De: Sem Dados Não Inteligente
No momento, as informações sobre o chatGPT estão muito dispersas e não há nenhum artigo detalhando todos os pontos de conhecimento e visão geral do sistema, portanto, o autor fez este artigo resumido.
Visão geral do processo de treinamento
Esclarecer o caminho evolutivo
Pré treino
Visão geral do GPT-3
A ideia do modelo GPT 3
Como o GPT-3 aprende
conjunto de dados
Ajuste fino de instrução (IFT)
Ajuste Fino Supervisionado (SFT)
Aprendizagem por Reforço de Feedback Humano (Aprendizado por Reforço de Feedback Humano, RLHF)
Outros métodos
Cadeia de pensamento (CoT)
Trabalho semelhante ao chatGPT
citar
Entre no grupo NLP —> junte-se ao grupo de troca NLP (observação nips/emnlp/nlpcc entra no grupo de contribuição correspondente)
Visão geral do processo de treinamento
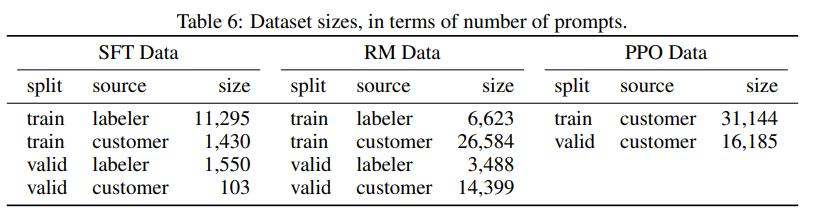
O OpenAI usa um modelo de linguagem grande (LM) com parâmetros de 175B e um modelo de recompensa (RM) com parâmetros de 6B. Além do pré-treinamento, o processo de treinamento é dividido em três etapas:
Colete conjuntos de dados de várias tarefas de NLP, adicione descrições de tarefas e prompts para montar novos conjuntos de dados e use esses dados para ajustar modelos de linguagem de grande escala pré-treinados. Incluindo ajuste fino de instrução e ajuste fino supervisionado .
Amostra do conjunto de dados acima, gere várias respostas usando um grande modelo de linguagem, classifique manualmente essas respostas e treine um modelo de recompensa (RM) para atender às preferências humanas.
Com base no modelo de ajuste fino supervisionado no primeiro estágio e no modelo de recompensa no segundo estágio, um grande modelo de linguagem é treinado posteriormente usando um algoritmo de aprendizado por reforço.

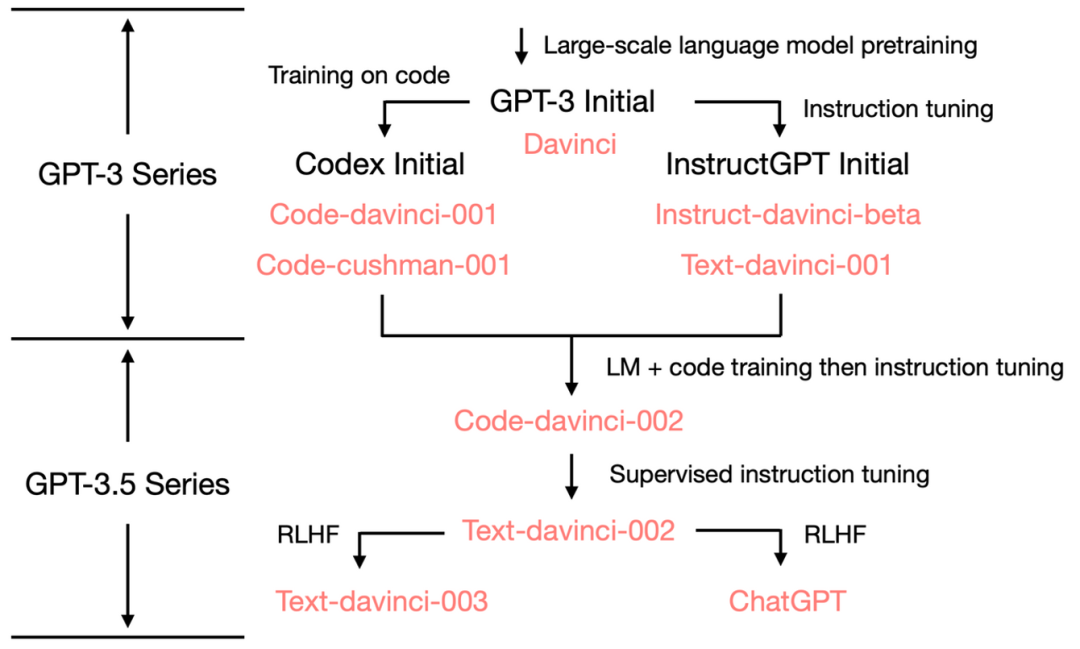
Esclarecer o caminho evolutivo
A quantidade de parâmetros do GPT-3.5 ainda é 175B, e a árvore evolutiva geral é a seguinte:

Pré treino
Visão geral do GPT-3
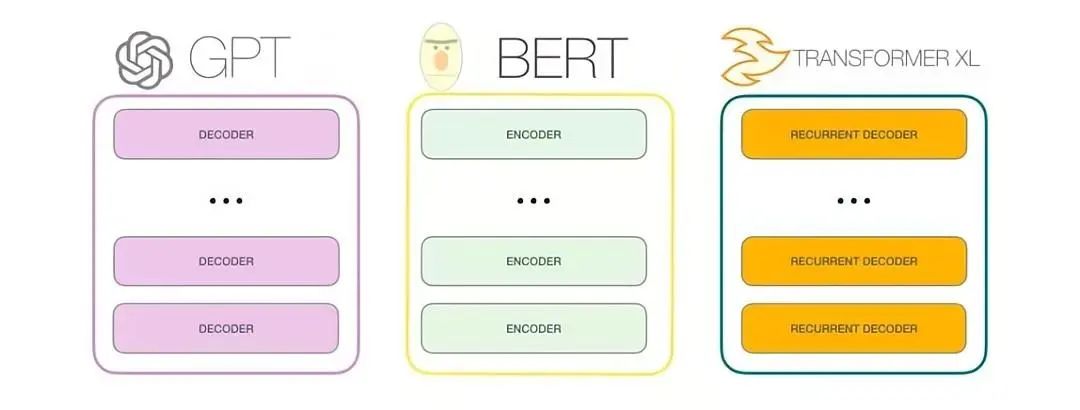
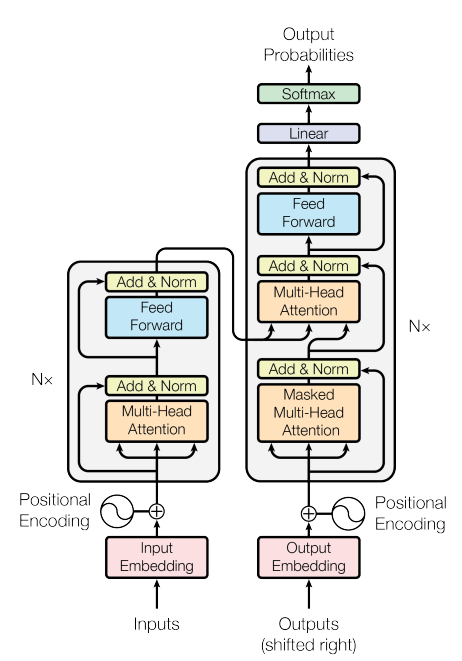
O GPT-3 é um modelo autorregressivo que usa apenas um decodificador, e o objetivo do treinamento também é prever a próxima palavra (a tarefa de não julgar a próxima frase).
O maior modelo GPT-3 tem parâmetros 175B, que é 470 vezes maior que o modelo BERT (0,375B)

A ideia do modelo GPT 3
Não há necessidade de se conectar a uma nova estrutura de modelo: se bert for usado para tarefas NER, geralmente é conectado a LSTM+CRF
nenhum ajuste fino necessário
Um modelo resolve várias tarefas de PNL
Tarefas de PNL podem ser resolvidas com modelos generativos
Como os humanos, ele só precisa ver um número muito pequeno de exemplos para aprender
Como o GPT-3 aprende
Aprendizado zero-shot: fornecer descrição da tarefa, dicas
Aprendizagem única: forneça uma descrição da tarefa, um exemplo, dicas
Aprendizagem de poucos tiros: forneça descrição da tarefa, alguns exemplos, dicas

conjunto de dados
| Modelo | tempo de lançamento | Valor do parâmetro | A quantidade de dados pré-treinamento |
|---|---|---|---|
| BERT-large | março de 2019 | 375 milhões | cerca de 3,3 GB |
| GPT | junho de 2018 | 117 milhões | cerca de 5 GB |
| GPT-2 | fevereiro de 2019 | 1.5 bilhoes | 40GB |
| GPT-3 | maio de 2020 | 175 bilhões | 45 TB |
BERT-large:LivrosCorpus 800 milhões de palavras、 Wikipédia em inglês 2,5Bpalavras
GPT: WebText2, BooksCorpus, Wikipedia acima de 5 GB.
GPT-2: A quantidade total de WebText2, BooksCorpus e Wikipedia atingiu 40 GB.
GPT-3: **WebText2, BooksCorpus, Wikipedia, Common Crawl** e outros conjuntos de dados com 45 TB de dados.
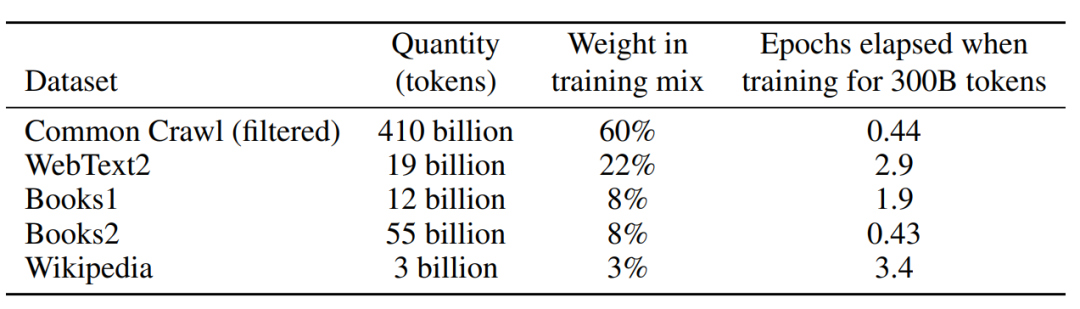
imagem-20230221153905277
Ajuste fino de instrução (IFT)
Colete conjuntos de dados de várias tarefas de NLP, adicione descrições de tarefas e dicas para montar novos conjuntos de dados. Os conjuntos de dados usados pelo chatGPT são os seguintes:
Alguns papéis relacionados:
Instruções não naturais (Honovich 等, '22): https://arxiv.org/abs/2212.09689
Instruções sobrenaturais (Wang 等, '22): https://arxiv.org/abs/2204.07705
Autoinstrução (Wang 等, '22): https://arxiv.org/abs/2212.10560
T0 (Sanh et al., '22): https://arxiv.org/abs/2110.08207
Conjunto de dados de instruções naturais (Mishra et al., '22): https://arxiv.org/abs/2104.08773
FLAN LM (Wei et al, '22): https://arxiv.org/abs/2109.01652
OPT-IML (Iyer 等, '22): https://arxiv.org/abs/2212.12017
Ajuste Fino Supervisionado (SFT)
Esta etapa não é para evitar respostas sem sentido como [não sei] ao encontrar tópicos delicados, para adicionar alguns dados rotulados manualmente para aumentar a segurança da resposta e pode ser concluída com um conjunto de dados de 100 níveis .

Alguns papéis relacionados:
LaMDA do Google: Apêndice A https://arxiv.org/abs/2201.08239
Sparrow por DeepMind: Sparrow: Apêndice F https://arxiv.org/abs/2209.14375
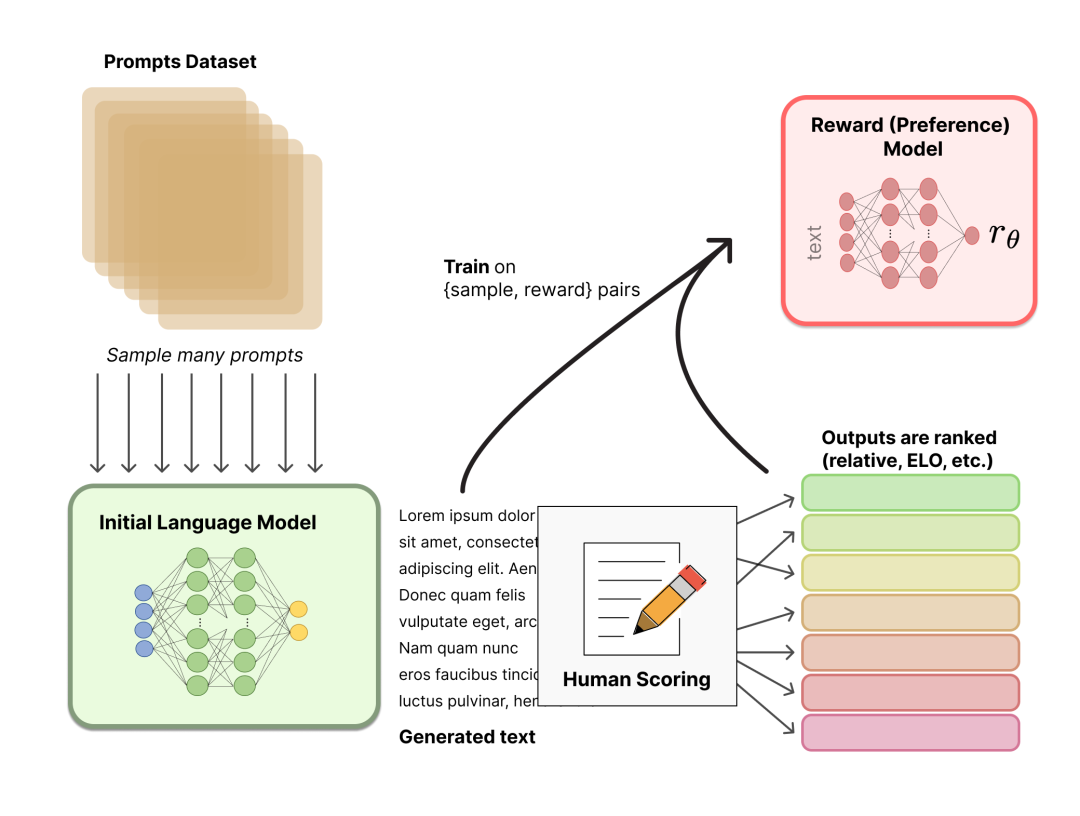
Aprendizagem por Reforço de Feedback Humano (Aprendizado por Reforço de Feedback Humano, RLHF)
descrever:
Política: Um LM que pega um prompt e retorna uma sequência de textos (ou uma distribuição de probabilidade de textos).
Action space (espaço de ação): todos os tokens correspondentes ao vocabulário de LM (geralmente na ordem de 50k),
O espaço de observação é a sequência de possíveis tokens de entrada, que também é relativamente grande (vocabulário ^ número de tokens de entrada).
A função de recompensa é uma combinação de um modelo de preferência e uma restrição de mudança de política.
Este processo é um processo de duas etapas :
Agregue dados de perguntas e respostas e treine um modelo de recompensa (Modelo de recompensa, RM)
LMs de ajuste fino com aprendizado por reforço (RL)
Conjuntos de dados de código aberto:
Antrópico/hh-rlhf · Conjuntos de dados no rosto de abraço
OpenAI usa feedback enviado por usuários.
Outros métodos
Esta parte apresenta brevemente alguns métodos paralelos ao ajuste fino usado pelo chatGPT
Cadeia de pensamento (CoT)
Ajuste fino usando alguns conjuntos de dados com inferência passo a passo, conforme mostrado abaixo
Laranja é a descrição da tarefa, rosa é a pergunta e resposta e azul é o processo de raciocínio
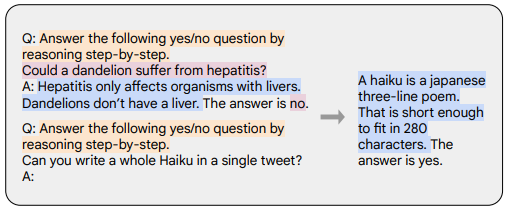
Cadeia de dicas de pensamento (Wei et al., '22): https://arxiv.org/abs/2201.11903
Trabalho semelhante ao chatGPT
BlenderBot da Meta: https://arxiv.org/abs/2208.03188
LaMDA do Google: https://arxiv.org/abs/2201.08239
Pardal por DeepMind: https://arxiv.org/abs/2209.14375
Anthropic 的 Assistant: https://arxiv.org/abs/2204.05862
citar
MODELOS DE TRANSFORMADORES: UMA INTRODUÇÃO E CATÁLOGO
WebGPT: Resposta a perguntas assistida por navegador com feedback humano
Modelos de linguagem de treinamento para seguir instruções com feedback humano
https://mp.weixin.qq.com/s/b0AI01-pUnXVWPPXix-hew
https://openai.com/blog/chatgpt/
https://mp.weixin.qq.com/s/eYmssaPFODjC7xwh1jHydQ
https://mp.weixin.qq.com/s/mXViN_GB9VC1WrXP1Q1iug
https://mp.weixin.qq.com/s/y9Jy9AyAyTCgCOKyMgTo3w
https://zhuanlan.zhihu.com/p/595891945
https://www.hpc-ai.tech/blog/colossal-ai-chatgpt
https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
https://arxiv.org/pdf/1706.03762.pdf
https://arxiv.org/pdf/2005.14165.pdf
https://arxiv.org/pdf/1810.04805.pdf
Entre no grupo NLP —> junte-se ao grupo de troca NLP (observação nips/emnlp/nlpcc entra no grupo de contribuição correspondente)
Junte-se ao planeta, você receberá:
1. Atualize 3-5 leituras de velocidade de papel mais recentes e de alta qualidade todos os dias
2. Os materiais de aprendizagem introdutórios e avançados mais recentes
4. Informações diárias de recrutamento 1-3 para cargos de IA, como PNL, pesquisa, promoção e promoção e CV
