Diretório de artigos
objetos de dados R
Divisão de tipo de objetos R
Particionando objetos R de uma perspectiva de armazenamento
(1) Tipo numérico
Tipo inteiro e tipo de número real; Tipo inteiro (Integer) é a forma de armazenamento de números inteiros, geralmente requerendo 2 bytes ou 4 bytes de espaço de armazenamento. O tipo de número real é usado para armazenar dados numéricos, incluindo casas decimais, e geralmente requer 4 bytes ou 8 bytes de espaço de armazenamento. Os dados numéricos em R são padronizados para números de precisão dupla.
(2) Tipo de caractere
, como nome e local de origem, é uma sequência de caracteres entre aspas duplas inglesas, denominada string.
(3) Tipo lógico
VERDADEIRO; FALSO
Dividir objetos R da perspectiva da estrutura de organização de dados
(1) Vetor
Vetor é a unidade básica da organização de dados do R. Do ponto de vista estatístico, um vetor corresponde a uma variável, armazenando vários valores de variáveis com o mesmo tipo de armazenamento. A menos que especificado de outra forma, os vetores são vetores de coluna.
Fator (Factor) é um tipo especial de vetor.
(2) Matriz
Uma matriz é uma forma bidimensional usada para organizar múltiplas variáveis com o mesmo tipo de armazenamento. As colunas da matriz são geralmente variáveis, observações de comportamento.
(3) Array
Um array é uma coleção de múltiplas tabelas bidimensionais, geralmente usadas para organizar dados de painel em estatísticas, etc.
(4) Quadro de dados
Um quadro de dados também é uma tabela bidimensional, semelhante a uma matriz, mas é usado para organizar e armazenar vários tipos de variáveis múltiplas. Entre eles, as colunas do quadro de dados são geralmente variáveis, observações de comportamento.
(5) Lista
Uma coleção de múltiplos vetores, matrizes, arrays, quadros de dados e listas é uma lista. É usado principalmente para "empacotar" a integração de resultados de análises estatísticas relevantes.
Criar e gerenciar objetos R
criar objeto R
对象名<-R常量或R函数
Acesso a objetos R
print(对象名)
Exibir a estrutura de um objeto R
str(对象名)
Gerenciar objetos R
ls()当前工作空间中的对象名列表将显示在R的控制台窗口中
rm(对象名或对象名列表)对象名列表中包含多个对象名,各个对象之间用英文逗号分隔
remove(对象名)删除当前工作空间中的指定对象
A maneira básica de organização de dados do R
Vetores R e sua criação e acesso
is.vector(对象名)#判断对象是否为向量
vetor R mais simples
> #创建包含一个元素的向量
> V1<-100 #创建整数形式的数值型向量V1,存储类型默认为双精度型
> V1 #显示V1的对象值
[1] 100
> V2<-123.5 #创建实数形式的数值型向量V2,存储类型为双精度型
> V2
[1] 123.5
> V3<-"abcd" #创建字符串型向量V3
> print(V3) #显示V3对象值
[1] "abcd"
> (V4<-TRUE) #创建逻辑型向量V4,并直接显示对象值
[1] TRUE
> is.vector(V1) #判断对象V1是否为向量
[1] TRUE
> is.logical(V4) #判断对象V4的存储类型是否为逻辑型
[1] TRUE
①Se a instrução de atribuição for colocada entre parênteses, significa criar um objeto e exibir diretamente o valor do objeto
②Ao exibir valores de objeto, cada linha começará automaticamente com colchetes, como [1], o número entre colchetes indica o primeiro elemento é o número de elementos no objeto de vetor R.
Usando vetores R para organizar variáveis
SiteName<-c("东四","天坛","官园","万寿西宫","奥体中心","农展馆","万柳","北部新区","植物园","丰台花园",
"云岗","古城","房山","大兴","亦庄","通州","顺义","昌平","门头沟","平谷","怀柔","密云","延庆","定陵",
"八达岭","密云水库","东高村","永乐店","榆垡","琉璃河","前门","永定门内","西直门北","南三环","东四环")
SiteTypes<-c(rep("城区环境评价点",12),rep("郊区环境评价点",11),rep("对照点及区域点",7),rep("交通污染监控点",5))
> length(SiteName)
[1] 35
> length(SiteTypes)
[1] 35
rep("城区环境评价点",12)Indica a geração repetida de 12 pontos de avaliação do ambiente urbano
Acessando elementos em um vetor R
> a<-vector(length=10)#创建包含10个元素的向量a
> a#显示初始值
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
> a[1]<-1#访问第一个元素,并赋值为1
> a[2:4]<-c(2,3,4)#访问第2至第4个元素,并赋值为2,3,4
> a
[1] 1 2 3 4 0 0 0 0 0 0
> b<-seq(from=5,to=9,by=1)#生成一个取值5至9的序列给向量b
> b
[1] 5 6 7 8 9
> a[c(5:9,10)]<-c(b,10)
> a
[1] 1 2 3 4 5 6 7 8 9 10
> b<-(2:4)#创建数值型位置向量b,依次取值为2,3,4
> a[b]#访问a中位置向量b所指位置(即2,3,4)上的元素
[1] 2 3 4
> b<-c(TRUE,FALSE,FALSE,TRUE,FALSE,FALSE,FALSE,FALSE,FALSE,FALSE)#创建逻辑型向量b
> a[b]#访问a中位置向量b取值为TRUE位置(即1,4)上的元素
[1] 1 4
> a[-1]#访问除第一个元素以外的元素
[1] 2 3 4 5 6 7 8 9 10
> a[-(2:4)]#访问除第2至第4个元素以外的元素
[1] 1 5 6 7 8 9 10
> a[-c(5:9,10)]#访问除第5至第9以及第10个元素以外的元素
[1] 1 2 3 4
> b<-(2:4)
> a[-b]#访问除位置向量b以外的元素
[1] 1 5 6 7 8 9 10
> ls()#显示当前工作空间中的对象列表
[1] "a" "b"
> rm(a,b)#删除当前工作空间中的对象a和对象b
Vetores especiais para R: fatores
> (a<-c("Poor","Improved","Excellent","Poor"))#创建包含4个元素的字符型向量a
[1] "Poor" "Improved" "Excellent" "Poor"
> is.vector(a)#判断a是否为向量
[1] TRUE
> (b<-as.factor(a))#将字符型向量a转换为因子b并显示b
[1] Poor Improved Excellent Poor
Levels: Excellent Improved Poor
> is.factor(b)#判断b是否为因子
[1] TRUE
> levels(b)#按因子水平值升序显示所对应的类别值
[1] "Excellent" "Improved" "Poor"
> typeof(b)#显示因子b的存储类型名
[1] "integer"
> (a<-c("Poor","Improved","Excellent","Poor"))#创建字符型向量a
[1] "Poor" "Improved" "Excellent" "Poor"
> (b<-factor(a,order=FALSE,levels=c("Poor","Improved","Excellent")))#指定类别值和水平值的对应关系
[1] Poor Improved Excellent Poor
Levels: Poor Improved Excellent
> (b<-factor(a,order=TRUE, levels=c("Poor","Improved","Excellent")))
[1] Poor Improved Excellent Poor
Levels: Poor < Improved < Excellent
> (a<-c("Poor","Improved","Excellent","Poor"))
[1] "Poor" "Improved" "Excellent" "Poor"
> (b<-factor(a,levels=c("Poor","Improved","Excellent")))
[1] Poor Improved Excellent Poor
Levels: Poor Improved Excellent
> (b<-factor(a,levels=c("Poor","Improved","Excellent"),labels=c("C","B","A")))
[1] C B A C
Levels: C B A
níveis é o valor original da categoria; rótulos é o novo valor da categoria
Matrizes e arrays R e sua criação e acesso
Combine vários vetores em uma matriz R
> Site<-cbind(SiteName,SiteTypes)
> is.matrix(Site)#判断对象是否为矩阵
[1] TRUE
> dim(Site)#获得矩阵的行数和列数
[1] 35 2

Converter vetores em matrizes R
> (a<-c("Poor","Improved","Excellent","Poor"))
[1] "Poor" "Improved" "Excellent" "Poor"
> data<-(1:30)#生成一个名为data的数值型向量
> data<-matrix(data,nrow=5,ncol=6,byrow=FALSE)#将向量a按列排列放置到5行6列的矩阵中
> data
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 6 11 16 21 26
[2,] 2 7 12 17 22 27
[3,] 3 8 13 18 23 28
[4,] 4 9 14 19 24 29
[5,] 5 10 15 20 25 30
Acessando elementos em uma matriz R
> data[2,3]#第2行第3列
[1] 12
> data[1:2,2:3]#访问第1行至第2行,第2列至第3列位置上的元素
[,1] [,2]
[1,] 6 11
[2,] 7 12
> data[1:2,c(1,3)]#访问第1行至第2行,第1,3列位置上的元素
[,1] [,2]
[1,] 1 11
[2,] 2 12
> data[2,]#访问第2行上的所有元素
[1] 2 7 12 17 22 27
> data[c(1,3),]#访问第1,3行上的所有元素
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 6 11 16 21 26
[2,] 3 8 13 18 23 28
> a<-c(TRUE,FALSE,TRUE,FALSE,FALSE)
> data[a,]
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 6 11 16 21 26
[2,] 3 8 13 18 23 28
> data[,1:3]#访问1-3列上的所有元素
[,1] [,2] [,3]
[1,] 1 6 11
[2,] 2 7 12
[3,] 3 8 13
[4,] 4 9 14
[5,] 5 10 15
> a<-matrix(nrow=5,ncol=2)#创建一个5x2的矩阵,初始值默认为缺失值
> a
[,1] [,2]
[1,] NA NA
[2,] NA NA
[3,] NA NA
[4,] NA NA
[5,] NA NA
> a[,1]<-seq(from=1,to=10,by=2)#给矩阵第1列赋值
> a[,2]<-seq(from=10,to=1,by=-2)#给矩阵第2列赋值
> a
[,1] [,2]
[1,] 1 10
[2,] 3 8
[3,] 5 6
[4,] 7 4
[5,] 9 2
Criar e acessar matrizes R
> a<-(1:60)
> dim1<-c("R1","R2","R3","R4")
> dim2<-c("C1","C2","C3","C4","C5")
> dim3<-c("T1","T2","T3")
> a<-array(a,c(4,5,3),dimnames = list(dim1,dim2,dim3))
> a#数组a由3张行数为4列数为5的二维表组成
> is.array(a)#判断a是否为数组
[1] TRUE
> a[1:3,c(1,3),2]#第2张表1-3行,1,3列
C1 C3
R1 21 29
R2 22 30
R3 23 31
Quadro de dados R e sua criação e acesso
Criar um quadro de dados R
> #创建数据框
> SiteName<-c("东四","天坛","官园","万寿西宫","奥体中心","农展馆","万柳","北部新区","植物园","丰台花园",
+ "云岗","古城","房山","大兴","亦庄","通州","顺义","昌平","门头沟","平谷","怀柔","密云","延庆","定陵",
+ "八达岭","密云水库","东高村","永乐店","榆垡","琉璃河","前门","永定门内","西直门北","南三环","东四环")
> SiteTypes<-c(rep("城区环境评价点",12),rep("郊区环境评价点",11),rep("对照点及区域点",7),rep("交通污染监控点",5))
> SiteX<-c(116.417,116.407,116.339,116.352,116.397,116.461,116.287,116.174,116.207,116.279,116.146,116.184,
+ 116.136,116.404,116.506,116.663,116.655,116.23,116.106,117.1,116.628,116.832,115.972,
+ 116.22,115.988,116.911,117.12,116.783,116.30,116.00,
+ 116.395,116.394,116.349,116.368,116.483)
> SiteY<-c(39.929,39.886,39.929,39.878,39.982,39.937,39.987,40.09,40.002,39.863,39.824,39.914,
+ 39.742,39.718,39.795,39.886,40.127,40.217,39.937,40.143,40.328,40.37,40.453,
+ 40.292,40.365,40.499,40.10,39.712,39.52,39.58,
+ 39.899,39.876,39.954,39.856,39.939)
> Site<-data.frame(Sitename=SiteName,Sitetypes=SiteTypes,Sitex=SiteX,Sitey=SiteY)
> names(Site)#显示数据框的域名
[1] "Sitename" "Sitetypes" "Sitex" "Sitey"
> str(Site)#显示对象的结构信息
'data.frame': 35 obs. of 4 variables:
$ Sitename : chr "东四" "天坛" "官园" "万寿西宫" ...
$ Sitetypes: chr "城区环境评价点" "城区环境评价点" "城区环境评价点" "城区环境评价点" ...
$ Sitex : num 116 116 116 116 116 ...
$ Sitey : num 39.9 39.9 39.9 39.9 40 ...
> is.data.frame(Site)#判断Site是否为数据框
[1] TRUE
> fix(Site)#显示部分数据内容
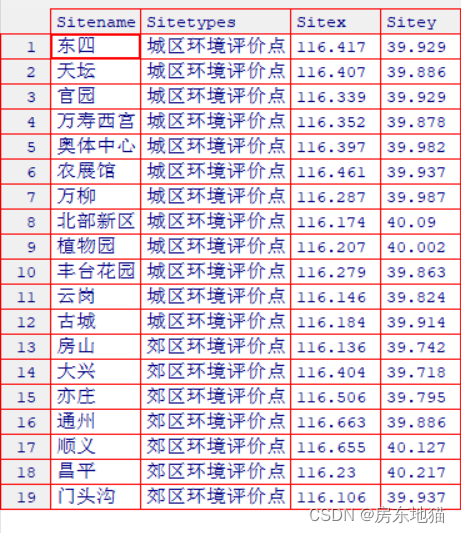
> head(Site)#仅显示数据框的前6行内容
Sitename Sitetypes Sitex Sitey
1 东四 城区环境评价点 116.417 39.929
2 天坛 城区环境评价点 116.407 39.886
3 官园 城区环境评价点 116.339 39.929
4 万寿西宫 城区环境评价点 116.352 39.878
5 奥体中心 城区环境评价点 116.397 39.982
6 农展馆 城区环境评价点 116.461 39.937
> head(Site$Sitename)#访问Sitename域且仅显示前6条内容
[1] "东四" "天坛" "官园" "万寿西宫" "奥体中心" "农展馆"
> tail(Site[["Sitename"]])#访问Sitename域且仅显示后6条内容
[1] "琉璃河" "前门" "永定门内" "西直门北" "南三环" "东四环"
> head(Site[1])#访问第一个域且仅显示前6条内容
Sitename
1 东四
2 天坛
3 官园
4 万寿西宫
5 奥体中心
6 农展馆
> tail(Site[c("Sitename","Sitetypes")])#访问Sitename和Sitetypes域且仅显示后6条内容
Sitename Sitetypes
30 琉璃河 对照点及区域点
31 前门 交通污染监控点
32 永定门内 交通污染监控点
33 西直门北 交通污染监控点
34 南三环 交通污染监控点
35 东四环 交通污染监控点
> attach(Site)#绑定Site数据框
> head(Sitename)
[1] "东四" "天坛" "官园" "万寿西宫" "奥体中心" "农展馆"
> detach(Site)#解除Site数据框的绑定
> head(Sitename)
Error in head(Sitename) : object 'Sitename' not found
Listas R e sua criação e acesso
> a<-c(1,2,3)#创建向量a
> b<-matrix(nrow=5,ncol=2)#创建矩阵b
> b[,1]=seq(from=1,to=10,by=2)
> b[,2]=seq(from=10,to=1,by=-2)
> c<-array(1:60,c(4,5,3))#创建数组c
> d<-list(L1=a,L2=b,L3=c)#创建列表d
> names(d)#显示列表d各成分名
[1] "L1" "L2" "L3"
> str(d)#显示对象d的存储类型和结构信息
List of 3
$ L1: num [1:3] 1 2 3
$ L2: num [1:5, 1:2] 1 3 5 7 9 10 8 6 4 2
$ L3: int [1:4, 1:5, 1:3] 1 2 3 4 5 6 7 8 9 10 ...
> is.list(d)#判断d是否为列表
[1] TRUE
> d$L1#访问列表d中的成分L1
[1] 1 2 3
> d[[2]]#访问列表d中的第二个成分(L2)
[,1] [,2]
[1,] 1 10
[2,] 3 8
[3,] 5 6
[4,] 7 4
[5,] 9 2
Outros problemas com a organização de dados do R
Armazenamento de dados do objeto R
write.table(Site,file="监测点信息.txt",row.names=FALSE,col.names=FALSE)
row.names=FALSE,col.names=FALSE
不将行编号和变量名写入文本文件
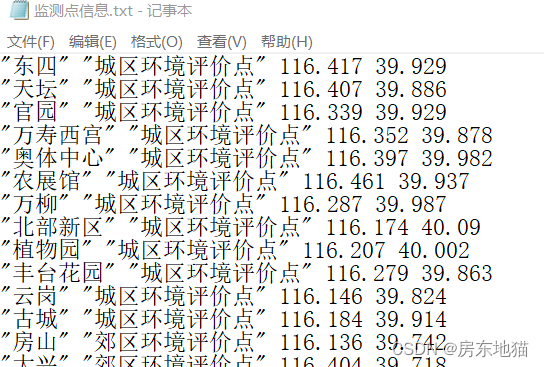
Ler dados via teclado
> a<-scan()#R将在控制台窗口等待用户输入数据,每个数据以回车键分隔
1: 10
2: 20
3: 30
4:
Read 3 items
> a
[1] 10 20 30
Quando a entrada estiver fechada, basta pressionar a tecla Enter sem inserir o conteúdo
Compartilhamento de pacotes de dados que acompanham o R
data(), o nome do conjunto de dados exibido e as informações de descrição são mostrados na figura abaixo
data("数据集名")#指定加载使用某个数据集
Estruturas de dados e organização R para casos de Big Data
Leia os dados do arquivo de texto no quadro de dados R
> getwd()#获取当前工作目录
[1] "D:/Program Files/RStudio/Projects"
> setwd("./课程数据集")#改变工作目录
> MyData<-read.table(file = "空气质量.txt",header = TRUE,sep=" ",stringsAsFactors = FALSE)
> str(MyData)
'data.frame': 12705 obs. of 11 variables:
$ SiteName : chr "奥体中心" "奥体中心" "奥体中心" "奥体中心" ...
$ date : int 20160101 20160626 20160505 20160307 20160907 20160314 20160717 20160122 20161119 20160526 ...
$ PM2.5 : num 165 39.9 48.7 50 40.2 ...
$ AQI : num 154.6 68.1 55.1 120.8 67.9 ...
$ CO : num 3.929 0.454 0.946 0.992 0.607 ...
$ NO2 : num 122.6 35.1 41 30.4 43.7 ...
$ O3 : num 10.7 119.2 82.1 53.3 106.9 ...
$ SO2 : num 45.67 4.88 14.83 14.83 4 ...
$ SiteTypes: chr "城区环境评价点" "城区环境评价点" "城区环境评价点" "城区环境评价点" ...
$ SiteX : num 116 116 116 116 116 ...
$ SiteY : num 40 40 40 40 40 ...