Índice
Visão geral do mecanismo de armazenamento
O processador de dados lida com os arquivos de disco onde os dados são realmente armazenados. Sua camada superior (camada de serviço) passa as instruções SQL processadas (processamento SQL e resultados da análise) para o processador de dados, e o processador de dados armazena os dados em arquivos de disco de acordo com as instruções ou Leia os dados do arquivo do disco. Portanto, o processador de dados é o núcleo de todo o DBMS e possui as funções mais essenciais: ler dados e armazenar dados.
O mecanismo de armazenamento também pode ser considerado como o tipo de tabela (o nome original do mecanismo de armazenamento 表处理器), porque diferentes tabelas podem escolher diferentes mecanismos de armazenamento, e diferentes mecanismos de armazenamento têm diferentes métodos de processamento de dados, estruturas de tabela, formatos de arquivo etc.
O mecanismo de armazenamento de dados do MySQL é conectável, ou seja, pode ser trocado à vontade. A unidade de ação do mecanismo de armazenamento de dados é uma tabela e um mecanismo de armazenamento adequado pode ser selecionado para cada tabela.
O mecanismo de armazenamento padrão após o MySQL5.5 é o mecanismo InnoDB (anteriormente MyISAM), que tem muitas vantagens em comparação com outros mecanismos de dados (as vantagens específicas serão discutidas posteriormente). as tabelas usam o mecanismo de armazenamento padrão InnoDB
O fluxo geral de execução das instruções SQL
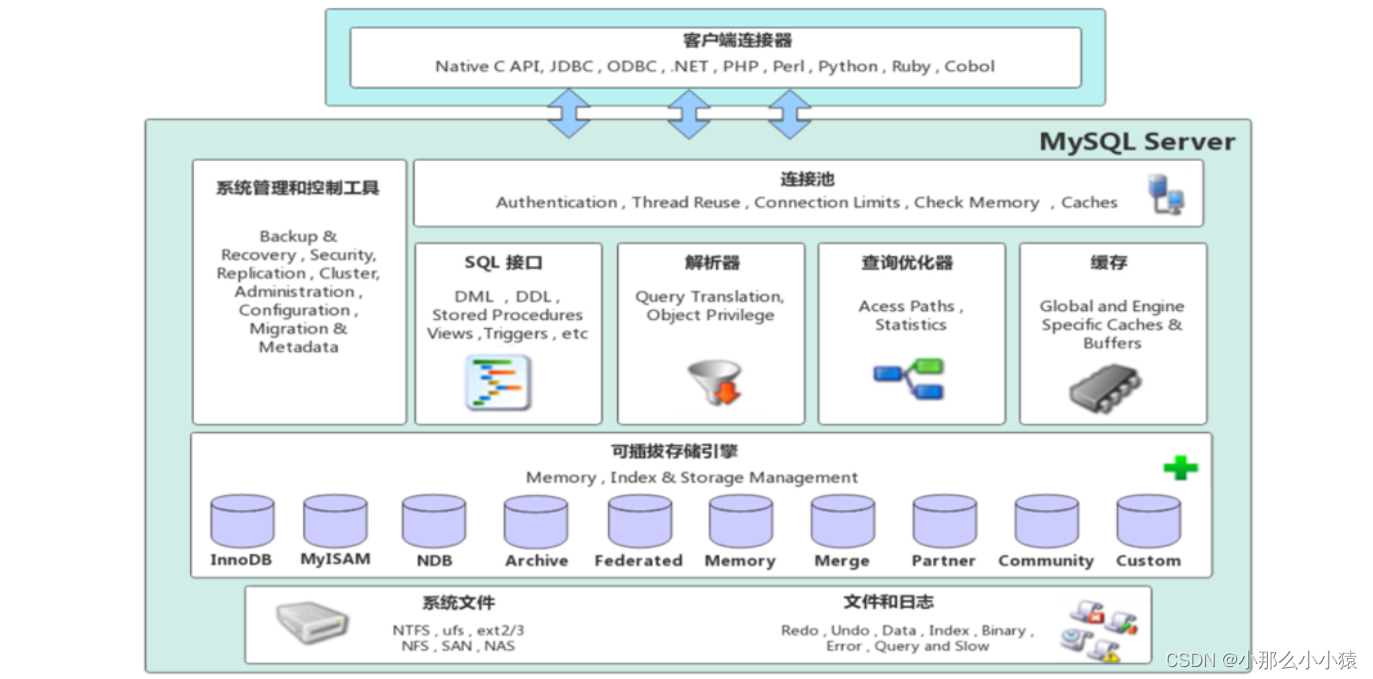
Quando queremos operar o banco de dados, devemos primeiro nos conectar ao serviço de banco de dados, seja usando um cliente gráfico ou uma linha de comando. Resumindo, para poder se conectar, a camada de conexão precisa fornecer conexão e autenticação. , autorização e outros serviços.
Após a conclusão da conexão, podemos inserir o SQL para operar. Nesse momento, a camada de serviço verificará a semântica e a gramática da instrução SQL que inserimos, criará uma árvore de análise sintática e executará a otimização automática (antes da versão 5.7, o cache deve ser consultado, se o cache Sim, retorne o resultado armazenado em cache diretamente. Como a taxa de acerto é muito baixa, ele foi descartado após a versão 8). Em seguida, passe os dados processados para a camada do mecanismo.
A camada do mecanismo é responsável por armazenar ou extrair os dados de acordo com os resultados da camada superior. A
camada de armazenamento realmente armazena os dados e logs e os gerencia com a camada do mecanismo.
Introdução a cada mecanismo de armazenamento
Você pode show enginesvisualizar comando

. InnoDBe transações distribuídas, e oferece suporte a bloqueios em nível de linha. , suporte a chaves estrangeiras
Cada mecanismo tem suas próprias características, porque é de código aberto, para que grandes empresas possam personalizar o mecanismo de acordo com o negócio específico.
Os mais importantes no banco de dados são o InnoDB motor e o motor MyISAM, cada um com suas próprias vantagens Desvantagem, não uma relação de substituição, um motor usado pela versão atual e outro usado pela versão antiga
InnoDBGenericName
Este mecanismo aparece após o MySQL 3.2 e é o mecanismo de armazenamento padrão após o MySQL 5.5
Vantagens do InnoDB
- O mecanismo InnoDB suporta chaves estrangeiras, mas as chaves estrangeiras podem causar problemas de desempenho
- O mecanismo InnoDB suporta transações (muito importante) e introduz duas operações, commit e rollback. Para dados importantes, ter transações pode garantir o ACID (atomicidade, consistência, isolamento e durabilidade) dos dados. Após uma falha, ele pode se recuperar sozinho e reverter os dados não confirmados.
- O InnoDB oferece suporte ao bloqueio em nível de linha. Quando vários threads são simultâneos, para resolver o problema de segurança do thread, é necessário travar. Outros mecanismos geralmente usam bloqueios em nível de tabela.Em segundo lugar, o InnoDB pode bloquear linhas de operações específicas, de modo que não afete as operações simultâneas de outros dados em toda a tabela e melhore a eficiência da simultaneidade. Portanto, as características são particularmente proeminentes quando a quantidade de dados é grande e a quantidade de simultaneidade é alta
Características do InnoDB
- Antes do MySQL8, os arquivos de armazenamento de tabelas eram divididos em duas categorias: estrutura da tabela
.frm, dados da tabela e índice.idb; após a versão do MySQL8, a estrutura da tabela, os dados da tabela e o índice da tabela eram todos colocados em um arquivo.idbpara armazenamento. - O índice de chave primária do InnoDB armazena todos os dados no nó folha
Desvantagens do InnoDB em comparação com o MyISAM
- Consulta em lote não é tão boa quanto MyISAM
- Alto uso de memória: como o InnoDB coloca dados e índices juntos, os dados desta página também são carregados ao carregar páginas de folha. No entanto, o MyISAM carrega o endereço de dados desta página, o que economiza muito espaço em comparação com os dados, o que faz com que o InnoDB tenha maiores requisitos de memória.
O InnoDB não oferece suporte a índices de hash, mas o mecanismo otimizará automaticamente e criará índices de hash adaptativos com base em consultas dentro do mecanismo. A intervenção humana não é possível.
Ao adicionar uma grande quantidade de dados, você pode excluir todos os índices na tabela primeiro, adicione em lotes e depois recriá-los. Torna desnecessário manter o índice ao adicionar, melhorando a eficiência
MySIAM
Vantagens do MySIAM
- acesso mais rápido
- count(*) é mais eficiente no nível O(1), porque existem variáveis para cálculo estatístico, e o InnoDB é usado para verificar o nível O(n) um por um
Desvantagens do MySIAM em comparação com o InnoDB:
- Não suporta chaves estrangeiras, transações, bloqueios em nível de linha (MyISAM é um bloqueio em nível de tabela)
O processamento MySIAM é adequado para pequenas, baixa simultaneidade (porque os bloqueios de tabela afetam a simultaneidade), sem requisitos de integridade de dados (porque não suporta transações, mas alto desempenho), consulta e adição são muito maiores do que modificação e exclusão de tabelas, pode economizar memória recursos e melhorar a eficiência de acesso (o mecanismo de dados InnoDB é recomendado para a maioria dos cenários)
Memória
- A estrutura da tabela é armazenada no disco e os dados da tabela são armazenados na memória. Por estar na memória, a velocidade é mais rápida, mas também é limitada pelo tamanho da memória, o que impossibilita o armazenamento de um grande quantidade de dados.
- A estrutura de índice padrão é um índice de hash, que se caracteriza por ser muito rápido na localização de um dado, mas não é tão bom quanto um índice de árvore B+ na busca por um intervalo.
- Afetado por fatores físicos, como tamanho da memória e falta de energia, ele só pode ser usado para armazenar dados temporários ou ser usado como cache. Mas esses recursos são substituídos por outro software de servidor, como o Redis. Portanto, use menos.
Comparação dos três motores
| características | InnoDBGenericName | MyISAMGenericName | Memória |
|---|---|---|---|
| romances | apoiar | não suporta | não suporta |
| chave estrangeira | apoiar | não suporta | não suporta |
| nível de bloqueio | bloqueio de nível de linha | nível da mesa | nível da mesa |
| Índice de árvore B+ | apoiar | apoiar | apoiar |
| índice de hash | Não suportado, mas otimizações internas são criadas e não podem ser intervencionadas | não suporta | suporte (padrão) |
| velocidade de inserção | lento | meio | rápido (nível de memória) |
| uso de memória | Médio (estrutura de índice) | Baixo | Alto (os dados são armazenados na memória) |
| cenas a serem usadas | Uma grande quantidade de dados, escrita simultânea, requisitos de transação | Pequenos dados, economia no consumo de recursos, negócios simples, sem requisitos de transação para dados | A quantidade de dados é pequena, não se preocupa com a segurança dos dados e possui requisitos de alto desempenho |
A principal razão para usar um banco de dados relacional é que seus recursos transacionais podem tornar os dados mais seguros.Se os dados não exigirem recursos transacionais, o NoSQL será considerado.
outros motores
- Arquivo: fornece a solução perfeita para armazenar e recuperar grandes quantidades de informações históricas, arquivadas ou de auditoria de segurança raramente referenciadas. Índices não são suportados, atualizações não são suportadas e bloqueios em nível de linha são suportados. É adequado para inserir dados que nunca são modificados uma vez e têm menos consultas.
- Mecanismo CSV: O arquivo csv pode ser processado como uma tabela mysql. O formato de armazenamento são arquivos csv comuns
e outros mecanismos raramente usados
Instruções SQL relacionadas ao mecanismo
- Veja o mecanismo de armazenamento padrão do sistema atual
show variables like '%storage_engine%';

- Modifique o mecanismo de armazenamento padrão do sistema
SET DEFAULT_STORAGE_ENGINE=引擎名称;. Esta configuração retornará à configuração original após a reinicialização do servidor. Ela podemy.cnfser modificada no arquivo de configuração de configuração do SQL.

- Especifique o mecanismo de armazenamento da tabela ao criar a tabela, não especifique o mecanismo de armazenamento padrão
CREATE TABLE 表名( 建表语句; ) ENGINE = 存储引擎名称; - Modifique o mecanismo de armazenamento da tabela
ALTER TABLE 表名 ENGINE = 存储引擎名称;
Mecanismo InnoDB
estrutura lógica de armazenamento
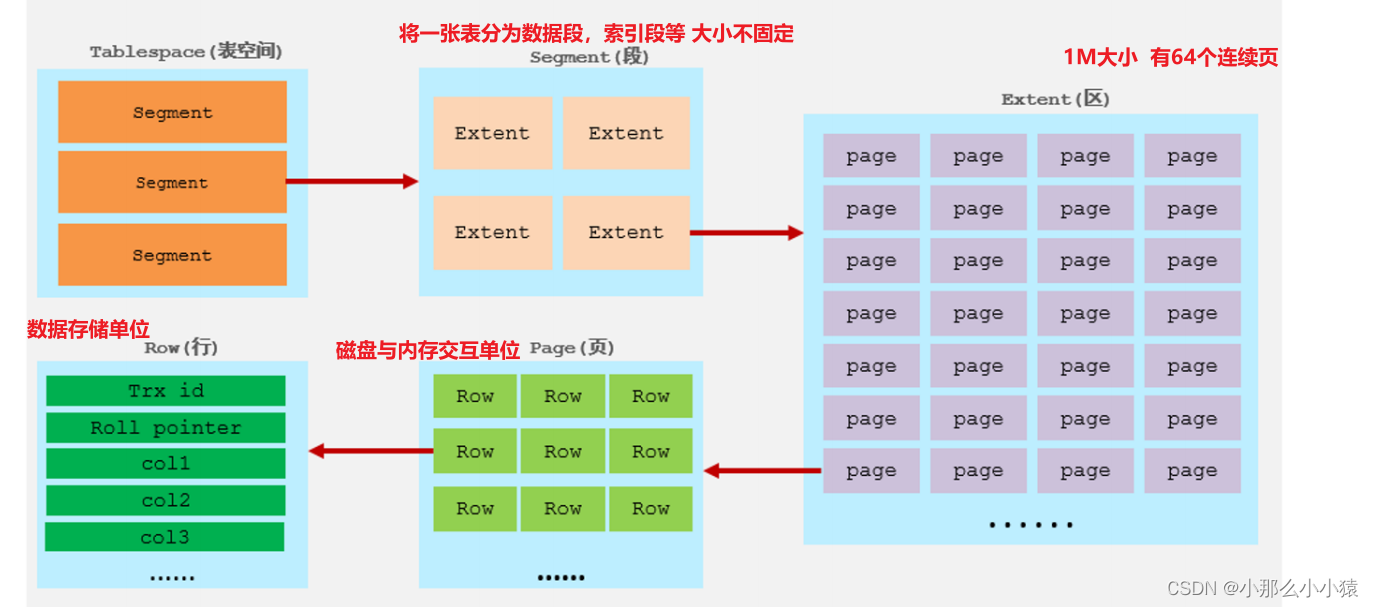
O mecanismo InnoDB é dividido em cinco níveis de estrutura: de grande a pequeno, é espaço de tabela, segmento, área, página e
espaço de tabela de linha.
O espaço de tabela é a estrutura mais alta do armazenamento lógico InnoDB e é dividido em espaço de tabela do sistema , espaço de tabela independente, espaço de tabela geral, espaço de tabela temporário e espaço de tabela undo
Após o MySQL 8, por padrão, cada tabela existirá em um espaço de tabela independente (a estrutura ainda é colocada no espaço de tabela do sistema) e é armazenada em um arquivo separado no disco. Pode ser definido por, se for definido como 0, os dados de cada tabela serão colocados no espaço de tabela do sistema数据索引xx.ibdinnodb_file_per_tableibdata1
段
O segmento é dividido em segmento de dados, segmento de índice, segmento de reversão e assim por diante. Os dados e índices de uma tabela são colocados em um espaço de tabela e, em um espaço de tabela, índices e dados também são divididos em diferentes segmentos para armazenamento. De acordo com a estrutura da árvore de índice B+, o segmento de dados é armazenado na árvore de índice 叶子节点e o segmento de índice é armazenado na árvore de índice 非叶子节点.
O espaço de um segmento se expande com o tamanho da mesa, o tamanho da mesa, o tamanho do segmento. Um segmento contém pelo menos uma área e a menor unidade de extensão de um segmento é uma área. O tamanho padrão de uma área é 1M, ou seja, 64 páginas consecutivas. Ao executar a expansão de área, para garantir a continuidade das páginas e evitar o máximo possível IO aleatório, 4 a 5 áreas serão solicitadas do disco a cada vez. O tamanho padrão de cada página é exatamente , a página no InnoDB é , o sistema operacional irá ler ou escrever 4 vezes. Cada nó na árvore de índice é uma página e pelo menos 2 itens de dados são armazenados em uma página. Se você inserir dados sequencialmente em uma página de dados completa, uma nova página será realocada da extensão. Se um dado for inserido no meio da árvore de índice, ocorrerá uma divisão de página quando a página estiver cheia.
区
页16K是Linux页大小的4倍磁盘与内存交互的最小单位
-
Divisão de página
O armazenamento dos dados da linha na folha deve ser armazenado em ordem, se for inserido fora de ordem, se for inserido em uma página inteira, ocorrerá divisão de página. pensar? Por que não inserir em uma nova página? Porque o armazenamento de dados é sequencial. Como evitar a divisão de páginas? Não insira dados nas páginas de dados que estão cheias no meio, ou seja, inserção sequencial.

Separe diretamente do meio da página inteira, divida-a em duas páginas e insira-a em uma página na ordem

. Após a divisão, sobrará espaço na página e, em seguida, insira os dados a serem inseridos.

Finalmente, conecte o páginas recém-abertas em ordem. Observe que é InnoDB O mecanismo otimizou a árvore bB+. As páginas são conectadas bidirecionalmente.

As divisões de página resultam em um grande número de páginas restantes, desperdiçando espaço. A divisão de páginas consome desempenho, então tente inserir em ordem ao inserir dados -
Mesclagem de página
Quando os dados são excluídos, o mecanismo InnoDB apenas faz uma marca. Quando o número de exclusões em uma página atinge 50% da página, ele procura as páginas antes e depois para determinar se pode ser mesclado.

Mescle duas páginas que não estão cheias. As linhas de dados na tabela são armazenadas na linha. O tamanho de armazenamento de cada linha depende do design do campo da tabela e do tamanho dos dados na linha. O InnoDB armazena em unidades de , e um página contém várias linhas.

行行
Resumir
arquitetura
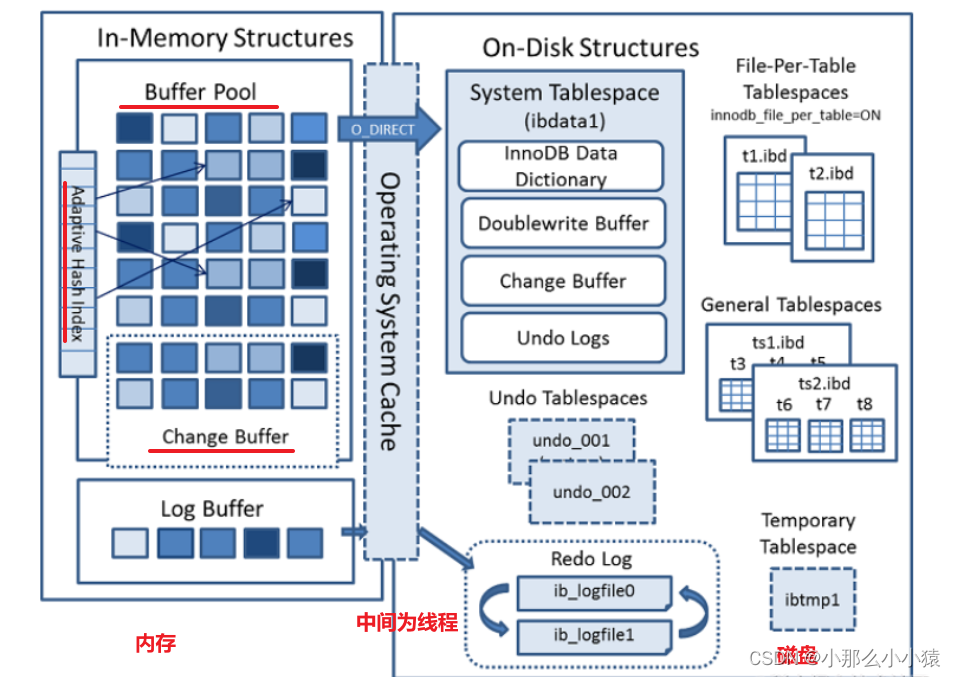
O mecanismo InnoDB consiste em três partes: pool de memória, thread de segundo plano e arquivo de disco.
parte da memória
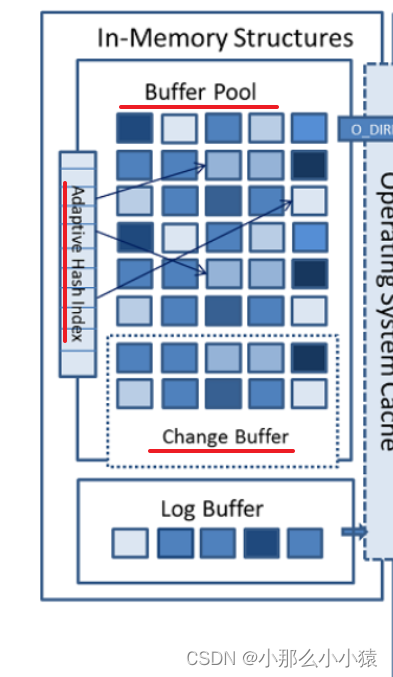
A partir da figura, a memória é composta principalmente por 4 partes, ou seja Buffer Pool, , Change buffer, Log Buffer,Adaptive Hash Index
Buffer Pool:
Primeira nota : Buffer pool 查询缓存não é a mesma coisa (porque eu estava confuso sobre isso quando comecei)
Cache de consulta : Quando a camada de serviço recebe o SQL para executar o tipo de consulta, ela primeiro vai para o cache de consulta de memória para descobrir se existe tal consulta Se os resultados do cache SQL não forem analisados pela sintaxe semântica, etc., eles serão finalmente entregues à camada do mecanismo para processamento. O Buffer Pool está no nível do mecanismo. E esse tipo de cache de consulta é muito pouco inteligente, ou seja, embora seja SQL com a mesma semântica, se houver uma pequena alteração (como adicionar um espaço), o cache do SQL anterior não pode ser encontrado e a taxa de acerto é muito baixo, que foi removido na versão MySQL8.
Por que introduzir o Buffer Pool :
Todos os tipos de dados e índices são colocados no espaço de tabela na forma de páginas, e o espaço de tabela também é uma abstração de arquivos no disco. Ou seja, os dados são colocados no disco.
No entanto, existe uma lacuna entre a velocidade do disco e a memória.Ao acessar um determinado dado, toda a página onde os dados estão localizados é carregada no disco, o que melhorará muito a eficiência. No entanto, após o acesso, as páginas não são descarregadas de volta para o disco imediatamente. Primeiro, o IO aleatório de tais discos flash frequentes afetará muito o desempenho. Segundo, os dados na memória ainda podem ser usados, para não lê-los de novo.
Introdução ao Buffer Pool :
O tamanho padrão do Buffer Pool é 128M, quanto maior o tamanho da memória, mais dados, menor a probabilidade de consultar o disco e maior o desempenho. Portanto, quanto maior, melhor, melhor o dispositivo permite. Pode haver vários Buffer Pools, o padrão é um e o número também pode ser modificado.
O buffer pool é baseado em páginas, e o tamanho de cada página é igual ao tamanho do disco 16K. De acordo com a função da página, ela é dividida em: 索引页, 数据页desfazer página, inserir cache, hash adaptável, bloquear informações, etc.
De acordo com o estado da página, ela é dividida em:
- página livre : página livre, página não utilizada na memória
- página limpa : Depois que os dados são carregados do disco para a memória, a página não foi modificada e é consistente com o disco
- dirty : Os dados da página foram modificados e a página não foi atualizada para o disco, ou seja, a página cujos dados da memória são inconsistentes com o disco
Na memória usada pelo MySQL, geralmente mais de 80% do espaço é dado ao buffer pool, e seu tamanho afetará diretamente o desempenho geral. Quando a memória não é suficiente, o mecanismo InnoDB usaLRU页面置换算法as páginas usadas menos recentemente para remover as páginas que não foram usadas recentemente do disco e atualizá-las no disco. No entanto, o mecanismo InnoDB otimiza o algoritmo LUR. Por exemplo, selecione * para executar uma verificação completa da tabela, que permite que os dados usados com pouca frequência sejam verificados e se tornem os dados usados mais recentemente. O mecanismo InnoDB é otimizado para essa situação.
Changer Pool: também é chamado de pool de buffer de inserção, 是针对非主键索引插入的优化porque a chave primária geralmente é inserida em ordem, o que é mais conveniente ao reindexar a árvore de índice de chave primária. (Basta adicionar nós de folha conforme necessário). Ao inserir, se um índice de chave não primária for estabelecido, não é necessário apenas inserir na árvore de índice de chave primária, mas também inserir na árvore de índice de chave não primária. As chaves de índice de índices de chave não primária são frequentemente inseridas fora de ordem, acesso discreto a índices de chave não primária, E/S aleatória levará à degradação do desempenho. Usando o change pool, ao inserir um índice de chave não primária, primeiro determine se a página da árvore de índice usada para inserção está na memória, se existir, insira-a diretamente, se não existir, coloque a página de índice correspondente na memória depois de ler a partir do disco e, em seguida, inserir. Ao ler os dados, mescle o Change Buffer com o Buffer Pool e, em seguida, atualize o Buffer Pool para o disco em uma determinada frequência.
Por exemplo: para inserir um dado com id=2 e name='zs', o id é o índice de chave primária e o nome é o índice comum. Ao inserir dados, o id é ordenado e inserido diretamente na página de índice da chave primária, enquanto ao inserir o nome, o nome geralmente está fora de ordem, o que requer colocar parte do índice no buffer pool de inserção e inseri-lo primeiro changer Pool. , libere-o para o disco juntos.提高非主键索引的插入性能
自适应哈希索引 AHI: o mecanismo cria automaticamente um índice de hash para páginas quentes, 页em unidade. Como o índice de hash pode acessar os dados apenas uma vez sem colisão de hash, e o índice de chave primária da árvore B+ geralmente precisa de 1 a 3 vezes. No entanto, o índice de hash não oferece suporte à consulta de intervalo, o que exige que o mecanismo julgue a situação e crie um índice de hash para os dados apropriados.无需人为干预
logo buffer: O buffer de log, a parte da memória como o redo log está aqui, o tamanho padrão é 16M, os dados na memória serão atualizados no disco na frequência especificada, existem três opções. O primeiro tipo é compartilhado e liberado no disco a cada 1s; o segundo tipo é liberado no disco depois que a transação é confirmada e o primeiro tipo também é usado ao mesmo tempo. A terceira é que, após a confirmação da transação, ela será entregue à página de cache do sistema e o sistema a atualizará no disco em um horário especificado, e o primeiro método também é usado ao mesmo tempo.
parte do disco
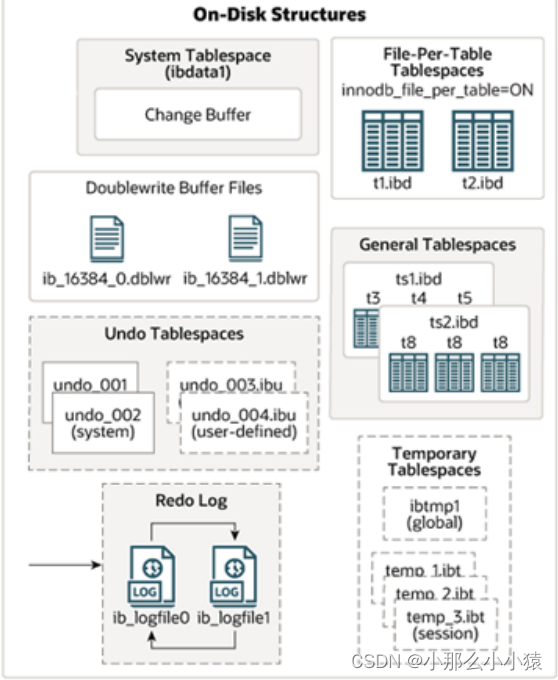
A estrutura do disco tem principalmente as seguintes partes:
-
Espaço de tabela do sistema : espaço de tabela do sistema
O espaço de tabela do sistema pode ter um ou mais arquivos de dados. Por padrão, um arquivo de dados de espaço de tabela do sistemaibdata1chamado .
O espaço de tabela do sistema inclui dicionário de dados (incluindo metadados), buffer de gravação dupla (sem área de armazenamento após a versão 8), buffer de alteração, log de desfazer e dados e índices de tabelas criadas no espaço de tabela do sistema (não criadas no espaço de tabela do sistema armazenado em um tablespace separado). -
Tablespaces de arquivo por tabela : tablespace independente
Cada tabela usa um tablespace independente por padrão para armazenar dados e índices, correspondendo a um único.idbarquivo no disco -
Tablespaces gerais : tablespace geral
é um tablespace compartilhado que pode armazenar várias tabelas -
Redo log
Os dois loops de Redo gravam arquivos ib_logfile0 e ib_logfile1
fio de fundo
É o thread que viaja entre a memória e o disco, faz o agendamento de acordo e fornece serviços de dados. É
dividido principalmente em Master Thread, IO Thread, Purge Thread,Page Cleaner Thread
O thread de segundo plano do Master Thread
é responsável pelo agendamento de outros threads e também é responsável por mesclar buffer poole change buffermesclar, armazenamento de páginas sujas, recuperação de páginas de desfazer, etc.
IO Thread
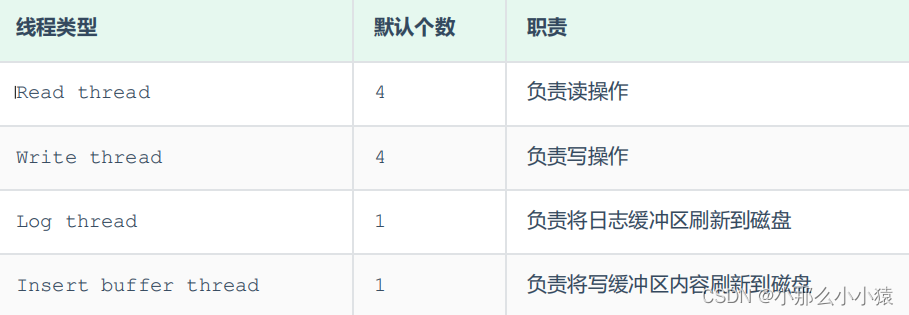
Purge Thread
é principalmente para recuperar logs de log de desfazer após a transação envio, reduzindo a pressão na
página do thread Master Cleaner Thread
Descarrega os dados da página suja na memória para o disco para reduzir a pressão no thread Master
Três principais recursos do InnoDB
Os três principais recursos do artigo recomendado
InnoDB são double write, Buffer pool, 自适应哈希索引
os dois últimos foram apresentados acima e apenas o mecanismo de gravação dupla é apresentado aqui.
Por que é chamado de escrita dupla? Como um dado na memória é primeiro 顺序gravado no buffer de gravação dupla no disco, depois de confirmar que a gravação foi bem-sucedida, os mesmos dados na memória 离散são gravados no espaço de tabela correspondente.
Por que existe um mecanismo de gravação dupla?
Primeiro, vamos falar sobre as desvantagens do mecanismo de gravação dupla: os mesmos dados são gravados no disco duas vezes e um IO adicional é executado. Embora seja gravado sequencialmente, o IO adicional reduz o desempenho geral em 5 a 10%.
Vamos falar sobre por que o mecanismo de gravação dupla foi introduzido? O motivo fundamental é resolver o problema de corrupção de página no processo de atualização dos dados da memória, ou seja, 部分写问题
o problema de corrupção de página: o mecanismo InnoDB usa páginas como unidades e o tamanho de cada página é de 16 K. O sistema operacional ( Linux) também usa páginas como unidades, mas seu tamanho é 4K, ou seja, quando os dados na memória querem ser atualizados para o disco, eles devem primeiro ser entregues à página do sistema operacional e à página do sistema operacional será atualizado para o disco. Isso significa que toda vez que uma página de dados da memória é atualizada, ela deve ser gravada no sistema operacional quatro vezes. No entanto, se ocorrer um acidente, como um tempo de inatividade durante essas 4 vezes, uma página incompleta da memória será gravada no disco, resultando em danos à página ( 部分写问题). Neste momento, o princípio da persistência não pode ser violado, então como recuperar os dados que não foram gravados corretamente no disco devido ao tempo de inatividade e assim por diante?
Em primeiro lugar, o que pensei foi garantir que os dados da memória fossem gravados no disco e houvesse um redo log. Mas o que é registrado no redo log? É um registro físico, ou seja, os dados de endereço da página xxx cujo deslocamento é xxx é xxxx, mas a página do registro que causou o downtime não foi totalmente gravada e a página está danificada, o que significa que o registro de 已经损坏!dados do endereço da página correspondente também é inválido. Então refazer não pode usar
o binlog? A função do binlog é backup de dados e replicação mestre-escravo, não presta atenção aos dados da memória e do disco, ou seja, não consegue distinguir quais foram gravados no disco e quais estão em páginas sujas.
Se a recuperação completa for realizada, parece estar tudo bem. Mas o custo é muito alto, não é realista.
Neste momento, é introduzido o mecanismo de double-write, ou seja, as páginas gravadas no redo log não são operadas primeiro, de forma a evitar que a página gravada no redo seja danificada e invalidada após ocorrer um acidente durante o processo de escrita .
Então, onde escrever os dados primeiro? O local para gravar deve estar no disco, caso contrário, não faz sentido. Porque o que fazemos é backup interativo entre memória e disco.
O mecanismo InnoDB permite que o pedido seja primeiro gravado no espaço de tabela do sistema e, em seguida, gravado discretamente no espaço de tabela independente correspondente após o sucesso. O InnoDB também otimiza a velocidade de gravação de gravação dupla, porque a gravação dessa maneira é uma gravação sequencial, mais uma operação de IO é adicionada e a perda de desempenho causada por ela também é minimizada.
O acima é por que a introdução双写机制
Arquivo de gravação dupla
Com este mecanismo, deve haver um arquivo de armazenamento correspondente.
O cache de gravação dupla tem uma parte compartilhada, parte na memória e parte no disco. Cada parte é fixada em 2 M.
O buffer de gravação dupla é de 128 páginas no espaço de tabela do disco, ou seja, duas áreas com 1 M cada, totalizando 2 M. Quando os dados do Buffer Pool são copiados, os dados devem primeiro ser copiados para a parte da memória do cache de gravação dupla e, em seguida, a parte da memória é dividida em duas vezes e o arquivo de gravação dupla da parte do disco é gravado primeiro no arquivo de gravação dupla com um tamanho de 1 M de cada vez. Depois que a gravação for bem-sucedida, grave discretamente os mesmos dados no espaço de tabela independente correspondente.
Quando a memória aciona o mecanismo de ponto de verificação, ela começa a gravar algumas páginas no disco. O processo específico é o seguinte:
- Copie as páginas sujas a serem gravadas na memória e copie-as para
double writea parte da memória - A parte da memória de gravação dupla é gravada em uma área por vez, ou seja, 1M, e gravada na parte do espaço de tabela do sistema em duas ordens
- Depois de confirmar que a gravação foi bem-sucedida, a parte da memória da gravação dupla grava discretamente os mesmos dados no espaço de tabela independente correspondente
E se ocorrer um acidente no processo de gravação dupla?
Ocorre um acidente na primeira gravação: a primeira vez é gravar os dados da memória (buffer de memória de gravação dupla) no arquivo de tabela do sistema para backup.
Se ocorrer um acidente neste processo, 但redo记载的页没有发生损坏você pode usar redo para restaurar diretamente
o segundo Acidente na segunda gravação: A segunda gravação é para gravar os dados da memória (buffer de memória de gravação dupla) no espaço de tabela independente correspondente. Um
acidente na gravação no disco fará com que a página seja danificada , e a página gravada em redo também será inválida neste momento. Mas com o arquivo no tablespace do sistema, quando o sistema estiver reiniciando, ele irá verificar se a página do processo está intacta. Se a página estiver danificada, ela será restaurada do tablespace do sistema. A página redo é impossível de
ter um acidente, porque somente depois que a página de redo é escrita com sucesso, o negócio é considerado concluído.
Exemplo: existe uma tabela de usuários, id é a chave primária, nome é um índice comum e idade é um campo comum. Quando eu me conecto ao MySQL e abro uma transação na tabela de usuários 修改e envio a idade do usuário cujo nome é 'zs' para 10, o processo interno geral do MySQL: A
camada de conexão do MySQL estabelece uma conexão com o cliente e verifica a sintaxe e a semântica da instrução SQL Finalmente, entregue-a à camada do mecanismo. O mecanismo que encontrou esta tabela é o mecanismo InnoDB. O mecanismo InnoDB procurará o usuário cujo nome é 'zs' no Buffer Pool. Se não for encontrado, ele usará o índice não clusterizado para usar o nome como o valor do índice para encontrar o id desta linha de dados. id vai para o índice clusterizado para encontrar a página (em xxx.ibd文件中) onde esta linha de dados está localizada, carrega-a em Buffer Poole coloca um bloqueio de gravação, bloqueio MDL, etc. linha (este processo possui um mecanismo MVCC para ler esta linha de dados). Ao mesmo tempo, aponte o ponteiro do log de desfazer nos dados para o registro do log de desfazer antes que a transação seja aberta e abra um novo log de desfazer ao mesmo tempo. Em seguida, altere a idade para 10 no Buffer Pool. Neste momento, redo registra a modificação dos dados no endereço do disco, desfaz registros como restaurar a operação de registro original e binlog registra a operação de comando do usuário. Quando a transação é enviada , redo e binlog serão imediatamente O conteúdo do buffer é liberado para o disco e desfazer é entregue ao segmento Purge Thread para reciclagem. No entanto, os dados modificados na memória podem não ser liberados para o disco.Quando houver outros dados para ler, os dados no Buffer Pool serão retornados diretamente. Quando a página suja desses dados acionar cheakPointo mecanismo, a página suja será copiada do Buffer Pool para double writero buffer de memória e os dados serão gravados na tabela do sistema duas vezes na memória. Grave os dados na memória na página correspondente . Os registros de redo log correspondentes são inúteis e serão substituídos por novos dados.