FCN: um modelo de segmentação semântica baseado em aprendizado profundo
Definição de segmentação semântica: classificação refinada de pixels.
Usando o aprendizado profundo para resolver a segmentação semântica, os principais problemas enfrentados são:
-
Os primeiros modelos profundos foram usados para classificação, gerando vetores unidimensionais, que não podiam ser divididos
-
O modelo de profundidade não é bom o suficiente
motivação
- Como disponibilizar a rede para segmentação?
Apenas deixe a rede gerar recursos bidimensionais
Como fazer com que as primeiras redes neurais produzam imagens bidimensionais?
Remova a camada totalmente conectada.
- Como tornar a saída do modelo suficientemente boa?
O motivo da imprecisão?
Após o agrupamento de convoluções multicamadas, a resolução do mapa de recursos é baixa.
Por exemplo, uma saída de imagem 224*224 é um mapa de recursos 7*7, que obviamente não pode ser muito bom
Um método viável é aumentar o tamanho de 7*7
O método específico é a deconvolução.
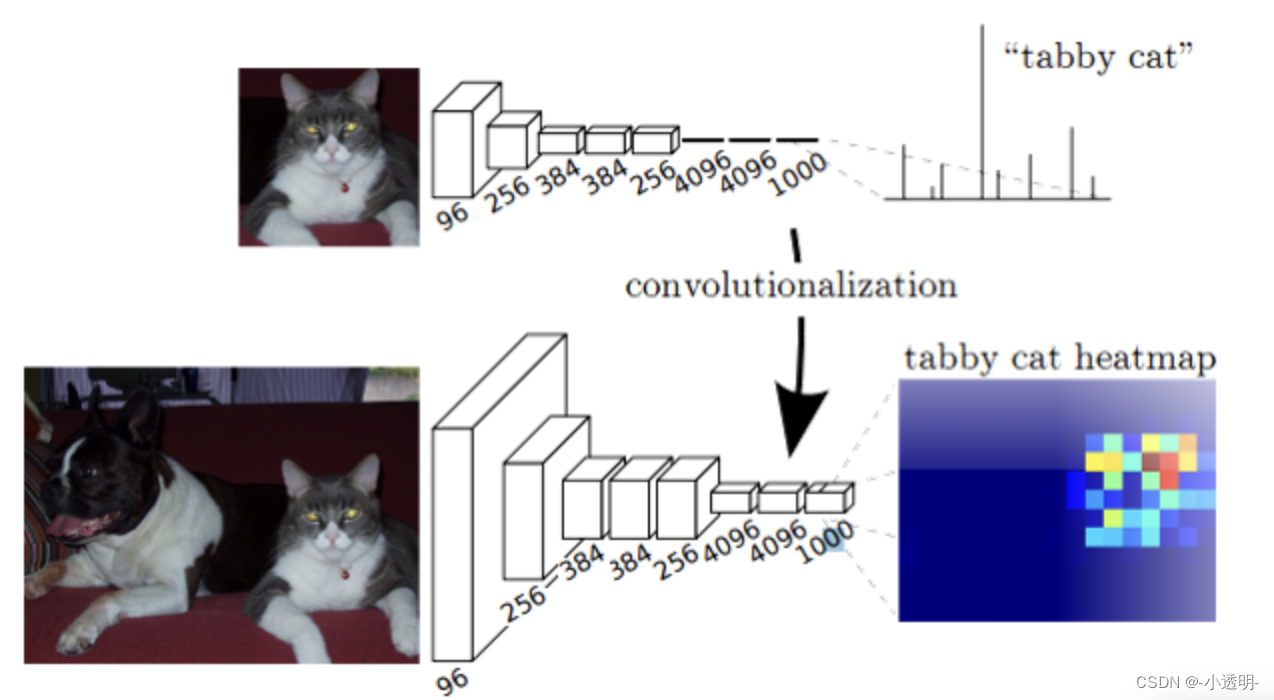
estrutura do modelo

Como a resolução de 1/32 é muito baixa, a segmentação direta é muito grosseira, então ela é expandida primeiro e depois juntada com 1/16... (A ideia por trás de yolov3 é inspirada nisso)
A frente é uma rede CNN regular, que transforma uma imagem em um mapa de características. Em seguida, a deconvolução é realizada para obter o tamanho da imagem original.
| camada | tamanho de saída |
|---|---|
| imagem de entrada | 224×224 |
| Convolução 1 | 224×224 |
| Agrupamento 1 | 112×112 |
| Convolução 2 | 112×112 |
| Agrupamento 2 | 56×56 |
| Convolução 3 | 56×56 |
| Agrupamento 3 | 28×28 |
| convolução 4 | 28×28 |
| agrupamento 4 | 14×14 |
| Convolução 5 | 14×14 |
| Deconvolução 6 | 224×224 |
| saída | 224×224 |
detalhes de implementação
deconvolução

Exibição do resultado

Anti-pooling e deconvolução: apenas o tamanho é restaurado e as informações perdidas durante o processo de convolução (ou pooling) não são restauradas
Downsampling (codificação) Downsampling (decodificação)
UNet


Segmentação semântica da série DeepLab
Problemas com FCN
-
A existência da camada de pooling leva à perda de informações detalhadas
-
A invariância espacial ( sem impacto nos resultados da classificação à esquerda e à direita ) não é amigável para tarefas de segmentação
Dificuldade 1: Perda de informações detalhadas
Essencialmente, a segmentação semântica é uma tarefa que inclui recursos semânticos de baixa dimensão.
É sensível a informações como bordas, texturas e cores.
A existência da camada de pooling leva à perda desses detalhes, que não podem ser recuperados mesmo com upsampling.
Como discutido anteriormente, o significado do pooling é concentrar informações, expandindo assim o campo receptivo e aumentando a dimensão da informação.
Então, como podemos maximizar o campo receptivo sem perder informações detalhadas?
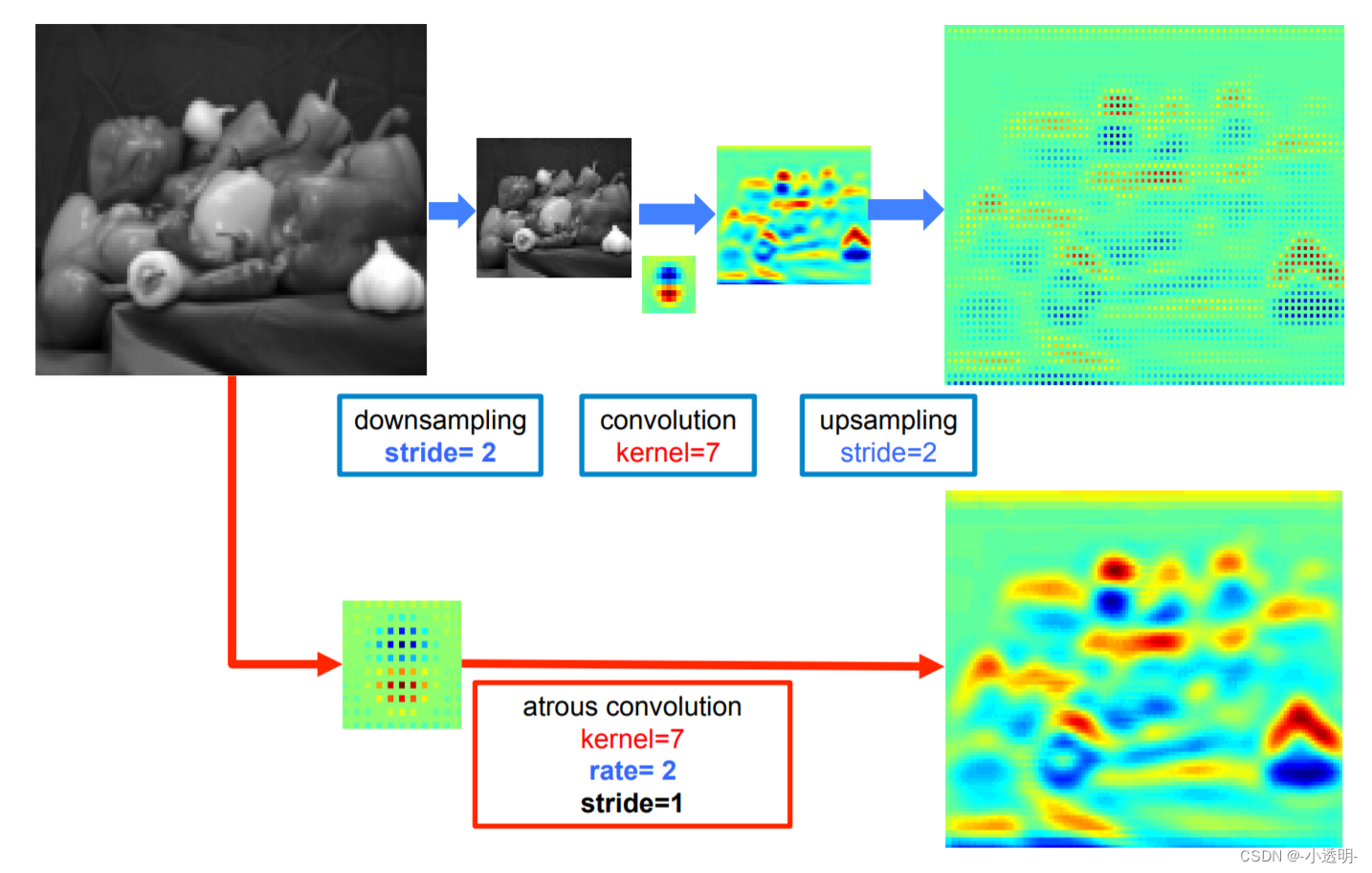
Solução 1: Convolução do furo
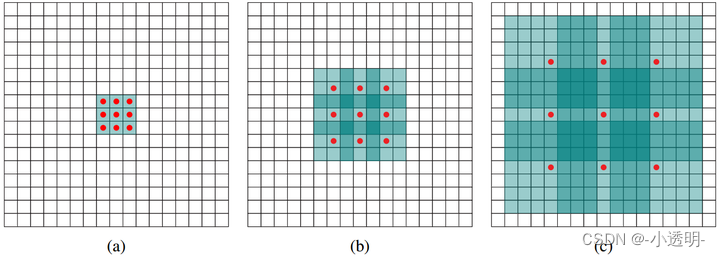
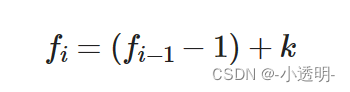
A convolução de buracos pode expandir o campo receptivo tanto quanto possível sem agrupamento, melhorando assim rapidamente a concentração de informações.
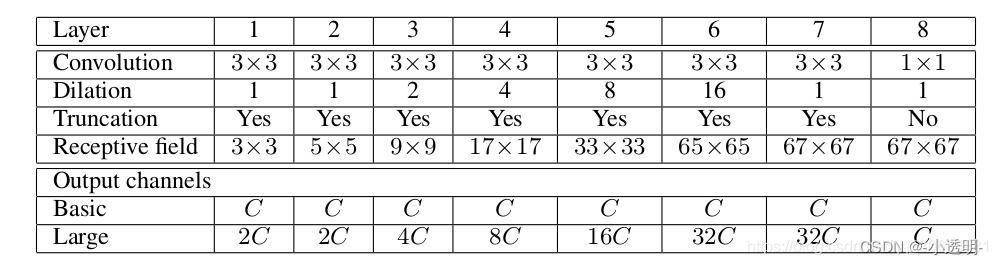
Exercício: Calcular o campo receptivo final do modelo acima
Vantagens da convolução do furo: expande o campo receptivo e preserva informações detalhadas
Desvantagens da convolução dilatada: Objetos pequenos não são suficientemente robustos
Dificuldade 2: Invariância espacial
Uma vantagem significativa das CNNs é a invariância espacial.
O mesmo objeto deve produzir o mesmo valor em diferentes posições, formas e ângulos da imagem.
Por exemplo, uma imagem de um gato sempre produzirá um vetor quente da categoria gato.
Mas para a segmentação, essa invariância espacial trará inconvenientes.
Solução correspondente: CRF
O CRF totalmente conectado é introduzido e a imagem original é usada como entrada, combinada com o mapa de recursos para otimização.
campo aleatório condicional
Pré-conhecimento
O CRF é um modelo discriminativo que usa o modelo de gráfico de probabilidade condicional para modelar a probabilidade condicional ��(�|�) para concluir a tarefa de discriminação.
Em outras palavras, CRF é uma estimativa de uma probabilidade condicional.

CRF para segmentação semântica
motivação
O objetivo principal da tarefa de segmentação de imagens é atribuir um rótulo a cada pixel.
No entanto, devido ao método de processamento de convolução de agrupamento, as bordas da área de destino ficam desfocadas.
Então o CRF é necessário para fornecer novas informações para a aresta, de modo a obter uma aresta melhor.

Criar um campo aleatório
Dada uma imagem:
* 定义 $X=\{X_1, X_2, ..., X_N\}$, 其中$X_i$为第i个像素的预测标签;
* 定义 $L=\{L_1, L_2, ..., L_N\}$, 其中$L_i$为第i个像素的真实标签;
* 定义 $I=\{I_1, I_2, ..., I_N\}$, 其中$I_i$为第i个像素数据。


explicação intuitiva

Cada pixel (RGB é um vetor) pode ser usado como uma observação e precisamos inferir um rótulo para cada pixel com base na observação.
Portanto, os atuais modelos de segmentação semântica mainstream são basicamente os seguintes frameworks
Quantas vezes o ciclo CRF? Quantas categorias, quantas vezes repetir

deficiência
Porém, existe um problema relativamente grande neste método, ou seja, a velocidade é lenta
O motivo da baixa velocidade vem principalmente da CRF.
A complexidade da solução do CRF é maior, por isso leva mais tempo para otimizar o resultado.
solução
Resolva aproximadamente o CRF por meio de treinamento
Ou seja, o processo CRF é decomposto em uma série de processos de convolução e resolvido por RNN.
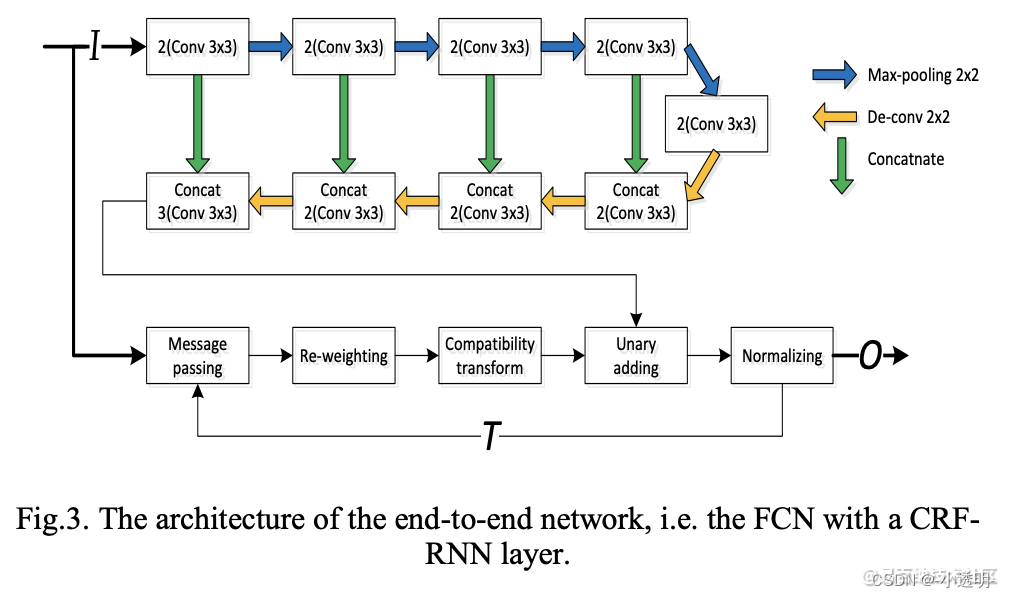

passo 2
Em segundo lugar, na etapa de passagem de mensagem, m filtros Gaussianos são usados para filtrar em Q.
É equivalente a desfocar o mapa de recursos, que é equivalente à operação de convolução.
obter o seguinte resultado

etapa 3
A terceira etapa: transformação de compatibilidade


Passo 4
Depois disso, os potenciais unários são realizados, ou seja, (subtração)
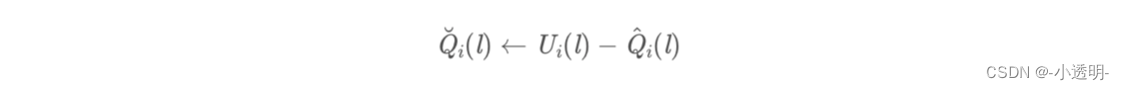
Isso é comparar o último resultado com o incremento deste resultado.
Finalmente, a normalização é realizada usando softmax.
CRF como RNN
Trate o acima como um processo RNN e execute o processamento CRF em cada tipo de mapa de recursos para obter melhores resultados.
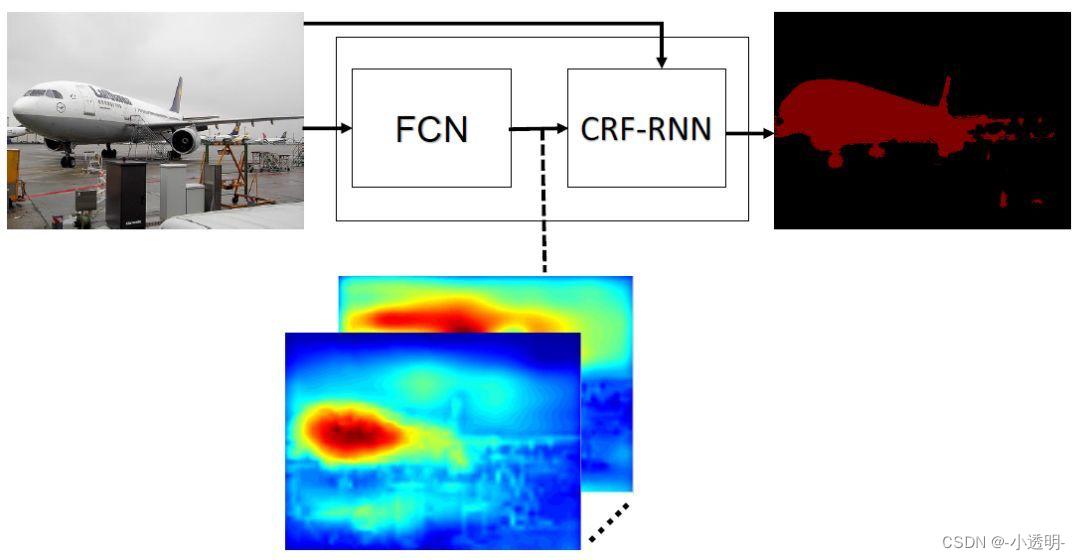
concluir
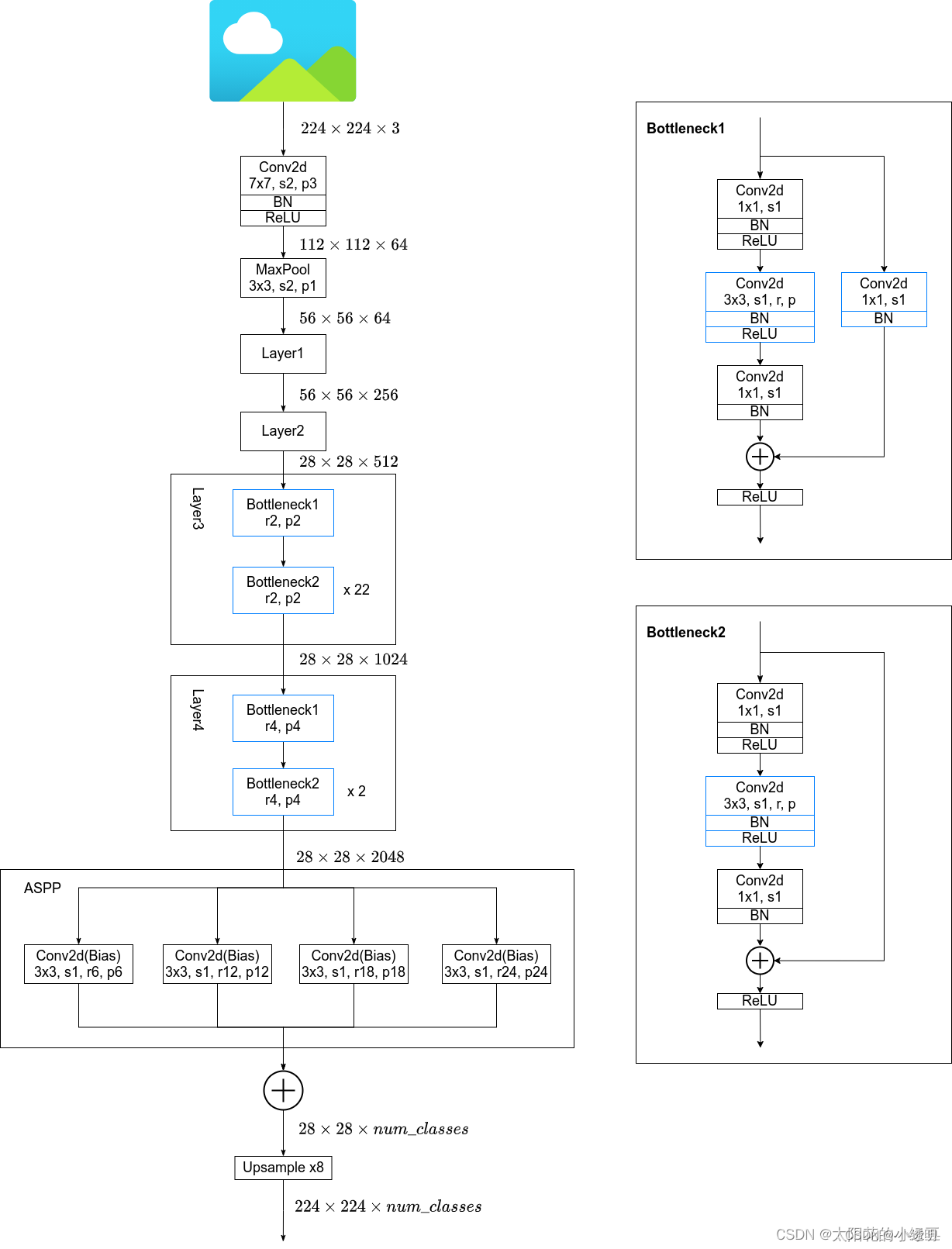
Diagrama de bloco geral do DeepLab v1

Segmentação Para obter uma coisa bidimensional, portanto, fc--->conv2d:
DeepLabV2
DeepLabV2 é uma melhoria para DeeplabV1, as principais melhorias incluem o seguinte:
-
Nova bottelNet
-
ASPP
-
CRF melhorado
ASPP
A ASPP é inspirada na SPPNet
Visa a fusão de características de diferentes escalas
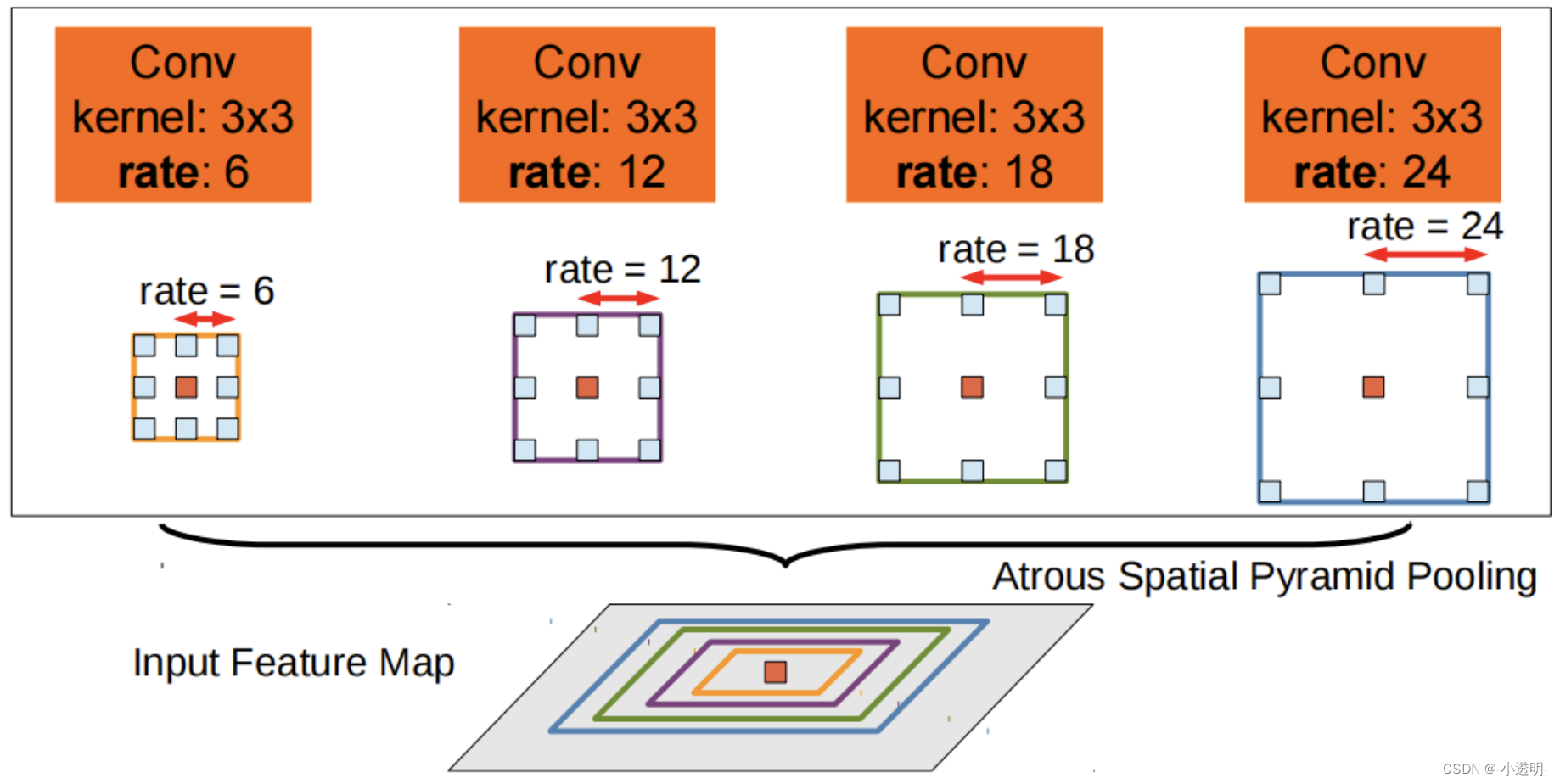

estrutura de rede
DeepLab V3
Melhorias em relação à V2:
- Os métodos anteriores eram todos cnn conectados por conjunto e nenhuma convolução dilatada foi usada. V3 usa uma convolução de furo em constante expansão para obter melhores detalhes

- ASPP melhorado
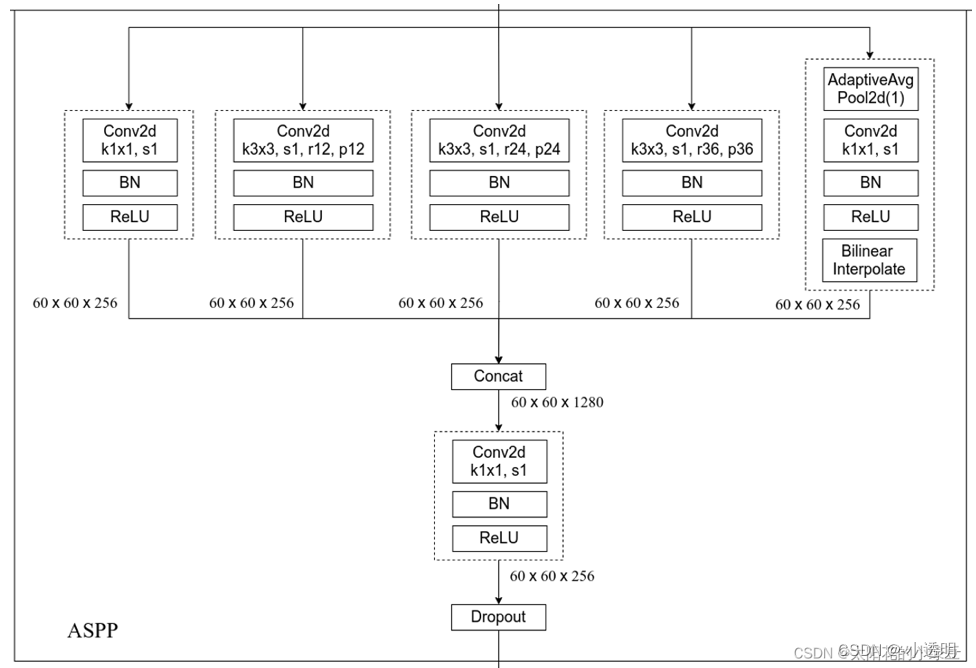
1*1 convolução : reduza os parâmetros e altere o número de canais .
Uma maneira melhor de fundir recursos é não adicioná-los diretamente: concatene-os e aprenda os parâmetros de mapeamento do novo canal por meio da convolução 1*1
Estrutura geral: r aumentando de forma incremental
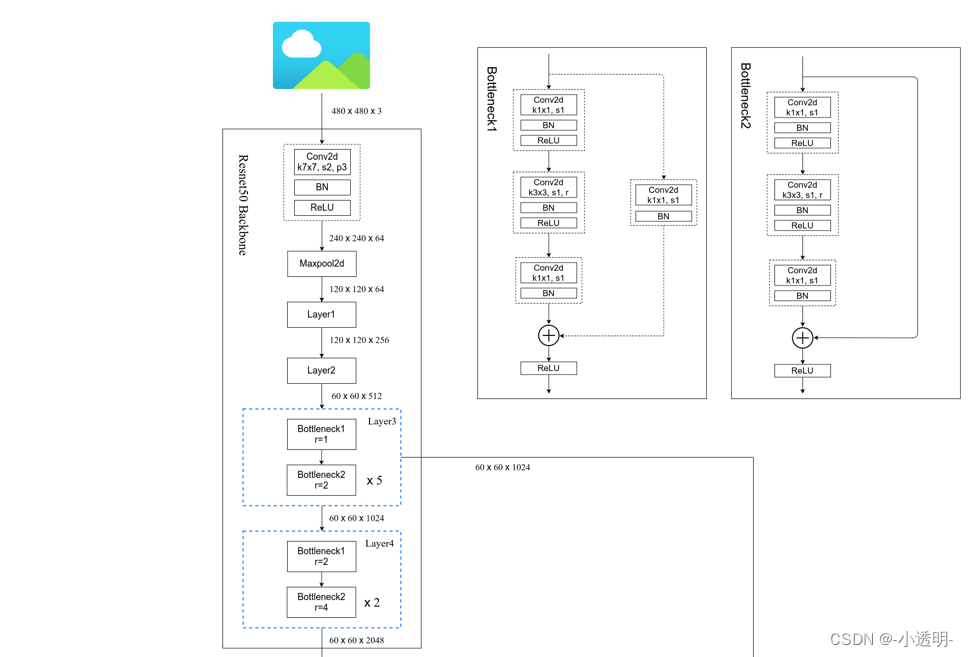

60*60-->480*480: realizado por interpolação linear, que substitui o CRF em V2