1. O que é TIDB
TiDB é um banco de dados NewSQL distribuído. Ele suporta expansão elástica horizontal, transações ACID, SQL padrão, sintaxe MySQL e protocolo MySQL e possui recursos de alta disponibilidade com forte consistência de dados. É um banco de dados híbrido adequado não apenas para cenários OLTP, mas também para cenários OLAP.
1.1 O que é NewSQL
- SQL, um banco de dados relacional tradicional, como o MySQL
- noSQL, como MongoDB, Redis
- novoSQL
1.1.1 Problemas com SQL tradicional
A Internet começou a se desenvolver rapidamente no início deste século. A escala de usuários e o volume de dados dos aplicativos da Internet estão aumentando e são necessários 7X24 horas online. Bancos de dados relacionais tradicionais se tornaram um gargalo nesse ambiente, e geralmente existem duas soluções:
①Atualize o hardware do servidor: Embora o desempenho tenha melhorado, sempre há um teto.
②Estilhaço de dados: quando os dados envolvem junções entre bancos de dados e transações entre bancos de dados, é muito problemático. Muitas pessoas simplesmente
os processam na camada de negócios por conta própria, o que é mais complicado.
1.1.2 Problemas com NoSQL
Posteriormente, surgiu o noSQL, abandonando a forte garantia de transação e modelo relacional do SQL tradicional, e focando na alta disponibilidade e escalabilidade do banco de dados.
vantagem:
- Alta disponibilidade e escalabilidade, particionamento automático, fácil expansão
- A consistência forte não é garantida e o desempenho é muito melhorado
- Extremamente flexível sem as restrições do modelo relacional
deficiência
- A consistência forte não é garantida, o que é bom para aplicativos comuns, mas ainda há muitos aplicativos de nível empresarial, como finanças, que exigem consistência forte.
- Ele não suporta instruções SQL, e a compatibilidade é um grande problema.Diferentes bancos de dados NoSQL têm suas próprias APIs para operar dados, o que é mais complicado.
1.1.3 Recursos do NewSQL
O NewSQL oferece a mesma escalabilidade do noSQL, ainda baseado no modelo relacional, mantém o SQL extremamente maduro como linguagem de consulta e garante características de transação ACID.
Simplificando, o NewSQL integra a poderosa escalabilidade do NoSQL em bancos de dados relacionais tradicionais.
Principais recursos do NewSQL
- Suporte SQL para consultas complexas e análise de big data.
- Suporte a transação ACID, nível de isolamento de suporte.
- O dimensionamento elástico, a expansão e a contração da capacidade são completamente transparentes para a camada de negócios.
- Alta disponibilidade e recuperação automática de desastres.
1.1.4 Comparação de três tipos de SQL
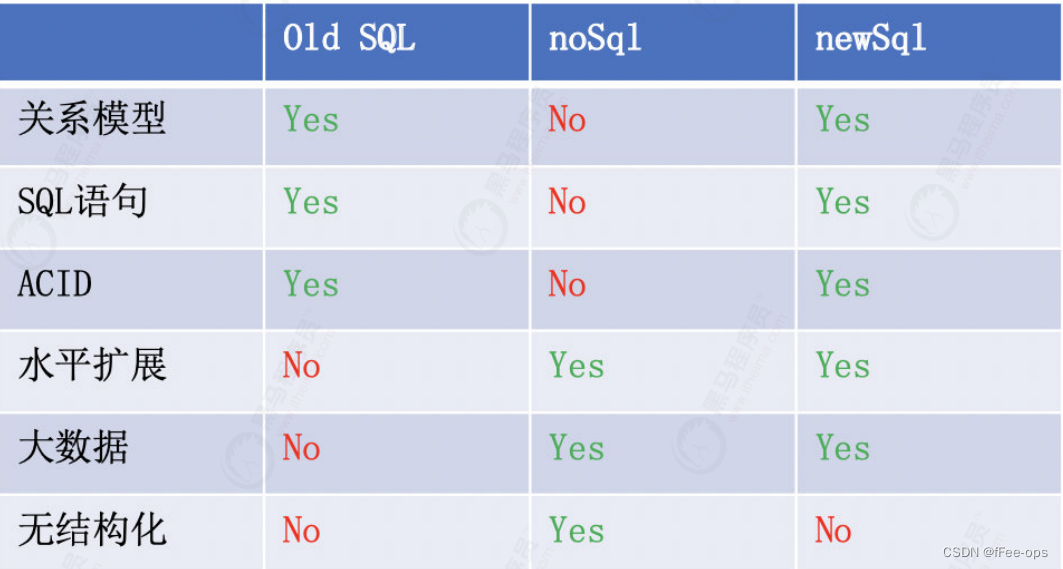
1.2 Principais recursos do TIDB
1.2.1 Expansão elástica horizontal
A expansão horizontal do TiDB pode ser alcançada simplesmente adicionando novos nós, e a taxa de transferência ou armazenamento pode ser expandida sob demanda para lidar facilmente com alta simultaneidade e cenários de dados massivos.
Graças ao design da arquitetura separada de computação de armazenamento do TiDB, a expansão ou redução on-line de computação e armazenamento pode ser realizada sob demanda, e o processo de expansão ou redução é transparente para a operação do aplicativo e para o pessoal de manutenção.
1.2.2 Suporte a transações distribuídas
TiDB 100% suporta transações ACID padrão
1.2.3 Alta disponibilidade em nível financeiro
Comparado com o esquema de replicação mestre-escravo (MS) tradicional, o protocolo de eleição majoritária baseado em Raft pode fornecer garantia de consistência forte de dados de 100% em nível financeiro e pode realizar recuperação automática de falhas sem perder a maioria das cópias (failover automático), sem manual intervenção
Os dados são armazenados em várias cópias e as cópias dos dados são sincronizadas com o log de transações por meio do protocolo Multi-Raft. A maioria das transações só pode ser enviada após a gravação bem-sucedida, garantindo forte consistência de dados e a disponibilidade dos dados não será afetada quando um pequeno número de cópias falha. Políticas como localização geográfica e número de réplicas podem ser configuradas sob demanda para atender aos requisitos de diferentes níveis de recuperação de desastres.
1.2.4 HTAP em tempo real
Como um típico banco de dados de armazenamento de linha OLTP, o TiDB também possui um poderoso desempenho OLAP. Com o TiSpark, ele pode fornecer uma solução HTAP completa. Um armazenamento pode lidar com OLTP e OLAP ao mesmo tempo sem o tradicional e complicado processo ETL
Fornece dois mecanismos de armazenamento: mecanismo de armazenamento de linha TiKV e mecanismo de armazenamento de coluna TiFlash. O TiFlash copia dados do TiKV em tempo real por meio do protocolo Multi-Raft Learner para garantir forte consistência de dados entre o mecanismo de armazenamento de linha TiKV e o mecanismo de armazenamento de coluna TiFlash. TiKV e TiFlash podem ser implantados em máquinas diferentes conforme necessário para resolver o problema de isolamento de recursos HTAP.
1.2.5 Banco de dados distribuído nativo da nuvem
O TiDB é um banco de dados projetado para a nuvem, profundamente acoplado ao Kubernetes e compatível com nuvens públicas, nuvens privadas e nuvens híbridas, tornando a implantação, configuração e manutenção muito simples. O objetivo do projeto do TiDB é 100% de cenários OLTP e 80% de cenários OLAP.Análise OLAP mais complexa pode ser feita por meio do projeto TiSpark. O TiDB não é intrusivo para os negócios e pode substituir graciosamente
o middleware de banco de dados tradicional, subbanco de banco de dados e subtabela e outras soluções de sharding. Ao mesmo tempo, também permite que o pessoal de desenvolvimento e manutenção se concentre no desenvolvimento de negócios sem prestar atenção aos detalhes da escala do banco de dados, o que melhora muito a produtividade da pesquisa e desenvolvimento
1.4.6 Altamente compatível com MySQL
Compatível com o protocolo MySQL 5.7, funções comuns do MySQL e o ecossistema MySQL, os aplicativos podem ser migrados do MySQL para o TiDB sem ou com uma pequena modificação de código.
Ferramentas avançadas de migração de dados são fornecidas para ajudar os aplicativos a concluir a migração de dados de maneira conveniente. Na maioria dos casos, é fácil migrar do MySQL para o TiDB sem modificar o código. Os clusters do MySQL após a divisão do subbanco de dados e da tabela também podem ser migrados em tempo real através do TiDB ferramentas.
1.3 OLTP&OLAP
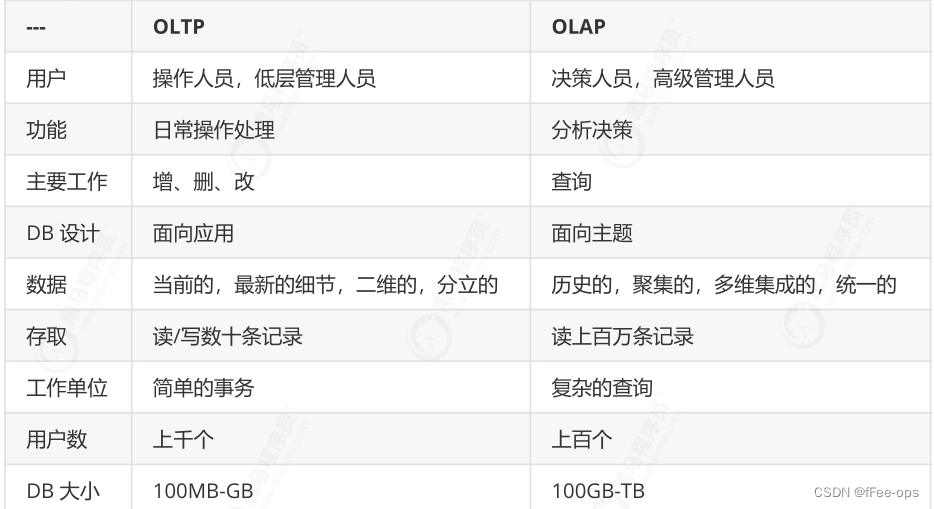
1.3.1 OLTP (Processamento de Transações Online)
OLTP (Online Transactional Processing) é o processamento de transações online. OLTP é a principal aplicação de bancos de dados relacionais tradicionais. Destina-se principalmente ao processamento básico e diário de transações. Registros são adicionados, excluídos, modificados e verificados em tempo real, como depósitos e retiradas uma quantia em um banco O pagamento é uma transação comercial
O processamento de transações on-line é um sistema muito transacional. Geralmente é um sistema on-line altamente disponível. Ele se concentra principalmente em pequenas transações e pequenas consultas. Ao avaliar seu sistema, geralmente depende do número de ransaction e Execute SQL executado por segundo. . Nesse sistema, um único banco de dados geralmente processa centenas ou milhares de transações por segundo, e o volume de execução das instruções Select é de milhares ou até dezenas de milhares por segundo. Os sistemas OLTP típicos incluem sistemas de comércio eletrônico, bancos, valores mobiliários, etc., como o banco de dados de negócios do eBay nos Estados Unidos, que é um banco de dados OLTP muito típico
1.3.2 OLAP (Processamento Analítico Online)
O OLAP (Online Analytical Processing) é o núcleo do data warehouse.Ele suporta operações de análise complexas, concentra-se no suporte à decisão e fornece resultados de consulta intuitivos e fáceis de entender.
Uma aplicação típica é um sistema de relatório dinâmico complexo. Nesse sistema, o volume de execução da instrução não é o padrão de avaliação, porque o tempo de execução de uma instrução pode ser muito longo e os dados lidos também são muito grandes. Portanto, em tal sistema, o padrão de avaliação geralmente é a taxa de transferência (largura de banda) do subsistema de disco, como quantos MB/s de tráfego podem ser alcançados.
1.3.3 Comparação de recursos
Comparação das características de OLTP e OLAP

1.3.4 Diferenças nos ângulos de projeto
2. A estrutura geral do TiDB
2.1 Vantagens do TiDB
Comparado com bancos de dados autônomos tradicionais, o TiDB tem as seguintes vantagens:
- Arquitetura puramente distribuída, com boa escalabilidade, suporta expansão e contração flexíveis
- Suporta SQL, expõe o protocolo de rede do MySQL para o mundo exterior e é compatível com a maioria das sintaxes do MySQL e pode substituir diretamente o MySQL na maioria dos cenários
- A alta disponibilidade é suportada por padrão. No caso de falha de um pequeno número de réplicas, o próprio banco de dados pode executar reparo e failover de dados automaticamente, o que é transparente para os negócios
- Oferece suporte a transações ACID e é compatível com alguns cenários com fortes requisitos de consistência, como transferências bancárias
- Possui uma rica ecologia de cadeia de ferramentas, abrangendo migração de dados, sincronização, backup e outros cenários
2.2 Componentes do TiDB
Para obter uma compreensão profunda da expansão horizontal e dos recursos de alta disponibilidade do TiDB, primeiro você precisa entender a arquitetura geral do TiDB. O cluster TiDB inclui principalmente três componentes principais: TiDB Server, PD Server e TiKV Server.Além disso, há um componente TiSpark para resolver necessidades complexas de OLAP dos usuários.
Em termos de design principal, o banco de dados distribuído TiDB divide a arquitetura geral em vários módulos, e cada módulo se comunica entre si para formar um sistema TiDB completo. O diagrama de arquitetura correspondente é o seguinte:
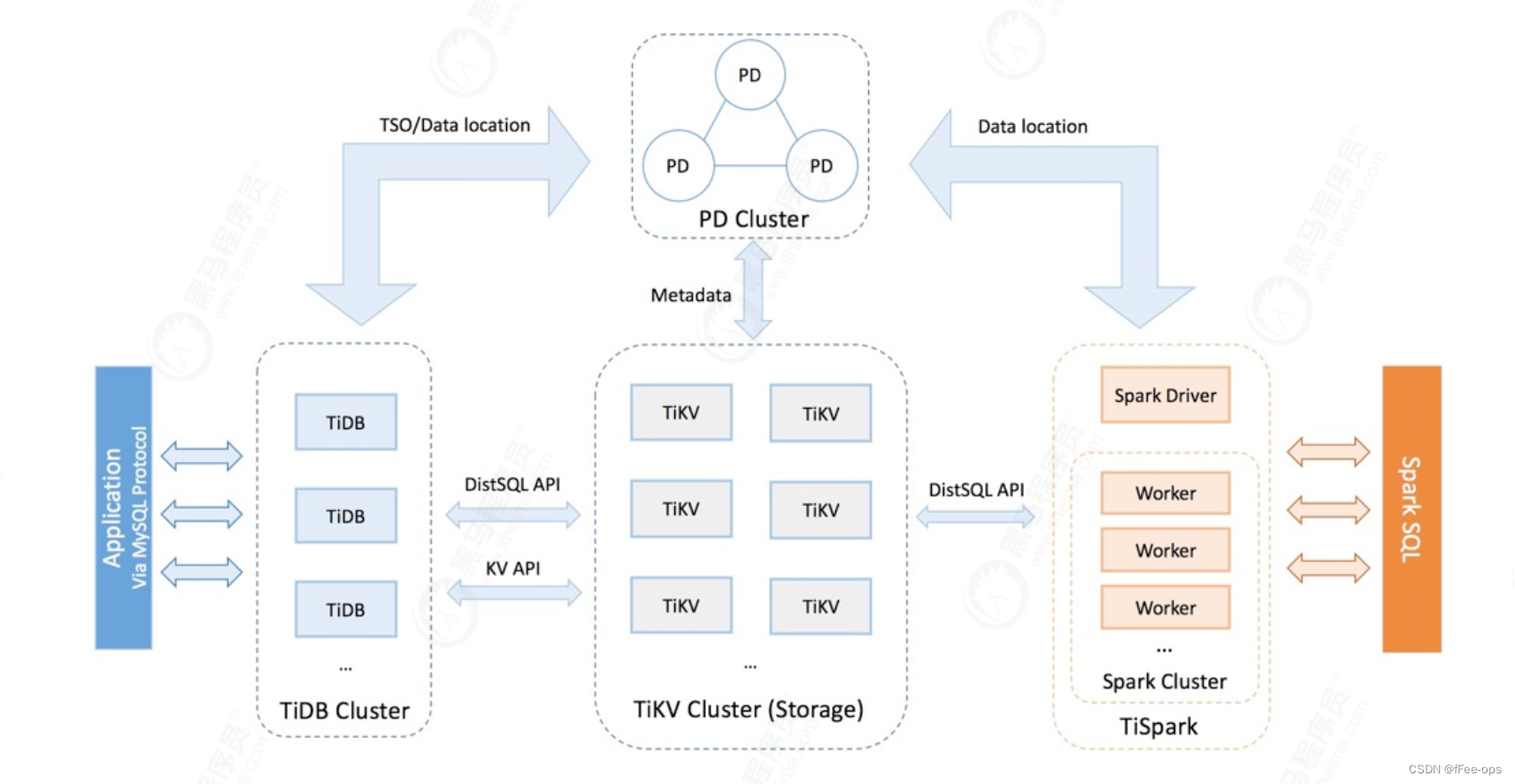
2.2.1 Servidor TiDB
O TiDB Server é responsável por receber solicitações SQL, processar a lógica relacionada ao SQL, encontrar o endereço TiKV para armazenar os dados necessários para o cálculo por meio de PD, interagir com o TiKV para obter dados e, finalmente, retornar o resultado. TiDB Server é stateless, não armazena dados em si, é responsável apenas pela computação, pode ser expandido horizontalmente indefinidamente e pode fornecer um endereço de acesso unificado externamente por meio de componentes de balanceamento de carga (como LVS, HAProxy ou F5).
2.2.2 Servidor PD (Driver de Colocação)
Placement Driver (referido como PD) é o módulo de gerenciamento de todo o cluster. Ele tem três tarefas principais:
uma é armazenar a metainformação do cluster (em qual nó TiKV uma chave é armazenada);
a outra é agendar e balancear a carga do cluster TiKV (como migração de dados, migração do líder do grupo Raft, etc.);
o terceiro é atribuir um ID de transação globalmente único e incremental.
A PD garante a segurança dos dados através do protocolo Raft. O servidor líder do Raft é responsável por lidar com todas as operações, e os demais servidores PD são usados apenas para garantir alta disponibilidade. Recomenda-se implantar um número ímpar de nós PD
2.2.3 Servidor TiKV
TiKV Server é responsável por armazenar dados.Do lado de fora, TiKV é um mecanismo de armazenamento de chave-valor distribuído que fornece transações. A unidade básica para armazenar dados é a Região, e cada Região é responsável por armazenar os dados de um Intervalo de Chaves (o intervalo esquerdo-fechado-direito aberto de StartKey a EndKey), e cada nó TiKV é responsável por várias Regiões. O TiKV usa o protocolo Raft para replicação para manter a consistência dos dados e a recuperação de desastres. As réplicas são gerenciadas em unidades de Regiões, e várias Regiões em nós diferentes formam um Grupo Raft, que são réplicas umas das outras. O balanceamento de carga de dados entre vários TiKVs é agendado por PD, que também é agendado em unidades de Regiões.
2.2.4 TiSpark
O TiSpark, como principal componente do TiDB para resolver as necessidades complexas de OLAP dos usuários, executa o Spark SQL diretamente na camada de armazenamento do TiDB e, ao mesmo tempo, integra as vantagens dos clusters distribuídos do TiKV e se integra à ecologia da comunidade de big data. Até agora, o TiDB pode suportar OLTP e OLAP por meio de um sistema, eliminando o problema de sincronização de dados do usuário.
2.2.5 TiFlash
TiFlash é um tipo especial de nó de armazenamento. Diferente dos nós comuns do TiKV, dentro do TiFlash os dados são armazenados na forma de colunas, e sua principal função é acelerar cenários analíticos.
2.3 Arquitetura geral do TiKV
Diferente do método tradicional de backup de nó completo, o TiKV divide os dados em fatias aproximadamente iguais (doravante denominadas coletivamente como Regiões) de acordo com o intervalo da chave. Cada fatia possui várias cópias (geralmente 3), uma das quais é Líder, fornecendo serviços de leitura e gravação.
O TiKV agenda essas regiões e réplicas por meio de PD para garantir que os dados e as cargas de leitura e gravação sejam distribuídos uniformemente em cada TiKV. Esse design garante a utilização total de todo o recurso do cluster e pode ser dimensionado horizontalmente à medida que o número de máquinas aumenta.
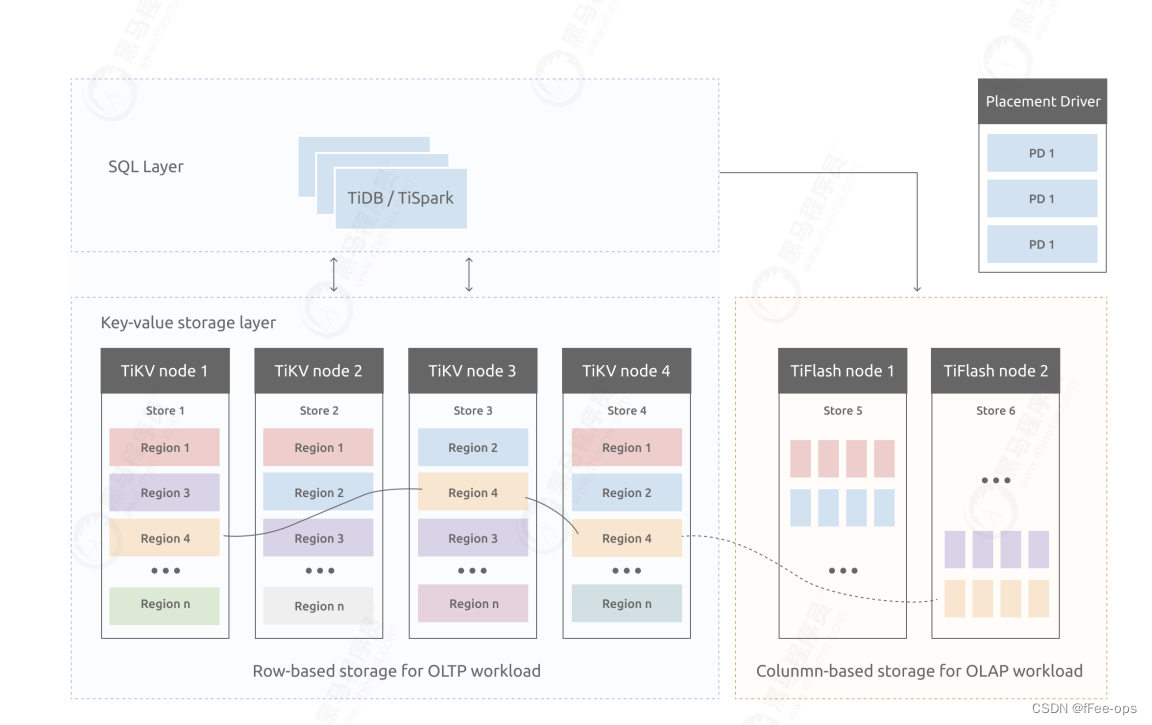
2.3.1 Divisão e fusão de regiões
Quando o tamanho de uma região excede um determinado limite (144 MB por padrão), o TiKV a divide em duas ou mais regiões para garantir que os tamanhos de cada região sejam aproximadamente semelhantes, o que é mais favorável à decisão de agendamento do PD. Da mesma forma, quando uma região fica menor devido a um grande número de solicitações de exclusão, o TiKV mesclará duas regiões adjacentes menores em uma.
2.3.2 Agendamento de regiões
A consistência dos dados é mantida entre a Região e a réplica através do protocolo Raft. Qualquer requisição de escrita só pode ser escrita no Líder, e precisa ser escrita na maioria das réplicas (a configuração padrão é 3 réplicas, ou seja, todas as requisições deve ser gravado em pelo menos duas réplicas com sucesso) retornará o sucesso de gravação do cliente.
Quando o PD precisar agendar uma cópia de uma região de um nó TiKV para outro, o PD primeiro adicionará uma cópia do aluno (cópia dos dados do líder) para este RaftGroup no nó de destino. Quando o progresso da cópia do Aprendiz alcança aproximadamente o da cópia do Líder, o Líder irá alterá-la para um Seguidor e, em seguida, remover a cópia do Seguidor do nó de operação, completando assim um agendamento da cópia da Região.
O princípio de agendamento da cópia do Líder é semelhante, mas depois que a cópia do Aprendiz do nó de destino se torna uma cópia do Seguidor, uma Transferência do Líder é executada novamente, para que o Seguidor inicie uma eleição para se tornar o novo Líder e, em seguida, o novo Líder é responsável por deletar a antiga cópia do Leader.
2.3.3 Transações distribuídas
O TiKV oferece suporte a transações distribuídas. Os usuários (ou TiDB) podem gravar vários valores-chave ao mesmo tempo, sem se preocupar se esses valores-chave estão na mesma fatia de dados (Região). O TiKV garante essas solicitações de leitura e gravação por meio de duas phase commit restrições ACID.
2.4 Arquitetura de alta disponibilidade
A alta disponibilidade é outro recurso importante do TiDB. Os três componentes do TiDB/TiKV/PD podem tolerar falhas de algumas instâncias sem afetar a disponibilidade de todo o cluster. A seguir, descrevemos a disponibilidade desses três componentes, as consequências de uma única falha de instância e como recuperá-los.
2.4.1 Alta Disponibilidade do TiDB
O TiDB é stateless. Recomenda-se implantar pelo menos duas instâncias e o front-end fornece serviços externos por meio do componente de balanceamento de carga. Quando uma única instância falha, isso afetará a sessão em andamento nesta instância.Do ponto de vista do aplicativo, haverá uma falha de solicitação única e o serviço poderá continuar sendo obtido após a reconexão. Após uma única instância falhar, ela pode ser reiniciada ou uma nova instância implantada.
2.4.2 Alta Disponibilidade PD
PD é um cluster que mantém a consistência dos dados através do protocolo Raft. Quando uma única instância falha, se a instância não for a líder do Raft, o serviço não será afetado; se a instância for o líder do Raft, um novo Raft líder será reeleito, para restabelecer automaticamente o serviço. O PD não pode prestar serviços externos durante o processo eleitoral, e este tempo é de cerca de 3 segundos. Recomenda-se implantar pelo menos três instâncias de PD. Depois que uma única instância falhar, reinicie a instância ou adicione uma nova instância.
2.4.3 Alta disponibilidade do TiKV
O TiKV é um cluster que mantém a consistência dos dados por meio do protocolo Raft (o número de cópias é configurável e três cópias são salvas por padrão) e usa PD para agendamento de balanceamento de carga. Quando um único nó falha, isso afetará todas as regiões armazenadas neste nó. Para o nó Líder na Região, o serviço será interrompido e aguardará a reeleição; para o nó Seguidor na Região, o serviço não será afetado. Quando um
nó TiKV falha e não pode ser recuperado dentro de um período de tempo (10 minutos por padrão), o PD migrará os dados nele para outros nós TiKV.
2.5 Cenários de aplicação
2.5.1 Fragmentação e fusão do MySQL
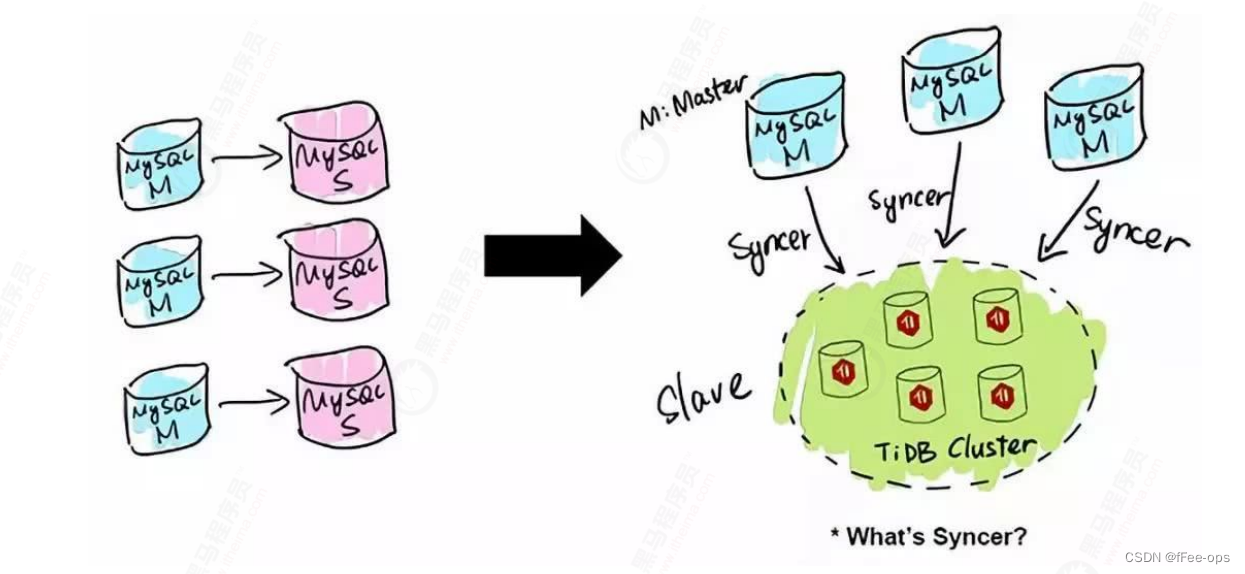
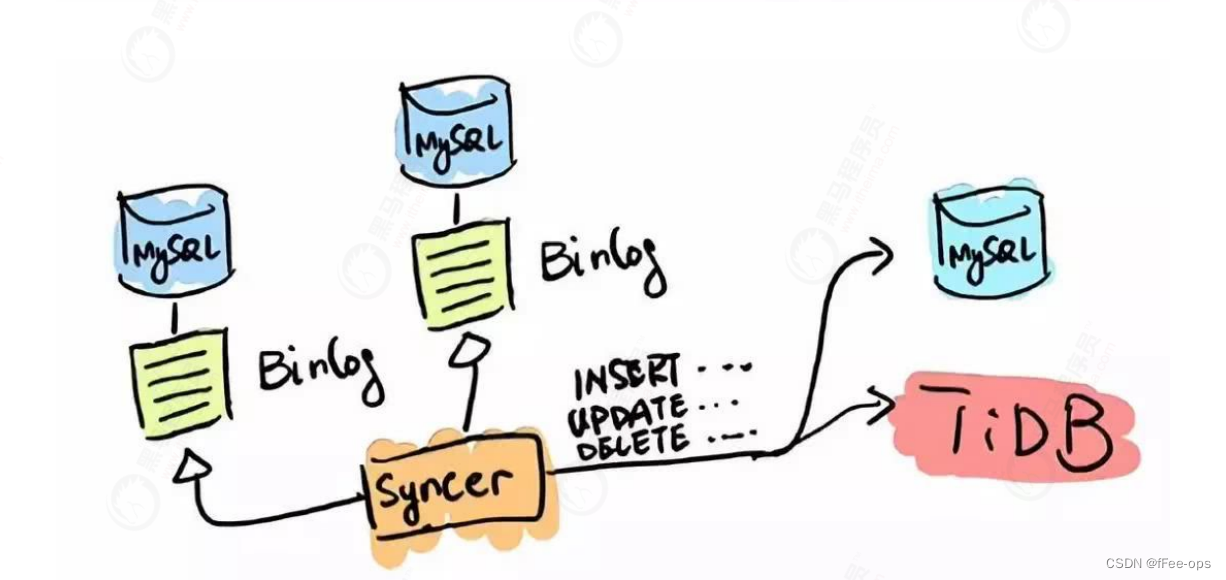
O primeiro tipo de cenário em que o TiDB é aplicado é a fragmentação e fusão do MySQL. Para empresas que já usam MySQL, subbancos de dados, tabelas, shards e middleware são métodos comumente usados. Com o aumento de shards, a consulta entre shards é um grande problema.
TiDB é compatível com o protocolo de acesso MySQL na camada de negócios. PingCAP fez uma ferramenta de sincronização de dados - Syncer, que pode usar TiDB como um MySQL Slave, e conectar TiDB como a biblioteca slave do banco de dados existente atrás da biblioteca MySQL principal. A primeira camada conecta os dados e pode executar diretamente consultas SQL em tempo real complexas entre bancos de dados, tabelas cruzadas e negócios cruzados.
2.5.2 Substituir diretamente o MySQL
Em um banco de dados TiDB, todos os cenários de negócios não precisam ser divididos em bancos de dados e tabelas, e todo o trabalho distribuído é feito pela camada de banco de dados. O TiDB é compatível com o protocolo MySQL, portanto, pode substituir diretamente o MySQL e basicamente funciona imediatamente. Não há necessidade de se preocupar com a carga de trabalho pesada e os custos de manutenção complicados trazidos pelo esquema tradicional de divisão de banco de dados e tabelas. O amigável interface do usuário permite que os técnicos regulares possam eficientemente
para manutenção e gestão. Além disso, o TiDB tem uma capacidade semelhante à do NoSQL e pode melhorar a capacidade de suporte ao negócio do sistema por meio da expansão horizontal quando a quantidade de dados e o tráfego de acesso continuam crescendo e o atraso de resposta é estável.
2.5.3 Armazém de dados
O próprio TiDB é um sistema distribuído e o terceiro cenário de uso é usar o TiDB como um data warehouse. TPC-H é um conjunto de teste no campo da análise de dados. O desempenho do TiDB 2.0 em cenários OLAP foi bastante aprimorado. Algumas consultas complexas que só podem ser executadas no data warehouse podem ser executadas no TiDB 2.0 e o tempo pode basicamente ser controlado dentro de 10 segundos. Obviamente, como o escopo do OLAP é muito grande,
o SQL do TiDB também é incerto. Por esse motivo, o PingCAP abriu o código do TiSpark. O TiSpark é um plug-in do Spark. Os usuários podem usar o Spark SQL diretamente para fazer análises de big data no TiKV em tempo real.