Diretório de artigos
1. O que é RDD
(1) Conceito de RDD
1. O Spark fornece uma abstração básica de dados chamada Resilient Distributed Dataset (RDD). Todo ou parte desse conjunto de dados pode ser armazenado em cache na memória e reutilizado em vários cálculos. O RDD é, na verdade, uma coleção de dados distribuídos em vários nós.
2. A elasticidade do RDD significa principalmente que, quando a memória é insuficiente, os dados podem ser persistidos no disco, e o RDD tem tolerância a falhas eficiente.
Um conjunto de dados distribuído significa que um conjunto de dados é armazenado em nós diferentes e cada nó armazena uma parte do conjunto de dados.
(2) Exemplo de RDD
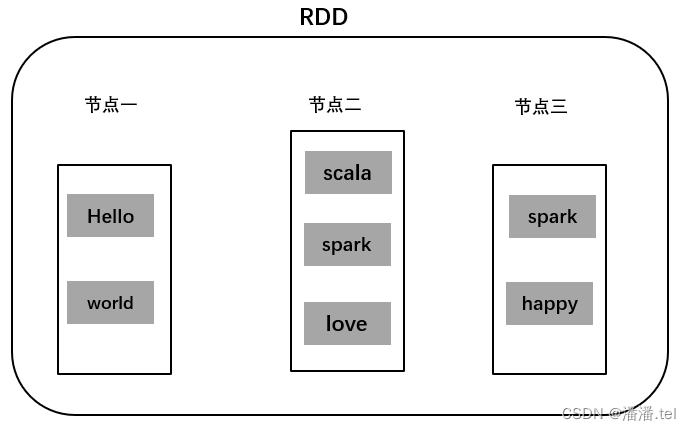
Armazene o conjunto de dados (hello, world, scala, spark, love, spark, happy) em três nós, lojas do nó 1 (hello, world), lojas do nó 2 (scala, spark, love), lojas do nó 3 (spark, feliz ), de modo que os dados dos três nós possam ser calculados em paralelo e os dados dos três nós juntos formem um RDD.
(3) Principais características do RDD
RDDs são imutáveis, mas RDDs podem ser transformados em novos RDDs para operações.
RDDs são particionáveis. O RDD consiste em muitas partições e cada partição corresponde a uma tarefa Tarefa a ser executada.
Operar no RDD é equivalente a operar em cada partição do RDD.
O RDD possui uma série de funções que realizam cálculos em partições, chamadas de operadores.
Existem dependências entre RDDs, que podem ser canalizadas e evitar o armazenamento de dados intermediários.
2. Prepare-se
(1) Preparar documentos
1. Prepare os arquivos do sistema local
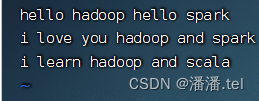
Crie test.txt no diretório /home

palavras separadas por espaços
2. Inicie o serviço HDFS
Execute o comando: start-dfs.sh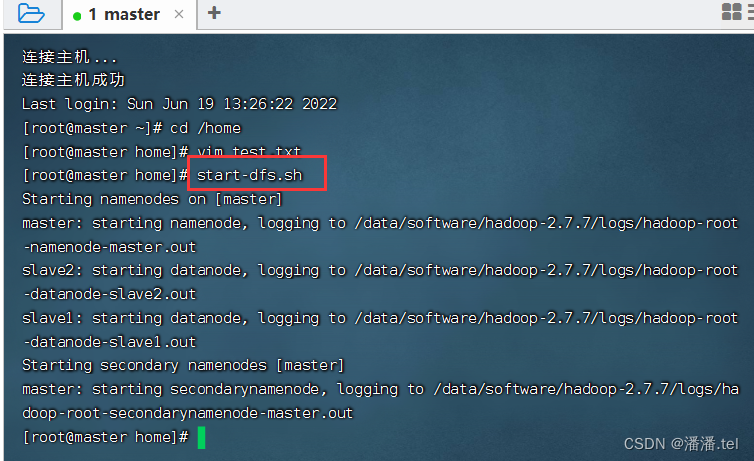
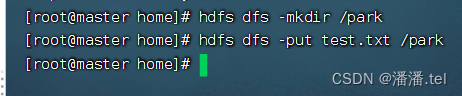
3. Faça upload de arquivos para HDFS
Carregar test.txt para o diretório /park do HDFS

ver o conteúdo do arquivo
(2) Inicie o Spark Shell
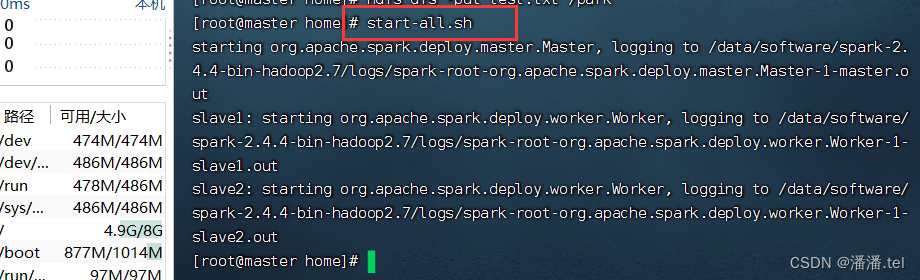
1. Inicie o serviço Spark
Execute o comando: start-all.sh
2. Inicie o Spark Shell

Veja a interface WebUi do Spark Shell
3. Criar RDD
(1) Crie um RDD a partir de uma coleção de objetos
O Spark pode converter uma coleção de objetos em um RDD por meio dos métodos parallelize() ou makeRDD().
1. Use o método parallelize() para criar RDD
Executando uma ordem:val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8)) 
2. Use o método makeRDD() para criar RDD
Execute o comando: val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8))

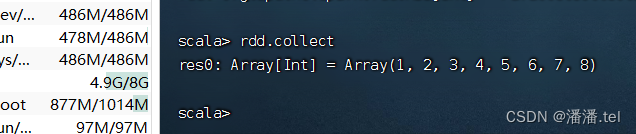
Execute o comando: rdd.collect(), colete dados rdd para exibição

Os colchetes do operador de ação [action operator] collect() podem ser omitidos
3. Breve descrição
(2) Criar RDD a partir de armazenamento externo
O método textFile() do Spark pode ler dados no sistema de arquivos local ou em outros sistemas externos e criar RDD. A diferença é que o caminho de origem dos dados é diferente
1. Leia os arquivos do sistema local

Execute o comando: val lines = rdd.collect(), visualize o conteúdo no RDD e salve-o nas linhas constantes

Execute o comando: lines.foreach(println) (use o operador de travessia foreach)

Execute o comando: for (linha <- linhas) println (linha)
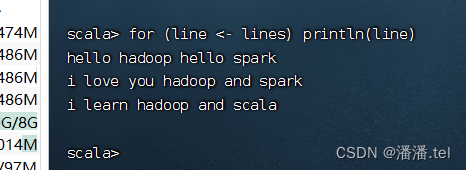
usando o loop for para obter

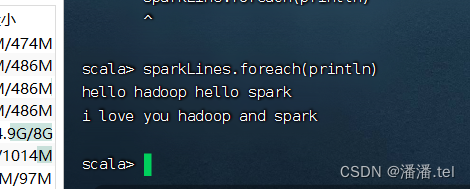
2. Leia arquivos em HDFS
Execute o comando: `val rdd = sc.textFile("hdfs://master:9000/park/test.txt")
` 
Execute o comando: val lines = rdd.collect, visualize o conteúdo no RDD

para obter as linhas contendo spark, execute o comando: val sparkLines = rdd.filter((line) => line.contains(“spark”)) (o filtro é um operador de transformação [operador de transformação])

Existe uma maneira mais simples de escrever, execute o comando: `val sparkLines = rdd.filter(_.contains(“spark”))
`

Use o operador transversal para exibir o conteúdo de sparkLines