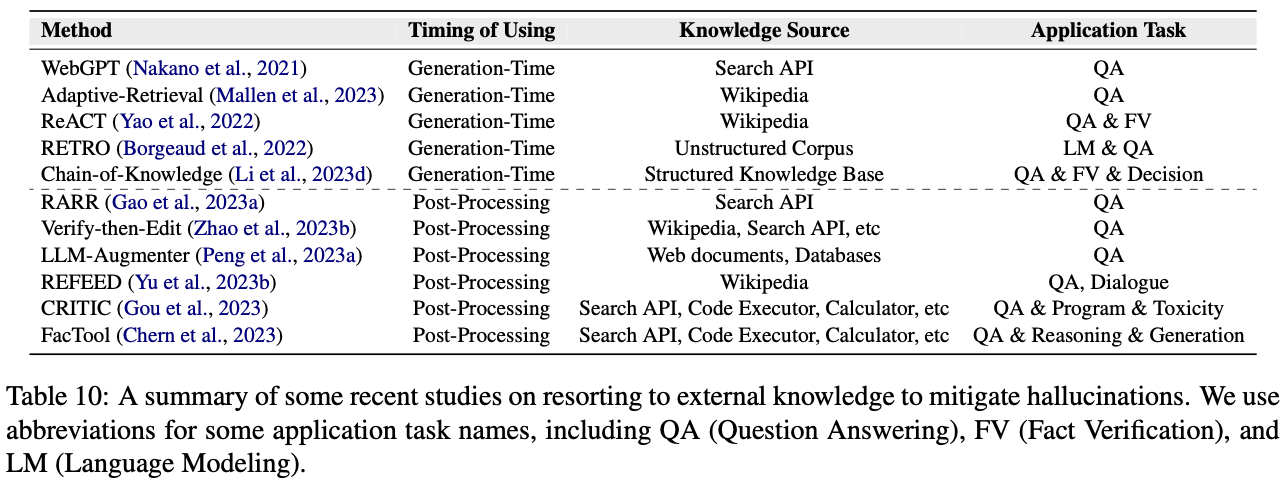
Existem dois tipos principais de conhecimento externo:
- Base de conhecimento externa: incluindo base de conhecimento na Internet, Wikipedia, gráfico de conhecimento, etc. Geralmente, são usados BM25, Dense Retrieve, mecanismos de busca, etc.
- Ferramentas externas: FacTool desenvolve algumas APIs externas para resolver alucinações para diferentes tarefas específicas, como a API do Google Scholar para detectar precisão em revisões acadêmicas; CRITIC permite que o modelo interaja com diferentes ferramentas e realize detecção de erros em resultados incorretos.
Duas ideias para usar o conhecimento externo para aliviar alucinações são as seguintes:
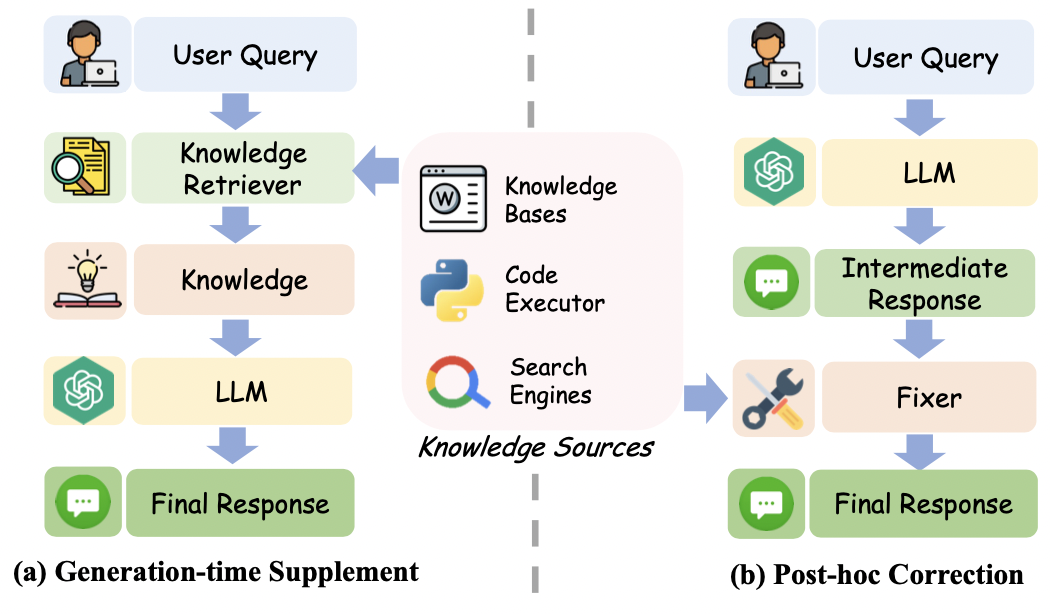
- Combine o conhecimento recuperado diretamente com a consulta.
- O conhecimento recuperado é utilizado para verificar e corrigir os resultados gerados.Neste momento, o LLM pode utilizar o conhecimento externo como fixador.
- RARR: Deixe o modelo grande encontrar as áreas que precisam ser corrigidas no conteúdo de vários aspectos e, em seguida, deixe o LLM corrigir os erros com base no conhecimento recuperado;
- Verificar e editar: verifica os resultados intermediários do raciocínio do modelo e recupera conhecimento externo para corrigir processos de raciocínio errados.
- LLM-Augmenter: Primeiro deixe o LLM resumir o conhecimento recuperado e, em seguida, deixe o fixador corrigir o texto alucinado com base no resumo.
O aprimoramento da consulta de pesquisa tem os seguintes desafios:
- O conhecimento recuperado geralmente vem da Internet, e ainda haverá informações errôneas e falsificadas.Portanto, como verificar a confiabilidade do conhecimento recuperado também é fundamental;
- A precisão e a eficiência do tempo do recuperador e do fixador também são partes muito importantes. Garantir que o desempenho da recuperação de conhecimento e correção de erros seja alto;
- O conhecimento recuperado pode entrar em conflito com o conhecimento dos parâmetros
(3) Incerteza
A incerteza dos resultados da previsão do modelo pode avaliar a confiança do modelo nos resultados gerados. Se o nível de incerteza dos resultados gerados pelo modelo puder ser obtido com precisão, esta parte do conteúdo poderá ser efetivamente filtrada ou reescrita.
Para avaliar a incerteza dos resultados da geração do modelo, o trabalho principal é "Os llms podem expressar sua incerteza? Uma avaliação empírica da elicitação de confiança nos llms".Existem três métodos principais:
- Avaliado com base em logits ou entropia de informação. Trabalho representativo: "Sobre calibração de redes neurais modernas."
- Método representativo: “Um ponto no tempo economiza nove: Detectando e mitigando alucinações de filmes validando a geração de baixa confiança” usa logits para encontrar a parte com alucinações e, em seguida, usa conhecimento externo e LLM adicional como um fixador para corrigi-lo;
requer acesso aos logits do modelo e normalmente mede a incerteza calculando a probabilidade ou entropia no nível do token.
- Baseado em verbalização: projete instruções para permitir que o modelo transmita diretamente sua confiança na resposta à pergunta. Por exemplo, adicione o comando: Responda e forneça sua pontuação de confiança (de 0 a 100). Pode ser combinado com CoT para melhorar o efeito;
- Método representativo:《Os modelos de linguagem sabem quando estão alucinando referências?》
- Consistência: deixe o modelo gerar a mesma pergunta várias vezes e julgue com base na consistência das respostas. Se os múltiplos resultados gerados pelo modelo forem muito inconsistentes, é uma alucinação sobre o problema;
- Método representativo: SelfCheckGPT
4.5 Outros métodos
(1) Interação multiagente
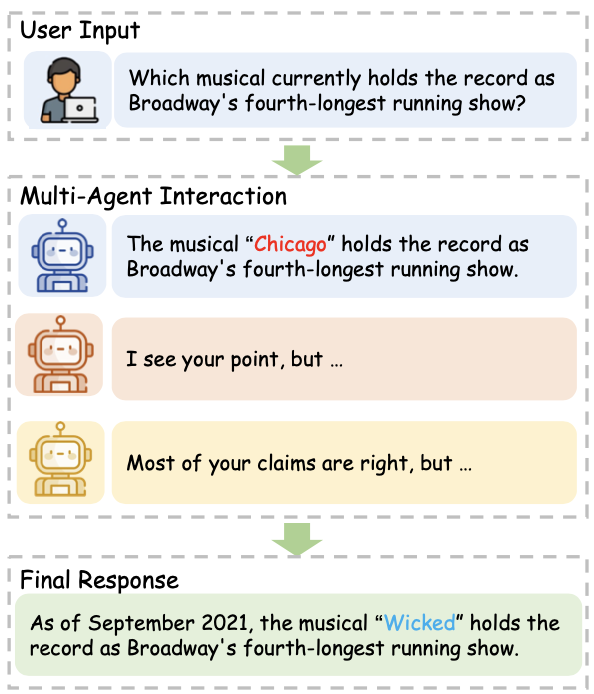
- Se apenas um grande modelo gera resultados, é mais fácil criar alucinações. Mas este problema pode ser aliviado se for respondido na forma de múltiplos debates de grandes modelos: “Melhorar a factualidade e o raciocínio em modelos de linguagem através do debate multiagente”
- Projetar dois LLMs, um responsável pela geração de conteúdo e outro responsável pela verificação: "Lm vs lm: Detectando erros factuais por meio de exame cruzado"
- Um LLM desempenha várias funções ao mesmo tempo: "Um agente de resolução de tarefas por meio da autocolaboração multipessoal."
(2) Engenharia de alertas:
Diferentes avisos também podem causar alucinações. CoT pode ser usado para melhorar a capacidade de raciocínio e evitar alucinações. Por outro lado, ao projetar o prompt do sistema, diga ao modelo para não inventar coisas. Por exemplo, no LLaMA2-Chat, defina "Se você não sabe a resposta a uma pergunta, por favor, não compartilhe informações falsas" (3) Human-
in-the-loop
representa o trabalho: "Mitigando a alucinação do modelo de linguagem com alinhamento interativo entre pergunta e conhecimento"
(4) Otimizando a estrutura do modelo
Estruturas de decodificador mais ricas:
- decodificador multi-ramificação:《Controlando alucinações em nível de palavra na geração de dados para texto》
- decodificador com reconhecimento de incerteza: 《Sobre alucinação e incerteza preditiva na geração de linguagem condicional》
- Estrutura do decodificador bidirecional: "Batgpt: um locutor autoregessivo bidirecional de um transformador generativo pré-treinado"
5. Outros aspectos
(1) Um método de avaliação mais adequado.
O método de avaliação atual ainda apresenta algumas deficiências, que se refletem em:
- Existem diferenças entre métodos de avaliação automatizados e avaliação humana;
- Resta estudar se os dois tipos de métodos de avaliação, discriminação e geração, podem representar com precisão a ilusão do modelo, e se podem ser universais em diferentes tarefas;
(2) Alucinação multilíngue
: A mesma pergunta pode ser respondida com precisão quando feita em inglês, mas ocorrerão erros quando feita em chinês, indicando que a alucinação do modelo se comportará de maneira diferente em diferentes idiomas. Isso geralmente ocorre em linguagens com poucos recursos.

(3) Alucinação multimodal
Alguns modelos multimodais substituirão o codificador visual pelo LLM. Mas o problema das alucinações também pode surgir neste momento.
Alguns parâmetros de avaliação de alucinações em cenas multimodais incluem:
- Avaliação de instrução visual assistida por GPT4 (GAVIE)
- M-HalDetect
(4) Edição de modelo
Existem dois tipos de edição de modelo, que eliminam diretamente a ilusão do modelo nos parâmetros ou estrutura do modelo:
- Usando uma sub-rede auxiliar: "Edição de modelo baseado em memória em escala", "Um erro vale um neurônio"
- Altere diretamente os parâmetros do modelo: "Localizando e editando associações factuais no gpt"
(5) Ataque e defesa:
Como evitar que alguns prompts sejam armadilhas maliciosas e bem projetadas e evitar que o modelo cuspa alucinações ou informações erradas.
- 《Jailbroken: Como o treinamento de segurança do llm falha?》
- 《Promptbench: Para avaliar a robustez de grandes modelos de linguagem em prompts adversários》
Vários estudos mostram que os LLMs podem ser manipulados usando técnicas como prompts de jailbreak meticulosamente elaborados para obter respostas desejadas arbitrárias
(6) Em outros
cenários de LLM como agente, como aliviar alucinações com grandes modelos é um novo desafio.